आधुनिक दुनिया में, अधिकांश व्यवसाय अपने विकास, रणनीतिक निवेश और ग्राहक जुड़ाव को बढ़ावा देने के लिए बड़े डेटा और एनालिटिक्स की शक्ति पर भरोसा करते हैं। बिग डेटा लक्षित विज्ञापन, वैयक्तिकृत विपणन, उत्पाद अनुशंसाएँ, अंतर्दृष्टि निर्माण, मूल्य अनुकूलन, भावना विश्लेषण, भविष्य कहनेवाला विश्लेषण, और बहुत कुछ में अंतर्निहित स्थिरांक है।
डेटा को अक्सर कई स्रोतों से एकत्र किया जाता है, रूपांतरित किया जाता है, संग्रहीत किया जाता है और डेटा झीलों पर ऑन-प्रिमाइसेस या ऑन-क्लाउड पर संसाधित किया जाता है। जबकि डेटा का प्रारंभिक अंतर्ग्रहण अपेक्षाकृत तुच्छ है और इन-हाउस या पारंपरिक ईटीएल (एक्स्ट्रेक्ट ट्रांसफ़ॉर्म लोड) टूल विकसित कस्टम स्क्रिप्ट के माध्यम से प्राप्त किया जा सकता है, समस्या जल्दी से जटिल और हल करने के लिए महंगी हो जाती है क्योंकि कंपनियों को:
- संपूर्ण डेटा जीवनचक्र प्रबंधित करें - हाउसकीपिंग और अनुपालन उद्देश्यों के लिए
- भंडारण का अनुकूलन - संबद्ध लागतों को कम करने के लिए
- आर्किटेक्चर को सरल बनाएं - कंप्यूटिंग इंफ्रास्ट्रक्चर के पुन: उपयोग के माध्यम से
- डेटा को क्रमिक रूप से संसाधित करें - शक्तिशाली राज्य प्रबंधन के माध्यम से
- बैच और स्ट्रीम डेटा पर समान नीतियां लागू करें - प्रयास के दोहराव के बिना
