पांडास, पायथन का उपयोग करके डेटा हेरफेर और विश्लेषण के लिए एक शक्तिशाली और व्यापक रूप से उपयोग की जाने वाली ओपन-सोर्स लाइब्रेरी है। इसकी प्रमुख विशेषताओं में से एक डेटाफ़्रेम को एक या अधिक कॉलम के आधार पर समूहों में विभाजित करके ग्रुपबाय फ़ंक्शन का उपयोग करके डेटा को समूहीकृत करने और फिर उनमें से प्रत्येक में विभिन्न एकत्रीकरण फ़ंक्शन लागू करने की क्षमता है।

से छवि Unsplash
RSI groupby फ़ंक्शन अविश्वसनीय रूप से शक्तिशाली है, क्योंकि यह आपको बड़े डेटासेट का त्वरित सारांश और विश्लेषण करने की अनुमति देता है। उदाहरण के लिए, आप किसी डेटासेट को एक विशिष्ट कॉलम के आधार पर समूहित कर सकते हैं और प्रत्येक समूह के लिए शेष कॉलमों के माध्य, योग या गिनती की गणना कर सकते हैं। आप अपने डेटा की अधिक विस्तृत समझ प्राप्त करने के लिए कई स्तंभों के आधार पर समूह भी बना सकते हैं। इसके अतिरिक्त, यह आपको कस्टम एकत्रीकरण फ़ंक्शन लागू करने की अनुमति देता है, जो जटिल डेटा विश्लेषण कार्यों के लिए एक बहुत शक्तिशाली उपकरण हो सकता है।
इस ट्यूटोरियल में, आप सीखेंगे कि विभिन्न प्रकार के डेटा को समूहीकृत करने और विभिन्न एकत्रीकरण संचालन करने के लिए पांडा में ग्रुपबी फ़ंक्शन का उपयोग कैसे करें। इस ट्यूटोरियल के अंत तक, आपको विभिन्न तरीकों से डेटा का विश्लेषण और सारांशित करने के लिए इस फ़ंक्शन का उपयोग करने में सक्षम होना चाहिए।
