दुनिया भर के संगठन - लाभ और गैर-लाभकारी दोनों - बेहतर व्यावसायिक प्रदर्शन के लिए डेटा एनालिटिक्स का लाभ उठाने पर विचार कर रहे हैं। ए से निष्कर्ष मैकिन्से सर्वेक्षण संकेत मिलता है कि डेटा-संचालित संगठनों के ग्राहक प्राप्त करने की संभावना 23 गुना अधिक है, ग्राहकों को बनाए रखने की संभावना छह गुना है, और 19 गुना अधिक लाभदायक है [1]। एमआईटी द्वारा अनुसंधान पाया गया कि डिजिटल रूप से परिपक्व कंपनियां अपने साथियों की तुलना में 26% अधिक लाभदायक हैं [2]। लेकिन कई कंपनियां, डेटा-समृद्ध होने के बावजूद, व्यावसायिक आवश्यकताओं, उपलब्ध क्षमताओं और संसाधनों के बीच परस्पर विरोधी प्राथमिकताओं के कारण डेटा एनालिटिक्स को लागू करने के लिए संघर्ष करती हैं। गार्टनर द्वारा शोध पाया गया कि 85% से अधिक डेटा और एनालिटिक्स प्रोजेक्ट विफल हो गए हैं [3] और ए संयुक्त रिपोर्ट आईबीएम और कार्नेगी मेलन से पता चलता है कि किसी संगठन में 90% डेटा का उपयोग कभी भी किसी रणनीतिक उद्देश्य के लिए सफलतापूर्वक नहीं किया जाता है [4]।
इस पृष्ठभूमि के साथ, हम "डेटा एनालिटिक्स फैब्रिक (डीएएफ)" अवधारणा को एक पारिस्थितिकी तंत्र या संरचना के रूप में पेश करते हैं, जो डेटा एनालिटिक्स को (ए) व्यावसायिक जरूरतों या उद्देश्यों, (बी) लोगों/कौशल जैसी उपलब्ध क्षमताओं के आधार पर प्रभावी ढंग से कार्य करने में सक्षम बनाता है। , प्रक्रियाएं, संस्कृति, प्रौद्योगिकियां, अंतर्दृष्टि, निर्णय लेने की क्षमताएं, और बहुत कुछ, और (सी) संसाधन (यानी, वे घटक जिनकी व्यवसाय को व्यवसाय संचालित करने के लिए आवश्यकता होती है)।
डेटा एनालिटिक्स फैब्रिक को पेश करने का हमारा प्राथमिक लक्ष्य इस मूलभूत प्रश्न का उत्तर देना है: "निर्णय-सक्षम प्रणाली को प्रभावी ढंग से बनाने के लिए क्या आवश्यक है" डाटा विज्ञान व्यावसायिक प्रदर्शन को मापने और सुधारने के लिए एल्गोरिदम? डेटा एनालिटिक्स फैब्रिक और इसकी पांच प्रमुख अभिव्यक्तियाँ नीचे दिखाई और चर्चा की गई हैं।
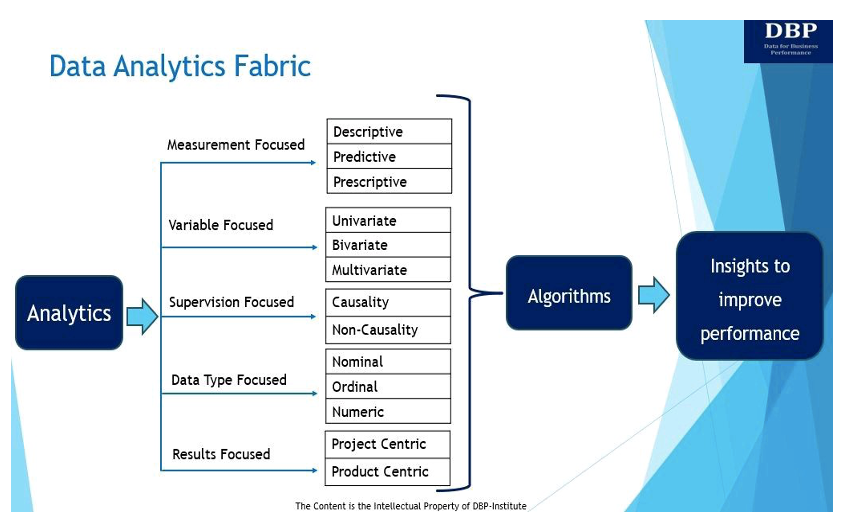
1. माप-केंद्रित
इसके मूल में, एनालिटिक्स अंतर्दृष्टि प्राप्त करने और व्यावसायिक प्रदर्शन को बेहतर बनाने के लिए डेटा का उपयोग करने के बारे में है [5]। व्यावसायिक प्रदर्शन को मापने और सुधारने के लिए तीन मुख्य प्रकार के विश्लेषण हैं:
- वर्णनात्मक विश्लेषण सवाल पूछता है, "क्या हुआ?" वर्णनात्मक विश्लेषण का उपयोग खोजपूर्ण, साहचर्य और अनुमानात्मक डेटा विश्लेषण तकनीकों का उपयोग करके पैटर्न, रुझान और संबंधों की पहचान करने के लिए ऐतिहासिक डेटा का विश्लेषण करने के लिए किया जाता है। खोजपूर्ण डेटा विश्लेषण तकनीकें डेटा सेट का विश्लेषण और सारांश प्रस्तुत करती हैं। साहचर्य वर्णनात्मक विश्लेषण चरों के बीच संबंध की व्याख्या करता है। नमूना डेटा सेट के आधार पर बड़ी आबादी के बारे में रुझान का अनुमान लगाने या निष्कर्ष निकालने के लिए अनुमानात्मक वर्णनात्मक डेटा विश्लेषण का उपयोग किया जाता है।
