L'environnement d'exécution Amazon EMR pour Apache Spark est un environnement d'exécution aux performances optimisées pour Apache Spark qui est 100 % compatible avec l'API open source Apache Spark. Avec Amazon DME version 6.9.0, le runtime EMR pour Apache Spark prend en charge la version Spark équivalente 3.3.0.
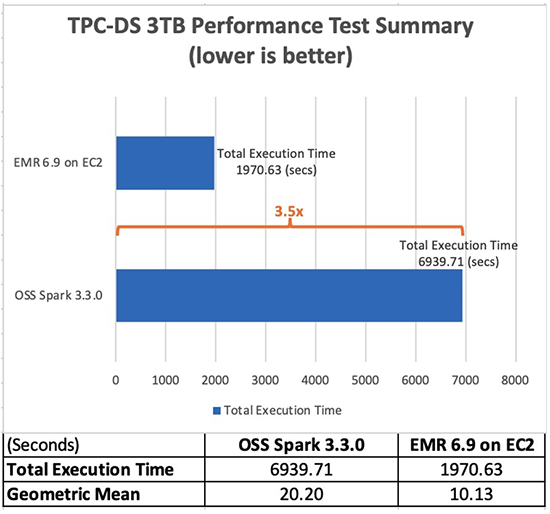
Avec Amazon EMR 6.9.0, vous pouvez désormais exécuter vos applications Apache Spark 3.x plus rapidement et à moindre coût sans avoir besoin de modifier vos applications. Dans nos tests d'évaluation des performances, dérivés des tests de performances TPC-DS à l'échelle de 3 To, nous avons constaté que le runtime EMR pour Apache Spark 3.3.0 fournit une amélioration des performances 3.5 fois (en utilisant le runtime total) en moyenne par rapport à l'open source Apache Spark 3.3.0. XNUMX.
Dans cet article, nous analysons les résultats de nos tests de référence en exécutant une application TPC-DS sur Apache Spark open source puis sur Amazon EMR 6.9, qui est livré avec un environnement d'exécution Spark optimisé compatible avec Spark open source. Nous passons en revue une analyse détaillée des coûts et fournissons enfin des instructions étape par étape pour exécuter le benchmark.
Résultats observés
Pour évaluer les améliorations de performances, nous avons utilisé un utilitaire de test de performances Spark open source dérivé de la boîte à outils de test de performances TPC-DS. Nous avons exécuté les tests sur un cluster EMR c5d.9xlarge à sept nœuds (six nœuds principaux et un nœud principal) avec le runtime EMR pour Apache Spark, et un deuxième cluster autogéré à sept nœuds sur Cloud de calcul élastique Amazon (Amazon EC2) avec la version open source équivalente de Spark. Nous avons exécuté les deux tests avec des données dans Service de stockage simple Amazon (Amazon S3).
L'allocation dynamique des ressources (DRA) est une excellente fonctionnalité à utiliser pour différentes charges de travail. Cependant, pour un exercice d'analyse comparative où nous comparons deux plates-formes uniquement sur la performance, et les volumes de données de test ne changent pas (3 To dans notre cas), nous pensons qu'il est préférable d'éviter la variabilité afin d'effectuer une comparaison de pommes à pommes. Lors de nos tests dans Spark open source et Amazon EMR, nous avons désactivé DRA lors de l'exécution de l'application d'analyse comparative.
Le tableau suivant montre le temps d'exécution total de la tâche pour toutes les requêtes (en secondes) dans l'ensemble de données de requête de 3 To entre la version Amazon EMR 6.9.0 et la version open source Spark 3.3.0. Nous avons observé que nos tests TPC-DS avaient un temps d'exécution total des tâches sur Amazon EMR sur Amazon EC2 qui était 3.5 fois plus rapide que celui utilisant un cluster Spark open source de la même configuration.
L'accélération par requête sur Amazon EMR 6.9 avec et sans l'environnement d'exécution EMR pour Apache Spark est illustrée dans le tableau suivant. L'axe horizontal montre chaque requête dans le benchmark de 3 To. L'axe vertical montre l'accélération de chaque requête due à l'exécution EMR. Les gains de performances notables sont plus de 10 fois plus rapides pour les requêtes TPC-DS 24b, 72, 95 et 96.

