Image par auteur
Les temps changent. Si vous voulez être un scientifique des données en 2023, vous devez ajouter plusieurs nouvelles compétences à votre liste, ainsi que la multitude de compétences existantes que vous devriez déjà maîtriser.
Pourquoi un ensemble de compétences aussi étendu ? Une partie du problème est le glissement de la portée du travail. Personne ne sait ce qu'est un data scientist, ni ce qu'il doit faire, et encore moins votre futur employeur. Ainsi, tout ce qui contient des données reste bloqué dans la catégorie de la science des données pour que vous puissiez vous en occuper.
Vous devez savoir comment nettoyer, transformer, analyser statistiquement, visualiser, communiquer et prédire les données. Non seulement cela, mais une nouvelle technologie (ou une technologie qui a récemment atteint le grand public) pourrait également être ajoutée à vos responsabilités professionnelles.
Dans cet article, je décomposerai les 19 principales compétences que vous devez connaître en 2023 pour être un scientifique des données.
Voici un aperçu des dix plus importants.
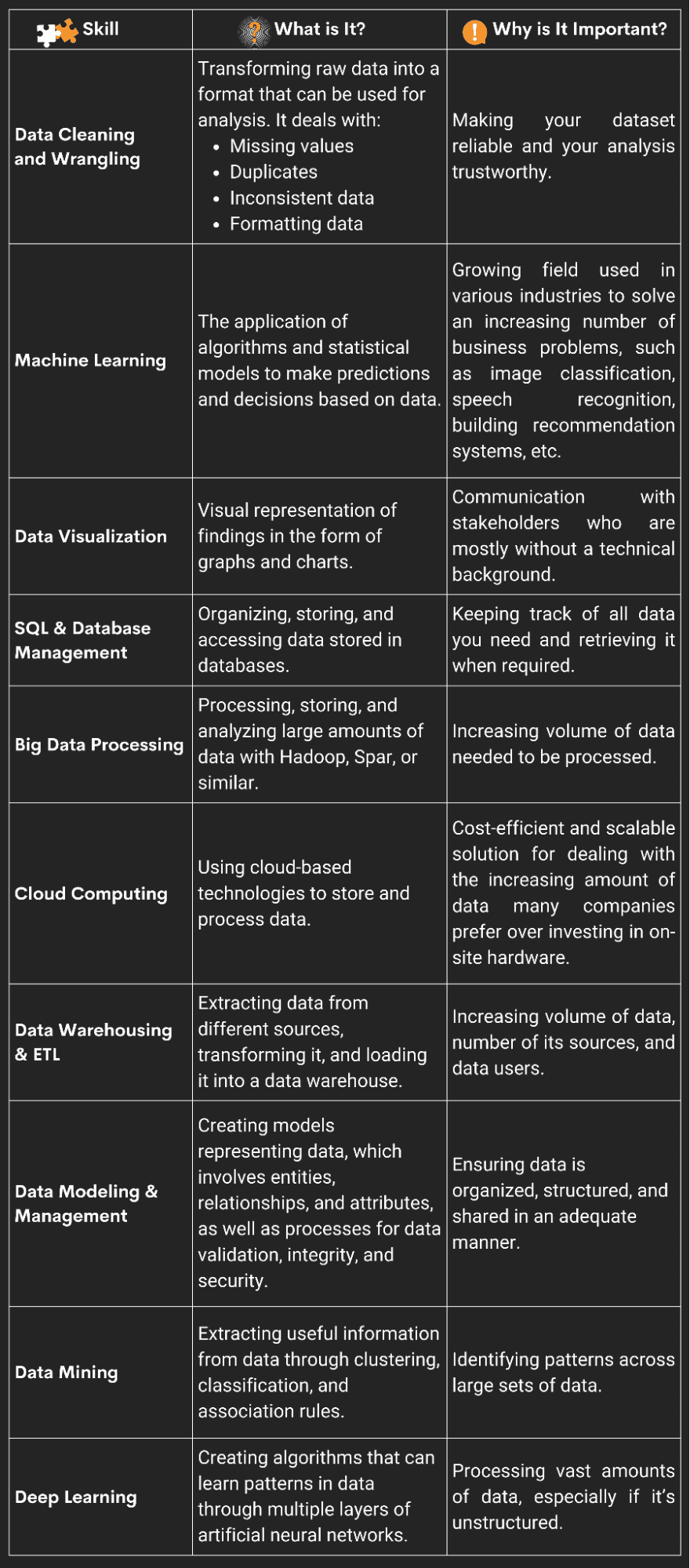
Image par auteur
Ces compétences vous aideront à décrocher un emploi, à décrocher un entretien, à garder une longueur d'avance et à négocier cette promotion. Dans chaque section, je résumerai brièvement ce qu'est chaque compétence, pourquoi elle est importante et je proposerai quelques endroits pour apprendre ces compétences.
