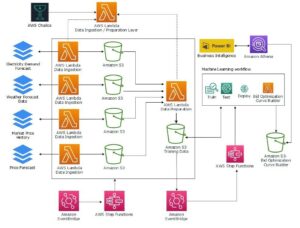
एंबेडिंग प्राकृतिक भाषा प्रसंस्करण (एनएलपी) और मशीन लर्निंग (एमएल) में महत्वपूर्ण भूमिका निभाती है। पाठ एम्बेडिंग पाठ को संख्यात्मक अभ्यावेदन में बदलने की प्रक्रिया को संदर्भित करता है जो उच्च-आयामी वेक्टर स्थान में रहता है। यह तकनीक एमएल एल्गोरिदम के उपयोग के माध्यम से प्राप्त की जाती है जो डेटा (शब्दार्थ संबंध) के अर्थ और संदर्भ को समझने और डेटा (वाक्यविन्यास संबंध) के भीतर जटिल संबंधों और पैटर्न को सीखने में सक्षम बनाती है। आप परिणामी वेक्टर अभ्यावेदन का उपयोग अनुप्रयोगों की एक विस्तृत श्रृंखला के लिए कर सकते हैं, जैसे सूचना पुनर्प्राप्ति, पाठ वर्गीकरण, प्राकृतिक भाषा प्रसंस्करण, और कई अन्य।
अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग एक टेक्स्ट एम्बेडिंग मॉडल है जो प्राकृतिक भाषा के टेक्स्ट - जिसमें एकल शब्द, वाक्यांश या यहां तक कि बड़े दस्तावेज़ शामिल हैं - को संख्यात्मक अभ्यावेदन में परिवर्तित करता है, जिसका उपयोग सिमेंटिक समानता के आधार पर खोज, वैयक्तिकरण और क्लस्टरिंग जैसे मामलों को सशक्त बनाने के लिए किया जा सकता है।
इस पोस्ट में, हम अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग मॉडल, इसकी विशेषताओं और उदाहरण उपयोग मामलों पर चर्चा करते हैं।
कुछ प्रमुख अवधारणाओं में शामिल हैं:
- पाठ (वेक्टर) का संख्यात्मक प्रतिनिधित्व शब्दों के बीच शब्दार्थ और संबंधों को दर्शाता है
- टेक्स्ट समानता की तुलना करने के लिए रिच एम्बेडिंग का उपयोग किया जा सकता है
- बहुभाषी पाठ एम्बेडिंग विभिन्न भाषाओं में अर्थ की पहचान कर सकती है
टेक्स्ट के एक टुकड़े को वेक्टर में कैसे परिवर्तित किया जाता है?
किसी वाक्य को वेक्टर में बदलने की कई तकनीकें हैं। एक लोकप्रिय तरीका Word2Vec, GloVe, या FastText जैसे शब्द एम्बेडिंग एल्गोरिदम का उपयोग करना है, और फिर वाक्य-स्तरीय वेक्टर प्रतिनिधित्व बनाने के लिए शब्द एम्बेडिंग को एकत्रित करना है।
एक अन्य सामान्य दृष्टिकोण बीईआरटी या जीपीटी जैसे बड़े भाषा मॉडल (एलएलएम) का उपयोग करना है, जो संपूर्ण वाक्यों के लिए प्रासंगिक एम्बेडिंग प्रदान कर सकता है। ये मॉडल ट्रांसफॉर्मर जैसे गहन शिक्षण आर्किटेक्चर पर आधारित हैं, जो एक वाक्य में शब्दों के बीच प्रासंगिक जानकारी और संबंधों को अधिक प्रभावी ढंग से पकड़ सकते हैं।
हमें एम्बेडिंग मॉडल की आवश्यकता क्यों है?
