आज, हम लामा 2 अनुमान और फाइन-ट्यूनिंग समर्थन की उपलब्धता की घोषणा करते हुए उत्साहित हैं एडब्ल्यूएस ट्रेनियम और एडब्ल्यूएस इन्फेंटेंटिया में उदाहरण हैं अमेज़न SageMaker जम्पस्टार्ट. सेजमेकर के माध्यम से एडब्ल्यूएस ट्रेनियम और इनफेरेंटिया आधारित उदाहरणों का उपयोग करने से उपयोगकर्ताओं को प्रति टोकन विलंबता कम करते हुए फाइन-ट्यूनिंग लागत को 50% तक कम करने और तैनाती लागत को 4.7x तक कम करने में मदद मिल सकती है। लामा 2 एक ऑटो-रिग्रेसिव जेनरेटिव टेक्स्ट लैंग्वेज मॉडल है जो एक अनुकूलित ट्रांसफार्मर आर्किटेक्चर का उपयोग करता है। सार्वजनिक रूप से उपलब्ध मॉडल के रूप में, लामा 2 को कई एनएलपी कार्यों जैसे पाठ वर्गीकरण, भावना विश्लेषण, भाषा अनुवाद, भाषा मॉडलिंग, पाठ निर्माण और संवाद प्रणाली के लिए डिज़ाइन किया गया है। अच्छा ग्राहक अनुभव प्रदान करने के लिए वास्तविक समय के प्रदर्शन को पूरा करने के लिए लामा 2 जैसे एलएलएम को फाइन-ट्यूनिंग और तैनात करना महंगा या चुनौतीपूर्ण हो सकता है। ट्रेनियम और एडब्ल्यूएस इनफेरेंटिया, द्वारा सक्षम AWS न्यूरॉन सॉफ्टवेयर डेवलपमेंट किट (एसडीके), लामा 2 मॉडल के प्रशिक्षण और अनुमान के लिए उच्च प्रदर्शन और लागत प्रभावी विकल्प प्रदान करता है।
इस पोस्ट में, हम प्रदर्शित करते हैं कि सेजमेकर जम्पस्टार्ट में ट्रेनियम और एडब्ल्यूएस इन्फेरेंटिया उदाहरणों पर लामा 2 को कैसे तैनात और फाइन-ट्यून किया जाए।
समाधान अवलोकन
इस ब्लॉग में, हम निम्नलिखित परिदृश्यों पर चलेंगे:
- दोनों में एडब्ल्यूएस इनफेरेंटिया उदाहरणों पर लामा 2 तैनात करें अमेज़ॅन सैजमेकर स्टूडियो यूआई, एक-क्लिक परिनियोजन अनुभव और सेजमेकर पायथन एसडीके के साथ।
- सेजमेकर स्टूडियो यूआई और सेजमेकर पायथन एसडीके दोनों में ट्रेनियम उदाहरणों पर लामा 2 को फाइन-ट्यून करें।
- फाइन-ट्यूनिंग की प्रभावशीलता दिखाने के लिए फाइन-ट्यून किए गए लामा 2 मॉडल के प्रदर्शन की तुलना पूर्व-प्रशिक्षित मॉडल से करें।
हाथ पाने के लिए, देखें GitHub उदाहरण नोटबुक.
सेजमेकर स्टूडियो यूआई और पायथन एसडीके का उपयोग करके एडब्ल्यूएस इनफेरेंटिया उदाहरणों पर लामा 2 को तैनात करें
इस अनुभाग में, हम प्रदर्शित करते हैं कि एक-क्लिक परिनियोजन और पायथन एसडीके के लिए सेजमेकर स्टूडियो यूआई का उपयोग करके एडब्ल्यूएस इनफेरेंटिया उदाहरणों पर लामा 2 को कैसे तैनात किया जाए।
सेजमेकर स्टूडियो यूआई पर लामा 2 मॉडल की खोज करें
सेजमेकर जम्पस्टार्ट सार्वजनिक रूप से उपलब्ध और मालिकाना दोनों तक पहुंच प्रदान करता है नींव मॉडल. फाउंडेशन मॉडल को तीसरे पक्ष और मालिकाना प्रदाताओं से ऑनबोर्ड और रखरखाव किया जाता है। इस प्रकार, उन्हें मॉडल स्रोत द्वारा निर्दिष्ट विभिन्न लाइसेंसों के तहत जारी किया जाता है। आपके द्वारा उपयोग किए जाने वाले किसी भी फाउंडेशन मॉडल के लाइसेंस की समीक्षा अवश्य करें। आप किसी भी लागू लाइसेंस शर्तों की समीक्षा करने और उनका अनुपालन करने के लिए जिम्मेदार हैं और यह सुनिश्चित करते हैं कि सामग्री को डाउनलोड करने या उपयोग करने से पहले वे आपके उपयोग के मामले में स्वीकार्य हैं।
आप सेजमेकर स्टूडियो यूआई और सेजमेकर पायथन एसडीके में सेजमेकर जम्पस्टार्ट के माध्यम से लामा 2 फाउंडेशन मॉडल तक पहुंच सकते हैं। इस अनुभाग में, हम सेजमेकर स्टूडियो में मॉडलों की खोज कैसे करें, इसके बारे में जानेंगे।
सेजमेकर स्टूडियो एक एकीकृत विकास वातावरण (आईडीई) है जो एक एकल वेब-आधारित विज़ुअल इंटरफ़ेस प्रदान करता है जहां आप डेटा तैयार करने से लेकर निर्माण, प्रशिक्षण और अपने एमएल को तैनात करने तक सभी मशीन लर्निंग (एमएल) विकास चरणों को करने के लिए उद्देश्य-निर्मित टूल तक पहुंच सकते हैं। मॉडल। सेजमेकर स्टूडियो कैसे शुरू करें और स्थापित करें, इसके बारे में अधिक जानकारी के लिए देखें अमेज़ॅन सेजमेकर स्टूडियो।
सेजमेकर स्टूडियो में होने के बाद, आप सेजमेकर जम्पस्टार्ट तक पहुंच सकते हैं, जिसमें पूर्व-प्रशिक्षित मॉडल, नोटबुक और पूर्वनिर्मित समाधान शामिल हैं। पूर्वनिर्मित और स्वचालित समाधान. मालिकाना मॉडल तक पहुंचने के तरीके के बारे में अधिक विस्तृत जानकारी के लिए, देखें अमेज़ॅन सेजमेकर स्टूडियो में अमेज़ॅन सेजमेकर जंपस्टार्ट के मालिकाना फाउंडेशन मॉडल का उपयोग करें.
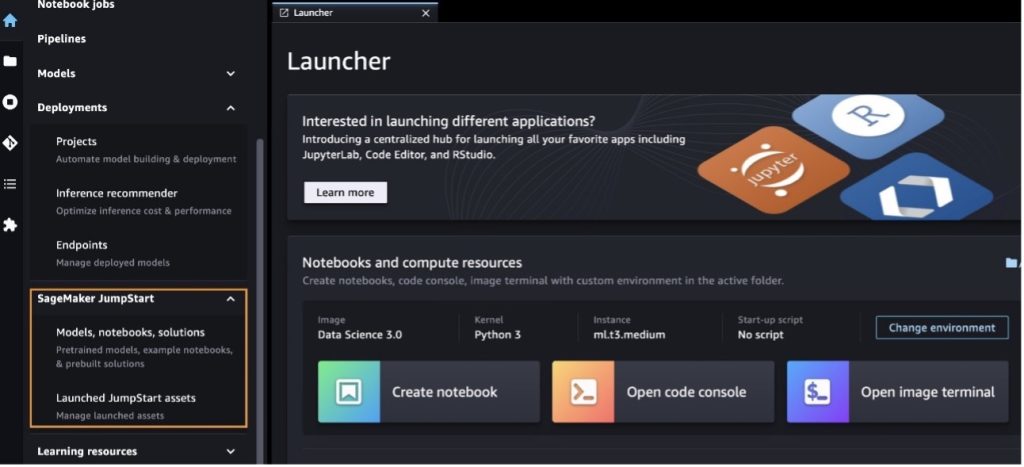
सेजमेकर जम्पस्टार्ट लैंडिंग पृष्ठ से, आप समाधान, मॉडल, नोटबुक और अन्य संसाधन ब्राउज़ कर सकते हैं।
यदि आपको लामा 2 मॉडल दिखाई नहीं देते हैं, तो बंद करके और पुनः आरंभ करके अपने सेजमेकर स्टूडियो संस्करण को अपडेट करें। संस्करण अपडेट के बारे में अधिक जानकारी के लिए देखें स्टूडियो क्लासिक ऐप्स बंद करें और अपडेट करें.