Alors que c'est ne sauraient 80 % du travail d'un data scientist, le nettoyage et la manipulation des données restent l'une des compétences les plus importantes qu'un data scientist puisse maîtriser en 2023.
Qu'est-ce que le nettoyage et la manipulation des données ?
Le nettoyage et le traitement des données sont les processus de transformation des données brutes dans un format pouvant être utilisé pour l'analyse. Cela implique de gérer les valeurs manquantes, de supprimer les doublons, de traiter les données incohérentes et de formater les données de manière à ce qu'elles soient prêtes pour l'analyse.
Le nettoyage des données consiste généralement à se débarrasser des valeurs incorrectes/inexactes, à remplir les blancs, à trouver des doublons et à s'assurer que votre ensemble de données est aussi impeccable et fiable que prévu. Le disputer (ou le munging, le masser ou tout autre verbe étrange comme ça) signifie le mettre dans une forme analysable. Vous le convertissez ou le mappez dans un autre format plus facile à regarder.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
Demandez à n'importe quel scientifique des données ce qu'il fait, et l'une des premières choses qu'il mentionnera sera le nettoyage et la manipulation des données. Les données n'arrivent jamais entre vos mains sous une forme agréable, propre et analysable, il est donc très important de savoir comment les ranger.
La possibilité de nettoyer et d'embrouiller les données garantit que vos résultats d'analyse sont fiables et permet d'éviter de tirer des conclusions erronées.
Où pouvez-vous apprendre cette compétence clé ?
Il existe de nombreuses options intéressantes pour apprendre le nettoyage et la manipulation des données. Harvard propose une cours sur EdX. Vous pouvez également vous entraîner par vous-même en nettoyant et en traitant des ensembles de données bruts gratuits tels que Common Crawl, des données d'exploration Web composées de plus de 50 milliards de pages Web (ici), ou les données météorologiques du Brésil (ici).
Non, ce n'est pas qu'un mot à la mode ! L'apprentissage automatique est une compétence très importante que tout futur data scientist doit connaître.
Qu'est-ce que l'apprentissage par machine?
L'apprentissage automatique est l'application d'algorithmes et de modèles statistiques pour faire des prédictions et des décisions basées sur des données.
C'est un sous-domaine de l'intelligence artificielle qui permet aux ordinateurs d'améliorer leurs performances sur une tâche spécifique en apprenant à partir de données, sans être explicitement programmés. Cela aide à l'automatisation. Vous le trouverez dans n'importe quelle industrie.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
Vous devez connaître l'apprentissage automatique en 2023, car il s'agit d'un domaine en croissance rapide qui est devenu un outil crucial pour résoudre des problèmes complexes et faire des prédictions dans diverses industries.
Les algorithmes d'apprentissage automatique peuvent être utilisés pour classer les images, reconnaître la parole, effectuer un traitement du langage naturel et créer des systèmes de recommandation. Vous aurez du mal à trouver une industrie qui ne fait pas (ou ne veut pas) faire ces tâches assistées par ML.
La maîtrise de l'apprentissage automatique permet à un scientifique des données d'extraire des informations précieuses à partir d'ensembles de données volumineux et complexes et de développer des modèles prédictifs qui peuvent conduire à de meilleures décisions commerciales.