वेक्टर एम्बेडिंग एलएलएम के लिए भाषा की शब्दार्थ डिग्री को समझने के लिए मौलिक है, और एलएलएम को भावना विश्लेषण, नामित इकाई पहचान और पाठ वर्गीकरण जैसे डाउनस्ट्रीम एनएलपी कार्यों पर अच्छा प्रदर्शन करने में भी सक्षम बनाता है।
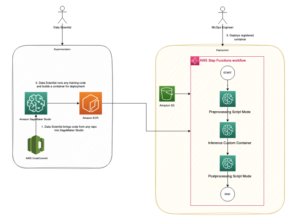
सिमेंटिक खोज के अलावा, आप रिट्रीवल ऑगमेंटेड जेनरेशन (आरएजी) के माध्यम से अधिक सटीक परिणामों के लिए अपने संकेतों को बढ़ाने के लिए एम्बेडिंग का उपयोग कर सकते हैं - लेकिन उनका उपयोग करने के लिए, आपको उन्हें वेक्टर क्षमताओं वाले डेटाबेस में संग्रहीत करने की आवश्यकता होगी।
अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग मॉडल को आरएजी उपयोग मामलों को सक्षम करने के लिए टेक्स्ट पुनर्प्राप्ति के लिए अनुकूलित किया गया है। यह आपको पहले अपने टेक्स्ट डेटा को संख्यात्मक अभ्यावेदन या वैक्टर में परिवर्तित करने में सक्षम बनाता है, और फिर वेक्टर डेटाबेस से प्रासंगिक अंशों की सटीक खोज करने के लिए उन वैक्टरों का उपयोग करता है, जिससे आप अन्य फाउंडेशन मॉडल के साथ संयोजन में अपने मालिकाना डेटा का अधिकतम लाभ उठा सकते हैं।
क्योंकि Amazon टाइटन टेक्स्ट एंबेडिंग एक प्रबंधित मॉडल है अमेज़ॅन बेडरॉक, यह पूरी तरह से सर्वर रहित अनुभव के रूप में पेश किया गया है। आप इसे अमेज़ॅन बेडरॉक रेस्ट के माध्यम से उपयोग कर सकते हैं API या AWS SDK. आवश्यक पैरामीटर वह टेक्स्ट हैं जिसकी एंबेडिंग्स आप उत्पन्न करना चाहते हैं modelID पैरामीटर, जो अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग मॉडल के नाम का प्रतिनिधित्व करता है। निम्नलिखित कोड Python (Boto3) के लिए AWS SDK का उपयोग करने वाला एक उदाहरण है:
आउटपुट कुछ इस प्रकार दिखेगा:
का संदर्भ लें अमेज़ॅन बेडरॉक boto3 सेटअप आवश्यक पैकेजों को स्थापित करने के तरीके के बारे में अधिक जानकारी के लिए, अमेज़ॅन बेडरॉक से कनेक्ट करें और मॉडलों को आमंत्रित करें।
अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग की विशेषताएं
अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग के साथ, आप 8,000 टोकन तक इनपुट कर सकते हैं, जिससे यह आपके उपयोग के मामले के आधार पर एकल शब्दों, वाक्यांशों या संपूर्ण दस्तावेज़ों के साथ काम करने के लिए उपयुक्त हो जाता है। अमेज़ॅन टाइटन आयाम 1536 के आउटपुट वैक्टर लौटाता है, जो इसे उच्च स्तर की सटीकता देता है, साथ ही कम-विलंबता, लागत प्रभावी परिणामों के लिए अनुकूलन भी करता है।
अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग 25 से अधिक विभिन्न भाषाओं में टेक्स्ट के लिए एंबेडिंग बनाने और क्वेरी करने का समर्थन करता है। इसका मतलब है कि आप जिस भाषा का समर्थन करना चाहते हैं उसके लिए अलग-अलग मॉडल बनाने और बनाए रखने की आवश्यकता के बिना मॉडल को अपने उपयोग के मामलों में लागू कर सकते हैं।
एक ही एम्बेडिंग मॉडल को कई भाषाओं में प्रशिक्षित करने से निम्नलिखित प्रमुख लाभ मिलते हैं:
- व्यापक पहुंच - 25 से अधिक भाषाओं का समर्थन करके, आप कई अंतरराष्ट्रीय बाजारों में उपयोगकर्ताओं और सामग्री तक अपने एप्लिकेशन की पहुंच का विस्तार कर सकते हैं।