आप चुनकर अन्य मॉडल वेरिएंट भी पा सकते हैं सभी टेक्स्ट जेनरेशन मॉडल का अन्वेषण करें या खोज रहे हैं llama or neuron खोज बॉक्स में. आप इस पेज पर लामा 2 न्यूरॉन मॉडल देख पाएंगे।
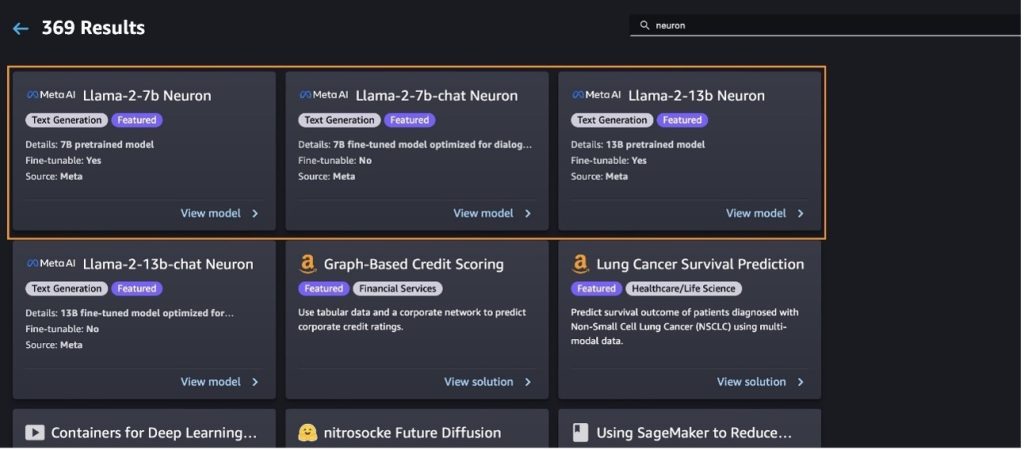
सेजमेकर जम्पस्टार्ट के साथ लामा-2-13बी मॉडल को तैनात करें
आप मॉडल के बारे में विवरण देखने के लिए मॉडल कार्ड चुन सकते हैं जैसे लाइसेंस, प्रशिक्षण के लिए उपयोग किया गया डेटा और इसका उपयोग कैसे करें। आप दो बटन भी पा सकते हैं, तैनाती और नोटबुक खोलें, जो आपको इस नो-कोड उदाहरण का उपयोग करके मॉडल का उपयोग करने में मदद करता है।
जब आप कोई भी बटन चुनते हैं, तो एक पॉप-अप आपको स्वीकार करने के लिए अंतिम उपयोगकर्ता लाइसेंस अनुबंध और स्वीकार्य उपयोग नीति (एयूपी) दिखाएगा।
नीतियों को स्वीकार करने के बाद, आप मॉडल के समापन बिंदु को तैनात कर सकते हैं और अगले अनुभाग में दिए गए चरणों के माध्यम से इसका उपयोग कर सकते हैं।
पायथन एसडीके के माध्यम से लामा 2 न्यूरॉन मॉडल को तैनात करें
जब आप चुनते हैं तैनाती और शर्तें स्वीकार करें, मॉडल परिनियोजन शुरू हो जाएगा। वैकल्पिक रूप से, आप उदाहरण नोटबुक के माध्यम से चयन करके तैनात कर सकते हैं नोटबुक खोलें. उदाहरण नोटबुक अनुमान लगाने और संसाधनों को साफ करने के लिए मॉडल को कैसे तैनात किया जाए, इस पर शुरू से अंत तक मार्गदर्शन प्रदान करता है।
ट्रेनियम या AWS इन्फेरेंटिया इंस्टेंसेस पर किसी मॉडल को तैनात या फाइन-ट्यून करने के लिए, आपको सबसे पहले PyTorch न्यूरॉन को कॉल करना होगा (टॉर्च-न्यूरॉनक्स) मॉडल को न्यूरॉन-विशिष्ट ग्राफ़ में संकलित करने के लिए, जो इसे इनफेरेंटिया के न्यूरॉनकोर्स के लिए अनुकूलित करेगा। उपयोगकर्ता एप्लिकेशन के उद्देश्यों के आधार पर कंपाइलर को न्यूनतम विलंबता या उच्चतम थ्रूपुट के लिए अनुकूलन करने का निर्देश दे सकते हैं। जंपस्टार्ट में, हमने विभिन्न प्रकार के कॉन्फ़िगरेशन के लिए न्यूरॉन ग्राफ़ को पूर्व-संकलित किया, ताकि उपयोगकर्ताओं को संकलन चरणों को सिप करने की अनुमति मिल सके, जिससे तेजी से फाइन-ट्यूनिंग और मॉडलों को तैनात किया जा सके।
ध्यान दें कि न्यूरॉन पूर्व-संकलित ग्राफ़ न्यूरॉन कंपाइलर संस्करण के एक विशिष्ट संस्करण के आधार पर बनाया गया है।
AWS इन्फेरेंटिया-आधारित उदाहरणों पर LIama 2 को तैनात करने के दो तरीके हैं। पहली विधि पूर्व-निर्मित कॉन्फ़िगरेशन का उपयोग करती है, और आपको कोड की केवल दो पंक्तियों में मॉडल को तैनात करने की अनुमति देती है। दूसरे में, कॉन्फ़िगरेशन पर आपका अधिक नियंत्रण होता है। आइए पहली विधि से शुरू करें, पूर्व-निर्मित कॉन्फ़िगरेशन के साथ, और एक उदाहरण के रूप में पूर्व-प्रशिक्षित लामा 2 13बी न्यूरॉन मॉडल का उपयोग करें। निम्नलिखित कोड दिखाता है कि केवल दो पंक्तियों के साथ लामा 13बी को कैसे तैनात किया जाए:
इन मॉडलों पर अनुमान लगाने के लिए, आपको तर्क निर्दिष्ट करने की आवश्यकता है accept_eula करने के लिए हो सकता है True के हिस्से के रूप में model.deploy() पुकारना। इस तर्क को सत्य मानते हुए, स्वीकार करें कि आपने मॉडल के EULA को पढ़ लिया है और स्वीकार कर लिया है। EULA मॉडल कार्ड विवरण में या से पाया जा सकता है मेटा वेबसाइट.
Llama 2 13B के लिए डिफ़ॉल्ट इंस्टेंस प्रकार ml.inf2.8xlarge है। आप अन्य समर्थित मॉडल आईडी भी आज़मा सकते हैं:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(चैट मॉडल)meta-textgenerationneuron-llama-2-13b-f(चैट मॉडल)
वैकल्पिक रूप से, यदि आप परिनियोजन कॉन्फ़िगरेशन पर अधिक नियंत्रण चाहते हैं, जैसे कि संदर्भ लंबाई, टेंसर समानांतर डिग्री और अधिकतम रोलिंग बैच आकार, तो आप उन्हें पर्यावरण चर के माध्यम से संशोधित कर सकते हैं, जैसा कि इस अनुभाग में दिखाया गया है। परिनियोजन का अंतर्निहित डीप लर्निंग कंटेनर (डीएलसी) है बड़े मॉडल अनुमान (एलएमआई) न्यूरॉनएक्स डीएलसी. पर्यावरण चर इस प्रकार हैं:
- OPTION_N_POSITIONS - इनपुट और आउटपुट टोकन की अधिकतम संख्या। उदाहरण के लिए, यदि आप मॉडल को संकलित करते हैं
OPTION_N_POSITIONS512 के रूप में, तो आप 128 के अधिकतम आउटपुट टोकन के साथ 384 (इनपुट प्रॉम्प्ट आकार) के इनपुट टोकन का उपयोग कर सकते हैं (इनपुट और आउटपुट टोकन का कुल योग 512 होना चाहिए)। अधिकतम आउटपुट टोकन के लिए, 384 से नीचे का कोई भी मान ठीक है, लेकिन आप इससे आगे नहीं जा सकते (उदाहरण के लिए, इनपुट 256 और आउटपुट 512)। - OPTION_TENSOR_PARALLEL_DEGREE - AWS इन्फेरेंटिया उदाहरणों में मॉडल को लोड करने के लिए न्यूरॉनकोर्स की संख्या।
- OPTION_MAX_ROLLING_BATCH_SIZE - समवर्ती अनुरोधों के लिए अधिकतम बैच आकार।
- OPTION_DTYPE - मॉडल लोड करने की तिथि प्रकार।
न्यूरॉन ग्राफ का संकलन संदर्भ लंबाई पर निर्भर करता है (OPTION_N_POSITIONS), टेंसर समानांतर डिग्री (OPTION_TENSOR_PARALLEL_DEGREE), अधिकतम बैच आकार (OPTION_MAX_ROLLING_BATCH_SIZE), और डेटा प्रकार (OPTION_DTYPE) मॉडल लोड करने के लिए। सेजमेकर जंपस्टार्ट ने रनटाइम संकलन से बचने के लिए पूर्ववर्ती मापदंडों के लिए विभिन्न प्रकार के कॉन्फ़िगरेशन के लिए न्यूरॉन ग्राफ़ को पूर्व-संकलित किया है। पूर्व-संकलित ग्राफ़ के कॉन्फ़िगरेशन निम्न तालिका में सूचीबद्ध हैं। जब तक पर्यावरण चर निम्नलिखित श्रेणियों में से एक में आते हैं, न्यूरॉन ग्राफ़ का संकलन छोड़ दिया जाएगा।
| LIama-2 7B और LIama-2 7B चैट | ||||
| उदाहरण प्रकार | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B और LIama-2 13B चैट | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
निम्नलिखित लामा 2 13बी को तैनात करने और सभी उपलब्ध कॉन्फ़िगरेशन को सेट करने का एक उदाहरण है।
अब जब हमने लामा-2-13बी मॉडल तैनात कर दिया है, तो हम समापन बिंदु को लागू करके इसके साथ अनुमान चला सकते हैं। निम्नलिखित कोड स्निपेट पाठ निर्माण को नियंत्रित करने के लिए समर्थित अनुमान पैरामीटर का उपयोग दर्शाता है:
- अधिकतम लंबाई - मॉडल आउटपुट लंबाई (जिसमें इनपुट संदर्भ लंबाई शामिल है) तक पहुंचने तक टेक्स्ट उत्पन्न करता है
