मिडजर्नी के साथ उत्पन्न
2023 से 10 दिसंबर तक जीवंत शहर न्यू ऑरलियन्स में आयोजित न्यूरआईपीएस 16 सम्मेलन में जेनरेटिव एआई और बड़े भाषा मॉडल (एलएलएम) पर विशेष जोर दिया गया था। इस क्षेत्र में हाल की अभूतपूर्व प्रगति के आलोक में, यह कोई आश्चर्य की बात नहीं है कि ये विषय चर्चाओं में हावी रहे।
इस वर्ष के सम्मेलन का एक मुख्य विषय अधिक कुशल एआई सिस्टम की खोज था। शोधकर्ता और डेवलपर्स सक्रिय रूप से एआई के निर्माण के तरीकों की तलाश कर रहे हैं जो न केवल वर्तमान एलएलएम की तुलना में तेजी से सीखता है बल्कि कम कंप्यूटिंग संसाधनों का उपभोग करते हुए उन्नत तर्क क्षमता भी रखता है। आर्टिफिशियल जनरल इंटेलिजेंस (एजीआई) को प्राप्त करने की दौड़ में यह खोज महत्वपूर्ण है, एक ऐसा लक्ष्य जो निकट भविष्य में तेजी से प्राप्य लगता है।
NeurIPS 2023 में आमंत्रित वार्ता इन गतिशील और तेजी से विकसित हो रहे हितों का प्रतिबिंब थी। एआई अनुसंधान के विभिन्न क्षेत्रों के प्रस्तुतकर्ताओं ने अत्याधुनिक एआई विकास में एक खिड़की की पेशकश करते हुए अपनी नवीनतम उपलब्धियों को साझा किया। इस लेख में, हम इन वार्ताओं में गहराई से उतरेंगे, मुख्य निष्कर्षों और सीखों को निकालेंगे और उन पर चर्चा करेंगे, जो एआई नवाचार के वर्तमान और भविष्य के परिदृश्य को समझने के लिए आवश्यक हैं।
नेक्स्टजेनएआई: स्केलिंग का भ्रम और जेनरेटिव एआई का भविष्य
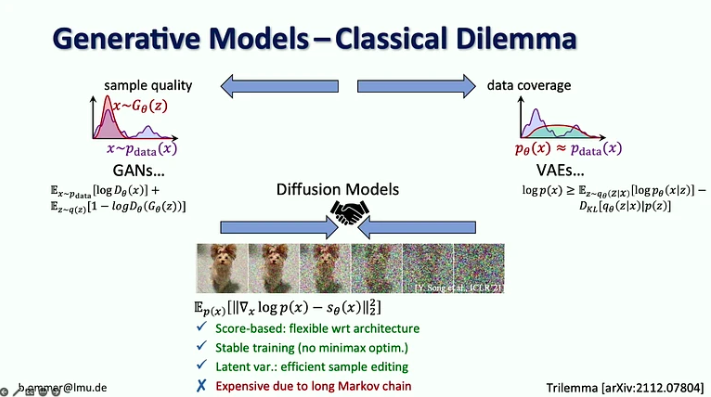
In उसकी बातम्यूनिख के लुडविग मैक्सिमिलियन विश्वविद्यालय में कंप्यूटर विज़न और लर्निंग ग्रुप के प्रमुख ब्योर्न ओमर ने साझा किया कि कैसे उनकी लैब ने स्टेबल डिफ्यूजन विकसित किया, इस प्रक्रिया से उन्होंने कुछ सबक सीखे, और हाल के घटनाक्रम, जिसमें हम डिफ्यूजन मॉडल को कैसे मिश्रित कर सकते हैं, शामिल हैं। प्रवाह मिलान, पुनर्प्राप्ति संवर्द्धन, और LoRA सन्निकटन, आदि।
चाबी छीन लेना:
- जेनरेटिव एआई के युग में, हम दृष्टि मॉडल (यानी, वस्तु पहचान) में धारणा पर ध्यान केंद्रित करने से लेकर लापता भागों (जैसे, प्रसार मॉडल के साथ छवि और वीडियो पीढ़ी) की भविष्यवाणी करने की ओर बढ़ गए हैं।
- 20 वर्षों तक, कंप्यूटर विज़न बेंचमार्क अनुसंधान पर केंद्रित था, जिससे सबसे प्रमुख समस्याओं पर ध्यान केंद्रित करने में मदद मिली। जेनरेटिव एआई में, हमारे पास अनुकूलित करने के लिए कोई बेंचमार्क नहीं है, जिसने हर किसी के लिए अपनी दिशा में जाने का क्षेत्र खोल दिया है।
- डिफ्यूजन मॉडल एक स्थिर प्रशिक्षण प्रक्रिया और कुशल नमूना संपादन के साथ स्कोर-आधारित होने के कारण पिछले जेनरेटिव मॉडल के फायदों को जोड़ते हैं, लेकिन वे अपनी लंबी मार्कोव श्रृंखला के कारण महंगे हैं।
- मजबूत संभावना मॉडल के साथ चुनौती यह है कि अधिकांश बिट्स उन विवरणों में जाते हैं जिन्हें मानव आंख द्वारा मुश्किल से देखा जा सकता है, जबकि शब्दार्थ को एन्कोड करना, जो सबसे अधिक मायने रखता है, केवल कुछ बिट्स लेता है। अकेले स्केलिंग से यह समस्या हल नहीं होगी क्योंकि कंप्यूटिंग संसाधनों की मांग GPU आपूर्ति की तुलना में 9 गुना तेजी से बढ़ रही है।
- सुझाया गया समाधान डिफ्यूजन मॉडल और कन्वनेट्स की ताकत को संयोजित करना है, विशेष रूप से स्थानीय विवरण का प्रतिनिधित्व करने के लिए कनवल्शन की दक्षता और लंबी दूरी के संदर्भ के लिए डिफ्यूजन मॉडल की अभिव्यक्ति।
- ब्योर्न ओमर छोटे अव्यक्त प्रसार मॉडल से उच्च-रिज़ॉल्यूशन छवि संश्लेषण को सक्षम करने के लिए प्रवाह-मिलान दृष्टिकोण का उपयोग करने का भी सुझाव देते हैं।
