परिचय
जेनेरिक एआई के तेजी से विकसित हो रहे परिदृश्य में, वेक्टर डेटाबेस की महत्वपूर्ण भूमिका तेजी से स्पष्ट हो गई है। यह लेख वेक्टर डेटाबेस और जेनरेटिव एआई समाधानों के बीच गतिशील तालमेल पर प्रकाश डालता है, यह पता लगाता है कि ये तकनीकी आधार कृत्रिम बुद्धिमत्ता रचनात्मकता के भविष्य को कैसे आकार दे रहे हैं। इस शक्तिशाली गठबंधन की पेचीदगियों के माध्यम से एक यात्रा पर हमारे साथ जुड़ें, परिवर्तनकारी प्रभाव में अंतर्दृष्टि को अनलॉक करें जो वेक्टर डेटाबेस अभिनव एआई समाधानों में सबसे आगे लाते हैं।
सीखने के मकसद
यह आलेख आपको नीचे दिए गए वेक्टर डेटाबेस के पहलुओं को समझने में मदद करता है।
- वेक्टर डेटाबेस का महत्व और इसके प्रमुख घटक
- पारंपरिक डेटाबेस के साथ वेक्टर डेटाबेस की तुलना का विस्तृत अध्ययन
- अनुप्रयोग-दृष्टिकोण से वेक्टर एंबेडिंग का अन्वेषण
- पिनकोन का उपयोग करके वेक्टर डेटाबेस निर्माण
- लैंगचैन एलएलएम मॉडल का उपयोग करके पाइनकोन वेक्टर डेटाबेस का कार्यान्वयन
इस लेख के एक भाग के रूप में प्रकाशित किया गया था डेटा साइंस ब्लॉगथॉन।
विषय - सूची
वेक्टर डेटाबेस क्या है?
वेक्टर डेटाबेस अंतरिक्ष में संग्रहीत डेटा संग्रह का एक रूप है। फिर भी, यहां, इसे गणितीय अभ्यावेदन में संग्रहीत किया जाता है क्योंकि डेटाबेस में संग्रहीत प्रारूप खुले एआई मॉडल के लिए इनपुट को याद रखना आसान बनाता है और हमारे खुले एआई एप्लिकेशन को विभिन्न उपयोग के मामलों के लिए संज्ञानात्मक खोज, सिफारिशों और पाठ पीढ़ी का उपयोग करने की अनुमति देता है। डिजिटल रूप से परिवर्तित उद्योग। डेटा संग्रहीत करना और पुनर्प्राप्ति को "वेक्टर एंबेडिंग" या "एंबेडिंग" कहा जाता है। इसके अलावा, इसे संख्यात्मक सरणी प्रारूप में दर्शाया गया है। विशाल, अनुक्रमित क्षमताओं वाले एआई परिप्रेक्ष्य के लिए उपयोग किए जाने वाले पारंपरिक डेटाबेस की तुलना में खोजना बहुत आसान है।
वेक्टर डेटाबेस के लक्षण
- यह इन वेक्टर एम्बेडिंग की शक्ति का लाभ उठाता है, जिससे विशाल डेटासेट में अनुक्रमण और खोज होती है।
- सभी डेटा प्रारूपों (चित्र, पाठ, या डेटा) के साथ कॉम्पैक्ट करने योग्य।
- चूंकि यह एम्बेडिंग तकनीकों और अत्यधिक अनुक्रमित सुविधाओं को अपनाता है, यह दी गई समस्या के लिए डेटा और इनपुट के प्रबंधन के लिए एक संपूर्ण समाधान प्रदान कर सकता है।
- एक वेक्टर डेटाबेस सैकड़ों आयाम वाले उच्च-आयामी वैक्टर के माध्यम से डेटा को व्यवस्थित करता है। हम उन्हें बहुत जल्दी कॉन्फ़िगर कर सकते हैं.
