इस पोस्ट में, हम प्रदर्शित करते हैं कि मॉडल के प्रदर्शन को बेहतर बनाने और अनुमान के समय को कम करने के लिए एक सुव्यवस्थित BERT मॉडल को संपीड़ित करने के लिए तंत्रिका वास्तुकला खोज (NAS) आधारित संरचनात्मक छंटाई का उपयोग कैसे करें। पूर्व-प्रशिक्षित भाषा मॉडल (पीएलएम) उत्पादकता उपकरण, ग्राहक सेवा, खोज और अनुशंसाओं, व्यवसाय प्रक्रिया स्वचालन और सामग्री निर्माण के क्षेत्रों में तेजी से वाणिज्यिक और उद्यम अपनाने के दौर से गुजर रहे हैं। पीएलएम अनुमान समापन बिंदुओं की तैनाती आमतौर पर गणना आवश्यकताओं के कारण उच्च विलंबता और उच्च बुनियादी ढांचे की लागत और बड़ी संख्या में मापदंडों के कारण कम कम्प्यूटेशनल दक्षता से जुड़ी होती है। पीएलएम की काट-छांट करने से मॉडल की पूर्वानुमानित क्षमताओं को बरकरार रखते हुए उसका आकार और जटिलता कम हो जाती है। काँटे गए पीएलएम एक छोटी मेमोरी फ़ुटप्रिंट और कम विलंबता प्राप्त करते हैं। हम यह प्रदर्शित करते हैं कि पीएलएम में कटौती करके और एक विशिष्ट लक्ष्य कार्य के लिए पैरामीटर गिनती और सत्यापन त्रुटि को दूर करके, और बेस पीएलएम मॉडल की तुलना में तेजी से प्रतिक्रिया समय प्राप्त करने में सक्षम हैं।
बहुउद्देश्यीय अनुकूलन निर्णय लेने का एक क्षेत्र है जो एक से अधिक उद्देश्य फ़ंक्शन, जैसे मेमोरी खपत, प्रशिक्षण समय और गणना संसाधनों को एक साथ अनुकूलित करने के लिए अनुकूलित करता है। स्ट्रक्चरल प्रूनिंग मॉडल सटीकता को संरक्षित करने का प्रयास करते हुए परतों या न्यूरॉन्स/नोड्स को प्रूनिंग करके पीएलएम के आकार और कम्प्यूटेशनल आवश्यकताओं को कम करने की एक तकनीक है। परतों को हटाकर, संरचनात्मक छंटाई उच्च संपीड़न दर प्राप्त करती है, जिससे हार्डवेयर-अनुकूल संरचित स्पार्सिटी होती है जो रनटाइम और प्रतिक्रिया समय को कम करती है। पीएलएम मॉडल में संरचनात्मक प्रूनिंग तकनीक को लागू करने से कम मेमोरी फ़ुटप्रिंट के साथ हल्के वजन वाला मॉडल तैयार होता है, जिसे जब सेजमेकर में एक अनुमान समापन बिंदु के रूप में होस्ट किया जाता है, तो मूल फाइन-ट्यून किए गए पीएलएम की तुलना में बेहतर संसाधन दक्षता और कम लागत प्रदान करता है।
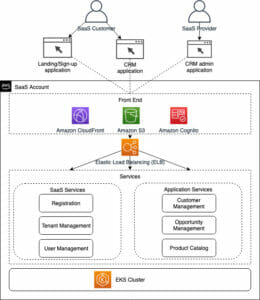
इस पोस्ट में चित्रित अवधारणाओं को उन अनुप्रयोगों पर लागू किया जा सकता है जो पीएलएम सुविधाओं का उपयोग करते हैं, जैसे अनुशंसा प्रणाली, भावना विश्लेषण और खोज इंजन। विशेष रूप से, आप इस दृष्टिकोण का उपयोग कर सकते हैं यदि आपके पास समर्पित मशीन लर्निंग (एमएल) और डेटा विज्ञान टीमें हैं जो डोमेन-विशिष्ट डेटासेट का उपयोग करके अपने स्वयं के पीएलएम मॉडल को ठीक करते हैं और बड़ी संख्या में अनुमान समापन बिंदुओं को तैनात करते हैं अमेज़न SageMaker. एक उदाहरण एक ऑनलाइन रिटेलर है जो पाठ सारांश, उत्पाद कैटलॉग वर्गीकरण और उत्पाद प्रतिक्रिया भावना वर्गीकरण के लिए बड़ी संख्या में अनुमान समापन बिंदु तैनात करता है। एक अन्य उदाहरण एक स्वास्थ्य सेवा प्रदाता हो सकता है जो नैदानिक दस्तावेज़ वर्गीकरण के लिए पीएलएम अनुमान समापन बिंदुओं का उपयोग करता है, मेडिकल रिपोर्ट, मेडिकल चैटबॉट और रोगी जोखिम स्तरीकरण से नामित इकाई मान्यता।
समाधान अवलोकन
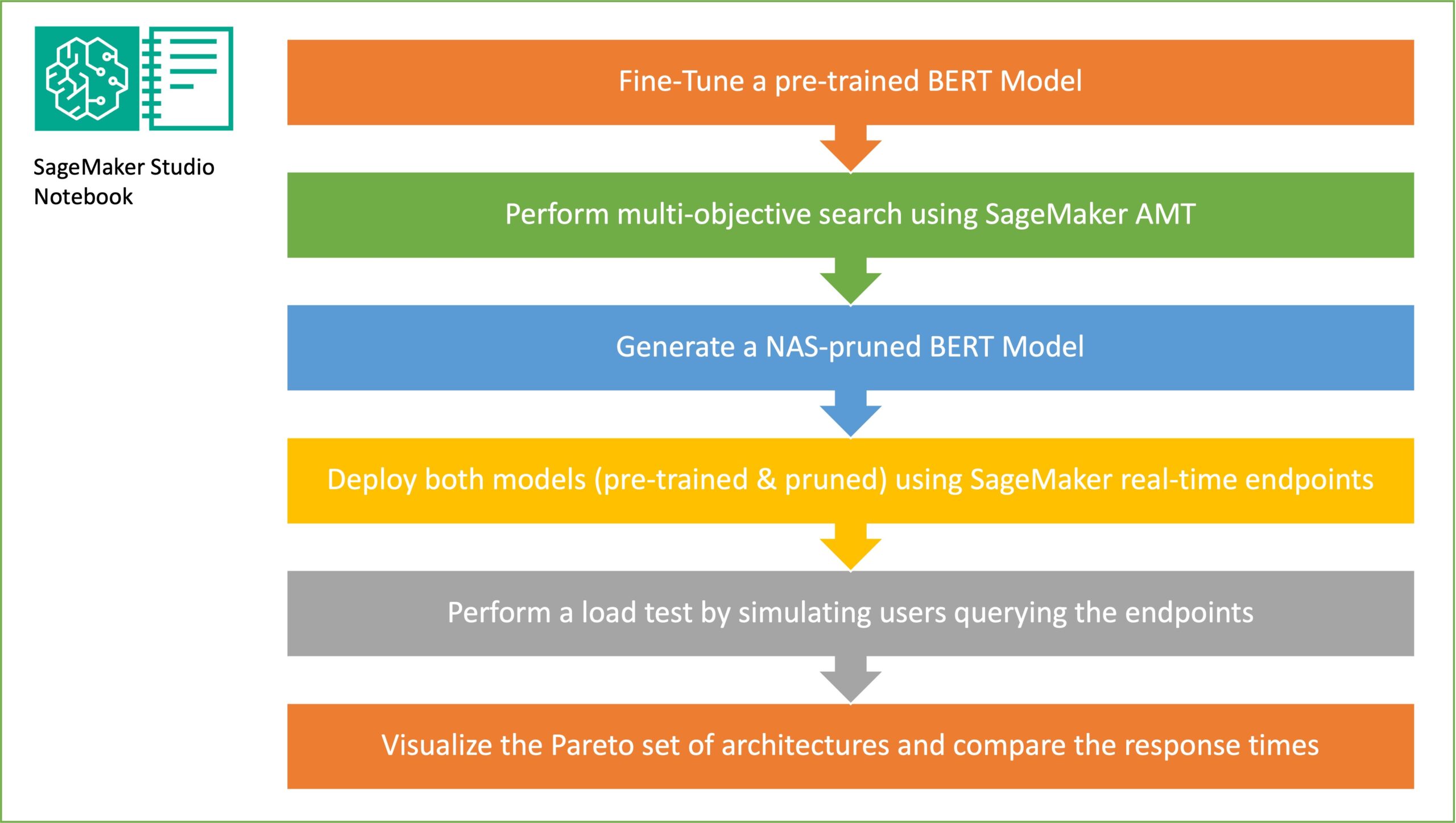