- छवि संश्लेषण की दक्षता बढ़ाने का एक अन्य तरीका विवरण भरने के लिए पुनर्प्राप्ति वृद्धि का उपयोग करते हुए दृश्य संरचना पर ध्यान केंद्रित करना है।
- अंत में, उन्होंने नियंत्रित स्टोकेस्टिक वीडियो संश्लेषण के लिए आईपोक दृष्टिकोण पेश किया।
यदि यह गहन सामग्री आपके लिए उपयोगी है, हमारी एआई मेलिंग सूची की सदस्यता लें जब हम नई सामग्री जारी करते हैं तो सतर्क रहें।
जिम्मेदार एआई के कई चेहरे
In उसकी प्रस्तुति, गूगल रिसर्च के एक शोध वैज्ञानिक लोरा अरोयो ने पारंपरिक मशीन सीखने के दृष्टिकोण में एक प्रमुख सीमा पर प्रकाश डाला: सकारात्मक या नकारात्मक उदाहरणों के रूप में डेटा के द्विआधारी वर्गीकरण पर उनकी निर्भरता। उन्होंने तर्क दिया कि यह अतिसरलीकरण वास्तविक दुनिया के परिदृश्यों और सामग्री में निहित जटिल व्यक्तिपरकता को नजरअंदाज कर देता है। विभिन्न उपयोग मामलों के माध्यम से, अरोयो ने प्रदर्शित किया कि कैसे सामग्री की अस्पष्टता और मानवीय दृष्टिकोण में प्राकृतिक भिन्नता अक्सर अपरिहार्य असहमति का कारण बनती है। उन्होंने इन असहमतियों को महज शोर के बजाय सार्थक संकेत मानने के महत्व पर जोर दिया।

यहां बातचीत के मुख्य अंश दिए गए हैं:
- मानव श्रम के बीच असहमति उत्पादक हो सकती है। सभी प्रतिक्रियाओं को सही या गलत मानने के बजाय, लोरा अरोयो ने "असहमति द्वारा सत्य" पेश किया, जो रेटर असहमति का उपयोग करके डेटा की विश्वसनीयता का आकलन करने के लिए वितरणात्मक सत्य का एक दृष्टिकोण है।
- विशेषज्ञों के साथ भी डेटा की गुणवत्ता कठिन है क्योंकि विशेषज्ञ भी उतने ही असहमत हैं जितने कि भीड़ के कार्यकर्ता। ये असहमतियां किसी एक विशेषज्ञ की प्रतिक्रियाओं से कहीं अधिक जानकारीपूर्ण हो सकती हैं।
- सुरक्षा मूल्यांकन कार्यों में, विशेषज्ञ 40% उदाहरणों पर असहमत हैं। इन असहमतियों को हल करने की कोशिश करने के बजाय, हमें ऐसे और उदाहरण एकत्र करने और मॉडल और मूल्यांकन मेट्रिक्स को बेहतर बनाने के लिए उनका उपयोग करने की आवश्यकता है।
- लोरा अरोयो ने भी अपनी प्रस्तुति दी विविधता के साथ सुरक्षा इसमें क्या है और इसे किसने एनोटेट किया है, इसके संदर्भ में डेटा की जांच करने की विधि।
- इस पद्धति ने मूल्यांकनकर्ताओं के विभिन्न जनसांख्यिकीय समूहों (कुल 2.5 मिलियन रेटिंग) में एलएलएम सुरक्षा निर्णयों में परिवर्तनशीलता के साथ एक बेंचमार्क डेटासेट तैयार किया।
- 20% वार्तालापों के लिए, यह तय करना मुश्किल था कि चैटबॉट प्रतिक्रिया सुरक्षित या असुरक्षित थी, क्योंकि लगभग समान संख्या में उत्तरदाताओं ने उन्हें सुरक्षित या असुरक्षित के रूप में लेबल किया था।
- मूल्यांकनकर्ताओं और डेटा की विविधता मॉडल के मूल्यांकन में महत्वपूर्ण भूमिका निभाती है। मानवीय दृष्टिकोण की विस्तृत श्रृंखला और सामग्री में मौजूद अस्पष्टता को स्वीकार करने में विफलता वास्तविक दुनिया की अपेक्षाओं के साथ मशीन सीखने के प्रदर्शन के संरेखण में बाधा उत्पन्न कर सकती है।
- एआई सुरक्षा के 80% प्रयास पहले से ही काफी अच्छे हैं, लेकिन शेष 20% में किनारे के मामलों और विविधता के अनंत स्थान के सभी प्रकारों को संबोधित करने के प्रयास को दोगुना करने की आवश्यकता है।
सुसंगत आँकड़े, स्व-निर्मित अनुभव, और युवा मनुष्य वर्तमान एआई की तुलना में अधिक स्मार्ट क्यों हैं
In उसकी बातइंडियाना यूनिवर्सिटी ब्लूमिंगटन की प्रतिष्ठित प्रोफेसर लिंडा स्मिथ ने शिशुओं और छोटे बच्चों की सीखने की प्रक्रियाओं में डेटा विरलता के विषय का पता लगाया। उन्होंने विशेष रूप से वस्तु पहचान और नाम सीखने पर ध्यान केंद्रित किया, इस बात पर ध्यान दिया कि कैसे शिशुओं द्वारा स्व-निर्मित अनुभवों के आँकड़े डेटा विरलता की चुनौती के लिए संभावित समाधान प्रदान करते हैं।