Analyse de coût
Les améliorations de performances du runtime EMR pour Apache Spark se traduisent directement par une réduction des coûts. Nous avons pu réaliser une économie de 67 % en exécutant l'application de référence sur Amazon EMR par rapport au coût engagé pour exécuter la même application sur Spark open source sur Amazon EC2 avec le même dimensionnement de cluster en raison des heures réduites d'Amazon EMR et d'Amazon. Utilisation EC2. La tarification Amazon EMR concerne les applications EMR exécutées sur des clusters EMR avec des instances EC2. Le prix Amazon EMR est ajouté aux prix sous-jacents du calcul et du stockage, tels que le prix de l'instance EC2 et Boutique de blocs élastiques Amazon (Amazon EBS) coût (si vous attachez des volumes EBS). Dans l'ensemble, le coût de référence estimé dans la région USA Est (Virginie du Nord) est de 27.01 USD par exécution pour le Spark open source sur Amazon EC2 et de 8.82 USD par exécution pour Amazon EMR.
| Emploi de référence | Autonomie (Heure) | Coût estimé | Nombre total d'instances EC2 | CPU virtuel total | Mémoire totale (Gio) | Périphérique racine (Amazon EBS) |
|
Spark open source sur Amazon EC2 (1 nœud principal et 6 nœuds principaux) |
2.23 | $27.01 | 7 | 252 | 504 | 20 Gio gp2 |
|
Amazon EMR sur Amazon EC2 (1 nœud principal et 6 nœuds principaux) |
0.63 | $8.82 | 7 | 252 | 504 | 20 Gio gp2 |
Évaluation du coût
Voici la répartition des coûts pour le travail open source Spark sur Amazon EC2 (27.01 $):
- Coût total d'Amazon EC2 – (7 * 1.728 $ * 2.23) = (nombre d'instances * taux horaire c5d.9xlarge * durée d'exécution de la tâche en heure) = 26.97 $
- Coût Amazon EBS – (0.1 $/730 * 20 * 7 * 2.23) = (Tarif horaire Amazon EBS par Go * taille EBS racine * nombre d'instances * durée d'exécution de la tâche en heure) = 0.042 $
Voici la répartition des coûts pour le travail Amazon EMR sur Amazon EC2 (8.82 $) :
- Coût total d'Amazon EMR – (7 * 0.27 $ * 0.63) = ((nombre de nœuds principaux + nombre de nœuds principaux)* c5d.9xlarge prix Amazon EMR * durée d'exécution de la tâche en heure) = 1.19 $
- Coût total d'Amazon EC2 – (7 * 1.728 $ * 0.63) = ((nombre de nœuds principaux + nombre de nœuds principaux)* prix de l'instance c5d.9xlarge * temps d'exécution de la tâche en heure) = 7.62 $
- Coût Amazon EBS – (0.1 $/730 * 20 Gio * 7 * 0.63) = (Tarif horaire Amazon EBS par Go * taille EBS * nombre d'instances * durée d'exécution de la tâche en heure) = 0.012 $
Configurer l'analyse comparative OSS Spark
Dans les sections suivantes, nous fournissons un bref aperçu des étapes impliquées dans la mise en place de l'analyse comparative. Pour des instructions détaillées avec des exemples, reportez-vous au GitHub repo.
Pour notre benchmarking OSS Spark, nous utilisons l'outil open-source Silex pour lancer notre solution basée sur Amazon EC2 Apache Spark grappe. Flintrock fournit un moyen rapide de lancer un cluster Apache Spark sur Amazon EC2 à l'aide de la ligne de commande.
Pré-requis
Effectuez les étapes préalables suivantes :
- Avoir Python 3.7.x ou supérieur.
- Avoir Pip3 22.2.2 ou supérieur.
- Ajoutez le répertoire Python bin au chemin de votre environnement. Le binaire Flintrock sera installé dans ce chemin.
- Courir
aws configurepour configurer votre Interface de ligne de commande AWS (AWS CLI) shell pour pointer vers le compte d'analyse comparative. Faire référence à Configuration rapide avec aws configure pour obtenir des instructions. - Vous Avez paire de clés avec des autorisations de fichier restrictives pour accéder au nœud principal OSS Spark.
- Créez un nouveau compartiment S3 dans votre compte de test si nécessaire.
- Copiez les données sources TPC-DS en tant qu'entrées dans votre compartiment S3.