- प्रत्येक आयाम उस डेटा ऑब्जेक्ट की एक विशिष्ट विशेषता या संपत्ति से मेल खाता है जिसका वह प्रतिनिधित्व करता है।
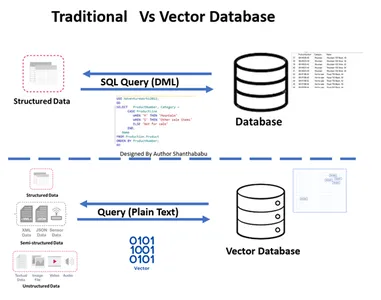
पारंपरिक बनाम. वेक्टर डेटाबेस
- चित्र पारंपरिक और वेक्टर डेटाबेस उच्च-स्तरीय वर्कफ़्लो दिखाता है
- औपचारिक डेटाबेस इंटरैक्शन के माध्यम से होता है एसक्यूएल पंक्ति-आधार और सारणीबद्ध प्रारूप में संग्रहीत कथन और डेटा।
- वेक्टर डेटाबेस में, इंटरैक्शन सादे पाठ (उदाहरण के लिए, अंग्रेजी) और गणितीय अभ्यावेदन में संग्रहीत डेटा के माध्यम से होता है।
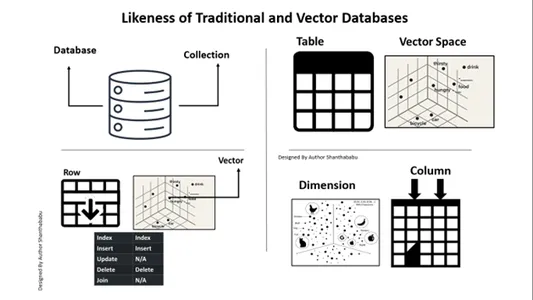
पारंपरिक और वेक्टर डेटाबेस की समानता
हमें इस बात पर विचार करना चाहिए कि वेक्टर डेटाबेस पारंपरिक डेटाबेस से किस प्रकार भिन्न हैं। आइए यहां इस पर चर्चा करें। एक त्वरित अंतर जो मैं दे सकता हूं वह पारंपरिक डेटाबेस में है। डेटा को ठीक वैसे ही संग्रहीत किया जाता है जैसे वह है; हम डेटा को ट्यून करने और व्यावसायिक आवश्यकताओं या मांगों के आधार पर डेटा को मर्ज या विभाजित करने के लिए कुछ व्यावसायिक तर्क जोड़ सकते हैं। हालाँकि, वेक्टर डेटाबेस में बड़े पैमाने पर परिवर्तन होता है, और डेटा एक जटिल वेक्टर प्रतिनिधित्व बन जाता है।
आपकी समझ और स्पष्टता के दृष्टिकोण के लिए यहां एक मानचित्र है संबंधपरक डेटाबेस वेक्टर डेटाबेस के विरुद्ध। पारंपरिक डेटाबेस के साथ वेक्टर डेटाबेस को समझने के लिए नीचे दी गई तस्वीर स्व-व्याख्यात्मक है। संक्षेप में, हम वेक्टर डेटाबेस में इंसर्ट और डिलीट निष्पादित कर सकते हैं, अपडेट स्टेटमेंट नहीं।
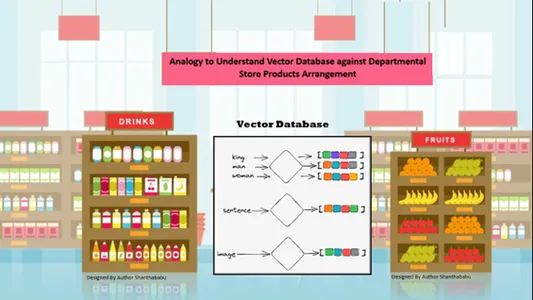
वेक्टर डेटाबेस को समझने के लिए सरल सादृश्य
संग्रहीत जानकारी में सामग्री की समानता के आधार पर डेटा स्वचालित रूप से स्थानिक रूप से व्यवस्थित होता है। तो, आइए वेक्टर डेटाबेस सादृश्य के लिए डिपार्टमेंटल स्टोर पर विचार करें; सभी उत्पादों को प्रकृति, उद्देश्य, निर्माण, उपयोग और मात्रा-आधार के आधार पर शेल्फ पर व्यवस्थित किया गया है। एक समान व्यवहार में, डेटा हैं
वेक्टर डेटाबेस में स्वचालित रूप से एक समान प्रकार से व्यवस्थित किया जाता है, भले ही डेटा को संग्रहीत या एक्सेस करते समय शैली को अच्छी तरह से परिभाषित नहीं किया गया हो।
वेक्टर डेटाबेस विशिष्ट समानताओं पर एक प्रमुख विवरण और आयाम की अनुमति देते हैं, इसलिए ग्राहक वांछित उत्पाद, निर्माता और मात्रा की खोज करता है और आइटम को कार्ट में रखता है। वेक्टर डेटाबेस सभी डेटा को एक आदर्श भंडारण संरचना में संग्रहीत करता है; यहां, मशीन लर्निंग और एआई इंजीनियरों को संग्रहीत सामग्री को मैन्युअल रूप से लेबल या टैग करने की आवश्यकता नहीं है।
वेक्टर डेटाबेस के पीछे आवश्यक सिद्धांत
- वेक्टर एंबेडिंग और उनका दायरा
- अनुक्रमण आवश्यकताएँ
- सिमेंटिक और समानता खोज को समझना
वेक्टर एंबेडिंग और उनका दायरा
एक वेक्टर एम्बेडिंग संख्यात्मक मानों के संदर्भ में एक वेक्टर प्रतिनिधित्व है। एक संपीड़ित प्रारूप में, एम्बेडिंग मूल डेटा के अंतर्निहित गुणों और संघों को कैप्चर करती है, जिससे वे आर्टिफिशियल इंटेलिजेंस और मशीन लर्निंग उपयोग के मामलों में प्रमुख बन जाते हैं। मूल डेटा के बारे में प्रासंगिक जानकारी को निचले-आयामी स्थान में एन्कोड करने के लिए एम्बेडिंग डिज़ाइन करना उच्च-पुनर्प्राप्ति गति, कम्प्यूटेशनल दक्षता और कुशल भंडारण सुनिश्चित करता है।