जब अच्छी तरह से अभ्यास किया जाता है तो अवधारणाओं को आंतरिक रूप दिया जाता है और यही वह है जो हम आगे करने जा रहे हैं यानी पांडा ग्रुपबी फ़ंक्शन के साथ हाथ मिलाना। का उपयोग करने की अनुशंसा की जाती है जुपीटर नोटबुक इस ट्यूटोरियल के लिए आप प्रत्येक चरण पर आउटपुट देख पा रहे हैं।
नमूना डेटा जनरेट करें
निम्नलिखित पुस्तकालय आयात करें:
- पांडा: डेटाफ़्रेम बनाने और ग्रुप बाय लागू करने के लिए
- यादृच्छिक - यादृच्छिक डेटा उत्पन्न करने के लिए
- पीप्रिंट - शब्दकोश मुद्रित करने के लिए
import pandas as pd
import random
import pprint
इसके बाद, हम एक खाली डेटाफ़्रेम आरंभ करेंगे और प्रत्येक कॉलम के लिए मान भरेंगे जैसा कि नीचे दिखाया गया है:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
बोनस टिप - समान कार्य करने का एक साफ़ तरीका सभी चर और मानों का एक शब्दकोश बनाना और बाद में इसे डेटाफ़्रेम में परिवर्तित करना है।
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
डेटाफ़्रेम नीचे दिखाए गए जैसा दिखता है। इस कोड को चलाते समय, कुछ मान मेल नहीं खाएंगे क्योंकि हम एक यादृच्छिक नमूने का उपयोग कर रहे हैं।
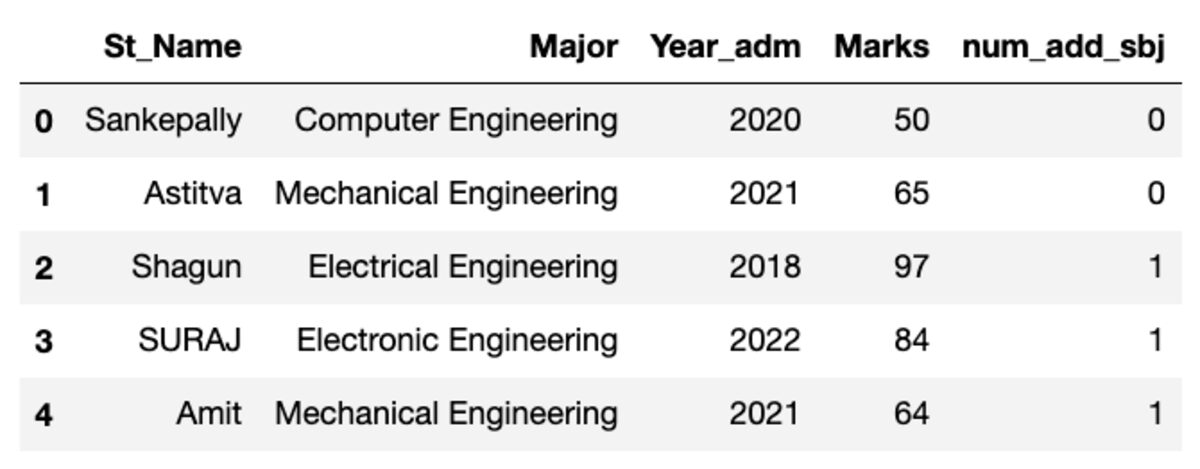
समूह बनाना
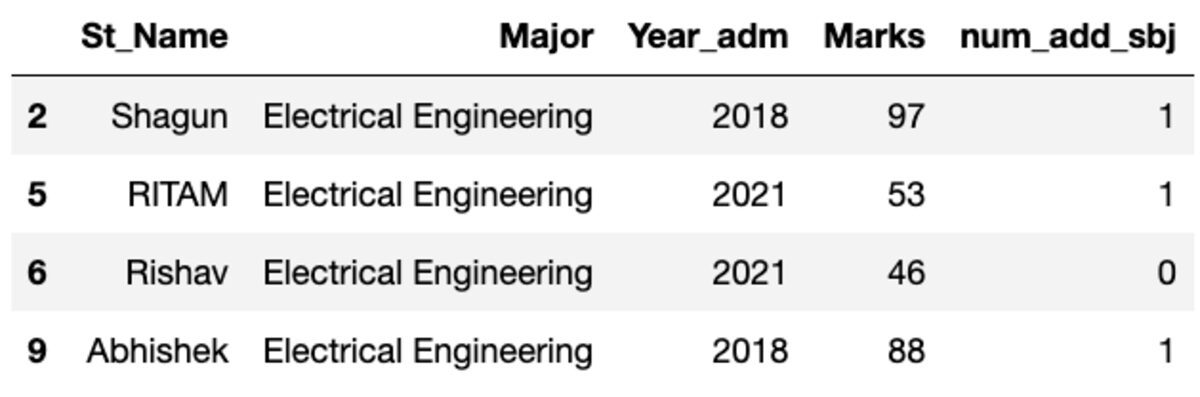