चाबी छीन लेना:
- तीन साल की उम्र तक, बच्चों में विभिन्न क्षेत्रों में एक बार में सीखने की क्षमता विकसित हो जाती है। अपने चौथे जन्मदिन तक 16,000 से भी कम जागने के घंटों में, वे 1,000 से अधिक वस्तु श्रेणियों को सीखने, अपनी मूल भाषा के वाक्यविन्यास में महारत हासिल करने और अपने पर्यावरण की सांस्कृतिक और सामाजिक बारीकियों को आत्मसात करने का प्रबंधन करते हैं।
- डॉ. लिंडा स्मिथ और उनकी टीम ने मानव सीखने के तीन सिद्धांतों की खोज की जो बच्चों को ऐसे विरल डेटा से बहुत कुछ हासिल करने की अनुमति देते हैं:
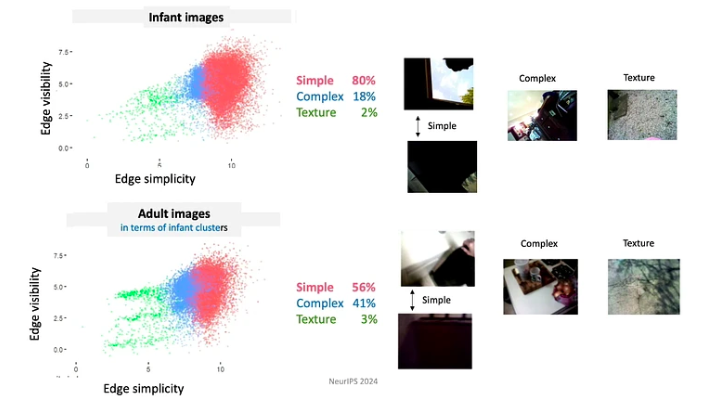
- शिक्षार्थी इनपुट को नियंत्रित करते हैं, पल-पल वे इनपुट को आकार और संरचना दे रहे हैं। उदाहरण के लिए, अपने जीवन के पहले कुछ महीनों के दौरान, बच्चे साधारण किनारों वाली वस्तुओं को अधिक देखते हैं।
- चूँकि बच्चे अपने ज्ञान और क्षमताओं में लगातार विकसित होते रहते हैं, इसलिए वे अत्यधिक सीमित पाठ्यक्रम का पालन करते हैं। जिस डेटा को वे उजागर करते हैं वह गहन रूप से महत्वपूर्ण तरीकों से व्यवस्थित होता है। उदाहरण के लिए, 4 महीने से कम उम्र के बच्चे चेहरे को देखने में सबसे अधिक समय बिताते हैं, प्रति घंटे लगभग 15 मिनट, जबकि 12 महीने से अधिक उम्र के बच्चे मुख्य रूप से हाथों पर ध्यान केंद्रित करते हैं, प्रति घंटे लगभग 20 मिनट तक उनका निरीक्षण करते हैं।
- सीखने के एपिसोड में परस्पर जुड़े अनुभवों की एक श्रृंखला शामिल होती है। स्थानिक और लौकिक सहसंबंध सुसंगतता पैदा करते हैं, जो बदले में एक बार की घटनाओं से स्थायी यादों के निर्माण की सुविधा प्रदान करते हैं। उदाहरण के लिए, जब बच्चों को खिलौनों का बेतरतीब वर्गीकरण प्रस्तुत किया जाता है, तो वे अक्सर कुछ 'पसंदीदा' खिलौनों पर ध्यान केंद्रित करते हैं। वे दोहराए गए पैटर्न का उपयोग करके इन खिलौनों से जुड़ते हैं, जो वस्तुओं को तेजी से सीखने में सहायता करता है।
- क्षणिक (कार्यशील) यादें संवेदी इनपुट की तुलना में अधिक समय तक बनी रहती हैं। सीखने की प्रक्रिया को बढ़ाने वाले गुणों में मल्टीमॉडलिटी, एसोसिएशन, पूर्वानुमानित संबंध और पिछली यादों की सक्रियता शामिल हैं।
- तेजी से सीखने के लिए, आपको डेटा उत्पन्न करने वाले तंत्र और सीखने वाले तंत्र के बीच गठबंधन की आवश्यकता होती है।
स्केचिंग: मुख्य उपकरण, सीखना-वृद्धि, और अनुकूली मजबूती
जेलानी नेल्सन, यूसी बर्कले में इलेक्ट्रिकल इंजीनियरिंग और कंप्यूटर विज्ञान के प्रोफेसर, डेटा 'स्केच' की अवधारणा पेश की - डेटासेट का मेमोरी-संपीड़ित प्रतिनिधित्व जो अभी भी उपयोगी प्रश्नों का उत्तर देने में सक्षम बनाता है। हालाँकि यह बातचीत काफी तकनीकी थी, इसने हाल की प्रगति सहित कुछ बुनियादी स्केचिंग टूल का उत्कृष्ट अवलोकन प्रदान किया।
मुख्य बातें:
- काउंटस्केच, कोर स्केचिंग टूल, पहली बार 2002 में 'हेवी हिटर्स' की समस्या का समाधान करने के लिए पेश किया गया था, जो आइटमों की दी गई स्ट्रीम से सबसे अधिक बार आने वाली वस्तुओं की एक छोटी सूची की रिपोर्ट करता था। काउंटस्केच इस उद्देश्य के लिए उपयोग किया जाने वाला पहला ज्ञात सबलाइनर एल्गोरिदम था।
- हेवी हिटर्स के दो गैर-स्ट्रीमिंग अनुप्रयोगों में शामिल हैं:
- आंतरिक बिंदु-आधारित विधि (आईपीएम) जो रैखिक प्रोग्रामिंग के लिए एक स्पर्शोन्मुख रूप से सबसे तेज़ ज्ञात एल्गोरिदम देती है।