- ऑन-प्रिमाइसेस और क्लाउड के बीच माइग्रेट करें - कम से कम प्रयास के साथ
यह कहाँ है अपाचे गोब्लिन, एक ओपन-सोर्स डेटा प्रबंधन, और एकीकरण प्रणाली आती है। अपाचे गोब्लिन अद्वितीय क्षमताएं प्रदान करता है जिसका उपयोग व्यवसाय की जरूरतों के आधार पर पूरे या भागों में किया जा सकता है।
इस खंड में, हम अपाचे गोब्लिन की विभिन्न क्षमताओं में तल्लीन होंगे जो पहले उल्लिखित चुनौतियों का समाधान करने में सहायता करते हैं।
पूर्ण डेटा जीवनचक्र का प्रबंधन
Apache Gobblin डेटा पाइपलाइनों के निर्माण के लिए क्षमताओं का एक सरगम प्रदान करता है जो डेटासेट पर डेटा जीवनचक्र संचालन के पूर्ण सूट का समर्थन करता है।
- इनजेस्ट डेटा - कई स्रोतों से डेटाबेस, बाकी एपीआई, एफ़टीपी / एसएफटीपी सर्वर, फाइलर्स, सीआरएम जैसे सेल्सफोर्स और डायनेमिक्स, और बहुत कुछ।
- डेटा को दोहराएं - डिस्टीसीपी-एनजी के माध्यम से हडूप वितरित फाइल सिस्टम के लिए विशेष क्षमताओं के साथ कई डेटा झीलों के बीच।
- डेटा शुद्ध करें - अवधारण नीतियों जैसे समय-आधारित, नवीनतम K, संस्करणित, या नीतियों के संयोजन का उपयोग करना।
गोब्लिन की तार्किक पाइपलाइन में एक 'स्रोत' होता है जो काम के वितरण को निर्धारित करता है और 'वर्कयूनिट' बनाता है। इन 'कार्य इकाइयों' को 'कार्य' के रूप में निष्पादन के लिए चुना जाता है, जिसमें