Où pouvez-vous apprendre cette compétence clé ?
Nous avons un référentiel de plus de trente projets d'apprentissage automatique sur ScrataScratch pour montrer cette compétence sur votre CV. TensorFlow a également un ensemble d'excellentes ressources gratuites pour apprendre l'apprentissage automatique.

Image par auteur
Cette compétence est assez explicite. Lorsque vous analysez des chiffres, les principales parties prenantes voudront comprendre vos résultats avec de jolis graphiques et tableaux.
Qu'est-ce que la visualisation de données ?
La visualisation des données est la création de tableaux, de graphiques et d'autres graphiques pour faciliter la compréhension des données. Vous prenez les chiffres que vous venez de nettoyer, de disputer ou de prédire et vous les mettez dans une sorte de format visuel, soit pour communiquer les tendances avec les autres, soit pour rendre les tendances plus faciles à repérer.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
En 2023, être capable de visualiser les données est crucial pour un data scientist. C'est comme avoir un super pouvoir secret pour découvrir des modèles et des tendances cachés dans les données qui pourraient ne pas être évidents à première vue. Et la meilleure partie ? Vous pouvez partager vos découvertes avec d'autres d'une manière à la fois engageante et mémorable. En tant que data scientist, vous travaillerez avec des groupes de niveaux d'expérience différents, mais une image est beaucoup plus facile à comprendre qu'une rangée de chiffres.
Donc, si vous voulez être un scientifique des données capable de communiquer efficacement vos idées et vos découvertes, il est important de maîtriser l'art de la visualisation des données.
Où pouvez-vous apprendre cette compétence clé ?
Voici une liste d'endroits gratuits pour apprendre les données à savoir.
SQL est un langage de requête structuré. Les scientifiques des données utilisent SQL pour travailler avec des bases de données SQL, gérer des bases de données et effectuer des tâches de stockage de données.
Qu'est-ce que SQL et la gestion de base de données ?
SQL est un langage très populaire qui vous permet d'accéder et de manipuler des données structurées. Cela va de pair avec la gestion de la base de données, qui se fait couramment en SQL. La gestion de base de données est essentiellement la façon dont vous pouvez organiser, stocker et récupérer des données à partir d'un emplacement. Les bases de données SQL font partie des meilleures technologies back-end apprendre en 2023, donc ce n'est pas seulement pour la science des données.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
En tant que data scientist, vous devez garder une trace de toutes les données, vous assurer qu'elles sont organisées et les récupérer lorsque quelqu'un en a besoin. C'est ce que SQL et la gestion de base de données vous permettent de faire.
Où pouvez-vous apprendre cette compétence clé ?
Coursera a une tonne d'excellents cours de gestion de base de données et d'administration à bon prix que vous pouvez essayer. Vous pouvez également obtenir un aperçu de certains Questions d'entretien SQL ici, ce qui peut être utile pour tester vos connaissances.
Le big data est un mot à la mode, oui, mais c'est aussi un vrai concept - Oracle définit comme « des données qui contiennent une plus grande variété, arrivant en volumes croissants et avec plus de vitesse », ou des données avec les trois V.
Qu'est-ce que le traitement du Big Data ?
Le traitement des mégadonnées est la capacité de traiter, de stocker et d'analyser de grandes quantités de données à l'aide de technologies telles que Hadoop et Spark.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
En 2023, la capacité à traiter le big data est critique pour les data scientists. Le volume de données générées continue de croître à un rythme exponentiel, et être capable de gérer et d'analyser efficacement ces données est essentiel pour prendre des décisions éclairées et obtenir des informations précieuses. Les scientifiques des données qui ont une compréhension approfondie des techniques de traitement du Big Data seront en mesure de travailler facilement avec de grands ensembles de données et de tirer le meilleur parti des informations qu'ils contiennent.
De plus, grâce à son buzz-wordiness, il ne fait jamais de mal de frapper "big data" sur votre CV.