डेटा के सार को अधिक समान रूप से संरचित तरीके से कैप्चर करना वेक्टर एम्बेडिंग की प्रक्रिया है, जो एक 'एंबेडिंग मॉडल' बनाती है। अंततः, ये मॉडल सभी डेटा ऑब्जेक्ट पर विचार करते हैं, डेटा स्रोत के भीतर सार्थक पैटर्न और संबंध निकालते हैं, और उन्हें वेक्टर एम्बेडिंग में बदल देते हैं। इसके बाद, एल्गोरिदम विभिन्न कार्यों को निष्पादित करने के लिए इन वेक्टर एम्बेडिंग का लाभ उठाते हैं। कई अत्यधिक विकसित एम्बेडिंग मॉडल, जो मुफ़्त या भुगतान के रूप में ऑनलाइन उपलब्ध हैं, वेक्टर एम्बेडिंग की उपलब्धि की सुविधा प्रदान करते हैं।
अनुप्रयोग-दृष्टिकोण से वेक्टर एंबेडिंग का दायरा
ये एम्बेडिंग कॉम्पैक्ट हैं, इसमें जटिल जानकारी होती है, वेक्टर डेटाबेस में संग्रहीत डेटा के बीच संबंध विरासत में मिलते हैं, समझ और निर्णय लेने की सुविधा के लिए एक कुशल डेटा-प्रोसेसिंग विश्लेषण सक्षम करते हैं, और किसी भी संगठन में गतिशील रूप से विभिन्न नवीन डेटा उत्पादों का निर्माण करते हैं।
पठनीय डेटा और जटिल एल्गोरिदम के बीच अंतर को जोड़ने के लिए वेक्टर एम्बेडिंग तकनीक आवश्यक हैं। डेटा प्रकार संख्यात्मक वेक्टर होने के कारण, हम उपलब्ध ओपन एआई मॉडल के साथ-साथ बड़ी संख्या में जेनरेटिव एआई अनुप्रयोगों की क्षमता को अनलॉक करने में सक्षम थे।
वेक्टर एंबेडिंग के साथ एकाधिक नौकरियां
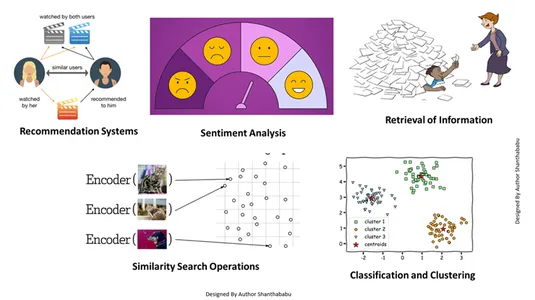
यह वेक्टर एम्बेडिंग हमें कई कार्य करने में मदद करती है:
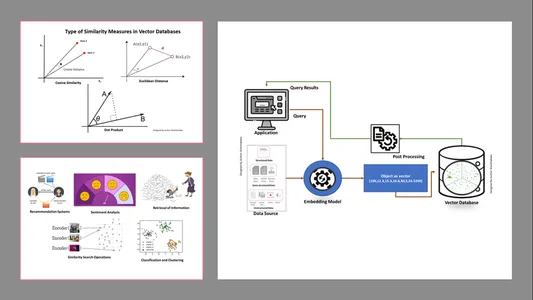
- सूचना की पुनर्प्राप्ति: इन शक्तिशाली तकनीकों की सहायता से, हम प्रभावशाली खोज इंजन बना सकते हैं जो संग्रहीत फ़ाइलों, दस्तावेज़ों या मीडिया से उपयोगकर्ता प्रश्नों के आधार पर प्रतिक्रियाएँ ढूंढने में हमारी सहायता कर सकते हैं।
- समानता खोज संचालन: यह सुव्यवस्थित और अनुक्रमित है; यह हमें वेक्टर डेटा में विभिन्न घटनाओं के बीच समानता खोजने में मदद करता है।
- वर्गीकरण और क्लस्टरिंग: इन एम्बेडिंग तकनीकों का उपयोग करके, हम प्रासंगिक मशीन लर्निंग एल्गोरिदम और समूह को प्रशिक्षित करने और उन्हें वर्गीकृत करने के लिए इन मॉडलों का प्रदर्शन कर सकते हैं।
- सिफ़ारिश प्रणाली: चूंकि एम्बेडिंग तकनीकों को ठीक से व्यवस्थित किया जाता है, यह ऐतिहासिक डेटा के आधार पर उत्पादों, मीडिया और लेखों से सटीक रूप से संबंधित अनुशंसा प्रणाली की ओर ले जाता है।
- भावनाओं का विश्लेषण: यह एम्बेडिंग मॉडल हमें भावना समाधानों को वर्गीकृत करने और प्राप्त करने में मदद करता है।
अनुक्रमण आवश्यकताएँ
जैसा कि हम जानते हैं, सूचकांक वेक्टर-डेटाबेस के समान पारंपरिक डेटाबेस में तालिका से खोज डेटा में सुधार करेगा, और अनुक्रमण सुविधाओं का प्रावधान करेगा।
वेक्टर डेटाबेस "फ्लैट इंडेक्स" प्रदान करते हैं, जो वेक्टर एम्बेडिंग का प्रत्यक्ष प्रतिनिधित्व हैं। खोज क्षमता व्यापक है, और यह पूर्व-प्रशिक्षित समूहों का उपयोग नहीं करती है। यह क्वेरी वेक्टर को प्रत्येक एकल वेक्टर एम्बेडिंग पर निष्पादित करता है, और प्रत्येक जोड़ी के लिए K दूरी की गणना की जाती है।
- इस सूचकांक की आसानी के कारण, नए सूचकांक बनाने के लिए न्यूनतम गणना की आवश्यकता होती है।