- भविष्यिक विश्लेषण प्रश्न का उत्तर देने पर विचार करता है, "क्या होगा?" मूल रूप से, भविष्य कहनेवाला विश्लेषण भविष्य के रुझानों और घटनाओं का पूर्वानुमान लगाने के लिए डेटा का उपयोग करने की प्रक्रिया है। पूर्वानुमानित विश्लेषण मैन्युअल रूप से (आमतौर पर विश्लेषक-संचालित भविष्य कहनेवाला विश्लेषण के रूप में जाना जाता है) या उपयोग करके किया जा सकता है मशीन लर्निंग एल्गोरिदम (डेटा-संचालित भविष्य कहनेवाला विश्लेषण के रूप में भी जाना जाता है)। किसी भी तरह, ऐतिहासिक डेटा का उपयोग भविष्य की भविष्यवाणी करने के लिए किया जाता है।
- प्रिस्क्रिप्टिव एनालिटिक्स प्रश्न का उत्तर देने में मदद करता है, "हम इसे कैसे संभव बना सकते हैं?" मूल रूप से, प्रिस्क्रिप्टिव एनालिटिक्स अनुकूलन और सिमुलेशन तकनीकों का उपयोग करके आगे बढ़ने के लिए सर्वोत्तम कार्रवाई की सिफारिश करता है। आमतौर पर, पूर्वानुमानित विश्लेषण और निर्देशात्मक विश्लेषण एक साथ चलते हैं क्योंकि पूर्वानुमानित विश्लेषण संभावित परिणाम खोजने में मदद करता है, जबकि निर्देशात्मक विश्लेषण उन परिणामों को देखता है और अधिक विकल्प ढूंढता है।
2. परिवर्तनीय-केंद्रित
उपलब्ध चरों की संख्या के आधार पर डेटा का विश्लेषण भी किया जा सकता है। इस संबंध में, चरों की संख्या के आधार पर, डेटा विश्लेषण तकनीकें एकचर, द्विचर या बहुभिन्नरूपी हो सकती हैं।
- वस्तु के एक प्रकार विश्लेषण: यूनीवेरिएट विश्लेषण में केंद्रीयता (माध्य, माध्य, मोड, और इसी तरह) और भिन्नता (मानक विचलन, मानक त्रुटि, भिन्नता, और इसी तरह) के उपायों का उपयोग करके एकल चर में मौजूद पैटर्न का विश्लेषण करना शामिल है।
- द्विचर विश्लेषण: ऐसे दो चर हैं जिनमें विश्लेषण कारण और दो चर के बीच संबंध से संबंधित है। ये दोनों चर एक दूसरे पर निर्भर या स्वतंत्र हो सकते हैं। सहसंबंध तकनीक सबसे अधिक उपयोग की जाने वाली द्विचर विश्लेषण तकनीक है।
- बहुभिन्नरूपी विश्लेषण: इस तकनीक का उपयोग दो से अधिक चरों का विश्लेषण करने के लिए किया जाता है। एक बहुभिन्नरूपी सेटिंग में, हम आम तौर पर पूर्वानुमानित विश्लेषण क्षेत्र में काम करते हैं और अधिकांश प्रसिद्ध मशीन लर्निंग (एमएल) एल्गोरिदम जैसे कि रैखिक प्रतिगमन, लॉजिस्टिक प्रतिगमन, प्रतिगमन पेड़, समर्थन वेक्टर मशीनें और तंत्रिका नेटवर्क आमतौर पर एक बहुभिन्नरूपी पर लागू होते हैं। सेटिंग।
3. पर्यवेक्षण-केंद्रित
तीसरे प्रकार का डेटा एनालिटिक्स फैब्रिक इनपुट डेटा या स्वतंत्र चर डेटा को प्रशिक्षित करने से संबंधित है जिसे किसी विशेष आउटपुट (यानी, निर्भर चर) के लिए लेबल किया गया है। मूलतः, स्वतंत्र चर वह है जिसे प्रयोगकर्ता नियंत्रित करता है। आश्रित चर वह चर है जो स्वतंत्र चर की प्रतिक्रिया में बदलता है। पर्यवेक्षण-केंद्रित डीएएफ दो प्रकारों में से एक हो सकता है।