Où pouvez-vous l'apprendre ?
J'aime Simplilearn Série de tutoriels YouTube sur cette notion.

Image par auteur
C'est drôle - à mesure que de plus en plus de produits et de services migrent vers le cloud, le cloud computing devient une exigence professionnelle pour à peu près tous les emplois techniques, qu'il s'agisse de DevOps ou un data scientist.
Qu'est-ce que le Cloud Computing?
Le cloud computing est l'utilisation de technologies et de plates-formes basées sur le cloud comme AWS, Azure ou Google Cloud pour stocker et traiter des données. C'est un peu comme avoir une salle de stockage virtuelle à laquelle vous pouvez accéder de n'importe où et à tout moment. Au lieu de stocker des données et des ressources informatiques sur des machines ou des serveurs locaux, le cloud computing permet aux organisations - et aux data scientists - d'accéder à ces ressources via Internet.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
Comme je ne cesse de le souligner, la quantité de données avec lesquelles vous êtes censé travailler en tant que data scientist augmente. De plus en plus d'entreprises le placeront dans le cloud plutôt que de le gérer sur site. Il devient de plus en plus important de pouvoir stocker et traiter ces données de manière évolutive et efficace.
Le cloud computing fournit une solution efficace pour cela, permettant aux scientifiques des données d'accéder à de grandes quantités de ressources informatiques et de stockage de données sans avoir besoin de matériel et d'infrastructure coûteux.
Où pouvez-vous l'apprendre ?
La bonne nouvelle est que parce que les entreprises possèdent divers clouds, beaucoup d'entre elles ont tout intérêt à vous en parler gratuitement, vous apprenez donc à utiliser les leurs. Google, Microsoftet la Amazon ont tous d'excellentes ressources de cloud computing.
« Attendez, n'avons-nous pas seulement couvert les bases de données ? Qu'est-ce qu'un entrepôt de données ? » Je vous entends demander.
Je te comprends. Parfois, on a l'impression que la compétence la plus critique en science des données consiste à garder tous les acronymes et le jargon corrects.
Qu'est-ce que l'entreposage de données et l'ETL ?
Commençons par différencier les entrepôts de données des bases de données.
Les entrepôts stockent les données actuelles et historiques de plusieurs systèmes, tandis que les bases de données stockent les données actuelles nécessaires pour alimenter un projet. Une base de données stocke les données actuelles nécessaires pour alimenter une application, tandis qu'un entrepôt de données stocke les données actuelles et historiques d'un ou plusieurs systèmes dans un schéma prédéfini et fixe pour analyser les données.
En bref, vous utiliseriez un entrepôt de données pour les données de nombreux projets différents, alors qu'une base de données stocke principalement les données d'un seul projet.
ETL est un processus qui implique l'entreposage de données, abréviation d'extraction, de transformation et de chargement. Un outil ETL extraira les données de tous les systèmes de source de données que vous souhaitez, les transformera dans la zone de préparation (généralement en les nettoyant, les manipulant ou les "munging"), puis les chargera dans un entrepôt de données.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
J'ai l'impression d'avoir répété ce point dans chaque compétence, mais les données augmentent. Les entreprises en ont soif et elles s'attendent à ce que vous le gériez. Savoir comment gérer les données dans des pipelines constructibles est essentiel.
Où pouvez-vous l'apprendre ?
Je recommande d'apprendre à faire un ETL approprié avec un langage spécifique, comme SQL ou Python. Datacamp a un bon avec Python. Microsoft exécute un plus tutoriel de niveau intermédiaire passer par une option SQL.
Chaque data scientist est un spécialiste des modèles. Je ne parle pas de Giselle Bundchen. Je veux dire créer un modèle de la façon dont les données sont stockées et organisées dans un système.
Qu'est-ce que la modélisation et la gestion des données ?
La modélisation et la gestion des données sont le processus de création de modèles mathématiques pour représenter les données, ainsi que la gestion des données pour maintenir leur qualité, leur précision et leur utilité.