- हाइपरअटेंशन विधि जो एलएलएम में उपयोग किए जाने वाले लंबे संदर्भों की बढ़ती जटिलता से उत्पन्न कम्प्यूटेशनल चुनौती को संबोधित करती है।
- हाल का अधिकांश कार्य ऐसे रेखाचित्रों को डिज़ाइन करने पर केंद्रित रहा है जो अनुकूली अंतःक्रिया के लिए मजबूत हों। मुख्य विचार अनुकूली डेटा विश्लेषण से अंतर्दृष्टि का उपयोग करना है।
स्केलिंग पैनल से परे
इस बड़े भाषा मॉडल पर शानदार पैनल कॉर्नेल टेक के एसोसिएट प्रोफेसर और हगिंग फेस के शोधकर्ता अलेक्जेंडर रश द्वारा संचालित किया गया था। अन्य प्रतिभागियों में शामिल हैं:
- आकांक्षा चौधरी - सिस्टम, एलएलएम प्रीट्रेनिंग और मल्टीमॉडलिटी में अनुसंधान रुचि के साथ Google डीपमाइंड में अनुसंधान वैज्ञानिक। वह PaLM, जेमिनी और पाथवे विकसित करने वाली टीम का हिस्सा थीं।
- एंजेला फैन - मेटा जेनेरेटिव एआई में अनुसंधान वैज्ञानिक, संरेखण, डेटा केंद्र और बहुभाषीता में अनुसंधान रुचि के साथ। उन्होंने लामा-2 और मेटा एआई असिस्टेंट के विकास में भाग लिया।
- पर्सी लियांग - स्टैनफोर्ड में प्रोफेसर, क्रिएटर्स, ओपन सोर्स और जेनरेटिव एजेंटों पर शोध कर रहे हैं। वह स्टैनफोर्ड में सेंटर फॉर रिसर्च ऑन फाउंडेशन मॉडल्स (सीआरएफएम) के निदेशक और टुगेदर एआई के संस्थापक हैं।
चर्चा चार प्रमुख विषयों पर केंद्रित थी: (1) वास्तुकला और इंजीनियरिंग, (2) डेटा और संरेखण, (3) मूल्यांकन और पारदर्शिता, और (4) निर्माता और योगदानकर्ता।
इस पैनल से कुछ निष्कर्ष इस प्रकार हैं:
- वर्तमान भाषा मॉडल का प्रशिक्षण स्वाभाविक रूप से कठिन नहीं है। लामा-2-7बी जैसे मॉडल को प्रशिक्षित करने में मुख्य चुनौती बुनियादी ढांचे की आवश्यकताओं और कई जीपीयू, डेटा केंद्रों आदि के बीच समन्वय की आवश्यकता में निहित है। हालांकि, यदि मापदंडों की संख्या इतनी छोटी है कि एक ही जीपीयू पर प्रशिक्षण की अनुमति दी जा सकती है, यहां तक कि एक स्नातक भी इसे प्रबंधित कर सकता है।
- जबकि ऑटोरेग्रेसिव मॉडल का उपयोग आमतौर पर पाठ निर्माण और छवियों और वीडियो बनाने के लिए प्रसार मॉडल के लिए किया जाता है, इन दृष्टिकोणों को उलटने के प्रयोग भी किए गए हैं। विशेष रूप से, जेमिनी प्रोजेक्ट में, छवि निर्माण के लिए एक ऑटोरेग्रेसिव मॉडल का उपयोग किया जाता है। पाठ निर्माण के लिए प्रसार मॉडल का उपयोग करने की भी खोज की गई है, लेकिन ये अभी तक पर्याप्त रूप से प्रभावी साबित नहीं हुए हैं।
- प्रशिक्षण मॉडल के लिए अंग्रेजी-भाषा डेटा की सीमित उपलब्धता को देखते हुए, शोधकर्ता वैकल्पिक दृष्टिकोण तलाश रहे हैं। एक संभावना पाठ, वीडियो, छवियों और ऑडियो के संयोजन पर मल्टीमॉडल मॉडल को प्रशिक्षित करना है, इस उम्मीद के साथ कि इन वैकल्पिक तौर-तरीकों से सीखे गए कौशल पाठ में स्थानांतरित हो सकते हैं। दूसरा विकल्प सिंथेटिक डेटा का उपयोग है. यह ध्यान रखना महत्वपूर्ण है कि सिंथेटिक डेटा अक्सर वास्तविक डेटा में मिश्रित हो जाता है, लेकिन यह एकीकरण यादृच्छिक नहीं है। ऑनलाइन प्रकाशित पाठ आम तौर पर मानव क्यूरेशन और संपादन से गुजरता है, जो मॉडल प्रशिक्षण के लिए अतिरिक्त मूल्य जोड़ सकता है।
- ओपन फाउंडेशन मॉडल को अक्सर नवाचार के लिए फायदेमंद माना जाता है, लेकिन एआई सुरक्षा के लिए संभावित रूप से हानिकारक होता है, क्योंकि दुर्भावनापूर्ण अभिनेताओं द्वारा उनका शोषण किया जा सकता है। हालाँकि, डॉ. पर्सी लियांग का तर्क है कि खुले मॉडल भी सुरक्षा में सकारात्मक योगदान देते हैं। उनका तर्क है कि सुलभ होने से, वे अधिक शोधकर्ताओं को एआई सुरक्षा अनुसंधान करने और संभावित कमजोरियों के लिए मॉडल की समीक्षा करने के अवसर प्रदान करते हैं।