इस अनुभाग में, हम समग्र वर्कफ़्लो प्रस्तुत करते हैं और दृष्टिकोण की व्याख्या करते हैं। सबसे पहले, हम एक का उपयोग करते हैं अमेज़ॅन सैजमेकर स्टूडियो नोटबुक डोमेन-विशिष्ट डेटासेट का उपयोग करके लक्ष्य कार्य पर पूर्व-प्रशिक्षित BERT मॉडल को ठीक करना। बर्ट (ट्रांसफॉर्मर्स से द्विदिश एनकोडर प्रतिनिधित्व) पर आधारित एक पूर्व-प्रशिक्षित भाषा मॉडल है ट्रांसफार्मर वास्तुकला प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कार्यों के लिए उपयोग किया जाता है। न्यूरल आर्किटेक्चर सर्च (एनएएस) कृत्रिम तंत्रिका नेटवर्क के डिजाइन को स्वचालित करने के लिए एक दृष्टिकोण है और यह हाइपरपैरामीटर ऑप्टिमाइजेशन से निकटता से संबंधित है, जो मशीन लर्निंग के क्षेत्र में व्यापक रूप से उपयोग किया जाने वाला दृष्टिकोण है। एनएएस का लक्ष्य ग्रेडिएंट-फ्री ऑप्टिमाइज़ेशन जैसी तकनीकों का उपयोग करके या वांछित मेट्रिक्स को अनुकूलित करके उम्मीदवार आर्किटेक्चर के एक बड़े सेट पर खोज करके किसी दी गई समस्या के लिए इष्टतम आर्किटेक्चर ढूंढना है। आर्किटेक्चर का प्रदर्शन आम तौर पर सत्यापन हानि जैसे मेट्रिक्स का उपयोग करके मापा जाता है। सेजमेकर स्वचालित मॉडल ट्यूनिंग (एएमटी) एमएल मॉडल के हाइपरपैरामीटर के इष्टतम संयोजनों को खोजने की कठिन और जटिल प्रक्रिया को स्वचालित करता है जो सर्वोत्तम मॉडल प्रदर्शन प्रदान करता है। एएमटी आपके द्वारा निर्दिष्ट हाइपरपैरामीटर की एक श्रृंखला का उपयोग करके बुद्धिमान खोज एल्गोरिदम और पुनरावृत्त मूल्यांकन का उपयोग करता है। यह हाइपरपैरामीटर मानों को चुनता है जो एक ऐसा मॉडल बनाता है जो सबसे अच्छा प्रदर्शन करता है, जैसा कि सटीकता और एफ-1 स्कोर जैसे प्रदर्शन मेट्रिक्स द्वारा मापा जाता है।
इस पोस्ट में वर्णित फाइन-ट्यूनिंग दृष्टिकोण सामान्य है और इसे किसी भी टेक्स्ट-आधारित डेटासेट पर लागू किया जा सकता है। बीईआरटी पीएलएम को सौंपा गया कार्य पाठ-आधारित कार्य हो सकता है जैसे भावना विश्लेषण, पाठ वर्गीकरण, या प्रश्नोत्तर। इस डेमो में, लक्ष्य कार्य एक द्विआधारी वर्गीकरण समस्या है जहां BERT का उपयोग डेटासेट से पहचानने के लिए किया जाता है, जिसमें पाठ खंडों के जोड़े का संग्रह होता है, कि क्या एक पाठ खंड का अर्थ दूसरे खंड से अनुमान लगाया जा सकता है। हम उपयोग करते हैं टेक्स्टुअल एंटेलमेंट डेटासेट को पहचानना GLUE बेंचमार्किंग सूट से। हम उन उप-नेटवर्कों की पहचान करने के लिए सेजमेकर एएमटी का उपयोग करके एक बहुउद्देश्यीय खोज करते हैं जो लक्ष्य कार्य के लिए पैरामीटर गणना और भविष्यवाणी सटीकता के बीच इष्टतम ट्रेड-ऑफ प्रदान करते हैं। बहुउद्देश्यीय खोज करते समय, हम सटीकता और पैरामीटर गिनती को उन उद्देश्यों के रूप में परिभाषित करने से शुरू करते हैं जिन्हें हम अनुकूलित करना चाहते हैं।
बीईआरटी पीएलएम नेटवर्क के भीतर, मॉड्यूलर, स्व-निहित उप-नेटवर्क हो सकते हैं जो मॉडल को भाषा समझ और ज्ञान प्रतिनिधित्व जैसी विशेष क्षमताएं रखने की अनुमति देते हैं। BERT PLM एक बहु-प्रमुख स्व-ध्यान उप-नेटवर्क और एक फ़ीड-फ़ॉरवर्ड उप-नेटवर्क का उपयोग करता है। एक बहु-प्रमुख, आत्म-ध्यान परत BERT को एकाधिक संदर्भ संकेतों में भाग लेने की अनुमति देकर अनुक्रम के प्रतिनिधित्व की गणना करने के लिए एक ही अनुक्रम की विभिन्न स्थितियों से संबंधित करने की अनुमति देती है। इनपुट को कई उप-स्थानों में विभाजित किया गया है और प्रत्येक उप-स्थान पर अलग से आत्म-ध्यान लगाया जाता है। एक ट्रांसफार्मर पीएलएम में एकाधिक हेड मॉडल को विभिन्न प्रतिनिधित्व उप-स्थानों से संयुक्त रूप से जानकारी प्राप्त करने की अनुमति देते हैं। फ़ीड-फ़ॉरवर्ड सब-नेटवर्क एक सरल तंत्रिका नेटवर्क है जो मल्टी-हेडेड सेल्फ-अटेंशन सब-नेटवर्क से आउटपुट लेता है, डेटा को संसाधित करता है, और अंतिम एनकोडर अभ्यावेदन लौटाता है।
