AWS गोंद स्टूडियो अब इसके साथ एकीकृत है AWS ग्लू डेटाब्रयू. AWS ग्लू स्टूडियो एक ग्राफ़िकल इंटरफ़ेस है जो निकालने, बदलने और लोड करने (ETL) नौकरियों को बनाना, चलाना और मॉनिटर करना आसान बनाता है एडब्ल्यूएस गोंद. DataBrew एक विज़ुअल डेटा तैयारी उपकरण है जो आपको बिना कोई कोड लिखे डेटा को साफ़ और सामान्य करने में सक्षम बनाता है। इसके द्वारा प्रदान किए गए 200 से अधिक परिवर्तन अब AWS ग्लू स्टूडियो विज़ुअल कार्य में उपयोग के लिए उपलब्ध हैं।
DataBrew में, ए नुस्खा डेटा परिवर्तन चरणों का एक सेट है जिसे आप इसके सहज दृश्य इंटरफ़ेस में अंतःक्रियात्मक रूप से लिख सकते हैं। इस पोस्ट में, आप देखेंगे कि DataBrew में एक रेसिपी कैसे बनाएं और फिर इसे AWS ग्लू स्टूडियो विज़ुअल ETL जॉब के हिस्से के रूप में कैसे लागू करें।
मौजूदा डेटाब्रू उपयोगकर्ताओं को भी इस एकीकरण से लाभ होगा - अब आप उन्नत जॉब कॉन्फ़िगरेशन और नवीनतम एडब्ल्यूएस ग्लू इंजन संस्करण का उपयोग करने में सक्षम होने के अलावा, एडब्ल्यूएस ग्लू स्टूडियो द्वारा प्रदान किए जाने वाले अन्य सभी घटकों के साथ एक बड़े विज़ुअल वर्कफ़्लो के हिस्से के रूप में अपने व्यंजनों को चला सकते हैं। .
यह एकीकरण दोनों उपकरणों के मौजूदा उपयोगकर्ताओं के लिए विशिष्ट लाभ लाता है:
- आपके पास AWS ग्लू स्टूडियो में शुरू से अंत तक समग्र ETL आरेख का एक केंद्रीकृत दृश्य है
- आप डेटाब्रू कंसोल पर मूल्यों, आंकड़ों और वितरण को देखकर एक नुस्खा को इंटरैक्टिव रूप से परिभाषित कर सकते हैं, फिर एडब्ल्यूएस ग्लू स्टूडियो विज़ुअल जॉब्स में उस परीक्षण और संस्करणित प्रसंस्करण तर्क का पुन: उपयोग कर सकते हैं।
- आप एडब्ल्यूएस ग्लू ईटीएल जॉब या यहां तक कि एडब्ल्यूएस ग्लू वर्कफ़्लोज़ का उपयोग करके कई नौकरियों में एकाधिक डेटाब्रू व्यंजनों को व्यवस्थित कर सकते हैं
- डेटाब्रू रेसिपी अब एडब्ल्यूएस ग्लू जॉब सुविधाओं का उपयोग कर सकती हैं जैसे कि वृद्धिशील डेटा प्रोसेसिंग के लिए बुकमार्क, स्वचालित रिट्रीट, ऑटो स्केल, या अधिक दक्षता के लिए छोटी फ़ाइलों को समूहीकृत करना।
समाधान अवलोकन
हमारे काल्पनिक उपयोग के मामले में, इस पोस्ट के लिए बनाए गए सिंथेटिक मेडिकल दावों के डेटासेट को साफ करने की आवश्यकता है, जिसमें डेटा तैयारी पर डेटाब्रू क्षमताओं को प्रदर्शित करने के उद्देश्य से कुछ डेटा गुणवत्ता संबंधी समस्याएं पेश की गई हैं। फिर दावा डेटा को एक अलग स्रोत से आने वाले संबंधित चिकित्सा प्रदाताओं के बारे में कुछ प्रासंगिक विवरणों के साथ समृद्ध करने के बाद, कैटलॉग में शामिल किया जाता है (ताकि यह विश्लेषकों को दिखाई दे)।
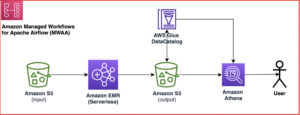
समाधान में AWS ग्लू स्टूडियो विज़ुअल जॉब शामिल है जो क्रमशः दावों और प्रदाताओं के साथ दो CSV फ़ाइलों को पढ़ता है। कार्य गुणवत्ता के मुद्दों को संबोधित करने के लिए पहले वाले का एक नुस्खा लागू करता है, दूसरे से कॉलम का चयन करता है, दोनों डेटासेट को जोड़ता है, और अंत में परिणाम को संग्रहीत करता है अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस3), कैटलॉग पर एक तालिका बना रहा है ताकि आउटपुट डेटा का उपयोग अन्य टूल द्वारा किया जा सके अमेज़न एथेना.
एक डेटाब्रू रेसिपी बनाएं
दावा फ़ाइल के लिए डेटा स्टोर पंजीकृत करके प्रारंभ करें। यह आपको वास्तविक डेटा का उपयोग करके इसके इंटरैक्टिव संपादक में रेसिपी बनाने की अनुमति देगा ताकि आप परिवर्तनों को परिभाषित करते समय उनके परिणाम का मूल्यांकन कर सकें।
- निम्नलिखित लिंक का उपयोग करके दावा CSV फ़ाइल डाउनलोड करें: alabama_claims_data_Jun2023.csv.
- DataBrew कंसोल पर, चुनें डेटासेट नेविगेशन फलक में, फिर चुनें नया डेटासेट कनेक्ट करें.
- विकल्प चुनें फाइल अपलोड.
- के लिए दातासेट नाम, दर्ज
Alabama claims. - के लिए अपलोड करने के लिए एक फ़ाइल चुनें, वह फ़ाइल चुनें जिसे आपने अभी-अभी अपने कंप्यूटर पर डाउनलोड किया है।
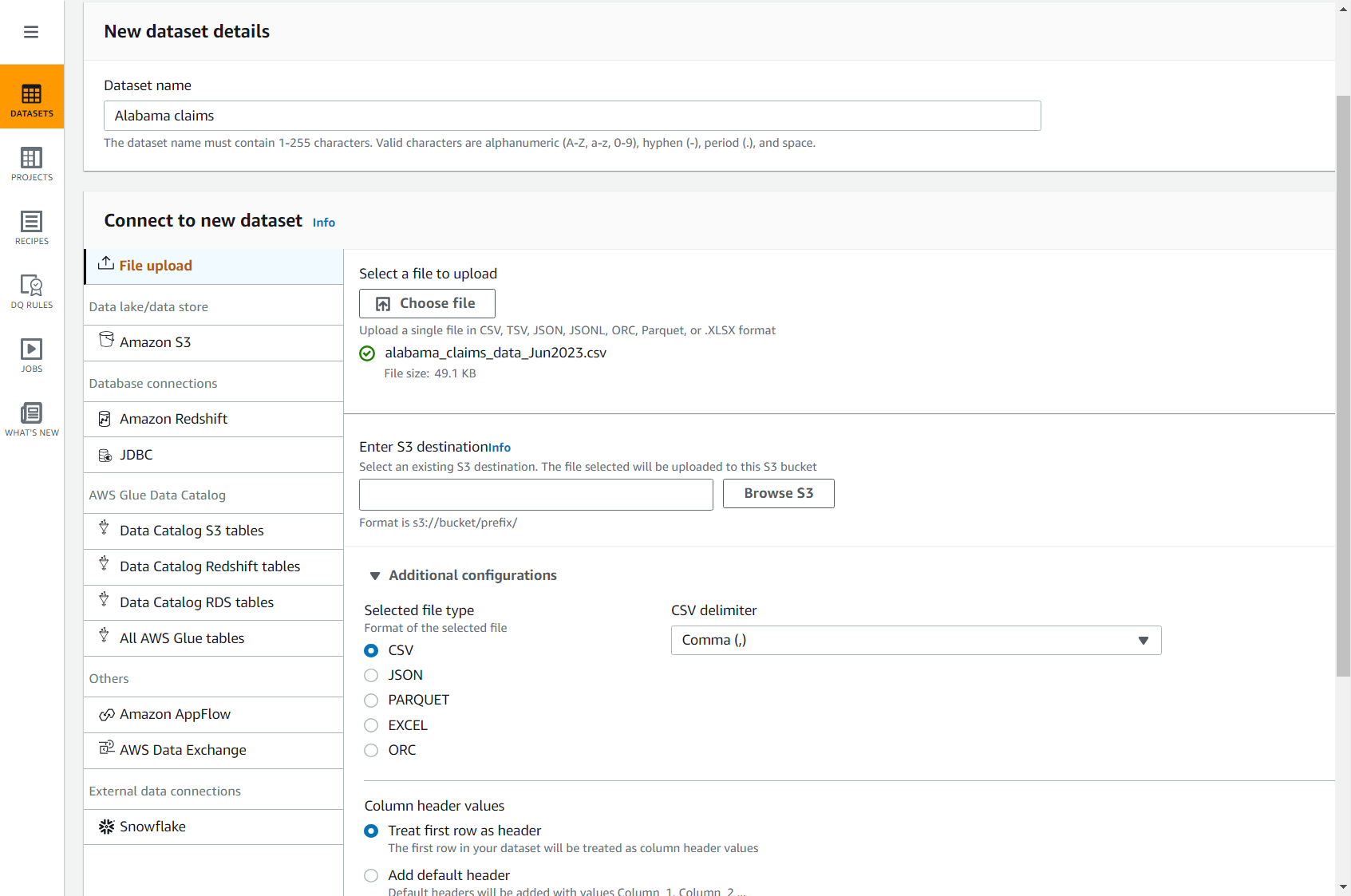
- के लिए S3 गंतव्य दर्ज करें, अपने खाते और क्षेत्र में एक बकेट दर्ज करें या ब्राउज़ करें।
- बाकी विकल्पों को डिफ़ॉल्ट रूप से छोड़ दें (सीएसवी को अल्पविराम और हेडर से अलग किया गया) और डेटासेट निर्माण पूरा करें।
- चुनें परियोजना नेविगेशन फलक में, फिर चुनें प्रोजेक्ट बनाएं.