- आज, डेटा एनोटेट करने के लिए पांच साल पहले की तुलना में एनोटेशन डोमेन में काफी अधिक विशेषज्ञता की आवश्यकता होती है। हालाँकि, यदि एआई सहायक भविष्य में अपेक्षा के अनुरूप प्रदर्शन करते हैं, तो हमें उपयोगकर्ताओं से अधिक मूल्यवान फीडबैक डेटा प्राप्त होगा, जिससे एनोटेटर्स के व्यापक डेटा पर निर्भरता कम हो जाएगी।
फ़ाउंडेशन मॉडल के लिए सिस्टम, और सिस्टम के लिए फ़ाउंडेशन मॉडल
In ये बातस्टैनफोर्ड विश्वविद्यालय में कंप्यूटर विज्ञान विभाग में एसोसिएट प्रोफेसर क्रिस्टोफर रे बताते हैं कि फाउंडेशन मॉडल ने हमारे द्वारा बनाए गए सिस्टम को कैसे बदल दिया। वह यह भी पता लगाता है कि डेटाबेस सिस्टम अनुसंधान से अंतर्दृष्टि उधार लेते हुए, फाउंडेशन मॉडल को कुशलतापूर्वक कैसे बनाया जाए, और ट्रांसफार्मर की तुलना में फाउंडेशन मॉडल के लिए संभावित रूप से अधिक कुशल आर्किटेक्चर पर चर्चा की जाती है।
इस बातचीत के मुख्य अंश इस प्रकार हैं:
- फाउंडेशन मॉडल '1000 कटौती से मौत' की समस्याओं को संबोधित करने में प्रभावी हैं, जहां प्रत्येक व्यक्तिगत कार्य अपेक्षाकृत सरल हो सकता है, लेकिन कार्यों की व्यापकता और विविधता एक महत्वपूर्ण चुनौती पेश करती है। इसका एक अच्छा उदाहरण डेटा सफाई समस्या है, जिसे एलएलएम अब अधिक कुशलता से हल करने में मदद कर सकता है।
- जैसे-जैसे त्वरक तेज़ होते जाते हैं, स्मृति अक्सर एक बाधा के रूप में उभरती है। यह एक ऐसी समस्या है जिसे डेटाबेस शोधकर्ता दशकों से संबोधित कर रहे हैं, और हम उनकी कुछ रणनीतियों को अपना सकते हैं। उदाहरण के लिए, फ्लैश अटेंशन दृष्टिकोण अवरोधन और आक्रामक संलयन के माध्यम से इनपुट-आउटपुट प्रवाह को कम करता है: जब भी हम जानकारी के एक टुकड़े तक पहुंचते हैं, तो हम उस पर यथासंभव अधिक से अधिक ऑपरेशन करते हैं।
- सिग्नल प्रोसेसिंग में निहित आर्किटेक्चर का एक नया वर्ग है, जो ट्रांसफॉर्मर मॉडल की तुलना में अधिक कुशल हो सकता है, खासकर लंबे अनुक्रमों को संभालने में। सिग्नल प्रोसेसिंग स्थिरता और दक्षता प्रदान करती है, जो S4 जैसे नवीन मॉडलों की नींव रखती है।
डिजिटल स्वास्थ्य हस्तक्षेपों में ऑनलाइन सुदृढीकरण सीखना
In उसकी बातहार्वर्ड विश्वविद्यालय में सांख्यिकी और कंप्यूटर विज्ञान के प्रोफेसर सुसान मर्फी ने डिजिटल स्वास्थ्य हस्तक्षेपों में उपयोग के लिए ऑनलाइन आरएल एल्गोरिदम विकसित करने में आने वाली कुछ चुनौतियों का पहला समाधान साझा किया।
प्रस्तुतीकरण से कुछ अंश इस प्रकार हैं:
- डॉ. सुसान मर्फी ने दो परियोजनाओं पर चर्चा की जिन पर वह काम कर रही हैं:
- हार्टस्टेप, जहां स्मार्टफोन और पहनने योग्य ट्रैकर्स के डेटा के आधार पर गतिविधियों का सुझाव दिया गया है, और
- मौखिक स्वास्थ्य कोचिंग के लिए ओरलिटिक्स, जहां हस्तक्षेप इलेक्ट्रॉनिक टूथब्रश से प्राप्त जुड़ाव डेटा पर आधारित थे।
- एआई एजेंट के लिए एक व्यवहार नीति विकसित करने में, शोधकर्ताओं को यह सुनिश्चित करना होगा कि यह स्वायत्त है और इसे व्यापक स्वास्थ्य देखभाल प्रणाली में लागू किया जा सकता है। इसमें यह सुनिश्चित करना शामिल है कि किसी व्यक्ति की भागीदारी के लिए आवश्यक समय उचित है, और अनुशंसित कार्य नैतिक रूप से उचित और वैज्ञानिक रूप से प्रशंसनीय हैं।
- डिजिटल स्वास्थ्य हस्तक्षेपों के लिए आरएल एजेंट विकसित करने में प्राथमिक चुनौतियों में उच्च शोर के स्तर से निपटना शामिल है, क्योंकि लोग अपना जीवन जीते हैं और हमेशा संदेशों का जवाब देने में सक्षम नहीं हो सकते हैं, भले ही वे चाहें, साथ ही मजबूत, विलंबित नकारात्मक प्रभावों का प्रबंधन भी कर सकते हैं। .
