लेखक द्वारा छवि
कई उन्नत मशीन लर्निंग मॉडल जैसे रैंडम फ़ॉरेस्ट या ग्रेडिएंट बूस्टिंग एल्गोरिदम जैसे XGBoost, CatBoost, या LightGBM (और यहां तक कि) ऑटो में सवार!) एक महत्वपूर्ण सामान्य घटक पर भरोसा करें: द निर्णय वृक्ष!
निर्णय वृक्षों को समझे बिना, उपरोक्त किसी भी उन्नत बैगिंग या ग्रेडिएंट-बूस्टिंग एल्गोरिदम को समझना असंभव है, जो किसी भी डेटा वैज्ञानिक के लिए अपमानजनक है! तो, आइए हम पायथन में एक निर्णय वृक्ष को लागू करके उसकी आंतरिक कार्यप्रणाली को स्पष्ट करें।
इस लेख में, आप सीखेंगे
- निर्णय वृक्ष डेटा को क्यों और कैसे विभाजित करता है,
- सूचना लाभ, और
- NumPy का उपयोग करके Python में निर्णय वृक्षों को कैसे कार्यान्वित करें।
आप कोड यहां पा सकते हैं मेरा जीथूब.
भविष्यवाणियाँ करने के लिए, निर्णय वृक्षों पर भरोसा किया जाता है बंटवारे पुनरावर्ती तरीके से डेटासेट को छोटे भागों में बाँटना।

लेखक द्वारा छवि
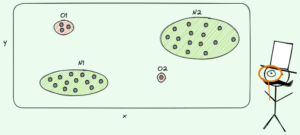
उपरोक्त चित्र में, आप विभाजन का एक उदाहरण देख सकते हैं - मूल डेटासेट दो भागों में अलग हो जाता है। अगले चरण में, ये दोनों भाग फिर से विभाजित हो जाते हैं, इत्यादि। यह तब तक जारी रहता है जब तक कि किसी प्रकार की रोक की कसौटी पूरी नहीं हो जाती, उदाहरण के लिए,
- यदि विभाजन के परिणामस्वरूप कोई भाग खाली हो जाता है
- यदि एक निश्चित पुनरावर्तन गहराई तक पहुँच गया था
- यदि (पिछले विभाजन के बाद) डेटासेट में केवल कुछ ही तत्व होते हैं, तो आगे विभाजन अनावश्यक हो जाता है।
हम इन विभाजनों का पता कैसे लगाते हैं? और हमें इसकी परवाह क्यों है? चलो पता करते हैं।
अभिप्रेरण
आइए मान लें कि हम a को हल करना चाहते हैं बाइनरी वर्गीकरण समस्या कि अब हम खुद को बनाते हैं:
import numpy as np
np.random.seed(0) X = np.random.randn(100, 2) # features
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)द्वि-आयामी डेटा इस तरह दिखता है:

लेखक द्वारा छवि
हम देख सकते हैं कि दो अलग-अलग वर्ग हैं - लगभग 75% मामलों में बैंगनी और लगभग 25% मामलों में पीला। यदि आप इस डेटा को निर्णय वृक्ष पर फ़ीड करते हैं वर्गीकृत, इस पेड़ के प्रारंभ में निम्नलिखित विचार हैं:
“दो अलग-अलग लेबल हैं, जो मेरे लिए बहुत गड़बड़ है। मैं डेटा को दो भागों में विभाजित करके इस गड़बड़ी को साफ करना चाहता हूं - ये हिस्से पहले के संपूर्ण डेटा की तुलना में अधिक साफ-सुथरे होने चाहिए। - वह पेड़ जिसने चेतना प्राप्त की
और पेड़ ऐसा ही करता है.