आइए डेटा को "प्रमुख" विषय के आधार पर समूहित करें और यह देखने के लिए समूह फ़िल्टर लागू करें कि इस समूह में कितने रिकॉर्ड आते हैं।
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
तो, चार छात्र इलेक्ट्रिकल इंजीनियरिंग प्रमुख से संबंधित हैं।
आप एक से अधिक कॉलम के आधार पर भी समूह बना सकते हैं (इस मामले में प्रमुख और num_add_sbj)।
groups = df.groupby(['Major', 'num_add_sbj'])
ध्यान दें कि सभी समग्र फ़ंक्शन जो एक कॉलम वाले समूहों पर लागू किए जा सकते हैं, उन्हें एकाधिक कॉलम वाले समूहों पर लागू किया जा सकता है। शेष ट्यूटोरियल के लिए, आइए एक उदाहरण के रूप में एकल कॉलम का उपयोग करके विभिन्न प्रकार के एकत्रीकरण पर ध्यान केंद्रित करें।
आइए "मेजर" कॉलम पर ग्रुपबी का उपयोग करके समूह बनाएं।
groups = df.groupby('Major')प्रत्यक्ष कार्य लागू करना
मान लीजिए कि आप प्रत्येक मेजर में औसत अंक खोजना चाहते हैं। आप क्या करेंगे?
- मार्क्स कॉलम चुनें
- माध्य फलन लागू करें
- अंकों को दो दशमलव स्थानों तक पूर्णांकित करने के लिए गोल फ़ंक्शन लागू करें (वैकल्पिक)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
कुल
समान परिणाम प्राप्त करने का दूसरा तरीका समग्र फ़ंक्शन का उपयोग करना है जैसा कि नीचे दिखाया गया है:
groups['Marks'].aggregate('mean').round(2)
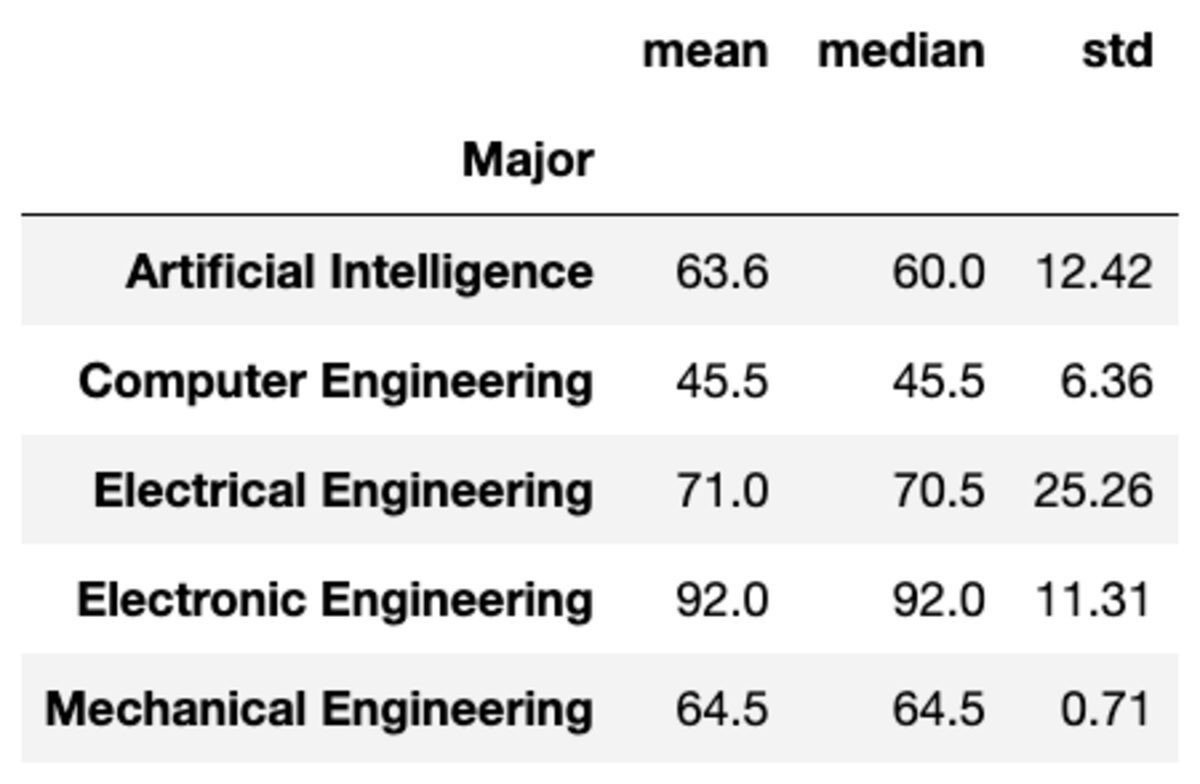
आप फ़ंक्शंस को स्ट्रिंग्स की सूची के रूप में पास करके समूहों में एकाधिक एकत्रीकरण भी लागू कर सकते हैं।