- करणीय: लेबल किया गया डेटा, चाहे स्वचालित रूप से या मैन्युअल रूप से उत्पन्न हो, पर्यवेक्षित शिक्षण के लिए आवश्यक है। लेबल किया गया डेटा किसी को एक आश्रित चर को स्पष्ट रूप से परिभाषित करने की अनुमति देता है, और फिर यह एआई/एमएल टूल बनाने के लिए भविष्य कहनेवाला विश्लेषण एल्गोरिदम का मामला है जो लेबल (आश्रित चर) और स्वतंत्र चर के सेट के बीच संबंध बनाएगा। तथ्य यह है कि हमारे पास एक आश्रित चर की धारणा और स्वतंत्र चर के एक सेट के बीच एक अलग सीमांकन है, हम रिश्ते को सर्वोत्तम रूप से समझाने के लिए खुद को "कारण-कारण" शब्द का परिचय देने की अनुमति देते हैं।
- गैर-कार्यकारण: जब हम "पर्यवेक्षण-केंद्रित" को अपने आयाम के रूप में इंगित करते हैं, तो हमारा मतलब "पर्यवेक्षण की अनुपस्थिति" भी होता है, और यह गैर-कारण मॉडल को चर्चा में लाता है। गैर-कारण मॉडल उल्लेख के लायक हैं क्योंकि उन्हें लेबल किए गए डेटा की आवश्यकता नहीं है। यहां मूल तकनीक क्लस्टरिंग है, और सबसे लोकप्रिय विधियां के-मीन्स और पदानुक्रमित क्लस्टरिंग हैं।
4. डेटा प्रकार-केंद्रित
डेटा एनालिटिक्स फैब्रिक का यह आयाम या अभिव्यक्ति स्वतंत्र और आश्रित दोनों चर से संबंधित तीन अलग-अलग प्रकार के डेटा वेरिएबल्स पर केंद्रित है जो अंतर्दृष्टि प्राप्त करने के लिए डेटा एनालिटिक्स तकनीकों में उपयोग किए जाते हैं।
- नाममात्र का आकड़ा डेटा को लेबल करने या वर्गीकृत करने के लिए उपयोग किया जाता है। इसमें कोई संख्यात्मक मान शामिल नहीं है और इसलिए नाममात्र डेटा के साथ कोई सांख्यिकीय गणना संभव नहीं है। नाममात्र डेटा के उदाहरण लिंग, उत्पाद विवरण, ग्राहक का पता और इसी तरह के अन्य हैं।
- सामान्य या रैंक किया गया डेटा मूल्यों का क्रम है, लेकिन प्रत्येक के बीच अंतर वास्तव में ज्ञात नहीं है। यहां सामान्य उदाहरण बाजार पूंजीकरण, विक्रेता भुगतान शर्तों, ग्राहक संतुष्टि स्कोर, वितरण प्राथमिकता आदि के आधार पर कंपनियों की रैंकिंग कर रहे हैं।
- संख्यात्मक डेटा किसी परिचय की आवश्यकता नहीं है और इसका मूल्य संख्यात्मक है। ये चर सबसे मौलिक डेटा प्रकार हैं जिनका उपयोग सभी प्रकार के एल्गोरिदम को मॉडल करने के लिए किया जा सकता है।
5. परिणाम-केंद्रित
इस प्रकार का डेटा एनालिटिक्स फैब्रिक उन तरीकों को देखता है जिसमें एनालिटिक्स से प्राप्त अंतर्दृष्टि से व्यावसायिक मूल्य प्रदान किया जा सकता है। ऐसे दो तरीके हैं जिनसे व्यावसायिक मूल्य को एनालिटिक्स द्वारा संचालित किया जा सकता है, और वे उत्पाद या परियोजनाओं के माध्यम से हैं। जबकि उत्पादों को उपयोगकर्ता अनुभव और सॉफ्टवेयर इंजीनियरिंग के आसपास अतिरिक्त प्रभावों को संबोधित करने की आवश्यकता हो सकती है, मॉडल प्राप्त करने के लिए किया गया मॉडलिंग अभ्यास परियोजना और उत्पाद दोनों में समान होगा।