लेखक द्वारा छवि
पेड़ लगभग साथ-साथ विभाजन करने का निर्णय लेता है x-एक्सिस। इसका असर यह हुआ कि डेटा का शीर्ष भाग अब बिल्कुल सही हो गया है स्वच्छ, मतलब कि आप ही पाते हैं एक एकल वर्ग (इस मामले में बैंगनी) वहाँ।
हालाँकि, निचला भाग अभी भी है गंदा, एक अर्थ में पहले से भी अधिक गन्दा। संपूर्ण डेटासेट में वर्ग अनुपात लगभग 75:25 हुआ करता था, लेकिन इस छोटे हिस्से में यह लगभग 50:50 है, जो जितना संभव हो उतना मिश्रित है
नोट: यहां, इससे कोई फर्क नहीं पड़ता कि चित्र में बैंगनी और पीला अच्छी तरह से अलग हो गए हैं। सिर्फ विभिन्न लेबलों का कच्चा माल दो भागों में गिना जाता है.

लेखक द्वारा छवि
फिर भी, यह पेड़ के लिए पहले कदम के रूप में काफी अच्छा है, और इसी तरह यह आगे बढ़ता है। हालाँकि यह शीर्ष पर एक और विभाजन पैदा नहीं करेगा, स्वच्छ अब भाग, इसे साफ करने के लिए निचले हिस्से में एक और विभाजन बना सकता है।

लेखक द्वारा छवि
और देखा, तीन अलग-अलग हिस्सों में से प्रत्येक पूरी तरह से साफ है, क्योंकि हमें प्रति भाग केवल एक ही रंग (लेबल) मिलता है।
अब भविष्यवाणियां करना वास्तव में आसान है: यदि कोई नया डेटा बिंदु आता है, तो आप बस यह जांचें कि इनमें से कौन सा है तीन हिस्से यह झूठ बोलता है और इसे उचित रंग देता है। यह अब बहुत अच्छा काम करता है क्योंकि प्रत्येक भाग है स्वच्छ. आसान, है ना?

लेखक द्वारा छवि
ठीक है, हम बात कर रहे थे स्वच्छ और गंदा डेटा लेकिन अभी तक ये शब्द केवल कुछ अस्पष्ट विचार का प्रतिनिधित्व करते हैं। किसी भी चीज़ को लागू करने के लिए, हमें परिभाषित करने का एक तरीका खोजना होगा स्वच्छता.
स्वच्छता के उपाय
उदाहरण के लिए, मान लीजिए कि हमारे पास कुछ लेबल हैं
y_1 = [0, 0, 0, 0, 0, 0, 0, 0] y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]सहजता से, y₁ लेबलों का सबसे साफ़ सेट है, इसके बाद y₂ और फिर y₃. अब तक सब ठीक है, लेकिन हम इस व्यवहार पर संख्याएँ कैसे डाल सकते हैं? शायद सबसे आसान बात जो दिमाग में आती है वह निम्नलिखित है:
बस शून्य की मात्रा और इकाई की मात्रा गिनें। उनके पूर्ण अंतर की गणना करें। इसे और अच्छा बनाने के लिए, सरणियों की लंबाई से विभाजित करके इसे सामान्य करें।
उदाहरण के लिए, y₂ इसमें कुल 8 प्रविष्टियाँ हैं - 6 शून्य और 2 एक। इसलिए, हमारी कस्टम-परिभाषित स्वच्छता अंक होगा |6 – 2| / 8 = 0.5. उस स्वच्छता स्कोर की गणना करना आसान है y₁ और y₃ क्रमशः 1.0 और 0.0 हैं। यहां, हम सामान्य सूत्र देख सकते हैं:

लेखक द्वारा छवि
यहाँ, n₀ और n₁ क्रमशः शून्य और एक की संख्याएँ हैं, एन = एन₀ + एन₁ सरणी की लंबाई है और पी₁ = एन₁ / एन 1 लेबल का हिस्सा है.
इस फॉर्मूले के साथ समस्या यह है कि यह है विशेष रूप से दो वर्गों के मामले के अनुरूप बनाया गया, लेकिन अक्सर हम बहु-वर्ग वर्गीकरण में रुचि रखते हैं। एक फ़ॉर्मूला जो काफी अच्छा काम करता है वह है गिनी अशुद्धता माप:

लेखक द्वारा छवि
या सामान्य मामला:

लेखक द्वारा छवि
यह इतनी अच्छी तरह से काम करता है कि स्किकिट-लर्न इसे डिफ़ॉल्ट उपाय के रूप में अपनाया गया मित्रता के लिए DecisionTreeClassifier वर्ग.