max_length. यदि निर्दिष्ट किया गया है, तो यह एक धनात्मक पूर्णांक होना चाहिए। - max_new_tokens - मॉडल आउटपुट लंबाई (इनपुट संदर्भ लंबाई को छोड़कर) तक पहुंचने तक टेक्स्ट उत्पन्न करता है
max_new_tokens. यदि निर्दिष्ट किया गया है, तो यह एक धनात्मक पूर्णांक होना चाहिए। - num_beams - यह लालची खोज में प्रयुक्त बीमों की संख्या को इंगित करता है। यदि निर्दिष्ट किया गया है, तो यह इससे बड़ा या इसके बराबर पूर्णांक होना चाहिए
num_return_sequences. - no_repeat_ngram_size - मॉडल यह सुनिश्चित करता है कि शब्दों का एक क्रम
no_repeat_ngram_sizeआउटपुट अनुक्रम में दोहराया नहीं जाता है। यदि निर्दिष्ट किया गया है, तो यह 1 से अधिक धनात्मक पूर्णांक होना चाहिए। - तापमान - यह आउटपुट में यादृच्छिकता को नियंत्रित करता है। उच्च तापमान के परिणामस्वरूप कम-संभावना वाले शब्दों वाला आउटपुट अनुक्रम उत्पन्न होता है; कम तापमान के परिणामस्वरूप उच्च-संभावना वाले शब्दों के साथ आउटपुट अनुक्रम उत्पन्न होता है। अगर
temperature0 के बराबर है, इसका परिणाम लालची डिकोडिंग में होता है। यदि निर्दिष्ट किया गया है, तो यह एक सकारात्मक फ्लोट होना चाहिए। - जल्दी रुकना - अगर
True, जब सभी बीम परिकल्पनाएं वाक्य टोकन के अंत तक पहुंच जाती हैं, तो पाठ निर्माण समाप्त हो जाता है। यदि निर्दिष्ट किया गया है, तो यह बूलियन होना चाहिए। - do_sample - अगर
True, मॉडल संभावना के अनुसार अगले शब्द का नमूना लेता है। यदि निर्दिष्ट किया गया है, तो यह बूलियन होना चाहिए। - शीर्ष_के - पाठ निर्माण के प्रत्येक चरण में, मॉडल केवल से नमूने लेता है
top_kसबसे अधिक संभावना शब्द। यदि निर्दिष्ट किया गया है, तो यह एक धनात्मक पूर्णांक होना चाहिए। - शीर्ष_पी - पाठ निर्माण के प्रत्येक चरण में, मॉडल संचयी संभावना वाले शब्दों के सबसे छोटे संभावित सेट से नमूने लेता है
top_p. यदि निर्दिष्ट किया गया है, तो यह 0-1 के बीच एक फ्लोट होना चाहिए। - रुकें - यदि निर्दिष्ट किया गया है, तो यह स्ट्रिंग्स की एक सूची होनी चाहिए। यदि निर्दिष्ट स्ट्रिंग में से कोई एक उत्पन्न होता है तो टेक्स्ट जनरेशन बंद हो जाता है।
निम्नलिखित कोड एक उदाहरण दिखाता है:
उत्पादन:
पेलोड में पैरामीटर्स के बारे में अधिक जानकारी के लिए देखें विस्तृत पैरामीटर.
आप इसमें मापदंडों के कार्यान्वयन का भी पता लगा सकते हैं नोटबुक नोटबुक के लिंक के बारे में अधिक जानकारी जोड़ने के लिए।
सेजमेकर स्टूडियो यूआई और सेजमेकर पायथन एसडीके का उपयोग करके ट्रेनियम इंस्टेंसेस पर लामा 2 मॉडल को फाइन-ट्यून करें
जेनरेटिव एआई फाउंडेशन मॉडल एमएल और एआई में प्राथमिक फोकस बन गए हैं, हालांकि, उनका व्यापक सामान्यीकरण स्वास्थ्य देखभाल या वित्तीय सेवाओं जैसे विशिष्ट डोमेन में कम हो सकता है, जहां अद्वितीय डेटासेट शामिल हैं। यह सीमा इन विशिष्ट क्षेत्रों में अपने प्रदर्शन को बढ़ाने के लिए डोमेन-विशिष्ट डेटा के साथ इन जेनरेटिव एआई मॉडल को ठीक करने की आवश्यकता पर प्रकाश डालती है।
अब जब हमने लामा 2 मॉडल का पूर्व-प्रशिक्षित संस्करण तैनात कर दिया है, तो आइए देखें कि हम सटीकता बढ़ाने के लिए इसे डोमेन-विशिष्ट डेटा में कैसे ठीक कर सकते हैं, त्वरित पूर्णता के संदर्भ में मॉडल में सुधार कर सकते हैं और मॉडल को अनुकूलित कर सकते हैं आपका विशिष्ट व्यावसायिक उपयोग मामला और डेटा। आप सेजमेकर स्टूडियो यूआई या सेजमेकर पायथन एसडीके का उपयोग करके मॉडल को फाइन-ट्यून कर सकते हैं। हम इस अनुभाग में दोनों विधियों पर चर्चा करते हैं।
सेजमेकर स्टूडियो के साथ लामा-2-13बी न्यूरॉन मॉडल को फाइन-ट्यून करें
सेजमेकर स्टूडियो में, लामा-2-13बी न्यूरॉन मॉडल पर जाएँ। पर तैनाती टैब, आप इंगित कर सकते हैं अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) बकेट जिसमें फ़ाइन-ट्यूनिंग के लिए प्रशिक्षण और सत्यापन डेटासेट शामिल हैं। इसके अलावा, आप फ़ाइन-ट्यूनिंग के लिए परिनियोजन कॉन्फ़िगरेशन, हाइपरपैरामीटर और सुरक्षा सेटिंग्स कॉन्फ़िगर कर सकते हैं। उसके बाद चुनो रेलगाड़ी सेजमेकर एमएल इंस्टेंस पर प्रशिक्षण कार्य शुरू करने के लिए।

लामा 2 मॉडल का उपयोग करने के लिए, आपको EULA और AUP को स्वीकार करना होगा। जब आप चुनेंगे तो यह दिखाई देगा रेलगाड़ी। चुनना मैंने EULA और AUP को पढ़ लिया है और स्वीकार कर लिया है फाइन-ट्यूनिंग कार्य शुरू करने के लिए।
आप सेजमेकर कंसोल पर चुनकर फाइन-ट्यून्ड मॉडल के लिए अपने प्रशिक्षण कार्य की स्थिति देख सकते हैं प्रशिक्षण कार्य नेविगेशन फलक में
आप या तो इस नो-कोड उदाहरण का उपयोग करके अपने लामा 2 न्यूरॉन मॉडल को फाइन-ट्यून कर सकते हैं, या पायथन एसडीके के माध्यम से फाइन-ट्यून कर सकते हैं, जैसा कि अगले भाग में दिखाया गया है।
सेजमेकर पायथन एसडीके के माध्यम से लामा-2-13बी न्यूरॉन मॉडल को फाइन-ट्यून करें
आप डोमेन अनुकूलन प्रारूप या के साथ डेटासेट को ठीक कर सकते हैं निर्देश-आधारित फ़ाइन-ट्यूनिंग प्रारूप। फ़ाइन-ट्यूनिंग में भेजे जाने से पहले प्रशिक्षण डेटा को कैसे स्वरूपित किया जाना चाहिए, इसके निर्देश निम्नलिखित हैं:
- निवेश - एक
trainनिर्देशिका जिसमें या तो JSON लाइनें (.jsonl) या टेक्स्ट (.txt) स्वरूपित फ़ाइल है।- JSON लाइन्स (.jsonl) फ़ाइल के लिए, प्रत्येक लाइन एक अलग JSON ऑब्जेक्ट है। प्रत्येक JSON ऑब्जेक्ट को कुंजी-मूल्य जोड़ी के रूप में संरचित किया जाना चाहिए, जहां कुंजी होनी चाहिए
text, और मूल्य एक प्रशिक्षण उदाहरण की सामग्री है। - ट्रेन निर्देशिका के अंतर्गत फ़ाइलों की संख्या 1 के बराबर होनी चाहिए।
- JSON लाइन्स (.jsonl) फ़ाइल के लिए, प्रत्येक लाइन एक अलग JSON ऑब्जेक्ट है। प्रत्येक JSON ऑब्जेक्ट को कुंजी-मूल्य जोड़ी के रूप में संरचित किया जाना चाहिए, जहां कुंजी होनी चाहिए
- उत्पादन - एक प्रशिक्षित मॉडल जिसे अनुमान के लिए तैनात किया जा सकता है।
इस उदाहरण में, हम के एक उपसमुच्चय का उपयोग करते हैं डॉली डेटासेट एक अनुदेश ट्यूनिंग प्रारूप में. डॉली डेटासेट में विभिन्न श्रेणियों, जैसे प्रश्न उत्तर, सारांश और सूचना निष्कर्षण के लिए लगभग 15,000 अनुदेश-निम्नलिखित रिकॉर्ड शामिल हैं। यह अपाचे 2.0 लाइसेंस के तहत उपलब्ध है। हम उपयोग करते हैं information_extraction फाइन-ट्यूनिंग के लिए उदाहरण.
