वस्तुतः सभी ग्राहकों की तरह, आप सर्वोत्तम प्रदर्शन प्राप्त करते हुए यथासंभव कम खर्च करना चाहते हैं। इसका मतलब है कि आपको मूल्य-प्रदर्शन पर ध्यान देने की आवश्यकता है। साथ अमेज़न रेडशिफ्ट, आप अपना केक ले सकते हैं और इसे भी खा सकते हैं! अमेज़ॅन रेडशिफ्ट सैकड़ों समवर्ती उपयोगकर्ताओं का समर्थन करने के लिए समवर्ती स्केलिंग जैसी उन्नत तकनीकों का उपयोग करके वास्तविक दुनिया के वर्कलोड पर अन्य क्लाउड डेटा वेयरहाउस की तुलना में प्रति उपयोगकर्ता 4.9 गुना कम लागत और 7.9 गुना बेहतर मूल्य-प्रदर्शन प्रदान करता है, तेज क्वेरी प्रदर्शन के लिए उन्नत स्ट्रिंग एन्कोडिंग , और अमेज़ॅन रेडशिफ्ट सर्वर रहित प्रदर्शन संवर्द्धन. यह समझने के लिए पढ़ें कि मूल्य-प्रदर्शन क्यों मायने रखता है और अमेज़ॅन रेडशिफ्ट मूल्य-प्रदर्शन इस बात का माप है कि किसी विशेष स्तर के कार्यभार प्रदर्शन, अर्थात् प्रदर्शन आरओआई (निवेश पर रिटर्न) प्राप्त करने में कितनी लागत आती है।
चूँकि मूल्य और प्रदर्शन दोनों ही मूल्य-प्रदर्शन गणना में शामिल होते हैं, इसलिए मूल्य-प्रदर्शन के बारे में सोचने के दो तरीके हैं। पहला तरीका मूल्य को स्थिर रखना है: यदि आपके पास खर्च करने के लिए $1 है, तो आपको अपने डेटा वेयरहाउस से कितना प्रदर्शन मिलता है? बेहतर मूल्य-प्रदर्शन वाला डेटाबेस खर्च किए गए प्रत्येक $1 के लिए बेहतर प्रदर्शन प्रदान करेगा। इसलिए, समान लागत वाले दो डेटा वेयरहाउस की तुलना करते समय मूल्य स्थिर रखने पर, बेहतर मूल्य-प्रदर्शन वाला डेटाबेस आपके प्रश्नों को तेज़ी से चलाएगा. मूल्य-प्रदर्शन को देखने का दूसरा तरीका प्रदर्शन को स्थिर रखना है: यदि आप चाहते हैं कि आपका कार्यभार 10 मिनट में समाप्त हो जाए, तो इसकी लागत क्या होगी? बेहतर मूल्य-प्रदर्शन वाला डेटाबेस आपके कार्यभार को कम लागत पर 10 मिनट में चला देगा। इसलिए, समान प्रदर्शन देने के लिए आकार के दो डेटा वेयरहाउस की तुलना करते समय प्रदर्शन को स्थिर रखने पर, बेहतर मूल्य-प्रदर्शन वाले डेटाबेस की लागत कम होगी और आपका पैसा बचेगा।
अंत में, मूल्य-प्रदर्शन का एक अन्य महत्वपूर्ण पहलू पूर्वानुमानशीलता है। यह जानना कि डेटा वेयरहाउस उपयोगकर्ताओं की संख्या बढ़ने पर आपके डेटा वेयरहाउस की लागत कितनी होगी, योजना बनाने के लिए महत्वपूर्ण है। इसे न केवल आज सर्वोत्तम मूल्य-प्रदर्शन प्रदान करना चाहिए, बल्कि अधिक उपयोगकर्ताओं और कार्यभार जुड़ने पर पूर्वानुमानित पैमाने पर और सर्वोत्तम मूल्य-प्रदर्शन भी प्रदान करना चाहिए। एक आदर्श डेटा वेयरहाउस होना चाहिए रैखिक पैमाने- क्वेरी थ्रूपुट को दोगुना करने के लिए अपने डेटा वेयरहाउस को स्केल करना आदर्श रूप से दोगुना (या कम) खर्च करना चाहिए।
इस पोस्ट में, हम यह बताने के लिए प्रदर्शन परिणाम साझा करते हैं कि कैसे अमेज़ॅन रेडशिफ्ट अग्रणी वैकल्पिक क्लाउड डेटा वेयरहाउस की तुलना में काफी बेहतर मूल्य-प्रदर्शन प्रदान करता है। इसका मतलब यह है कि यदि आप Amazon Redshift पर उतनी ही राशि खर्च करते हैं जितनी आप इन अन्य डेटा वेयरहाउसों में से किसी एक पर खर्च करते हैं, तो आपको Amazon Redshift के साथ बेहतर प्रदर्शन मिलेगा। वैकल्पिक रूप से, यदि आप समान प्रदर्शन देने के लिए अपने रेडशिफ्ट क्लस्टर को आकार देते हैं, तो आपको इन विकल्पों की तुलना में कम लागत दिखाई देगी।
वास्तविक दुनिया के कार्यभार के लिए मूल्य-प्रदर्शन