यादृच्छिक उप-नेटवर्क नमूनाकरण का लक्ष्य छोटे BERT मॉडल को प्रशिक्षित करना है जो लक्ष्य कार्यों पर काफी अच्छा प्रदर्शन कर सकते हैं। हम फाइन-ट्यून्ड बेस BERT मॉडल से 100 यादृच्छिक उप-नेटवर्क का नमूना लेते हैं और एक साथ 10 नेटवर्क का मूल्यांकन करते हैं। वस्तुनिष्ठ मेट्रिक्स के लिए प्रशिक्षित उप-नेटवर्क का मूल्यांकन किया जाता है और वस्तुनिष्ठ मेट्रिक्स के बीच पाए जाने वाले ट्रेड-ऑफ के आधार पर अंतिम मॉडल चुना जाता है। हम कल्पना करते हैं पेरेटो सामने नमूना किए गए उप-नेटवर्क के लिए, जिसमें काटा गया मॉडल शामिल है जो मॉडल सटीकता और मॉडल आकार के बीच इष्टतम व्यापार-बंद प्रदान करता है। हम मॉडल आकार और मॉडल सटीकता के आधार पर उम्मीदवार उप-नेटवर्क (एनएएस-प्रून्ड बीईआरटी मॉडल) का चयन करते हैं जिसे हम बदलना चाहते हैं। इसके बाद, हम सेजमेकर का उपयोग करके एंडपॉइंट्स, पूर्व-प्रशिक्षित BERT बेस मॉडल और NAS-प्रून्ड BERT मॉडल को होस्ट करते हैं। लोड परीक्षण करने के लिए, हम उपयोग करते हैं टिड्डी, एक खुला स्रोत लोड परीक्षण उपकरण जिसे आप पायथन का उपयोग करके कार्यान्वित कर सकते हैं। हम लोकस्ट का उपयोग करके दोनों एंडपॉइंट पर लोड परीक्षण चलाते हैं और दोनों मॉडलों के लिए प्रतिक्रिया समय और सटीकता के बीच व्यापार-बंद को चित्रित करने के लिए पेरेटो फ्रंट का उपयोग करके परिणामों की कल्पना करते हैं। निम्नलिखित चित्र इस पोस्ट में बताए गए वर्कफ़्लो का अवलोकन प्रदान करता है।
.. पूर्वापेक्षाएँ
इस पद के लिए निम्नलिखित आवश्यक शर्तें आवश्यक हैं:
आपको भी बढ़ाने की जरूरत है सेवा कोटा SageMaker में ml.g4dn.xlarge उदाहरणों के कम से कम तीन उदाहरणों तक पहुँचने के लिए। इंस्टेंस प्रकार ml.g4dn.xlarge लागत कुशल GPU इंस्टेंस है जो आपको PyTorch को मूल रूप से चलाने की अनुमति देता है। सेवा कोटा बढ़ाने के लिए, निम्नलिखित चरणों को पूरा करें:
- कंसोल पर, सेवा कोटा पर जाएँ।
- के लिए कोटा प्रबंधित करें, चुनें अमेज़न SageMaker, उसके बाद चुनो कोटा देखें.

- "प्रशिक्षण कार्य उपयोग के लिए ml-g4dn.xlarge" खोजें और कोटा आइटम चुनें।
- चुनें खाता-स्तर पर वृद्धि का अनुरोध करें.
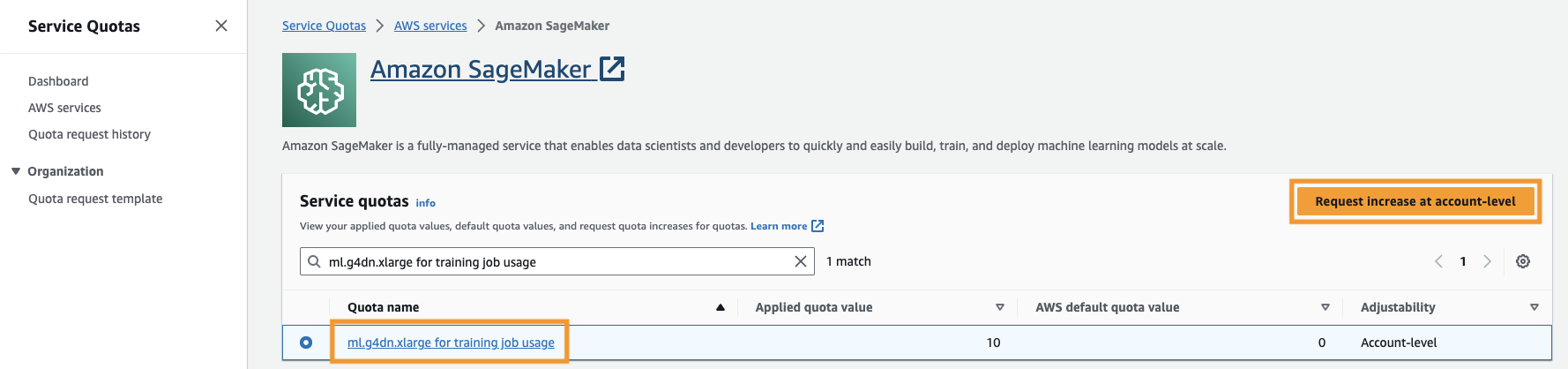
- के लिए कोटा मूल्य बढ़ाएँ, 5 या अधिक का मान दर्ज करें।
- चुनें निवेदन.
अनुरोधित कोटा अनुमोदन को खाता अनुमतियों के आधार पर पूरा होने में कुछ समय लग सकता है।

- सेजमेकर कंसोल से सेजमेकर स्टूडियो खोलें।

- चुनें सिस्टम टर्मिनल के अंतर्गत उपयोगिताएँ और फ़ाइलें.

- क्लोन करने के लिए निम्न कमांड चलाएँ गीथहब रेपो सेजमेकर स्टूडियो उदाहरण के लिए:
- पर जाए
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - फ़ाइल खोलें
nas_for_llm_with_amt.ipynb. - के साथ वातावरण स्थापित करें
ml.g4dn.xlargeउदाहरण और चुनें चुनते हैं.