जैसा कि आप देख सकते हैं, NeurIPS 2023 ने AI के भविष्य की एक रोशन झलक प्रदान की है। आमंत्रित वार्ता में अधिक कुशल, संसाधन-सचेत मॉडल और पारंपरिक प्रतिमानों से परे नवीन वास्तुकला की खोज की प्रवृत्ति पर प्रकाश डाला गया।
इस लेख का आनंद लें? अधिक AI अनुसंधान अपडेट के लिए साइन अप करें।
जब हम इस तरह के और अधिक सारांश लेख जारी करते हैं तो हम आपको बताएंगे।
सम्बंधित
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.topbots.com/neurips-2023-invited-talks/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 000
- 1
- 10
- 10th
- 11
- 110
- 12
- 12 महीने
- 125
- 13
- 14
- 15% तक
- 154
- 16
- 16th
- 17
- 20
- 20 साल
- 2023
- 32
- 35% तक
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- क्षमता
- योग्य
- About
- त्वरक
- पहुँच
- सुलभ
- उपलब्धियों
- प्राप्त करने
- स्वीकार करना
- के पार
- कार्रवाई
- सक्रियण
- सक्रिय रूप से
- गतिविधियों
- अभिनेताओं
- अनुकूली
- जोड़ना
- अतिरिक्त
- पता
- पतों
- को संबोधित
- अपनाना
- प्रगति
- फायदे
- उम्र
- एजेंट
- एजेंटों
- आक्रामक
- आंदोलन
- पूर्व
- AI
- एआई सहायक
- ai शोध
- एआई सिस्टम
- एड्स
- अलेक्जेंडर
- कलन विधि
- एल्गोरिदम
- संरेखण
- सब
- संधि
- अनुमति देना
- अकेला
- पहले ही
- भी
- वैकल्पिक
- हालांकि
- हमेशा
- अस्पष्टता
- के बीच में
- an
- विश्लेषण
- और
- अन्य
- कोई
- अनुप्रयोगों
- दृष्टिकोण
- दृष्टिकोण
- लगभग
- हैं
- तर्क दिया
- तर्क
- लेख
- लेख
- कृत्रिम
- कृत्रिम सामान्य बुद्धि
- AS
- आकलन
- सहायक
- सहायकों
- सहयोगी
- संघों
- वर्गीकरण
- At
- प्राप्य
- ध्यान
- ऑडियो
- स्वायत्त
- उपलब्धता
- आधारित
- BE
- क्योंकि
- बन
- किया गया
- व्यवहार
- जा रहा है
- बेंचमार्क
- मानक
- लाभदायक
- बर्कले
- के बीच
- परे
- मिश्रण
- मिश्रणों
- ब्लॉकिंग
- उधार
- के छात्रों
- चौड़ाई
- व्यापक
- निर्माण
- लेकिन
- by
- आया
- कर सकते हैं
- क्षमताओं
- कब्जा
- मामलों
- श्रेणियाँ
- केंद्र
- केंद्र
- श्रृंखला
- चुनौती
- चुनौतियों
- बदल
- chatbot
- बच्चे
- क्रिस्टोफर
- City
- कक्षा
- सफाई
- कोचिंग
- इकट्ठा
- संयोजन
- गठबंधन
- तुलना
- जटिल
- जटिलता
- रचना
- कम्प्यूटेशनल
- कंप्यूटर
- कम्प्यूटर साइंस
- Computer Vision
- कंप्यूटिंग
- संकल्पना
- आचरण
- सम्मेलन
- निर्माण
- सामग्री
- प्रसंग
- संदर्भों
- लगातार
- योगदान
- योगदानकर्ताओं
- नियंत्रण
- नियंत्रित
- बातचीत
- समन्वय
- मूल
- कॉर्नेल
- सही
- सहसंबंध
- सका
- बनाना
- रचनाकारों
- भीड़
- महत्वपूर्ण
- सांस्कृतिक
- क्यूरेशन
- वर्तमान
- पाठ्यचर्या
- अग्रणी
- तिथि
- डेटा विश्लेषण
- डेटा केन्द्रों
- डाटाबेस
- व्यवहार
- दशकों
- दिसंबर
- तय
- Deepmind
- विलंबित
- गड्ढा
- मांग
- मांग
- जनसांख्यिकीय
- साबित
- विभाग
- डिज़ाइन बनाना
- विस्तार
- विवरण
- विकसित करना
- विकसित
- डेवलपर्स
- विकासशील
- विकास
- के घटनाक्रम
- मुश्किल
- प्रसार
- डिजिटल
- डिजिटल स्वास्थ्य
- दिशा
- निदेशक