लेखक द्वारा छवि
नोट: गिनी उपाय गड़बड़ स्वच्छता के बजाय. उदाहरण: यदि किसी सूची में केवल एक वर्ग (=बहुत साफ डेटा!) शामिल है, तो योग में सभी पद शून्य हैं, इसलिए योग शून्य है। सबसे खराब स्थिति यह है कि यदि सभी कक्षाएं सटीक संख्या में बार दिखाई देती हैं, तो उस स्थिति में गिनी 1-1/हैC जहां C कक्षाओं की संख्या है.
अब जबकि हमारे पास सफ़ाई/गंदगी का एक माप है, तो आइए देखें कि इसका उपयोग अच्छे विभाजन खोजने के लिए कैसे किया जा सकता है।
विभाजन ढूँढना
ऐसे बहुत सारे विभाजन हैं जिनमें से हम चुनते हैं, लेकिन कौन सा अच्छा है? आइए गिनी अशुद्धता माप के साथ, अपने प्रारंभिक डेटासेट का फिर से उपयोग करें।

लेखक द्वारा छवि
हम अभी अंक नहीं गिनेंगे, लेकिन मान लेते हैं कि 75% बैंगनी हैं और 25% पीले हैं। गिनी की परिभाषा का उपयोग करते हुए, संपूर्ण डेटासेट की अशुद्धता है

लेखक द्वारा छवि
यदि हम डेटासेट को विभाजित करते हैं x-अक्ष, जैसा पहले किया गया था:

लेखक द्वारा छवि
RSI शीर्ष भाग में गिनी अशुद्धता 0.0 है और निचला भाग

लेखक द्वारा छवि
औसतन, दोनों भागों में गिनी अशुद्धता (0.0 + 0.5) / 2 = 0.25 है, जो पहले से पूरे डेटासेट के 0.375 से बेहतर है। हम इसे तथाकथित के संदर्भ में भी व्यक्त कर सकते हैं जानकारी हासिल करें:
इस विभाजन का सूचना लाभ 0.375 - 0.25 = 0.125 है।
उतना ही आसान. सूचना लाभ जितना अधिक होगा (अर्थात गिनी अशुद्धता जितनी कम होगी), उतना बेहतर होगा।
नोट: एक और समान रूप से अच्छा प्रारंभिक विभाजन y-अक्ष के साथ होगा।
ध्यान रखने वाली एक महत्वपूर्ण बात यह है कि यह उपयोगी है भागों की गिनी अशुद्धियों को भागों के आकार के अनुसार तौलें. उदाहरण के लिए, मान लीजिए
- भाग 1 में 50 डेटापॉइंट हैं और इसमें 0.0 की गिनी अशुद्धता है
- भाग 2 में 450 डेटापॉइंट हैं और इसमें 0.5 की गिनी अशुद्धता है,
तो औसत गिनी अशुद्धता (0.0 + 0.5) / 2 = 0.25 नहीं बल्कि 50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = होनी चाहिए 0.45.
ठीक है, और हम सर्वोत्तम विभाजन कैसे ढूँढ़ सकते हैं? सरल लेकिन गंभीर उत्तर है:
बस सभी विभाजनों को आज़माएँ और सबसे अधिक जानकारी प्राप्त करने वाले को चुनें। यह मूलतः एक पाशविक-बल वाला दृष्टिकोण है।
अधिक सटीक होने के लिए, मानक निर्णय वृक्षों का उपयोग किया जाता है निर्देशांक अक्षों के अनुदिश विभाजित होता है, अर्थात् एक्सᵢ = सी किसी सुविधा के लिए i और दहलीज c. इसका मतलब यह है कि
- विभाजित डेटा के एक भाग में सभी डेटा बिंदु शामिल होते हैं x साथ में xᵢ सीऔर
- सभी बिंदुओं का दूसरा भाग x साथ में xᵢ ≥ सी.
ये सरल विभाजन नियम व्यवहार में काफी अच्छे साबित हुए हैं, लेकिन आप निश्चित रूप से इस तर्क का विस्तार अन्य विभाजन बनाने के लिए भी कर सकते हैं (अर्थात विकर्ण रेखाएँ जैसे xᵢ + 2xⱼ = 3, उदाहरण के लिए)।
बढ़िया, ये सभी सामग्रियां हैं जिनकी हमें अभी आवश्यकता है!
हम अब निर्णय वृक्ष लागू करेंगे। चूँकि इसमें नोड्स होते हैं, आइए हम इसे परिभाषित करें Node कक्षा प्रथम.
from dataclasses import dataclass @dataclass
class Node: feature: int = None # feature for the split value: float = None # split threshold OR final prediction left: np.array = None # store one part of the data right: np.array = None # store the other part of the dataएक नोड उस सुविधा को जानता है जिसका उपयोग वह विभाजन के लिए करता है (feature) साथ ही विभाजन मूल्य (value). value निर्णय वृक्ष की अंतिम भविष्यवाणी के लिए भंडारण के रूप में भी उपयोग किया जाता है। चूँकि हम एक बाइनरी ट्री का निर्माण करेंगे, प्रत्येक नोड को अपने बाएँ और दाएँ बच्चों को जानना होगा, जैसा कि संग्रहीत है left और right .
अब, आइए वास्तविक निर्णय वृक्ष कार्यान्वयन करें। मैं इसे स्किकिट-लर्न संगत बना रहा हूं, इसलिए मैं कुछ कक्षाओं का उपयोग करता हूं sklearn.base . यदि आप इससे परिचित नहीं हैं, तो मेरे लेख को देखें स्किकिट-लर्न संगत मॉडल कैसे बनाएं.
आइये अमल करें!
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin class DecisionTreeClassifier(BaseEstimator, ClassifierMixin): def __init__(self): self.root = Node() @staticmethod def _gini(y): """Gini impurity.""" counts = np.bincount(y) p = counts / counts.sum() return (p * (1 - p)).sum() def _split(self, X, y): """Bruteforce search over all features and splitting points.""" best_information_gain = float("-inf") best_feature = None best_split = None for feature in range(X.shape[1]): split_candidates = np.unique(X[:, feature]) for split in split_candidates: left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] information_gain = self._gini(y) - ( len(X_left) / len(X) * self._gini(y_left) + len(X_right) / len(X) * self._gini(y_right) ) if information_gain > best_information_gain: best_information_gain = information_gain best_feature = feature best_split = split return best_feature, best_split def _build_tree(self, X, y): """The heavy lifting.""" feature, split = self._split(X, y) left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] if len(X_left) == 0 or len(X_right) == 0: return Node(value=np.argmax(np.bincount(y))) else: return Node( feature, split, self._build_tree(X_left, y_left), self._build_tree(X_right, y_right), ) def _find_path(self, x, node): """Given a data point x, walk from the root to the corresponding leaf node. Output its value.""" if node.feature == None: return node.value else: if x[node.feature] node.value: return self._find_path(x, node.left) else: return self._find_path(x, node.right) def fit(self, X, y): self.root = self._build_tree(X, y) return self def predict(self, X): return np.array([self._find_path(x, self.root) for x in X])और बस! अब आप स्किकिट-लर्न के बारे में वे सभी चीज़ें कर सकते हैं जो आपको पसंद हैं:
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy # Output
# 1.0चूंकि पेड़ अनियमित है, यह बहुत अधिक फिट हो रहा है, इसलिए एकदम सही ट्रेन स्कोर है। अदृश्य डेटा पर सटीकता बदतर होगी। हम यह भी जांच सकते हैं कि पेड़ कैसा दिखता है
print(dt.root) # Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )चित्र के रूप में, यह इस प्रकार होगा:

लेखक द्वारा छवि
इस लेख में हमने विस्तार से देखा है कि निर्णय वृक्ष कैसे काम करते हैं। हमने कुछ अस्पष्ट, फिर भी सहज विचारों के साथ शुरुआत की और उन्हें सूत्रों और एल्गोरिदम में बदल दिया। अंत में, हम स्क्रैच से निर्णय वृक्ष को लागू करने में सक्षम हुए।
हालाँकि सावधानी का एक शब्द: हमारे निर्णय वृक्ष को अभी तक नियमित नहीं किया जा सकता है। आमतौर पर, हम जैसे पैरामीटर निर्दिष्ट करना चाहेंगे
- अधिकतम गहराई
- पत्ती का आकार
- और न्यूनतम सूचना लाभ
कई अन्य के बीच। सौभाग्य से, इन चीज़ों को लागू करना उतना कठिन नहीं है, जो इसे आपके लिए एक आदर्श होमवर्क बनाता है। उदाहरण के लिए, यदि आप निर्दिष्ट करते हैं leaf_size=10 एक पैरामीटर के रूप में, 10 से अधिक नमूनों वाले नोड्स को अब विभाजित नहीं किया जाना चाहिए। इसके अलावा, यह कार्यान्वयन है कुशल नहीं. आमतौर पर, आप डेटासेट के कुछ हिस्सों को नोड्स में संग्रहीत नहीं करना चाहेंगे, बल्कि इसके बजाय केवल सूचकांकों को संग्रहीत करना चाहेंगे। तो आपका (संभावित रूप से बड़ा) डेटासेट केवल एक बार मेमोरी में है।
अच्छी बात यह है कि अब आप इस निर्णय वृक्ष टेम्पलेट के दीवाने हो सकते हैं। तुम कर सकते हो:
- विकर्ण विभाजन लागू करें, अर्थात xᵢ + 2xⱼ = 3 इसके बजाय बस xᵢ = 3,
- पत्तों के अंदर होने वाले तर्क को बदलें, यानी आप केवल बहुमत वोट करने के बजाय प्रत्येक पत्ते के भीतर एक लॉजिस्टिक रिग्रेशन चला सकते हैं, जो आपको एक देता है रैखिक वृक्ष
- बंटवारे की प्रक्रिया को बदलें, यानी क्रूर बल लगाने के बजाय, कुछ यादृच्छिक संयोजनों को आज़माएं और सबसे अच्छा चुनें, जो आपको एक देता है अतिरिक्त-वृक्ष वर्गीकरणकर्ता
- और अधिक.
डॉ रॉबर्ट कुब्लेरी पब्लिसिस मीडिया में डेटा साइंटिस्ट हैं और डेटा साइंस की ओर लेखक हैं।
मूल। अनुमति के साथ पुनर्प्रकाशित।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html?utm_source=rss&utm_medium=rss&utm_campaign=understanding-by-implementing-decision-tree
- 1
- 10
- 100
- 11
- 28
- 7
- 9
- a
- योग्य
- About
- ऊपर
- पूर्ण
- शुद्धता
- उन्नत
- बाद
- एल्गोरिदम
- सब
- राशि
- और
- अन्य
- जवाब
- दिखाई देते हैं
- दृष्टिकोण
- लगभग
- चारों ओर
- ऐरे
- लेख
- लेखक
- औसत
- आधार
- मूल रूप से
- क्योंकि
- से पहले
- जा रहा है
- BEST
- बेहतर
- बढ़ाने
- तल
- जानवर बल
- निर्माण
- नही सकता
- कौन
- मामला
- मामलों
- कुछ
- चेक
- बच्चे
- चुनें
- कक्षा
- कक्षाएं
- वर्गीकरण
- कोड
- रंग
- संयोजन
- सामान्य
- संगत
- पूरा
- पूरी तरह से