निष्कर्षण, रूपांतरण, गुणवत्ता जांच और गंतव्य के लिए डेटा लिखना शामिल है। अंतिम चरण, 'डेटा प्रकाशित करें,' पाइपलाइन के सफल निष्पादन को मान्य करता है और यदि गंतव्य इसका समर्थन करता है, तो परमाणु रूप से आउटपुट डेटा जमा करता है।
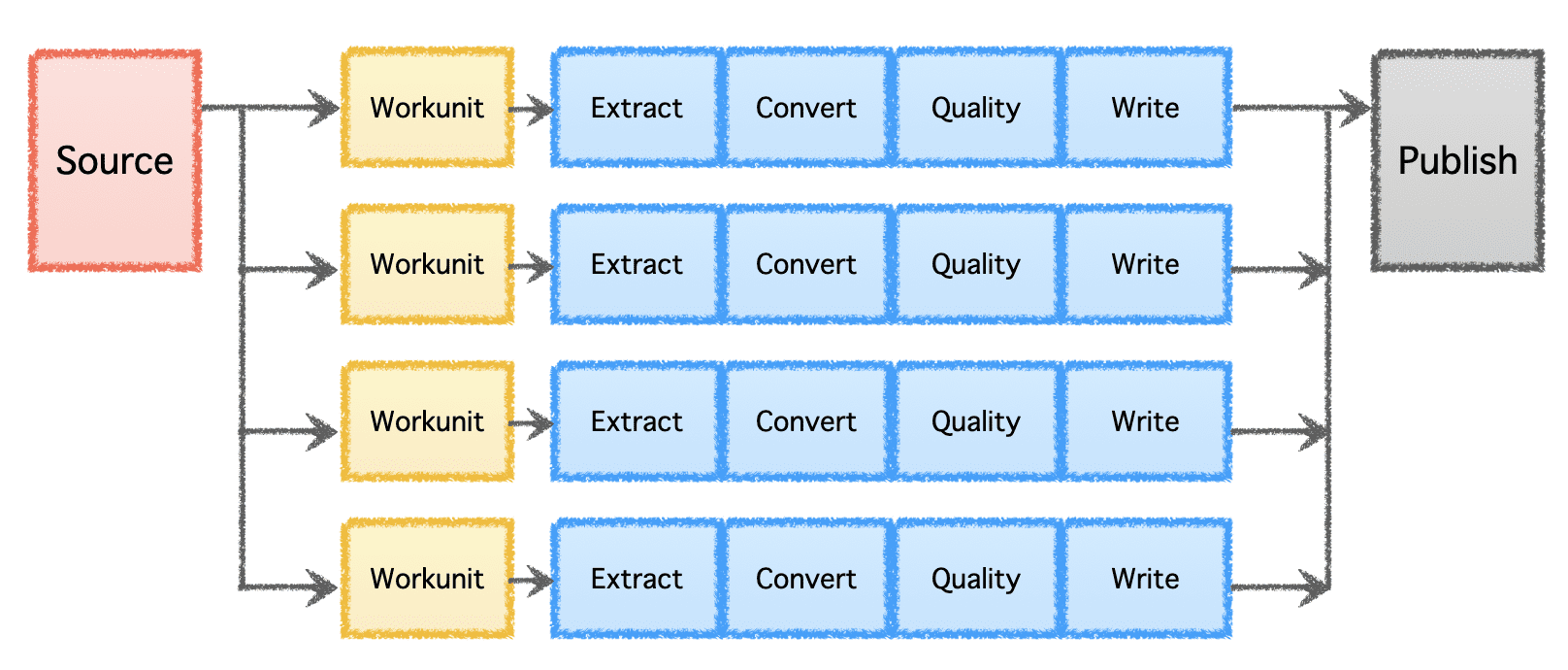
लेखक द्वारा छवि
संग्रहण को ऑप्टिमाइज़ करें
अपाचे गोब्लिन संघनन या प्रारूप रूपांतरण के माध्यम से अंतर्ग्रहण या प्रतिकृति के बाद प्रसंस्करण डेटा के माध्यम से डेटा के लिए आवश्यक भंडारण की मात्रा को कम करने में मदद कर सकता है।
- कॉम्पैक्शन - पोस्ट-प्रोसेसिंग डेटा को रिकॉर्ड के सभी फ़ील्ड या प्रमुख फ़ील्ड के आधार पर डीडुप्लिकेट करने के लिए, डेटा को केवल एक रिकॉर्ड को एक ही कुंजी के साथ नवीनतम टाइमस्टैम्प के साथ रखने के लिए ट्रिम करना।
- एवरो टू ओआरसी - लोकप्रिय पंक्ति-आधारित एवरो प्रारूप को हाइपर-अनुकूलित कॉलम-आधारित ओआरसी प्रारूप में बदलने के लिए एक विशेष प्रारूप रूपांतरण तंत्र के रूप में।
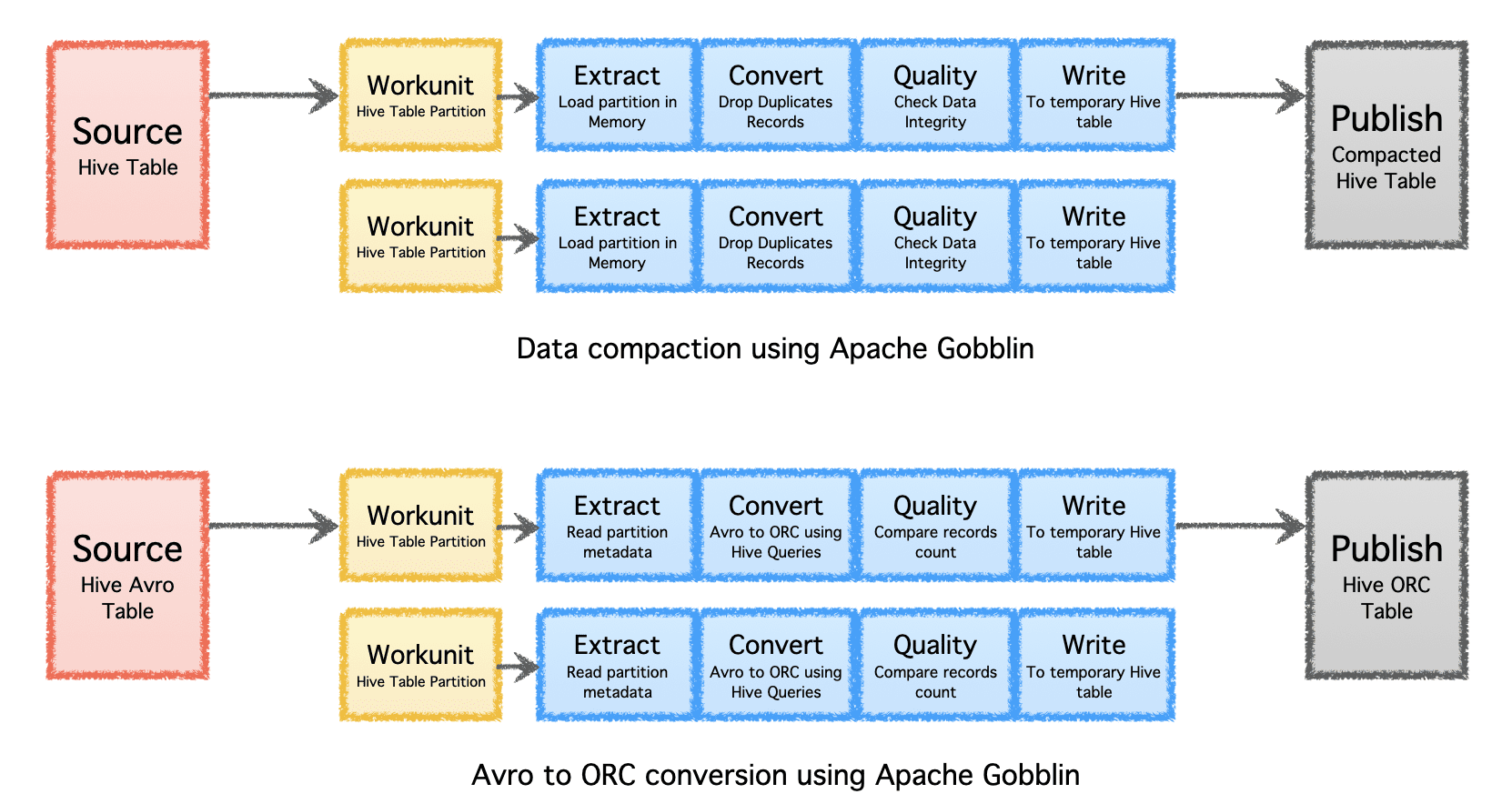
लेखक द्वारा छवि
आर्किटेक्चर को सरल बनाएं
कंपनी के चरण (स्टार्टअप टू एंटरप्राइज), स्केल आवश्यकताओं और उनके संबंधित आर्किटेक्चर के आधार पर, कंपनियां अपने डेटा इंफ्रास्ट्रक्चर को स्थापित या विकसित करना पसंद करती हैं। अपाचे गोब्लिन बहुत लचीला है और कई निष्पादन मॉडल का समर्थन करता है।