आप जटिल एक्स्ट्रैक्ट, ट्रांसफ़ॉर्म और लोड (ईटीएल)-आधारित रिपोर्टों के बैच-प्रोसेसिंग और वास्तविक समय स्ट्रीमिंग एनालिटिक्स से लेकर कम-विलंबता बिजनेस इंटेलिजेंस (बीआई) डैशबोर्ड तक, वर्कलोड की एक बहुत विस्तृत विविधता को सशक्त बनाने के लिए अमेज़ॅन रेडशिफ्ट का उपयोग कर सकते हैं। एक ही समय में सैकड़ों या यहां तक कि हजारों उपयोगकर्ताओं को उप-सेकंड प्रतिक्रिया समय और बीच में सब कुछ प्रदान करने की आवश्यकता है। अपने ग्राहकों के लिए मूल्य-प्रदर्शन में लगातार सुधार करने का एक तरीका रेडशिफ्ट बेड़े से सॉफ्टवेयर और हार्डवेयर प्रदर्शन टेलीमेट्री की लगातार समीक्षा करना, अवसरों और ग्राहक उपयोग के मामलों की तलाश करना है जहां हम अमेज़ॅन रेडशिफ्ट प्रदर्शन को और बेहतर बना सकते हैं।
फ्लीट टेलीमेट्री द्वारा संचालित प्रदर्शन अनुकूलन के कुछ हालिया उदाहरणों में शामिल हैं:
- स्ट्रिंग क्वेरी अनुकूलन - अमेज़ॅन रेडशिफ्ट ने रेडशिफ्ट बेड़े में विभिन्न डेटा प्रकारों को कैसे संसाधित किया, इसका विश्लेषण करके, हमने पाया कि स्ट्रिंग-भारी प्रश्नों को अनुकूलित करने से हमारे ग्राहकों के कार्यभार में महत्वपूर्ण लाभ होगा। (हम इस पोस्ट में बाद में इस पर अधिक विस्तार से चर्चा करेंगे।)
- स्वचालित भौतिक दृश्य - हमने पाया कि अमेज़ॅन रेडशिफ्ट ग्राहक अक्सर कई क्वेरी चलाते हैं जिनमें सामान्य सबक्वेरी पैटर्न होते हैं। उदाहरण के लिए, कई अलग-अलग क्वेरीज़ समान जॉइन कंडीशन का उपयोग करके समान तीन तालिकाओं में शामिल हो सकती हैं। अमेज़ॅन रेडशिफ्ट अब स्वचालित रूप से भौतिक दृश्यों को बनाने और बनाए रखने में सक्षम है और फिर मशीन-सीखे गए का उपयोग करके भौतिक दृश्यों का उपयोग करने के लिए प्रश्नों को पारदर्शी रूप से फिर से लिखता है। स्वचालित भौतिकीकृत दृश्य Amazon Redshift में ऑटोनॉमिक्स सुविधा। सक्षम होने पर, स्वचालित भौतिक दृश्य किसी भी उपयोगकर्ता के हस्तक्षेप के बिना दोहराए जाने वाले प्रश्नों के लिए क्वेरी प्रदर्शन को पारदर्शी रूप से बढ़ा सकते हैं। (ध्यान दें कि इस पोस्ट में चर्चा किए गए किसी भी बेंचमार्क परिणाम में स्वचालित भौतिक दृश्यों का उपयोग नहीं किया गया था)।
- उच्च-समवर्ती कार्यभार - एक बढ़ता हुआ उपयोग मामला जो हम देख रहे हैं वह है डैशबोर्ड-जैसे वर्कलोड को पूरा करने के लिए अमेज़ॅन रेडशिफ्ट का उपयोग करना। इन कार्यभारों को एकल-अंकीय सेकंड या उससे कम के वांछित क्वेरी प्रतिक्रिया समय की विशेषता होती है, जिसमें दसियों या सैकड़ों समवर्ती उपयोगकर्ता एक साथ स्पाइकी और अक्सर अप्रत्याशित उपयोग पैटर्न के साथ क्वेरी चलाते हैं। इसका प्रोटोटाइप उदाहरण अमेज़ॅन रेडशिफ्ट-समर्थित बीआई डैशबोर्ड है जिसमें सोमवार की सुबह ट्रैफ़िक में वृद्धि होती है जब बड़ी संख्या में उपयोगकर्ता अपना सप्ताह शुरू करते हैं।
विशेष रूप से उच्च-समवर्ती वर्कलोड में बहुत व्यापक प्रयोज्यता होती है: अधिकांश डेटा वेयरहाउस वर्कलोड समवर्ती पर काम करते हैं, और एक ही समय में सैकड़ों या हजारों उपयोगकर्ताओं के लिए अमेज़ॅन रेडशिफ्ट पर क्वेरी चलाना असामान्य नहीं है। अमेज़ॅन रेडशिफ्ट को क्वेरी प्रतिक्रिया समय को पूर्वानुमानित और तेज़ रखने के लिए डिज़ाइन किया गया था। रेडशिफ्ट सर्वरलेस क्वेरी प्रतिक्रिया समय को तेज और पूर्वानुमानित रखने के लिए आवश्यकतानुसार गणना जोड़कर और हटाकर आपके लिए स्वचालित रूप से ऐसा करता है। इसका मतलब है कि एक रेडशिफ्ट सर्वर रहित-समर्थित डैशबोर्ड जो एक या दो उपयोगकर्ताओं द्वारा एक्सेस किए जाने पर तेज़ी से लोड होता है, तब भी तेज़ी से लोड होता रहेगा जब कई उपयोगकर्ता इसे एक ही समय में लोड कर रहे हों।
