जेनरेटिव एआई वर्कलोड के लिए सबसे उपयोगी एप्लिकेशन पैटर्न में से एक रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) है। आरएजी पैटर्न में, हम एम्बेडिंग पर समानता खोज करके इनपुट प्रॉम्प्ट से संबंधित संदर्भ सामग्री के टुकड़े पाते हैं। एंबेडिंग पाठ के मुख्य भाग में सूचना सामग्री को कैप्चर करती है, जिससे प्राकृतिक भाषा प्रसंस्करण (एनएलपी) मॉडल को संख्यात्मक रूप में भाषा के साथ काम करने की अनुमति मिलती है। एंबेडिंग केवल फ़्लोटिंग पॉइंट संख्याओं के वेक्टर हैं, इसलिए हम तीन महत्वपूर्ण प्रश्नों के उत्तर देने में सहायता के लिए उनका विश्लेषण कर सकते हैं: क्या हमारा संदर्भ डेटा समय के साथ बदल रहा है? क्या उपयोगकर्ता जो प्रश्न पूछ रहे हैं वे समय के साथ बदल रहे हैं? और अंततः, हमारा संदर्भ डेटा पूछे जाने वाले प्रश्नों को कितनी अच्छी तरह कवर कर रहा है?
इस पोस्ट में, आप एम्बेडिंग वेक्टर विश्लेषण और एम्बेडिंग बहाव के संकेतों का पता लगाने के लिए कुछ विचारों के बारे में जानेंगे। क्योंकि एम्बेडिंग सामान्य रूप से एनएलपी मॉडल और विशेष रूप से जेनरेटिव एआई समाधानों के लिए डेटा का एक महत्वपूर्ण स्रोत है, हमें यह मापने का एक तरीका चाहिए कि क्या हमारी एम्बेडिंग समय के साथ बदल रही है (बहती है)। इस पोस्ट में, आप बड़े भाषा मॉडल (एलएलएमएस) के साथ क्लस्टरिंग तकनीक का उपयोग करके एम्बेडिंग वैक्टर पर बहाव का पता लगाने का एक उदाहरण देखेंगे। अमेज़न SageMaker जम्पस्टार्ट. आप दिए गए दो उदाहरणों के माध्यम से भी इन अवधारणाओं का पता लगाने में सक्षम होंगे, जिसमें एक एंड-टू-एंड नमूना एप्लिकेशन या, वैकल्पिक रूप से, एप्लिकेशन का एक सबसेट शामिल है।
आरएजी का अवलोकन
RSI आरएजी पैटर्न आपको बाहरी स्रोतों, जैसे पीडीएफ दस्तावेज़, विकी लेख, या कॉल ट्रांसक्रिप्ट से ज्ञान प्राप्त करने देता है, और फिर उस ज्ञान का उपयोग एलएलएम को भेजे गए निर्देश संकेत को बढ़ाने के लिए करता है। यह एलएलएम को प्रतिक्रिया उत्पन्न करते समय अधिक प्रासंगिक जानकारी का संदर्भ देने की अनुमति देता है। उदाहरण के लिए, यदि आप एलएलएम से चॉकलेट चिप कुकीज बनाने का तरीका पूछते हैं, तो इसमें आपकी अपनी रेसिपी लाइब्रेरी से जानकारी शामिल हो सकती है। इस पैटर्न में, रेसिपी टेक्स्ट को एक एम्बेडिंग मॉडल का उपयोग करके एम्बेडिंग वैक्टर में परिवर्तित किया जाता है, और एक वेक्टर डेटाबेस में संग्रहीत किया जाता है। आने वाले प्रश्नों को एम्बेडिंग में बदल दिया जाता है, और फिर वेक्टर डेटाबेस संबंधित सामग्री को खोजने के लिए एक समानता खोज चलाता है। फिर प्रश्न और संदर्भ डेटा एलएलएम के लिए प्रॉम्प्ट में चला जाता है।
आइए बनाए गए एम्बेडिंग वैक्टरों पर करीब से नज़र डालें और उन वैक्टरों पर ड्रिफ्ट विश्लेषण कैसे करें।
एम्बेडिंग वैक्टर पर विश्लेषण
एम्बेडिंग वेक्टर हमारे डेटा का संख्यात्मक प्रतिनिधित्व हैं इसलिए इन वैक्टर का विश्लेषण हमारे संदर्भ डेटा में अंतर्दृष्टि प्रदान कर सकता है जिसका उपयोग बाद में बहाव के संभावित संकेतों का पता लगाने के लिए किया जा सकता है। एम्बेडिंग वेक्टर एन-आयामी स्थान में एक आइटम का प्रतिनिधित्व करते हैं, जहां एन अक्सर बड़ा होता है। उदाहरण के लिए, इस पोस्ट में प्रयुक्त GPT-J 6B मॉडल, 4096 आकार के वेक्टर बनाता है। बहाव को मापने के लिए, मान लें कि हमारा एप्लिकेशन संदर्भ डेटा और आने वाले संकेतों दोनों के लिए एम्बेडिंग वैक्टर को कैप्चर करता है।
हम प्रिंसिपल कंपोनेंट एनालिसिस (पीसीए) का उपयोग करके आयाम में कमी करके शुरुआत करते हैं। पीसीए डेटा में अधिकांश भिन्नताओं को संरक्षित करते हुए आयामों की संख्या को कम करने का प्रयास करता है। इस मामले में, हम उन आयामों की संख्या खोजने का प्रयास करते हैं जो 95% विचरण को संरक्षित करते हैं, जो दो मानक विचलन के भीतर कुछ भी कैप्चर करना चाहिए।
फिर हम क्लस्टर केंद्रों के एक सेट की पहचान करने के लिए K-मीन्स का उपयोग करते हैं। के-मीन्स बिंदुओं को एक साथ समूहों में समूहित करने का प्रयास करता है ताकि प्रत्येक क्लस्टर अपेक्षाकृत कॉम्पैक्ट हो और क्लस्टर एक दूसरे से यथासंभव दूर हों।
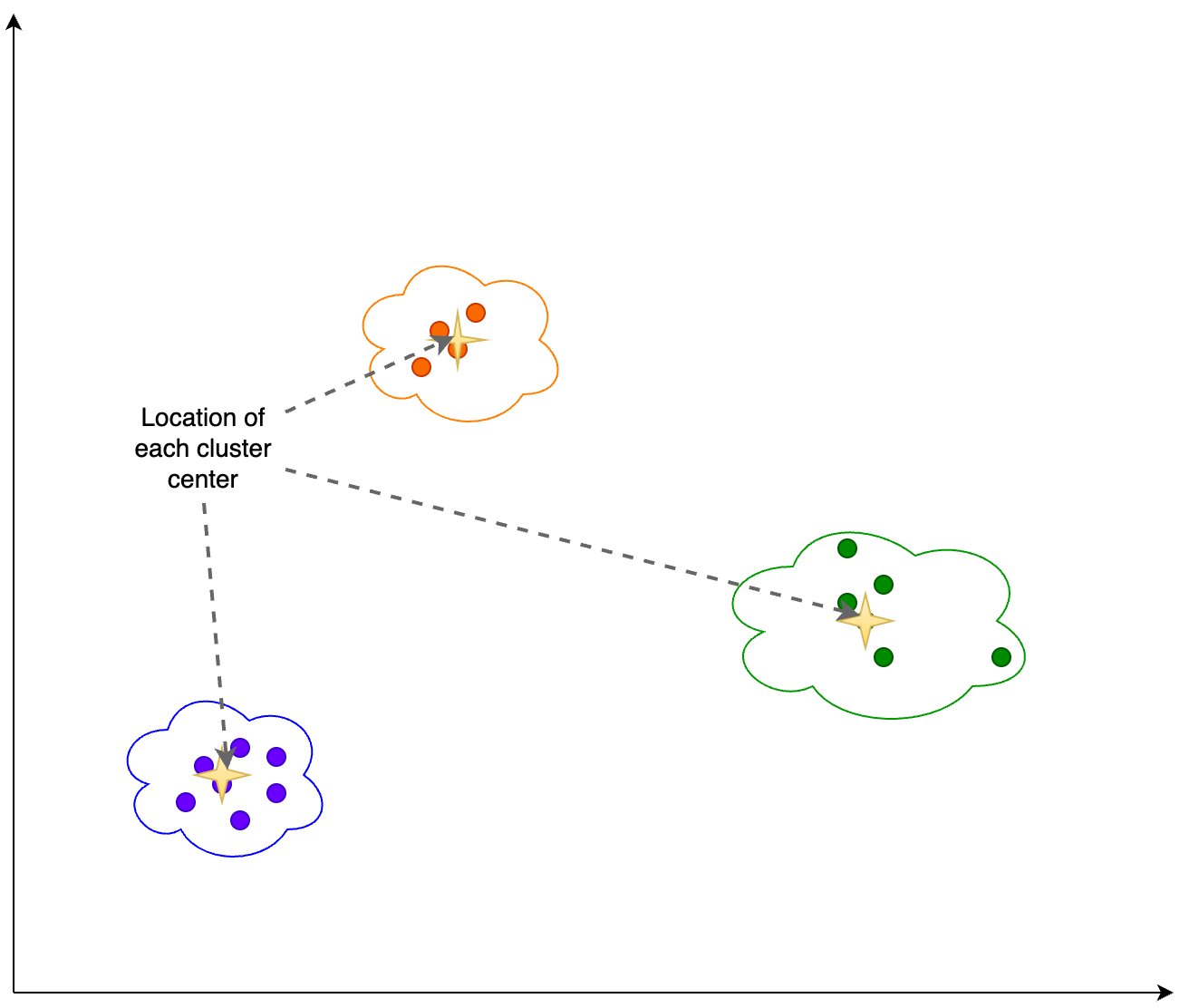
हम निम्नलिखित चित्र में दिखाए गए क्लस्टरिंग आउटपुट के आधार पर निम्नलिखित जानकारी की गणना करते हैं:
- पीसीए में आयामों की संख्या जो 95% विचरण की व्याख्या करती है
- प्रत्येक क्लस्टर केंद्र, या केन्द्रक का स्थान