- के लिए परियोजना का नाम, नाम लो
ClaimsCleanup. - के अंतर्गत पकाने की विधि विवरणके लिए, संलग्न नुस्खा, चुनें नई रेसिपी बनाएं, नाम लो
ClaimsCleanup-recipe, और चुनेंAlabama claimsआपके द्वारा अभी बनाया गया डेटासेट।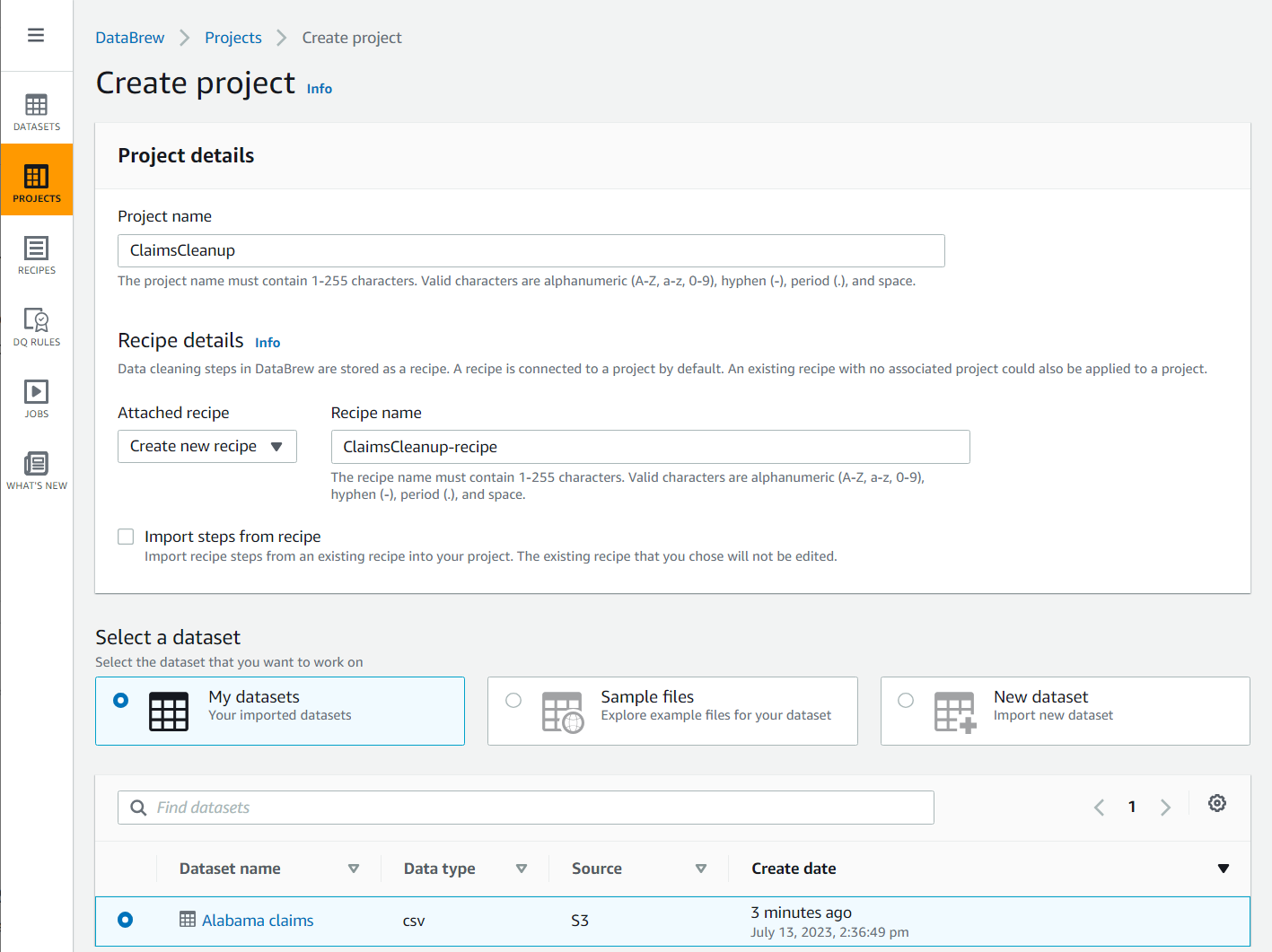
- एक का चयन करें DataBrew के लिए उपयुक्त भूमिका या एक नया बनाएं, और प्रोजेक्ट निर्माण पूरा करें।
यह डेटा के कॉन्फ़िगर करने योग्य सबसेट का उपयोग करके एक सत्र बनाएगा। सत्र आरंभ होने के बाद, आप देख सकते हैं कि कुछ कक्षों में अमान्य या अनुपलब्ध मान हैं।
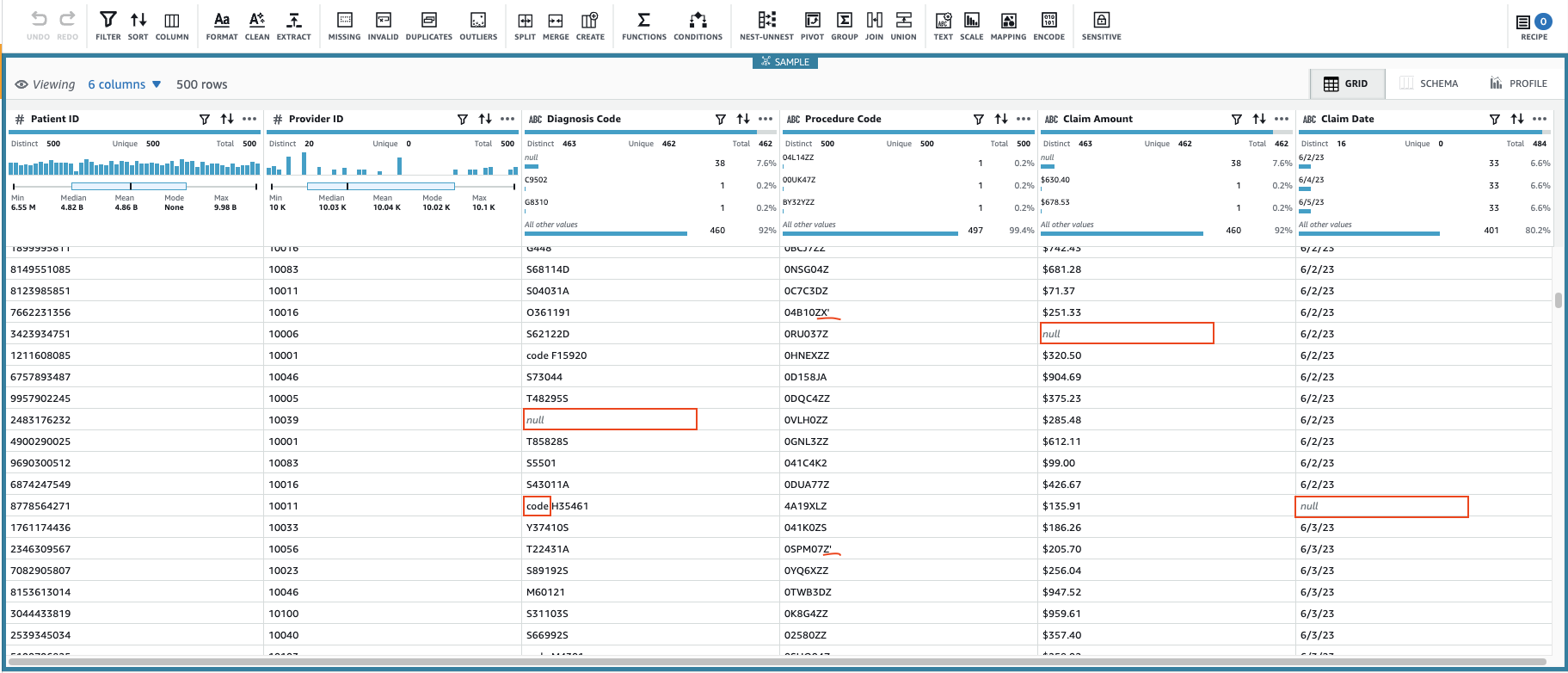
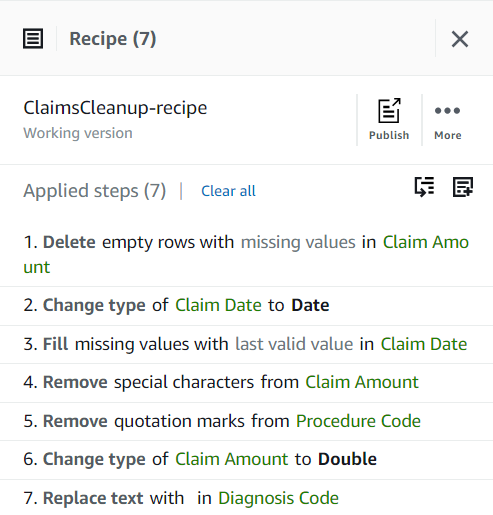
स्तंभों में लुप्त मानों के अतिरिक्त निदान कोड, दावा राशि, तथा दावा दिनांक, डेटा में कुछ मानों में कुछ अतिरिक्त वर्ण हैं: निदान कोड मानों को कभी-कभी "कोड" (स्थान शामिल) के साथ जोड़ा जाता है, और प्रक्रिया संहिता मानों के बाद कभी-कभी एकल उद्धरण चिह्न लगाए जाते हैं।
दावा राशि मानों का उपयोग संभवतः कुछ गणनाओं के लिए किया जाएगा, इसलिए संख्या में कनवर्ट करें, और डेटा का दावा करें दिनांक प्रकार में परिवर्तित किया जाना चाहिए।
अब जब हमने डेटा गुणवत्ता संबंधी मुद्दों की पहचान कर ली है, तो हमें यह निर्णय लेने की आवश्यकता है कि प्रत्येक मामले से कैसे निपटा जाए।
ऐसे कई तरीके हैं जिनसे आप रेसिपी चरण जोड़ सकते हैं, जिसमें कॉलम संदर्भ मेनू, शीर्ष पर टूलबार या रेसिपी सारांश का उपयोग करना शामिल है। अंतिम विधि का उपयोग करके, आप इस पोस्ट में बनाई गई रेसिपी को दोहराने के लिए संकेतित चरण प्रकार की खोज कर सकते हैं।
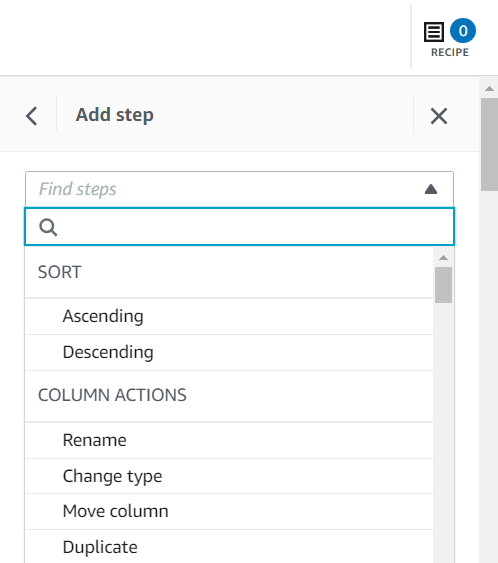
दावा राशि इस उपयोग के मामले के लिए आवश्यक है, और निर्णय ऐसी पंक्तियों को हटाने का है।
- चरण जोड़ें लुप्त मान हटाएँ.
- के लिए स्रोत स्तंभ, चुनें दावा राशि.