- लगातार प्रदर्शन - कई भाषाओं को कवर करने वाले एकीकृत मॉडल के साथ, आपको प्रति भाषा अलग-अलग अनुकूलन के बजाय सभी भाषाओं में लगातार परिणाम मिलते हैं। मॉडल को समग्र रूप से प्रशिक्षित किया गया है ताकि आपको सभी भाषाओं में लाभ मिल सके।
- बहुभाषी क्वेरी समर्थन - अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग किसी भी समर्थित भाषा में टेक्स्ट एंबेडिंग को क्वेरी करने की अनुमति देता है। यह किसी एक भाषा तक सीमित हुए बिना विभिन्न भाषाओं में शब्दार्थ रूप से समान सामग्री को पुनः प्राप्त करने की लचीलापन प्रदान करता है। आप ऐसे एप्लिकेशन बना सकते हैं जो समान एकीकृत एम्बेडिंग स्पेस का उपयोग करके बहुभाषी डेटा की क्वेरी और विश्लेषण करते हैं।
इस लेखन के समय, निम्नलिखित भाषाएँ समर्थित हैं:
- अरबी भाषा
- सरलीकृत चीनी)
- चीनी पारंपरिक)
- चेक
- डच
- अंग्रेज़ी
- फ्रेंच
- जर्मन
- यहूदी
- हिंदी
- इतालवी
- जापानी
- कन्नड़
- कोरियाई
- मलयालम
- मराठी
- पोलिश
- पुर्तगाली
- रूसी
- स्पेनिश
- स्वीडिश
- फिलिपिनो तागालोग
- तामिल
- तेलुगु
- तुर्की
लैंगचेन के साथ अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग का उपयोग करना
लैंगचैन जेनेरिक एआई मॉडल और सहायक प्रौद्योगिकियों के साथ काम करने के लिए एक लोकप्रिय ओपन सोर्स फ्रेमवर्क है। इसमें शामिल है ए बेडरॉकएंबेडिंग क्लाइंट जो आसानी से Boto3 SDK को एक अमूर्त परत के साथ लपेटता है। BedrockEmbeddings क्लाइंट आपको JSON अनुरोध या प्रतिक्रिया संरचनाओं के विवरण को जाने बिना, सीधे टेक्स्ट और एम्बेडिंग के साथ काम करने की अनुमति देता है। निम्नलिखित एक सरल उदाहरण है:
आप लैंगचेन का भी उपयोग कर सकते हैं BedrockEmbeddings आरएजी, सिमेंटिक सर्च और अन्य एम्बेडिंग-संबंधित पैटर्न को लागू करने को सरल बनाने के लिए अमेज़ॅन बेडरॉक एलएलएम क्लाइंट के साथ क्लाइंट।
एम्बेडिंग के लिए केस का उपयोग करें
हालाँकि आरएजी वर्तमान में एम्बेडिंग के साथ काम करने के लिए सबसे लोकप्रिय उपयोग का मामला है, ऐसे कई अन्य उपयोग के मामले हैं जहां एम्बेडिंग लागू की जा सकती है। निम्नलिखित कुछ अतिरिक्त परिदृश्य हैं जहां आप विशिष्ट समस्याओं को हल करने के लिए एम्बेडिंग का उपयोग कर सकते हैं, या तो स्वयं या एलएलएम के सहयोग से:
- प्रश्न और उत्तर - एंबेडिंग आरएजी पैटर्न के माध्यम से प्रश्न और उत्तर इंटरफेस का समर्थन करने में मदद कर सकती है। वेक्टर डेटाबेस के साथ जोड़ी गई एंबेडिंग पीढ़ी आपको ज्ञान भंडार में प्रश्नों और सामग्री के बीच करीबी मिलान खोजने की अनुमति देती है।
- व्यक्तिगत सिफारिशें - प्रश्न और उत्तर के समान, आप उपयोगकर्ता द्वारा प्रदान किए गए मानदंडों के आधार पर अवकाश स्थलों, कॉलेजों, वाहनों या अन्य उत्पादों को खोजने के लिए एम्बेडिंग का उपयोग कर सकते हैं। यह मिलानों की एक सरल सूची का रूप ले सकता है, या फिर आप प्रत्येक अनुशंसा को संसाधित करने और यह समझाने के लिए एलएलएम का उपयोग कर सकते हैं कि यह उपयोगकर्ता के मानदंडों को कैसे पूरा करता है। आप इस दृष्टिकोण का उपयोग किसी उपयोगकर्ता के लिए उनकी विशिष्ट आवश्यकताओं के आधार पर कस्टम "10 सर्वश्रेष्ठ" लेख तैयार करने के लिए भी कर सकते हैं।