- Construisez l'application de référence en suivant les étapes fournies dans Étapes pour créer une application d'assemblage Spark-Benchmark. Alternativement, vous pouvez télécharger un pré-construit étincelle-benchmark-assembly-3.3.0.jar si vous voulez une application basée sur Spark 3.3.0.
Déployer le cluster Spark et exécuter la tâche de référence
Effectuez les étapes suivantes:
- Installez l'outil Flintrock via pip comme indiqué dans Étapes pour configurer OSS Spark Benchmarking.
- Exécutez la commande flintrock configure, qui affiche un fichier de configuration par défaut.
- Modifier la valeur par défaut
config.yamlfichier en fonction de vos besoins. Sinon, copiez et collez le fichier config.yaml content dans le fichier de configuration par défaut. Enregistrez ensuite le fichier à l'endroit où il se trouvait. - Enfin, lancez le cluster Spark à 7 nœuds sur Amazon EC2 via Flintrock.
Cela devrait créer un cluster Spark avec un nœud principal et six nœuds de travail. Si vous voyez des messages d'erreur, revérifiez les valeurs du fichier de configuration, en particulier les versions Spark et Hadoop et les attributs de download-source et de l'AMI.
Le cluster OSS Spark n'est pas fourni avec le gestionnaire de ressources YARN. Pour l'activer, nous devons configurer le cluster.
- Télécharger fil-site.xml et les activer-yarn.sh fichiers du référentiel GitHub.
- Remplacer avec l'adresse IP du nœud principal de votre cluster Flintrock.
Vous pouvez récupérer l'adresse IP à partir de la console Amazon EC2.
- Chargez les fichiers sur tous les nœuds du cluster Spark.
- Exécutez le script enable-yarn.
- Activez la prise en charge de Snappy dans Hadoop (le travail de référence lit les données compressées Snappy).
- Télécharger le fichier JAR de l'application utilitaire de référence étincelle-benchmark-assembly-3.3.0.jar à votre machine locale.
- Copiez ce fichier dans le cluster.
- Connectez-vous au nœud principal et démarrez YARN.
- Soumettez la tâche de test sur le cluster Spark open source, comme indiqué dans Soumettre le travail de référence.
Résumer les résultats
Télécharger le fichier de résultats de test à partir du compartiment S3 de sortie s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Remplacer $YOUR_S3_BUCKET avec votre nom de compartiment S3.) Vous pouvez utiliser la console Amazon S3 et accéder à l'emplacement de sortie S3 ou utiliser l'AWS CLI.
L'application de référence Spark crée un dossier d'horodatage et écrit un fichier récapitulatif dans un préfixe summary.csv. Votre horodatage et votre nom de fichier seront différents de ceux indiqués dans l'exemple précédent.
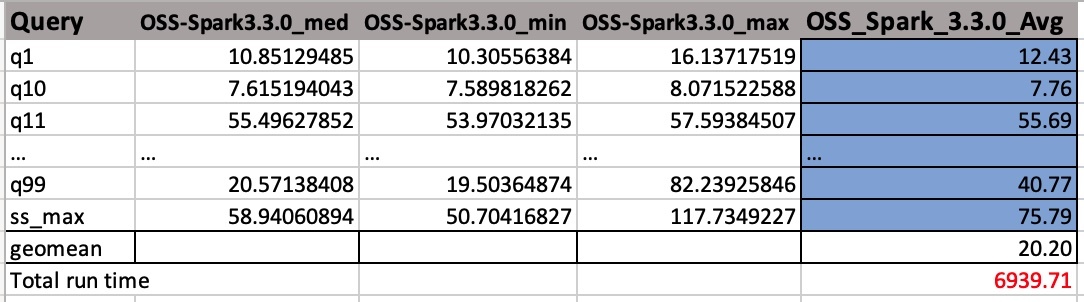
Les fichiers CSV de sortie comportent quatre colonnes sans nom d'en-tête. Ils sont:
- Nom de la requête
- Temps médian
- Temps minimum
- Temps maximum
La capture d'écran suivante montre un exemple de sortie. Nous avons ajouté manuellement les noms de colonne. La façon dont nous calculons la moyenne géographique et le temps d'exécution total du travail est basée sur des moyennes arithmétiques. Nous prenons d'abord la moyenne des valeurs med, min et max en utilisant la formule AVERAGE(B2:D2). Ensuite, nous prenons une moyenne géométrique de la colonne Avg en utilisant la formule GEOMEAN(E2:E105).