- डिफ़ॉल्ट क्रिया छोड़ें लुप्त मानों वाली पंक्तियाँ हटाएँ और चुनें लागू करें इसे बचाने के लिए
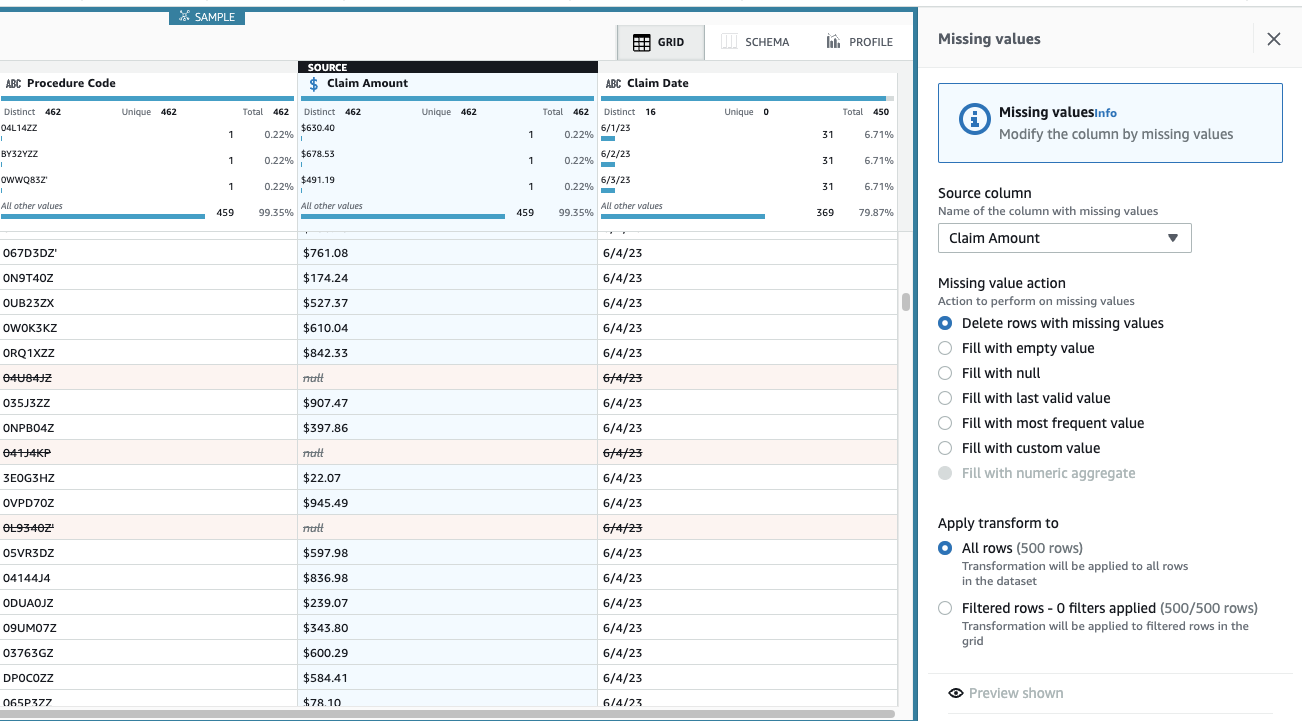
दृश्य को अब चरण अनुप्रयोग को प्रतिबिंबित करने के लिए अद्यतन किया गया है और गायब मात्रा वाली पंक्तियाँ अब वहां नहीं हैं।
निदान कोड खाली हो सकता है इसलिए इसे स्वीकार किया जाता है, लेकिन के मामले में दावा दिनांक, हम एक उचित अनुमान लगाना चाहते हैं। डेटा में पंक्तियों को कालानुक्रमिक क्रम में क्रमबद्ध किया गया है, इसलिए आप पूर्ववर्ती पंक्तियों से पूर्वावलोकन के वैध मान का उपयोग करके लापता तिथियों को लागू कर सकते हैं। यह मानते हुए कि हर दिन दावे होते हैं, सबसे बड़ी त्रुटि इसे पूर्वावलोकन दिवस पर निर्दिष्ट करना होगा यदि यह उस दिन का पहला दावा था जिसमें तारीख गायब थी; उदाहरण के लिए, आइए उस संभावित त्रुटि को स्वीकार्य मानें।
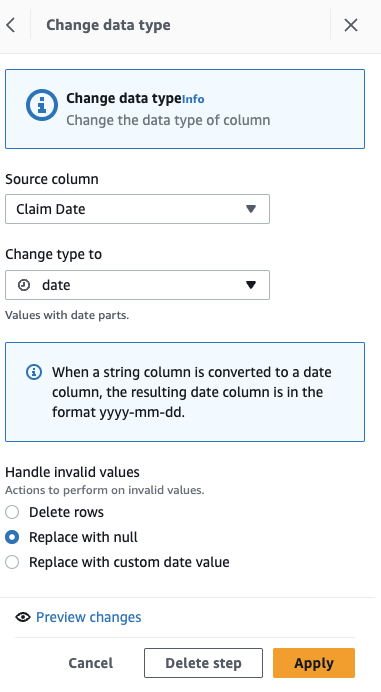
सबसे पहले, कॉलम को स्ट्रिंग से दिनांक प्रकार में बदलें।
- चरण जोड़ें प्रकार बदलें.
- चुनें दावा दिनांक स्तंभ के रूप में और डेटा प्रकार के रूप में, फिर चुनें लागू करें.
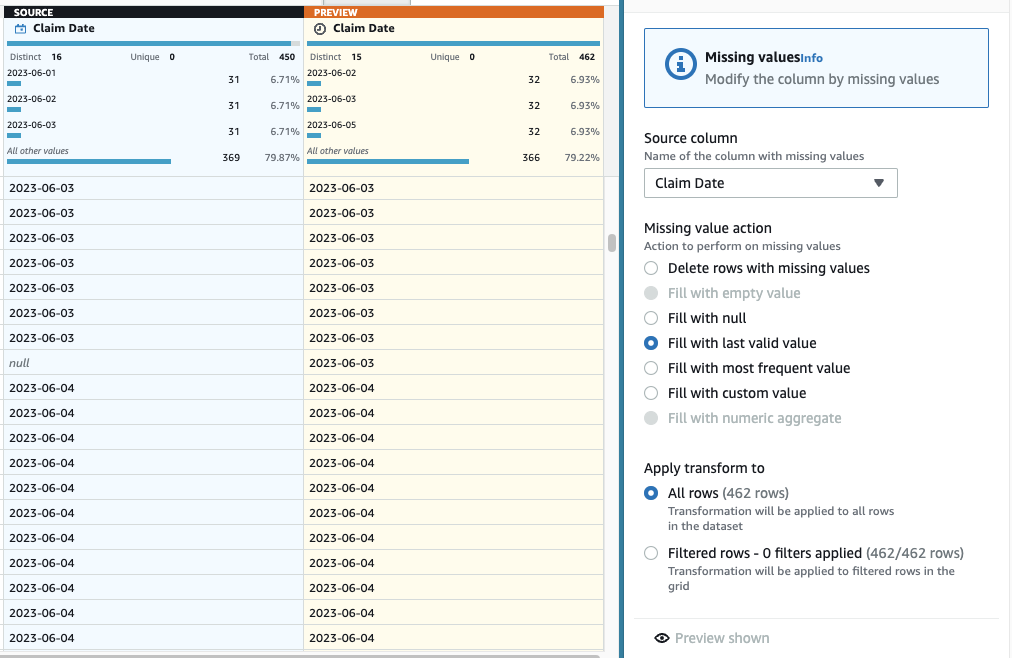
- अब लुप्त तिथियों का आकलन करने के लिए चरण जोड़ें लुप्त मान भरें या आरोपित करें.
- कार्रवाई के रूप में अंतिम वैध मान भरें चुनें और चुनें दावा दिनांक स्रोत के रूप में.
- चुनें परिवर्तनों का पूर्वावलोकन करें इसे सत्यापित करने के लिए, फिर चुनें लागू करें कदम बचाने के लिए।
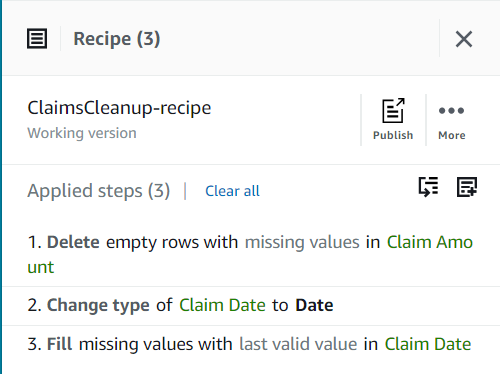
अब तक, आपकी रेसिपी में तीन चरण होने चाहिए, जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है।
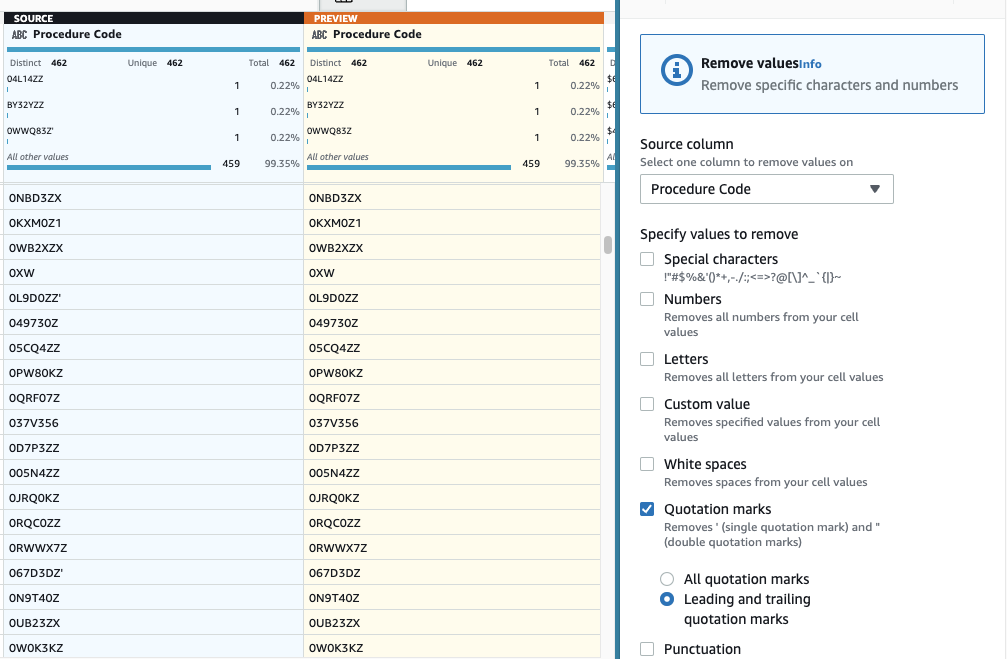
- अगला, चरण जोड़ें उद्धरण चिह्न हटाएँ.