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
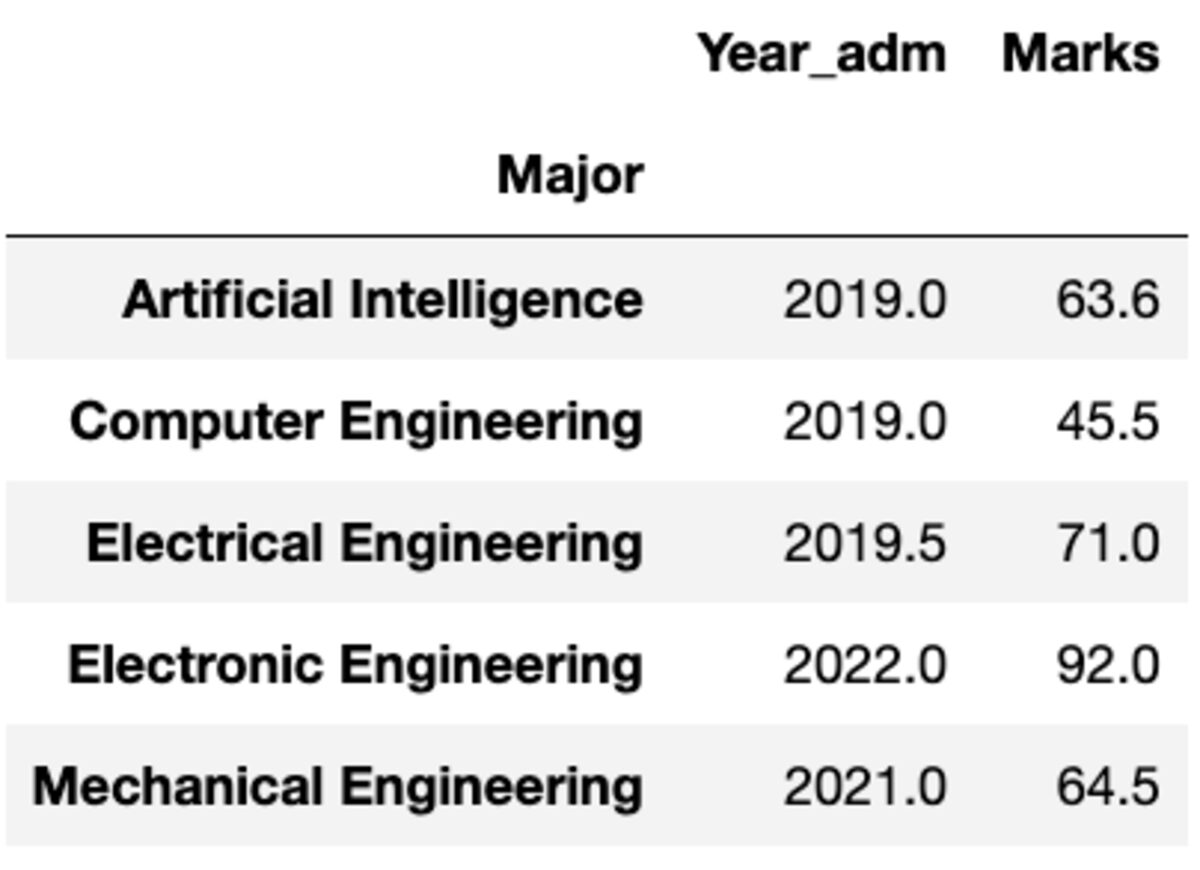
लेकिन क्या होगा यदि आपको एक अलग कॉलम में एक अलग फ़ंक्शन लागू करने की आवश्यकता है। चिंता मत करो। आप {column: function} जोड़ी को पास करके भी ऐसा कर सकते हैं।
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
रूपांतरण
आपको किसी विशेष कॉलम में कस्टम परिवर्तन करने की बहुत आवश्यकता हो सकती है जिसे ग्रुपबी() का उपयोग करके आसानी से प्राप्त किया जा सकता है। आइए स्केलेर के प्रीप्रोसेसिंग मॉड्यूल में उपलब्ध मानक स्केलर के समान एक मानक स्केलर को परिभाषित करें। आप ट्रांसफ़ॉर्म विधि को कॉल करके और कस्टम फ़ंक्शन पास करके सभी कॉलमों को रूपांतरित कर सकते हैं।
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
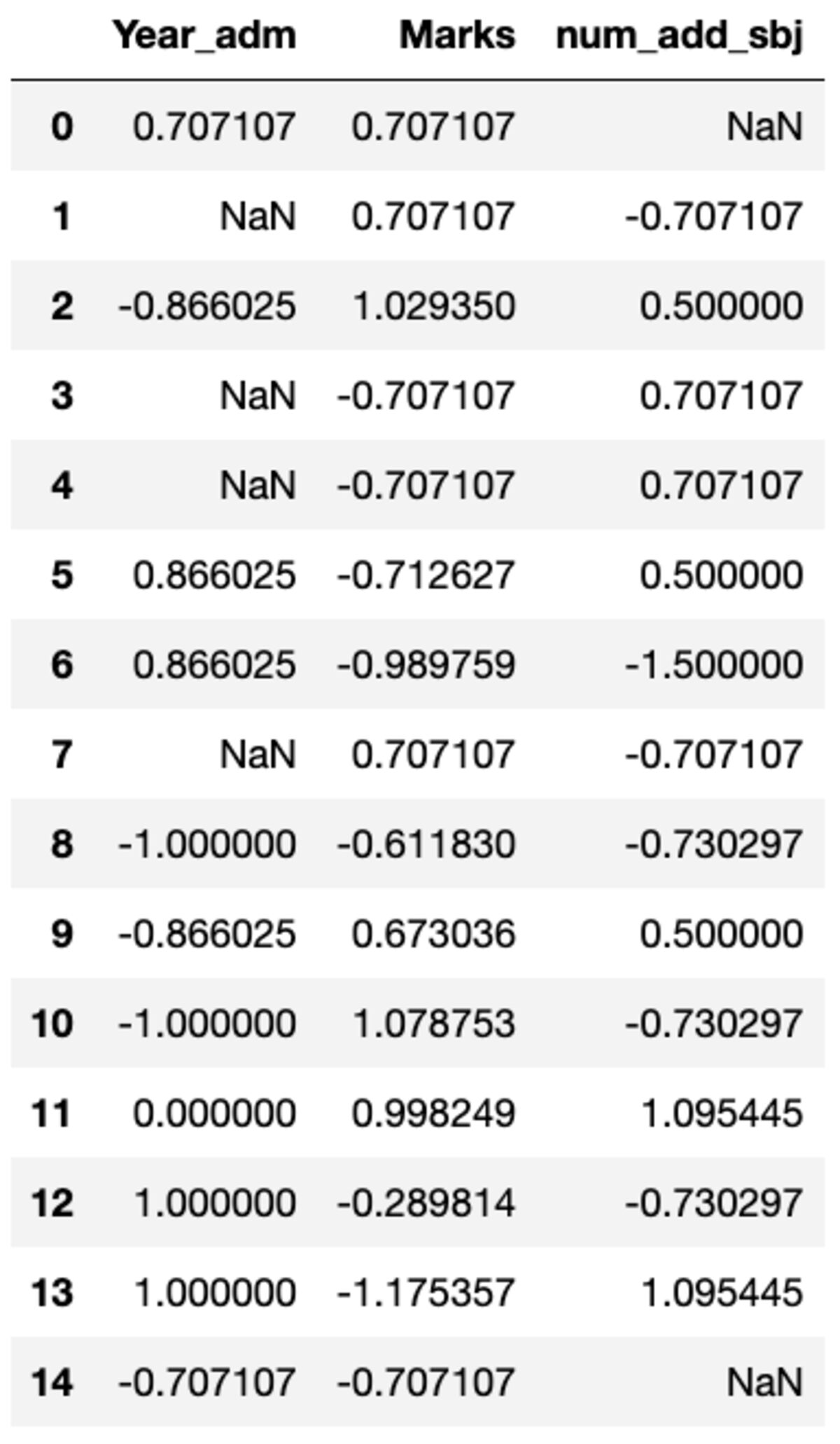
ध्यान दें कि "NaN" शून्य मानक विचलन वाले समूहों का प्रतिनिधित्व करता है।
फ़िल्टर
आप यह जांचना चाह सकते हैं कि कौन सा "मेजर" खराब प्रदर्शन कर रहा है यानी वह जहां औसत छात्र "अंक" 60 से कम हैं। इसके लिए आपको उन समूहों के लिए एक फ़िल्टर विधि लागू करने की आवश्यकता है जिनके अंदर एक फ़ंक्शन है। नीचे दिया गया कोड a का उपयोग करता है भेड़ का बच्चा समारोह फ़िल्टर किए गए परिणाम प्राप्त करने के लिए.