Cela implique de définir des entités de données, des relations et des attributs, ainsi que de mettre en œuvre des processus de validation, d'intégrité et de sécurité des données.
En termes plus simples, la modélisation des données signifie essentiellement que vous créez un plan pour la façon dont les données sont organisées et connectées dans les systèmes de votre employeur. Vous pouvez y penser comme la rédaction d'un plan d'une maison. Tout comme un plan montre les différentes pièces et comment elles sont connectées, la modélisation des données montre comment différentes informations sont liées et connectées les unes aux autres.
Cela permet de garantir que les données sont stockées et utilisées de manière cohérente et efficace.
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
En tant que data scientist, vous serez responsable de vous assurer que les données sont organisées et structurées de manière accessible. La modélisation et la gestion des données vous aident à travailler avec les données, à les partager, à vous assurer qu'elles sont exactes et à prendre des décisions en fonction de celles-ci.
Où pouvez-vous l'apprendre ?
Microsoft a une bonne l'intro sur leur blog, à peine une demi-heure et très apprécié. C'est un bon point de départ.

Image de l'auteur
De nombreux termes de la science des données viennent d'être volés à d'autres professions, comme la modélisation et l'exploitation minière. Voyons ce que cela signifie et pourquoi c'est important.
Qu'est-ce que l'exploration de données?
L'exploration de données est le processus d'extraction d'informations utiles à partir de données grâce à des techniques telles que le regroupement, la classification et les règles d'association. Vous parcourez le véritable flot de données pour trouver des pépites d'or utiles. (Peut-être que le panoramique des données aurait été un meilleur nom pour cette compétence !)
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
Imaginez : vous êtes un data scientist en 2023. Vous disposez de données provenant de dix mille sources différentes. Quelle compétence utilisez-vous pour identifier des modèles dans toutes ces fontaines de données ?
C'est de l'exploration de données.
Où pouvez-vous l'apprendre ?
L'exploration de données est généralement couverte par des cours qui couvrent le Big Data ou l'analyse de données, car il s'agit d'un élément assez essentiel de ces deux compétences. EdX offre un couple d'options pour apprendre l'exploration de données.
L'apprentissage en profondeur est subtilement différent de l'apprentissage automatique ! L'apprentissage en profondeur est un sous-domaine de l'apprentissage automatique.
Qu'est-ce que le Deep Learning?
L'apprentissage en profondeur est une facette de l'apprentissage automatique qui se concentre sur la création d'algorithmes capables d'apprendre des modèles de données à travers plusieurs couches de réseaux de neurones artificiels. (Les réseaux de neurones artificiels, soit dit en passant, sont un type d'algorithme d'apprentissage automatique modélisé pour être similaire à la structure et à la fonction du cerveau humain.)
Pourquoi est-ce important de devenir Data Scientist en 2023 ?
L'intelligence artificielle devient plus sophistiquée en 2023. Il ne suffit pas de connaître les bases de l'IA et du ML - vous devez également être familiarisé avec les technologies de pointe, car elles ne seront plus à la pointe demain. L'apprentissage en profondeur était nouveau il y a quelques années, et maintenant c'est une nécessité.
Les scientifiques des données devront utiliser l'apprentissage en profondeur lorsque les entreprises auront accès à une très grande quantité de données. Il est utilisé pour le traitement d'images et de vidéos ou les applications de vision par ordinateur.
Où pouvez-vous l'apprendre?
J'aime Tutoriel de Simplilearn comme point de départ.
Il existe de nombreuses technologies et techniques émergentes qu'il est utile de connaître. Celles-ci sont soit encore plus avancées, comme les réseaux antagonistes génératifs, soit davantage basées sur les compétences non techniques, comme la narration de données, ou spécialisées dans un domaine comme la prévision de séries chronologiques. Je vais les résumer brièvement ici :
- Traitement du langage naturel (PNL): Un sous-domaine de l'IA qui gère le traitement et la compréhension du langage humain. Les chatbots l'utilisent.