इस प्रकार के कार्यभार का अनुकरण करने के लिए, हमने 100 जीबी डेटा सेट के साथ टीपीसी-डीएस से प्राप्त बेंचमार्क का उपयोग किया। टीपीसी-डीएस एक उद्योग-मानक बेंचमार्क है जिसमें विभिन्न प्रकार के विशिष्ट डेटा वेयरहाउस क्वेरी शामिल हैं। 100 जीबी के इस अपेक्षाकृत छोटे पैमाने पर, इस बेंचमार्क में क्वेरीज़ रेडशिफ्ट सर्वरलेस पर औसतन कुछ सेकंड में चलती हैं, जो कि एक इंटरैक्टिव बीआई डैशबोर्ड लोड करने वाले उपयोगकर्ताओं की अपेक्षा का प्रतिनिधित्व करता है। हमने इस बेंचमार्क के 1-200 समवर्ती परीक्षण चलाए, एक ही समय में डैशबोर्ड लोड करने का प्रयास करने वाले 1-200 उपयोगकर्ताओं के बीच अनुकरण किया। हमने कई लोकप्रिय वैकल्पिक क्लाउड डेटा वेयरहाउस के खिलाफ परीक्षण भी दोहराया है जो स्वचालित रूप से स्केलिंग का समर्थन करते हैं (यदि आप पोस्ट से परिचित हैं अमेज़ॅन रेडशिफ्ट ने अपना मूल्य-प्रदर्शन नेतृत्व जारी रखा है, हमने प्रतिस्पर्धी ए को शामिल नहीं किया क्योंकि यह स्वचालित रूप से स्केलिंग का समर्थन नहीं करता है)। हमने औसत क्वेरी प्रतिक्रिया समय मापा, जिसका अर्थ है कि उपयोगकर्ता अपने प्रश्नों के समाप्त होने (या अपने डैशबोर्ड को लोड होने) के लिए कितनी देर तक प्रतीक्षा करेगा। परिणाम निम्नलिखित चार्ट में दिखाए गए हैं।
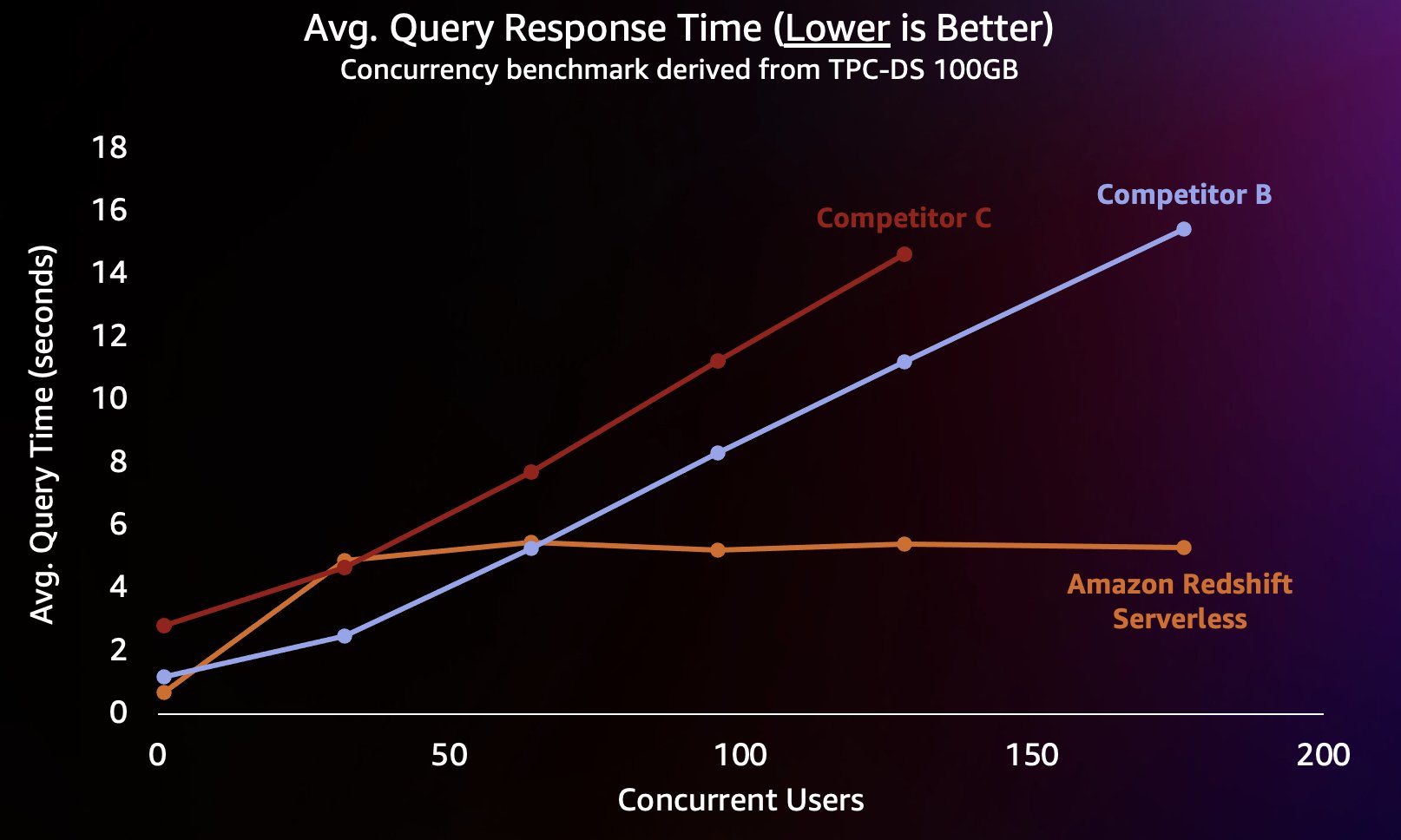
प्रतियोगी बी लगभग 64 समवर्ती प्रश्नों तक अच्छी तरह से स्केल करता है, जिस बिंदु पर यह अतिरिक्त गणना प्रदान करने में असमर्थ होता है और प्रश्न कतारबद्ध होने लगते हैं, जिससे क्वेरी प्रतिक्रिया समय बढ़ जाता है। यद्यपि प्रतिस्पर्धी सी स्वचालित रूप से स्केल करने में सक्षम है, यह अमेज़ॅन रेडशिफ्ट और प्रतिस्पर्धी बी दोनों की तुलना में कम क्वेरी थ्रूपुट को स्केल करता है और क्वेरी रनटाइम को कम रखने में सक्षम नहीं है। इसके अलावा, जब इसकी गणना समाप्त हो जाती है तो यह कतारबद्ध प्रश्नों का समर्थन नहीं करता है, जो इसे लगभग 128 समवर्ती उपयोगकर्ताओं से आगे बढ़ने से रोकता है। इससे अधिक अतिरिक्त प्रश्न सबमिट करने पर सिस्टम द्वारा अस्वीकार कर दिया जाता है।
यहां, रेडशिफ्ट सर्वरलेस क्वेरी प्रतिक्रिया समय को लगभग 5 सेकंड पर अपेक्षाकृत सुसंगत रखने में सक्षम है, तब भी जब सैकड़ों उपयोगकर्ता एक ही समय में क्वेरी चला रहे हों। जैसे-जैसे वेयरहाउस पर लोड बढ़ता है, प्रतिस्पर्धी बी और सी के लिए औसत क्वेरी प्रतिक्रिया समय लगातार बढ़ता है, जिसके परिणामस्वरूप डेटा वेयरहाउस व्यस्त होने पर उपयोगकर्ताओं को अपने प्रश्नों के लिए लंबे समय तक (16 सेकंड तक) इंतजार करना पड़ता है। इसका मतलब यह है कि यदि कोई उपयोगकर्ता डैशबोर्ड को रीफ्रेश करने का प्रयास कर रहा है (जो पुनः लोड होने पर कई समवर्ती क्वेरी भी सबमिट कर सकता है), अमेज़ॅन रेडशिफ्ट डैशबोर्ड लोड समय को कहीं अधिक सुसंगत रखने में सक्षम होगा, भले ही डैशबोर्ड दसियों या सैकड़ों अन्य द्वारा लोड किया जा रहा हो उपयोगकर्ता एक ही समय में.
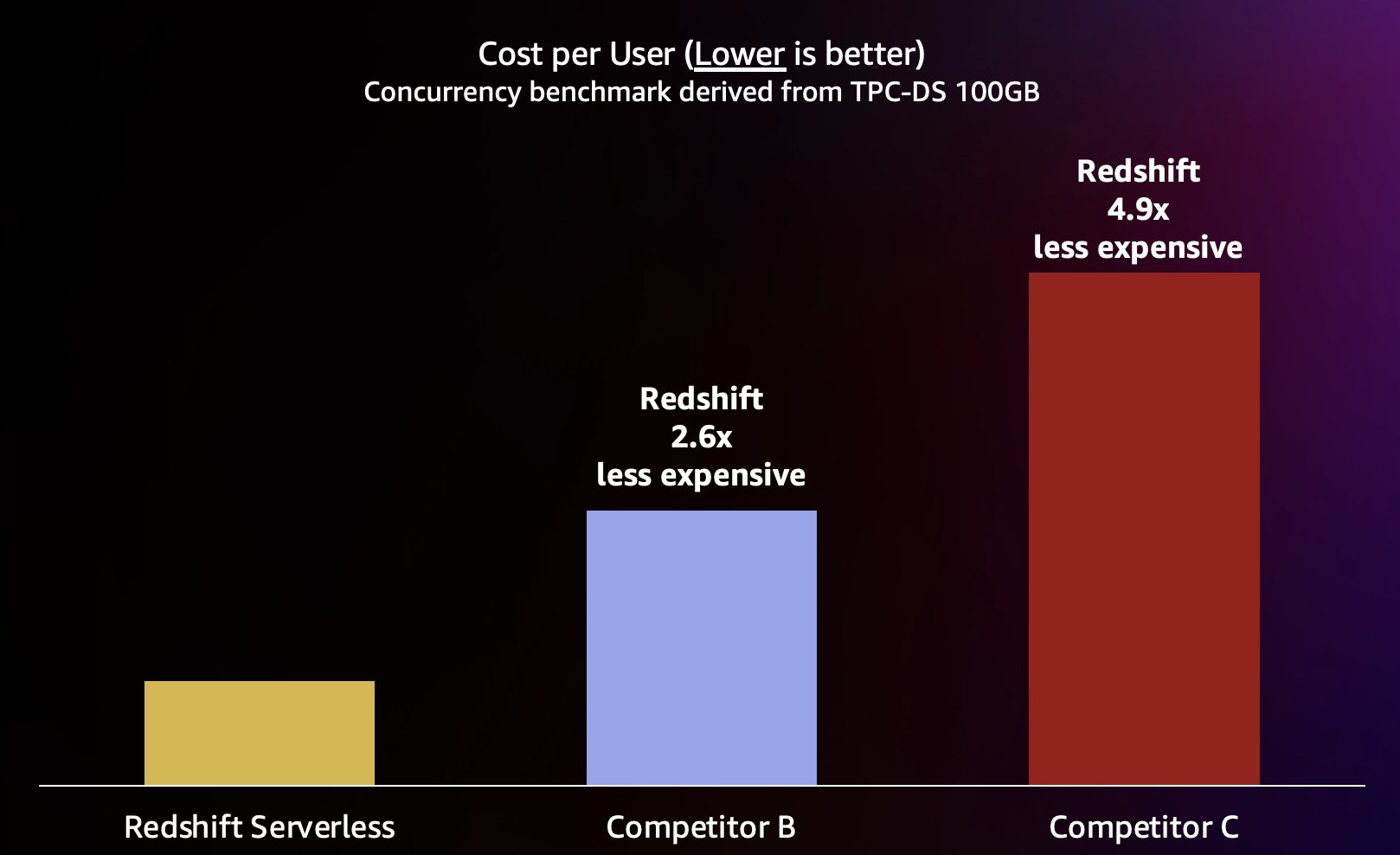
क्योंकि अमेज़ॅन रेडशिफ्ट छोटी क्वेरी के लिए बहुत उच्च क्वेरी थ्रूपुट प्रदान करने में सक्षम है (जैसा कि हमने इसके बारे में लिखा था)। अमेज़ॅन रेडशिफ्ट ने अपना मूल्य-प्रदर्शन नेतृत्व जारी रखा है), यह अधिक कुशलता से स्केलिंग करते समय इन उच्च समवर्तीताओं को संभालने में भी सक्षम है और इसलिए काफी कम लागत पर। इसे मापने के लिए, हम प्रकाशित का उपयोग करके मूल्य-प्रदर्शन को देखते हैं ऑन-डिमांड मूल्य निर्धारण पिछले परीक्षण में प्रत्येक गोदाम के लिए, निम्नलिखित चार्ट में दिखाया गया है। यह ध्यान देने योग्य है कि इसका उपयोग करें आरक्षित उदाहरण (आरआई), विशेष रूप से सभी अग्रिम भुगतान विकल्प के साथ खरीदे गए 3-वर्षीय आरआई में प्रावधानित क्लस्टर पर अमेज़ॅन रेडशिफ्ट चलाने की लागत सबसे कम है, जिसके परिणामस्वरूप ऑन-डिमांड या अन्य आरआई विकल्पों की तुलना में सबसे अच्छा सापेक्ष मूल्य-प्रदर्शन होता है।