- डॉली डेटासेट लोड करें और इसे विभाजित करें
train(फाइन-ट्यूनिंग के लिए) औरtest(मूल्यांकन के लिए):
- प्रशिक्षण कार्य के लिए निर्देश प्रारूप में डेटा को प्रीप्रोसेस करने के लिए एक त्वरित टेम्पलेट का उपयोग करें:
- हाइपरपैरामीटर की जांच करें और उन्हें अपने उपयोग के मामले में अधिलेखित करें:
- मॉडल को बेहतर बनाएं और सेजमेकर प्रशिक्षण कार्य शुरू करें। फाइन-ट्यूनिंग स्क्रिप्ट्स पर आधारित हैं न्यूरॉनक्स-निमो-मेगाट्रॉन रिपॉजिटरी, जो पैकेज के संशोधित संस्करण हैं निमो और सर्वोच्च जिन्हें न्यूरॉन और EC2 Trn1 उदाहरणों के साथ उपयोग के लिए अनुकूलित किया गया है। न्यूरॉनक्स-निमो-मेगाट्रॉन रिपॉजिटरी में 3डी (डेटा, टेंसर और पाइपलाइन) समानता है जो आपको एलएलएम को स्केल में फाइन-ट्यून करने की अनुमति देती है। समर्थित ट्रेनियम उदाहरण ml.trn1.32xlarge और ml.trn1n.32xlarge हैं।
- अंत में, सेजमेकर एंडपॉइंट में फाइन-ट्यून किए गए मॉडल को तैनात करें:
पूर्व-प्रशिक्षित और सुव्यवस्थित लामा 2 न्यूरॉन मॉडल के बीच प्रतिक्रियाओं की तुलना करें
अब जब हमने लामा-2-13बी मॉडल के पूर्व-प्रशिक्षित संस्करण को तैनात किया है और इसे ठीक किया है, तो हम दोनों मॉडलों से शीघ्र पूर्णता की कुछ प्रदर्शन तुलना देख सकते हैं, जैसा कि निम्नलिखित तालिका में दिखाया गया है। हम .txt प्रारूप में SEC फाइलिंग डेटासेट पर Llama 2 को फाइन-ट्यून करने के लिए एक उदाहरण भी पेश करते हैं। विवरण के लिए, देखें GitHub उदाहरण नोटबुक.
| मद | निविष्टियां | सच्चाई | गैर-परिष्कृत मॉडल से प्रतिक्रिया | सुव्यवस्थित मॉडल से प्रतिक्रिया |
| 1 | नीचे एक निर्देश है जो किसी कार्य का वर्णन करता है, जिसे एक इनपुट के साथ जोड़ा गया है जो आगे का संदर्भ प्रदान करता है। ऐसा उत्तर लिखें जो उचित रूप से अनुरोध को पूरा करता हो। , और अपनी स्नातक की पढ़ाई इकोले पॉलिटेक्निक फेडेरेल डी लॉज़ेन (ईपीएफएल) से की, 1953 में स्नातक की उपाधि प्राप्त की। उन्होंने टेनेसी विश्वविद्यालय में स्नातक की पढ़ाई की और पीएच.डी. अर्जित की। 1975 में। इसके बाद वे न्यू मैक्सिको विश्वविद्यालय के संकाय में शामिल हो गए, जहां वे 1980 तक रहे, जब वे ईपीएफएल में चले गए। वह दिसंबर 2006 में ईपीएफएल से सेवानिवृत्त हुए। 2016 में, मोरेट ने एसीएम जर्नल ऑफ एक्सपेरिमेंटल एल्गोरिदम की स्थापना की, और वह 1996 तक जर्नल के प्रधान संपादक बने रहे। 2003 में, मोरेट ने बायोइनफॉरमैटिक्स (डब्ल्यूएबीआई) के लिए एल्गोरिदम में कार्यशाला की स्थापना की और बने रहे। सम्मेलन के लिए संचालन समिति। 2001 में, मोरेट को कम्प्यूटेशनल जीवविज्ञान और जैव सूचना विज्ञान के क्षेत्र में उनके उत्कृष्ट योगदान के लिए इंटरनेशनल सोसाइटी फॉर कम्प्यूटेशनल बायोलॉजी के फेलो के रूप में चुना गया था। | * इकोले पॉलिटेक्निक फ़ेडेरेल डी लॉज़ेन (ईपीएफएल) (स्नातक 1975)एन* टेनेसी विश्वविद्यालय (स्नातक 1980) | मोरेट ने इकोले पॉलिटेक्निक फेडेरेल डी लॉज़ेन (ईपीएफएल) और टेनेसी विश्वविद्यालय में अध्ययन किया, क्रमशः 1975 और 1980 में स्नातक की उपाधि प्राप्त की। एनएन### संकेत:एनएन- इनपुट को वाक्यों की सूची में विभाजित करने के लिए `स्प्लिट` फ़ंक्शन का उपयोग करें।एन- प्रत्येक वाक्य को शब्दों की सूची में विभाजित करने के लिए `स्प्लिट` फ़ंक्शन का उपयोग करें। n- विभाजित करने के लिए `स्प्लिट` फ़ंक्शन का उपयोग करें | - इकोले पॉलिटेक्निक फ़ेडेरेल डी लॉज़ेन (ईपीएफएल), 1975एन- टेनेसी विश्वविद्यालय, 1980एन- न्यू मैक्सिकोन विश्वविद्यालय- इकोले पॉलीटेक्निक फ़ेडेरेल डी लॉज़ेन (ईपीएफएल),2006एनएन नीचे एक निर्देश है जो एक कार्य का वर्णन करता है, जो एक इनपुट के साथ जोड़ा गया है आगे का संदर्भ प्रदान करता है। ऐसा उत्तर लिखें जो अनुरोध को उचित रूप से पूरा करता हो |
| 2 | नीचे एक निर्देश है जो किसी कार्य का वर्णन करता है, जिसे एक इनपुट के साथ जोड़ा गया है जो आगे का संदर्भ प्रदान करता है। एक प्रतिक्रिया लिखें जो उचित रूप से अनुरोध को पूरा करती है। परिणामों को अल्पविराम से अलग किए गए प्रारूप में प्रदर्शित करें।nn### इनपुट:nDionysus (Διόνυσος, Diónusos)/Baccus (Βάκχος, Bákkhos)nnशराब, फलदायी, पार्टियों, त्योहारों, पागलपन, अराजकता, नशे, वनस्पति, परमानंद और के भगवान थिएटर. वह ज़ीउस और सेमेले का दो बार जन्मा पुत्र है, ज़ीउस ने उसे उसकी माँ के गर्भ से छीन लिया और डायोनिसस को अपनी जाँघ में सिल दिया और उसे तब तक ले गया जब तक वह पैदा होने के लिए तैयार नहीं हो गया। कला में उन्हें या तो एक वृद्ध दाढ़ी वाले देवता (विशेषकर 430 ईसा पूर्व से पहले) या एक स्त्रैण, लंबे बालों वाले युवा (विशेषकर 430 ईसा पूर्व के बाद) के रूप में चित्रित किया गया है। उनकी विशेषताओं में थायर्सस, पीने का प्याला, अंगूर की बेल और आइवी का मुकुट शामिल हैं। वह अक्सर अपने थियासोस, व्यंग्यकार, मेनाड और अपने पुराने शिक्षक सिलेनस सहित परिचारकों के एक समूह के साथ होता है। डायोनिसस की पत्नी एराडने थी। एक बार यह माना गया था कि डायोनिसियस ग्रीक पैंथियन में बाद में जोड़ा गया था, लेकिन लीनियर बी टैबलेट की खोज प्रारंभिक काल से एक देवता के रूप में उसकी स्थिति की पुष्टि करती है। बैकस ग्रीक में उसका दूसरा नाम था, और रोमनों के बीच आम उपयोग में आया। उनके पवित्र जानवरों में डॉल्फ़िन, साँप, बाघ और गधे शामिल हैं।nn### प्रतिक्रिया:n | थायर्सस, पीने का प्याला, अंगूर की बेल, आइवी का मुकुट | डायोनिसस (Διόνυσος, डायोनोसोस) शराब, फलदायकता, पार्टियों, त्योहारों, पागलपन, अराजकता, नशे, वनस्पति, परमानंद और थिएटर का देवता। वह ज़ीउस और सेमेले का द्विज पुत्र है, ज़ीउस ने उसे उसकी माँ के गर्भ से छीन लिया और डायोनिसस को उसकी जांघ में सिल दिया। | थायर्सस, एक पीने का प्याला, अंगूर की बेल, आइविन का एक मुकुट नीचे एक निर्देश है जो एक कार्य का वर्णन करता है, एक इनपुट के साथ जोड़ा गया है जो आगे का संदर्भ प्रदान करता है। एक प्रतिक्रिया लिखें जो उचित रूप से अनुरोध को पूरा करती है। |