groups.filter(lambda x: x['Marks'].mean() 60)

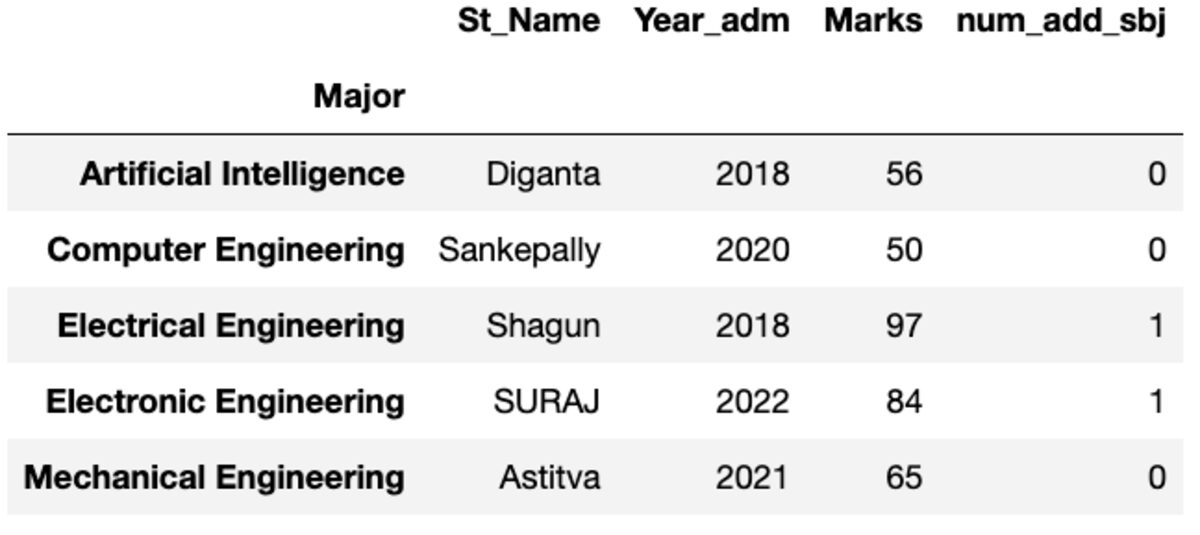
प्रथम
यह आपको सूचकांक द्वारा क्रमबद्ध इसका पहला उदाहरण देता है।
groups.first()
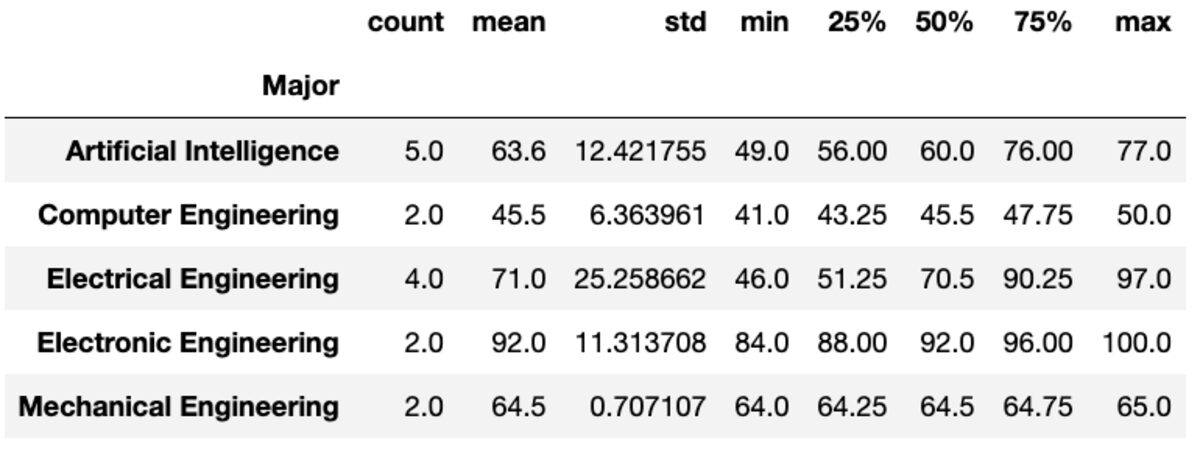
वर्णन करें
"वर्णन" विधि दिए गए कॉलम के लिए गिनती, माध्य, एसटीडी, न्यूनतम, अधिकतम आदि जैसे बुनियादी आँकड़े लौटाती है।
groups['Marks'].describe()
आकार
आकार, जैसा कि नाम से पता चलता है, रिकॉर्ड की संख्या के संदर्भ में प्रत्येक समूह का आकार लौटाता है।
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64काउंट और न्युनिक
"गणना" सभी मान लौटाता है जबकि "नुनिक" उस समूह में केवल अद्वितीय मान लौटाता है।
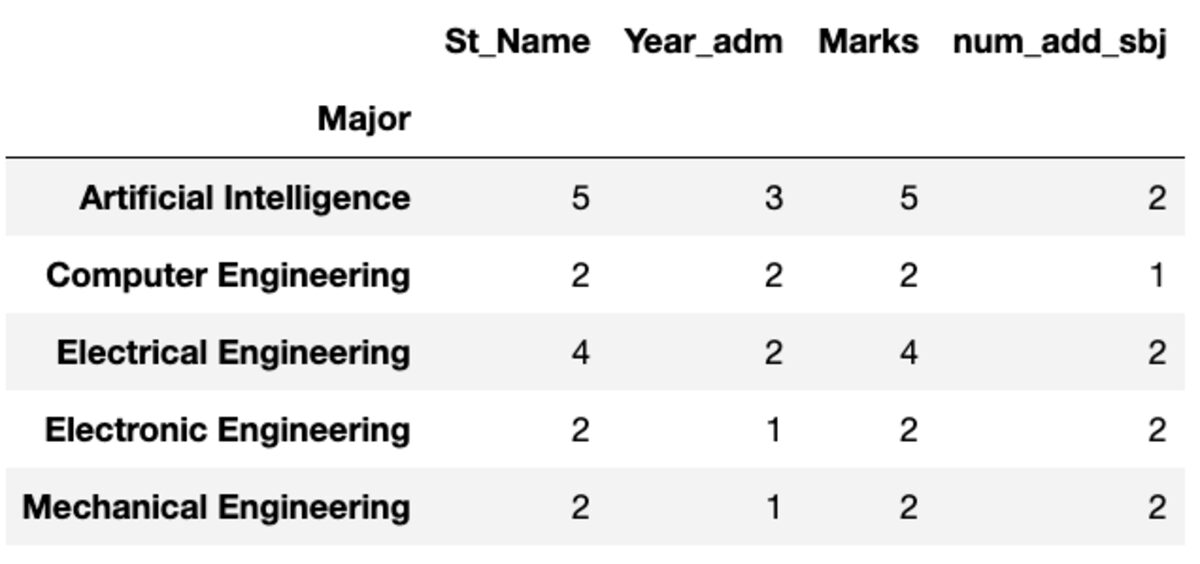
groups.count()
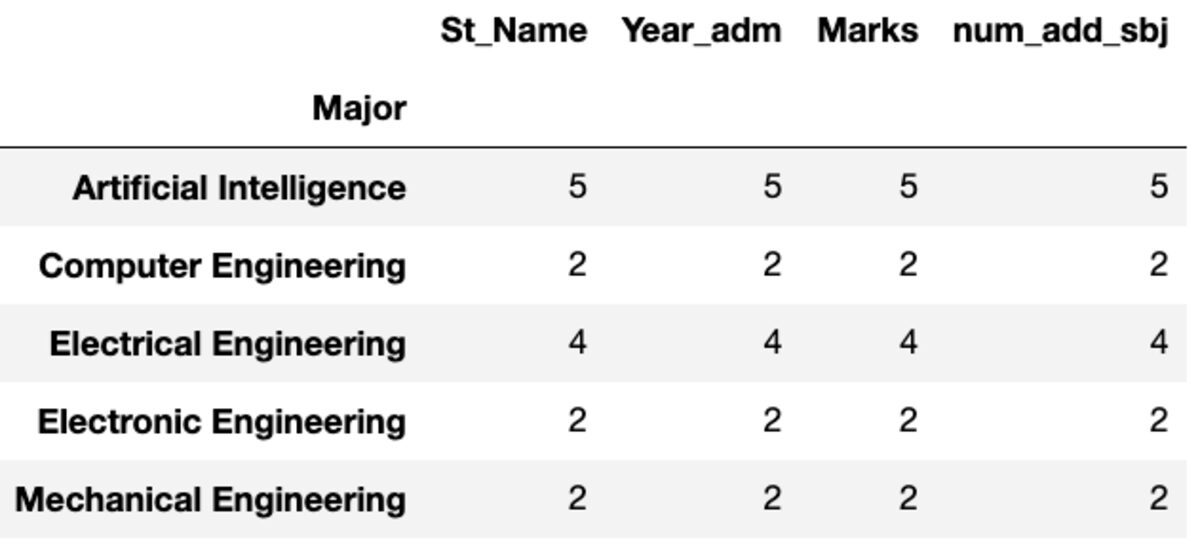
groups.nunique()
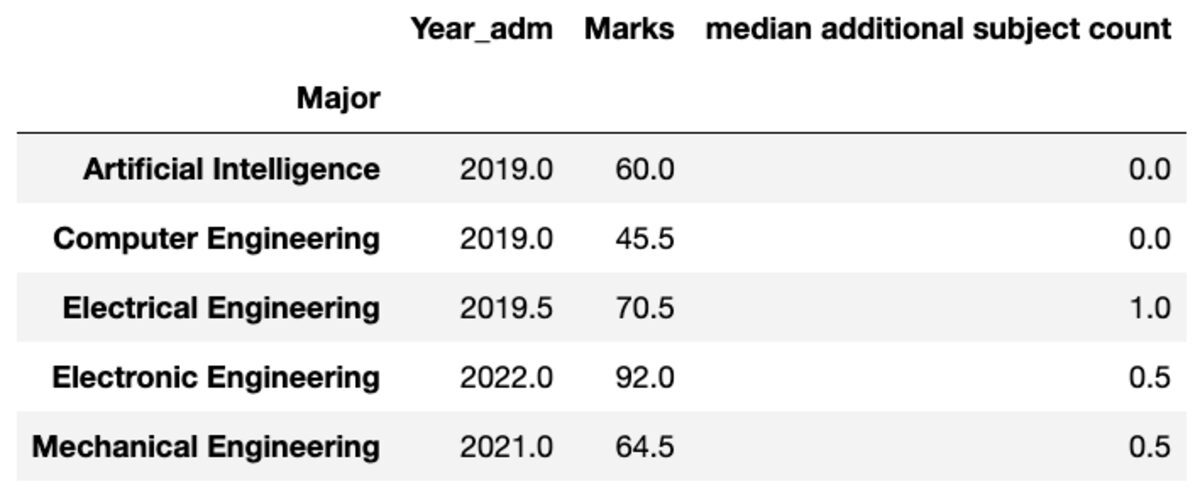
नाम बदलें
आप अपनी पसंद के अनुसार एकत्रित कॉलम का नाम भी बदल सकते हैं।
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- ग्रुपबी के उद्देश्य पर स्पष्ट रहें: क्या आप दूसरे कॉलम का माध्य प्राप्त करने के लिए डेटा को एक कॉलम के आधार पर समूहीकृत करने का प्रयास कर रहे हैं? या क्या आप प्रत्येक समूह में पंक्तियों की गिनती प्राप्त करने के लिए डेटा को कई कॉलमों द्वारा समूहीकृत करने का प्रयास कर रहे हैं?