Configurer l'analyse comparative Amazon EMR
Pour des instructions détaillées, voir Étapes pour configurer l'analyse comparative EMR.
Pré-requis
Effectuez les étapes préalables suivantes :
- Courir
aws configurepour configurer votre shell AWS CLI afin qu'il pointe vers le compte d'analyse comparative. Faire référence à Configuration rapide avec aws configure pour obtenir des instructions. - Chargez l'application de référence sur Amazon S3.
Déployer le cluster EMR et exécuter la tâche de benchmark
Effectuez les étapes suivantes:
- Lancez Amazon EMR dans votre shell AWS CLI à l'aide de la ligne de commande, comme indiqué dans Déployer le cluster EMR et exécuter le travail de référence.
- Configurez Amazon EMR avec un nœud principal (c5d.9xlarge) et six nœuds principaux (c5d.9xlarge). Faire référence à créer un cluster pour une description détaillée des options de l'AWS CLI.
- Stockez l'ID de cluster de la réponse. Vous en aurez besoin à l'étape suivante.
- Soumettez la tâche de référence dans Amazon EMR à l'aide d'étapes d'ajout dans l'AWS CLI.
Résumer les résultats
Résumer les résultats du bucket de sortie s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT de la même manière que nous l'avons fait pour les résultats OSS et comparer.
Nettoyer
Pour éviter d'encourir des frais futurs, supprimez les ressources que vous avez créées en suivant les instructions du Section de nettoyage du dépôt GitHub.
- Arrêtez les clusters EMR et OSS Spark. Vous pouvez également les supprimer si vous ne souhaitez pas conserver le contenu. Vous pouvez supprimer ces ressources en exécutant le script nettoyage-benchmark-env.sh depuis un terminal dans votre environnement de référence.
- Si vous avez utilisé AWSCloud9 comme IDE pour créer le fichier JAR de l'application de référence à l'aide Étapes pour créer une application d'assemblage Spark-Benchmark, vous pouvez également supprimer l'environnement.
Conclusion
Vous pouvez exécuter vos charges de travail Apache Spark 3.5 fois (sur la base du temps d'exécution total) plus rapidement et à moindre coût sans apporter de modifications à vos applications en utilisant Amazon EMR 6.9.0.
Pour rester informé, abonnez-vous au Big Data Blog's Flux RSS pour en savoir plus sur l'environnement d'exécution EMR pour Apache Spark, les bonnes pratiques de configuration et les conseils de réglage.
Pour les tests de référence passés, voir Exécutez les charges de travail Apache Spark 3.0 1.7 fois plus rapidement avec l'environnement d'exécution Amazon EMR pour Apache Spark. Notez que le résultat de référence passé de 1.7 fois la performance était basé sur la moyenne géométrique. Sur la base d'une moyenne géométrique, les performances d'Amazon EMR 6.9 étaient deux fois plus rapides.
À propos des auteurs
 Sekar Srinivasan est un architecte de solutions spécialisé senior chez AWS, spécialisé dans le Big Data et l'analyse. Sekar a plus de 20 ans d'expérience dans le travail avec les données. Il se passionne pour aider les clients à créer des solutions évolutives en modernisant leur architecture et en générant des informations à partir de leurs données. Dans ses temps libres, il aime travailler sur des projets à but non lucratif, en particulier ceux axés sur l'éducation des enfants défavorisés.
Sekar Srinivasan est un architecte de solutions spécialisé senior chez AWS, spécialisé dans le Big Data et l'analyse. Sekar a plus de 20 ans d'expérience dans le travail avec les données. Il se passionne pour aider les clients à créer des solutions évolutives en modernisant leur architecture et en générant des informations à partir de leurs données. Dans ses temps libres, il aime travailler sur des projets à but non lucratif, en particulier ceux axés sur l'éducation des enfants défavorisés.
 Prabu Ravichandran est un architecte de données senior chez Amazon Web Services, spécialisé dans l'analyse, l'architecture et la mise en œuvre des lacs de données. Il aide les clients à concevoir et à créer des solutions évolutives et robustes à l'aide des services AWS. Pendant son temps libre, Prabu aime voyager et passer du temps avec sa famille.