पूर्व-प्रशिक्षित BERT मॉडल स्थापित करें
इस अनुभाग में, हम डेटासेट लाइब्रेरी से रिकॉग्नाइजिंग टेक्स्टुअल एंटेलमेंट डेटासेट आयात करते हैं और डेटासेट को प्रशिक्षण और सत्यापन सेट में विभाजित करते हैं। इस डेटासेट में वाक्यों के जोड़े हैं। बीईआरटी पीएलएम का कार्य दो पाठ खंडों को देखते हुए यह पहचानना है कि क्या एक पाठ खंड का अर्थ दूसरे खंड से अनुमान लगाया जा सकता है। निम्नलिखित उदाहरण में, हम दूसरे वाक्यांश से पहले वाक्यांश का अर्थ अनुमान लगा सकते हैं:
हम टेक्स्टुअल पहचानने वाले एंटेलमेंट डेटासेट को लोड करते हैं GLUE के माध्यम से बेंचमार्किंग सुइट डेटासेट लाइब्रेरी हमारी प्रशिक्षण स्क्रिप्ट में हगिंग फेस से (./training.py). हमने मूल प्रशिक्षण डेटासेट को GLUE से एक प्रशिक्षण और सत्यापन सेट में विभाजित किया है। हमारे दृष्टिकोण में, हम प्रशिक्षण डेटासेट का उपयोग करके बेस BERT मॉडल को ठीक करते हैं, फिर हम उप-नेटवर्क के सेट की पहचान करने के लिए एक बहुउद्देश्यीय खोज करते हैं जो उद्देश्य मेट्रिक्स के बीच इष्टतम संतुलन बनाता है। हम प्रशिक्षण डेटासेट का उपयोग विशेष रूप से BERT मॉडल को ठीक करने के लिए करते हैं। हालाँकि, हम होल्डआउट सत्यापन डेटासेट पर सटीकता को मापकर बहुउद्देश्यीय खोज के लिए सत्यापन डेटा का उपयोग करते हैं।
डोमेन-विशिष्ट डेटासेट का उपयोग करके BERT PLM को फाइन-ट्यून करें
कच्चे BERT मॉडल के लिए विशिष्ट उपयोग के मामलों में अगले वाक्य की भविष्यवाणी या छिपी हुई भाषा मॉडलिंग शामिल है। डाउनस्ट्रीम कार्यों जैसे टेक्स्टुअल रिकॉग्निशनिंग एंटेलमेंट के लिए बेस BERT मॉडल का उपयोग करने के लिए, हमें डोमेन-विशिष्ट डेटासेट का उपयोग करके मॉडल को और बेहतर बनाना होगा। आप अनुक्रम वर्गीकरण, प्रश्न उत्तर और टोकन वर्गीकरण जैसे कार्यों के लिए एक सुव्यवस्थित BERT मॉडल का उपयोग कर सकते हैं। हालाँकि, इस डेमो के प्रयोजनों के लिए, हम बाइनरी वर्गीकरण के लिए सुव्यवस्थित मॉडल का उपयोग करते हैं। हम निम्नलिखित हाइपरपैरामीटर का उपयोग करके पहले से तैयार किए गए प्रशिक्षण डेटासेट के साथ पूर्व-प्रशिक्षित BERT मॉडल को ठीक करते हैं:
हम मॉडल प्रशिक्षण के चेकपॉइंट को एक में सहेजते हैं अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस3) बकेट, ताकि मॉडल को एनएएस-आधारित बहुउद्देश्यीय खोज के दौरान लोड किया जा सके। मॉडल को प्रशिक्षित करने से पहले, हम युग, प्रशिक्षण हानि, मापदंडों की संख्या और सत्यापन त्रुटि जैसे मेट्रिक्स को परिभाषित करते हैं:
फाइन-ट्यूनिंग प्रक्रिया शुरू होने के बाद, प्रशिक्षण कार्य पूरा होने में लगभग 15 मिनट लगते हैं।
उप-नेटवर्क का चयन करने और परिणामों की कल्पना करने के लिए बहुउद्देश्यीय खोज करें
अगले चरण में, हम सेजमेकर एएमटी का उपयोग करके यादृच्छिक उप-नेटवर्क का नमूना लेकर फाइन-ट्यून्ड बेस BERT मॉडल पर एक बहुउद्देश्यीय खोज करते हैं। सुपर-नेटवर्क (फाइन-ट्यून्ड बीईआरटी मॉडल) के भीतर एक उप-नेटवर्क तक पहुंचने के लिए, हम पीएलएम के उन सभी घटकों को हटा देते हैं जो उप-नेटवर्क का हिस्सा नहीं हैं। पीएलएम में उप-नेटवर्क खोजने के लिए सुपर-नेटवर्क को मास्क करना एक ऐसी तकनीक है जिसका उपयोग मॉडल के व्यवहार के पैटर्न को अलग करने और पहचानने के लिए किया जाता है। ध्यान दें कि हगिंग फेस ट्रांसफॉर्मर को छिपे हुए आकार को सिरों की संख्या के गुणक की आवश्यकता होती है। ट्रांसफार्मर पीएलएम में छिपा हुआ आकार छिपे हुए राज्य वेक्टर स्थान के आकार को नियंत्रित करता है, जो डेटा में जटिल प्रतिनिधित्व और पैटर्न सीखने की मॉडल की क्षमता को प्रभावित करता है। बीईआरटी पीएलएम में, छिपा हुआ राज्य वेक्टर एक निश्चित आकार (768) का होता है। हम छिपे हुए आकार को नहीं बदल सकते, और इसलिए शीर्षों की संख्या [1, 3, 6, 12] में होनी चाहिए।