- डेटा फ़्रेम के अनुक्रमण को समझें: ग्रुपबी फ़ंक्शन डेटा को समूहीकृत करने के लिए इंडेक्स का उपयोग करता है। यदि आप डेटा को एक कॉलम के आधार पर समूहित करना चाहते हैं, तो सुनिश्चित करें कि कॉलम इंडेक्स के रूप में सेट है या आप .set_index() का उपयोग कर सकते हैं
- उपयुक्त समुच्चय फ़ंक्शन का उपयोग करें: इसका उपयोग विभिन्न एकत्रीकरण कार्यों जैसे माध्य (), योग (), गिनती (), न्यूनतम (), अधिकतम () के साथ किया जा सकता है।
- As_index पैरामीटर का उपयोग करें: जब गलत पर सेट किया जाता है, तो यह पैरामीटर पांडा को इंडेक्स के बजाय समूहीकृत कॉलम को नियमित कॉलम के रूप में उपयोग करने के लिए कहता है।
आप अपने डेटा से अधिक जानकारी निकालने के लिए अन्य पांडा फ़ंक्शंस जैसे पिवोट_टेबल(), क्रॉसटैब() और कट() के साथ ग्रुपबी() का भी उपयोग कर सकते हैं।
ग्रुपबाय फ़ंक्शन डेटा विश्लेषण और हेरफेर के लिए एक शक्तिशाली उपकरण है क्योंकि यह आपको एक या अधिक कॉलम के आधार पर डेटा की पंक्तियों को समूहित करने और फिर समूहों पर समग्र गणना करने की अनुमति देता है। ट्यूटोरियल ने कोड उदाहरणों की सहायता से ग्रुपबी फ़ंक्शन का उपयोग करने के विभिन्न तरीकों का प्रदर्शन किया। आशा है कि यह आपको इसके साथ आने वाले विभिन्न विकल्पों की समझ प्रदान करेगा और यह भी बताएगा कि वे डेटा विश्लेषण में कैसे मदद करते हैं।