- चुनना प्रक्रिया संहिता कॉलम और चयन करें अग्रणी और अनुगामी उद्धरण चिह्न.
- यह सत्यापित करने के लिए पूर्वावलोकन करें कि इसका वांछित प्रभाव है और नया चरण लागू करें।
- चरण जोड़ें विशेष वर्ण हटाएँ.
- चुनना दावा राशि कॉलम और अधिक विशिष्ट होने के लिए, चुनें कस्टम विशेष वर्ण और दर्ज करें
$एसटी कस्टम विशेष वर्ण दर्ज करें.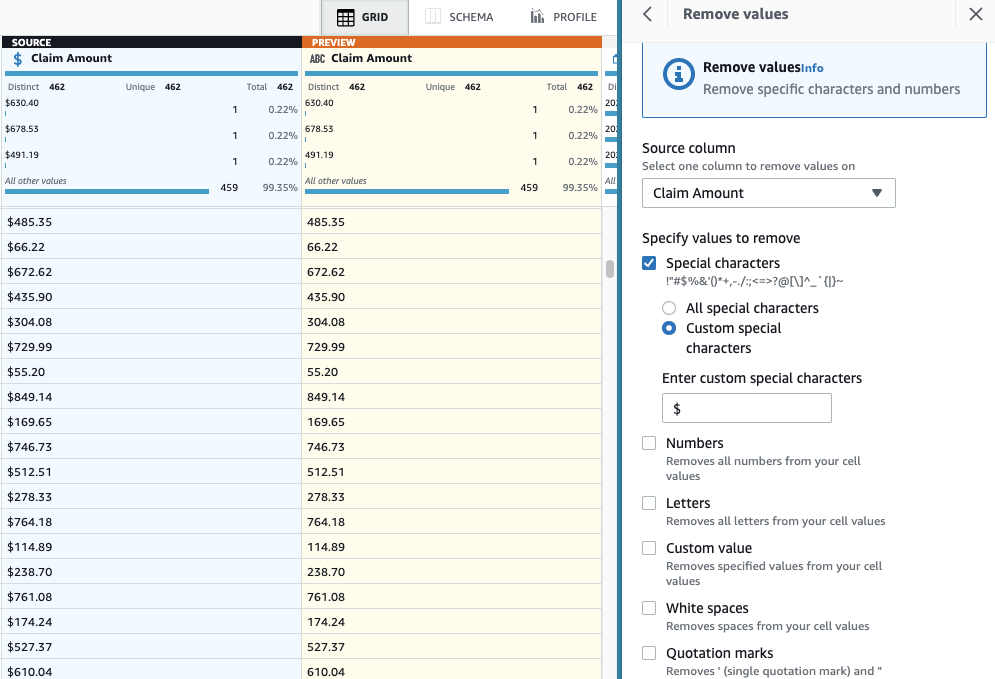
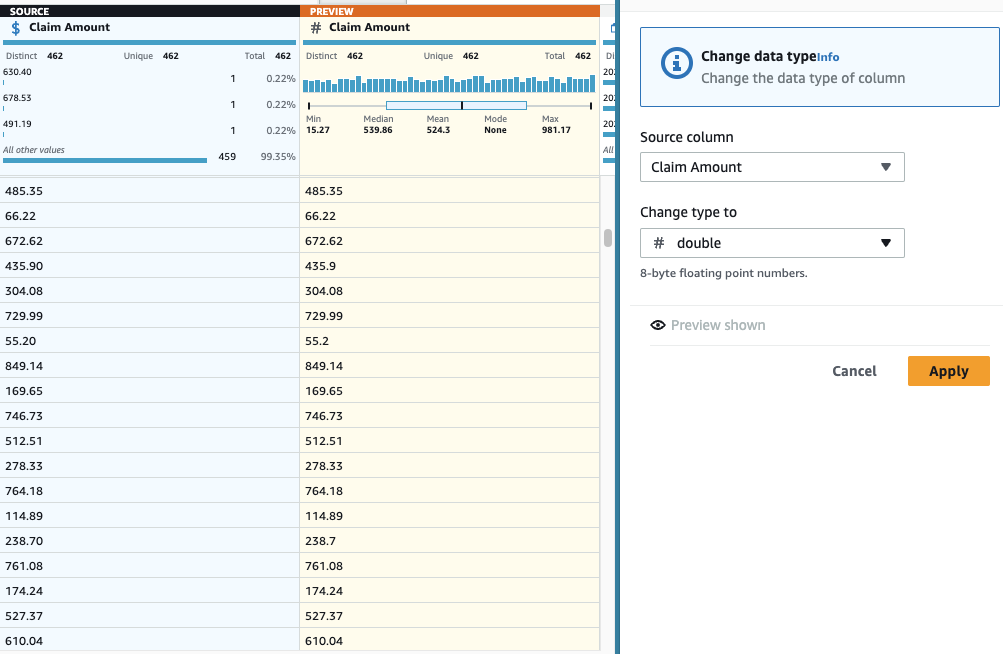
- एक जोड़ें प्रकार बदलें स्तंभ पर कदम रखें दावा राशि और चुनें डबल प्रकार के रूप में.
- अंतिम चरण के रूप में, अनावश्यक "कोड" उपसर्ग को हटाने के लिए, एक जोड़ें मान या पैटर्न बदलें कदम।
- कॉलम चुनें निदान कोडके लिए, और कस्टम मान दर्ज करें, दर्ज
code(अंत में एक स्थान के साथ)।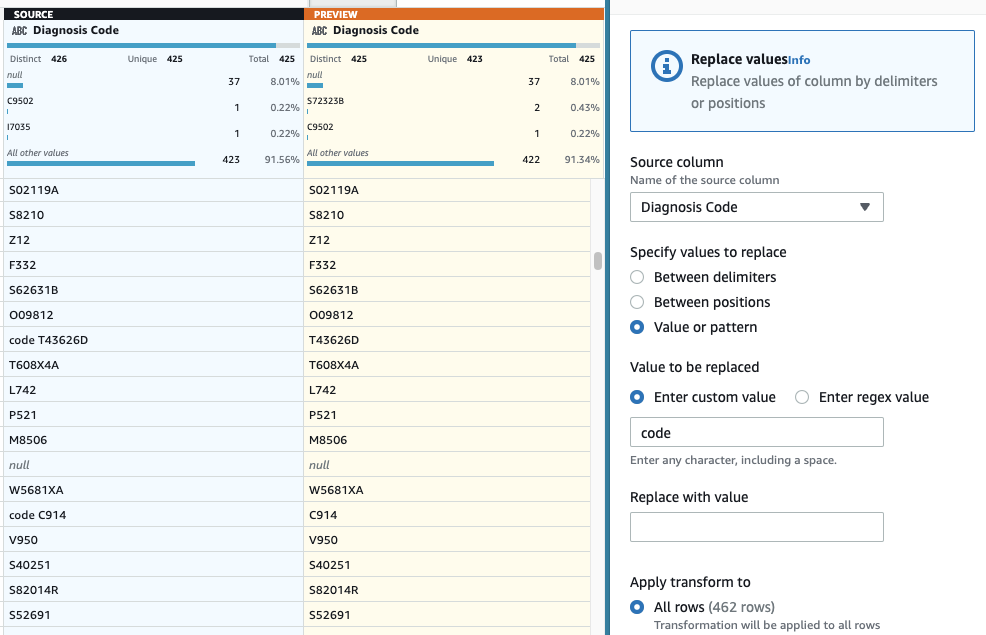
अब जब आपने नमूने में पहचाने गए सभी डेटा गुणवत्ता मुद्दों का समाधान कर लिया है, तो प्रोजेक्ट को एक रेसिपी के रूप में प्रकाशित करें।
- चुनें प्रकाशित करना में नुस्खा फलक, एक वैकल्पिक विवरण दर्ज करें, और प्रकाशन पूरा करें।
हर बार जब आप प्रकाशित करेंगे, तो यह रेसिपी का एक अलग संस्करण तैयार करेगा। बाद में, आप यह चुनने में सक्षम होंगे कि नुस्खा के किस संस्करण का उपयोग करना है।
AWS ग्लू स्टूडियो में एक विज़ुअल ETL जॉब बनाएं
इसके बाद, आप वह कार्य बनाते हैं जो नुस्खा का उपयोग करता है। निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस ग्लू स्टूडियो कंसोल पर, चुनें विजुअल ईटीएल नेविगेशन फलक में
- चुनें एक खाली कैनवास के साथ दृश्य और दृश्य कार्य बनाएं.
- कार्य के शीर्ष पर, "शीर्षक रहित कार्य" को अपनी पसंद के नाम से बदलें।
- पर नौकरी विवरण टैब, वह भूमिका निर्दिष्ट करें जिसका उपयोग कार्य करेगा।
यह एक होना जरूरी है AWS पहचान और अभिगम प्रबंधन (मैं हूँ) AWS गोंद के लिए उपयुक्त भूमिका Amazon S3 और AWS ग्लू डेटा कैटलॉग की अनुमति के साथ। ध्यान दें कि DataBrew के लिए पहले उपयोग की गई भूमिका रन जॉब के लिए उपयोग योग्य नहीं है, इसलिए इसे सूचीबद्ध नहीं किया जाएगा IAM भूमिका यहां ड्रॉप-डाउन मेनू.