- डाटा प्रबंधन - जब आपके पास डेटा स्रोत होते हैं जो एक-दूसरे से स्पष्ट रूप से मैप नहीं होते हैं, लेकिन आपके पास टेक्स्ट सामग्री होती है जो डेटा रिकॉर्ड का वर्णन करती है, तो आप संभावित डुप्लिकेट रिकॉर्ड की पहचान करने के लिए एम्बेडिंग का उपयोग कर सकते हैं। उदाहरण के लिए, आप डुप्लिकेट उम्मीदवारों की पहचान करने के लिए एम्बेडिंग का उपयोग कर सकते हैं जो अलग-अलग फ़ॉर्मेटिंग, संक्षिप्ताक्षरों का उपयोग कर सकते हैं, या यहां तक कि अनुवादित नामों का भी उपयोग कर सकते हैं।
- अनुप्रयोग पोर्टफोलियो युक्तिकरण - जब किसी मूल कंपनी और अधिग्रहण में एप्लिकेशन पोर्टफ़ोलियो को संरेखित करना चाहते हैं, तो यह हमेशा स्पष्ट नहीं होता है कि संभावित ओवरलैप कहां से शुरू करें। कॉन्फ़िगरेशन प्रबंधन डेटा की गुणवत्ता एक सीमित कारक हो सकती है, और एप्लिकेशन परिदृश्य को समझने के लिए टीमों के बीच समन्वय करना कठिन हो सकता है। एम्बेडिंग के साथ सिमेंटिक मिलान का उपयोग करके, हम युक्तिकरण के लिए उच्च-संभावित उम्मीदवार अनुप्रयोगों की पहचान करने के लिए एप्लिकेशन पोर्टफोलियो में त्वरित विश्लेषण कर सकते हैं।
- सामग्री समूहन - आप समान सामग्री को उन श्रेणियों में समूहित करने में सहायता के लिए एम्बेडिंग का उपयोग कर सकते हैं जिन्हें आप समय से पहले नहीं जानते होंगे। उदाहरण के लिए, मान लें कि आपके पास ग्राहक ईमेल या ऑनलाइन उत्पाद समीक्षाओं का संग्रह है। आप प्रत्येक आइटम के लिए एम्बेडिंग बना सकते हैं, फिर उन एम्बेडिंग को चला सकते हैं k- साधन क्लस्टरिंग ग्राहकों की चिंताओं, उत्पाद की प्रशंसा या शिकायतों या अन्य विषयों के तार्किक समूहों की पहचान करना। फिर आप एलएलएम का उपयोग करके उन समूहों की सामग्री से केंद्रित सारांश तैयार कर सकते हैं।
सिमेंटिक खोज उदाहरण
हमारे में GitHub पर उदाहरण, हम अमेज़ॅन टाइटन टेक्स्ट एंबेडिंग, लैंगचेन और स्ट्रीमलिट के साथ एक सरल एंबेडिंग खोज एप्लिकेशन प्रदर्शित करते हैं।
उदाहरण उपयोगकर्ता की क्वेरी को इन-मेमोरी वेक्टर डेटाबेस में निकटतम प्रविष्टियों से मेल खाता है। फिर हम उन मिलानों को सीधे उपयोगकर्ता इंटरफ़ेस में प्रदर्शित करते हैं। यदि आप किसी RAG एप्लिकेशन का समस्या निवारण करना चाहते हैं, या किसी एम्बेडिंग मॉडल का सीधे मूल्यांकन करना चाहते हैं तो यह उपयोगी हो सकता है।
सरलता के लिए, हम इन-मेमोरी का उपयोग करते हैं FAISS एम्बेडिंग वैक्टर को संग्रहीत करने और खोजने के लिए डेटाबेस। बड़े पैमाने पर वास्तविक दुनिया के परिदृश्य में, आप संभवतः एक सतत डेटा स्टोर का उपयोग करना चाहेंगे अमेज़ॅन ओपनसर्च सर्वरलेस के लिए वेक्टर इंजन या पीजीवेक्टर PostgreSQL के लिए एक्सटेंशन।
वेब एप्लिकेशन से विभिन्न भाषाओं में कुछ संकेत आज़माएँ, जैसे कि निम्नलिखित:
- मैं अपने उपयोग की निगरानी कैसे कर सकता हूं?
- मैं मॉडलों को कैसे अनुकूलित कर सकता हूँ?
- मैं कौन सी प्रोग्रामिंग भाषाओं का उपयोग कर सकता हूं?
- मेरे सुरक्षा कारणों पर टिप्पणी करें?
- मैं आपको यह बताना चाहता हूं कि यह कैसे काम करता है?
- बेडरॉक के लिए डिज़ाइन किए गए मॉडल की क्या आवश्यकता है?
- वेल्चेन क्षेत्र में क्या अमेज़ॅन बेडरॉक उपलब्ध है?
- 有哪些级别的支持?
ध्यान दें कि भले ही स्रोत सामग्री अंग्रेजी में थी, अन्य भाषाओं की क्वेरीज़ प्रासंगिक प्रविष्टियों से मेल खाती थीं।
निष्कर्ष