विधी चुग एक एआई रणनीतिकार और एक डिजिटल परिवर्तन नेता है जो स्केलेबल मशीन लर्निंग सिस्टम बनाने के लिए उत्पाद, विज्ञान और इंजीनियरिंग के चौराहे पर काम कर रहा है। वह एक पुरस्कार विजेता नवाचार नेता, एक लेखक और एक अंतरराष्ट्रीय वक्ता हैं। वह मशीन लर्निंग का लोकतंत्रीकरण करने और इस परिवर्तन का हिस्सा बनने के लिए हर किसी के लिए शब्दजाल को तोड़ने के मिशन पर है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- क्षमता
- योग्य
- पाना
- हासिल
- अतिरिक्त
- इसके अतिरिक्त
- एकत्रीकरण
- AI
- सब
- की अनुमति देता है
- विश्लेषण
- विश्लेषण करें
- और
- अन्य
- लागू
- लागू करें
- लागू
- उपयुक्त
- कृत्रिम
- कृत्रिम बुद्धिमत्ता
- लेखक
- उपलब्ध
- औसत
- पुरस्कार विजेता
- आधारित
- बुनियादी
- नीचे
- जैव प्रौद्योगिकी
- टूटना
- निर्माण
- गणना
- बुला
- मामला
- चेक
- स्पष्ट
- कोड
- स्तंभ
- स्तंभ
- कैसे
- जटिल
- कंप्यूटर
- कंप्यूटर इंजीनियरिंग
- बनाना
- बनाना
- रिवाज
- तिथि
- डेटा विश्लेषण
- डेटासेट
- प्रजातंत्रीय बनाना
- साबित
- विचलन
- विभिन्न
- डिजिटल
- डिजिटल परिवर्तन
- प्रत्यक्ष
- dont
- से प्रत्येक
- आसानी
- प्रभावी रूप से
- इलेक्ट्रिकल इंजीनियरिंग
- इलेक्ट्रोनिक
- अभियांत्रिकी
- आदि
- हर कोई
- उदाहरण
- उदाहरण
- उद्धरण
- गिरना
- विशेषताएं
- भरना
- फ़िल्टर
- खोज
- प्रथम
- फोकस
- निम्नलिखित
- फ्रेम
- से
- समारोह
- कार्यों
- उत्पन्न
- मिल
- दी
- देता है
- जा
- समूह
- समूह की
- हाथों पर
- मदद
- आशा
- कैसे
- How To
- एचटीएमएल
- HTTPS
- आयात
- in
- अविश्वसनीय रूप से
- अनुक्रमणिका
- नवोन्मेष
- अंतर्दृष्टि
- उदाहरण
