अधिक सक्षम, तेज, छोटी और कम बिजली प्रणालियों की दिशा में आगे बढ़ते हुए, मूर के कानून ने सॉफ्टवेयर को 30 से अधिक वर्षों तक पूरी तरह से सेमीकंडक्टर प्रक्रिया विकास पर मुफ्त सवारी प्रदान की। कंप्यूट हार्डवेयर ने हर साल बेहतर प्रदर्शन/क्षेत्र/पावर मेट्रिक्स प्रदान किए, जिससे सॉफ्टवेयर को जटिलता में विस्तार करने और बिना किसी नकारात्मक पहलू के अधिक क्षमता प्रदान करने की अनुमति मिली। फिर आसान जीत कम आसान हो गई. अधिक उन्नत प्रक्रियाओं ने प्रति यूनिट क्षेत्र में उच्च गेट गिनती प्रदान करना जारी रखा लेकिन प्रदर्शन और शक्ति में लाभ कम होने लगा। चूंकि नवप्रवर्तन के प्रति हमारी अपेक्षाएं बंद नहीं हुई हैं, हार्डवेयर वास्तुकला में प्रगति सुस्ती को दूर करने में अधिक महत्वपूर्ण हो गई है।

कोर-गिनती बढ़ाने के लिए ड्राइवर
इस दिशा में एक प्रारंभिक कदम में कोर में समवर्ती कार्यों के मिश्रण को थ्रेडिंग या वर्चुअलाइज करके कुल थ्रूपुट में तेजी लाने के लिए मल्टी-कोर सीपीयू का उपयोग किया गया, निष्क्रिय कोर को निष्क्रिय करके या पावर डाउन करके आवश्यकतानुसार बिजली को कम किया गया। मल्टी-कोर आज मानक है और एडब्ल्यूएस, एज़्योर, अलीबाबा और अन्य के क्लाउड प्लेटफ़ॉर्म में उपलब्ध सर्वर इंस्टेंस विकल्पों में कई-कोर (एक चिप पर और भी अधिक सीपीयू) का चलन पहले से ही स्पष्ट है।
मल्टी-/मैनी-कोर आर्किटेक्चर एक कदम आगे है, लेकिन सीपीयू क्लस्टर के माध्यम से समानता मोटे तौर पर है और इसकी अपनी प्रदर्शन और शक्ति सीमाएं हैं, अमदहल के कानून के लिए धन्यवाद। छवि, ऑडियो और अन्य विशिष्ट आवश्यकताओं के लिए त्वरक जोड़कर आर्किटेक्चर अधिक विविध हो गए। एआई त्वरक ने सिस्टोलिक सरणियों और अन्य डोमेन-विशिष्ट तकनीकों की ओर बढ़ते हुए, बारीक समानता को भी आगे बढ़ाया है। जो तब तक बहुत अच्छी तरह से काम कर रहा था जब तक चैटजीपीटी 175 अरब मापदंडों के साथ प्रकट नहीं हुआ, जीपीटी-3 4 ट्रिलियन मापदंडों के साथ जीपीटी-100 में विकसित हुआ - जो आज के एआई सिस्टम की तुलना में अधिक जटिल है - एआई त्वरक के भीतर और भी अधिक विशिष्ट त्वरण सुविधाओं को मजबूर करता है।
एक अलग मोर्चे पर, ऑटोमोटिव अनुप्रयोगों में मल्टी-सेंसर सिस्टम अब बेहतर पर्यावरण जागरूकता और बेहतर पीपीए के लिए एकल एसओसी में एकीकृत हो रहे हैं। यहां, ऑटोमोटिव में स्वायत्तता के नए स्तर 2X, 4X या 8X द्वारा प्रतिकृति उप-प्रणालियों में एक ही डिवाइस के भीतर कई सेंसर प्रकारों से जुड़े इनपुट पर निर्भर करते हैं।
माइकल सिविंस्की (आर्टेरिस में सीएमओ) के अनुसार, अनुप्रयोगों की एक विस्तृत श्रृंखला में कई डिज़ाइन टीमों के साथ एक महीने की चर्चा के नमूने से पता चलता है कि वे टीमें क्षमता, प्रदर्शन और शक्ति लक्ष्यों को पूरा करने के लिए सक्रिय रूप से उच्च कोर गणनाओं की ओर रुख कर रही हैं। उन्होंने मुझसे कहा कि वे भी इस प्रवृत्ति को तेज़ होते हुए देख रहे हैं। प्रक्रिया में प्रगति अभी भी एसओसी गेट गिनती में मदद करती है, लेकिन प्रदर्शन और बिजली लक्ष्यों को पूरा करने की जिम्मेदारी अब आर्किटेक्ट्स के हाथों में है।