एकल-उद्देश्य अनुकूलन के विपरीत, बहु-उद्देश्यीय सेटिंग में, हमारे पास आम तौर पर एक भी समाधान नहीं होता है जो एक साथ सभी उद्देश्यों को अनुकूलित करता हो। इसके बजाय, हमारा लक्ष्य ऐसे समाधानों का एक समूह एकत्र करना है जो कम से कम एक उद्देश्य (जैसे सत्यापन त्रुटि) में अन्य सभी समाधानों पर हावी हों। अब हम उन मेट्रिक्स को सेट करके एएमटी के माध्यम से बहुउद्देश्यीय खोज शुरू कर सकते हैं जिन्हें हम कम करना चाहते हैं (सत्यापन त्रुटि और मापदंडों की संख्या)। यादृच्छिक उप-नेटवर्क को पैरामीटर द्वारा परिभाषित किया गया है max_jobs और एक साथ नौकरियों की संख्या पैरामीटर द्वारा परिभाषित की जाती है max_parallel_jobs. मॉडल चेकपॉइंट को लोड करने और उप-नेटवर्क का मूल्यांकन करने के लिए कोड उपलब्ध है evaluate_subnetwork.py लिपियों.
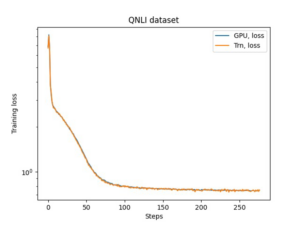
एएमटी ट्यूनिंग कार्य को चलने में लगभग 2 घंटे 20 मिनट का समय लगता है। एएमटी ट्यूनिंग कार्य सफलतापूर्वक चलने के बाद, हम कार्य के इतिहास को पार्स करते हैं और उप-नेटवर्क की कॉन्फ़िगरेशन एकत्र करते हैं, जैसे हेड की संख्या, परतों की संख्या, इकाइयों की संख्या, और संबंधित मेट्रिक्स जैसे सत्यापन त्रुटि और पैरामीटर की संख्या। निम्नलिखित स्क्रीनशॉट एक सफल एएमटी ट्यूनर कार्य का सारांश दिखाता है।
इसके बाद, हम पेरेटो सेट (जिसे पेरेटो फ्रंटियर या पेरेटो इष्टतम सेट के रूप में भी जाना जाता है) का उपयोग करके परिणामों की कल्पना करते हैं, जो हमें उप-नेटवर्क के इष्टतम सेट की पहचान करने में मदद करता है जो उद्देश्य मीट्रिक (सत्यापन त्रुटि) में अन्य सभी उप-नेटवर्क पर हावी है:
सबसे पहले, हम एएमटी ट्यूनिंग कार्य से डेटा एकत्र करते हैं। फिर हम पेरेटो सेट का उपयोग करके प्लॉट करते हैं matplotlob.pyplot x अक्ष में पैरामीटरों की संख्या और y अक्ष में सत्यापन त्रुटि के साथ। इसका तात्पर्य यह है कि जब हम पेरेटो सेट के एक उप-नेटवर्क से दूसरे में जाते हैं, तो हमें या तो प्रदर्शन या मॉडल आकार का त्याग करना होगा लेकिन दूसरे में सुधार करना होगा। अंततः, पेरेटो सेट हमें उस उप-नेटवर्क को चुनने की सुविधा प्रदान करता है जो हमारी प्राथमिकताओं के लिए सबसे उपयुक्त है। हम यह तय कर सकते हैं कि हम अपने नेटवर्क का आकार कितना कम करना चाहते हैं और प्रदर्शन में कितना त्याग करना चाहते हैं।

सेजमेकर का उपयोग करके सुव्यवस्थित BERT मॉडल और NAS-अनुकूलित उप-नेटवर्क मॉडल को तैनात करें
इसके बाद, हम अपने पेरेटो सेट में सबसे बड़ा मॉडल तैनात करते हैं जो प्रदर्शन में सबसे कम गिरावट की ओर ले जाता है SageMaker समापन बिंदु. सबसे अच्छा मॉडल वह है जो सत्यापन त्रुटि और हमारे उपयोग के मामले के लिए मापदंडों की संख्या के बीच एक इष्टतम व्यापार-बंद प्रदान करता है।
मॉडल की तुलना
हमने एक पूर्व-प्रशिक्षित आधार BERT मॉडल लिया, इसे एक डोमेन-विशिष्ट डेटासेट का उपयोग करके ठीक किया, उद्देश्य मेट्रिक्स के आधार पर प्रमुख उप-नेटवर्क की पहचान करने के लिए एक NAS खोज चलाई, और एक सेजमेकर एंडपॉइंट पर छंटनी किए गए मॉडल को तैनात किया। इसके अलावा, हमने पूर्व-प्रशिक्षित बेस BERT मॉडल लिया और बेस मॉडल को दूसरे सेजमेकर एंडपॉइंट पर तैनात किया। इसके बाद, हम भागे लोड परीक्षण दोनों अनुमान समापन बिंदुओं पर लोकस्ट का उपयोग किया गया और प्रतिक्रिया समय के संदर्भ में प्रदर्शन का मूल्यांकन किया गया।
सबसे पहले, हम आवश्यक Locust और Boto3 लाइब्रेरी आयात करते हैं। फिर हम एक अनुरोध मेटाडेटा बनाते हैं और लोड परीक्षण के लिए उपयोग किए जाने वाले प्रारंभ समय को रिकॉर्ड करते हैं। फिर वास्तविक उपयोगकर्ता अनुरोधों को अनुकरण करने के लिए पेलोड को बोटोक्लाइंट के माध्यम से सेजमेकर एंडपॉइंट इनवोक एपीआई को भेज दिया जाता है। हम समानांतर में अनुरोध भेजने और लोड के तहत एंडपॉइंट प्रदर्शन को मापने के लिए कई आभासी उपयोगकर्ताओं को उत्पन्न करने के लिए लोकस्ट का उपयोग करते हैं। दोनों अंतिम बिंदुओं में से प्रत्येक के लिए क्रमशः उपयोगकर्ताओं की संख्या बढ़ाकर परीक्षण चलाए जाते हैं। परीक्षण पूरा होने के बाद, टिड्डी प्रत्येक तैनात मॉडल के लिए एक अनुरोध सांख्यिकी सीएसवी फ़ाइल आउटपुट करता है।
इसके बाद, हम लोकस्ट के साथ परीक्षण चलाने के बाद डाउनलोड की गई सीएसवी फ़ाइलों से प्रतिक्रिया समय प्लॉट तैयार करते हैं। प्रतिक्रिया समय बनाम उपयोगकर्ताओं की संख्या की योजना बनाने का उद्देश्य मॉडल समापन बिंदुओं के प्रतिक्रिया समय के प्रभाव की कल्पना करके लोड परीक्षण परिणामों का विश्लेषण करना है। निम्नलिखित चार्ट में, हम देख सकते हैं कि NAS-प्रून्ड मॉडल एंडपॉइंट बेस BERT मॉडल एंडपॉइंट की तुलना में कम प्रतिक्रिया समय प्राप्त करता है।