इसलिए अमेज़ॅन रेडशिफ्ट न केवल उच्च समवर्ती पर बेहतर प्रदर्शन देने में सक्षम है, बल्कि यह काफी कम लागत पर ऐसा करने में सक्षम है। मूल्य-प्रदर्शन चार्ट में प्रत्येक डेटा बिंदु निर्दिष्ट समवर्ती पर बेंचमार्क चलाने की लागत के बराबर है। क्योंकि मूल्य-प्रदर्शन रैखिक है, हम किसी भी संगामिति पर बेंचमार्क को चलाने की लागत को समवर्ती (इस चार्ट में समवर्ती उपयोगकर्ताओं की संख्या) से विभाजित कर सकते हैं ताकि हमें पता चल सके कि इस विशेष बेंचमार्क के लिए प्रत्येक नए उपयोगकर्ता को जोड़ने की लागत कितनी है।
पिछले परिणामों को दोहराना आसान है। बेंचमार्क में प्रयुक्त सभी प्रश्न हमारे यहां उपलब्ध हैं गिटहब भंडार और प्रदर्शन को डेटा वेयरहाउस लॉन्च करके, अमेज़ॅन रेडशिफ्ट (या अन्य वेयरहाउस पर संबंधित ऑटो स्केलिंग सुविधा) पर कॉन्करेंसी स्केलिंग को सक्षम करके, डेटा को बॉक्स से बाहर लोड करके (कोई मैन्युअल ट्यूनिंग या डेटाबेस-विशिष्ट सेटअप नहीं) और फिर चलाकर मापा जाता है। प्रत्येक डेटा वेयरहाउस पर 1 के चरणों में 200-32 तक समवर्ती प्रश्नों की समवर्ती धारा। वही GitHub रेपो पूर्व-निर्मित (और असंशोधित) TPC-DS डेटा का संदर्भ देता है अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस3) आधिकारिक टीपीसी-डीएस डेटा जेनरेशन किट का उपयोग करके विभिन्न पैमानों पर।
स्ट्रिंग-भारी कार्यभार का अनुकूलन
जैसा कि पहले उल्लेख किया गया है, अमेज़ॅन रेडशिफ्ट टीम अपने ग्राहकों के लिए बेहतर मूल्य-प्रदर्शन प्रदान करने के लिए लगातार नए अवसरों की तलाश कर रही है। एक सुधार जिसे हमने हाल ही में लॉन्च किया है, जिससे प्रदर्शन में काफी सुधार हुआ है, वह एक अनुकूलन है जो स्ट्रिंग डेटा पर प्रश्नों के प्रदर्शन को तेज करता है। उदाहरण के लिए, हो सकता है कि आप न्यूयॉर्क शहर में स्थित खुदरा स्टोरों से उत्पन्न कुल राजस्व का पता लगाना चाहें, जैसे किसी प्रश्न के साथ SELECT sum(price) FROM sales WHERE city = ‘New York’. यह क्वेरी स्ट्रिंग डेटा पर एक विधेय लागू कर रही है (city = ‘New York’). जैसा कि आप कल्पना कर सकते हैं, डेटा वेयरहाउस अनुप्रयोगों में स्ट्रिंग डेटा प्रोसेसिंग सर्वव्यापी है।
यह निर्धारित करने के लिए कि ग्राहकों का कार्यभार कितनी बार स्ट्रिंग्स तक पहुंचता है, हमने अमेज़ॅन रेडशिफ्ट द्वारा प्रबंधित हजारों ग्राहक समूहों के बेड़े टेलीमेट्री का उपयोग करके स्ट्रिंग डेटा प्रकार के उपयोग का विस्तृत विश्लेषण किया। हमारा विश्लेषण बताता है कि 90% क्लस्टरों में, स्ट्रिंग कॉलम सभी कॉलमों का कम से कम 30% हिस्सा बनाते हैं, और 50% क्लस्टरों में, स्ट्रिंग कॉलम सभी कॉलमों का कम से कम 50% हिस्सा बनाते हैं। इसके अलावा, अधिकांश क्वेरीज़ अमेज़ॅन रेडशिफ्ट क्लाउड डेटा वेयरहाउस प्लेटफ़ॉर्म पर कम से कम एक स्ट्रिंग कॉलम तक पहुंचती हैं। एक अन्य महत्वपूर्ण कारक यह है कि स्ट्रिंग डेटा अक्सर कम कार्डिनैलिटी वाला होता है, जिसका अर्थ है कि कॉलम में अद्वितीय मानों का अपेक्षाकृत छोटा सेट होता है। उदाहरण के लिए, यद्यपि ए orders बिक्री डेटा का प्रतिनिधित्व करने वाली तालिका में अरबों पंक्तियाँ हो सकती हैं, और order_status उस तालिका के कॉलम में उन अरबों पंक्तियों में केवल कुछ अद्वितीय मान हो सकते हैं, जैसे pending, in process, तथा completed.