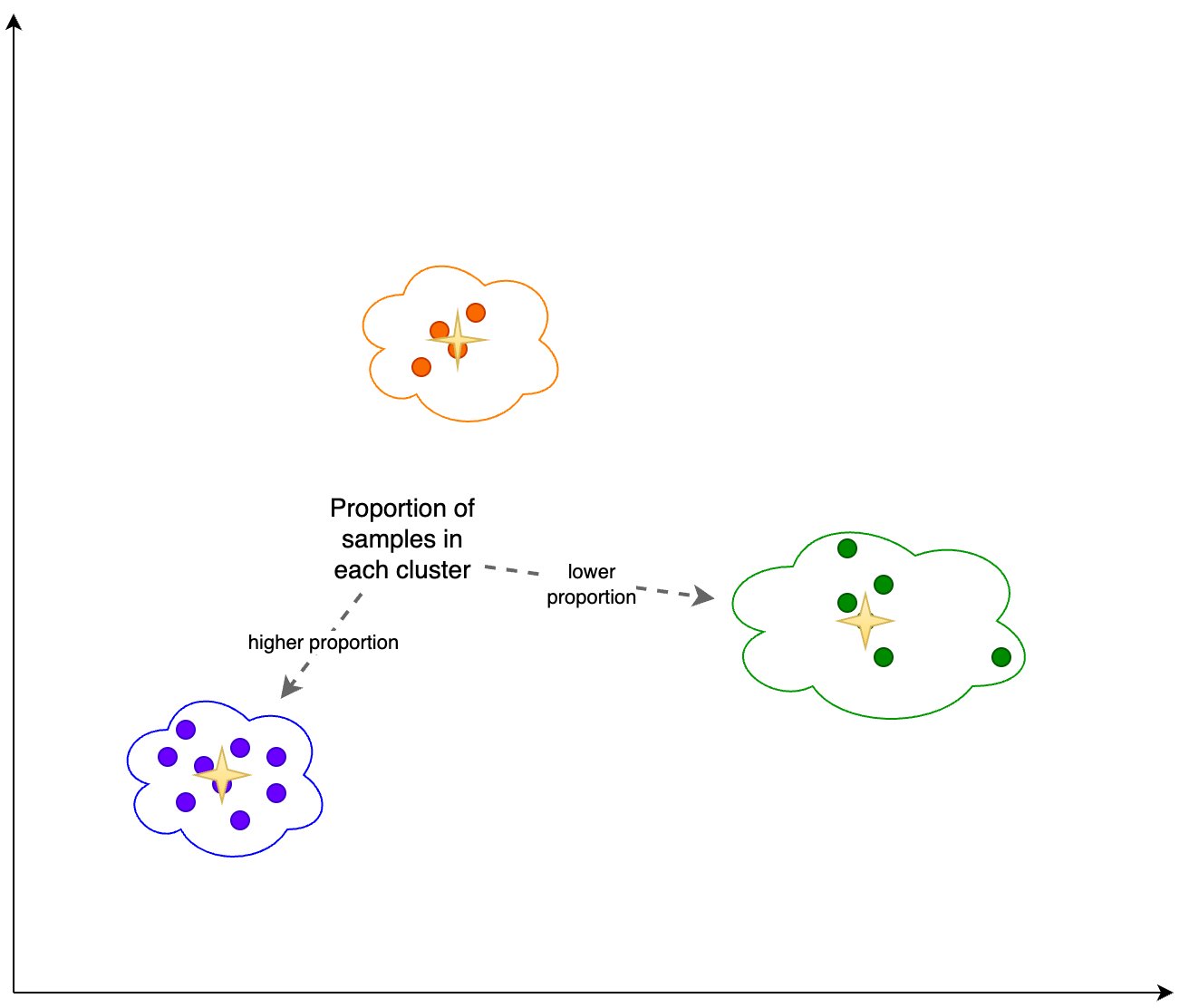
इसके अतिरिक्त, हम प्रत्येक क्लस्टर में नमूनों के अनुपात (उच्च या निम्न) को देखते हैं, जैसा कि निम्नलिखित आंकड़े में दिखाया गया है।
अंत में, हम इस विश्लेषण का उपयोग निम्नलिखित की गणना करने के लिए करते हैं:
- इनेरशिया - जड़ता क्लस्टर सेंट्रोइड्स के लिए वर्ग दूरी का योग है, जो मापता है कि के-मीन्स का उपयोग करके डेटा को कितनी अच्छी तरह क्लस्टर किया गया था।
- सिल्हूट स्कोर - सिल्हूट स्कोर क्लस्टर के भीतर स्थिरता के सत्यापन के लिए एक उपाय है, और -1 से 1 तक होता है। 1 के करीब मान का मतलब है कि क्लस्टर में बिंदु उसी क्लस्टर में अन्य बिंदुओं के करीब हैं और दूर हैं अन्य समूहों के बिंदु. सिल्हूट स्कोर का एक दृश्य प्रतिनिधित्व निम्नलिखित चित्र में देखा जा सकता है।

हम समय-समय पर स्रोत संदर्भ डेटा और संकेतों दोनों के लिए एम्बेडिंग के स्नैपशॉट के लिए इस जानकारी को कैप्चर कर सकते हैं। इस डेटा को कैप्चर करने से हमें एम्बेडिंग ड्रिफ्ट के संभावित संकेतों का विश्लेषण करने की अनुमति मिलती है।
एम्बेडिंग बहाव का पता लगाना
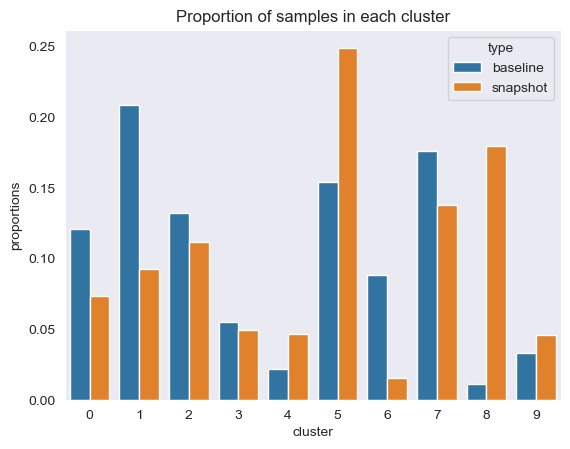
समय-समय पर, हम डेटा के स्नैपशॉट के माध्यम से क्लस्टरिंग जानकारी की तुलना कर सकते हैं, जिसमें संदर्भ डेटा एम्बेडिंग और प्रॉम्प्ट एम्बेडिंग शामिल हैं। सबसे पहले, हम क्लस्टरिंग कार्य से एम्बेडिंग डेटा, जड़ता और सिल्हूट स्कोर में 95% भिन्नता को समझाने के लिए आवश्यक आयामों की संख्या की तुलना कर सकते हैं। जैसा कि आप निम्न तालिका में देख सकते हैं, बेसलाइन की तुलना में, एम्बेडिंग के नवीनतम स्नैपशॉट को भिन्नता को समझाने के लिए 39 और आयामों की आवश्यकता होती है, जो दर्शाता है कि हमारा डेटा अधिक बिखरा हुआ है। जड़ता बढ़ गई है, जो दर्शाता है कि नमूने कुल मिलाकर अपने क्लस्टर केंद्रों से बहुत दूर हैं। इसके अतिरिक्त, सिल्हूट स्कोर कम हो गया है, जो दर्शाता है कि क्लस्टर अच्छी तरह से परिभाषित नहीं हैं। त्वरित डेटा के लिए, यह संकेत दे सकता है कि सिस्टम में आने वाले प्रश्नों के प्रकार अधिक विषयों को कवर कर रहे हैं।
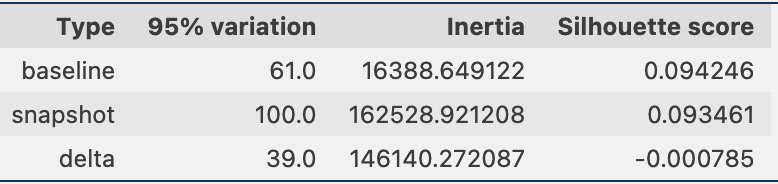
आगे, निम्नलिखित आंकड़े में, हम देख सकते हैं कि समय के साथ प्रत्येक क्लस्टर में नमूनों का अनुपात कैसे बदल गया है। यह हमें दिखा सकता है कि क्या हमारा नया संदर्भ डेटा मोटे तौर पर पिछले सेट के समान है, या नए क्षेत्रों को कवर करता है।
अंत में, हम देख सकते हैं कि क्या क्लस्टर केंद्र घूम रहे हैं, जो क्लस्टर में जानकारी में बहाव दिखाएगा, जैसा कि निम्नलिखित तालिका में दिखाया गया है।

आने वाले प्रश्नों के लिए संदर्भ डेटा कवरेज
हम यह भी मूल्यांकन कर सकते हैं कि हमारा संदर्भ डेटा आने वाले प्रश्नों के साथ कितनी अच्छी तरह मेल खाता है। ऐसा करने के लिए, हम प्रत्येक प्रॉम्प्ट एम्बेडिंग को एक संदर्भ डेटा क्लस्टर में निर्दिष्ट करते हैं। हम प्रत्येक प्रॉम्प्ट से उसके संबंधित केंद्र तक की दूरी की गणना करते हैं, और उन दूरियों के माध्य, माध्यिका और मानक विचलन को देखते हैं। हम उस जानकारी को संग्रहीत कर सकते हैं और देख सकते हैं कि यह समय के साथ कैसे बदलती है।
निम्नलिखित आंकड़ा समय के साथ प्रॉम्प्ट एम्बेडिंग और संदर्भ डेटा केंद्रों के बीच की दूरी का विश्लेषण करने का एक उदाहरण दिखाता है।

जैसा कि आप देख सकते हैं, प्रारंभिक आधार रेखा और नवीनतम स्नैपशॉट के बीच शीघ्र एम्बेडिंग और संदर्भ डेटा केंद्रों के बीच माध्य, मध्य और मानक विचलन दूरी के आँकड़े कम हो रहे हैं। यद्यपि दूरी के पूर्ण मूल्य की व्याख्या करना कठिन है, हम यह निर्धारित करने के लिए रुझानों का उपयोग कर सकते हैं कि संदर्भ डेटा और आने वाले प्रश्नों के बीच अर्थ ओवरलैप समय के साथ बेहतर या बदतर हो रहा है या नहीं।
नमूना आवेदन
पिछले अनुभाग में चर्चा किए गए प्रायोगिक परिणामों को इकट्ठा करने के लिए, हमने एक नमूना एप्लिकेशन बनाया जो सेजमेकर जम्पस्टार्ट के माध्यम से तैनात और होस्ट किए गए एम्बेडिंग और जेनरेशन मॉडल का उपयोग करके आरएजी पैटर्न को लागू करता है। अमेज़न SageMaker वास्तविक समय समापनबिंदु।
एप्लिकेशन के तीन मुख्य घटक हैं:
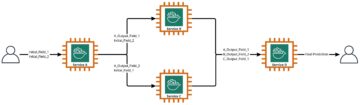
- हम एक इंटरैक्टिव प्रवाह का उपयोग करते हैं, जिसमें लैंगचेन का उपयोग करके आरएजी ऑर्केस्ट्रेशन परत के साथ संयुक्त संकेतों को कैप्चर करने के लिए एक उपयोगकर्ता इंटरफ़ेस शामिल है।