- Analyse et prévision des séries chronologiques: L'étude des données au fil du temps et l'utilisation de modèles statistiques pour faire des prédictions sur les événements futurs. Vous pouvez utiliser cette compétence pour effectuer une analyse des ventes ou des revenus.
- Conception expérimentale et tests A/B: Le processus de conception et de réalisation d'expériences contrôlées pour tester des hypothèses et prendre des décisions basées sur des données.
- Scénario de données : La capacité de communiquer efficacement les informations et les résultats des données aux parties prenantes non techniques. De plus en plus d'acteurs s'intéressent à la why derrière les décisions basées sur les données, c'est donc essentiel.
- Réseaux Génératifs d'Adversariat (GAN): Un type d'architecture d'apprentissage en profondeur où deux réseaux de neurones sont entraînés à travailler ensemble pour générer de nouvelles données qui ressemblent à un ensemble de données donné.
- Apprentissage par transfert : Une technique d'apprentissage automatique dans laquelle un modèle est pré-entraîné sur une tâche et affiné sur une tâche connexe, améliorant les performances et réduisant la quantité de données d'apprentissage nécessaires. Les petites entreprises qui disposent de ressources plus limitées trouveront cela utile.
- Apprentissage automatique automatisé (AutoML) : L'invention concerne une méthode d'automatisation du processus de sélection, de formation et de déploiement de modèles d'apprentissage automatique.
- Réglage des hyperparamètres : Une autre sous-catégorie de ML. Il s'agit du processus d'optimisation des performances d'un modèle d'apprentissage automatique en ajustant les paramètres qui ne sont pas appris à partir des données, tels que le taux d'apprentissage ou le nombre de couches cachées.
- IA explicable (XAI): Une branche de l'IA axée sur la création d'algorithmes et de modèles transparents et interprétables, afin que leurs processus de prise de décision puissent être compris par les humains. Encore une fois, aider les parties prenantes à comprendre ce qui se passe.
Si vous voulez être un data scientist en 2023, ces 19 compétences sont absolument essentielles. La très bonne nouvelle est que bon nombre de ces compétences peuvent être apprises en autodidacte, tandis que d'autres peuvent être acquises tout en travaillant dans un rôle de niveau plus subalterne comme un analyste de données ou d'affaires.
Quelques façons d'apprendre :
- Vérifiez toujours YouTube. Il existe de nombreuses ressources gratuites et complètes. J'en ai énuméré quelques-unes ici, mais il existe pratiquement une infinité de vidéos.
- Des plateformes comme Coursera et EdX ont souvent des séries de conférences
- Nous avons plus d'un millier de vraies questions d'entretien sur lesquelles nous exercer, à la fois basé sur le codage ainsi que les non codant. Nous vous proposons également exemples de projets de données.
Profitez du voyage d'apprentissage de ces compétences pour devenir un scientifique des données en 2023.
Nate Rosidi est data scientist et en stratégie produit. Il est également professeur adjoint enseignant l'analytique et fondateur de StrataScratch, une plate-forme aidant les data scientists à préparer leurs entretiens avec de vraies questions d'entretien posées par les meilleures entreprises. Connectez-vous avec lui sur Twitter : StrataScratch or LinkedIn.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/04/top-19-skills-need-know-2023-data-scientist.html?utm_source=rss&utm_medium=rss&utm_campaign=top-19-skills-you-need-to-know-in-2023-to-be-a-data-scientist