इस लेखन के समय, अमेज़ॅन रेडशिफ्ट में अधिकांश स्ट्रिंग कॉलम संपीड़ित हैं एलजेडओ or जेडएसटीडी एल्गोरिदम. ये अच्छे सामान्य प्रयोजन संपीड़न एल्गोरिदम हैं, लेकिन इन्हें कम-कार्डिनैलिटी स्ट्रिंग डेटा का लाभ उठाने के लिए डिज़ाइन नहीं किया गया है। विशेष रूप से, उन्हें आवश्यकता होती है कि डेटा को संचालित करने से पहले डीकंप्रेस किया जाए, और हार्डवेयर मेमोरी बैंडविड्थ के उपयोग में वे कम कुशल हैं। कम-कार्डिनैलिटी डेटा के लिए, एक अन्य प्रकार की एन्कोडिंग है जो अधिक इष्टतम हो सकती है: बाइटडिक्ट. यह एन्कोडिंग एक शब्दकोश-एन्कोडिंग योजना का उपयोग करती है जो डेटाबेस इंजन को पहले इसे डीकंप्रेस करने की आवश्यकता के बिना संपीड़ित डेटा पर सीधे काम करने की अनुमति देती है।
स्ट्रिंग-हैवी वर्कलोड के लिए मूल्य-प्रदर्शन को और बेहतर बनाने के लिए, अमेज़ॅन रेडशिफ्ट अब अतिरिक्त प्रदर्शन संवर्द्धन पेश कर रहा है जो स्कैन को गति देता है और कम-कार्डिनैलिटी स्ट्रिंग कॉलम पर मूल्यांकन करता है, जो कि BYTEDICT के रूप में एन्कोड किए गए हैं, 5-63 गुना तेजी से (परिणाम देखें) अगला भाग) LZO या ZSTD जैसे वैकल्पिक संपीड़न एन्कोडिंग की तुलना में। अमेज़ॅन रेडशिफ्ट हल्के, सीपीयू-कुशल, BYTEDICT-एनकोडेड, कम-कार्डिनैलिटी स्ट्रिंग कॉलम पर स्कैन को वेक्टराइज़ करके इस प्रदर्शन में सुधार प्राप्त करता है। ये स्ट्रिंग-प्रोसेसिंग अनुकूलन आधुनिक हार्डवेयर द्वारा वहन की जाने वाली मेमोरी बैंडविड्थ का प्रभावी उपयोग करते हैं, जिससे स्ट्रिंग डेटा पर वास्तविक समय विश्लेषण सक्षम होता है। ये नई शुरू की गई प्रदर्शन क्षमताएं कम-कार्डिनैलिटी स्ट्रिंग कॉलम (कुछ सौ अद्वितीय स्ट्रिंग मानों तक) के लिए इष्टतम हैं।
आप सक्षम करके इस नए उच्च प्रदर्शन स्ट्रिंग एन्हांसमेंट से स्वचालित रूप से लाभ उठा सकते हैं स्वचालित तालिका अनुकूलन आपके Amazon Redshift डेटा वेयरहाउस में। यदि आपकी तालिकाओं पर स्वचालित तालिका अनुकूलन सक्षम नहीं है, तो आप अनुशंसाएँ प्राप्त कर सकते हैं अमेज़न रेडशिफ्ट सलाहकार अमेज़ॅन रेडशिफ्ट कंसोल में BYTEDICT एन्कोडिंग के लिए एक स्ट्रिंग कॉलम की उपयुक्तता पर। आप नई तालिकाओं को भी परिभाषित कर सकते हैं जिनमें BYTEDICT एन्कोडिंग के साथ कम-कार्डिनैलिटी स्ट्रिंग कॉलम हैं। Amazon Redshift में स्ट्रिंग एन्हांसमेंट अब सभी AWS क्षेत्रों में उपलब्ध हैं अमेज़न रेडशिफ्ट उपलब्ध है.
प्रदर्शन परिणाम
हमारे स्ट्रिंग संवर्द्धन के प्रदर्शन प्रभाव को मापने के लिए, हमने 10TB (टेरा बाइट) डेटासेट तैयार किया जिसमें कम-कार्डिनैलिटी स्ट्रिंग डेटा शामिल था। हमने अमेज़ॅन रेडशिफ्ट फ्लीट टेलीमेट्री से स्ट्रिंग लंबाई के 25वें, 50वें और 75वें प्रतिशतक के अनुरूप छोटी, मध्यम और लंबी स्ट्रिंग का उपयोग करके डेटा के तीन संस्करण तैयार किए। हमने इस डेटा को अमेज़ॅन रेडशिफ्ट में दो बार लोड किया, इसे एक मामले में एलजेडओ संपीड़न का उपयोग करके और दूसरे में BYTEDICT संपीड़न का उपयोग करके एन्कोड किया। अंत में, हमने स्कैन-भारी प्रश्नों के प्रदर्शन को मापा जो कई पंक्तियाँ (तालिका का 90%), पंक्तियों की एक मध्यम संख्या (तालिका का 50%), और इन निम्न पर कुछ पंक्तियाँ (तालिका का 1%) लौटाते हैं। -कार्डिनैलिटी स्ट्रिंग डेटासेट। प्रदर्शन परिणाम निम्नलिखित चार्ट में संक्षेपित हैं।

पंक्तियों के उच्च प्रतिशत से मेल खाने वाले विधेय वाले प्रश्नों में LZO की तुलना में नए वेक्टरकृत BYTEDICT एन्कोडिंग के साथ 5-30 गुना सुधार देखा गया, जबकि कम प्रतिशत पंक्तियों से मेल खाने वाले विधेय वाले प्रश्नों में इस आंतरिक बेंचमार्क में 10-63 गुना सुधार देखा गया।
रेडशिफ्ट सर्वर रहित मूल्य-प्रदर्शन
इस पोस्ट में प्रस्तुत उच्च-समवर्ती प्रदर्शन परिणामों के अलावा, हमने बड़े 3TB डेटासेट का उपयोग करके अन्य डेटा वेयरहाउस के साथ रेडशिफ्ट सर्वरलेस के मूल्य-प्रदर्शन की तुलना करने के लिए टीपीसी-डीएस-व्युत्पन्न क्लाउड डेटा वेयरहाउस बेंचमार्क का भी उपयोग किया। हमने ऐसे डेटा वेयरहाउस चुने जिनकी कीमत समान थी, इस मामले में सार्वजनिक रूप से उपलब्ध ऑन-डिमांड मूल्य निर्धारण का उपयोग करते हुए $10 प्रति घंटे के 32% के भीतर। ये नतीजे बताते हैं कि, अमेज़ॅन रेडशिफ्ट आरए3 उदाहरणों की तरह, रेडशिफ्ट सर्वरलेस अन्य प्रमुख क्लाउड डेटा वेयरहाउस की तुलना में बेहतर मूल्य-प्रदर्शन प्रदान करता है। हमेशा की तरह, इन परिणामों को हमारी SQL स्क्रिप्ट का उपयोग करके दोहराया जा सकता है गिटहब भंडार.