- दरअसल, एक फ्लैट इंडेक्स प्रश्नों को प्रभावी ढंग से संभाल सकता है और त्वरित पुनर्प्राप्ति समय प्रदान कर सकता है।
सिमेंटिक और समानता खोज को समझना
हम वेक्टर डेटाबेस में दो अलग-अलग खोजें करते हैं: सिमेंटिक और समानता खोज।
- अर्थपूर्ण खोज: जानकारी खोजते समय, कीवर्ड के आधार पर खोजने के बजाय, आप उन्हें सार्थक वार्तालाप पद्धति के आधार पर पा सकते हैं। प्रॉम्प्ट इंजीनियरिंग इनपुट को सिस्टम तक पहुंचाने में महत्वपूर्ण भूमिका निभाती है। यह खोज निस्संदेह उच्च-गुणवत्ता वाली खोज और परिणामों की अनुमति देती है जिन्हें नवीन अनुप्रयोगों, एसईओ, पाठ निर्माण और सारांश के लिए फीड किया जा सकता है।
- समानता खोज: हमेशा डेटा विश्लेषण में, समानता खोज असंरचित, बहुत बेहतर दिए गए डेटासेट की अनुमति देती है। वेक्टर डेटाबेस के संबंध में, हमें दो वैक्टरों की निकटता का पता लगाना चाहिए और वे एक-दूसरे से कैसे मिलते-जुलते हैं: टेबल, टेक्स्ट, दस्तावेज़, चित्र, शब्द और ऑडियो फ़ाइलें। समझने की प्रक्रिया में, वैक्टर के बीच समानता दिए गए डेटासेट में डेटा ऑब्जेक्ट के बीच समानता के रूप में प्रकट होती है। यह अभ्यास हमें बातचीत को समझने, पैटर्न की पहचान करने, अंतर्दृष्टि निकालने और अनुप्रयोग परिप्रेक्ष्य से निर्णय लेने में मदद करता है। सिमेंटिक और समानता खोज हमें उद्योग लाभ के लिए नीचे दिए गए एप्लिकेशन बनाने में मदद करेगी।
- सूचना की पुनर्प्राप्ति: ओपन एआई और वेक्टर डेटाबेस का उपयोग करते हुए, हम व्यावसायिक उपयोगकर्ताओं या अंतिम उपयोगकर्ताओं के प्रश्नों और वेक्टर डीबी के अंदर अनुक्रमित दस्तावेजों का उपयोग करके जानकारी पुनर्प्राप्ति के लिए खोज इंजन का निर्माण करेंगे।
- वर्गीकरण और क्लस्टरिंग:समान डेटा बिंदुओं या वस्तुओं के समूहों को वर्गीकृत या क्लस्टर करने में उन्हें साझा विशेषताओं के आधार पर कई श्रेणियों में निर्दिष्ट करना शामिल है।
- असंगति का पता लगाये: डेटा बिंदुओं की समानता को मापकर और अनियमितताओं का पता लगाकर सामान्य पैटर्न से असामान्यताओं की खोज करना।
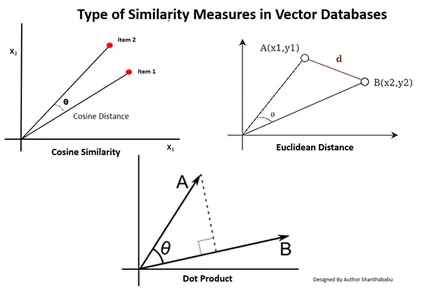
वेक्टर डेटाबेस में समानता उपायों के प्रकार
मापने के तरीके डेटा की प्रकृति और एप्लिकेशन विशिष्ट पर निर्भर करते हैं। आमतौर पर, मशीन लर्निंग के साथ समानता और परिचितता को मापने के लिए तीन तरीकों का उपयोग किया जाता है।
यूक्लिडियन दूरी
सरल शब्दों में, दो वेक्टरों के बीच की दूरी दो वेक्टर बिंदुओं के बीच की सीधी-रेखा की दूरी है जो सेंट को मापती है।
डॉट उत्पाद
इससे हमें दो वैक्टरों के बीच संरेखण को समझने में मदद मिलती है, जिससे पता चलता है कि क्या वे एक ही दिशा में, विपरीत दिशाओं में इंगित करते हैं, या एक दूसरे के लंबवत हैं।
कोसाइन समानता
यह दो वैक्टरों के बीच के कोण का उपयोग करके उनकी समानता का आकलन करता है, जैसा कि चित्र में दिखाया गया है। इस मामले में, वैक्टर के मूल्य और परिमाण महत्वहीन हैं और परिणामों को प्रभावित नहीं करते हैं; गणना में केवल कोण पर विचार किया जाता है।
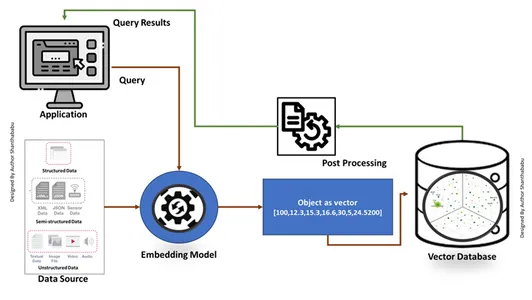