- स्टैंडअलोन मोड - नंगे धातु के बक्से पर एक स्टैंडअलोन प्रक्रिया के रूप में चलाने के लिए, यानी सरल उपयोग के मामलों और कम मांग वाली स्थितियों के लिए एकल होस्ट।
- MapReduce मोड - पेटाबाइट्स स्केल में डेटासेट को संभालने के लिए बड़े डेटा मामलों के लिए Hadoop इन्फ्रास्ट्रक्चर पर MapReduce जॉब के रूप में चलाने के लिए।
- क्लस्टर मोड: स्टैंडअलोन - हडूप एमआर ढांचे से स्वतंत्र बड़े पैमाने पर संभालने के लिए नंगे धातु मशीनों या मेजबानों के एक सेट पर अपाचे हेलिक्स और अपाचे ज़ूकीपर द्वारा समर्थित क्लस्टर के रूप में चलाने के लिए।
- क्लस्टर मोड: यार्न - हडूप एमआर ढांचे के बिना देशी यार्न पर क्लस्टर के रूप में चलाने के लिए।
- क्लस्टर मोड: एडब्ल्यूएस - अमेज़ॅन की सार्वजनिक क्लाउड पेशकश पर क्लस्टर के रूप में चलाने के लिए, यानी। AWS पर होस्ट किए गए इन्फ्रास्ट्रक्चर के लिए AWS।
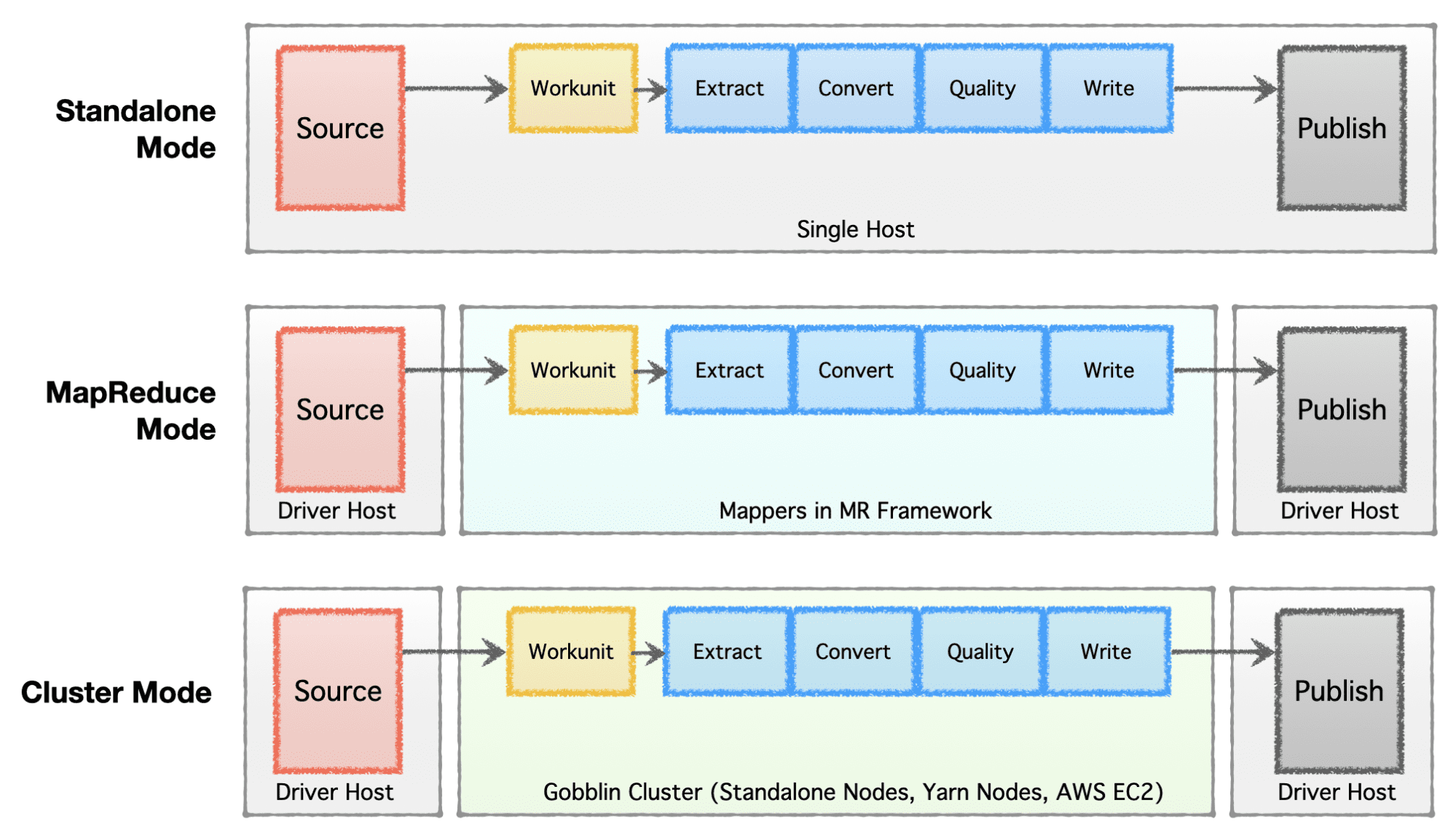
लेखक द्वारा छवि
डेटा को धीरे-धीरे प्रोसेस करें
कई डेटा पाइपलाइनों और उच्च मात्रा के साथ एक महत्वपूर्ण पैमाने पर, डेटा को बैचों में और समय के साथ संसाधित करने की आवश्यकता होती है। इसलिए, इसे चेकपॉइंटिंग की आवश्यकता होती है ताकि डेटा पाइपलाइनें फिर से शुरू हो सकें, जहां से