Prabu Ravichandran est un architecte de données senior chez Amazon Web Services, spécialisé dans l'analyse, l'architecture et la mise en œuvre des lacs de données. Il aide les clients à concevoir et à créer des solutions évolutives et robustes à l'aide des services AWS. Pendant son temps libre, Prabu aime voyager et passer du temps avec sa famille.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 ans
- 7
- 9
- a
- Capable
- A Propos
- au dessus de
- accès
- Compte
- ajoutée
- propos
- conseils
- Tous
- allocation
- Amazon
- Amazon EC2
- Amazon DME
- Amazon Web Services
- selon une analyse de l’Université de Princeton
- analytique
- il analyse
- et les
- Apache
- Apache Spark
- api
- Application
- applications
- architecture
- attributs
- moyen
- AVG
- AWS
- Axis
- basé
- CROYONS
- référence
- LES MEILLEURS
- les meilleures pratiques
- jusqu'à XNUMX fois
- Big
- Big Data
- Block
- Breakdown
- construire
- Développement
- maisons
- Change
- Modifications
- des charges
- Graphique
- Grappe
- Colonne
- Colonnes
- comment
- comparer
- Comparaison
- compatible
- calcul
- configuration
- Console
- contenu
- Core
- Prix
- les économies de coûts
- Costs
- engendrent
- créée
- crée des
- Clients
- données
- Lac de données
- Date
- Réglage par défaut
- Dérivé
- la description
- détaillé
- dispositif
- DID
- différent
- directement
- handicapé
- Ne fait pas
- Ne pas
- download
- chacun
- Est
- ebs
- Éducation
- permettre
- Environment
- Équivalent
- erreur
- notamment
- estimé
- Ether (ETH)
- évaluer
- exemple
- exemples
- Exercises
- d'experience
- famille
- plus rapide
- Fonctionnalité
- Déposez votre dernière attestation
- Fichiers
- finalement
- Prénom
- concentré
- focalisé
- Abonnement
- formule
- trouvé
- gratuitement ici
- De
- avenir
- Gains
- générateur
- GitHub
- l'
- Hadoop
- aider
- aide
- Horizontal
- HEURES
- Cependant
- HTML
- HTTPS
- la mise en oeuvre
- amélioration
- améliorations
- in
- contribution
- idées.
- instance
- Des instructions
- impliqué
- IP
- IP dédiée
- IT
- Emploi
- XNUMX éléments à
- lac
- lancer
- APPRENTISSAGE
- Gamme
- locales
- emplacement
- click
- Fabrication
- manager
- manière
- manuellement
- max
- veux dire
- Mémoire
- messages
- PLUS
- prénom
- noms
- NAVIGUER
- Besoin
- nécessaire
- Besoins
- Nouveauté
- next
- nœud
- nœuds
- une organisation à but non lucratif
- notable
- nombre
- ONE
- open source
- optimisé
- Options
- de commander
- Oss
- contour
- global
- passionné
- passé
- chemin
- performant
- autorisations
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- Pops
- Post
- pratiques
- prix
- Tarifs
- établissement des prix
- primaire
- Privé
- projets
- fournir
- à condition de
- fournit
- purement
- Python
- Rapide
- Tarif
- réaliser
- Prix Réduit
- région
- libérer
- remplacer
- ressource
- Resources
- réponse
- Restrictif
- résultat
- Résultats
- robuste
- racine
- Courir
- pour le running
- même
- Épargnez
- Épargnes
- évolutive
- Escaliers intérieurs
- Deuxièmement
- secondes
- Section
- les sections
- supérieur
- Services
- mise
- installation
- coquillage
- devrait
- montré
- Spectacles
- étapes
- SIX
- Taille
- Solutions
- Identifier
- Spark
- spécialiste
- Dépenses
- Commencer
- étapes
- Étapes
- storage
- inscrire
- tel
- RÉSUMÉ
- Support
- Les soutiens
- table
- Prenez
- terminal
- tester
- tests
- Le
- leur
- Avec
- fiable
- fois
- horodatage
- à
- outil
- Boîte à outils
- Total
- traduire
- Voyages
- sous-jacent
- défavorisés
- us
- Utilisation
- utilisé
- utilitaire
- Valeurs
- version
- via
- Virginie
- volumes
- web
- services Web
- qui
- tout en
- sera
- sans
- activités principales
- travailleur
- de travail
- X
- XML
- yaml
- années
- Votre
- zéphyrnet