पारंपरिक डेटाबेस सटीक SQL कथन मिलान की खोज करते हैं और सारणीबद्ध प्रारूप में डेटा पुनर्प्राप्त करते हैं। साथ ही, हम प्रॉम्प्ट इंजीनियरिंग तकनीकों का उपयोग करके सादे अंग्रेजी में इनपुट क्वेरी के लिए सबसे समान वेक्टर की खोज करने वाले वेक्टर डेटाबेस से निपटते हैं। डेटाबेस समान डेटा खोजने के लिए अनुमानित निकटतम पड़ोसी (एएनएन) खोज एल्गोरिदम का उपयोग करता है। हमेशा उच्च प्रदर्शन, सटीकता और प्रतिक्रिया समय पर उचित सटीक परिणाम प्रदान करें।
कार्य तंत्र
- वेक्टर डेटाबेस पहले डेटा को एम्बेडिंग वैक्टर में परिवर्तित करते हैं, इसे वेक्टर डेटाबेस में संग्रहीत करते हैं, और त्वरित खोज के लिए इंडेक्सिंग बनाते हैं।
- एप्लिकेशन से एक क्वेरी एम्बेडिंग वेक्टर के साथ इंटरैक्ट करेगी, एक इंडेक्स का उपयोग करके वेक्टर डेटाबेस में निकटतम पड़ोसी या समान डेटा की खोज करेगी और एप्लिकेशन को दिए गए परिणामों को पुनः प्राप्त करेगी।
- व्यावसायिक आवश्यकताओं के आधार पर, पुनर्प्राप्त डेटा को ठीक किया जाएगा, स्वरूपित किया जाएगा, और अंतिम उपयोगकर्ता पक्ष या क्वेरी या एक्शन फ़ीड में प्रदर्शित किया जाएगा।
एक वेक्टर डेटाबेस बनाना
आइए पाइनकोन से जुड़ें।
आप Google, GitHub, या Microsoft ID का उपयोग करके पाइनकोन से जुड़ सकते हैं।
अपने उपयोग के लिए एक नया उपयोगकर्ता लॉगिन बनाएं।
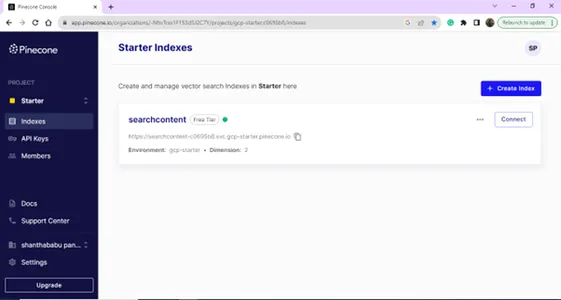
सफल लॉगिन के बाद, आप इंडेक्स पेज पर पहुंच जाएंगे; आप अपने वेक्टर डेटाबेस उद्देश्यों के लिए एक इंडेक्स बना सकते हैं। क्रिएट इंडेक्स बटन पर क्लिक करें।
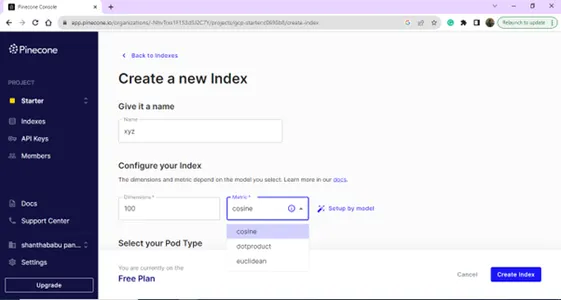
नाम और आयाम प्रदान करके अपना नया सूचकांक बनाएं।
सूचकांक सूची पृष्ठ,
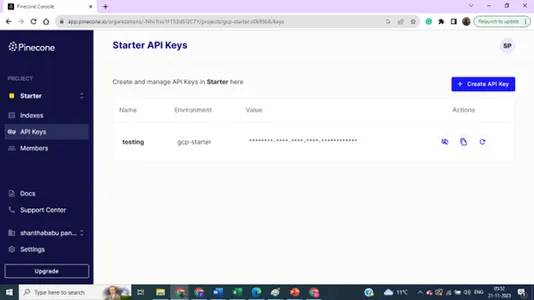
सूचकांक विवरण - नाम, क्षेत्र और पर्यावरण - हमें अपने वेक्टर डेटाबेस को मॉडल बिल्डिंग कोड से जोड़ने के लिए इन सभी विवरणों की आवश्यकता है।
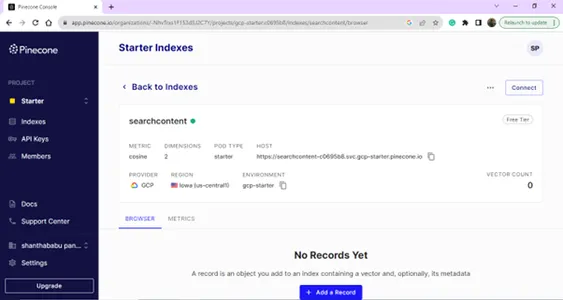
प्रोजेक्ट सेटिंग विवरण,
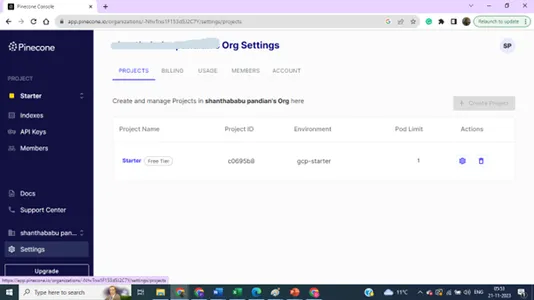
आप प्रोजेक्ट उद्देश्यों के लिए एकाधिक अनुक्रमणिका और कुंजियों के लिए अपनी प्राथमिकताओं को अपग्रेड कर सकते हैं।
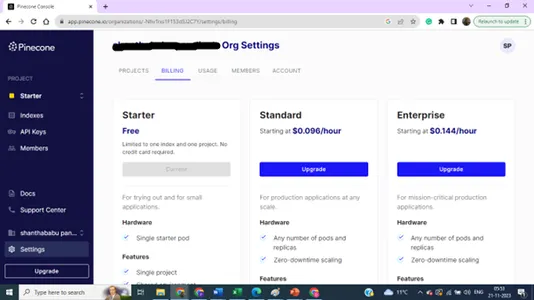
अब तक, हमने पाइनकोन में वेक्टर डेटाबेस इंडेक्स और सेटिंग्स बनाने पर चर्चा की है।
पायथन का उपयोग करके वेक्टर डेटाबेस कार्यान्वयन
चलिए अब कुछ कोडिंग करते हैं।
पुस्तकालयों का आयात करना
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIOpenAI और वेक्टर डेटाबेस के लिए API कुंजी प्रदान करना
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)एलएलएम की शुरुआत
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)पाइनकोन की शुरुआत
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" वेक्टर डेटाबेस बनाने के लिए .csv फ़ाइल लोड हो रही है
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()पाठ को टुकड़ों में विभाजित करें
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)text_chunk में टेक्स्ट ढूँढना
text_chunksउत्पादन
[दस्तावेज़ (पेज_कंटेंट='नाम: 100% ब्रैनएमएफआर: एनटाइप: सीएनकैलोरी: 70एनप्रोटीन: 4एनफैट: 1एनसोडियम: 130एनफाइबर: 10एनकार्बो: 5एनशुगर: 6एनपोटेशियम: 280एनविटामिन: 25एनशेल्फ़: 3एनवजन: 1एनकप: 0.33एनरेटिंग: 68.402973 100एनसिफारिश: बच्चों', मेटाडेटा={ 'स्रोत': '0% चोकर', 'पंक्ति': XNUMX}), , …..