पिछली बार छोड़ी गई थीं और आगे जारी रहेंगी। Apache Gobblin निम्न और उच्च वॉटरमार्क का समर्थन करता है और HDFS, AWS S3, MySQL और अधिक पारदर्शी रूप से स्टेट स्टोर के माध्यम से मजबूत राज्य प्रबंधन शब्दार्थ का समर्थन करता है।
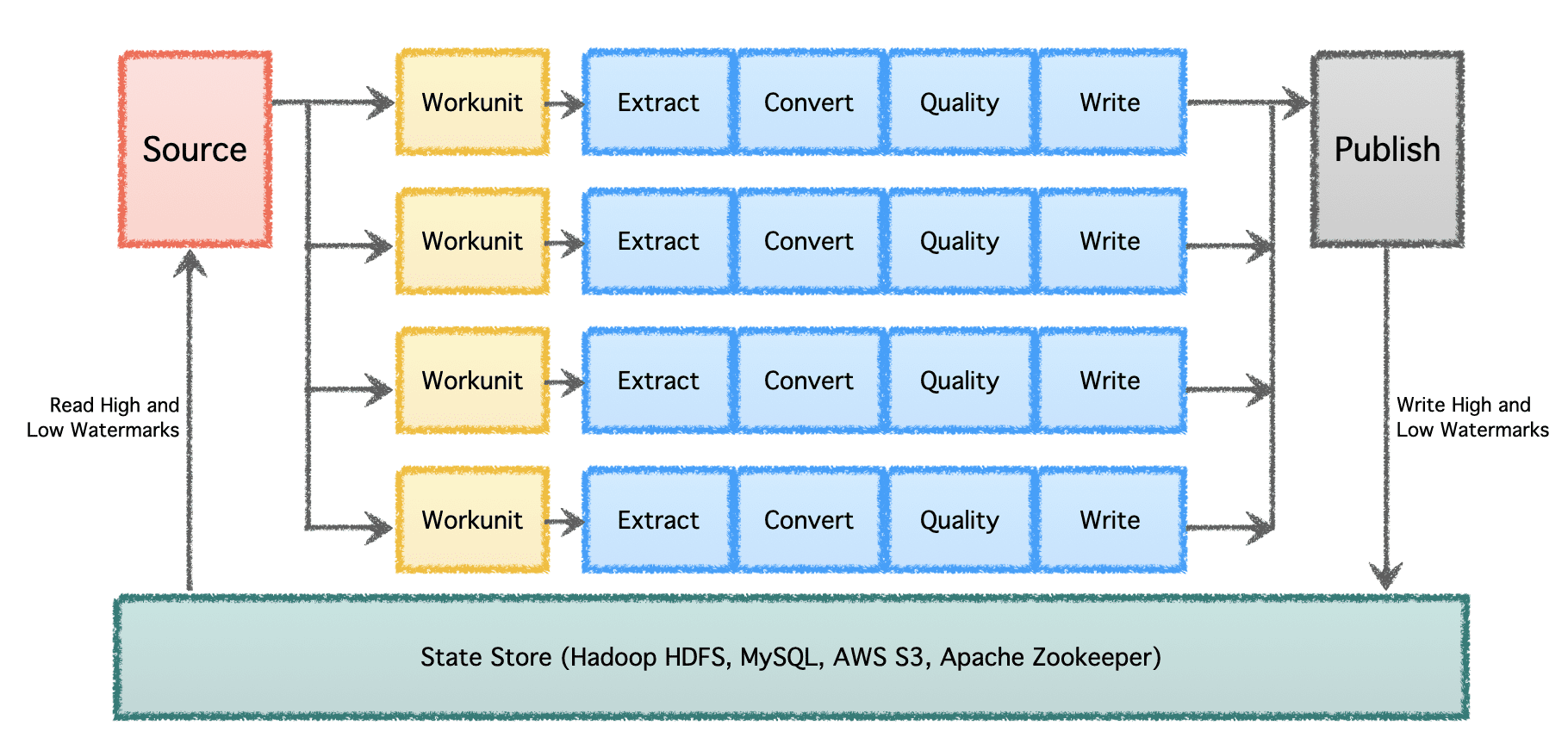
लेखक द्वारा छवि
बैच और स्ट्रीम डेटा पर समान नीतियां
अधिकांश डेटा पाइपलाइनों को आज दो बार लिखना पड़ता है, एक बार बैच डेटा के लिए और फिर नियर-लाइन या स्ट्रीमिंग डेटा के लिए। यह प्रयास को दोगुना करता है और विभिन्न प्रकार की पाइपलाइनों पर लागू नीतियों और एल्गोरिदम में विसंगतियों का परिचय देता है। Apache Gobblin उपयोगकर्ताओं को एक बार पाइपलाइन लिखने और इसे Gobblin क्लस्टर मोड, AWS मोड पर Gobblin, या Yarn मोड पर Gobblin में उपयोग किए जाने पर दोनों बैच और स्ट्रीम डेटा पर चलाने की अनुमति देकर इसे हल करता है।
ऑन-प्रिमाइसेस और क्लाउड के बीच माइग्रेट करें
इसके बहुमुखी मोड के कारण जो एक बॉक्स, नोड्स के एक समूह, या क्लाउड पर ऑन-प्रिमाइसेस चल सकता है - अपाचे गोब्लिन को ऑन-प्रिमाइसेस और क्लाउड पर तैनात और उपयोग किया जा सकता है। इसलिए, उपयोगकर्ताओं को एक बार अपने डेटा पाइपलाइनों को लिखने और विशिष्ट आवश्यकताओं के आधार पर ऑन-प्रिमाइसेस और क्लाउड के बीच आसानी से गोब्लिन परिनियोजन के साथ माइग्रेट करने की अनुमति देता है।