हम आपको अपना स्वयं का उपयोग करके Amazon Redshift आज़माने के लिए प्रोत्साहित करते हैं अवधारणा के सुबूत वर्कलोड यह देखने का सबसे अच्छा तरीका है कि अमेज़ॅन रेडशिफ्ट आपकी डेटा एनालिटिक्स आवश्यकताओं को कैसे पूरा कर सकता है।
अपने कार्यभार के लिए सर्वोत्तम मूल्य-प्रदर्शन खोजें
इस पोस्ट में उपयोग किए गए बेंचमार्क उद्योग-मानक टीपीसी-डीएस बेंचमार्क से लिए गए हैं और इनमें निम्नलिखित विशेषताएं हैं:
- स्कीमा और डेटा का उपयोग टीपीसी-डीएस से असंशोधित किया जाता है।
- क्वेरीज़ आधिकारिक टीपीसी-डीएस किट का उपयोग करके उत्पन्न की जाती हैं, जिसमें क्वेरी पैरामीटर टीपीसी-डीएस किट के डिफ़ॉल्ट यादृच्छिक बीज का उपयोग करके उत्पन्न होते हैं। यदि वेयरहाउस डिफ़ॉल्ट टीपीसी-डीएस क्वेरी की एसक्यूएल बोली का समर्थन नहीं करता है तो टीपीसी-अनुमोदित क्वेरी वेरिएंट का उपयोग वेयरहाउस के लिए किया जाता है।
- परीक्षण में 99 टीपीसी-डीएस सेलेक्ट क्वेरीज़ शामिल हैं। इसमें रखरखाव और थ्रूपुट चरण शामिल नहीं हैं।
- एकल 3टीबी समवर्ती परीक्षण के लिए, तीन पावर रन चलाए गए, और प्रत्येक डेटा वेयरहाउस के लिए सबसे अच्छा रन लिया गया।
- टीपीसी-डीएस प्रश्नों के लिए मूल्य-प्रदर्शन की गणना घंटों में बेंचमार्क रनटाइम की लागत प्रति घंटे (यूएसडी) के रूप में की जाती है, जो बेंचमार्क को चलाने की लागत के बराबर है। नवीनतम प्रकाशित ऑन-डिमांड मूल्य निर्धारण का उपयोग सभी डेटा वेयरहाउसों के लिए किया जाता है, न कि आरक्षित इंस्टेंस मूल्य निर्धारण के लिए जैसा कि पहले उल्लेख किया गया है।
हम इसे क्लाउड डेटा वेयरहाउस बेंचमार्क कहते हैं, और आप हमारे में उपलब्ध स्क्रिप्ट, क्वेरी और डेटा का उपयोग करके पिछले बेंचमार्क परिणामों को आसानी से पुन: पेश कर सकते हैं। गिटहब भंडार. यह इस पोस्ट में वर्णित टीपीसी-डीएस बेंचमार्क से लिया गया है, और इस तरह प्रकाशित टीपीसी-डीएस परिणामों से तुलनीय नहीं है, क्योंकि हमारे परीक्षणों के परिणाम आधिकारिक विनिर्देश का अनुपालन नहीं करते हैं।
निष्कर्ष
अमेज़ॅन रेडशिफ्ट विभिन्न प्रकार के कार्यभार के लिए उद्योग का सर्वोत्तम मूल्य-प्रदर्शन प्रदान करने के लिए प्रतिबद्ध है। रेडशिफ्ट सर्वरलेस सर्वोत्तम (न्यूनतम) मूल्य-प्रदर्शन के साथ रैखिक रूप से स्केल करता है, लगातार क्वेरी प्रतिक्रिया समय को बनाए रखते हुए सैकड़ों समवर्ती उपयोगकर्ताओं का समर्थन करता है। इस पोस्ट में चर्चा किए गए परीक्षण परिणामों के आधार पर, अमेज़ॅन रेडशिफ्ट का निकटतम प्रतिद्वंद्वी (प्रतियोगी बी) की तुलना में समवर्ती स्तर पर 2.6 गुना बेहतर मूल्य-प्रदर्शन है। जैसा कि पहले उल्लेख किया गया है, 3-वर्षीय ऑल अपफ्रंट विकल्प के साथ आरक्षित इंस्टेंस का उपयोग करने से आपको अमेज़ॅन रेडशिफ्ट चलाने की सबसे कम लागत मिलती है, जिसके परिणामस्वरूप ऑन-डिमांड इंस्टेंस मूल्य निर्धारण की तुलना में बेहतर सापेक्ष मूल्य-प्रदर्शन होता है, जिसका उपयोग हमने इस पोस्ट में किया था। निरंतर प्रदर्शन सुधार के लिए हमारे दृष्टिकोण में महत्वपूर्ण प्रदर्शन अनुकूलन करने के अवसरों की पहचान करने के लिए निरंतर बेड़े डेटा विश्लेषण के साथ-साथ ग्राहक उपयोग के मामलों और उनके संबंधित स्केलेबिलिटी बाधाओं को समझने के लिए ग्राहक जुनून का एक अनूठा संयोजन शामिल है।
प्रत्येक कार्यभार में अद्वितीय विशेषताएं होती हैं, इसलिए यदि आप अभी शुरुआत कर रहे हैं, तो a अवधारणा के सुबूत यह समझने का सबसे अच्छा तरीका है कि कैसे Amazon Redshift बेहतर प्रदर्शन प्रदान करते हुए आपकी लागत कम कर सकता है। अवधारणा का अपना प्रमाण चलाते समय, सही मेट्रिक्स-क्वेरी थ्रूपुट (प्रति घंटे प्रश्नों की संख्या), प्रतिक्रिया समय और मूल्य-प्रदर्शन पर ध्यान देना महत्वपूर्ण है। आप स्वयं अवधारणा का प्रमाण चलाकर डेटा-संचालित निर्णय ले सकते हैं सहायता से AWS से या a सिस्टम एकीकरण और परामर्श भागीदार.
अमेज़ॅन रेडशिफ्ट में नवीनतम विकास के साथ अपडेट रहने के लिए, इसका अनुसरण करें अमेज़न रेडशिफ्ट में नया क्या है? खिलाओ.