बिल्डिंग एम्बेडिंग
embeddings = OpenAIEmbeddings()'डेटा' से वेक्टर डेटाबेस के लिए एक पाइनकोन उदाहरण बनाएं
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")वेक्टर डेटाबेस को क्वेरी करने के लिए एक रिट्रीवर बनाएं।
retriever = vectordb.as_retriever(score_threshold = 0.7)वेक्टर डेटाबेस से डेटा पुनर्प्राप्त करना
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsप्रॉम्प्ट का उपयोग करें और डेटा पुनः प्राप्त करें
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
चलिए डेटा के बारे में पूछते हैं।
chain('Can you please provide cereal recommendation for Kids?')क्वेरी से आउटपुट
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]निष्कर्ष
आशा है कि आप समझ सकते हैं कि वेक्टर डेटाबेस कैसे काम करते हैं, उनके घटक, आर्किटेक्चर और जेनरेटिव एआई समाधानों में वेक्टर डेटाबेस की विशेषताएं। समझें कि वेक्टर डेटाबेस पारंपरिक डेटाबेस से कैसे भिन्न है और पारंपरिक डेटाबेस तत्वों के साथ तुलना करें। दरअसल, सादृश्य आपको वेक्टर डेटाबेस को बेहतर ढंग से समझने में मदद करता है। पाइनकोन वेक्टर डेटाबेस और अनुक्रमण चरण आपको एक वेक्टर डेटाबेस बनाने और निम्नलिखित कोड कार्यान्वयन के लिए कुंजी लाने में मदद करेंगे।
चाबी छीन लेना
- संरचित, असंरचित और अर्ध-संरचित डेटा के साथ कॉम्पैक्टेबल।
- यह एम्बेडिंग तकनीकों और अत्यधिक अनुक्रमित सुविधाओं को अपनाता है।
- इंटरैक्शन एक प्रॉम्प्ट (उदाहरण के लिए, अंग्रेजी) का उपयोग करके सादे पाठ के माध्यम से होता है। और डेटा गणितीय अभ्यावेदन में संग्रहीत है।
- यूक्लिडियन दूरी, कोसाइन समानता और डॉट उत्पाद के माध्यम से वेक्टर डेटाबेस में समानता को कैलिब्रेट किया जाता है।
आम सवाल-जवाब
A. एक वेक्टर डेटाबेस अंतरिक्ष में डेटा का संग्रह संग्रहीत करता है। यह डेटा को गणितीय निरूपण में रखता है। चूंकि डेटाबेस में संग्रहीत प्रारूप ओपन एआई मॉडल के लिए पिछले इनपुट को याद रखना आसान बनाता है और हमारे ओपन एआई एप्लिकेशन को डिजिटल रूप से परिवर्तित उद्योगों में विभिन्न-उपयोग-मामलों के लिए संज्ञानात्मक खोज, सिफारिशों और सटीक पाठ पीढ़ी का उपयोग करने की अनुमति देता है।
A. कुछ विशेषताएं हैं: 1. यह इन वेक्टर एम्बेडिंग की शक्ति का लाभ उठाता है, जिससे बड़े पैमाने पर डेटासेट में अनुक्रमण और खोज होती है। 2. संरचित, असंरचित और अर्ध-संरचित डेटा के साथ कॉम्पैक्टेबल। 3. एक वेक्टर डेटाबेस सैकड़ों-आयाम वाले उच्च-आयामी वैक्टर के माध्यम से डेटा को व्यवस्थित करता है
ए. डेटाबेस ==> संग्रह
तालिका==> वेक्टर स्पेस
पंक्ति==>सेक्टर
कॉलम==>आयाम
पारंपरिक डेटाबेस की तरह, वेक्टर डेटाबेस में सम्मिलित करना और हटाना संभव है।
अपडेट और जॉइन दायरे में नहीं हैं।
- बड़े पैमाने पर डेटा संग्रह के लिए शीघ्रता से सूचना की पुनर्प्राप्ति।
- विशाल आकार के दस्तावेजों से अर्थ और समानता खोज संचालन।
- वर्गीकरण और क्लस्टरिंग अनुप्रयोग।
- सिफ़ारिश और भावना विश्लेषण प्रणाली।
A5: समानता मापने की तीन विधियाँ नीचे दी गई हैं:
- यूक्लिडियन दूरी
- कोसाइन समानता
- डॉट उत्पाद
इस लेख में दिखाया गया मीडिया एनालिटिक्स विद्या के स्वामित्व में नहीं है और इसका उपयोग लेखक के विवेक पर किया जाता है।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :हैस