यदि आपने पहले केवल DataBrew नौकरियों का उपयोग किया था, तो ध्यान दें कि AWS ग्लू स्टूडियो में, आप कार्यकर्ता आकार, ऑटो स्केलिंग और सहित प्रदर्शन और लागत सेटिंग्स चुन सकते हैं। लचीला निष्पादन, साथ ही नवीनतम AWS ग्लू 4.0 रनटाइम का उपयोग करें और इसके द्वारा लाए गए महत्वपूर्ण प्रदर्शन सुधारों से लाभ उठाएं। इस कार्य के लिए, आप डिफ़ॉल्ट सेटिंग्स का उपयोग कर सकते हैं, लेकिन मितव्ययिता के हित में श्रमिकों की अनुरोधित संख्या कम कर सकते हैं। इस उदाहरण के लिए, दो कर्मचारी काम करेंगे। - पर दृश्य टैब, एक S3 स्रोत जोड़ें और इसे नाम दें
Providers. - के लिए एस3 यूआरएल, दर्ज
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.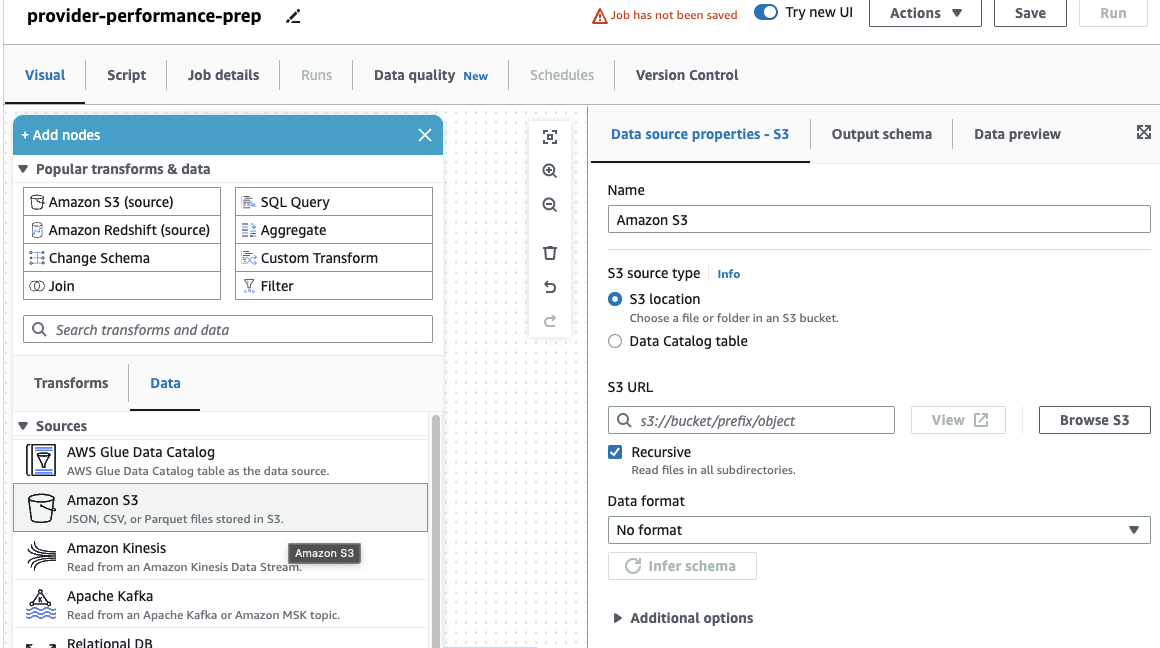
- इस रूप में प्रारूप का चयन करें CSV और चुनें स्कीमा का अनुमान लगाएं.
अब स्कीमा पर सूचीबद्ध है आउटपुट स्कीमा फ़ाइल हेडर का उपयोग करके टैब।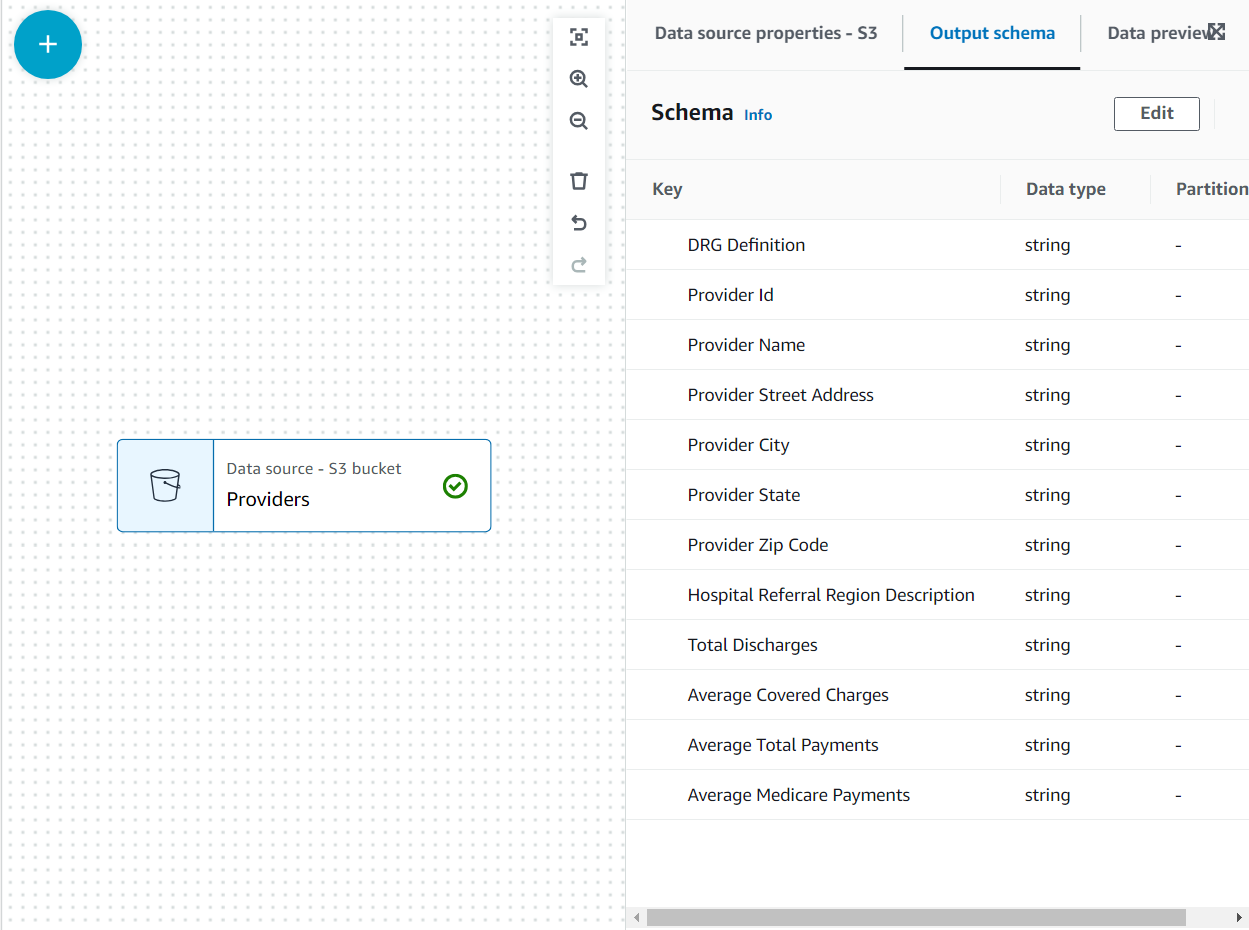
इस उपयोग के मामले में, निर्णय यह है कि प्रदाता डेटासेट में सभी कॉलम की आवश्यकता नहीं है, इसलिए हम बाकी को छोड़ सकते हैं।
- उसके साथ प्रदाताओं नोड चयनित, जोड़ें a ड्रॉप फील्ड्स ट्रांसफॉर्म (यदि आपने पैरेंट नोड का चयन नहीं किया है, तो इसमें एक भी नहीं होगा; उस स्थिति में, नोड पैरेंट को मैन्युअल रूप से असाइन करें)।
- इसके बाद सभी फ़ील्ड का चयन करें प्रदाता ज़िप कोड.
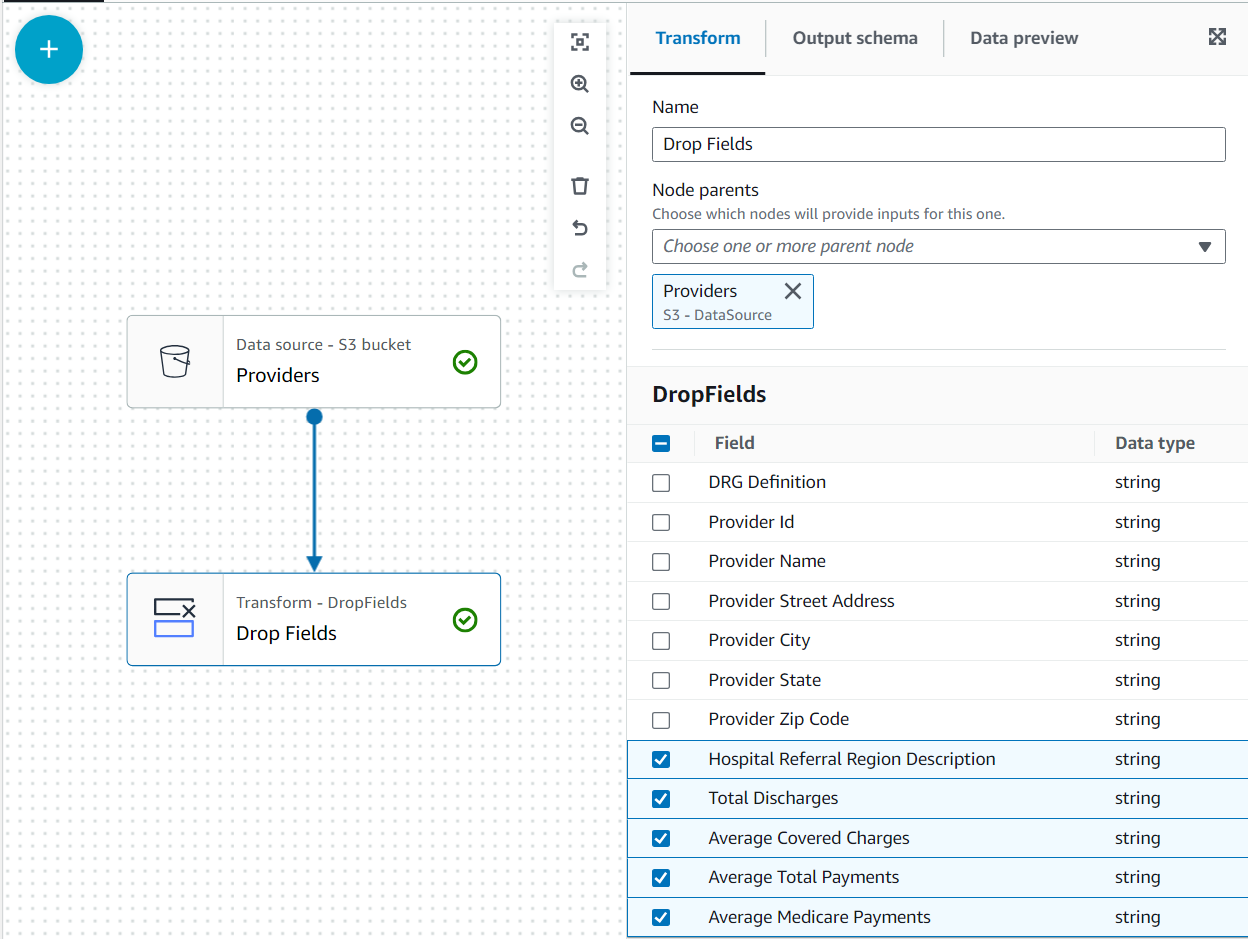
बाद में, यह डेटा प्रदाता का उपयोग करके अलबामा राज्य के दावों में शामिल हो जाएगा; हालाँकि, उस दूसरे डेटासेट में राज्य निर्दिष्ट नहीं है। हम डेटा के ज्ञान का उपयोग उस डेटा को फ़िल्टर करके जुड़ाव को अनुकूलित करने के लिए कर सकते हैं जिसकी हमें वास्तव में आवश्यकता है।
- एक जोड़ें फ़िल्टर के एक बच्चे के रूप में बदलो ड्रॉप फील्ड्स.