- डेटा प्रोसेसिंग प्रवाह पीडीएफ दस्तावेजों से डेटा निकालता है और एम्बेडिंग बनाता है जो संग्रहीत हो जाता है अमेज़न ओपन सर्च सर्विस. हम इनका उपयोग एप्लिकेशन के अंतिम एम्बेडिंग ड्रिफ्ट विश्लेषण घटक में भी करते हैं।
- एंबेडिंग्स को कैद कर लिया गया है अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) के माध्यम से अमेज़न Kinesis डेटा Firehose, और हम इसका एक संयोजन चलाते हैं एडब्ल्यूएस गोंद एम्बेडिंग विश्लेषण करने के लिए नौकरियों और ज्यूपिटर नोटबुक को निकालें, बदलें और लोड करें।
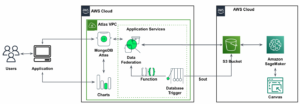
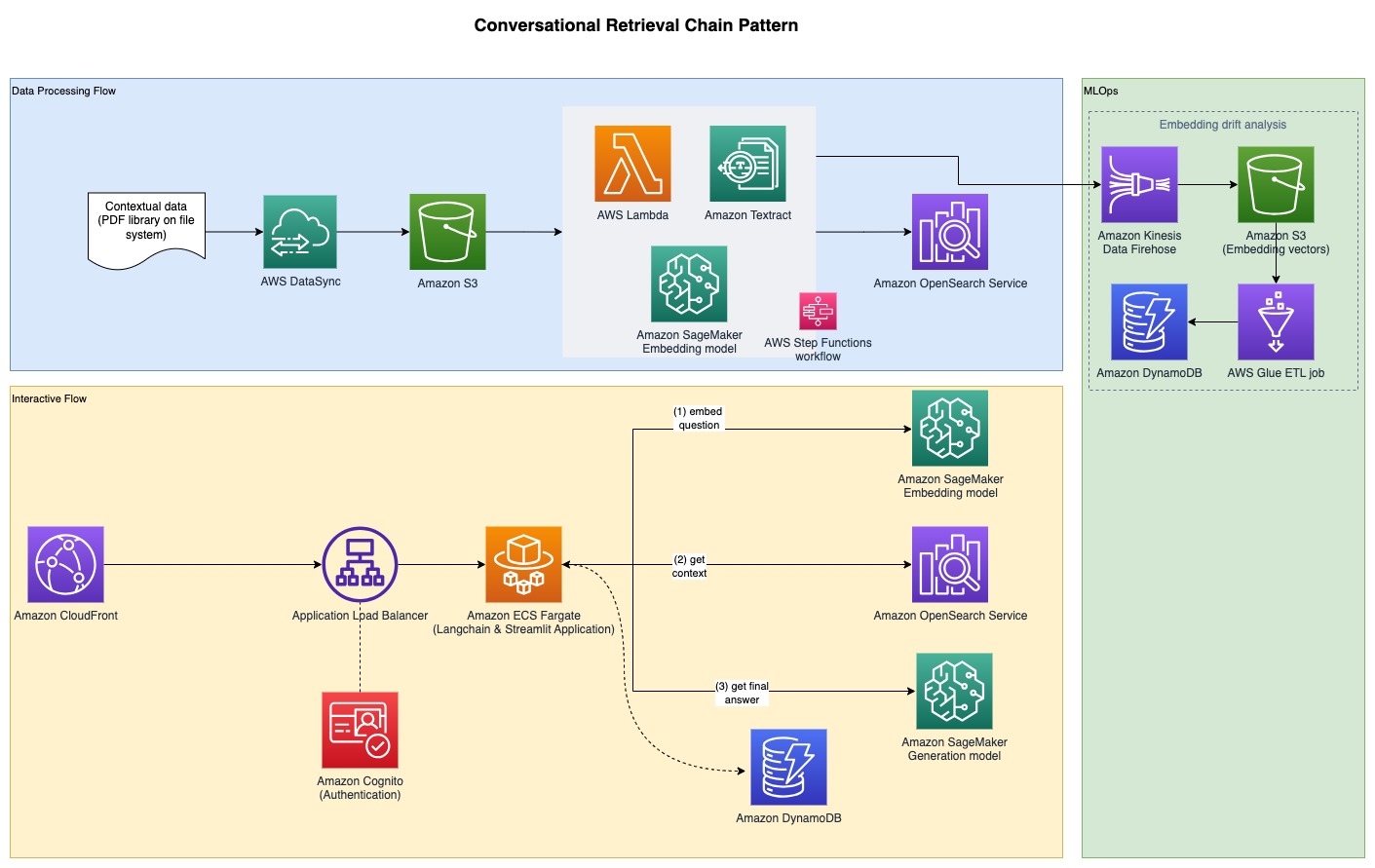
निम्नलिखित चित्र एंड-टू-एंड आर्किटेक्चर को दर्शाता है।
पूरा नमूना कोड यहां उपलब्ध है GitHub. प्रदान किया गया कोड दो अलग-अलग पैटर्न में उपलब्ध है:
- स्ट्रीमलिट फ्रंटएंड के साथ नमूना पूर्ण-स्टैक एप्लिकेशन - यह एक एंड-टू-एंड एप्लिकेशन प्रदान करता है, जिसमें संकेतों को कैप्चर करने के लिए स्ट्रीमलाइट का उपयोग करने वाला एक उपयोगकर्ता इंटरफ़ेस, आरएजी ऑर्केस्ट्रेशन परत के साथ संयुक्त, लैंगचेन का उपयोग करना शामिल है। अमेज़ॅन इलास्टिक कंटेनर सेवा (अमेज़ॅन ईसीएस) के साथ AWS फरगेट
- बैकएंड अनुप्रयोग - उन लोगों के लिए जो पूर्ण एप्लिकेशन स्टैक को तैनात नहीं करना चाहते हैं, आप वैकल्पिक रूप से केवल बैकएंड को तैनात करना चुन सकते हैं AWS क्लाउड डेवलपमेंट किट (एडब्ल्यूएस सीडीके) स्टैक, और फिर लैंगचेन का उपयोग करके आरएजी ऑर्केस्ट्रेशन करने के लिए प्रदान की गई ज्यूपिटर नोटबुक का उपयोग करें
प्रदान किए गए पैटर्न बनाने के लिए, निम्नलिखित अनुभागों में कई पूर्वापेक्षाएँ विस्तृत हैं, जो जेनरेटिव और टेक्स्ट एम्बेडिंग मॉडल को तैनात करने से शुरू होती हैं और फिर अतिरिक्त पूर्वापेक्षाओं पर आगे बढ़ती हैं।
सेजमेकर जम्पस्टार्ट के माध्यम से मॉडल तैनात करें
दोनों पैटर्न एक एम्बेडिंग मॉडल और जेनरेटिव मॉडल की तैनाती मानते हैं। इसके लिए, आप सेजमेकर जम्पस्टार्ट से दो मॉडल तैनात करेंगे। पहला मॉडल, GPT-J 6B, एम्बेडिंग मॉडल के रूप में उपयोग किया जाता है और दूसरा मॉडल, Falcon-40b, टेक्स्ट जेनरेशन के लिए उपयोग किया जाता है।
आप इनमें से प्रत्येक मॉडल को सेजमेकर जम्पस्टार्ट के माध्यम से तैनात कर सकते हैं एडब्ल्यूएस प्रबंधन कंसोल, अमेज़ॅन सैजमेकर स्टूडियो, या प्रोग्रामेटिक रूप से। अधिक जानकारी के लिए देखें जम्पस्टार्ट फाउंडेशन मॉडल का उपयोग कैसे करें. परिनियोजन को सरल बनाने के लिए, आप इसका उपयोग कर सकते हैं नोटबुक प्रदान की गई सेजमेकर जम्पस्टार्ट द्वारा स्वचालित रूप से बनाई गई नोटबुक से प्राप्त। यह नोटबुक मॉडलों को सेजमेकर जम्पस्टार्ट एमएल हब से खींचती है और उन्हें दो अलग-अलग सेजमेकर रीयल-टाइम एंडपॉइंट्स पर तैनात करती है।
नमूना नोटबुक में एक सफाई अनुभाग भी है। उस अनुभाग को अभी तक न चलाएं, क्योंकि यह अभी तैनात किए गए अंतिम बिंदुओं को हटा देगा। आप वॉकथ्रू के अंत में सफाई पूरी कर लेंगे।
अंतिम बिंदुओं के सफल परिनियोजन की पुष्टि करने के बाद, आप पूर्ण नमूना एप्लिकेशन को परिनियोजित करने के लिए तैयार हैं। हालाँकि, यदि आप केवल बैकएंड और विश्लेषण नोटबुक की खोज में अधिक रुचि रखते हैं, तो आप वैकल्पिक रूप से केवल उसे ही तैनात कर सकते हैं, जो अगले भाग में शामिल है।
विकल्प 1: केवल बैकएंड एप्लिकेशन परिनियोजित करें
यह पैटर्न आपको केवल बैकएंड समाधान को तैनात करने और ज्यूपिटर नोटबुक का उपयोग करके समाधान के साथ इंटरैक्ट करने की अनुमति देता है। यदि आप पूर्ण फ्रंटएंड इंटरफ़ेस नहीं बनाना चाहते हैं तो इस पैटर्न का उपयोग करें।
.. पूर्वापेक्षाएँ
आपके पास निम्नलिखित पूर्वापेक्षाएँ होनी चाहिए:
- एक सेजमेकर जंपस्टार्ट मॉडल एंडपॉइंट तैनात किया गया - जैसा कि पहले बताया गया है, सेजमेकर जम्पस्टार्ट का उपयोग करके मॉडलों को सेजमेकर रीयल-टाइम एंडपॉइंट पर तैनात करें
- परिनियोजन पैरामीटर - निम्नलिखित रिकॉर्ड करें:
- पाठ मॉडल समापनबिंदु नाम - सेजमेकर जम्पस्टार्ट के साथ तैनात टेक्स्ट जेनरेशन मॉडल का समापन बिंदु नाम
- एंबेडिंग मॉडल समापन बिंदु नाम - सेजमेकर जम्पस्टार्ट के साथ तैनात एम्बेडिंग मॉडल का समापन बिंदु नाम
AWS CDK का उपयोग करके संसाधन तैनात करें
AWS CDK स्टैक को परिनियोजित करने के लिए पिछले अनुभाग में नोट किए गए परिनियोजन पैरामीटर का उपयोग करें। AWS CDK इंस्टालेशन के बारे में अधिक जानकारी के लिए देखें AWS CDK के साथ शुरुआत करना.