- :है
- :नहीं
- $यूपी
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- योग्य
- About
- तक पहुँचने
- शुद्धता
- सही
- सही रूप में
- के पार
- अनुकूलन
- जोड़ना
- को प्रभावित
- AI
- एआई मॉडल
- कलन विधि
- एल्गोरिदम
- संरेखण
- सब
- संधि
- अनुमति देना
- की अनुमति देता है
- साथ में
- हमेशा
- के बीच में
- an
- विश्लेषण
- विश्लेषिकी
- एनालिटिक्स विधा
- और
- जवाब
- कोई
- एपीआई
- स्पष्ट
- आवेदन
- आवेदन विशिष्ट
- अनुप्रयोगों
- अनुमानित
- स्थापत्य
- हैं
- व्यवस्था की
- ऐरे
- लेख
- लेख
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- आर्टिफिशियल इंटेलिजेंस एंड मशीन लर्निंग
- AS
- पहलुओं
- निर्धारितियों
- संघों
- At
- ऑडियो
- स्वतः
- उपलब्ध
- आधारित
- BE
- बन
- हो जाता है
- व्यवहार
- पीछे
- जा रहा है
- नीचे
- लाभ
- बेहतर
- के बीच
- ब्लॉगथॉन
- लाना
- निर्माण
- इमारत
- व्यापार
- बटन
- by
- परिकलित
- हिसाब
- बुलाया
- कर सकते हैं
- क्षमताओं
- क्षमता
- कब्जा
- मामला
- मामलों
- श्रेणियाँ
- श्रृंखला
- चेन
- विशेषताएँ
- स्पष्टता
- वर्गीकरण
- वर्गीकृत
- क्लिक करें
- गुच्छन
- कोड
- कोडन
- संज्ञानात्मक
- संग्रह
- सामान्यतः
- सघन
- तुलना
- तुलना
- पूरा
- जटिल
- घटकों
- व्यापक
- गणना
- कम्प्यूटेशनल
- जुडिये
- कनेक्ट कर रहा है
- विचार करना
- माना
- शामिल
- सामग्री
- प्रसंग
- परम्परागत
- कन्वर्सेशन (Conversation)
- बदलना
- मेल खाती है
- सका
- बनाना
- बनाना
- रचनात्मकता
- ग्राहक
- तिथि
- डेटा विश्लेषण
- डेटा अंक
- डेटा संसाधन
- डाटाबेस
- डेटाबेस
- डेटासेट
- सौदा
- निर्णय
- निर्णय
- मांग
- निकाले जाते हैं
- डिज़ाइन बनाना
- वांछित
- विवरण
- खोज
- विकसित
- अलग
- अंतर
- विभिन्न
- डिजिटली
- आयाम
- आयाम
- प्रत्यक्ष
- दिशा
- दिशाओं
- खोज
- विवेक
- चर्चा करना
- चर्चा की
- दिखाया गया है
- दूरी
- do
- दस्तावेजों
- कर देता है
- डॉन
- DOT
- गतिशील
- गतिशील
- e
- से प्रत्येक
- आराम
- आसान
- प्रभावी रूप से
- दक्षता
- कुशल
- भी
- तत्व
- embedding
- सक्षम
- समाप्त
- अभियांत्रिकी
- इंजीनियर्स
- इंजन
- अंग्रेज़ी
- सुनिश्चित
- वातावरण
- सार
- आवश्यक
- ईथर (ईटीएच)
- और भी
- उद्विकासी
- निष्पादित
- व्यायाम
- तलाश
- उद्धरण
- की सुविधा
- सुपरिचय
- दूर
- Feature
- विशेषताएं
- फेड
- आकृति
- पट्टिका
- फ़ाइलें
- खोज
- प्रथम
- फ्लैट
- निम्नलिखित
- के लिए
- सबसे आगे
- प्रपत्र
- प्रारूप
- मुक्त
- से
- भविष्य
- अन्तर
- उत्पन्न
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- शैली
- GitHub
- देना
- दी
- गूगल
- समूह
- समूह की
- संभालना
- होना
- है
- मदद
- मदद करता है
- यहाँ उत्पन्न करें
- हाई
- उच्च स्तर
- अत्यधिक
- ऐतिहासिक
- कैसे
- तथापि
- HTTPS
- विशाल
- सैकड़ों
- i
- ID
- पहचान करना
- if
- छवियों
- प्रभाव
- कार्यान्वयन
- आयात
- में सुधार
- in
- तेजी
- अनुक्रमणिका
- अनुक्रमित
- अनुक्रमणिका
- यह दर्शाता है
- Indices
- उद्योगों
- उद्योग
- प्रभावशाली
- करें-
- निहित
- अभिनव
- निवेश
- निविष्टियां
- आवेषण
- अंदर
- अंतर्दृष्टि
- उदाहरण
- बजाय
- बुद्धि
- बातचीत
- बातचीत
- बातचीत
- में
- पेचीदगियों
- शामिल
- IT