- :est
- $UP
- 2023
- a
- capacité
- Capable
- Qui sommes-nous
- à propos de ça
- absolument
- accès
- accessible
- précision
- Avec cette connaissance vient le pouvoir de prendre
- Acronymes
- à travers
- ajoutée
- Avancée
- contradictoire
- devant
- AI
- algorithme
- algorithmes
- Tous
- Permettre
- permet
- déjà
- Amazon
- montant
- quantités
- selon une analyse de l’Université de Princeton
- analytique
- il analyse
- ainsi que les
- et infrastructure
- Une autre
- de n'importe où
- Application
- applications
- architecture
- SONT
- Réservé
- en arrivant
- Art
- article
- artificiel
- intelligence artificielle
- réseaux de neurones artificiels
- AS
- Association
- At
- attributs
- automatiser
- Automation
- AutoML
- AWS
- Azure
- backend
- basé
- En gros
- Basics
- BE
- car
- devenez
- devient
- devenir
- derrière
- va
- LES MEILLEURS
- Améliorée
- Big
- Big Data
- Milliards
- Blog
- Cerveau
- Branche
- Pause
- brièvement
- la performance des entreprises
- by
- CAN
- Catégories
- en changeant
- Charts
- Chatbots
- vérifier
- classification
- Classer
- Nettoyage
- le cloud
- le cloud computing
- regroupement
- COM
- Venir
- Commun
- communément
- communiquer
- Sociétés
- complexe
- composant
- composé
- complet
- ordinateur
- Vision par ordinateur
- Applications de vision par ordinateur
- ordinateurs
- informatique
- concept
- conduite
- NOUS CONTACTER
- connecté
- cohérent
- contient
- continue
- contrôlée
- convertir
- pourriez
- Coursera
- cours
- couverture
- couvert
- engendrent
- La création
- création
- critique
- crucial
- Courant
- courbe
- Coupe
- données
- Analyse de Donnée
- data mining
- informatique
- science des données
- Data Scientist
- ensemble de données
- ensembles de données
- stockage de données
- visualisation de données
- entrepôt de données
- entrepôts de données
- Base de données
- bases de données
- ensembles de données
- affaire
- traitement
- La prise de décision
- décisions
- profond
- l'apprentissage en profondeur
- définir
- déployer
- Conception
- conception
- développer
- différent
- différencier
- Ne fait pas
- down
- tiré
- motivation
- doublons
- chacun
- plus facilement
- même
- Edge
- edx
- Efficace
- de manière efficace
- efficace
- non plus
- permet
- engageant
- assez
- assurer
- Assure
- entités
- essential
- Ether (ETH)
- Pourtant, la
- événements
- Chaque
- existant
- attendre
- attendu
- d'experience
- exponentiel
- les
- extrait
- familier
- few
- champ
- Trouvez
- trouver
- Prénom
- fixé
- inondation
- concentré
- se concentre
- Pour
- le format
- fondateur
- Gratuit
- de
- fonction
- drôle
- avenir
- gagner
- GAN
- générer
- généré
- génératif
- réseaux accusatoires génératifs
- obtenez
- obtention
- donné
- Résumé
- Go
- Goes
- Or
- Bien
- Google Cloud
- graphique
- graphiques
- l'
- plus grand
- Groupes
- Croître
- Croissance
- Hadoop
- Half
- main
- manipuler
- Poignées
- Maniabilité
- Mains
- EN COURS
- Matériel
- harvard
- Vous avez
- ayant
- entendre
- vous aider
- aider
- aide
- ici
- caché
- Soulignant
- très
- historique
- Villa
- Comment
- How To
- HTTPS
- humain
- Les êtres humains
- Avide
- i
- MAUVAIS
- identifier
- image
- satellite
- la mise en œuvre
- important
- améliorer
- l'amélioration de
- in
- croissant
- de plus en plus
- secteurs
- industrie
- d'information
- Actualités
- Infrastructure
- idées.