अधिक कोर, अधिक इंटरकनेक्ट
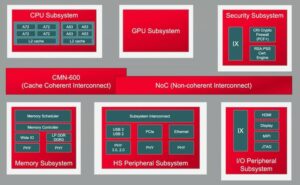
एक चिप पर अधिक कोर उन कोर के बीच अधिक डेटा कनेक्शन का संकेत देते हैं। पड़ोसी प्रसंस्करण तत्वों के बीच एक त्वरक के भीतर, स्थानीय कैश के लिए, विरल मैट्रिक्स और अन्य विशेष हैंडलिंग के लिए त्वरक तक। एक्सेलेरेटर टाइल्स और सिस्टम लेवल बसों के बीच पदानुक्रमित कनेक्टिविटी जोड़ें। ऑन-चिप वेट स्टोरेज, डीकंप्रेसन, प्रसारण, इकट्ठा करने और पुनः संपीड़न के लिए कनेक्टिविटी जोड़ें। कार्यशील कैश के लिए HBM कनेक्टिविटी जोड़ें। यदि आवश्यक हो तो फ़्यूज़न इंजन जोड़ें।
सीपीयू-आधारित नियंत्रण क्लस्टर को उन प्रतिकृति उप-प्रणालियों में से प्रत्येक और सभी सामान्य कार्यों से कनेक्ट होना चाहिए - यदि उपयुक्त हो तो कोडेक्स, मेमोरी प्रबंधन, सुरक्षा द्वीप और ट्रस्ट की जड़, मल्टी-चिपलेट कार्यान्वयन के लिए यूसीआईई, उच्च बैंडविड्थ I/O के लिए पीसीआईई , और नेटवर्किंग के लिए ईथरनेट या फाइबर।
यह बहुत अधिक अंतर्संबंध है, जिसका सीधा परिणाम उत्पाद की विपणन क्षमता पर पड़ता है। 16एनएम से नीचे की प्रक्रियाओं में, एनओसी इंफ्रास्ट्रक्चर अब क्षेत्र में 10-12% का योगदान देता है। इससे भी अधिक महत्वपूर्ण, कोर के बीच संचार राजमार्ग के रूप में, यह प्रदर्शन और शक्ति पर महत्वपूर्ण प्रभाव डाल सकता है। वास्तविक ख़तरा है कि एक उप-इष्टतम कार्यान्वयन अपेक्षित वास्तुकला प्रदर्शन और शक्ति लाभ को बर्बाद कर देगा, या इससे भी बदतर, कई पुन: डिज़ाइन लूपों को एक साथ लाने का परिणाम होगा। फिर भी एक जटिल SoC फ़्लोरप्लान में एक अच्छा कार्यान्वयन ढूंढना अभी भी पहले से ही तंग डिज़ाइन शेड्यूल में धीमी परीक्षण-और-त्रुटि अनुकूलन पर निर्भर करता है। जटिल NoC पदानुक्रमों से पूर्ण प्रदर्शन और शक्ति समर्थन की गारंटी के लिए, हमें भौतिक रूप से जागरूक NoC डिज़ाइन की ओर छलांग लगाने की आवश्यकता है और हमें इन अनुकूलन को तेज़ बनाने की आवश्यकता है।
शारीरिक रूप से जागरूक एनओसी डिज़ाइन मूर के नियम को ट्रैक पर रखता है
मूर का नियम ख़त्म नहीं हुआ है, लेकिन आज प्रदर्शन और शक्ति में प्रगति प्रक्रिया के बजाय वास्तुकला और एनओसी इंटरकनेक्ट से आती है। आर्किटेक्चर अधिक त्वरक कोर, त्वरक के भीतर अधिक त्वरक, और चिप पर अधिक सबसिस्टम प्रतिकृति पर जोर दे रहा है। ये सभी ऑन-चिप इंटरकनेक्ट की जटिलता को बढ़ाते हैं। जैसे-जैसे डिज़ाइन कोर गिनती बढ़ाते हैं और 16 एनएम और उससे कम पर ज्यामिति को संसाधित करने के लिए आगे बढ़ते हैं, एसओसी और इसके उप-प्रणालियों में फैले कई एनओसी इंटरकनेक्ट केवल इन जटिल डिजाइनों की पूरी क्षमता का समर्थन कर सकते हैं यदि भौतिक और समय की बाधाओं के खिलाफ भौतिक रूप से जागरूक नेटवर्क के माध्यम से इष्टतम ढंग से कार्यान्वित किया जाता है। चिप डिजाइन पर.
यदि आप भी इन रुझानों के बारे में चिंतित हैं, तो आप Arteris FlexNoC 5 IP तकनीक के बारे में अधिक जानना चाहेंगे यहाँ.