फाउंडेशन मॉडल की पाठ निर्माण क्षमताएं बहुत रोमांचक हैं, लेकिन यह याद रखना महत्वपूर्ण है कि पाठ को समझना, ज्ञान के एक समूह से प्रासंगिक सामग्री ढूंढना और अनुच्छेदों के बीच संबंध बनाना जेनरेटर एआई के पूर्ण मूल्य को प्राप्त करने के लिए महत्वपूर्ण है। हम अगले वर्षों में एम्बेडिंग के लिए नए और दिलचस्प उपयोग के मामले देखना जारी रखेंगे क्योंकि इन मॉडलों में सुधार जारी रहेगा।
अगले चरण
आप निम्नलिखित कार्यशालाओं में नोटबुक या डेमो एप्लिकेशन के रूप में एम्बेडिंग के अतिरिक्त उदाहरण पा सकते हैं:
लेखक के बारे में
 जेसन स्टेहले न्यू इंग्लैंड क्षेत्र में स्थित AWS में एक वरिष्ठ समाधान वास्तुकार हैं। वह ग्राहकों के साथ उनकी सबसे बड़ी व्यावसायिक चुनौतियों के साथ AWS क्षमताओं को संरेखित करने के लिए काम करता है। काम के अलावा, वह अपना समय चीज़ें बनाने और अपने परिवार के साथ कॉमिक बुक फिल्में देखने में बिताता है।
जेसन स्टेहले न्यू इंग्लैंड क्षेत्र में स्थित AWS में एक वरिष्ठ समाधान वास्तुकार हैं। वह ग्राहकों के साथ उनकी सबसे बड़ी व्यावसायिक चुनौतियों के साथ AWS क्षमताओं को संरेखित करने के लिए काम करता है। काम के अलावा, वह अपना समय चीज़ें बनाने और अपने परिवार के साथ कॉमिक बुक फिल्में देखने में बिताता है।
 नितिन यूसेबियस AWS में एक सीनियर एंटरप्राइज सॉल्यूशंस आर्किटेक्ट हैं, जो सॉफ्टवेयर इंजीनियरिंग, एंटरप्राइज आर्किटेक्चर और AI/ML में अनुभवी हैं। उन्हें जेनरेटिव एआई की संभावनाएं तलाशने का गहरा शौक है। वह AWS प्लेटफ़ॉर्म पर अच्छी तरह से डिज़ाइन किए गए एप्लिकेशन बनाने में मदद करने के लिए ग्राहकों के साथ सहयोग करता है, और प्रौद्योगिकी चुनौतियों को हल करने और उनकी क्लाउड यात्रा में सहायता करने के लिए समर्पित है।
नितिन यूसेबियस AWS में एक सीनियर एंटरप्राइज सॉल्यूशंस आर्किटेक्ट हैं, जो सॉफ्टवेयर इंजीनियरिंग, एंटरप्राइज आर्किटेक्चर और AI/ML में अनुभवी हैं। उन्हें जेनरेटिव एआई की संभावनाएं तलाशने का गहरा शौक है। वह AWS प्लेटफ़ॉर्म पर अच्छी तरह से डिज़ाइन किए गए एप्लिकेशन बनाने में मदद करने के लिए ग्राहकों के साथ सहयोग करता है, और प्रौद्योगिकी चुनौतियों को हल करने और उनकी क्लाउड यात्रा में सहायता करने के लिए समर्पित है।
 राज पाठक कनाडा और संयुक्त राज्य अमेरिका में बड़ी फॉर्च्यून 50 कंपनियों और मध्यम आकार के वित्तीय सेवा संस्थानों (एफएसआई) के प्रमुख समाधान वास्तुकार और तकनीकी सलाहकार हैं। वह जेनरेटिव एआई, प्राकृतिक भाषा प्रसंस्करण, बुद्धिमान दस्तावेज़ प्रसंस्करण और एमएलओपीएस जैसे मशीन सीखने के अनुप्रयोगों में माहिर हैं।
राज पाठक कनाडा और संयुक्त राज्य अमेरिका में बड़ी फॉर्च्यून 50 कंपनियों और मध्यम आकार के वित्तीय सेवा संस्थानों (एफएसआई) के प्रमुख समाधान वास्तुकार और तकनीकी सलाहकार हैं। वह जेनरेटिव एआई, प्राकृतिक भाषा प्रसंस्करण, बुद्धिमान दस्तावेज़ प्रसंस्करण और एमएलओपीएस जैसे मशीन सीखने के अनुप्रयोगों में माहिर हैं।