- नाम दें
Alabama providersऔर एक शर्त जोड़ें कि राज्य का मिलान होना चाहिएAL.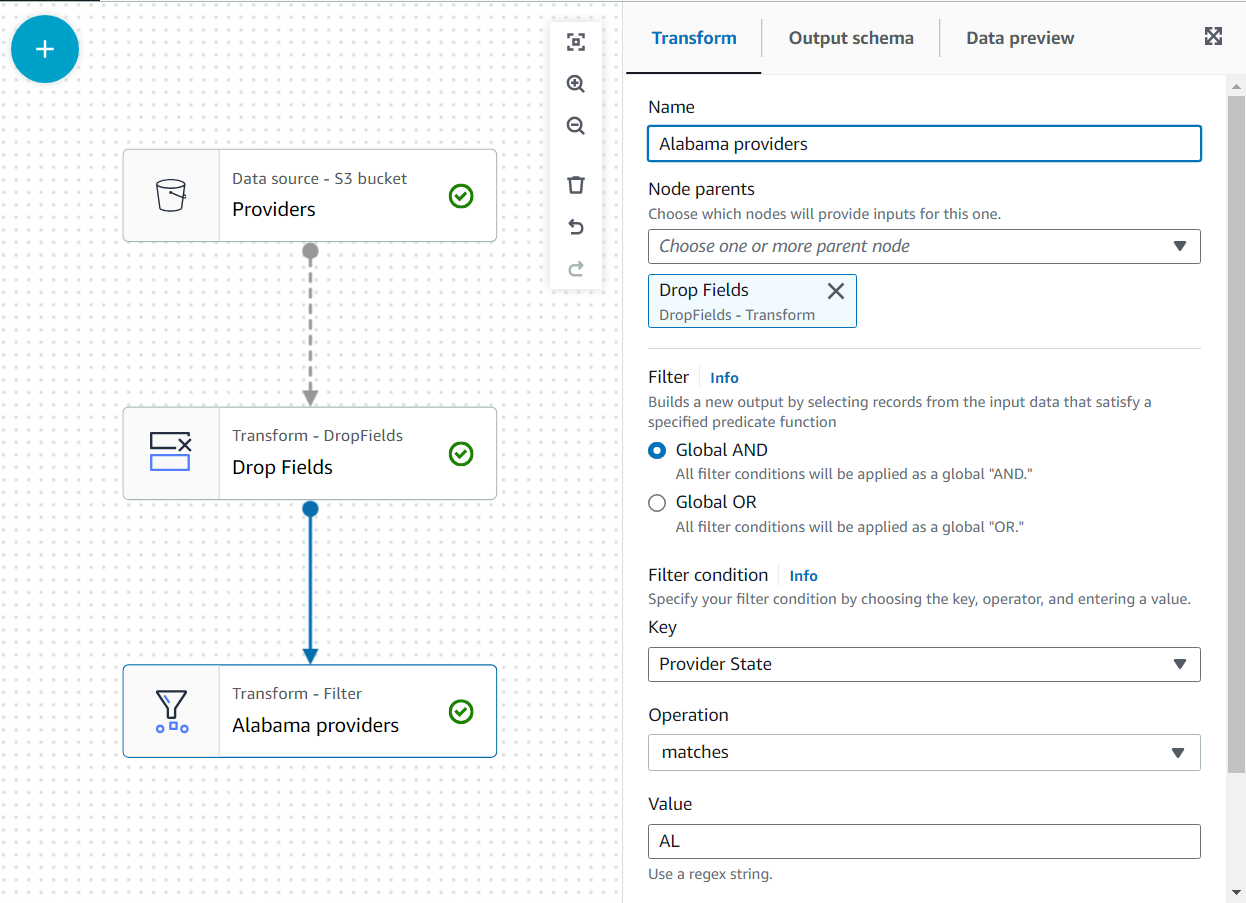
- दूसरा स्रोत (एक नया S3 स्रोत) जोड़ें और इसे नाम दें
Alabama claims. - प्रवेश हेतु एस3 यूआरएल, एक अलग ब्राउज़र टैब पर डेटाब्रू खोलें, नेविगेशन फलक में डेटासेट चुनें, और टेबल पर दिखाए गए स्थान को कॉपी करें अलबामा का दावा है (s3:// से शुरू होने वाले टेक्स्ट को कॉपी करें, संबंधित http लिंक को नहीं)। फिर विज़ुअल जॉब पर वापस, इसे इस रूप में पेस्ट करें एस3 यूआरएल; यदि यह सही है, तो आप इसमें देखेंगे आउटपुट स्कीमा सूचीबद्ध डेटा फ़ील्ड को टैब करें।
- सीएसवी प्रारूप का चयन करें और स्कीमा का अनुमान लगाएं जैसे आपने अन्य स्रोत के साथ किया था।
- इस स्रोत के एक बच्चे के रूप में, इसमें खोजें नोड्स जोड़ें के लिए मेनू
recipeऔर चुनें डेटा तैयार करने की विधि.
- इस नए नोड के गुणों में, इसे नाम दें
Claim cleanup recipeऔर वह रेसिपी और संस्करण चुनें जिसे आपने पहले प्रकाशित किया था। - आप यहां नुस्खा चरणों की समीक्षा कर सकते हैं और यदि आवश्यक हो तो परिवर्तन करने के लिए डेटाब्रू के लिंक का उपयोग कर सकते हैं।
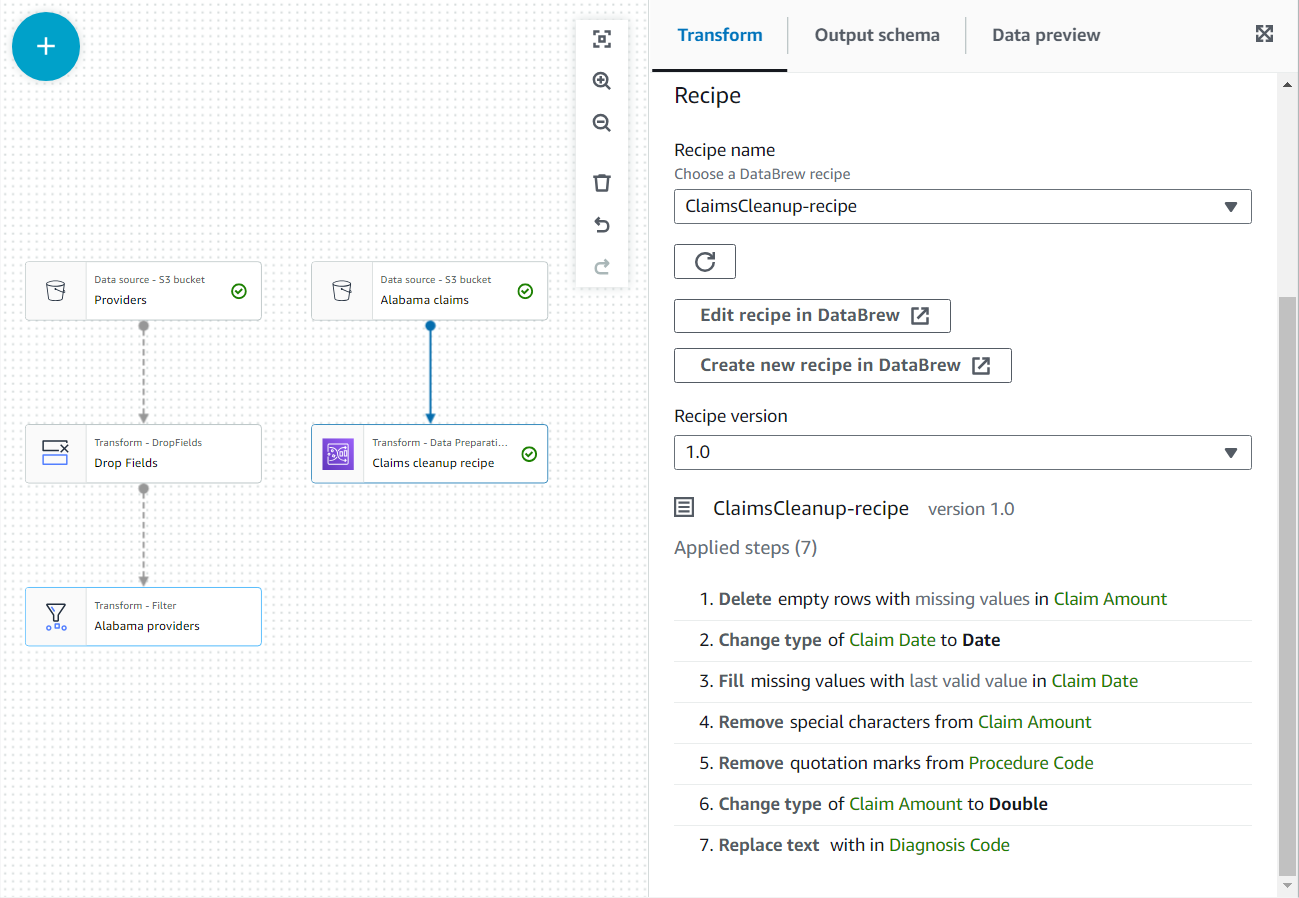
- एक जोड़ें जुडें नोड और दोनों का चयन करें अलबामा प्रदाता और सफाई व्यंजनों का दावा करें माता-पिता के रूप में.