इस पोस्ट को इसके माध्यम से साझा करें:
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :है
- $यूपी
- 100
- a
- About
- में तेजी लाने के
- तेज
- त्वरण
- त्वरक
- त्वरक
- के पार
- सक्रिय रूप से
- उन्नत
- अग्रिमों
- के खिलाफ
- AI
- एआई सिस्टम
- अलीबाबा
- सब
- की अनुमति दे
- पहले ही
- और
- छपी
- अनुप्रयोगों
- उपयुक्त
- स्थापत्य
- हैं
- क्षेत्र
- AS
- At
- ऑडियो
- मोटर वाहन
- उपलब्ध
- जागरूकता
- एडब्ल्यूएस
- नीला
- बैंडविड्थ
- BE
- बन
- नीचे
- के बीच
- बिलियन
- प्रसारण
- बसें
- by
- कैश
- कर सकते हैं
- सक्षम
- ChatGPT
- टुकड़ा
- बादल
- समूह
- सीएमओ
- कैसे
- संचार
- जटिल
- जटिलता
- गणना करना
- समवर्ती
- जुडिये
- कनेक्शन
- कनेक्टिविटी
- Consequences
- की कमी
- निरंतर
- नियंत्रण
- मिलना
- मूल
- सी पी यू
- खतरा
- तिथि
- मृत
- उद्धार
- दिया गया
- निर्भर करता है
- डिज़ाइन
- डिजाइन
- युक्ति
- विभिन्न
- प्रत्यक्ष
- दिशा
- विचार - विमर्श
- नीचे
- कमियां
- से प्रत्येक
- शीघ्र
- तत्व
- इंजन
- वातावरण
- और भी
- प्रत्येक
- विकास
- उद्विकासी
- विस्तार
- उम्मीदों
- अपेक्षित
- और तेज
- विशेषताएं
- खोज
- दृढ़ता से
- के लिए
- आगे
- मुक्त
- से
- सामने
- पूर्ण
- कार्यों
- संलयन
- लाभ
- लक्ष्यों
- अच्छा
- गारंटी
- हैंडलिंग
- हाथ
- हार्डवेयर
- है
- मदद
- यहाँ उत्पन्न करें
- हाई
- उच्चतर
- राजमार्ग
- HTTPS
- की छवि
- प्रभाव
- कार्यान्वयन
- कार्यान्वित
- महत्वपूर्ण
- उन्नत
- in
- निष्क्रिय
- बढ़ना
- बढ़ती
- इंफ्रास्ट्रक्चर
- नवोन्मेष
- उदाहरण
- घालमेल
- IP
- द्वीप
- IT
- आईटी इस
- छलांग
- कानून
- जानें
- स्तर
- स्तर
- सीमाएं
- स्थानीय
- लॉट
- बनाना
- प्रबंध
- मार्च
- मैट्रिक्स
- अधिकतम-चौड़ाई
- मिलना
- बैठक
- याद
- मेट्रिक्स
- हो सकता है
- महीना
- अधिक
- चाल
- चलती
- विभिन्न
- आवश्यकता
- जरूरत
- की जरूरत है
- नेटवर्क
- शुद्ध कार्यशील
- नया
- अनेक
- of
- on
- ऑप्शंस
- आदेशों
- अन्य
- अन्य
- अपना
- पैरामीटर
- प्रदर्शन
- भौतिक
- शारीरिक रूप से
- प्लेटफार्म
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- पद
- संभावित
- बिजली
- शक्ति
- सुंदर
- प्रक्रिया
- प्रक्रियाओं
- प्रसंस्करण
- एस्ट्रो मॉल
- विशुद्ध रूप से
- धकेल दिया
- धक्का
- रेंज
- बल्कि
- वास्तविक
- को कम करने
- दोहराया
- प्रतिकृति
- जिम्मेदारी
- परिणाम
- सवारी
- जड़
- सुरक्षा
- अर्धचालक
- महत्वपूर्ण
- के बाद से
- एक
- ढीला
- धीमा
- छोटे
- So
- सॉफ्टवेयर
- विरल मैट्रिक्स
- विशेषीकृत
- सुर्ख़ियाँ
- मानक
- शुरू
- कदम
- फिर भी
- रुकें
- भंडारण
- पता चलता है
- समर्थन
- प्रणाली
- सिस्टम
- कार्य
- टीमों
- तकनीक
- टेक्नोलॉजी
- बताता है
- कि
- RSI
- इन
- यहाँ
- THROUGHPUT
- समय
- सेवा मेरे
- आज
- आज का दि
- कुल
- प्रवृत्ति
- रुझान
- खरब
- ट्रस्ट
- मोड़
- प्रकार
- के अंतर्गत
- इकाई
- के माध्यम से
- भार
- कुंआ
- कौन कौन से
- चौड़ा
- विस्तृत श्रृंखला
- मर्जी
- जीत
- साथ में
- अंदर
- काम कर रहे
- वर्ष
- साल
- जेफिरनेट