- A डेटा विश्लेषण उत्पाद व्यवसाय की दीर्घकालिक आवश्यकताओं को पूरा करने के लिए एक पुन: प्रयोज्य डेटा संपत्ति है। यह प्रासंगिक डेटा स्रोतों से डेटा एकत्र करता है, डेटा की गुणवत्ता सुनिश्चित करता है, इसे संसाधित करता है, और इसे किसी भी जरूरतमंद के लिए सुलभ बनाता है। उत्पाद आम तौर पर व्यक्तियों के लिए डिज़ाइन किए जाते हैं और उनके कई जीवनचक्र चरण या पुनरावृत्तियाँ होती हैं, जिस पर उत्पाद मूल्य का एहसास होता है।
- A डेटा विश्लेषण परियोजना किसी विशेष या विशिष्ट व्यावसायिक आवश्यकता को संबोधित करने के लिए डिज़ाइन किया गया है और इसका एक परिभाषित या संकीर्ण उपयोगकर्ता आधार या उद्देश्य है। मूल रूप से, एक परियोजना एक अस्थायी प्रयास है जिसका उद्देश्य एक निर्धारित दायरे में, बजट के भीतर और समय पर समाधान प्रदान करना है।
आने वाले वर्षों में दुनिया की अर्थव्यवस्था नाटकीय रूप से बदल जाएगी क्योंकि संगठन अंतर्दृष्टि प्राप्त करने और व्यावसायिक प्रदर्शन को मापने और सुधारने के लिए निर्णय लेने के लिए डेटा और एनालिटिक्स का तेजी से उपयोग करेंगे। मैकिन्से पाया गया कि जो कंपनियाँ अंतर्दृष्टि-संचालित हैं, वे EBITDA (ब्याज, कर, मूल्यह्रास और परिशोधन से पहले की कमाई) में 25% तक की वृद्धि दर्ज करती हैं [5]। हालाँकि, कई संगठन व्यावसायिक परिणामों में सुधार के लिए डेटा और एनालिटिक्स का लाभ उठाने में सफल नहीं हैं। लेकिन डेटा विश्लेषण प्रदान करने का कोई एक मानक तरीका या दृष्टिकोण नहीं है। डेटा एनालिटिक्स समाधानों की तैनाती या कार्यान्वयन व्यावसायिक उद्देश्यों, क्षमताओं और संसाधनों पर निर्भर करता है। यहां चर्चा की गई डीएएफ और इसकी पांच अभिव्यक्तियां व्यावसायिक आवश्यकताओं, उपलब्ध क्षमताओं और संसाधनों के आधार पर विश्लेषण को प्रभावी ढंग से तैनात करने में सक्षम बना सकती हैं।
संदर्भ
- mckinsey.com/capability/growth-marketing-and-sales/our-insights/ five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-फर्म-अपने-साथियों की तुलना में 26-अधिक-लाभकारी हैं/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- साउथेकल, प्रशांत, "एनालिटिक्स बेस्ट प्रैक्टिसेस", टेक्निक्स, 2020
- mckinsey.com/capability/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. ऑटोमोटिव/ईवीएस, कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- चार्टप्राइम. चार्टप्राइम के साथ अपने ट्रेडिंग गेम को उन्नत करें। यहां पहुंचें।
- BlockOffsets. पर्यावरणीय ऑफसेट स्वामित्व का आधुनिकीकरण। यहां पहुंचें।
- स्रोत: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- :हैस