 मणि खानूजा एक टेक लीड - जेनेरेटिव एआई स्पेशलिस्ट, पुस्तक की लेखिका - एप्लाइड मशीन लर्निंग एंड हाई परफॉर्मेंस कंप्यूटिंग ऑन एडब्ल्यूएस, और मैन्युफैक्चरिंग एजुकेशन फाउंडेशन बोर्ड में महिलाओं के लिए निदेशक मंडल की सदस्य हैं। वह कंप्यूटर विज़न, प्राकृतिक भाषा प्रसंस्करण और जेनरेटिव एआई जैसे विभिन्न डोमेन में मशीन लर्निंग (एमएल) परियोजनाओं का नेतृत्व करती हैं। वह ग्राहकों को बड़े पैमाने पर मशीन लर्निंग मॉडल बनाने, प्रशिक्षित करने और तैनात करने में मदद करती है। वह आंतरिक और बाहरी सम्मेलनों जैसे री:इन्वेंट, वीमेन इन मैन्युफैक्चरिंग वेस्ट, यूट्यूब वेबिनार और जीएचसी 23 में बोलती हैं। अपने खाली समय में, वह समुद्र तट के किनारे लंबी सैर करना पसंद करती हैं।
मणि खानूजा एक टेक लीड - जेनेरेटिव एआई स्पेशलिस्ट, पुस्तक की लेखिका - एप्लाइड मशीन लर्निंग एंड हाई परफॉर्मेंस कंप्यूटिंग ऑन एडब्ल्यूएस, और मैन्युफैक्चरिंग एजुकेशन फाउंडेशन बोर्ड में महिलाओं के लिए निदेशक मंडल की सदस्य हैं। वह कंप्यूटर विज़न, प्राकृतिक भाषा प्रसंस्करण और जेनरेटिव एआई जैसे विभिन्न डोमेन में मशीन लर्निंग (एमएल) परियोजनाओं का नेतृत्व करती हैं। वह ग्राहकों को बड़े पैमाने पर मशीन लर्निंग मॉडल बनाने, प्रशिक्षित करने और तैनात करने में मदद करती है। वह आंतरिक और बाहरी सम्मेलनों जैसे री:इन्वेंट, वीमेन इन मैन्युफैक्चरिंग वेस्ट, यूट्यूब वेबिनार और जीएचसी 23 में बोलती हैं। अपने खाली समय में, वह समुद्र तट के किनारे लंबी सैर करना पसंद करती हैं।
 मार्क रॉय AWS के लिए एक प्रमुख मशीन लर्निंग आर्किटेक्ट है, जो ग्राहकों को AI/ML समाधान डिजाइन करने और बनाने में मदद करता है। मार्क का काम एमएल उपयोग के मामलों की एक विस्तृत श्रृंखला को कवर करता है, जिसमें प्राथमिक रुचि कंप्यूटर विज़न, गहन शिक्षा और पूरे उद्यम में एमएल को स्केल करना है। उन्होंने बीमा, वित्तीय सेवाओं, मीडिया और मनोरंजन, स्वास्थ्य सेवा, उपयोगिताओं और विनिर्माण सहित कई उद्योगों में कंपनियों की मदद की है। मार्क के पास एमएल स्पेशलिटी सर्टिफिकेशन सहित छह एडब्ल्यूएस प्रमाणन हैं। AWS में शामिल होने से पहले, मार्क 25 वर्षों से अधिक समय तक एक वास्तुकार, डेवलपर और प्रौद्योगिकी नेता थे, जिसमें वित्तीय सेवाओं में 19 वर्ष भी शामिल थे।
मार्क रॉय AWS के लिए एक प्रमुख मशीन लर्निंग आर्किटेक्ट है, जो ग्राहकों को AI/ML समाधान डिजाइन करने और बनाने में मदद करता है। मार्क का काम एमएल उपयोग के मामलों की एक विस्तृत श्रृंखला को कवर करता है, जिसमें प्राथमिक रुचि कंप्यूटर विज़न, गहन शिक्षा और पूरे उद्यम में एमएल को स्केल करना है। उन्होंने बीमा, वित्तीय सेवाओं, मीडिया और मनोरंजन, स्वास्थ्य सेवा, उपयोगिताओं और विनिर्माण सहित कई उद्योगों में कंपनियों की मदद की है। मार्क के पास एमएल स्पेशलिटी सर्टिफिकेशन सहित छह एडब्ल्यूएस प्रमाणन हैं। AWS में शामिल होने से पहले, मार्क 25 वर्षों से अधिक समय तक एक वास्तुकार, डेवलपर और प्रौद्योगिकी नेता थे, जिसमें वित्तीय सेवाओं में 19 वर्ष भी शामिल थे।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- About
- मतिहीनता
- स्वीकार करें
- शुद्धता
- सही
- सही रूप में
- हासिल
- प्राप्त करने
- अर्जन
- के पार
- इसके अलावा
- अतिरिक्त
- लाभ
- सलाहकार
- आगे
- AI
- एआई मॉडल
- ऐ / एमएल
- एल्गोरिदम
- संरेखित करें
- सब
- अनुमति देना
- की अनुमति दे
- की अनुमति देता है
- साथ में
- साथ - साथ
- भी
- हमेशा
- वीरांगना
- अमेज़ॅन वेब सेवा
- an
- विश्लेषण
- विश्लेषण करें
- और
- जवाब
- कोई
- आवेदन
- अनुप्रयोगों
- लागू
- लागू करें
- दृष्टिकोण