सुनिश्चित करें कि डॉकर स्थापित है और वर्कस्टेशन पर चल रहा है जिसका उपयोग AWS CDK परिनियोजन के लिए किया जाएगा। को देखें डॉकर प्राप्त करें अतिरिक्त मार्गदर्शन के लिए।
वैकल्पिक रूप से, आप नामक फ़ाइल में संदर्भ मान दर्ज कर सकते हैं cdk.context.json में pattern1-rag/cdk निर्देशिका और चलाएँ cdk deploy BackendStack --exclusively.
परिनियोजन आउटपुट प्रिंट करेगा, जिनमें से कुछ की नोटबुक चलाने के लिए आवश्यकता होगी। इससे पहले कि आप प्रश्न और उत्तर देना शुरू करें, संदर्भ दस्तावेज़ एम्बेड करें, जैसा कि अगले भाग में दिखाया गया है।
संदर्भ दस्तावेज़ एम्बेड करें
इस आरएजी दृष्टिकोण के लिए, संदर्भ दस्तावेजों को पहले टेक्स्ट एम्बेडिंग मॉडल के साथ एम्बेड किया जाता है और एक वेक्टर डेटाबेस में संग्रहीत किया जाता है। इस समाधान में, एक अंतर्ग्रहण पाइपलाइन बनाई गई है जो पीडीएफ दस्तावेज़ों को ग्रहण करती है।
An अमेज़ॅन इलास्टिक कम्प्यूट क्लाउड (अमेज़ॅन EC2) उदाहरण पीडीएफ दस्तावेज़ अंतर्ग्रहण और एक के लिए बनाया गया है अमेज़ॅन इलास्टिक फ़ाइल सिस्टम (अमेज़ॅन ईएफएस) फ़ाइल सिस्टम पीडीएफ दस्तावेज़ों को सहेजने के लिए ईसी2 इंस्टेंस पर लगाया गया है। एक एडब्ल्यूएस डेटासिंक ईएफएस फ़ाइल सिस्टम पथ में पाए गए पीडीएफ दस्तावेजों को लाने और टेक्स्ट एम्बेडिंग प्रक्रिया शुरू करने के लिए उन्हें एस 3 बाल्टी में अपलोड करने के लिए कार्य हर घंटे चलाया जाता है। यह प्रक्रिया संदर्भ दस्तावेज़ों को एम्बेड करती है और एम्बेडिंग को ओपनसर्च सेवा में सहेजती है। यह बाद के विश्लेषण के लिए किनेसिस डेटा फ़ायरहोज़ के माध्यम से एक एम्बेडिंग संग्रह को S3 बकेट में भी सहेजता है।
संदर्भ दस्तावेज़ों को ग्रहण करने के लिए, निम्नलिखित चरणों को पूरा करें:
- बनाए गए नमूना EC2 इंस्टेंस आईडी को पुनः प्राप्त करें (AWS CDK आउटपुट देखें)।
JumpHostId) और का उपयोग करके कनेक्ट करें सत्र प्रबंधक, की क्षमता एडब्ल्यूएस सिस्टम मैनेजर. निर्देशों के लिए, देखें AWS सिस्टम मैनेजर सत्र प्रबंधक के साथ अपने लिनक्स इंस्टेंस से कनेक्ट करें. - निर्देशिका पर जाएँ
/mnt/efs/fs1, जो कि वह जगह है जहां ईएफएस फ़ाइल सिस्टम माउंट किया गया है, और एक फ़ोल्डर बनाएं जिसे कहा जाता हैingest: - इसमें अपना संदर्भ पीडीएफ दस्तावेज़ जोड़ें
ingestनिर्देशिका.
एम्बेडिंग प्रक्रिया शुरू करने के लिए इस निर्देशिका में पाई गई सभी फ़ाइलों को Amazon S3 पर अपलोड करने के लिए DataSync कार्य कॉन्फ़िगर किया गया है।
डेटासिंक कार्य प्रति घंटे के शेड्यूल पर चलता है; आपके द्वारा जोड़े गए पीडीएफ दस्तावेज़ों के लिए एम्बेडिंग प्रक्रिया तुरंत शुरू करने के लिए आप वैकल्पिक रूप से मैन्युअल रूप से कार्य शुरू कर सकते हैं।
- कार्य शुरू करने के लिए, AWS CDK आउटपुट से कार्य आईडी ढूंढें
DataSyncTaskIDऔर कार्य प्रारंभ करें डिफ़ॉल्ट के साथ.
एम्बेडिंग बनने के बाद, आप ज्यूपिटर नोटबुक के माध्यम से आरएजी प्रश्न और उत्तर देना शुरू कर सकते हैं, जैसा कि अगले भाग में दिखाया गया है।
ज्यूपिटर नोटबुक का उपयोग करके प्रश्न और उत्तर देना
निम्नलिखित चरणों को पूरा करें:
- AWS CDK आउटपुट से SageMaker नोटबुक इंस्टेंस नाम पुनर्प्राप्त करें
NotebookInstanceNameऔर SageMaker कंसोल से JupyterLab से कनेक्ट करें। - निर्देशिका पर जाएँ
fmops/full-stack/pattern1-rag/notebooks/. - नोटबुक खोलें और चलाएं
query-llm.ipynbRAG का उपयोग करके प्रश्न और उत्तर देने के लिए नोटबुक उदाहरण में।
का उपयोग अवश्य करें conda_python3 नोटबुक के लिए कर्नेल.