इसकी अत्यधिक लचीली वास्तुकला, शक्तिशाली विशेषताओं और डेटा वॉल्यूम के चरम पैमाने के कारण जो इसे समर्थन और प्रक्रिया कर सकता है, Apache Gobblin का उपयोग उत्पादन के बुनियादी ढांचे में किया जाता है। प्रमुख प्रौद्योगिकी कंपनियां और आज किसी भी बड़े डेटा इंफ्रास्ट्रक्चर परिनियोजन के लिए जरूरी है।
Apache Gobblin के बारे में अधिक जानकारी और इसका उपयोग कैसे करें पर पाया जा सकता है https://gobblin.apache.org
अभिषेक तिवारी लिंक्डइन में एक वरिष्ठ प्रबंधक हैं, जो कंपनी के बिग डेटा पाइपलाइन संगठन का नेतृत्व कर रहे हैं। वे Apache Software Foundation में Apache Gobblin के वाइस प्रेसिडेंट और ब्रिटिश कंप्यूटर सोसाइटी के फेलो भी हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- हासिल
- को संबोधित
- विज्ञापन
- बाद
- सहायता
- एल्गोरिदम
- सब
- की अनुमति दे
- राशि
- विश्लेषण
- विश्लेषिकी
- और
- अपाचे
- एपीआई
- लागू
- स्थापत्य
- जुड़े
- लेखक
- एडब्ल्यूएस
- अस्तरवाला
- आधारित
- हो जाता है
- के बीच
- बड़ा
- बड़ा डेटा
- मुक्केबाज़ी
- ब्रिटिश
- व्यापार
- व्यवसायों
- क्षमताओं
- मामलों
- चुनौतियों
- जाँच
- बादल
- समूह
- संयोजन
- कंपनियों
- कंपनी
- जटिल
- अनुपालन
- कंप्यूटर
- कंप्यूटिंग
- स्थिर