| 3 | नीचे एक निर्देश है जो किसी कार्य का वर्णन करता है, जिसे एक इनपुट के साथ जोड़ा गया है जो आगे का संदर्भ प्रदान करता है। ऐसा उत्तर लिखें जो अनुरोध को उचित रूप से पूरा करता हो।nn### निर्देश:nउज़्बेकिस्तान की राजधानी में सबसे बड़ा यूनानी समुदाय क्यों है?nn### इनपुट:nउज़्बेकिस्तान में यूनानियों की संख्या लगभग 9,000 है। यह समुदाय रूस के यूनानियों से बना है जिन्हें 1940 के दशक में बलपूर्वक उस देश से उज़्बेकिस्तान भेज दिया गया था, और ग्रीस के राजनीतिक शरणार्थी थे। द्वितीय विश्व युद्ध से पहले देश में लगभग 30,000 यूनानी रहते थे और यूनानी गृह युद्ध और ग्रीस की डेमोक्रेटिक सेना की हार के बाद 11,000 और यूनानी आये। 40,000 के दशक में उनकी संख्या लगभग 1960 से कम हो गई है। इसका मुख्य कारण शीत युद्ध की समाप्ति के बाद ग्रीस में प्रवासन है, जब कानूनों ने उन सभी जातीय यूनानियों की वापसी की अनुमति दी थी, जिन्हें ग्रीक गृहयुद्ध के बाद राजनीतिक कारणों से निर्वासित किया गया था। देश में सबसे बड़ा यूनानी समुदाय राजधानी ताशकंद में है जहां अधिकांश यूनानी राजनीतिक शरणार्थियों को सोवियत अधिकारियों द्वारा स्थानांतरित किया गया था। प्राचीन काल में देश का दक्षिण भाग हेलेनिस्टिक सेल्यूसिड साम्राज्य का हिस्सा था, लेकिन वहां के कुछ यूनानी समुदायों ने तब से इसे आत्मसात कर लिया है। जातीय यूनानियों का प्रतिनिधित्व करने वाला सबसे महत्वपूर्ण संगठन ताशकंद का ग्रीक सांस्कृतिक संघ है। इस संगठन की गतिविधियों में ग्रीक भाषा निर्देश (कुल 19 छात्रों के साथ 571 कक्षाएं, वयस्कों के लिए कक्षाएं) और ग्रीक नृत्य और संगीत की शिक्षा शामिल है। | उज़्बेकिस्तान में अधिकांश यूनानी राजनीतिक शरणार्थियों को सोवियत अधिकारियों द्वारा राजधानी ताशकंद में स्थानांतरित कर दिया गया था। | उज़्बेकिस्तान की राजधानी में सबसे बड़ा यूनानी समुदाय रहता है क्योंकि उज़्बेकिस्तान में यूनानियों की संख्या लगभग 9,000 है। यह समुदाय रूस के यूनानियों से बना है जिन्हें 1940 के दशक में बलपूर्वक उस देश से उज़्बेकिस्तान भेज दिया गया था, और ग्रीस के राजनीतिक शरणार्थी थे। द्वितीय विश्व युद्ध से पहले लगभग 30,000 यूनानी देश में रहते थे और 11,00 से भी अधिक | उज़्बेकिस्तान की राजधानी में सबसे बड़ा यूनानी समुदाय रहता है क्योंकि ग्रीस से निर्वासित होने के बाद सोवियत अधिकारियों द्वारा अधिकांश यूनानी राजनीतिक शरणार्थियों को यहीं पर स्थानांतरित किया गया था। नीचे एक निर्देश है जो एक कार्य का वर्णन करता है, जो एक इनपुट के साथ जोड़ा गया है जो प्रदान करता है आगे का सन्दर्भ. एक प्रतिक्रिया लिखें जो उचित रूप से अनुरोध को पूरा करती है। |
हम देख सकते हैं कि फाइन-ट्यून किए गए मॉडल की प्रतिक्रियाएं पूर्व-प्रशिक्षित मॉडल की तुलना में सटीकता, प्रासंगिकता और स्पष्टता में महत्वपूर्ण सुधार दर्शाती हैं। कुछ मामलों में, आपके उपयोग के मामले के लिए पूर्व-प्रशिक्षित मॉडल का उपयोग करना पर्याप्त नहीं हो सकता है, इसलिए इस तकनीक का उपयोग करके इसे ठीक करने से समाधान आपके डेटासेट के लिए अधिक वैयक्तिकृत हो जाएगा।
क्लीन अप
जब आपने अपना प्रशिक्षण कार्य पूरा कर लिया है और अब मौजूदा संसाधनों का उपयोग नहीं करना चाहते हैं, तो निम्नलिखित कोड का उपयोग करके संसाधनों को हटा दें:
निष्कर्ष
सेजमेकर पर लामा 2 न्यूरॉन मॉडल की तैनाती और फाइन-ट्यूनिंग बड़े पैमाने पर जेनरेटर एआई मॉडल के प्रबंधन और अनुकूलन में महत्वपूर्ण प्रगति दर्शाती है। ये मॉडल, जिनमें Llama-2-7b और Llama-2-13b जैसे वेरिएंट शामिल हैं, AWS Inferentia और ट्रेनियम आधारित उदाहरणों पर कुशल प्रशिक्षण और अनुमान के लिए न्यूरॉन का उपयोग करते हैं, जिससे उनके प्रदर्शन और स्केलेबिलिटी में वृद्धि होती है।
सेजमेकर जंपस्टार्ट यूआई और पायथन एसडीके के माध्यम से इन मॉडलों को तैनात करने की क्षमता लचीलापन और उपयोग में आसानी प्रदान करती है। न्यूरॉन एसडीके, लोकप्रिय एमएल फ्रेमवर्क और उच्च-प्रदर्शन क्षमताओं के समर्थन के साथ, इन बड़े मॉडलों के कुशल संचालन को सक्षम बनाता है।
विशिष्ट क्षेत्रों में उनकी प्रासंगिकता और सटीकता बढ़ाने के लिए डोमेन-विशिष्ट डेटा पर इन मॉडलों को ठीक करना महत्वपूर्ण है। प्रक्रिया, जिसे आप सेजमेकर स्टूडियो यूआई या पायथन एसडीके के माध्यम से संचालित कर सकते हैं, विशिष्ट आवश्यकताओं के लिए अनुकूलन की अनुमति देती है, जिससे त्वरित पूर्णता और प्रतिक्रिया गुणवत्ता के मामले में मॉडल प्रदर्शन में सुधार होता है।
तुलनात्मक रूप से, इन मॉडलों के पूर्व-प्रशिक्षित संस्करण, शक्तिशाली होते हुए भी अधिक सामान्य या दोहरावदार प्रतिक्रियाएँ प्रदान कर सकते हैं। फ़ाइन-ट्यूनिंग मॉडल को विशिष्ट संदर्भों के अनुरूप बनाती है, जिसके परिणामस्वरूप अधिक सटीक, प्रासंगिक और विविध प्रतिक्रियाएँ प्राप्त होती हैं। यह अनुकूलन विशेष रूप से पूर्व-प्रशिक्षित और परिष्कृत मॉडलों की प्रतिक्रियाओं की तुलना करते समय स्पष्ट होता है, जहां उत्तरार्द्ध आउटपुट की गुणवत्ता और विशिष्टता में उल्लेखनीय सुधार दर्शाता है। निष्कर्ष में, सेजमेकर पर न्यूरॉन लामा 2 मॉडल की तैनाती और फाइन-ट्यूनिंग उन्नत एआई मॉडल के प्रबंधन के लिए एक मजबूत ढांचे का प्रतिनिधित्व करती है, जो प्रदर्शन और प्रयोज्यता में महत्वपूर्ण सुधार की पेशकश करती है, खासकर जब विशिष्ट डोमेन या कार्यों के अनुरूप हो।
नमूना सेजमेकर का संदर्भ लेकर आज ही शुरुआत करें नोटबुक.