यह पैटर्न पूर्ण-स्टैक एप्लिकेशन के लिए आवश्यक अतिरिक्त शर्तों को प्रावधान किए बिना बैकएंड समाधान का पता लगाने के लिए उपयोगी है। अगला अनुभाग आपके जेनरेटिव एआई एप्लिकेशन के साथ इंटरैक्ट करने के लिए एक यूजर इंटरफेस प्रदान करने के लिए फ्रंटएंड और बैकएंड दोनों घटकों सहित एक पूर्ण-स्टैक एप्लिकेशन के कार्यान्वयन को शामिल करता है।
विकल्प 2: स्ट्रीमलिट फ्रंटएंड के साथ पूर्ण-स्टैक नमूना एप्लिकेशन को तैनात करें
यह पैटर्न आपको प्रश्न और उत्तर के लिए उपयोगकर्ता फ्रंटएंड इंटरफ़ेस के साथ समाधान तैनात करने की अनुमति देता है।
.. पूर्वापेक्षाएँ
नमूना एप्लिकेशन को तैनात करने के लिए, आपके पास निम्नलिखित शर्तें होनी चाहिए:
- सेजमेकर जंपस्टार्ट मॉडल एंडपॉइंट तैनात किया गया - दिए गए नोटबुक का उपयोग करके, जैसा कि पिछले अनुभाग में बताया गया है, सेजमेकर जम्पस्टार्ट का उपयोग करके मॉडल को अपने सेजमेकर रीयल-टाइम एंडपॉइंट पर तैनात करें।
- अमेज़ॅन रूट 53 होस्टेड ज़ोन - बनाओ अमेज़ॅन रूट 53 सार्वजनिक होस्ट किया गया क्षेत्र इस समाधान के लिए उपयोग करने के लिए. आप मौजूदा रूट 53 सार्वजनिक होस्टेड ज़ोन का भी उपयोग कर सकते हैं, जैसे
example.com. - AWS प्रमाणपत्र प्रबंधक प्रमाणपत्र - प्रावधान ए AWS प्रमाणपत्र प्रबंधक (एसीएम) रूट 53 होस्टेड ज़ोन डोमेन नाम और इसके लागू उपडोमेन के लिए टीएलएस प्रमाणपत्र, जैसे
example.comऔर*.example.comसभी उपडोमेन के लिए. निर्देशों के लिए, देखें सार्वजनिक प्रमाणपत्र का अनुरोध. इस प्रमाणपत्र का उपयोग HTTPS को कॉन्फ़िगर करने के लिए किया जाता है अमेज़न CloudFront और मूल लोड बैलेंसर। - परिनियोजन पैरामीटर - निम्नलिखित रिकॉर्ड करें:
- फ्रंटएंड एप्लिकेशन कस्टम डोमेन नाम - एक कस्टम डोमेन नाम जिसका उपयोग फ्रंटएंड नमूना एप्लिकेशन तक पहुंचने के लिए किया जाता है। प्रदान किए गए डोमेन नाम का उपयोग फ्रंटएंड क्लाउडफ्रंट वितरण की ओर इशारा करते हुए रूट 53 डीएनएस रिकॉर्ड बनाने के लिए किया जाता है; उदाहरण के लिए,
app.example.com. - लोड बैलेंसर मूल कस्टम डोमेन नाम - क्लाउडफ्रंट वितरण लोड बैलेंसर मूल के लिए उपयोग किया जाने वाला एक कस्टम डोमेन नाम। प्रदान किए गए डोमेन नाम का उपयोग मूल लोड बैलेंसर की ओर इशारा करते हुए रूट 53 डीएनएस रिकॉर्ड बनाने के लिए किया जाता है; उदाहरण के लिए,
app-lb.example.com. - रूट 53 होस्टेड ज़ोन आईडी - प्रदान किए गए कस्टम डोमेन नामों को होस्ट करने के लिए रूट 53 होस्टेड ज़ोन आईडी; उदाहरण के लिए,
ZXXXXXXXXYYYYYYYYY. - रूट 53 होस्टेड ज़ोन का नाम - प्रदान किए गए कस्टम डोमेन नामों को होस्ट करने के लिए रूट 53 होस्टेड ज़ोन का नाम; उदाहरण के लिए,
example.com. - एसीएम प्रमाणपत्र एआरएन - एसीएम प्रमाणपत्र का एआरएन प्रदान किए गए कस्टम डोमेन के साथ उपयोग किया जाएगा।
- पाठ मॉडल समापनबिंदु नाम - सेजमेकर जम्पस्टार्ट के साथ तैनात टेक्स्ट जेनरेशन मॉडल का समापन बिंदु नाम।
- एंबेडिंग मॉडल समापन बिंदु नाम - सेजमेकर जम्पस्टार्ट के साथ तैनात एम्बेडिंग मॉडल का समापन बिंदु नाम।
- फ्रंटएंड एप्लिकेशन कस्टम डोमेन नाम - एक कस्टम डोमेन नाम जिसका उपयोग फ्रंटएंड नमूना एप्लिकेशन तक पहुंचने के लिए किया जाता है। प्रदान किए गए डोमेन नाम का उपयोग फ्रंटएंड क्लाउडफ्रंट वितरण की ओर इशारा करते हुए रूट 53 डीएनएस रिकॉर्ड बनाने के लिए किया जाता है; उदाहरण के लिए,
AWS CDK का उपयोग करके संसाधन तैनात करें
AWS CDK स्टैक को परिनियोजित करने के लिए पूर्वापेक्षाओं में आपके द्वारा नोट किए गए परिनियोजन पैरामीटर का उपयोग करें। अधिक जानकारी के लिए देखें AWS CDK के साथ शुरुआत करना.
सुनिश्चित करें कि डॉकर स्थापित है और वर्कस्टेशन पर चल रहा है जिसका उपयोग AWS CDK परिनियोजन के लिए किया जाएगा।
पूर्ववर्ती कोड में, -c इनपुट पर प्रदान की गई आवश्यक शर्तों के रूप में एक संदर्भ मान का प्रतिनिधित्व करता है। वैकल्पिक रूप से, आप नामक फ़ाइल में संदर्भ मान दर्ज कर सकते हैं cdk.context.json में pattern1-rag/cdk निर्देशिका और चलाएँ cdk deploy --all.
ध्यान दें कि हम फ़ाइल में क्षेत्र निर्दिष्ट करते हैं bin/cdk.ts. ALB एक्सेस लॉग को कॉन्फ़िगर करने के लिए एक निर्दिष्ट क्षेत्र की आवश्यकता होती है। आप तैनाती से पहले इस क्षेत्र को बदल सकते हैं।
परिनियोजन स्ट्रीमलिट एप्लिकेशन तक पहुंचने के लिए यूआरएल का प्रिंट आउट लेगा। इससे पहले कि आप प्रश्न और उत्तर देना शुरू करें, आपको संदर्भ दस्तावेज़ एम्बेड करने होंगे, जैसा कि अगले भाग में दिखाया गया है।
संदर्भ दस्तावेज़ एम्बेड करें
आरएजी दृष्टिकोण के लिए, संदर्भ दस्तावेजों को पहले टेक्स्ट एम्बेडिंग मॉडल के साथ एम्बेड किया जाता है और एक वेक्टर डेटाबेस में संग्रहीत किया जाता है। इस समाधान में, एक अंतर्ग्रहण पाइपलाइन बनाई गई है जो पीडीएफ दस्तावेज़ों को ग्रहण करती है।
जैसा कि हमने पहले परिनियोजन विकल्प में चर्चा की है, पीडीएफ दस्तावेज़ अंतर्ग्रहण के लिए एक उदाहरण EC2 इंस्टेंस बनाया गया है और PDF दस्तावेज़ों को सहेजने के लिए EC2 इंस्टेंस पर एक EFS फ़ाइल सिस्टम लगाया गया है। ईएफएस फ़ाइल सिस्टम पथ में पाए गए पीडीएफ दस्तावेजों को लाने और टेक्स्ट एम्बेडिंग प्रक्रिया शुरू करने के लिए उन्हें एस 3 बाल्टी में अपलोड करने के लिए हर घंटे एक डेटासिंक कार्य चलाया जाता है। यह प्रक्रिया संदर्भ दस्तावेज़ों को एम्बेड करती है और एम्बेडिंग को ओपनसर्च सेवा में सहेजती है। यह बाद के विश्लेषण के लिए किनेसिस डेटा फ़ायरहोज़ के माध्यम से एक एम्बेडिंग संग्रह को S3 बकेट में भी सहेजता है।
संदर्भ दस्तावेज़ों को ग्रहण करने के लिए, निम्नलिखित चरणों को पूरा करें:
- बनाए गए नमूना EC2 इंस्टेंस आईडी को पुनः प्राप्त करें (AWS CDK आउटपुट देखें)।
JumpHostId) और सत्र प्रबंधक का उपयोग करके कनेक्ट करें। - निर्देशिका पर जाएँ
/mnt/efs/fs1, जो कि वह जगह है जहां ईएफएस फ़ाइल सिस्टम माउंट किया गया है, और एक फ़ोल्डर बनाएं जिसे कहा जाता हैingest: - इसमें अपना संदर्भ पीडीएफ दस्तावेज़ जोड़ें
ingestनिर्देशिका.
एम्बेडिंग प्रक्रिया शुरू करने के लिए इस निर्देशिका में पाई गई सभी फ़ाइलों को Amazon S3 पर अपलोड करने के लिए DataSync कार्य कॉन्फ़िगर किया गया है।
डेटासिंक कार्य प्रति घंटे के शेड्यूल पर चलता है। आपके द्वारा जोड़े गए पीडीएफ दस्तावेजों के लिए एम्बेडिंग प्रक्रिया तुरंत शुरू करने के लिए आप वैकल्पिक रूप से कार्य को मैन्युअल रूप से शुरू कर सकते हैं।
- कार्य शुरू करने के लिए, AWS CDK आउटपुट से कार्य आईडी ढूंढें
DataSyncTaskIDऔर कार्य प्रारंभ करें डिफ़ॉल्ट के साथ.
प्रश्न और उत्तर
संदर्भ दस्तावेज़ एम्बेड किए जाने के बाद, आप स्ट्रीमलिट एप्लिकेशन तक पहुंचने के लिए यूआरएल पर जाकर आरएजी प्रश्न और उत्तर शुरू कर सकते हैं। एक अमेज़ॅन कॉग्निटो प्रमाणीकरण परत का उपयोग किया जाता है, इसलिए इसे एप्लिकेशन तक पहली बार पहुंच के लिए AWS CDK (उपयोगकर्ता पूल नाम के लिए AWS CDK आउटपुट देखें) के माध्यम से तैनात अमेज़ॅन कॉग्निटो उपयोगकर्ता पूल में एक उपयोगकर्ता खाता बनाने की आवश्यकता होती है। Amazon Cognito उपयोगकर्ता बनाने के निर्देशों के लिए, देखें AWS प्रबंधन कंसोल में एक नया उपयोगकर्ता बनाना.