- की खोज
- चर्चा की
- पर चर्चा
- चर्चा
- विचार - विमर्श
- विशिष्ट
- विविधता
- डोमेन
- डोमेन
- बोलबाला
- dont
- दोहरीकरण
- dr
- दो
- दौरान
- गतिशील
- e
- से प्रत्येक
- Edge
- संपादन
- प्रभावी
- प्रभाव
- दक्षता
- कुशल
- कुशलता
- प्रयास
- प्रयासों
- भी
- इलेक्ट्रिकल इंजीनियरिंग
- इलेक्ट्रोनिक
- उभर रहे हैं
- जोर
- पर बल दिया
- सक्षम
- सक्षम बनाता है
- एन्कोडिंग
- लगाना
- सगाई
- अभियांत्रिकी
- बढ़ाना
- वर्धित
- पर्याप्त
- सुनिश्चित
- सुनिश्चित
- वातावरण
- एपिसोड
- बराबर
- विशेष रूप से
- आवश्यक
- आदि
- ईथर (ईटीएच)
- का मूल्यांकन
- मूल्यांकन
- और भी
- घटनाओं
- हर कोई
- विकसित करना
- उद्विकासी
- उदाहरण
- उदाहरण
- उत्कृष्ट
- उम्मीद
- उम्मीदों
- अपेक्षित
- महंगा
- अनुभव
- अनुभव
- प्रयोगों
- विशेषज्ञ
- विशेषज्ञता
- विशेषज्ञों
- शोषित
- अन्वेषण
- पता लगाया
- पड़ताल
- तलाश
- उजागर
- व्यापक
- आंख
- चेहरा
- चेहरे के
- की सुविधा
- में नाकाम रहने
- प्रशंसक
- और तेज
- सबसे तेजी से
- प्रतिक्रिया
- कुछ
- कम
- खेत
- भरना
- प्रथम
- पांच
- फ़्लैश
- प्रवाह
- प्रवाह
- फोकस
- ध्यान केंद्रित
- का पालन करें
- के लिए
- निकट
- निर्माण
- बुनियाद
- संस्थापक
- चार
- चौथा
- बारंबार
- अक्सर
- से
- मौलिक
- संलयन
- भविष्य
- एअर इंडिया का भविष्य
- मिथुन राशि
- सामान्य जानकारी
- सामान्य बुद्धि
- उत्पन्न
- सृजन
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- दी
- देता है
- झलक
- Go
- लक्ष्य
- अच्छा
- गूगल
- GPU
- GPUs
- अभूतपूर्व
- समूह
- समूह की
- बढ़ रहा है
- था
- हैंडलिंग
- हाथ
- हानिकारक
- दोहन
- हावर्ड
- हार्वर्ड विश्वविद्यालय
- है
- he
- सिर
- स्वास्थ्य
- स्वास्थ्य सेवा
- mmmmm
- धारित
- मदद
- मदद की
- उसे
- हाई
- उच्च संकल्प
- हाइलाइट
- अत्यधिक
- बाधा पहुंचाना
- उसके
- घंटा
- घंटे
- कैसे
- How To
- तथापि
- http
- HTTPS
- मानव
- मनुष्य
- i
- विचार
- if
- रोशन
- की छवि
- छवि निर्माण
- छवियों
- कार्यान्वित
- महत्व
- महत्वपूर्ण
- में सुधार
- in
- में गहराई
- शामिल
- शामिल
- सहित
- बढ़ती
- तेजी
- इंडियाना
- व्यक्ति
- अपरिहार्य
- करें-
- जानकारीपूर्ण
- इंफ्रास्ट्रक्चर
- निहित
- स्वाभाविक
- नवोन्मेष
- अभिनव
- निवेश
- अंतर्दृष्टि
- उदाहरण
- बजाय
- एकीकरण
- बुद्धि
- बातचीत
- परस्पर
- रुचियों
- हस्तक्षेपों
- में
- शुरू की
- आमंत्रित
- IT
- आइटम
- जेपीजी
- निर्णय
- कुंजी
- जानना
- ज्ञान
- जानने वाला
- प्रयोगशाला
- लेबलिंग
- भाषा
- बड़ा
- स्थायी
- ताज़ा
- बिछाने
- नेतृत्व
- प्रमुख
- जानें
- सीखा
- शिक्षार्थियों
- सीख रहा हूँ
- विरासत
- कम
- पाठ
- चलो
- स्तर
- झूठ
- प्रकाश
- पसंद
- संभावना
- सीमा
- सीमित
- लिंडा
- सूची
- लाइव्स
- स्थानीय
- लंबा
- लंबे समय तक
- देखिए
- देख
- मशीन
- यंत्र अधिगम
- मेलिंग
- मुख्य
- प्रबंधन
- प्रबंध
- बहुत
- मास्टर
- मिलान
- सामग्री
- मैटर्स
- अधिकतम-चौड़ाई
- मई..
- सार्थक
- तंत्र
- -K-on (ITS MY FAVORITE ANIME!)