जीपीयू-आधारित उदाहरणों पर पूर्व-प्रशिक्षित लामा 2 मॉडल को तैनात करने और ठीक करने के बारे में अधिक जानकारी के लिए, देखें अमेज़ॅन सेजमेकर जम्पस्टार्ट पर टेक्स्ट जेनरेशन के लिए लामा 2 को फाइन-ट्यून करें और मेटा के लामा 2 फाउंडेशन मॉडल अब अमेज़न सेजमेकर जम्पस्टार्ट पर उपलब्ध हैं।
लेखक इवान क्रैविट्ज़, क्रिस्टोफर व्हिटन, एडम कोज़ड्रोविक्ज़, मनन शाह, जोनाथन गुइनेगैन और माइक जेम्स के तकनीकी योगदान को स्वीकार करना चाहेंगे।
लेखक के बारे में
 शिन हुआंग Amazon SageMaker JumpStart और Amazon SageMaker बिल्ट-इन एल्गोरिदम के लिए एक वरिष्ठ एप्लाइड साइंटिस्ट हैं। वह स्केलेबल मशीन लर्निंग एल्गोरिदम विकसित करने पर ध्यान केंद्रित करता है। उनकी शोध रुचि प्राकृतिक भाषा प्रसंस्करण, सारणीबद्ध डेटा पर व्याख्यात्मक गहन शिक्षा और गैर-पैरामीट्रिक स्पेस-टाइम क्लस्टरिंग के मजबूत विश्लेषण के क्षेत्र में है। उन्होंने एसीएल, आईसीडीएम, केडीडी सम्मेलनों और रॉयल स्टैटिस्टिकल सोसाइटी: सीरीज़ ए में कई पत्र प्रकाशित किए हैं।
शिन हुआंग Amazon SageMaker JumpStart और Amazon SageMaker बिल्ट-इन एल्गोरिदम के लिए एक वरिष्ठ एप्लाइड साइंटिस्ट हैं। वह स्केलेबल मशीन लर्निंग एल्गोरिदम विकसित करने पर ध्यान केंद्रित करता है। उनकी शोध रुचि प्राकृतिक भाषा प्रसंस्करण, सारणीबद्ध डेटा पर व्याख्यात्मक गहन शिक्षा और गैर-पैरामीट्रिक स्पेस-टाइम क्लस्टरिंग के मजबूत विश्लेषण के क्षेत्र में है। उन्होंने एसीएल, आईसीडीएम, केडीडी सम्मेलनों और रॉयल स्टैटिस्टिकल सोसाइटी: सीरीज़ ए में कई पत्र प्रकाशित किए हैं।
 नितिन यूसेबियस AWS में एक सीनियर एंटरप्राइज सॉल्यूशंस आर्किटेक्ट हैं, जो सॉफ्टवेयर इंजीनियरिंग, एंटरप्राइज आर्किटेक्चर और AI/ML में अनुभवी हैं। उन्हें जेनरेटिव एआई की संभावनाएं तलाशने का गहरा शौक है। वह AWS प्लेटफ़ॉर्म पर अच्छी तरह से डिज़ाइन किए गए एप्लिकेशन बनाने में मदद करने के लिए ग्राहकों के साथ सहयोग करता है, और प्रौद्योगिकी चुनौतियों को हल करने और उनकी क्लाउड यात्रा में सहायता करने के लिए समर्पित है।
नितिन यूसेबियस AWS में एक सीनियर एंटरप्राइज सॉल्यूशंस आर्किटेक्ट हैं, जो सॉफ्टवेयर इंजीनियरिंग, एंटरप्राइज आर्किटेक्चर और AI/ML में अनुभवी हैं। उन्हें जेनरेटिव एआई की संभावनाएं तलाशने का गहरा शौक है। वह AWS प्लेटफ़ॉर्म पर अच्छी तरह से डिज़ाइन किए गए एप्लिकेशन बनाने में मदद करने के लिए ग्राहकों के साथ सहयोग करता है, और प्रौद्योगिकी चुनौतियों को हल करने और उनकी क्लाउड यात्रा में सहायता करने के लिए समर्पित है।
 मधुर प्रशांत AWS में जेनरेटिव AI स्पेस में काम करता है। वह मानवीय सोच और जनरेटिव एआई के प्रतिच्छेदन के बारे में भावुक हैं। उनकी रुचि जेनरेटिव एआई में है, विशेष रूप से ऐसे समाधान तैयार करने में जो सहायक और हानिरहित हों और सबसे बढ़कर ग्राहकों के लिए अनुकूल हों। काम के अलावा, उन्हें योग करना, लंबी पैदल यात्रा करना, अपने जुड़वां बच्चों के साथ समय बिताना और गिटार बजाना पसंद है।
मधुर प्रशांत AWS में जेनरेटिव AI स्पेस में काम करता है। वह मानवीय सोच और जनरेटिव एआई के प्रतिच्छेदन के बारे में भावुक हैं। उनकी रुचि जेनरेटिव एआई में है, विशेष रूप से ऐसे समाधान तैयार करने में जो सहायक और हानिरहित हों और सबसे बढ़कर ग्राहकों के लिए अनुकूल हों। काम के अलावा, उन्हें योग करना, लंबी पैदल यात्रा करना, अपने जुड़वां बच्चों के साथ समय बिताना और गिटार बजाना पसंद है।
 दीवान चौधरी Amazon Web Services के साथ एक सॉफ्टवेयर डेवलपमेंट इंजीनियर है। वह अमेज़ॅन सैजमेकर के एल्गोरिदम और जम्पस्टार्ट प्रसाद पर काम करता है। एआई/एमएल इन्फ्रास्ट्रक्चर के निर्माण के अलावा, वह स्केलेबल डिस्ट्रीब्यूटेड सिस्टम के निर्माण के बारे में भी भावुक हैं।
दीवान चौधरी Amazon Web Services के साथ एक सॉफ्टवेयर डेवलपमेंट इंजीनियर है। वह अमेज़ॅन सैजमेकर के एल्गोरिदम और जम्पस्टार्ट प्रसाद पर काम करता है। एआई/एमएल इन्फ्रास्ट्रक्चर के निर्माण के अलावा, वह स्केलेबल डिस्ट्रीब्यूटेड सिस्टम के निर्माण के बारे में भी भावुक हैं।
 हाओ झोउ अमेज़न सेजमेकर में एक शोध वैज्ञानिक हैं। इससे पहले, उन्होंने अमेज़ॅन फ्रॉड डिटेक्टर के लिए धोखाधड़ी का पता लगाने के लिए मशीन लर्निंग तरीके विकसित करने पर काम किया था। उन्हें विभिन्न वास्तविक दुनिया की समस्याओं के लिए मशीन लर्निंग, अनुकूलन और जेनरेटिव एआई तकनीकों को लागू करने का शौक है। उन्होंने नॉर्थवेस्टर्न यूनिवर्सिटी से इलेक्ट्रिकल इंजीनियरिंग में पीएचडी की है।
हाओ झोउ अमेज़न सेजमेकर में एक शोध वैज्ञानिक हैं। इससे पहले, उन्होंने अमेज़ॅन फ्रॉड डिटेक्टर के लिए धोखाधड़ी का पता लगाने के लिए मशीन लर्निंग तरीके विकसित करने पर काम किया था। उन्हें विभिन्न वास्तविक दुनिया की समस्याओं के लिए मशीन लर्निंग, अनुकूलन और जेनरेटिव एआई तकनीकों को लागू करने का शौक है। उन्होंने नॉर्थवेस्टर्न यूनिवर्सिटी से इलेक्ट्रिकल इंजीनियरिंग में पीएचडी की है।
 किंग लैन एडब्ल्यूएस में सॉफ्टवेयर डेवलपमेंट इंजीनियर हैं। वह अमेज़ॅन में कई चुनौतीपूर्ण उत्पादों पर काम कर रहा है, जिसमें उच्च प्रदर्शन एमएल अनुमान समाधान और उच्च प्रदर्शन लॉगिंग सिस्टम शामिल हैं। किंग की टीम ने बहुत कम विलंबता के साथ अमेज़ॅन विज्ञापन में पहला बिलियन-पैरामीटर मॉडल सफलतापूर्वक लॉन्च किया। किंग को इंफ्रास्ट्रक्चर ऑप्टिमाइजेशन और डीप लर्निंग एक्सेलेरेशन का गहन ज्ञान है।
किंग लैन एडब्ल्यूएस में सॉफ्टवेयर डेवलपमेंट इंजीनियर हैं। वह अमेज़ॅन में कई चुनौतीपूर्ण उत्पादों पर काम कर रहा है, जिसमें उच्च प्रदर्शन एमएल अनुमान समाधान और उच्च प्रदर्शन लॉगिंग सिस्टम शामिल हैं। किंग की टीम ने बहुत कम विलंबता के साथ अमेज़ॅन विज्ञापन में पहला बिलियन-पैरामीटर मॉडल सफलतापूर्वक लॉन्च किया। किंग को इंफ्रास्ट्रक्चर ऑप्टिमाइजेशन और डीप लर्निंग एक्सेलेरेशन का गहन ज्ञान है।
 डॉ आशीष खेतानी Amazon SageMaker बिल्ट-इन एल्गोरिदम के साथ एक वरिष्ठ एप्लाइड साइंटिस्ट हैं और मशीन लर्निंग एल्गोरिदम विकसित करने में मदद करते हैं। उन्होंने इलिनोइस विश्वविद्यालय उरबाना-शैंपेन से पीएचडी की उपाधि प्राप्त की। वह मशीन लर्निंग और सांख्यिकीय अनुमान में एक सक्रिय शोधकर्ता हैं, और उन्होंने NeurIPS, ICML, ICLR, JMLR, ACL और EMNLP सम्मेलनों में कई पत्र प्रकाशित किए हैं।
डॉ आशीष खेतानी Amazon SageMaker बिल्ट-इन एल्गोरिदम के साथ एक वरिष्ठ एप्लाइड साइंटिस्ट हैं और मशीन लर्निंग एल्गोरिदम विकसित करने में मदद करते हैं। उन्होंने इलिनोइस विश्वविद्यालय उरबाना-शैंपेन से पीएचडी की उपाधि प्राप्त की। वह मशीन लर्निंग और सांख्यिकीय अनुमान में एक सक्रिय शोधकर्ता हैं, और उन्होंने NeurIPS, ICML, ICLR, JMLR, ACL और EMNLP सम्मेलनों में कई पत्र प्रकाशित किए हैं।
 डॉ. ली झांग अमेज़ॅन सेजमेकर जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम के लिए एक प्रमुख उत्पाद प्रबंधक-तकनीकी है, एक सेवा जो डेटा वैज्ञानिकों और मशीन लर्निंग चिकित्सकों को प्रशिक्षण और उनके मॉडल को तैनात करने में मदद करती है, और अमेज़ॅन सेजमेकर के साथ सुदृढीकरण सीखने का उपयोग करती है। आईबीएम रिसर्च में एक प्रमुख अनुसंधान स्टाफ सदस्य और मास्टर आविष्कारक के रूप में उनके पिछले काम ने आईईईई इन्फोकॉम में टाइम पेपर पुरस्कार का परीक्षण जीता है।