- :है
- :नहीं
- $यूपी
- 1
- 19
- 23
- a
- About
- सुलभ
- अधिग्रहण
- कार्य
- अतिरिक्त
- पता
- ऐ / एमएल
- कलन विधि
- एल्गोरिदम
- सब
- अनुमति देना
- की अनुमति देता है
- भी
- ऋणमुक्ति
- an
- विश्लेषण
- विश्लेषिकी
- विश्लेषण करें
- विश्लेषण किया
- का विश्लेषण
- और
- जवाब
- कोई
- किसी
- लागू
- दृष्टिकोण
- हैं
- अखाड़ा
- चारों ओर
- AS
- आस्ति
- At
- स्वतः
- उपलब्ध
- b
- पृष्ठभूमि
- आधार
- आधारित
- बुनियादी
- मूल रूप से
- BE
- क्योंकि
- किया गया
- से पहले
- जा रहा है
- नीचे
- BEST
- के बीच
- के छात्रों
- लाता है
- बजट
- निर्माण
- व्यापार
- व्यापार की उपलब्धि
- लेकिन
- by
- कर सकते हैं
- क्षमताओं
- पूंजीकरण
- वर्गीकरण
- कारण
- केन्द्रीयता
- परिवर्तन
- स्पष्ट रूप से
- गुच्छन
- एकत्र
- COM
- अ रहे है
- सामान्य
- सामान्यतः
- कंपनियों
- घटकों
- संकल्पना
- निष्कर्ष निकाला है
- संचालित
- विरोधी
- नियंत्रण
- मूल
- सह - संबंध
- सका
- पाठ्यक्रम
- संस्कृति
- ग्राहक
- ग्राहक संतुष्टि
- ग्राहक
- तिथि
- डेटा विश्लेषण
- डेटा विश्लेषण
- आँकड़े की गुणवत्ता
- डेटा सेट
- डेटा सेट
- डेटा पर ही आधारित
- डेटावर्सिटी
- सौदा
- निर्णय
- निर्णय
- परिभाषित
- परिभाषित
- उद्धार
- दिया गया
- प्रसव
- निर्भर
- निर्भर करता है
- तैनात
- तैनाती
- मूल्यह्रास
- निकाली गई
- विवरण
- लायक
- बनाया गया
- के बावजूद
- विचलन
- मतभेद
- विभिन्न
- डिजिटली
- आयाम
- चर्चा की
- चर्चा
- अलग
- do
- कर देता है
- किया
- नाटकीय रूप से
- संचालित
- दो
- e
- से प्रत्येक
- कमाई
- एबिटा
- अर्थव्यवस्था
- पारिस्थितिकी तंत्र
- प्रभावी रूप से
- भी
- सक्षम
- सक्षम बनाता है
- प्रयास
- अभियांत्रिकी
- सुनिश्चित
- त्रुटि
- आवश्यक
- घटनाओं
- उदाहरण
- व्यायाम
- अनुभव
- समझाना
- बताते हैं
- अन्वेषणात्मक डेटा विश्लेषण
- कपड़ा
- तथ्य
- असफल
- खोज
- निष्कर्ष
- पाता
- फर्मों
- पांच
- केंद्रित
- के लिए
- फ़ोर्ब्स
- पूर्वानुमान
- आगे
- पाया
- से
- समारोह
- मौलिक
- भविष्य
- गार्टनर
- लिंग
- उत्पन्न
- Go
- लक्ष्य
- होना
- हुआ
- है
- मदद करता है
- इसलिये
- यहाँ उत्पन्न करें
- ऐतिहासिक
- तथापि
- HTTPS
- i
- आईबीएम
- पहचान करना
- लागू करने के
- कार्यान्वयन
- में सुधार
- उन्नत
- में सुधार लाने
- in
- बढ़ जाती है
- तेजी
- स्वतंत्र
- संकेत मिलता है
- निवेश
- अंतर्दृष्टि
- इरादा
- ब्याज
- परिचय कराना
- शुरू करने
- परिचय
- शामिल करना
- शामिल
- IT
- पुनरावृत्तियों
- आईटी इस
- कुंजी
- जानने वाला
- लेबल
- लेबलिंग
- बड़ा
- सीख रहा हूँ
- लाभ
- जीवन चक्र
- पसंद
- संभावित
- लंबे समय तक
- देख
- लग रहा है
- मशीन
- यंत्र अधिगम
- मशीनें
- मुख्य
- बनाना
- बनाता है
- मैन्युअल
- बहुत
- बाजार
- बाजार पूंजीकरण
- बात
- परिपक्व
- अधिकतम-चौड़ाई
- मई..