- निर्माण
- जारी रखने के
- रूपांतरण
- बदलना
- बनाता है
- रिवाज
- ग्राहक
- ग्राहक अनुबंध
- तिथि
- डेटा अवसंरचना
- आँकड़ा प्रबंधन
- डेटाबेस
- डेटासेट
- निर्भर करता है
- तैनात
- तैनाती
- तैनाती
- गंतव्य
- विवरण
- निर्धारित
- विकसित
- विभिन्न
- वितरित
- वितरण
- गतिकी
- आसानी
- प्रयास
- सगाई
- उद्यम
- ईथर (ईटीएच)
- विकसित करना
- निष्पादन
- महंगा
- उद्धरण
- निष्कर्षण
- चरम
- विशेषताएं
- साथी
- फ़ील्ड
- पट्टिका
- अंतिम
- लचीला
- प्रारूप
- पाया
- बुनियाद
- ढांचा
- से
- ईंधन
- पूर्ण
- पीढ़ी
- विकास
- Hadoop
- संभालना
- मदद
- हाई
- अत्यधिक
- मेजबान
- मेजबानी
- कैसे
- How To
- HTTPS
- in
- शामिल
- स्वतंत्र
- इंफ्रास्ट्रक्चर
- बुनियादी सुविधाओं
- प्रारंभिक
- अंतर्दृष्टि
- एकीकरण
- द्वारा प्रस्तुत
- निवेश
- IT
- काम
- केडनगेट्स
- रखना
- कुंजी
- बड़ा
- पिछली बार
- ताज़ा
- प्रमुख
- लिंक्डइन
- भार
- निम्न
- मशीनें
- प्रबंध
- प्रबंधक
- विपणन (मार्केटिंग)
- तंत्र
- धातु
- विस्थापित
- मोड
- मॉडल
- आधुनिक
- मोड
- अधिक
- अधिकांश
- विभिन्न
- अत्यावश्यक
- MySQL
- देशी
- जरूरत
- की जरूरत है
- नवीनतम
- नोड्स
- की पेशकश
- ONE
- खुला स्रोत
- संचालन
- संगठन
- उल्लिखित
- भागों
- निजीकृत
- उठाया
- पाइपलाइन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- नीतियाँ