- आईटी इस
- नौकरियां
- में शामिल होने
- हमसे जुड़ें
- यात्रा
- केवल
- कुंजी
- Instagram पर
- खोजशब्दों
- बच्चे
- जानना
- लेबल
- भूमि
- परिदृश्य
- बड़ा
- प्रमुख
- बिक्रीसूत्र
- सीख रहा हूँ
- लीवरेज
- leverages
- पसंद
- सूची
- लोडर
- तर्क
- लॉग इन
- मशीन
- यंत्र अधिगम
- प्रमुख
- बनाना
- बनाता है
- निर्माण
- प्रबंध
- ढंग
- मैन्युअल
- उत्पादक
- नक्शा
- विशाल
- मैच
- गणितीय
- सार्थक
- माप
- उपायों
- मापने
- तंत्र
- मीडिया
- मर्ज
- क्रियाविधि
- तरीकों
- माइक्रोसॉफ्ट
- कम से कम
- आदर्श
- मॉडल
- अधिक
- और भी
- अधिकांश
- बहुत
- विभिन्न
- चाहिए
- नाम
- प्रकृति
- आवश्यकता
- नया
- अभी
- अनेक
- वस्तु
- वस्तुओं
- of
- प्रस्ताव
- on
- ONE
- लोगों
- ऑनलाइन
- केवल
- खुला
- OpenAI
- संचालन
- विपरीत
- or
- संगठन
- संगठित
- का आयोजन
- मूल
- OS
- अन्य
- हमारी
- स्वामित्व
- पृष्ठ
- जोड़ा
- भाग
- पारित कर दिया
- पासिंग
- पैटर्न उपयोग करें
- उत्तम
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- प्रदर्शन
- परिप्रेक्ष्य
- दृष्टिकोण
- चित्र
- केंद्रीय
- मैदान
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- निभाता
- कृप्या अ
- बिन्दु
- अंक
- संभव
- संभावित
- बिजली
- शक्तिशाली
- व्यावहारिक
- व्यावहारिक अनुप्रयोगों
- ठीक
- ठीक - ठीक
- वरीयताओं
- पिछला
- मुसीबत
- प्रक्रिया
- एस्ट्रो मॉल
- उत्पाद
- परियोजना
- प्रसिद्ध
- संकेतों
- अच्छी तरह
- गुण
- संपत्ति
- प्रदान करना
- प्रदान कर
- प्रावधान
- प्रकाशित
- कश
- उद्देश्य
- प्रयोजनों
- मात्रा
- प्रश्नों
- प्रश्न
- त्वरित
- तेज
- जल्दी से
- तेजी
- सिफारिश
- सिफारिशें
- के बारे में
- क्षेत्र
- संबंधों
- रिश्ते
- प्रासंगिक
- प्रतिनिधित्व
- प्रतिनिधित्व
- का प्रतिनिधित्व करता है
- अपेक्षित
- आवश्यकताएँ
- प्रतिक्रिया
- प्रतिक्रियाएं
- परिणाम
- परिणाम
- प्रकट
- भूमिका
- आरओडब्ल्यू
- s
- वही
- विज्ञान
- क्षेत्र
- Search
- खोज इंजन
- खोजें
- खोज
- भावुकता
- एसईओ
- सेटिंग्स
- आकार
- आकार देने
- साझा
- शेल्फ
- कम
- दिखाया
- दिखाता है
- पक्ष
- समान
- समानता
- सरल
- के बाद से
- एक
- आकार
- So
- समाधान
- समाधान ढूंढे
- कुछ
- स्रोत
- अंतरिक्ष
- विशिष्ट
- गति
- विभाजित
- खोलना
- एसक्यूएल
- राज्य
- कथन
- बयान
- कदम
- फिर भी
- भंडारण
- की दुकान
- संग्रहित
- भंडार
- संरचना
- संरचित
- अध्ययन
- इसके बाद
- सफल
- तालमेल
- प्रणाली
- सिस्टम
- T
- तालिका
- टैग
- कार्य
- तकनीक
- प्रौद्योगिकीय
- शर्तों
- टेक्स्ट
- पाठ पीढ़ी
- से
- कि
- RSI
- भविष्य
- लेकिन हाल ही
- उन
- इन
- वे
- इसका
- तीन
- यहाँ
- पहर
- बार
- सेवा मेरे
- परंपरागत
- रेलगाड़ी
- बदालना
- परिवर्तन
- परिवर्तनकारी
- तब्दील
- कोशिश
- दो
- प्रकार
- अंत में
- समझना
- समझ
- निश्चित रूप से
- अनलॉक
- अनलॉकिंग
- अपडेट
- उन्नयन
- us
- प्रयोग
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- का उपयोग करता है
- का उपयोग
- सामान्य
- मान
- विविधता
- विभिन्न
- बहुत
- महत्वपूर्ण
- vs
- था
- we
- webp
- अच्छी तरह से परिभाषित
- थे
- क्या
- एचएमबी क्या है?
- या
- कौन कौन से
- जब
- मर्जी
- साथ में
- अंदर
- शब्द
- काम
- काम कर रहे
- होगा
- इसलिए आप
- आपका
- जेफिरनेट