- स्थापत्य
- आर्किटेक्चर
- हैं
- क्षेत्र
- लेख
- AS
- की सहायता
- At
- बढ़ाना
- संवर्धित
- लेखक
- उपलब्ध
- एडब्ल्यूएस
- आधारित
- BE
- समुद्र तट
- जा रहा है
- लाभ
- के बीच
- मंडल
- निदेशक मंडल
- परिवर्तन
- किताब
- मुक्केबाज़ी
- निर्माण
- इमारत
- व्यापार
- लेकिन
- by
- कर सकते हैं
- कनाडा
- उम्मीदवार
- उम्मीदवारों
- क्षमताओं
- कब्जा
- कब्जा
- मामला
- मामलों
- श्रेणियाँ
- प्रमाणीकरण
- प्रमाणपत्र
- चुनौतियों
- वर्गीकरण
- ग्राहक
- समापन
- बादल
- गुच्छन
- कोड
- संग्रह
- कॉलेजों
- संयोजन
- सामान्य
- कंपनियों
- कंपनी
- तुलना
- शिकायतों
- जटिल
- कंप्यूटर
- Computer Vision
- कंप्यूटिंग
- अवधारणाओं
- चिंताओं
- सम्मेलनों
- विन्यास
- जुडिये
- संबंध
- कनेक्शन
- संगत
- सामग्री
- प्रसंग
- प्रासंगिक
- जारी रखने के
- आसानी से
- बदलना
- परिवर्तित
- सहयोग
- समन्वय
- प्रभावी लागत
- सका
- कवर
- शामिल किया गया
- बनाना
- बनाना
- मापदंड
- महत्वपूर्ण
- वर्तमान में
- रिवाज
- ग्राहक
- ग्राहक
- अनुकूलित
- तिथि
- डाटाबेस
- de
- समर्पित
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- गहरा
- परिभाषित
- डिग्री
- डेमो
- दिखाना
- तैनात
- वर्णन करता है
- डिज़ाइन
- स्थलों
- विवरण
- डेवलपर
- विभिन्न
- मुश्किल
- आयाम
- सीधे
- निदेशकों
- चर्चा करना
- डिस्प्ले
- do
- दस्तावेज़
- दस्तावेजों
- डोमेन
- dont
- से प्रत्येक
- शिक्षा
- प्रभावी रूप से
- भी
- ईमेल
- embedding
- उभरना
- सक्षम
- सक्षम बनाता है
- इंजन
- अभियांत्रिकी
- इंगलैंड
- अंग्रेज़ी
- उद्यम
- उद्यम समाधान
- मनोरंजन
- संपूर्ण
- पूरी तरह से
- सत्ता
- ईथर (ईटीएच)
- मूल्यांकन करें
- और भी
- उदाहरण
- उदाहरण
- उत्तेजक
- विस्तार
- अनुभव
- अनुभवी
- समझाना
- तलाश
- विस्तार
- बाहरी
- की सुविधा
- कारक
- परिवार
- विशेषताएं
- कुछ
- वित्तीय
- वित्तीय सेवाओं
- खोज
- खोज
- प्रथम
- लचीलापन
- ध्यान केंद्रित
- निम्नलिखित
- के लिए
- प्रपत्र
- धन
- बुनियाद
- ढांचा
- मुक्त
- से
- पूर्ण
- मौलिक
- उत्पन्न
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- मिल
- मिल रहा
- देते
- दस्ताना
- Go
- अधिकतम
- था
- है
- he
- स्वास्थ्य सेवा
- मदद
- मदद की
- मदद
- मदद करता है
- उसे
- हाई
- उच्च प्रदर्शन कंप्यूटिंग
- उसके
- रखती है
- कैसे
- How To
- एचटीएमएल
- HTTPS
- i
- पहचान करना
- if
- कार्यान्वयन
- आयात
- महत्वपूर्ण
- में सुधार
- in
- अन्य में
- शामिल
- शामिल
- सहित
- उद्योगों
- करें-
- निवेश
- स्थापित
- बजाय
- संस्थानों
- बीमा
- बुद्धिमान
- बुद्धिमान दस्तावेज़ प्रसंस्करण
- ब्याज
- दिलचस्प
- इंटरफेस
- इंटरफेस
- आंतरिक
- अंतरराष्ट्रीय स्तर पर
- में
- IT
- आईटी इस
- शामिल होने
- यात्रा
- जेपीजी
- JSON
- कुंजी
- जानना
- ज्ञान
- ज्ञान
- परिदृश्य
- भाषा
- भाषाऐं
- बड़ा
- परत
- नेतृत्व
- नेता
- बिक्रीसूत्र
- सीख रहा हूँ
- चलो
- पसंद
- संभावित
- को यह पसंद है
- सीमित
- सूची
- एलएलएम
- तार्किक
- लंबा
- देखिए
- देख
- मशीन
- यंत्र अधिगम
- बनाए रखना
- बनाना
- निर्माण
- कामयाब
- प्रबंध
- विनिर्माण
- बहुत
- नक्शा
- निशान
- निशान
- Markets
- मिलान किया
- मैच
- मिलान
- सामग्री
- me
- अर्थ
- साधन
- मीडिया
- सदस्य
- तरीका