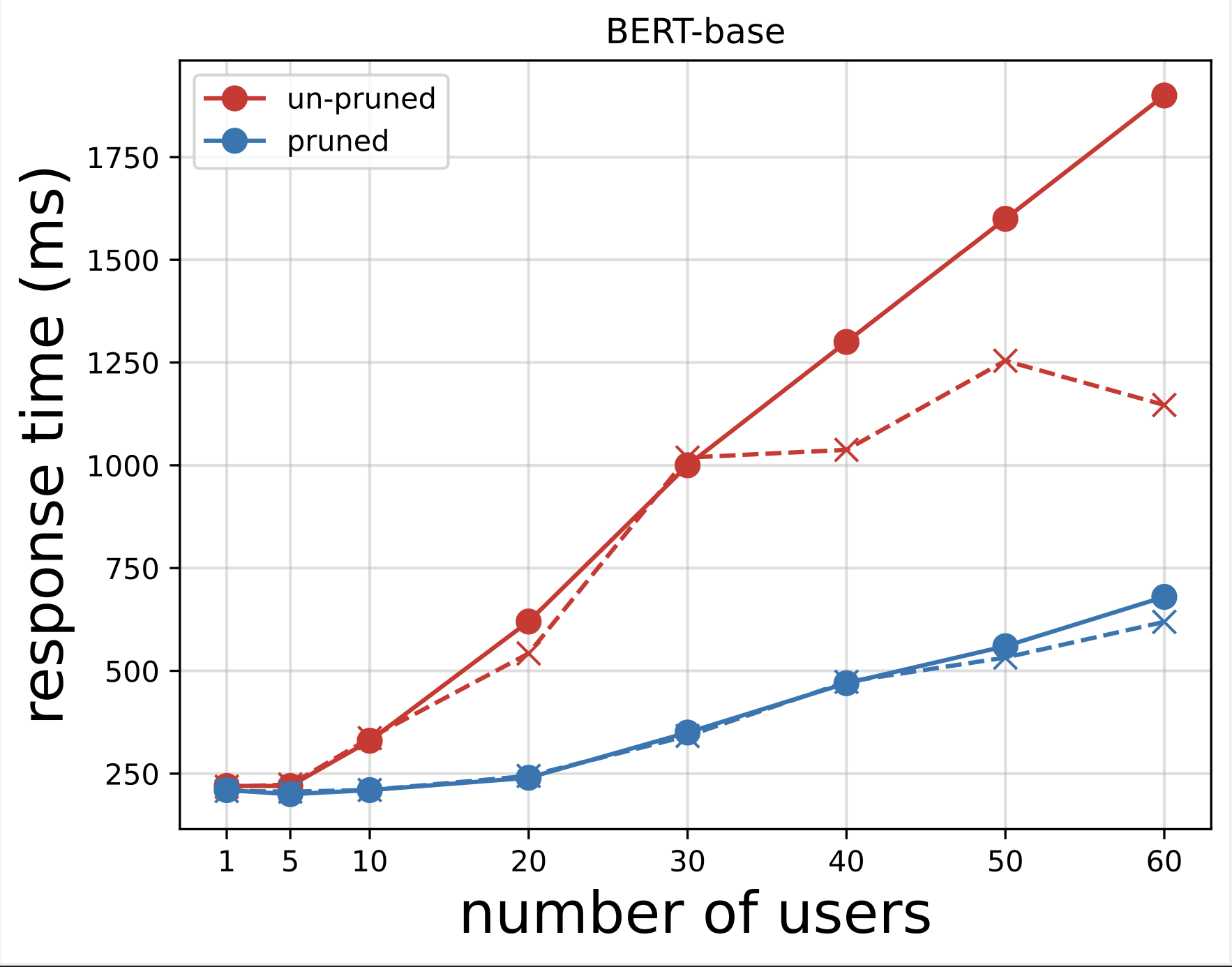
दूसरे चार्ट में, जो पहले चार्ट का विस्तार है, हम देखते हैं कि लगभग 70 उपयोगकर्ताओं के बाद, सेजमेकर बेस BERT मॉडल एंडपॉइंट को दबाना शुरू कर देता है और एक अपवाद फेंकता है। हालाँकि, NAS-प्रून्ड मॉडल एंडपॉइंट के लिए, थ्रॉटलिंग 90-100 उपयोगकर्ताओं के बीच और कम प्रतिक्रिया समय के साथ होती है।

दो चार्टों से, हम देखते हैं कि बिना काटे गए मॉडल की तुलना में काटे गए मॉडल का प्रतिक्रिया समय तेज होता है और स्केल बेहतर होता है। जैसे-जैसे हम अनुमान समापन बिंदुओं की संख्या को मापते हैं, जैसा कि उन उपयोगकर्ताओं के मामले में होता है जो अपने पीएलएम अनुप्रयोगों के लिए बड़ी संख्या में अनुमान समापन बिंदुओं को तैनात करते हैं, लागत लाभ और प्रदर्शन में सुधार काफी महत्वपूर्ण होने लगता है।
क्लीन अप
फाइन-ट्यून बेस BERT मॉडल और NAS-प्रून्ड मॉडल के लिए सेजमेकर एंडपॉइंट्स को हटाने के लिए, निम्नलिखित चरणों को पूरा करें:
- SageMaker कंसोल पर, चुनें अनुमान और endpoints नेविगेशन फलक में
- समापन बिंदु का चयन करें और इसे हटा दें।
वैकल्पिक रूप से, सेजमेकर स्टूडियो नोटबुक से, एंडपॉइंट नाम प्रदान करके निम्नलिखित कमांड चलाएँ:
निष्कर्ष
इस पोस्ट में, हमने चर्चा की कि फाइन-ट्यून्ड BERT मॉडल की छंटाई करने के लिए NAS का उपयोग कैसे किया जाए। हमने पहले डोमेन-विशिष्ट डेटा का उपयोग करके एक बेस BERT मॉडल को प्रशिक्षित किया और इसे SageMaker एंडपॉइंट पर तैनात किया। हमने लक्ष्य कार्य के लिए सेजमेकर एएमटी का उपयोग करके फाइन-ट्यून्ड बेस BERT मॉडल पर एक बहुउद्देश्यीय खोज की। हमने पेरेटो फ्रंट की कल्पना की और पेरेटो इष्टतम एनएएस-प्रून्ड बीईआरटी मॉडल का चयन किया और मॉडल को दूसरे सेजमेकर एंडपॉइंट पर तैनात किया। हमने दोनों अंतिम बिंदुओं पर क्वेरी करने वाले उपयोगकर्ताओं को अनुकरण करने के लिए लोकस्ट का उपयोग करके लोड परीक्षण किया, और एक सीएसवी फ़ाइल में प्रतिक्रिया समय को मापा और रिकॉर्ड किया। हमने दोनों मॉडलों के लिए प्रतिक्रिया समय बनाम उपयोगकर्ताओं की संख्या की योजना बनाई।
हमने देखा कि काँटे गए BERT मॉडल ने प्रतिक्रिया समय और उदाहरण थ्रॉटलिंग थ्रेशोल्ड दोनों में काफी बेहतर प्रदर्शन किया। हमने निष्कर्ष निकाला कि एनएएस-प्रून्ड मॉडल एंडपॉइंट पर बढ़े हुए लोड के प्रति अधिक लचीला था, कम प्रतिक्रिया समय बनाए रखता था, भले ही अधिक उपयोगकर्ताओं ने बेस बीईआरटी मॉडल की तुलना में सिस्टम पर जोर दिया हो। आप इस पोस्ट में वर्णित एनएएस तकनीक को किसी भी बड़े भाषा मॉडल पर लागू कर सकते हैं ताकि एक छोटा मॉडल ढूंढा जा सके जो लक्ष्य कार्य को काफी कम प्रतिक्रिया समय के साथ पूरा कर सके। आप सत्यापन हानि के अतिरिक्त एक पैरामीटर के रूप में विलंबता का उपयोग करके दृष्टिकोण को और अधिक अनुकूलित कर सकते हैं।
हालाँकि हम इस पोस्ट में NAS का उपयोग करते हैं, लेकिन पीएलएम मॉडल को अनुकूलित और संपीड़ित करने के लिए परिमाणीकरण एक और सामान्य दृष्टिकोण है। क्वांटाइजेशन एक प्रशिक्षित नेटवर्क में वजन और सक्रियण की सटीकता को 32-बिट फ्लोटिंग पॉइंट से कम बिट चौड़ाई जैसे 8-बिट या 16-बिट पूर्णांक तक कम कर देता है, जिसके परिणामस्वरूप एक संपीड़ित मॉडल होता है जो तेजी से अनुमान उत्पन्न करता है। परिमाणीकरण मापदंडों की संख्या को कम नहीं करता है; इसके बजाय यह एक संपीड़ित मॉडल प्राप्त करने के लिए मौजूदा मापदंडों की सटीकता को कम कर देता है। एनएएस प्रूनिंग पीएलएम में अनावश्यक नेटवर्क को हटा देता है, जो कम मापदंडों के साथ एक विरल मॉडल बनाता है। आमतौर पर, मॉडल सटीकता बनाए रखने, प्रदर्शन में सुधार करते हुए सत्यापन हानि को कम करने और मॉडल आकार को कम करने के लिए बड़े पीएलएम को संपीड़ित करने के लिए एनएएस प्रूनिंग और क्वांटिज़ेशन का एक साथ उपयोग किया जाता है। पीएलएम के आकार को कम करने के लिए आमतौर पर इस्तेमाल की जाने वाली अन्य तकनीकों में शामिल हैं ज्ञान आसवन, मैट्रिक्स गुणनखंडन, तथा आसवन झरना.