एंबेड बहाव विश्लेषण
इस अनुभाग में, हम आपको दिखाते हैं कि पहले संदर्भ डेटा एम्बेडिंग और शीघ्र एम्बेडिंग की आधार रेखा बनाकर और फिर समय के साथ एम्बेडिंग का एक स्नैपशॉट बनाकर बहाव विश्लेषण कैसे करें। यह आपको बेसलाइन एम्बेडिंग की तुलना स्नैपशॉट एम्बेडिंग से करने की अनुमति देता है।
संदर्भ डेटा और प्रॉम्प्ट के लिए एक एम्बेडिंग बेसलाइन बनाएं
संदर्भ डेटा की एम्बेडिंग बेसलाइन बनाने के लिए, AWS ग्लू कंसोल खोलें और ETL जॉब चुनें embedding-drift-analysis. ईटीएल कार्य के लिए पैरामीटर निम्नानुसार सेट करें और कार्य चलाएँ:
- सेट
--job_typeसेवा मेरेBASELINE. - सेट
--out_tableको अमेज़ॅन डायनेमोडीबी संदर्भ एम्बेडिंग डेटा के लिए तालिका। (एडब्ल्यूएस सीडीके आउटपुट देखेंDriftTableReferenceतालिका नाम के लिए.) - सेट
--centroid_tableसंदर्भ सेंट्रोइड डेटा के लिए DynamoDB तालिका में। (एडब्ल्यूएस सीडीके आउटपुट देखेंCentroidTableReferenceतालिका नाम के लिए.) - सेट
--data_pathउपसर्ग के साथ S3 बाल्टी में; उदाहरण के लिए,s3:///embeddingarchive/. (एडब्ल्यूएस सीडीके आउटपुट देखेंBucketNameबाल्टी के नाम के लिए.)
इसी तरह, ईटीएल नौकरी का उपयोग करना embedding-drift-analysis, संकेतों की एक एम्बेडिंग बेसलाइन बनाएं। ईटीएल कार्य के लिए पैरामीटर निम्नानुसार सेट करें और कार्य चलाएँ:
- सेट
--job_typeसेवा मेरेBASELINE - सेट
--out_tableशीघ्र एम्बेडिंग डेटा के लिए DynamoDB तालिका में। (एडब्ल्यूएस सीडीके आउटपुट देखेंDriftTablePromptsNameतालिका नाम के लिए.) - सेट
--centroid_tableप्रॉम्प्ट सेंट्रोइड डेटा के लिए DynamoDB तालिका में। (एडब्ल्यूएस सीडीके आउटपुट देखेंCentroidTablePromptsतालिका नाम के लिए.) - सेट
--data_pathउपसर्ग के साथ S3 बाल्टी में; उदाहरण के लिए,s3:///promptarchive/. (एडब्ल्यूएस सीडीके आउटपुट देखेंBucketNameबाल्टी के नाम के लिए.)
संदर्भ डेटा और प्रॉम्प्ट के लिए एक एम्बेडिंग स्नैपशॉट बनाएं
ओपनसर्च सेवा में अतिरिक्त जानकारी डालने के बाद, ईटीएल कार्य चलाएँ embedding-drift-analysis संदर्भ डेटा एम्बेडिंग को फिर से स्नैपशॉट करने के लिए। पैरामीटर ईटीएल जॉब के समान होंगे जो आपने संदर्भ डेटा की एम्बेडिंग बेसलाइन बनाने के लिए चलाया था जैसा कि पिछले अनुभाग में दिखाया गया है, सेटिंग के अपवाद के साथ --job_type करने के लिए पैरामीटर SNAPSHOT.
इसी तरह, प्रॉम्प्ट एम्बेडिंग को स्नैपशॉट करने के लिए, ईटीएल जॉब चलाएँ embedding-drift-analysis दोबारा। पैरामीटर ईटीएल जॉब के समान होंगे जो आपने पिछले अनुभाग में दिखाए गए संकेतों के लिए एम्बेडिंग बेसलाइन बनाने के लिए चलाया था, सेटिंग के अपवाद के साथ --job_type करने के लिए पैरामीटर SNAPSHOT.
आधार रेखा की तुलना स्नैपशॉट से करें
संदर्भ डेटा और संकेतों के लिए एम्बेडिंग बेसलाइन और स्नैपशॉट की तुलना करने के लिए, दिए गए नोटबुक का उपयोग करें pattern1-rag/notebooks/drift-analysis.ipynb.
संदर्भ डेटा या संकेतों के लिए एम्बेडिंग तुलना देखने के लिए, DynamoDB तालिका नाम चर बदलें (tbl और c_tbl) नोटबुक में नोटबुक के प्रत्येक रन के लिए उपयुक्त DynamoDB तालिका में।
नोटबुक चर tbl उचित बहाव तालिका नाम में बदला जाना चाहिए। नोटबुक में वेरिएबल को कहां कॉन्फ़िगर करना है इसका एक उदाहरण निम्नलिखित है।

तालिका के नाम इस प्रकार प्राप्त किए जा सकते हैं:
- संदर्भ एम्बेडिंग डेटा के लिए, AWS CDK आउटपुट से ड्रिफ्ट तालिका नाम पुनर्प्राप्त करें
DriftTableReference - शीघ्र एम्बेडिंग डेटा के लिए, AWS CDK आउटपुट से ड्रिफ्ट तालिका नाम पुनर्प्राप्त करें
DriftTablePromptsName
इसके अलावा, नोटबुक चर c_tbl उचित सेंट्रोइड तालिका नाम में बदला जाना चाहिए। नोटबुक में वेरिएबल को कहां कॉन्फ़िगर करना है इसका एक उदाहरण निम्नलिखित है।

तालिका के नाम इस प्रकार प्राप्त किए जा सकते हैं:
- संदर्भ एम्बेडिंग डेटा के लिए, AWS CDK आउटपुट से सेंट्रोइड तालिका नाम पुनर्प्राप्त करें
CentroidTableReference - शीघ्र एम्बेडिंग डेटा के लिए, AWS CDK आउटपुट से सेंट्रोइड तालिका नाम पुनर्प्राप्त करें
CentroidTablePrompts
संदर्भ डेटा से शीघ्र दूरी का विश्लेषण करें
सबसे पहले, AWS ग्लू कार्य चलाएँ embedding-distance-analysis. यह कार्य संदर्भ डेटा एम्बेडिंग के के-मीन्स मूल्यांकन से यह पता लगाएगा कि प्रत्येक प्रॉम्प्ट किस क्लस्टर से संबंधित है। इसके बाद यह प्रत्येक प्रॉम्प्ट से संबंधित क्लस्टर के केंद्र तक की दूरी के माध्य, माध्यिका और मानक विचलन की गणना करता है।
आप नोटबुक चला सकते हैं pattern1-rag/notebooks/distance-analysis.ipynb समय के साथ दूरी मेट्रिक्स में रुझान देखने के लिए। इससे आपको त्वरित एम्बेडिंग दूरियों के वितरण में समग्र रुझान का एहसास होगा।
नोटबुक pattern1-rag/notebooks/prompt-distance-outliers.ipynb एक AWS ग्लू नोटबुक है जो आउटलेर्स की तलाश करती है, जो आपको यह पहचानने में मदद कर सकती है कि क्या आपको अधिक संकेत मिल रहे हैं जो संदर्भ डेटा से संबंधित नहीं हैं।
समानता स्कोर की निगरानी करें
ओपनसर्च सेवा से सभी समानता स्कोर लॉग इन हैं अमेज़ॅन क्लाउडवॉच नीचे rag नामस्थान. डैशबोर्ड RAG_Scores औसत स्कोर और ग्रहण किए गए स्कोर की कुल संख्या दिखाता है।
क्लीन अप
भविष्य में शुल्क लगने से बचने के लिए, अपने द्वारा बनाए गए सभी संसाधनों को हटा दें।
तैनात सेजमेकर मॉडल हटाएं
के सफ़ाई अनुभाग का संदर्भ लें उदाहरण नोटबुक प्रदान की गई तैनात सेजमेकर जम्पस्टार्ट मॉडल को हटाने के लिए, या आप कर सकते हैं सेजमेकर कंसोल पर मॉडल हटाएं.