- हो सकता है
- ML
- एमएल एल्गोरिदम
- एमएलओपीएस
- आदर्श
- मॉडल
- मॉनिटर
- अधिक
- अधिकांश
- सबसे लोकप्रिय
- चलचित्र
- विभिन्न
- my
- नाम
- नामांकित
- नामों
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- आवश्यकता
- ज़रूरत
- की जरूरत है
- नया
- अगला
- NLP
- पुस्तिकाओं
- स्पष्ट
- of
- प्रस्तुत
- on
- ONE
- ऑनलाइन
- खुला
- खुला स्रोत
- अनुकूलित
- के अनुकूलन के
- or
- आदेश
- अन्य
- अन्य
- हमारी
- आउट
- उत्पादन
- बाहर
- के ऊपर
- अपना
- संकुल
- बनती
- प्राचल
- पैरामीटर
- मूल कंपनी
- मार्ग
- आवेशपूर्ण
- पैटर्न
- पैटर्न उपयोग करें
- प्रति
- निष्पादन
- प्रदर्शन
- निजीकरण
- मुहावरों
- टुकड़ा
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्ले
- कृप्या अ
- लोकप्रिय
- द्वारा
- संविभाग
- विभागों
- संभावनाओं
- पद
- PostgreSQL
- संभावित
- बिजली
- प्राथमिक
- प्रिंसिपल
- छाप
- पूर्व
- समस्याओं
- प्रक्रिया
- प्रसंस्करण
- एस्ट्रो मॉल
- उत्पाद समीक्षा
- उत्पाद
- प्रोग्रामिंग
- प्रोग्रामिंग की भाषाएँ
- परियोजनाओं
- संकेतों
- मालिकाना
- प्रदान करना
- बशर्ते
- प्रदान करता है
- अजगर
- गुणवत्ता
- प्रश्नों
- सवाल
- प्रश्न
- प्रशन
- त्वरित
- खपरैल
- रेंज
- RE
- पहुंच
- असली दुनिया
- मान्यता
- सिफारिश
- सिफारिशें
- रिकॉर्ड
- अभिलेख
- संदर्भित करता है
- रिश्ते
- प्रासंगिक
- याद
- कोष
- प्रतिनिधित्व
- का प्रतिनिधित्व करता है
- का अनुरोध
- अपेक्षित
- प्रतिक्रिया
- बाकी
- प्रतिबंधित
- जिसके परिणामस्वरूप
- परिणाम
- बहाली
- रिटर्न
- समीक्षा
- भूमिका
- रन
- चलाता है
- s
- वही
- कहना
- स्केल
- स्केलिंग
- परिदृश्य
- परिदृश्यों
- एसडीके
- Search
- देखना
- अर्थ
- अर्थ विज्ञान
- वरिष्ठ
- वाक्य
- भावुकता
- अलग
- serverless
- सेवाएँ
- वह
- समान
- सरल
- सादगी
- सरलीकृत
- को आसान बनाने में
- एक
- छह
- So
- सॉफ्टवेयर
- सॉफ्टवेयर इंजीनियरिंग
- समाधान ढूंढे
- हल
- सुलझाने
- कुछ
- कुछ
- स्रोत
- सूत्रों का कहना है
- अंतरिक्ष
- बोलता हे
- विशेषज्ञों
- माहिर
- विशेषता
- विशिष्ट
- प्रारंभ
- शुरू
- राज्य
- की दुकान
- संरचनाओं
- ऐसा
- समर्थन
- समर्थित
- सहायक
- समर्थन करता है
- लेना
- कार्य
- टीमों
- तकनीक
- तकनीकी
- तकनीक
- तकनीक
- टेक्नोलॉजीज
- टेक्नोलॉजी
- कहना
- टेक्स्ट
- पाठ वर्गीकरण
- पाठ पीढ़ी
- कि
- RSI
- स्रोत
- लेकिन हाल ही
- उन
- विषयों
- फिर
- वहाँ।
- इन
- चीज़ें
- इसका
- उन
- हालांकि?
- यहाँ
- पहर
- टाइटन
- सेवा मेरे
- टोकन
- परंपरागत
- रेलगाड़ी
- प्रशिक्षित
- ट्रान्सफ़ॉर्मर
- बदलने
- समझना
- समझ
- एकीकृत
- यूनाइटेड
- संयुक्त राज्य अमेरिका
- प्रयोग
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगी
- उपयोगकर्ता
- यूजर इंटरफेस
- उपयोगकर्ताओं
- का उपयोग
- उपयोगिताओं
- छुट्टी
- मूल्य
- विभिन्न
- वाहन
- बहुत
- के माध्यम से
- दृष्टि
- करना चाहते हैं
- था
- देख
- we
- वेब
- वेब एप्लीकेशन
- वेब सेवाओं
- Webinars
- कुंआ
- थे
- पश्चिम
- कब
- कौन कौन से
- जब
- चौड़ा
- विस्तृत श्रृंखला
- मर्जी
- साथ में
- अंदर
- बिना
- महिलाओं
- शब्द
- शब्द
- काम
- काम कर रहे
- कार्य
- कार्यशालाओं
- होगा
- लिखना
- लिख रहे हैं
- साल
- इसलिए आप
- आपका
- यूट्यूब
- जेफिरनेट