ब्लॉगपोस्ट में प्रस्तावित दृष्टिकोण उन टीमों के लिए उपयुक्त है जो डोमेन-विशिष्ट डेटा का उपयोग करके मॉडल को प्रशिक्षित करने और ठीक करने और अनुमान उत्पन्न करने के लिए एंडपॉइंट तैनात करने के लिए सेजमेकर का उपयोग करते हैं। यदि आप एक पूरी तरह से प्रबंधित सेवा की तलाश कर रहे हैं जो जेनरेटिव एआई अनुप्रयोगों के निर्माण के लिए आवश्यक उच्च प्रदर्शन वाले फाउंडेशन मॉडल का विकल्प प्रदान करती है, तो इसका उपयोग करने पर विचार करें अमेज़ॅन बेडरॉक. यदि आप व्यावसायिक उपयोग के मामलों की एक विस्तृत श्रृंखला के लिए पूर्व-प्रशिक्षित, ओपन सोर्स मॉडल की तलाश कर रहे हैं और समाधान टेम्पलेट्स और उदाहरण नोटबुक तक पहुंच चाहते हैं, तो इसका उपयोग करने पर विचार करें अमेज़न SageMaker जम्पस्टार्ट. हगिंग फेस BERT बेस केस मॉडल का एक पूर्व-प्रशिक्षित संस्करण, जिसका उपयोग हमने इस पोस्ट में किया है, सेजमेकर जम्पस्टार्ट पर भी उपलब्ध है।
लेखक के बारे में
 अपराजितन वैद्यनाथन AWS में प्रिंसिपल एंटरप्राइज सॉल्यूशंस आर्किटेक्ट हैं। वह एक क्लाउड आर्किटेक्ट हैं जिनके पास उद्यम, बड़े पैमाने पर और वितरित सॉफ्टवेयर सिस्टम को डिजाइन करने और विकसित करने का 24+ वर्षों का अनुभव है। वह जेनरेटिव एआई और मशीन लर्निंग डेटा इंजीनियरिंग में माहिर हैं। वह एक महत्वाकांक्षी मैराथन धावक हैं और उनके शौक में लंबी पैदल यात्रा, बाइक चलाना और अपनी पत्नी और दो लड़कों के साथ समय बिताना शामिल है।
अपराजितन वैद्यनाथन AWS में प्रिंसिपल एंटरप्राइज सॉल्यूशंस आर्किटेक्ट हैं। वह एक क्लाउड आर्किटेक्ट हैं जिनके पास उद्यम, बड़े पैमाने पर और वितरित सॉफ्टवेयर सिस्टम को डिजाइन करने और विकसित करने का 24+ वर्षों का अनुभव है। वह जेनरेटिव एआई और मशीन लर्निंग डेटा इंजीनियरिंग में माहिर हैं। वह एक महत्वाकांक्षी मैराथन धावक हैं और उनके शौक में लंबी पैदल यात्रा, बाइक चलाना और अपनी पत्नी और दो लड़कों के साथ समय बिताना शामिल है।
 आरोन क्लेन AWS में एक वरिष्ठ एप्लाइड वैज्ञानिक हैं जो गहरे तंत्रिका नेटवर्क के लिए स्वचालित मशीन सीखने के तरीकों पर काम कर रहे हैं।
आरोन क्लेन AWS में एक वरिष्ठ एप्लाइड वैज्ञानिक हैं जो गहरे तंत्रिका नेटवर्क के लिए स्वचालित मशीन सीखने के तरीकों पर काम कर रहे हैं।
 जेसेक गोलेबिओस्की एडब्ल्यूएस में सीनियर एप्लाइड साइंटिस्ट हैं।
जेसेक गोलेबिओस्की एडब्ल्यूएस में सीनियर एप्लाइड साइंटिस्ट हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :हैस
- :है
- :नहीं
- :कहाँ
- ][पी
- $यूपी
- 1
- 10
- 100
- 11
- 12
- 13
- 15% तक
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- क्षमता
- योग्य
- पहुँच
- लेखा
- शुद्धता
- पाना
- प्राप्त
- सक्रियता
- इसके अलावा
- दत्तक ग्रहण
- बाद
- AI
- उद्देश्य
- एमिंग
- एल्गोरिदम
- सब
- अनुमति देना
- की अनुमति दे
- की अनुमति देता है
- भी
- वीरांगना
- अमेज़ॅन वेब सेवा
- राशि
- an
- विश्लेषण
- विश्लेषिकी
- विश्लेषण करें
- और
- अन्य
- जवाब दे
- कोई
- एपीआई
- अनुप्रयोगों
- लागू
- लागू करें
- लागू
- दृष्टिकोण
- अनुमोदन
- लगभग
- स्थापत्य
- हैं
- क्षेत्र
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- तर्क
- चारों ओर
- कृत्रिम
- कृत्रिम तंत्रिका प्रसार
- AS
- आकांक्षी
- सौंपा
- जुड़े
- At
- प्रयास करने से
- भाग लेने के लिए
- स्वचालित
- स्वचालित मशीन सीखना
- ऑटोमेटा
- स्वचालित
- स्वचालित
- स्वचालन
- उपलब्ध
- एडब्ल्यूएस
- अक्ष
- शेष
- आधार
- आधारित
- BE
- बन
- से पहले
- व्यवहार
- बेंच मार्किंग
- लाभ
- BEST
- बेहतर
- के बीच
- बिट
- परिवर्तन
- के छात्रों
- निर्माण
- व्यापार
- व्यापार प्रक्रिया
- व्यापार प्रक्रिया स्वचालन
- लेकिन
- by
- कर सकते हैं
- उम्मीदवार
- क्षमताओं
- मामला
- मामलों
- सूची
- परिवर्तन
- चार्ट
- चार्ट
- chatbots
- चुनाव
- चुनें
- करने के लिए चुना
- कक्षा
- वर्गीकरण
- क्लिनिकल
- निकट से
- बादल
- कोड
- इकट्ठा
- संग्रह
- संयोजन
- वाणिज्यिक
- सामान्य
- सामान्यतः
- तुलना
- पूरा
- पूरा
- जटिल
- जटिलता
- घटकों
- कम्प्यूटेशनल
- गणना करना
- अवधारणाओं
- निष्कर्ष निकाला
- विचार करना
- होते हैं
- कंसोल
- की कमी
- निर्माण
- खपत
- शामिल हैं
- सामग्री
- सामग्री निर्माण
- प्रसंग
- जारी रखने के
- इसके विपरीत
- नियंत्रण
- इसी
- लागत
- लागत
- गणना
- बनाना
- बनाता है
- निर्माण
- ग्राहक
- ग्राहक सेवा
- तिथि
- डेटा विज्ञान
- डेटासेट
- दिनांक और समय
- तय
- निर्णय
- समर्पित
- गहरा
- गहरे तंत्रिका नेटवर्क
- परिभाषित
- परिभाषित
- परिभाषित करने
- डेमो
- दिखाना
- निर्भर करता है
- तैनात
- तैनात
- तैनाती
- तैनात
- वर्णित
- डिज़ाइन
- डिज़ाइन बनाना
- वांछित
- विकासशील
- विभिन्न
- चर्चा की
- वितरित
- दस्तावेज़
- नहीं करता है
- प्रमुख
- हावी
- dont
- दो
- दौरान
- e
- से प्रत्येक
- दक्षता
- कुशल
- भी
- endpoint
- अंतबिंदु
- अभियांत्रिकी
- इंजन
- पर्याप्त
- दर्ज
- उद्यम
- उद्यम को अपनाना
- उद्यम समाधान
- सत्ता
- प्रविष्टि
- वातावरण
- युग
- त्रुटि
- ईथर (ईटीएच)
- मूल्यांकन करें
- मूल्यांकित
- मूल्यांकन
- और भी
- घटनाओं
- उदाहरण
- सिवाय
- अपवाद
- अनन्य रूप से
- मौजूदा
- अनुभव
- समझाना
- समझाया
- विस्तार
- चेहरा
- असत्य
- और तेज
- विशेषताएं
- प्रतिक्रिया
- कम
- खेत
- पट्टिका
- फ़ाइलें
- अंतिम
- खोज
- खोज
- प्रथम
- तय
- लचीलापन
- चल
- निम्नलिखित
- पदचिह्न
- के लिए
- पाया
- बुनियाद
- से
- सामने
- सीमांत
- पूरी तरह से
- समारोह
- आगे
- उत्पन्न
- उत्पन्न करता है
- उत्पादक
- जनरेटिव एआई
- मिल
- दी
- लक्ष्य
- GPU
- ग्रे
- हो जाता
- है
- he
- सिर
- सिर
- स्वास्थ्य सेवा
- मदद करता है
- छिपा हुआ
- उच्च कार्य - निष्पादन
- उच्चतर
- हाइकिंग
- उसके
- इतिहास
- शौक
- मेजबान
- मेजबानी
- घंटे
- कैसे
- How To
- तथापि
- एचटीएमएल
- http
- HTTPS
- हगिंग फ़ेस
- हाइपरपरमेटर अनुकूलन
- हाइपरपरमेटर ट्यूनिंग
- i
- पहचान करना
- IDX
- if
- समझाना
- प्रभाव
- Impacts
- लागू करने के
- आयात
- में सुधार
- उन्नत
- सुधार
- में सुधार लाने
- in
- शामिल
- बढ़ना
- वृद्धि हुई
- बढ़ती
- करें-
- इंफ्रास्ट्रक्चर
- निवेश
- उदाहरण
- उदाहरणों
- बजाय
- बुद्धिमान
- में
- IT
- आईटी इस
- काम
- नौकरियां
- जेपीजी
- JSON
- ज्ञान
- जानने वाला
- भाषा
- बड़ा
- बड़े पैमाने पर
- सबसे बड़ा
- विलंब
- परत
- परतों
- बिक्रीसूत्र
- जानें
- सीख रहा हूँ
- कम से कम
- चलो
- पुस्तकालयों
- पुस्तकालय
- लाइन
- भार
- लॉग इन
- लॉगिंग
- देख
- बंद
- हानि
- कम
- मशीन
- यंत्र अधिगम
- बनाए रखना
- को बनाए रखने
- आदमी
- कामयाब
- मैराथन
- मुखौटा
- matplotlib
- अधिकतम
- मई..