- दोनों स्रोतों से प्रदाता आईडी के बराबर एक जुड़ने की शर्त जोड़ें।
- अंतिम चरण के रूप में, एक S3 नोड को लक्ष्य के रूप में जोड़ें (ध्यान दें कि जब आप खोजते हैं तो सूचीबद्ध पहला स्रोत है; सुनिश्चित करें कि आप उस संस्करण का चयन करें जो लक्ष्य के रूप में सूचीबद्ध है)।
- नोड कॉन्फ़िगरेशन में, डिफ़ॉल्ट प्रारूप JSON छोड़ें और एक S3 URL दर्ज करें जिस पर जॉब रोल को लिखने की अनुमति है।
इसके अलावा, डेटा आउटपुट को कैटलॉग में एक तालिका के रूप में उपलब्ध कराएं।
- में डेटा कैटलॉग अपडेट विकल्प अनुभाग, दूसरा विकल्प चुनें डेटा कैटलॉग में एक तालिका बनाएं और बाद के रन पर, स्कीमा को अपडेट करें और नए विभाजन जोड़ें, फिर एक डेटाबेस चुनें जिस पर आपको टेबल बनाने की अनुमति है।
- सौंपना
alabama_claimsनाम के रूप में और चुनें दावा दिनांक विभाजन कुंजी के रूप में (यह चित्रण उद्देश्यों के लिए है; इस तरह की एक छोटी तालिका को वास्तव में विभाजन की आवश्यकता नहीं होती है यदि आगे डेटा बाद में नहीं जोड़ा जाएगा)।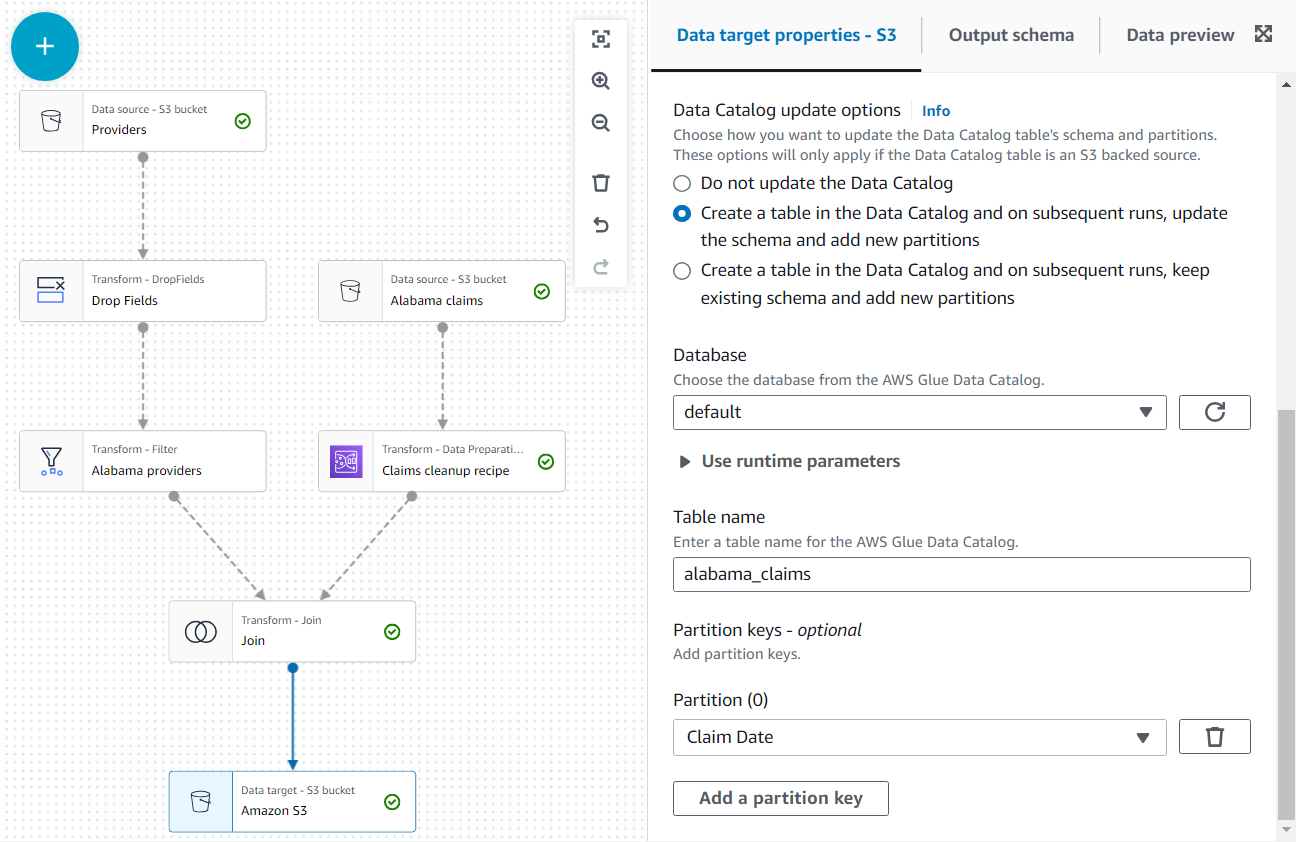
- अब आप कार्य को सहेज और चला सकते हैं.
- पर रन टैब पर, आप जॉब आईडी लिंक का उपयोग करके प्रक्रिया पर नज़र रख सकते हैं और विस्तृत जॉब मेट्रिक्स देख सकते हैं।
कार्य पूरा होने में कुछ मिनट लगने चाहिए.
- जब कार्य पूरा हो जाए, तो एथेना कंसोल पर जाएँ।
- तालिका खोजें
alabama_claimsआपके द्वारा चयनित डेटाबेस में और, संदर्भ मेनू का उपयोग करके, चुनें पूर्वावलोकन तालिका, जो टेबल पर एक सरल SELECT * SQL स्टेटमेंट चलाएगा।
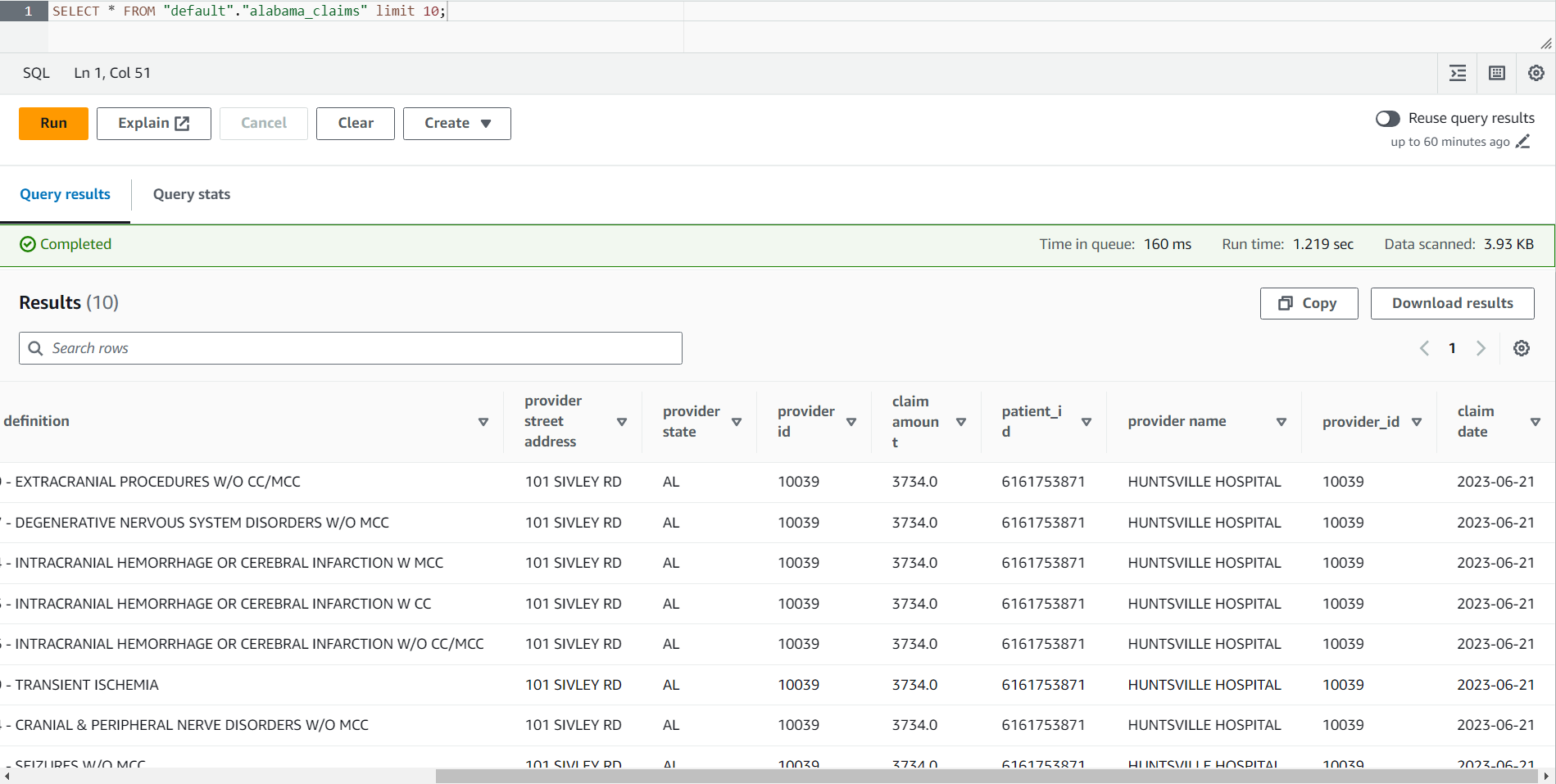
आप कार्य के परिणाम में देख सकते हैं कि डेटा को DataBrew रेसिपी द्वारा साफ़ किया गया था और AWS ग्लू स्टूडियो जॉइन द्वारा समृद्ध किया गया था।
अपाचे स्पार्क वह इंजन है जो AWS ग्लू स्टूडियो पर बनाई गई नौकरियों को चलाता है। इसके द्वारा उत्पादित इवेंट लॉग पर स्पार्क यूआई का उपयोग करके, आप जॉब प्लान और रन के बारे में अंतर्दृष्टि देख सकते हैं, जो आपको यह समझने में मदद कर सकता है कि आपका काम कैसा प्रदर्शन कर रहा है और संभावित प्रदर्शन बाधाएं। उदाहरण के लिए, बड़े डेटासेट पर इस कार्य के लिए, आप इसका उपयोग जुड़ने से पहले प्रदाता स्थिति को स्पष्ट रूप से फ़िल्टर करने के प्रभाव की तुलना करने के लिए कर सकते हैं, या यह पहचान सकते हैं कि क्या आप समानता में सुधार के लिए ऑटोबैलेंस ट्रांसफॉर्म जोड़ने से लाभ उठा सकते हैं।
डिफ़ॉल्ट रूप से, कार्य अपाचे स्पार्क ईवेंट लॉग को पथ के अंतर्गत संग्रहीत करेगा s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. नौकरियाँ देखने के लिए, आपको एक इतिहास सर्वर का उपयोग करके स्थापित करना होगा उपलब्ध विधियों में से एक.