- याद
- mers
- संदेश
- मेटा
- तरीका
- मेट्रिक्स
- हो सकता है
- दस लाख
- कम करता है
- मिनट
- लापता
- तौर-तरीकों
- आदर्श
- मॉडल
- पल
- महीने
- अधिक
- अधिक कुशल
- अधिकांश
- ले जाया गया
- बहुत
- विभिन्न
- म्यूनिख
- चाहिए
- नाम
- देशी
- प्राकृतिक
- आवश्यकता
- नकारात्मक
- न्यूरिप्स
- नया
- न्यू ऑर्लेअंस
- नहीं
- शोर
- कोई नहीं
- नोट
- उपन्यास
- अभी
- लकीर खींचने की क्रिया
- संख्या
- वस्तु
- वस्तुओं
- of
- प्रस्ताव
- की पेशकश
- ऑफर
- अक्सर
- बड़े
- on
- ONE
- ऑनलाइन
- केवल
- खुला
- खुला स्रोत
- खोला
- संचालन
- अवसर
- ऑप्टिमाइज़ करें
- विकल्प
- or
- मौखिक
- मौखिक स्वास्थ्य
- संगठित
- ऑरलियन्स
- अन्य
- अन्य प्रतिभागियों
- अन्य
- हमारी
- के ऊपर
- सिंहावलोकन
- अपना
- ताड़
- पैनल
- उदाहरण
- पैरामीटर
- भाग
- प्रतिभागियों
- भाग लिया
- विशेष
- विशेष रूप से
- भागों
- अतीत
- रास्ते
- पैटर्न उपयोग करें
- स्टाफ़
- प्रति
- धारणा
- निष्पादन
- प्रदर्शन
- दृष्टिकोण
- टुकड़ा
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्रशंसनीय
- निभाता
- नीति
- उत्पन्न
- सकारात्मक
- सकारात्मक
- के पास
- संभावना
- संभव
- संभावित
- संभावित
- की भविष्यवाणी
- भविष्य कहनेवाला
- वर्तमान
- प्रदर्शन
- प्रस्तुत
- पिछला
- मुख्यत
- प्राथमिक
- सिद्धांतों
- मुसीबत
- समस्याओं
- प्रक्रिया
- प्रक्रिया
- प्रक्रियाओं
- प्रसंस्करण
- प्रस्तुत
- उत्पादक
- प्रोफेसर
- गंभीरतापूर्वक
- प्रोग्रामिंग
- परियोजना
- परियोजनाओं
- प्रसिद्ध
- गुण
- साबित
- प्रदान करना
- बशर्ते
- प्रकाशित
- उद्देश्य
- पीछा
- गुणवत्ता
- प्रश्नों
- खोज
- बिल्कुल
- दौड़
- बिना सोचे समझे
- रेंज
- उपवास
- तेजी
- बल्कि
- रेटिंग
- वास्तविक
- असली दुनिया
- उचित
- प्राप्त करना
- प्राप्त
- हाल
- मान्यता
- की सिफारिश की
- को कम करने
- प्रतिबिंब
- सुदृढीकरण सीखना
- संबंधों
- अपेक्षाकृत
- और
- विश्वसनीयता
- रिलायंस
- शेष
- बार - बार आने वाला
- रिपोर्टिंग
- प्रतिनिधित्व
- का प्रतिनिधित्व
- की आवश्यकता होती है
- अपेक्षित
- आवश्यकताएँ
- अनुसंधान
- शोधकर्ता
- शोधकर्ताओं
- संकल्प
- उपयुक्त संसाधन चुनें
- प्रतिक्रिया
- उत्तरदाताओं
- प्रतिक्रिया
- प्रतिक्रियाएं
- जिम्मेदार
- की समीक्षा
- मजबूत
- भूमिका
- जड़ें
- लगभग
- भीड़
- सुरक्षित
- सुरक्षा
- स्केलिंग
- परिदृश्यों
- दृश्य
- विज्ञान
- विज्ञान
- वैज्ञानिक
- देखना
- मांग
- लगता है
- देखा
- अर्थ विज्ञान
- कई
- आकार देने
- साझा
- वह
- दिखाता है
- हस्ताक्षर
- संकेत
- संकेत
- महत्वपूर्ण
- काफी
- सरल
- एक
- कौशल
- छोटा
- होशियार
- smartphones के
- स्मिथ
- So
- सोशल मीडिया
- समाधान
- समाधान ढूंढे
- हल
- कुछ
- ध्वनि
- स्रोत
- अंतरिक्ष
- स्थानिक
- विशेष रूप से
- बिताना
- स्थिरता
- स्थिर
- स्टैनफोर्ड
- स्टैनफोर्ड विश्वविद्यालय
- आँकड़े
- फिर भी
- रणनीतियों
- धारा
- ताकत
- मजबूत
- संरचना
- ऐसा
- पता चलता है
- सारांश
- आपूर्ति
- आश्चर्य
- सुसान
- वाक्यविन्यास
- संश्लेषण
- कृत्रिम
- सिंथेटिक डेटा
- प्रणाली
- सिस्टम
- Takeaways
- लेता है
- बातचीत
- बाते
- कार्य
- कार्य
- टीम
- तकनीक
- तकनीकी
- करते हैं
- शर्तों
- टेक्स्ट
- पाठ पीढ़ी
- से
- कि
- RSI
- भविष्य
- लेकिन हाल ही
- उन
- विषयों
- वहाँ।
- इन
- वे
- इसका
- उन
- तीन
- यहाँ
- पहर
- सेवा मेरे
- एक साथ
- साधन
- उपकरण
- टॉपबॉट्स
- विषय
- विषय
- कुल
- की ओर
- ट्रैकर्स
- परंपरागत
- प्रशिक्षण
- स्थानांतरण
- ट्रांसफार्मर
- ट्रांसपेरेंसी
- इलाज
- प्रवृत्ति
- सच
- की कोशिश कर रहा
- मोड़
- दो
- आम तौर पर
- के अंतर्गत
- से होकर गुजरती है
- समझ
- विश्वविद्यालय
- अपडेट
- उपयोग
- प्रयुक्त
- उपयोगकर्ताओं
- का उपयोग
- आमतौर पर
- उपयोग किया
- मूल्यवान
- मूल्य
- विविधता
- विभिन्न
- जीवंत
- वीडियो
- वीडियो
- दृष्टिकोण
- दृष्टि
- कमजोरियों
- W3
- था
- तरीके
- we
- पहनने योग्य
- कुंआ
- थे
- क्या
- कब
- जब कभी
- जहाँ तक
- या
- कौन कौन से
- जब
- कौन
- क्यों
- चौड़ा
- विस्तृत श्रृंखला
- मर्जी
- खिड़की
- साथ में
- काम
- काम कर रहे
- गलत
- साल
- अभी तक
- इसलिए आप
- युवा
- जेफिरनेट