AWS CDK संसाधन हटाएँ
यदि आपने अपना पैरामीटर a में दर्ज किया है cdk.context.json फ़ाइल को इस प्रकार साफ़ करें:
यदि आपने कमांड लाइन पर अपने पैरामीटर दर्ज किए हैं और केवल बैकएंड एप्लिकेशन (बैकएंड एडब्ल्यूएस सीडीके स्टैक) तैनात किया है, तो निम्नानुसार सफाई करें:
यदि आपने कमांड लाइन पर अपने पैरामीटर दर्ज किए हैं और पूर्ण समाधान (फ्रंटएंड और बैकएंड एडब्ल्यूएस सीडीके स्टैक) तैनात किया है, तो निम्नानुसार सफाई करें:
निष्कर्ष
इस पोस्ट में, हमने एक एप्लिकेशन का एक कामकाजी उदाहरण प्रदान किया है जो जेनरेटिव एआई के लिए आरएजी पैटर्न में संदर्भ डेटा और प्रॉम्प्ट दोनों के लिए एम्बेडिंग वैक्टर को कैप्चर करता है। हमने दिखाया कि यह निर्धारित करने के लिए क्लस्टरिंग विश्लेषण कैसे किया जाए कि क्या संदर्भ या त्वरित डेटा समय के साथ बह रहा है, और संदर्भ डेटा उपयोगकर्ताओं द्वारा पूछे जाने वाले प्रश्नों के प्रकारों को कितनी अच्छी तरह कवर करता है। यदि आप बहाव का पता लगाते हैं, तो यह संकेत दे सकता है कि वातावरण बदल गया है और आपके मॉडल को नए इनपुट मिल रहे हैं जिन्हें संभालने के लिए इसे अनुकूलित नहीं किया जा सकता है। यह बदलते इनपुट के विरुद्ध वर्तमान मॉडल के सक्रिय मूल्यांकन की अनुमति देता है।
लेखक के बारे में
 अब्दुल्लाही ओलाओये अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक वरिष्ठ समाधान वास्तुकार हैं। अब्दुल्लाही के पास विचिटा स्टेट यूनिवर्सिटी से कंप्यूटर नेटवर्किंग में एमएससी है और वह एक प्रकाशित लेखक हैं, जिन्होंने डेवऑप्स, इंफ्रास्ट्रक्चर आधुनिकीकरण और एआई जैसे विभिन्न प्रौद्योगिकी डोमेन में भूमिकाएँ निभाई हैं। वह वर्तमान में जेनेरेटिव एआई पर ध्यान केंद्रित कर रहे हैं और जेनेरेटिव एआई द्वारा संचालित अत्याधुनिक समाधानों को तैयार करने और बनाने में उद्यमों की सहायता करने में महत्वपूर्ण भूमिका निभाते हैं। प्रौद्योगिकी के दायरे से परे, उसे अन्वेषण की कला में आनंद मिलता है। जब वह एआई समाधान तैयार नहीं कर रहे होते हैं, तो उन्हें नई जगहों का पता लगाने के लिए अपने परिवार के साथ यात्रा करने में आनंद आता है।
अब्दुल्लाही ओलाओये अमेज़ॅन वेब सर्विसेज (एडब्ल्यूएस) में एक वरिष्ठ समाधान वास्तुकार हैं। अब्दुल्लाही के पास विचिटा स्टेट यूनिवर्सिटी से कंप्यूटर नेटवर्किंग में एमएससी है और वह एक प्रकाशित लेखक हैं, जिन्होंने डेवऑप्स, इंफ्रास्ट्रक्चर आधुनिकीकरण और एआई जैसे विभिन्न प्रौद्योगिकी डोमेन में भूमिकाएँ निभाई हैं। वह वर्तमान में जेनेरेटिव एआई पर ध्यान केंद्रित कर रहे हैं और जेनेरेटिव एआई द्वारा संचालित अत्याधुनिक समाधानों को तैयार करने और बनाने में उद्यमों की सहायता करने में महत्वपूर्ण भूमिका निभाते हैं। प्रौद्योगिकी के दायरे से परे, उसे अन्वेषण की कला में आनंद मिलता है। जब वह एआई समाधान तैयार नहीं कर रहे होते हैं, तो उन्हें नई जगहों का पता लगाने के लिए अपने परिवार के साथ यात्रा करने में आनंद आता है।
 रैंडी डेफॉउ AWS में वरिष्ठ प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं। उनके पास मिशिगन विश्वविद्यालय से एमएसईई है, जहां उन्होंने स्वायत्त वाहनों के लिए कंप्यूटर विज़न पर काम किया। उन्होंने कोलोराडो स्टेट यूनिवर्सिटी से एमबीए भी किया है। रैंडी ने प्रौद्योगिकी क्षेत्र में सॉफ्टवेयर इंजीनियरिंग से लेकर उत्पाद प्रबंधन तक विभिन्न पदों पर काम किया है। 2013 में बिग डेटा क्षेत्र में प्रवेश किया और उस क्षेत्र का पता लगाना जारी रखा। वह एमएल क्षेत्र में परियोजनाओं पर सक्रिय रूप से काम कर रहे हैं और उन्होंने स्ट्रेटा और ग्लूकॉन सहित कई सम्मेलनों में प्रस्तुति दी है।
रैंडी डेफॉउ AWS में वरिष्ठ प्रिंसिपल सॉल्यूशंस आर्किटेक्ट हैं। उनके पास मिशिगन विश्वविद्यालय से एमएसईई है, जहां उन्होंने स्वायत्त वाहनों के लिए कंप्यूटर विज़न पर काम किया। उन्होंने कोलोराडो स्टेट यूनिवर्सिटी से एमबीए भी किया है। रैंडी ने प्रौद्योगिकी क्षेत्र में सॉफ्टवेयर इंजीनियरिंग से लेकर उत्पाद प्रबंधन तक विभिन्न पदों पर काम किया है। 2013 में बिग डेटा क्षेत्र में प्रवेश किया और उस क्षेत्र का पता लगाना जारी रखा। वह एमएल क्षेत्र में परियोजनाओं पर सक्रिय रूप से काम कर रहे हैं और उन्होंने स्ट्रेटा और ग्लूकॉन सहित कई सम्मेलनों में प्रस्तुति दी है।
 शेल्बी आइजेनब्रोड Amazon Web Services (AWS) में प्रिंसिपल AI और मशीन लर्निंग स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। वह कई उद्योगों, प्रौद्योगिकियों और भूमिकाओं में फैले 24 वर्षों से प्रौद्योगिकी में है। वह वर्तमान में अपने DevOps और ML पृष्ठभूमि को MLOps के डोमेन में संयोजित करने पर ध्यान केंद्रित कर रही है ताकि ग्राहकों को बड़े पैमाने पर ML वर्कलोड वितरित करने और प्रबंधित करने में मदद मिल सके। विभिन्न प्रौद्योगिकी डोमेन में 35 से अधिक पेटेंट दिए जाने के साथ, उन्हें निरंतर नवाचार और व्यावसायिक परिणामों को चलाने के लिए डेटा का उपयोग करने का जुनून है। शेल्बी कौरसेरा पर प्रैक्टिकल डेटा साइंस विशेषज्ञता के सह-निर्माता और प्रशिक्षक हैं। वह डेनवर चैप्टर में वीमेन इन बिग डेटा (वाईबीडी) की सह-निदेशक भी हैं। अपने खाली समय में, वह अपने परिवार, दोस्तों और अति सक्रिय कुत्तों के साथ समय बिताना पसंद करती है।
शेल्बी आइजेनब्रोड Amazon Web Services (AWS) में प्रिंसिपल AI और मशीन लर्निंग स्पेशलिस्ट सॉल्यूशंस आर्किटेक्ट हैं। वह कई उद्योगों, प्रौद्योगिकियों और भूमिकाओं में फैले 24 वर्षों से प्रौद्योगिकी में है। वह वर्तमान में अपने DevOps और ML पृष्ठभूमि को MLOps के डोमेन में संयोजित करने पर ध्यान केंद्रित कर रही है ताकि ग्राहकों को बड़े पैमाने पर ML वर्कलोड वितरित करने और प्रबंधित करने में मदद मिल सके। विभिन्न प्रौद्योगिकी डोमेन में 35 से अधिक पेटेंट दिए जाने के साथ, उन्हें निरंतर नवाचार और व्यावसायिक परिणामों को चलाने के लिए डेटा का उपयोग करने का जुनून है। शेल्बी कौरसेरा पर प्रैक्टिकल डेटा साइंस विशेषज्ञता के सह-निर्माता और प्रशिक्षक हैं। वह डेनवर चैप्टर में वीमेन इन बिग डेटा (वाईबीडी) की सह-निदेशक भी हैं। अपने खाली समय में, वह अपने परिवार, दोस्तों और अति सक्रिय कुत्तों के साथ समय बिताना पसंद करती है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 100
- 2%
- 2013
- 24
- 35% तक
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- 95% तक
- a
- योग्य
- About
- पूर्ण
- पहुँच
- लेखा
- एसीएम
- के पार
- सक्रिय रूप से
- जोड़ा
- इसके अलावा
- अतिरिक्त
- अतिरिक्त जानकारी
- इसके अतिरिक्त
- फिर
- के खिलाफ
- कुल
- AI
- संरेखित करता है
- सब
- की अनुमति दे
- की अनुमति देता है
- भी
- हालांकि
- वीरांगना
- अमेज़ॅन कॉग्निटो
- अमेज़ॅन EC2
- अमेज़न SageMaker
- अमेज़न SageMaker जम्पस्टार्ट
- अमेज़ॅन वेब सेवा
- अमेज़ॅन वेब सेवा (एडब्ल्यूएस)
- an
- विश्लेषण
- विश्लेषण करें
- का विश्लेषण
- और
- जवाब
- जवाब दे
- कुछ भी
- उपयुक्त
- आवेदन
- दृष्टिकोण
- उपयुक्त
- स्थापत्य
- पुरालेख
- हैं
- क्षेत्र
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- कला
- लेख
- AS
- पूछना
- पूछ
- की सहायता
- मान लीजिये
- At
- बढ़ाना
- संवर्धित