क्लीन अप
यदि आपको अब इस समाधान की आवश्यकता नहीं है, तो आप Amazon S3 पर उत्पन्न फ़ाइलें, जॉब द्वारा बनाई गई तालिका, डेटाब्रू रेसिपी और AWS ग्लू जॉब को हटा सकते हैं।
निष्कर्ष
इस पोस्ट में, हमने दिखाया कि आप दिए गए इंटरैक्टिव संपादक का उपयोग करके एक रेसिपी बनाने के लिए AWS DataBrew का उपयोग कैसे कर सकते हैं और फिर AWS ग्लू स्टूडियो विज़ुअल ETL जॉब के हिस्से के रूप में प्रकाशित रेसिपी का उपयोग कर सकते हैं। हमने सामान्य कार्यों के कुछ उदाहरण शामिल किए हैं जिनकी आवश्यकता डेटा तैयार करने और एडब्ल्यूएस ग्लू कैटलॉग तालिकाओं में डेटा डालने के लिए होती है।
इस उदाहरण में विज़ुअल जॉब में एक ही रेसिपी का उपयोग किया गया है, लेकिन ईटीएल प्रक्रिया के विभिन्न हिस्सों में कई रेसिपी का उपयोग करना संभव है, साथ ही कई नौकरियों पर एक ही रेसिपी का पुन: उपयोग करना भी संभव है।
ये AWS ग्लू समाधान आपको प्रभावी ढंग से उन्नत ETL पाइपलाइन बनाने की अनुमति देते हैं जिनका निर्माण और रखरखाव करना आसान है, बिना कोई कोड लिखे। आप आज ही ऐसे समाधान बनाना शुरू कर सकते हैं जो दोनों उपकरणों को जोड़ते हैं।
लेखक के बारे में
 मिखाइल स्मिरनोव वह AWS ग्लू टीम में एक सीनियर सॉफ्टवेयर डेव इंजीनियर हैं और AWS ग्लू डेटाब्रू डेवलपमेंट टीम का हिस्सा हैं। काम के अलावा, उनकी रुचियों में गिटार बजाना सीखना और अपने परिवार के साथ यात्रा करना शामिल है।
मिखाइल स्मिरनोव वह AWS ग्लू टीम में एक सीनियर सॉफ्टवेयर डेव इंजीनियर हैं और AWS ग्लू डेटाब्रू डेवलपमेंट टीम का हिस्सा हैं। काम के अलावा, उनकी रुचियों में गिटार बजाना सीखना और अपने परिवार के साथ यात्रा करना शामिल है।
 गोंजालो हेरेरोस AWS ग्लू टीम में एक सीनियर बिग डेटा आर्किटेक्ट हैं। डबलिन, आयरलैंड में स्थित, वह ग्राहकों को AWS ग्लू पर आधारित बड़े डेटा समाधानों के साथ सफल होने में मदद करता है। अपने खाली समय में, वह बोर्ड गेम और साइकिल चलाना पसंद करते हैं।
गोंजालो हेरेरोस AWS ग्लू टीम में एक सीनियर बिग डेटा आर्किटेक्ट हैं। डबलिन, आयरलैंड में स्थित, वह ग्राहकों को AWS ग्लू पर आधारित बड़े डेटा समाधानों के साथ सफल होने में मदद करता है। अपने खाली समय में, वह बोर्ड गेम और साइकिल चलाना पसंद करते हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. ऑटोमोटिव/ईवीएस, कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- BlockOffsets. पर्यावरणीय ऑफसेट स्वामित्व का आधुनिकीकरण। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :हैस
- :है
- :नहीं
- $यूपी
- 10
- 100
- 12
- 15% तक
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- योग्य
- About
- स्वीकार्य
- स्वीकृत
- पहुँच
- लेखा
- कार्य
- वास्तविक
- जोड़ना
- जोड़ा
- जोड़ने
- इसके अलावा
- पता
- उन्नत
- बाद
- अलबामा
- सब
- अनुमति देना
- भी
- वीरांगना
- अमेज़ॅन वेब सेवा
- राशियाँ
- an
- विश्लेषकों
- और
- कोई
- अपाचे
- अपाचे स्पार्क
- आवेदन
- लागू करें
- हैं
- AS
- जुड़े
- At
- लेखक
- स्वत:
- स्वचालित
- उपलब्ध
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- वापस
- आधारित
- BE
- से पहले
- जा रहा है
- लाभ
- लाभ
- बड़ा
- बड़ा डेटा
- रिक्त
- मंडल
- बोर्ड खेल
- बुकमार्क
- के छात्रों
- लाता है
- ब्राउज़र
- निर्माण
- लेकिन
- by
- कर सकते हैं
- क्षमताओं
- मामला
- सूची
- कोशिकाओं
- केंद्रीकृत
- परिवर्तन
- परिवर्तन
- अक्षर
- बच्चा
- चुनाव
- चुनें
- दावा
- का दावा है
- कोड
- स्तंभ
- स्तंभ
- गठबंधन
- अ रहे है
- सामान्य
- तुलना
- पूरा
- घटकों
- कंप्यूटर
- शर्त
- विन्यास
- विचार करना
- होते हैं
- कंसोल
- प्रसंग
- बदलना
- परिवर्तित
- सही
- इसी
- लागत
- सका
- बनाना
- बनाया
- बनाना
- निर्माण
- रिवाज
- ग्राहक
- तिथि
- डेटा तैयारी
- डेटा संसाधन
- आँकड़े की गुणवत्ता
- डाटाबेस
- डेटासेट
- तारीख
- खजूर
- दिन
- सौदा
- तय
- निर्णय
- चूक
- दिखाना
- विवरण
- वांछित
- विस्तृत
- विवरण
- देव
- विकास
- विकास दल
- डीआईडी
- विभिन्न
- अलग
- वितरण
- do
- नहीं करता है
- कर
- डॉलर
- डबल
- बूंद
- डबलिन
- से प्रत्येक
- आसान
- संपादक
- प्रभाव
- प्रभावी रूप से
- सक्षम बनाता है
- समाप्त
- इंजन
- इंजीनियर
- समृद्ध
- समृद्ध
- दर्ज
- त्रुटि
- आवश्यक
- ईथर (ईटीएच)
- मूल्यांकन करें
- और भी
- कार्यक्रम
- प्रत्येक
- प्रतिदिन
- उदाहरण
- उदाहरण
- मौजूदा
- अतिरिक्त
- उद्धरण
- परिवार
- दूर
- विशेषताएं
- कुछ
- फ़ील्ड
- पट्टिका
- फ़ाइलें
- भरना
- फ़िल्टर
- छानने
- अंत में
- प्रथम
- पीछा किया
- निम्नलिखित
- के लिए
- प्रारूप
- से
- आगे
- Games
- उत्पन्न
- देना
- अधिक से अधिक
- है
- he
- मदद
- मदद करता है
- यहाँ उत्पन्न करें
- उसके
- इतिहास
- कैसे
- How To
- तथापि
- एचटीएमएल
- http
- HTTPS
- आई ए एम
- ID
- पहचान
- पहचान करना
- पहचान
- if
- प्रभाव
- में सुधार
- सुधार
- in
- शामिल
- शामिल
- सहित
- संकेत दिया
- निवेश
- अंतर्दृष्टि
- स्थापित
- उदाहरण
- एकीकृत
- एकीकरण
- इंटरैक्टिव
- ब्याज
- रुचियों
- इंटरफेस
- में
- शुरू की
- सहज ज्ञान युक्त
- आयरलैंड
- मुद्दों
- IT
- आईटी इस
- काम
- नौकरियां
- में शामिल होने
- में शामिल हो गए
- जेपीजी
- JSON
- केवल
- रखना
- कुंजी
- ज्ञान
- बड़ा
- बड़ा
- सबसे बड़ा
- पिछली बार
- बाद में
- ताज़ा
- सीख रहा हूँ
- छोड़ना
- पसंद
- संभावित
- LINK
- सूचीबद्ध
- भार
- स्थान
- तर्क
- लंबे समय तक
- बनाए रखना
- बनाना
- बनाता है
- मैन्युअल
- मैच
- मेडिकल
- मेन्यू
- तरीका
- तरीकों
- मेट्रिक्स
- मिनट
- लापता
- मॉनिटर
- अधिक
- विभिन्न
- चाहिए
- नाम
- नेविगेट करें
- पथ प्रदर्शन
- आवश्यकता
- जरूरत
- की जरूरत है
- नया
- नहीं
- नोड
- सूचना..
- अभी
- संख्या
- of
- on
- ONE
- केवल
- खुला
- ऑप्टिमाइज़ करें
- विकल्प
- ऑप्शंस
- or
- आदेश
- अन्य
- हमारी
- उत्पादन
- बाहर
- के ऊपर
- कुल
- फलक
- भाग
- भागों
- पथ
- प्रदर्शन
- प्रदर्शन
- अनुमति
- अनुमतियाँ
- योजना
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्ले
- संभव
- पद
- संभावित
- तैयारी
- पूर्वावलोकन
- पूर्वावलोकन
- प्रक्रिया
- प्रसंस्करण
- पैदा करता है
- परियोजना
- गुण
- बशर्ते
- प्रदाता
- प्रदाताओं
- प्रदान करता है
- प्रकाशन
- प्रकाशित करना
- प्रकाशित
- उद्देश्य
- प्रयोजनों
- गुणवत्ता
- उद्धरण
- वास्तव में
- उचित
- नुस्खा
- व्यंजन विधि
- को कम करने
- प्रतिबिंबित
- क्षेत्र
- पंजीकरण
- प्रासंगिक
- हटाना
- की जगह
- का अनुरोध किया
- अपेक्षित
- आवश्यकता
- क्रमश
- बाकी
- परिणाम
- परिणाम
- पुनः प्रयोग
- की समीक्षा
- भूमिका
- रन
- चलाता है
- वही
- सहेजें
- स्केल
- स्केलिंग
- Search
- दूसरा
- अनुभाग
- देखना
- देखकर
- चयनित
- अलग
- सेवाएँ
- सत्र
- सेट
- सेटिंग्स
- चाहिए
- पता चला
- दिखाया
- हस्ताक्षर
- महत्वपूर्ण
- सरल
- एक
- आकार
- छोटा
- So
- अब तक
- सॉफ्टवेयर
- समाधान
- समाधान ढूंढे
- कुछ
- स्रोत
- सूत्रों का कहना है
- अंतरिक्ष
- स्पार्क
- विशेष
- विशिष्ट
- विनिर्दिष्ट
- एसक्यूएल
- प्रारंभ
- शुरुआत में
- राज्य
- कथन
- आँकड़े
- कदम
- कदम
- भंडारण
- की दुकान
- सरल
- तार
- स्टूडियो
- आगामी
- सफल
- ऐसा
- उपयुक्त
- सारांश
- निश्चित
- कृत्रिम
- तालिका
- लेना
- लक्ष्य
- कार्य
- टीम
- परीक्षण किया
- कि
- RSI
- स्रोत
- राज्य
- उन
- फिर
- वहाँ।
- इसका
- तीन
- पहर
- सेवा मेरे
- आज
- साधन
- उपकरण
- ऊपर का
- ट्रैक
- बदालना
- परिवर्तन
- परिवर्तनों
- यात्रा का
- दो
- टाइप
- ui
- के अंतर्गत
- समझना
- अपडेट
- अद्यतन
- यूआरएल
- प्रयोग करने योग्य
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ताओं
- का उपयोग करता है
- का उपयोग
- सत्यापित करें
- मूल्य
- मान
- सत्यापित
- संस्करण
- देखें
- दिखाई
- करना चाहते हैं
- था
- तरीके
- we
- वेब
- वेब सेवाओं
- कुंआ
- थे
- कब
- कौन कौन से
- मर्जी
- साथ में
- बिना
- काम
- कामगार
- श्रमिकों
- वर्कफ़्लो
- होगा
- लिखना
- लिख रहे हैं
- इसलिए आप
- आपका
- जेफिरनेट
- ज़िप