लेखक के बारे में
 स्टीफ़न ग्रोमोल अमेज़ॅन रेडशिफ्ट टीम के साथ एक वरिष्ठ प्रदर्शन इंजीनियर हैं जहां वह रेडशिफ्ट प्रदर्शन को मापने और सुधारने के लिए जिम्मेदार हैं। अपने खाली समय में, वह खाना बनाना, अपने तीन लड़कों के साथ खेलना और जलाऊ लकड़ी काटना पसंद करता है।
स्टीफ़न ग्रोमोल अमेज़ॅन रेडशिफ्ट टीम के साथ एक वरिष्ठ प्रदर्शन इंजीनियर हैं जहां वह रेडशिफ्ट प्रदर्शन को मापने और सुधारने के लिए जिम्मेदार हैं। अपने खाली समय में, वह खाना बनाना, अपने तीन लड़कों के साथ खेलना और जलाऊ लकड़ी काटना पसंद करता है।
 रवि अनिमी अमेज़ॅन रेडशिफ्ट टीम में एक वरिष्ठ उत्पाद प्रबंधन नेता हैं और प्रदर्शन, स्थानिक विश्लेषण, स्ट्रीमिंग अंतर्ग्रहण और माइग्रेशन रणनीतियों सहित अमेज़ॅन रेडशिफ्ट क्लाउड डेटा वेयरहाउस सेवा के कई कार्यात्मक क्षेत्रों का प्रबंधन करते हैं। उनके पास रिलेशनल डेटाबेस, मल्टी-डायमेंशनल डेटाबेस, IoT टेक्नोलॉजीज, स्टोरेज और कंप्यूट इंफ्रास्ट्रक्चर सेवाओं का अनुभव है और हाल ही में एआई/डीप लर्निंग, कंप्यूटर विज़न और रोबोटिक्स का उपयोग करके एक स्टार्टअप संस्थापक के रूप में भी काम किया है।
रवि अनिमी अमेज़ॅन रेडशिफ्ट टीम में एक वरिष्ठ उत्पाद प्रबंधन नेता हैं और प्रदर्शन, स्थानिक विश्लेषण, स्ट्रीमिंग अंतर्ग्रहण और माइग्रेशन रणनीतियों सहित अमेज़ॅन रेडशिफ्ट क्लाउड डेटा वेयरहाउस सेवा के कई कार्यात्मक क्षेत्रों का प्रबंधन करते हैं। उनके पास रिलेशनल डेटाबेस, मल्टी-डायमेंशनल डेटाबेस, IoT टेक्नोलॉजीज, स्टोरेज और कंप्यूट इंफ्रास्ट्रक्चर सेवाओं का अनुभव है और हाल ही में एआई/डीप लर्निंग, कंप्यूटर विज़न और रोबोटिक्स का उपयोग करके एक स्टार्टअप संस्थापक के रूप में भी काम किया है।
 आमेर शाह अमेज़न रेडशिफ्ट सर्विस टीम में एक वरिष्ठ इंजीनियर हैं।
आमेर शाह अमेज़न रेडशिफ्ट सर्विस टीम में एक वरिष्ठ इंजीनियर हैं।
 संकेत हसे अमेज़न रेडशिफ्ट सर्विस टीम में सॉफ्टवेयर डेवलपमेंट मैनेजर हैं।
संकेत हसे अमेज़न रेडशिफ्ट सर्विस टीम में सॉफ्टवेयर डेवलपमेंट मैनेजर हैं।
 ऑरेस्टिस पॉलीक्रोनिउ अमेज़न रेडशिफ्ट सर्विस टीम में प्रिंसिपल इंजीनियर हैं।
ऑरेस्टिस पॉलीक्रोनिउ अमेज़न रेडशिफ्ट सर्विस टीम में प्रिंसिपल इंजीनियर हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 10
- 100
- 16
- 32
- 7
- 9
- a
- योग्य
- About
- तेज करता
- पहुँच
- पहुँचा
- प्राप्त
- के पार
- जोड़ा
- जोड़ने
- इसके अलावा
- अतिरिक्त
- उन्नत
- लाभ
- समर्थ बनाया
- के खिलाफ
- एल्गोरिदम
- सब
- की अनुमति देता है
- भी
- वैकल्पिक
- विकल्प
- हालांकि
- हमेशा
- वीरांगना
- अमेज़ॅन वेब सेवा
- राशि
- an
- विश्लेषण
- विश्लेषिकी
- का विश्लेषण
- और
- अन्य
- कोई
- अनुप्रयोगों
- लागू
- दृष्टिकोण
- हैं
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- चारों ओर
- AS
- पहलू
- जुड़े
- At
- ध्यान
- स्वत:
- स्वचालित
- स्वचालित
- स्वतः
- उपलब्ध
- औसत
- एडब्ल्यूएस
- b
- बैंडविड्थ
- आधारित
- BE
- क्योंकि
- से पहले
- शुरू करना
- जा रहा है
- बेंचमार्क
- मानक
- लाभ
- BEST
- बेहतर
- के बीच
- परे
- अरबों
- के छात्रों
- बाधाओं
- मुक्केबाज़ी
- लाना
- विस्तृत
- व्यापार
- व्यापारिक सूचना
- व्यस्त
- लेकिन
- by
- केक
- परिकलित
- हिसाब
- कॉल
- कर सकते हैं
- क्षमताओं
- मामला
- मामलों
- विशेषताएँ
- विशेषता
- चार्ट
- चटकना
- चुना
- City
- बादल
- समूह
- स्तंभ
- स्तंभ
- संयोजन
- प्रतिबद्ध
- सामान्य
- तुलनीय
- तुलना
- तुलना
- की तुलना
- प्रतियोगी
- प्रतियोगियों
- जटिल
- पालन करना
- गणना करना
- कंप्यूटर
- Computer Vision
- संकल्पना
- समवर्ती
- शर्त
- संचालित
- संगत
- कंसोल
- स्थिर
- निरंतर
- का गठन
- परामर्श
- शामिल
- लगातार
- जारी रखने के
- जारी
- निरंतर
- लगातार
- खाना पकाने
- इसी
- लागत
- लागत
- युग्मित
- बनाना
- महत्वपूर्ण
- ग्राहक
- ग्राहक
- डैशबोर्ड
- डैशबोर्ड
- तिथि
- डेटा विश्लेषण
- डेटा विश्लेषण
- डेटा संसाधन
- डेटा सेट
- डाटा गोदाम
- डेटा वेयरहाउस
- डेटा पर ही आधारित
- डाटाबेस
- डेटाबेस
- डेटासेट
- तारीख
- निर्णय
- चूक
- परिभाषित
- उद्धार
- पहुंचाने
- बचाता है
- निकाली गई
- वर्णित
- बनाया गया
- वांछित
- विस्तार
- विस्तृत
- विकास
- के घटनाक्रम
- विभिन्न
- सीधे
- चर्चा करना
- चर्चा की
- विविधता
- विभाजित
- do
- कर देता है
- नहीं करता है
- dont
- संचालित
- से प्रत्येक
- पूर्व
- आसानी
- खाने
- प्रभावी
- कुशल
- कुशलता
- सक्षम
- समर्थकारी
- प्रोत्साहित करना
- इंजन
- इंजीनियर
- वर्धित
- वृद्धि
- संवर्द्धन
- दर्ज
- बराबर
- विशेष रूप से
- ईथर (ईटीएच)
- मूल्यांकन
- और भी
- सब कुछ
- उदाहरण
- उदाहरण
- उम्मीद
- अनुभव
- उद्धरण
- कारक
- परिचित
- दूर
- फास्ट
- और तेज
- Feature
- कुछ
- अंत में
- खोज
- खत्म
- प्रथम
- बेड़ा
- फोकस
- का पालन करें
- निम्नलिखित
- के लिए
- पाया
- संस्थापक
- से
- कार्यात्मक
- आगे
- सामान्य उद्देश्य
- उत्पन्न
- पीढ़ी
- मिल
- मिल रहा
- GitHub
- देता है
- जा
- अच्छा
- बढ़ रहा है
- उगता है
- संभालना
- हार्डवेयर
- है
- होने
- he
- हाई
- उच्चतर
- उसके
- पकड़
- पकड़े
- घंटा
- घंटे
- कैसे
- एचटीएमएल
- http
- HTTPS
- सौ
- सैकड़ों
- आदर्श
- आदर्श
- पहचान करना
- if
- समझाना
- कल्पना करना
- प्रभाव
- महत्वपूर्ण
- महत्वपूर्ण पहलू
- में सुधार
- उन्नत
- सुधार
- सुधार
- में सुधार लाने
- in
- शामिल
- शामिल
- सहित
- बढ़ना
- वृद्धि हुई
- बढ़ जाती है
- इंगित करता है
- उद्योग का
- इंफ्रास्ट्रक्चर
- उदाहरण
- उदाहरणों
- एकीकरण
- बुद्धि
- इंटरैक्टिव
- आंतरिक
- हस्तक्षेप
- में
- शुरू की
- शुरू करने
- निवेश
- शामिल
- IOT
- IT
- आईटी इस
- में शामिल होने
- जेपीजी
- केवल
- रखना
- किट
- ज्ञान
- बड़ा
- बड़ा
- बाद में
- ताज़ा
- नवीनतम घटनाक्रम
- शुभारंभ
- शुरू करने
- नेता
- प्रमुख
- सीख रहा हूँ
- कम से कम
- कम
- स्तर
- हल्के
- पसंद
- थोड़ा
- भार
- लोड हो रहा है
- भार
- स्थित
- लंबा
- लंबे समय तक
- देखिए
- देख
- निम्न
- कम
- सबसे कम
- बनाए रखना
- को बनाए रखने
- रखरखाव
- बहुमत
- बनाना
- कामयाब
- प्रबंध
- प्रबंधक
- प्रबंधन करता है
- गाइड
- बहुत
- मैच
- मैटर्स
- मई..