- गणना करना
- चेतना
- जारी
- समन्वय
- इसी
- पाठ्यक्रम
- बनाना
- महत्वपूर्ण
- तिथि
- डेटा विज्ञान
- आँकड़े वाला वैज्ञानिक
- डेटासेट
- निर्णय
- निर्णय वृक्ष
- चूक
- गहराई
- विस्तार
- अंतर
- विभिन्न
- मुश्किल
- नहीं करता है
- कर
- से प्रत्येक
- सबसे आसान
- प्रभाव
- तत्व
- पर्याप्त
- संपूर्ण
- समान रूप से
- ईथर (ईटीएच)
- और भी
- उदाहरण
- व्यक्त
- विस्तार
- परिचित
- फैशन
- Feature
- विशेषताएं
- कुछ
- अंतिम
- खोज
- प्रथम
- नाव
- पीछा किया
- निम्नलिखित
- सेना
- सूत्र
- से
- आगे
- लाभ
- सामान्य जानकारी
- मिल
- गिनी
- देना
- दी
- देता है
- Go
- जा
- अच्छा
- हो जाता
- यहाँ उत्पन्न करें
- उच्चतर
- उच्चतम
- होमवर्क
- कैसे
- एचटीएमएल
- HTTPS
- विचार
- विचारों
- लागू करने के
- कार्यान्वयन
- कार्यान्वयन
- आयात
- महत्वपूर्ण
- असंभव
- in
- Indices
- करें-
- प्रारंभिक
- शुरू में
- बजाय
- रुचि
- सहज ज्ञान युक्त
- IT
- केडनगेट्स
- रखना
- बच्चा
- जानना
- लेबल
- लेबल
- बड़ा
- सीख रहा हूँ
- लंबाई
- उत्तोलक
- पंक्तियां
- लिंक्डइन
- सूची
- लग रहा है
- लॉट
- मोहब्बत
- मशीन
- यंत्र अधिगम
- बहुमत
- बनाना
- बनाता है
- निर्माण
- मैन्युअल
- बहुत
- बात
- साधन
- माप
- मीडिया
- याद
- मन
- कम से कम
- मिश्रित
- मॉडल
- अधिक
- आवश्यकता
- की जरूरत है
- नया
- अगला
- नोड
- नोड्स
- संख्या
- संख्या
- numpy
- ONE
- आदेश
- मूल
- अन्य
- अन्य
- प्राचल
- पैरामीटर
- भाग
- भागों
- उत्तम
- अनुमति
- चुनना
- चित्र
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- बिन्दु
- अंक
- संभावित
- अभ्यास
- भविष्यवाणी
- भविष्यवाणियों
- पिछला
- मुसीबत
- साबित
- रखना
- अजगर
- बिना सोचे समझे
- अनुपात
- पहुँचे
- पुनरावर्ती
- प्रतीपगमन
- प्रतिनिधित्व
- क्रमश
- परिणाम
- वापसी
- रॉबर्ट
- जड़
- नियम
- रन
- विज्ञान
- वैज्ञानिक
- scikit सीखने
- Search
- स्व
- भावना
- अलग
- सेट
- Share
- चाहिए
- सरल
- के बाद से
- एक
- आकार
- छोटे
- So
- अब तक
- हल
- कुछ
- विभाजित
- विभाजन
- मानक
- शुरू
- कदम
- रोक
- भंडारण
- की दुकान
- संग्रहित
- ऐसा
- अनुरूप
- में बात कर
- टेम्पलेट
- शर्तों
- RSI
- जानकारी
- लेकिन हाल ही
- बात
- चीज़ें
- तीन
- द्वार
- यहाँ
- बार
- सेवा मेरे
- एक साथ
- भी
- ऊपर का
- कुल
- की ओर
- रेलगाड़ी
- पेड़
- बदल गया
- समझना
- समझ
- us
- उपयोग
- आमतौर पर
- मूल्य
- वोट
- कौन कौन से
- जब
- मर्जी
- अंदर
- शब्द
- शब्द
- काम
- कामकाज
- कार्य
- वर्स्ट
- होगा
- X
- एक्सजीबूस्ट
- आपका
- जेफिरनेट
- शून्य