- अर्थ
- माप
- मापा
- मापने
- मेडिकल
- मिलना
- याद
- मेटाडाटा
- तरीकों
- मीट्रिक
- मेट्रिक्स
- हो सकता है
- कम से कम
- मिनट
- ML
- आदर्श
- मोडलिंग
- मॉडल
- मॉड्यूलर
- अधिक
- चाल
- बहुत
- विभिन्न
- चाहिए
- नाम
- नामांकित
- नामों
- में
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- नेविगेट करें
- पथ प्रदर्शन
- आवश्यक
- आवश्यकता
- जरूरत
- की जरूरत है
- नेटवर्क
- नेटवर्क
- तंत्रिका
- तंत्रिका नेटवर्क
- तंत्रिका जाल
- अगला
- NLP
- कोई नहीं
- नोट
- नोटबुक
- पुस्तिकाओं
- अभी
- संख्या
- वस्तु
- उद्देश्य
- उद्देश्य
- निरीक्षण
- मनाया
- of
- बंद
- प्रस्ताव
- ऑफर
- on
- ONE
- ऑनलाइन
- ऑनलाइन रिटेलर
- केवल
- खुला
- खुला स्रोत
- इष्टतम
- इष्टतमीकरण
- ऑप्टिमाइज़ करें
- अनुकूलित
- अनुकूलन
- के अनुकूलन के
- or
- आदेश
- मूल
- अन्य
- हमारी
- आउट
- उत्पादन
- outputs के
- के ऊपर
- कुल
- सिंहावलोकन
- अपना
- जोड़े
- फलक
- समानांतर
- प्राचल
- पैरामीटर
- परेटो
- भाग
- पारित कर दिया
- पथ
- रोगी
- पैटर्न उपयोग करें
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- प्रदर्शन
- प्रदर्शन
- अनुमतियाँ
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- बिन्दु
- अंक
- पदों
- पद
- शुद्धता
- भविष्यवाणी
- भविष्य कहनेवाला
- Predictor
- वरीयताओं
- तैयार
- आवश्यक शर्तें
- वर्तमान
- पहले से
- प्रिंसिपल
- मुसीबत
- प्रक्रिया
- प्रक्रिया स्वचालन
- प्रक्रियाओं
- प्रसंस्करण
- एस्ट्रो मॉल
- उत्पादकता
- उत्पादकता टूल
- प्रस्तावित
- प्रदाता
- प्रदान करता है
- प्रदान कर
- खींच
- खींचती
- उद्देश्य
- प्रयोजनों
- अजगर
- pytorch
- क्यू एंड ए
- प्रश्न
- बिल्कुल
- बिना सोचे समझे
- रेंज
- उपवास
- दरें
- कच्चा
- वास्तविक
- मान्यता
- पहचान
- मान्यता देना
- सिफारिश
- सिफारिशें
- रिकॉर्ड
- दर्ज
- लाल
- को कम करने
- घटी
- कम कर देता है
- प्रतीपगमन
- सम्बंधित
- हटा देगा
- हटाने
- रिपोर्ट
- प्रतिनिधित्व
- का अनुरोध
- का अनुरोध किया
- अनुरोधों
- अपेक्षित
- आवश्यकताएँ
- लचीला
- संसाधन
- उपयुक्त संसाधन चुनें
- क्रमश
- प्रतिक्रिया
- परिणाम
- खुदरा
- बनाए रखने की
- रिटर्न
- घुड़सवारी
- जोखिम
- आरओडब्ल्यू
- रन
- धावक
- दौड़ना
- चलाता है
- s
- त्याग
- sagemaker
- सेजमेकर अनुमान
- सहेजें
- स्केल
- तराजू
- विज्ञान
- वैज्ञानिक
- स्कोर
- लिपि
- Search
- खोज इंजन
- खोज
- दूसरा
- अनुभाग
- देखना
- चयन
- चयनित
- स्व
- भेजें
- वाक्य
- भावुकता
- अनुक्रम
- सेवा
- सेवाएँ
- सत्र
- सेट
- सेट
- की स्थापना
- दिखाता है
- संकेत
- काफी
- सरल
- समकालिक
- एक साथ
- एक
- आकार
- छोटे
- So
- सॉफ्टवेयर
- समाधान
- समाधान ढूंढे
- कुछ
- स्रोत
- अंतरिक्ष
- स्पोन
- विशेषीकृत
- माहिर
- विशिष्ट
- विशेष रूप से
- खर्च
- विभाजित
- प्रारंभ
- शुरू होता है
- राज्य
- आँकड़े
- कदम
- कदम
- भंडारण
- संरचनात्मक
- संरचित
- स्टूडियो
- पर्याप्त
- सफल
- सफलतापूर्वक
- ऐसा
- उपयुक्त
- सूट
- सारांश
- प्रणाली
- सिस्टम
- T
- लेना
- लेता है
- लक्ष्य
- कार्य
- कार्य
- टीमों
- तकनीक
- तकनीक
- टेम्पलेट्स
- शर्तों
- परीक्षण
- परीक्षण
- टेक्स्ट
- पाठ वर्गीकरण
- शाब्दिक
- से
- कि
- RSI
- लेकिन हाल ही
- फिर
- वहाँ।
- इसलिये
- इन
- इसका
- तीन
- द्वार
- यहाँ
- पहर
- बार
- सेवा मेरे
- एक साथ
- टोकन
- ले गया
- साधन
- उपकरण
- व्यापार
- व्यापार
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- ट्रांसफार्मर
- ट्रान्सफ़ॉर्मर
- <strong>उद्देश्य</strong>
- कोशिश
- दो
- टाइप
- प्रकार
- ठेठ
- आम तौर पर
- अंत में
- के अंतर्गत
- के दौर से गुजर
- समझ
- इकाइयों
- us
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग करता है
- का उपयोग
- सत्यापन
- मूल्य
- मान
- संस्करण
- के माध्यम से
- वास्तविक
- कल्पना
- vs
- करना चाहते हैं
- था
- we
- वेब
- वेब सेवाओं
- कुंआ
- कब
- या
- कौन कौन से
- जब
- कौन
- चौड़ा
- विस्तृत श्रृंखला
- व्यापक रूप से
- पत्नी
- विकिपीडिया
- मर्जी
- तैयार
- साथ में
- अंदर
- काम
- वर्कफ़्लो
- काम कर रहे
- X
- साल
- प्राप्ति
- इसलिए आप
- आपका
- जेफिरनेट