- अर्थ
- साधन
- माप
- मापा
- मापने
- मध्यम
- मिलना
- याद
- उल्लेख किया
- हो सकता है
- प्रवास
- मिनट
- आधुनिक
- सोमवार
- धन
- अधिक
- और भी
- अधिकांश
- बहुत
- यानी
- आवश्यकता
- जरूरत
- की जरूरत है
- नया
- न्यूयॉर्क
- न्यू यॉर्क शहर
- नए नए
- अगला
- नहीं
- नोट
- विख्यात
- ध्यान देने योग्य बात
- अभी
- संख्या
- of
- सरकारी
- अक्सर
- on
- ऑन डिमांड
- ONE
- केवल
- संचालित
- संचालित
- अवसर
- इष्टतम
- इष्टतमीकरण
- के अनुकूलन के
- विकल्प
- ऑप्शंस
- or
- अन्य
- हमारी
- आउट
- के ऊपर
- अपना
- पैरामीटर
- विशेष
- पैटर्न
- पैटर्न उपयोग करें
- वेतन
- भुगतान
- प्रति
- प्रतिशतता
- प्रदर्शन
- की योजना बना
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- खेल
- बिन्दु
- लोकप्रिय
- संभव
- पद
- बिजली
- उम्मीद के मुताबिक
- प्रस्तुत
- रोकता है
- मूल्य
- कीमत निर्धारण
- प्रिंसिपल
- संसाधित
- प्रसंस्करण
- एस्ट्रो मॉल
- उत्पाद प्रबंधन
- प्रमाण
- अवधारणा के सुबूत
- प्रदान करना
- सार्वजनिक रूप से
- प्रकाशित
- खरीदा
- प्रश्नों
- जल्दी से
- बिना सोचे समझे
- पढ़ना
- असली दुनिया
- वास्तविक समय
- प्राप्त करना
- हाल
- हाल ही में
- सिफारिशें
- संदर्भ
- क्षेत्रों
- अस्वीकृत..
- सापेक्ष
- अपेक्षाकृत
- हटाने
- दोहराया गया
- बार - बार आने वाला
- दोहराया
- रिपोर्ट
- प्रतिनिधि
- का प्रतिनिधित्व
- की आवश्यकता होती है
- आरक्षित
- प्रतिक्रिया
- जिम्मेदार
- जिसके परिणामस्वरूप
- परिणाम
- खुदरा
- वापसी
- राजस्व
- की समीक्षा
- सही
- रोबोटिक्स
- आरओआई
- रन
- दौड़ना
- चलाता है
- विक्रय
- वही
- सहेजें
- देखा
- अनुमापकता
- स्केल
- तराजू
- स्केलिंग
- स्कैन
- योजना
- लिपियों
- दूसरा
- सेकंड
- अनुभाग
- देखना
- बीज
- वरिष्ठ
- सेवा
- serverless
- सेवा
- सेवाएँ
- सेट
- व्यवस्था
- कई
- Share
- कम
- चाहिए
- दिखाना
- दिखाया
- महत्वपूर्ण
- काफी
- उसी प्रकार
- सरल
- एक साथ
- एक
- आकार
- आकार
- छोटा
- So
- सॉफ्टवेयर
- सॉफ्टवेयर विकास
- स्थानिक
- विनिर्देश
- विनिर्दिष्ट
- गति
- बिताना
- खर्च
- कील
- एसक्यूएल
- प्रारंभ
- शुरू
- स्टार्टअप
- रहना
- तेजी
- कदम
- भंडारण
- भंडार
- सरल
- रणनीतियों
- धारा
- स्ट्रीमिंग
- तार
- प्रस्तुत
- ऐसा
- उपयुक्तता
- समर्थन
- सहायक
- प्रणाली
- तालिका
- लेना
- लिया
- टीम
- तकनीक
- टेक्नोलॉजीज
- कहना
- है
- परीक्षण
- परीक्षण
- से
- कि
- RSI
- लेकिन हाल ही
- फिर
- वहाँ।
- इसलिये
- इन
- वे
- सोचना
- इसका
- उन
- हजारों
- तीन
- THROUGHPUT
- पहर
- बार
- सेवा मेरे
- आज
- कुल
- यातायात
- बदालना
- पारदर्शी रूप से
- कोशिश
- की कोशिश कर रहा
- दो बार
- दो
- टाइप
- प्रकार
- ठेठ
- देशव्यापी
- असमर्थ
- असामान्य
- समझना
- अद्वितीय
- अप्रत्याशित
- जब तक
- us
- प्रयोग
- यूएसडी
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग करता है
- का उपयोग
- मान
- विविधता
- विभिन्न
- बहुत
- विचारों
- वास्तव में
- दृष्टि
- प्रतीक्षा
- करना चाहते हैं
- गोदाम
- था
- मार्ग..
- तरीके
- we
- वेब
- वेब सेवाओं
- सप्ताह
- कुंआ
- थे
- क्या
- कब
- जहाँ तक
- कौन कौन से
- जब
- क्यों
- चौड़ा
- मर्जी
- साथ में
- अंदर
- बिना
- लायक
- होगा
- लिख रहे हैं
- लिखा था
- यॉर्क
- इसलिए आप
- आपका
- जेफिरनेट