- लोकप्रिय
- बिजली
- शक्तिशाली
- भविष्य कहनेवाला विश्लेषिकी
- पसंद करते हैं
- अध्यक्ष
- पहले से
- मूल्य
- मुसीबत
- प्रक्रिया
- एस्ट्रो मॉल
- उत्पादन
- प्रदान करता है
- सार्वजनिक
- सार्वजनिक क्लाउड
- प्रकाशित करना
- गुणवत्ता
- जल्दी से
- लेकर
- सिफारिशें
- रिकॉर्ड
- अभिलेख
- को कम करने
- अपेक्षाकृत
- प्रतिकृति
- आवश्यकताएँ
- कि
- बाकी
- बायोडाटा
- प्रतिधारण
- मजबूत
- रन
- salesforce
- वही
- स्केल
- स्केलिंग
- लिपियों
- अनुभाग
- अर्थ विज्ञान
- वरिष्ठ
- भावुकता
- सेट
- महत्वपूर्ण
- सरल
- एक
- स्थितियों
- So
- समाज
- सॉफ्टवेयर
- हल
- हल करती है
- स्रोत
- सूत्रों का कहना है
- विशेषीकृत
- विशिष्ट
- ट्रेनिंग
- स्टैंडअलोन
- स्टार्टअप
- राज्य
- कदम
- भंडारण
- की दुकान
- संग्रहित
- सामरिक
- धारा
- स्ट्रीमिंग
- सफल
- सूट
- समर्थन
- समर्थन करता है
- प्रणाली
- लक्षित
- कार्य
- टेक्नोलॉजी
- RSI
- लेकिन हाल ही
- इसलिये
- यहाँ
- पहर
- टाइमस्टैम्प
- सेवा मेरे
- आज
- उपकरण
- परंपरागत
- बदालना
- तब्दील
- प्रकार
- आधारभूत
- अद्वितीय
- उपयोग
- उपयोगकर्ताओं
- विभिन्न
- बहुमुखी
- के माध्यम से
- वाइस राष्ट्रपति
- आयतन
- संस्करणों
- कौन कौन से
- जब
- मर्जी
- बिना
- काम
- विश्व
- लिखना
- लिख रहे हैं
- लिखा हुआ
- जेफिरनेट