- plutôt ;
- intégrité
- Intelligence
- intérêt
- Internet
- Interview
- questions d'interview
- Interviews
- IT
- SES
- jargon
- Emploi
- chemin
- KDnuggetsGenericName
- XNUMX éléments à
- en gardant
- ACTIVITES
- Genre
- Savoir
- connaissance
- spécialisées
- Transport routier
- langue
- gros
- poules pondeuses
- APPRENTISSAGE
- savant
- apprentissage
- Cours magistral
- Allons-y
- niveaux
- comme
- Listé
- charge
- locales
- Location
- love
- click
- machine learning
- Les machines
- Courant dominant
- maintenir
- a prendre une
- FAIT DU
- Fabrication
- gérer
- gestion
- manipuler
- manière
- de nombreuses
- Localisation
- maître
- mathématique
- Matière
- compte
- veux dire
- méthode
- Microsoft
- pourrait
- Mines
- manquant
- ML
- modèle
- modélisation statistique
- numériques jumeaux (digital twin models)
- PLUS
- (en fait, presque toutes)
- Bougez
- plusieurs
- prénom
- Nature
- Langage naturel
- Traitement du langage naturel
- Besoin
- nécessaire
- besoin
- Besoins
- réseaux
- Neural
- les réseaux de neurones
- Nouveauté
- nouvelles
- nlp
- non technique
- roman
- nombre
- numéros
- évident
- of
- code
- Offres Speciales
- on
- ONE
- l'optimisation
- Option
- Options
- oracle
- organisations
- Organisé
- Autre
- Autres
- autrement
- vue d'ensemble
- propre
- paramètres
- partie
- motifs
- effectuer
- performant
- en particulier pendant la préparation
- image
- pièces
- Place
- Des endroits
- plateforme
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Beaucoup
- Point
- Populaire
- power
- pratiquement
- pratique
- prévoir
- prédit
- Prédictions
- Préparer
- assez
- Aperçu
- Problème
- d'ouvrabilité
- processus
- les process
- traitement
- Produit
- Produits
- Produits et services
- Professeur
- programmé
- Projet
- projets
- promotion
- correct
- fournit
- mettre
- Python
- qualité
- fréquemment posées
- rapidement
- Tarif
- plutôt
- raw
- les données brutes
- RE
- atteint
- solutions
- réal
- récemment
- reconnaître
- recommander
- Recommandation
- réduire
- se réfère
- en relation
- Les relations
- enlever
- répété
- dépôt
- représentent
- conditions
- exigence
- Ressemble
- Resources
- responsabilités
- responsables
- Résultats
- CV
- de revenus
- Débarrasser
- Rôle
- Salle
- Chambres
- liste
- RANGÉE
- s
- vente
- évolutive
- Sciences
- Scientifique
- scientifiques
- portée
- secret
- Section
- sécurité
- la sélection
- Série
- Services
- set
- Sets
- plusieurs
- Forme
- Partager
- Shorts
- devrait
- montrer
- Spectacles
- similaires
- depuis
- unique
- compétence
- compétences
- faibles
- se glisser
- So
- sur mesure
- Résoudre
- quelques
- Quelqu'un
- sophistiqué
- Identifier
- Sources
- Spark
- spécialiste
- spécialisé
- groupe de neurones
- discours
- Spot
- SQL
- mise en scène
- parties prenantes
- Commencer
- Commencez
- statistique
- rester
- collage
- Encore
- storage
- Boutique
- stockée
- STORES
- storytelling
- droit
- de Marketing
- structure
- structuré
- Étude
- tel
- résumé
- Super
- superpuissance
- combustion propre
- Système
- Prenez
- prise
- parlant
- Tâche
- tâches
- Enseignement
- techniques
- Les technologies
- Technologie
- Dix
- tensorflow
- conditions
- tester
- Essais
- qui
- Les
- Les bases
- les informations
- leur
- Les
- Là.
- Ces
- des choses
- trois
- Avec
- fiable
- Des séries chronologiques
- à
- ensemble
- demain
- trop
- outil
- top
- suivre
- qualifié
- Formation
- Transformer
- transformer
- communication
- Trends
- digne de confiance
- tutoriel
- typiquement
- comprendre
- compréhension
- compris
- utilisé
- informations utiles
- d'habitude
- validation
- Précieux
- Valeurs
- variété
- divers
- Vaste
- Rapidité
- Vidéo
- Vidéos
- Salle de conférence virtuelle
- vision
- visualisation
- le volume
- volumes
- Entrepots
- Entreposage
- Façon..
- façons
- Météo
- web
- WELL
- Quoi
- que
- qui
- tout en
- WHO
- sera
- comprenant
- sans
- activités principales
- travailler ensemble
- de travail
- pourra
- années
- Votre
- Youtube
- zéphyrnet