- बजाय
- बुद्धि
- अंतरराष्ट्रीय स्तर पर
- प्रतिच्छेदन
- IT
- शब्दजाल
- केडनगेट्स
- कुंजी
- बड़ा
- नेता
- जानें
- सीख रहा हूँ
- पुस्तकालयों
- पुस्तकालय
- सूची
- लग रहा है
- मशीन
- यंत्र अधिगम
- प्रमुख
- बनाना
- जोड़ - तोड़
- बहुत
- मैच
- मैक्स
- यांत्रिक
- मैकेनिकल इंजीनियरिंग
- मध्यम
- तरीका
- मिशन
- मॉड्यूल
- अधिक
- विभिन्न
- नाम
- नामों
- आवश्यकता
- अगला
- संख्या
- ONE
- खुला स्रोत
- संचालन
- ऑप्शंस
- अन्य
- पांडा
- प्राचल
- भाग
- विशेष
- पासिंग
- निष्पादन
- गंतव्य
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- शक्तिशाली
- छाप
- एस्ट्रो मॉल
- प्रदान करता है
- उद्देश्य
- अजगर
- जल्दी से
- बिना सोचे समझे
- की सिफारिश की
- अभिलेख
- नियमित
- शेष
- का प्रतिनिधित्व करता है
- की आवश्यकता होती है
- बाकी
- परिणाम
- परिणाम
- वापसी
- रिटर्न
- रिचर्ड
- दौर
- दौड़ना
- वही
- स्केलेबल
- विज्ञान
- सेट
- चाहिए
- दिखाया
- समान
- एक
- आकार
- कुछ
- वक्ता
- विशिष्ट
- मानक
- आँकड़े
- कदम
- रणनीतिज्ञ
- छात्र
- छात्र
- विषय
- पता चलता है
- संक्षेप में प्रस्तुत करना
- सिस्टम
- कार्य
- कार्य
- बताता है
- शर्तों
- RSI
- टाइप
- सेवा मेरे
- साधन
- बदालना
- परिवर्तन
- परिवर्तनों
- ट्यूटोरियल
- प्रकार
- समझ
- अद्वितीय
- उपयोग
- मान
- विभिन्न
- तरीके
- क्या
- कौन कौन से
- मर्जी
- काम कर रहे
- होगा
- X
- वर्ष
- आपका
- जेफिरनेट
- शून्य