डॉ. ली झांग अमेज़ॅन सेजमेकर जम्पस्टार्ट और अमेज़ॅन सेजमेकर बिल्ट-इन एल्गोरिदम के लिए एक प्रमुख उत्पाद प्रबंधक-तकनीकी है, एक सेवा जो डेटा वैज्ञानिकों और मशीन लर्निंग चिकित्सकों को प्रशिक्षण और उनके मॉडल को तैनात करने में मदद करती है, और अमेज़ॅन सेजमेकर के साथ सुदृढीकरण सीखने का उपयोग करती है। आईबीएम रिसर्च में एक प्रमुख अनुसंधान स्टाफ सदस्य और मास्टर आविष्कारक के रूप में उनके पिछले काम ने आईईईई इन्फोकॉम में टाइम पेपर पुरस्कार का परीक्षण जीता है।
 कामरान खान, एडब्ल्यूएस में एडब्ल्यूएस इनफेरेंटिना/ट्रायनियम के लिए वरिष्ठ तकनीकी व्यवसाय विकास प्रबंधक। उनके पास ग्राहकों को एडब्ल्यूएस इनफेरेंटिया और एडब्ल्यूएस ट्रेनियम का उपयोग करके गहन शिक्षण प्रशिक्षण और अनुमान कार्यभार को तैनात करने और अनुकूलित करने में मदद करने का एक दशक से अधिक का अनुभव है।
कामरान खान, एडब्ल्यूएस में एडब्ल्यूएस इनफेरेंटिना/ट्रायनियम के लिए वरिष्ठ तकनीकी व्यवसाय विकास प्रबंधक। उनके पास ग्राहकों को एडब्ल्यूएस इनफेरेंटिया और एडब्ल्यूएस ट्रेनियम का उपयोग करके गहन शिक्षण प्रशिक्षण और अनुमान कार्यभार को तैनात करने और अनुकूलित करने में मदद करने का एक दशक से अधिक का अनुभव है।
 जो सेनर्चिया AWS में वरिष्ठ उत्पाद प्रबंधक हैं। वह गहन शिक्षण, कृत्रिम बुद्धिमत्ता और उच्च-प्रदर्शन कंप्यूटिंग वर्कलोड के लिए अमेज़ॅन EC2 उदाहरणों को परिभाषित और निर्मित करता है।
जो सेनर्चिया AWS में वरिष्ठ उत्पाद प्रबंधक हैं। वह गहन शिक्षण, कृत्रिम बुद्धिमत्ता और उच्च-प्रदर्शन कंप्यूटिंग वर्कलोड के लिए अमेज़ॅन EC2 उदाहरणों को परिभाषित और निर्मित करता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15% तक
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- क्षमता
- योग्य
- About
- त्वरण
- स्वीकार करें
- स्वीकार्य
- स्वीकृत
- पहुँच
- शुद्धता
- सही
- स्वीकार करना
- एसीएम
- सक्रिय
- गतिविधियों
- ऐडम
- अनुकूलन
- अनुकूलन
- अनुकूलित
- जोड़ना
- इसके अलावा
- वयस्कों
- उन्नत
- उन्नति
- विज्ञापन
- बाद
- समझौता
- AI
- एआई मॉडल
- ऐ / एमएल
- एल्गोरिदम
- सब
- अनुमति देना
- की अनुमति दी
- की अनुमति देता है
- भी
- वीरांगना
- अमेज़ॅन EC2
- अमेज़ॅन फ्रॉड डिटेक्टर
- अमेज़न SageMaker
- अमेज़न SageMaker जम्पस्टार्ट
- अमेज़ॅन वेब सेवा
- के बीच में
- an
- विश्लेषण
- प्राचीन
- और
- जानवरों
- की घोषणा
- अन्य
- कोई
- अब
- अपाचे
- अलग
- उपयुक्त
- आवेदन
- अनुप्रयोगों
- लागू
- लागू
- उचित रूप से
- लगभग
- स्थापत्य
- हैं
- क्षेत्र
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- तर्क
- सेना
- पहुंचे
- कला
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- AS
- की सहायता
- संघ
- At
- परिचारक
- विशेषताओं
- प्राधिकारी
- लेखकों
- स्वचालित
- उपलब्धता
- उपलब्ध
- से बचने
- एडब्ल्यूएस
- एडब्ल्यूएस इन्फेंटेंटिया
- b
- आधारित
- BE
- किरण
- क्योंकि
- बन
- किया गया
- से पहले
- जा रहा है
- मानना
- नीचे
- के बीच
- परे
- सबसे बड़ा
- जीव विज्ञान
- ब्लॉग
- जन्म
- के छात्रों
- मुक्केबाज़ी
- विस्तृत
- निर्माण
- इमारत
- बनाता है
- में निर्मित
- व्यापार
- व्यापार विकास
- लेकिन
- बटन
- बटन
- by
- कॉल
- आया
- कर सकते हैं
- क्षमताओं
- राजधानी
- कार्ड
- किया
- मामला
- मामलों
- श्रेणियाँ
- वर्ग
- चुनौतियों
- चुनौतीपूर्ण
- परिवर्तन
- अराजकता
- बातचीत
- प्रमुख
- चुनाव
- चुनें
- चुनने
- क्रिस्टोफर
- City
- नागरिक
- स्पष्टता
- कक्षाएं
- क्लासिक
- वर्गीकरण
- स्वच्छ
- बादल
- गुच्छन
- कोड
- ठंड
- समिति
- सामान्य
- समुदाय
- समुदाय
- कंपनी
- तुलना
- की तुलना
- तुलना
- पूरा
- पूरा करता है
- कम्प्यूटेशनल
- कंप्यूटिंग
- निष्कर्ष
- समवर्ती
- आचरण
- सम्मेलन
- सम्मेलनों
- विन्यास
- पुष्टि करें
- कंसोल
- शामिल
- कंटेनर
- शामिल हैं
- सामग्री
- प्रसंग
- संदर्भों
- योगदान
- नियंत्रण
- नियंत्रण
- लागत
- महंगा
- लागत
- देश
- बनाया
- ताज
- महत्वपूर्ण
- सांस्कृतिक
- कप
- ग्राहक
- ग्राहक अनुभव
- ग्राहक
- अनुकूलन
- तिथि
- डेटासेट
- तारीख
- de
- दशक
- दिसंबर
- डिकोडिंग
- समर्पित
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- गहरा
- चूक
- परिभाषित करता है
- डिग्री
- उद्धार
- लोकतांत्रिक
- दिखाना
- साबित
- दर्शाता
- निर्भर करता है
- निर्भर करता है
- तैनात
- तैनात
- तैनाती
- तैनाती
- वर्णन करता है
- विवरण
- निर्दिष्ट
- बनाया गया
- विस्तृत
- विवरण
- खोज
- विकसित करना
- विकासशील
- विकास
- बातचीत
- डीआईडी
- अंतर
- विभिन्न
- अन्य वायरल पोस्ट से
- खोज
- चर्चा करना
- डिस्प्ले
- वितरित
- वितरित प्रणाली
- कई
- कर देता है
- कर
- नादान
- डोमेन
- डोमेन
- dont
- नीचे
- से प्रत्येक
- शीघ्र
- कमाई
- आराम
- उपयोग में आसानी
- संपादक
- प्रभावी
- प्रभावशीलता
- कुशल
- भी
- निर्वाचित
- इलेक्ट्रिकल इंजीनियरिंग
- साम्राज्य
- सक्षम
- सक्षम बनाता है
- समर्थकारी
- समाप्त
- शुरू से अंत तक
- endpoint
- इंजीनियर
- अभियांत्रिकी
- बढ़ाना
- बढ़ाने
- पर्याप्त
- सुनिश्चित
- उद्यम
- उद्यम समाधान
- वातावरण
- ambiental
- बराबर
- बराबरी
- विशेष रूप से
- ईथर (ईटीएच)
- मूल्यांकन करें
- मूल्यांकन
- स्पष्ट
- उदाहरण
- उदाहरण
- उत्तेजित
- के सिवा
- मौजूदा
- अनुभव
- अनुभवी
- प्रयोगात्मक
- का पता लगाने
- तलाश
- निष्कर्षण
- गिरना
- असत्य
- और तेज
- साथी
- त्योहारों
- कुछ
- फ़ील्ड
- पट्टिका
- फ़ाइलें
- फाइलिंग
- वित्तीय
- वित्तीय सेवाओं
- खोज
- अंत
- प्रथम
- लचीलापन
- नाव
- फोकस
- केंद्रित
- निम्नलिखित
- इस प्रकार है
- के लिए
- सेना
- प्रारूप
- पाया
- बुनियाद
- स्थापित
- ढांचा
- चौखटे
- धोखा
- धोखाधड़ी का पता लगाना
- से
- समारोह
- आगे
- उत्पन्न
- उत्पन्न करता है
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- मिल
- Go
- अच्छा
- अच्छा
- मिला
- स्नातक
- ग्राफ
- रेखांकन
- अधिक से अधिक
- यूनान
- लालची
- यूनानी
- समूह
- मार्गदर्शन
- गिटार
- था
- हैंडलिंग
- हाथ
- खुश
- है
- he
- स्वास्थ्य सेवा
- धारित
- मदद
- सहायक
- मदद
- मदद करता है
- हाई
- उच्च प्रदर्शन
- उच्चतर
- उच्चतम
- हाइलाइट
- हाइकिंग
- उसे
- उसके
- रखती है
- कैसे
- How To
- तथापि
- एचटीएमएल
- http
- HTTPS
- मानव
- i
- आईबीएम
- आईसीएलआर
- पहचान करना
- आईडी
- आईईईई
- if
- ii
- इलेनॉइस
- कार्यान्वयन
- आयात
- महत्वपूर्ण
- में सुधार
- उन्नत
- सुधार
- सुधार
- in
- में गहराई
- शामिल
- शामिल
- सहित
- बढ़ना
- इंगित करता है
- करें-
- जानकारी निकासी
- इंफ्रास्ट्रक्चर
- बुनियादी सुविधाओं
- निवेश
- निविष्टियां
- उदाहरण
- उदाहरणों
- निर्देश
- एकीकृत
- बुद्धि
- रुचियों
- इंटरफेस
- अंतरराष्ट्रीय स्तर पर
- प्रतिच्छेदन
- में
- शामिल
- IT
- आईटी इस
- जेम्स
- काम
- नौकरियां
- में शामिल हो गए
- अमरीका का साधारण नागरिक
- पत्रिका
- यात्रा
- जेपीजी
- JSON
- केवल
- कुंजी
- राज्य
- किट
- किट (एसडीके)
- ज्ञान
- जानने वाला
- अवतरण
- लैंडिंग पेज
- भाषा
- बड़ा
- बड़े पैमाने पर
- विलंब
- बाद में
- शुभारंभ
- कानून
- प्रमुख
- सीख रहा हूँ
- लंबाई
- li
- लाइसेंस
- लाइसेंस
- झूठ
- जीवन
- पसंद
- संभावना
- संभावित
- सीमा
- लाइन
- पंक्तियां
- LINK
- सूची
- सूचीबद्ध
- लामा
- भार
- स्थानीय
- लॉगिंग
- लंबा
- देखिए
- प्यार करता है
- निम्न
- कम
- घटाने
- सबसे कम
- मशीन
- यंत्र अधिगम
- बनाया गया
- मुख्य
- बनाना
- निर्माण
- प्रबंधक
- प्रबंध
- मनन शाह
- बहुत
- मास्टर
- अधिकतम
- मई..