- मैकिन्से
- मतलब
- माप
- उपायों
- उल्लेख
- तरीकों
- एमआईटी
- ML
- मोड
- आदर्श
- मोडलिंग
- मॉडल
- अधिक
- अधिकांश
- सबसे लोकप्रिय
- चलती
- विभिन्न
- आवश्यकता
- की जरूरत है
- नेटवर्क
- तंत्रिका
- तंत्रिका जाल
- कभी नहीँ
- नहीं
- ग़ैर-लाभकारी
- धारणा
- संख्या
- उद्देश्य
- of
- on
- ONE
- संचालित
- इष्टतमीकरण
- ऑप्शंस
- or
- आदेश
- संगठन
- संगठनों
- अन्य
- हमारी
- आप
- परिणामों
- उत्पादन
- के ऊपर
- विशेष
- पैटर्न
- पैटर्न उपयोग करें
- भुगतान
- प्रदर्शन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- लोकप्रिय
- आबादी
- संभव
- संभावित
- भविष्यवाणियों
- भविष्य कहनेवाला
- भविष्य कहनेवाला विश्लेषण
- भविष्य कहनेवाला विश्लेषिकी
- वर्तमान
- प्राथमिक
- प्राथमिकता
- प्रक्रिया
- प्रक्रियाओं
- एस्ट्रो मॉल
- उत्पाद
- लाभ
- लाभदायक
- परियोजना
- परियोजनाओं
- उद्देश्य
- गुणवत्ता
- प्रश्न
- असर
- वें स्थान पर
- रैंकिंग
- एहसास हुआ
- वास्तव में
- की सिफारिश की
- सम्मान
- प्रतीपगमन
- सम्बंधित
- संबंध
- रिश्ते
- प्रासंगिक
- रिपोर्ट
- की आवश्यकता होती है
- अपेक्षित
- उपयुक्त संसाधन चुनें
- प्रतिक्रिया
- बनाए रखने के
- पुन: प्रयोज्य
- संतोष
- क्षेत्र
- स्कोर
- सेवा
- सेट
- सेट
- की स्थापना
- दिखाया
- दिखाता है
- समान
- अनुकार
- एक
- छह
- So
- सॉफ्टवेयर
- सॉफ्टवेयर इंजीनियरिंग
- समाधान
- समाधान ढूंढे
- स्रोत
- सूत्रों का कहना है
- चरणों
- मानक
- सांख्यिकीय
- सामरिक
- संरचना
- संघर्ष
- सफल
- सफलतापूर्वक
- ऐसा
- संक्षेप में प्रस्तुत करना
- पर्यवेक्षित अध्ययन
- पर्यवेक्षण
- समर्थन
- प्रणाली
- कर
- तकनीक
- टेक्नोलॉजीज
- अस्थायी
- अवधि
- शर्तों
- से
- कि
- RSI
- दुनिया
- लेकिन हाल ही
- फिर
- वहाँ।
- इन
- वे
- तीसरा
- इसका
- उन
- तीन
- यहाँ
- पहर
- बार
- सेवा मेरे
- एक साथ
- साधन
- प्रशिक्षण
- बदालना
- पेड़
- रुझान
- दो
- टाइप
- प्रकार
- आम तौर पर
- अद्वितीय
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ता अनुभव
- का उपयोग
- मूल्य
- मान
- परिवर्तनशील
- विक्रेता
- मार्ग..
- तरीके
- we
- प्रसिद्ध
- कब
- या
- कौन कौन से
- जब
- कौन
- मर्जी
- साथ में
- अंदर
- विश्व
- दुनिया की
- होगा
- साल
- जेफिरनेट