- प्रमाणीकरण
- लेखक
- स्वतः
- स्वायत्त
- स्वायत्त वाहनों
- उपलब्ध
- औसत
- से बचने
- दूर
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- बैकएण्ड
- पृष्ठभूमि
- कसरती
- आधारित
- आधारभूत
- BE
- क्योंकि
- किया गया
- से पहले
- जा रहा है
- अंतर्गत आता है
- बेहतर
- के बीच
- परे
- बड़ा
- बड़ा डेटा
- शव
- के छात्रों
- मोटे तौर पर
- निर्माण
- बनाया गया
- व्यापार
- by
- गणना
- गणना
- कॉल
- बुलाया
- कर सकते हैं
- क्षमता
- कब्जा
- पर कब्जा कर लिया
- कब्जा
- कैप्चरिंग
- मामला
- CD
- केंद्र
- केंद्र
- प्रमाण पत्र
- परिवर्तन
- बदल
- परिवर्तन
- बदलना
- अध्याय
- प्रभार
- टुकड़ा
- चॉकलेट
- चुनें
- स्वच्छ
- समापन
- करीब
- बादल
- समूह
- गुच्छन
- कोड
- कोलोराडो
- संयोजन
- संयुक्त
- संयोजन
- अ रहे है
- सघन
- तुलना
- तुलना
- तुलना
- पूरा
- अंग
- घटकों
- गणना करना
- कंप्यूटर
- Computer Vision
- अवधारणाओं
- सम्मेलनों
- कॉन्फ़िगर किया गया
- को विन्यस्त
- जुडिये
- विचार
- स्थिरता
- कंसोल
- कंटेनर
- सामग्री
- प्रसंग
- जारी
- निरंतर
- परिवर्तित
- कुकीज़
- मूल
- इसी
- Coursera
- व्याप्ति
- कवर
- कवर
- शामिल किया गया
- बनाना
- बनाया
- बनाता है
- बनाना
- वर्तमान
- वर्तमान में
- रिवाज
- ग्राहक
- अग्रणी
- डैशबोर्ड
- तिथि
- डेटा केन्द्रों
- डेटा संसाधन
- डेटा विज्ञान
- डाटाबेस
- कम
- चूक
- परिभाषित
- हटाना
- उद्धार
- डेन्वेर
- तैनात
- तैनात
- तैनाती
- तैनाती
- तैनात
- निकाली गई
- को नष्ट
- विस्तृत
- पता लगाना
- खोज
- निर्धारित करना
- विकास
- विचलन
- DevOps
- आरेख
- विभिन्न
- मुश्किल
- आयाम
- आयाम
- चर्चा की
- तितर - बितर
- दूरी
- दूर
- वितरण
- DNS
- do
- डाक में काम करनेवाला मज़दूर
- दस्तावेज़
- दस्तावेजों
- कुत्ते की
- डोमेन
- डोमेन नाम
- कार्यक्षेत्र नाम
- डोमेन
- dont
- नीचे
- ड्राइव
- से प्रत्येक
- एम्बेड
- एम्बेडेड
- embedding
- समाप्त
- शुरू से अंत तक
- endpoint
- अंतबिंदु
- अभियांत्रिकी
- दर्ज
- घुसा
- उद्यम
- वातावरण
- ईथर (ईटीएच)
- मूल्यांकन करें
- मूल्यांकन
- प्रत्येक
- उदाहरण
- उदाहरण
- अपवाद
- मौजूदा
- प्रयोगात्मक
- समझाना
- अन्वेषण
- का पता लगाने
- तलाश
- बाहरी
- उद्धरण
- अर्क
- परिवार
- दूर
- आकृति
- पट्टिका
- फ़ाइलें
- अंतिम
- अंत में
- खोज
- पाता
- प्रथम
- चल
- प्रवाह
- ध्यान केंद्रित
- ध्यान केंद्रित
- निम्नलिखित
- इस प्रकार है
- के लिए
- प्रपत्र
- पाया
- बुनियाद
- मित्रों
- से
- दृश्यपटल
- पूर्ण
- भविष्य
- इकट्ठा
- सामान्य जानकारी
- सृजन
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- जेनेरिक मॉडल
- मिल
- मिल रहा
- देना
- Go
- चला गया
- दी गई
- समूह
- मार्गदर्शन
- संभालना
- है
- he
- धारित
- मदद
- उसे
- उच्चतर
- उसके
- रखती है
- मेजबान
- मेजबानी
- घंटा
- कैसे
- How To
- तथापि
- एचटीएमएल
- http
- HTTPS
- हब
- ID
- पहचान करना
- if
- दिखाता है
- तुरंत
- कार्यान्वयन
- औजार
- महत्वपूर्ण
- in
- शामिल
- शामिल
- सहित
- आवक
- संकेत मिलता है
- यह दर्शाता है
- उद्योगों
- जड़ता
- करें-
- इंफ्रास्ट्रक्चर
- प्रारंभिक
- नवोन्मेष
- निवेश
- निविष्टियां
- अन्तर्दृष्टि
- स्थापना
- उदाहरण
- निर्देश
- बातचीत
- बातचीत
- इंटरैक्टिव
- रुचि
- इंटरफेस
- में
- IT
- आईटी इस
- काम
- नौकरियां
- हर्ष
- जेपीजी
- जुपीटर नोटबुक
- केवल
- कुंजी
- किनेसिस डेटा फायरहोज
- ज्ञान
- भाषा
- बड़ा
- बाद में
- ताज़ा
- परत
- जानें
- सीख रहा हूँ
- चलें
- पुस्तकालय
- को यह पसंद है
- लाइन
- लिनक्स
- एलएलएम
- भार
- स्थान
- लॉग इन
- देखिए
- लग रहा है
- कम
- मशीन
- यंत्र अधिगम
- बनाना
- प्रबंधन
- प्रबंध
- प्रबंधक
- मैन्युअल
- मई..
- एमबीए
- मतलब
- साधन
- माप
- उपायों
- मेट्रिक्स
- मिशिगन
- हो सकता है
- ML
- एमएलओपीएस
- आदर्श
- मॉडल
- आधुनिकीकरण
- मॉनिटर
- अधिक
- अधिकांश
- चलती
- विभिन्न
- चाहिए
- नाम
- नामों
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- आवश्यकता
- जरूरत
- ज़रूरत
- शुद्ध कार्यशील
- नया
- नए
- अगला
- NLP
- नोटबुक
- पुस्तिकाओं
- विख्यात
- संख्या
- संख्या
- अनेक
- of
- अक्सर
- on
- केवल
- खुला
- अनुकूलित
- विकल्प
- or
- आर्केस्ट्रा
- आदेश
- मूल
- अन्य
- हमारी
- आउट
- परिणामों
- उल्लिखित
- उत्पादन
- outputs के
- के ऊपर
- कुल
- ओवरलैप
- अपना
- प्राचल
- पैरामीटर
- विशेष
- जुनून
- पेटेंट
- पथ
- पैटर्न
- पैटर्न उपयोग करें
- पीडीएफ
- निष्पादन
- प्रदर्शन
- टुकड़े
- पाइपलाइन
- गंतव्य
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- निभाता
- बिन्दु
- अंक
- पूल
- पदों
- संभव
- पद
- संभावित
- संचालित
- व्यावहारिक
- पूर्ववर्ती
- आवश्यक शर्तें
- प्रस्तुत
- बरकरार रखता है
- संरक्षण
- पिछला
- पहले से
- प्रिंसिपल
- छाप
- प्रोएक्टिव
- प्रक्रिया
- प्रसंस्करण
- एस्ट्रो मॉल
- उत्पाद प्रबंधन
- परियोजनाओं
- संकेतों
- अनुपात
- प्रदान करना
- बशर्ते
- प्रदान करता है
- प्रावधान
- सार्वजनिक
- प्रकाशित
- खींचती
- प्रश्न
- प्रशन
- खपरैल
- पर्वतमाला
- लेकर
- तैयार
- वास्तविक समय
- क्षेत्र
- नुस्खा
- रिकॉर्ड
- को कम करने
- कमी
- उल्लेख
- संदर्भ
- क्षेत्र
- सम्बंधित
- अपेक्षाकृत
- प्रासंगिक
- प्रतिनिधित्व
- प्रतिनिधित्व
- का प्रतिनिधित्व करता है
- अपेक्षित
- की आवश्यकता होती है
- उपयुक्त संसाधन चुनें
- प्रतिक्रिया
- परिणाम
- बहाली
- भूमिका
- भूमिकाओं
- मार्ग
- रन
- दौड़ना
- चलाता है
- sagemaker
- वही
- सहेजें
- स्केल
- अनुसूची
- विज्ञान
- स्कोर
- स्कोर
- Search
- खोजें
- दूसरा
- अनुभाग
- वर्गों
- देखना
- देखा
- चयन
- अर्थ
- वरिष्ठ
- भावना
- भेजा
- अलग
- सेवा
- सेवाएँ
- सत्र
- सेट
- की स्थापना
- कई
- वह
- चाहिए
- दिखाना
- पता चला
- दिखाया
- दिखाता है
- संकेत
- संकेत
- समान
- सरल
- को आसान बनाने में
- आकार
- आशुचित्र
- So
- सॉफ्टवेयर
- सॉफ्टवेयर इंजीनियरिंग
- समाधान
- समाधान ढूंढे
- कुछ
- स्रोत
- सूत्रों का कहना है
- अंतरिक्ष
- तनाव
- विशेषज्ञ
- विनिर्दिष्ट
- बिताना
- चौकोर
- धुआँरा
- ढेर
- मानक
- प्रारंभ
- शुरू
- शुरुआत में
- राज्य
- आँकड़े
- कदम
- भंडारण
- की दुकान
- संग्रहित
- सफल
- ऐसा
- योग
- निश्चित
- प्रणाली
- सिस्टम
- तालिका
- लेना
- कार्य
- तकनीक
- टेक्नोलॉजीज
- टेक्नोलॉजी
- टेक्स्ट
- पाठ पीढ़ी
- कि
- RSI
- जानकारी
- स्रोत
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- इसका
- उन
- तीन
- यहाँ
- पहर
- टीएलएस
- सेवा मेरे
- एक साथ
- विषय
- कुल
- बदालना
- यात्रा का
- प्रवृत्ति
- रुझान
- कोशिश करता
- कोशिश
- दो
- प्रकार
- के अंतर्गत
- विश्वविद्यालय
- यूनिवर्सिटी ऑफ मिशिगन
- यूआरएल
- us
- उपयोग
- प्रयुक्त
- उपयोगी
- उपयोगकर्ता
- यूजर इंटरफेस
- उपयोगकर्ताओं
- का उपयोग
- सत्यापन
- मूल्य
- मान
- परिवर्तनशील
- चर
- विविधता
- विभिन्न
- वेक्टर
- वैक्टर
- वाहन
- के माध्यम से
- दृष्टि
- दृश्य
- walkthrough
- करना चाहते हैं
- था
- मार्ग..
- we
- वेब
- वेब सेवाओं
- कुंआ
- कब
- या
- कौन कौन से
- जब
- मर्जी
- साथ में
- अंदर
- बिना
- महिलाओं
- काम
- काम किया
- काम कर रहे
- वर्कस्टेशन
- बदतर
- होगा
- साल
- अभी तक
- इसलिए आप
- आपका
- जेफिरनेट
- क्षेत्र