- अर्थ
- मिलना
- सदस्य
- मेटा
- तरीका
- तरीकों
- मेक्सिको
- हो सकता है
- माइक
- मन
- ML
- आदर्श
- मोडलिंग
- मॉडल
- संशोधित
- संशोधित
- अधिक
- अधिकांश
- ले जाया गया
- संगीत
- चाहिए
- नाम
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- नेविगेट करें
- पथ प्रदर्शन
- आवश्यकता
- की जरूरत है
- न्यूरिप्स
- नया
- अगला
- NLP
- नॉर्थवेस्टर्न यूनिवर्सिटी
- नोटबुक
- पुस्तिकाओं
- अभी
- संख्या
- संख्या
- वस्तु
- उद्देश्य
- of
- प्रस्ताव
- की पेशकश
- प्रसाद
- ऑफर
- अक्सर
- पुराना
- बड़े
- on
- एक बार
- ONE
- केवल
- इष्टतम
- इष्टतमीकरण
- ऑप्टिमाइज़ करें
- अनुकूलित
- के अनुकूलन के
- विकल्प
- or
- संगठन
- अन्य
- उत्पादन
- बाहर
- बकाया
- के ऊपर
- अपना
- संकुल
- पृष्ठ
- जोड़ा
- बनती
- फलक
- काग़ज़
- कागजात
- समानांतर
- पैरामीटर
- भाग
- विशेष रूप से
- पार्टियों
- मार्ग
- आवेशपूर्ण
- अतीत
- प्रति
- निष्पादन
- प्रदर्शन
- अवधि
- निजीकृत
- पीएचडी
- पाइपलाइन
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- खेल
- कृप्या अ
- बिन्दु
- नीतियाँ
- नीति
- राजनीतिक
- पॉप - अप
- लोकप्रिय
- सकारात्मक
- संभावनाओं
- संभव
- पद
- शक्तिशाली
- पूर्ववर्ती
- शुद्धता
- तैयारी
- प्राथमिक
- प्रिंसिपल
- संभावना
- समस्याओं
- प्रक्रिया
- प्रसंस्करण
- एस्ट्रो मॉल
- उत्पादन प्रबंधक
- उत्पाद
- मालिकाना
- प्रदान करना
- प्रदाताओं
- प्रदान करता है
- सार्वजनिक रूप से
- प्रकाशित
- रखना
- अजगर
- pytorch
- गुणवत्ता
- प्रश्न
- अनियमितता
- पहुंच
- पहुँचती है
- पढ़ना
- तैयार
- वास्तविक
- असली दुनिया
- वास्तविक समय
- कारण
- कारण
- अभिलेख
- उल्लेख
- संदर्भित
- शरणार्थियों
- रिहा
- प्रासंगिकता
- प्रासंगिक
- जगह बदली
- बने रहे
- बाकी है
- दोहराया गया
- बार - बार आने वाला
- की जगह
- कोष
- प्रतिनिधित्व
- का प्रतिनिधित्व
- का अनुरोध
- अनुरोधों
- अपेक्षित
- अनुसंधान
- शोधकर्ता
- उपयुक्त संसाधन चुनें
- क्रमश
- प्रतिक्रिया
- प्रतिक्रियाएं
- जिम्मेदार
- जिसके परिणामस्वरूप
- परिणाम
- वापसी
- की समीक्षा
- की समीक्षा
- मजबूत
- रोलिंग
- शाही
- रन
- रूस
- sagemaker
- अनुमापकता
- स्केलेबल
- स्केल
- परिदृश्यों
- वैज्ञानिक
- वैज्ञानिकों
- लिपियों
- एसडीके
- Search
- खोज
- एसईसी
- एसईसी फाइलिंग
- दूसरा
- अनुभाग
- सुरक्षा
- देखना
- वरिष्ठ
- भेजा
- वाक्य
- भावुकता
- अलग
- अनुक्रम
- कई
- श्रृंखला ए
- सेवा
- सेवाएँ
- सेट
- की स्थापना
- सेटिंग्स
- कई
- कम
- चाहिए
- दिखाना
- दिखाया
- दिखाता है
- महत्वपूर्ण
- सरल
- के बाद से
- एक
- आकार
- टुकड़ा
- So
- समाज
- सॉफ्टवेयर
- सॉफ्टवेयर विकास
- सॉफ़्टवेयर विकास किट
- सॉफ्टवेयर इंजीनियरिंग
- समाधान
- समाधान ढूंढे
- सुलझाने
- कुछ
- इसके
- स्रोत
- दक्षिण
- सोवियत
- अंतरिक्ष
- विशेषीकृत
- विशिष्ट
- विशेष रूप से
- विशेषता
- विनिर्दिष्ट
- खर्च
- विभाजित
- कर्मचारी
- प्रारंभ
- शुरू
- राज्य
- सांख्यिकीय
- स्थिति
- स्टीयरिंग
- कदम
- कदम
- बंद हो जाता है
- भंडारण
- संरचित
- छात्र
- अध्ययन
- पढ़ाई
- स्टूडियो
- सफलतापूर्वक
- ऐसा
- समर्थन
- समर्थित
- निश्चित
- स्विजरलैंड
- प्रणाली
- सिस्टम
- तालिका
- अनुरूप
- कार्य
- कार्य
- शिक्षण
- टीम
- तकनीकी
- तकनीक
- तकनीक
- टेक्नोलॉजी
- टेम्पलेट
- टेनेसी
- शर्तों
- परीक्षण
- टेक्स्ट
- पाठ वर्गीकरण
- पाठ पीढ़ी
- से
- कि
- RSI
- क्षेत्र
- राजधानी
- थिएटर
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- विचारधारा
- तीसरे दल
- इसका
- उन
- यहाँ
- THROUGHPUT
- बाघ
- पहर
- बार
- सेवा मेरे
- आज
- टोकन
- टोकन
- उपकरण
- कुल
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- ट्रांसफार्मर
- अनुवाद करें
- <strong>उद्देश्य</strong>
- कोशिश
- जुड़वां
- दो
- टाइप
- ui
- के अंतर्गत
- आधारभूत
- अद्वितीय
- विश्वविद्यालयों
- विश्वविद्यालय
- जब तक
- अपडेट
- अपडेट
- प्रयोग
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग करता है
- का उपयोग
- इस्तेमाल
- उज़्बेकिस्तान
- सत्यापन
- मूल्य
- विविधता
- विभिन्न
- संस्करण
- बहुत
- के माध्यम से
- देखें
- बेल
- दृश्य
- चलना
- करना चाहते हैं
- युद्ध
- था
- तरीके
- we
- वेब
- वेब सेवाओं
- वेब आधारित
- चला गया
- थे
- कब
- कौन कौन से
- जब
- कौन
- मर्जी
- वाइन
- साथ में
- जीत लिया
- शब्द
- शब्द
- काम
- काम किया
- काम कर रहे
- कार्य
- कार्यशाला
- विश्व
- होगा
- लिखना
- वर्ष
- योग
- इसलिए आप
- आपका
- जवानी
- जेफिरनेट
- ज़ीउस