Avec le lancement de la fonction de recherche neuronale pour Service Amazon OpenSearch dans OpenSearch 2.9, il est désormais facile d’intégrer des modèles AI/ML pour alimenter la recherche sémantique et d’autres cas d’utilisation. OpenSearch Service prend en charge la recherche lexicale et vectorielle depuis l'introduction de sa fonctionnalité k-plus proche voisin (k-NN) en 2020 ; cependant, la configuration de la recherche sémantique nécessitait la création d'un cadre pour intégrer des modèles d'apprentissage automatique (ML) à ingérer et à rechercher. La fonction de recherche neuronale facilite la transformation texte en vecteur lors de l'ingestion et de la recherche. Lorsque vous utilisez une requête neuronale pendant la recherche, la requête est traduite en une intégration vectorielle et k-NN est utilisé pour renvoyer les intégrations vectorielles les plus proches du corpus.
Pour utiliser la recherche neuronale, vous devez configurer un modèle ML. Nous vous recommandons de configurer les connecteurs AI/ML vers les services AWS AI et ML (tels que Amazon Sage Maker or Socle amazonien) ou des alternatives tierces. À partir de la version 2.9 sur OpenSearch Service, les connecteurs AI/ML s'intègrent à la recherche neuronale pour simplifier et opérationnaliser la traduction de votre corpus de données et de vos requêtes en intégrations vectorielles, éliminant ainsi une grande partie de la complexité de l'hydratation et de la recherche de vecteurs.
Dans cet article, nous montrons comment configurer des connecteurs AI/ML vers des modèles externes via la console OpenSearch Service.
Présentation de la solution
Plus précisément, cet article vous guide dans la connexion à un modèle dans SageMaker. Ensuite, nous vous guidons dans l'utilisation du connecteur pour configurer la recherche sémantique sur OpenSearch Service comme exemple de cas d'utilisation pris en charge via la connexion à un modèle ML. Les intégrations Amazon Bedrock et SageMaker sont actuellement prises en charge sur l'interface utilisateur de la console OpenSearch Service, et la liste des intégrations propriétaires et tierces prises en charge par l'interface utilisateur continuera de s'allonger.
Pour tous les modèles non pris en charge via l'interface utilisateur, vous pouvez les configurer à l'aide des API disponibles et du Plans ML. Pour plus d'informations, reportez-vous à Introduction aux modèles OpenSearch. Vous pouvez trouver des plans pour chaque connecteur dans le Dépôt GitHub ML Commons.
Pré-requis
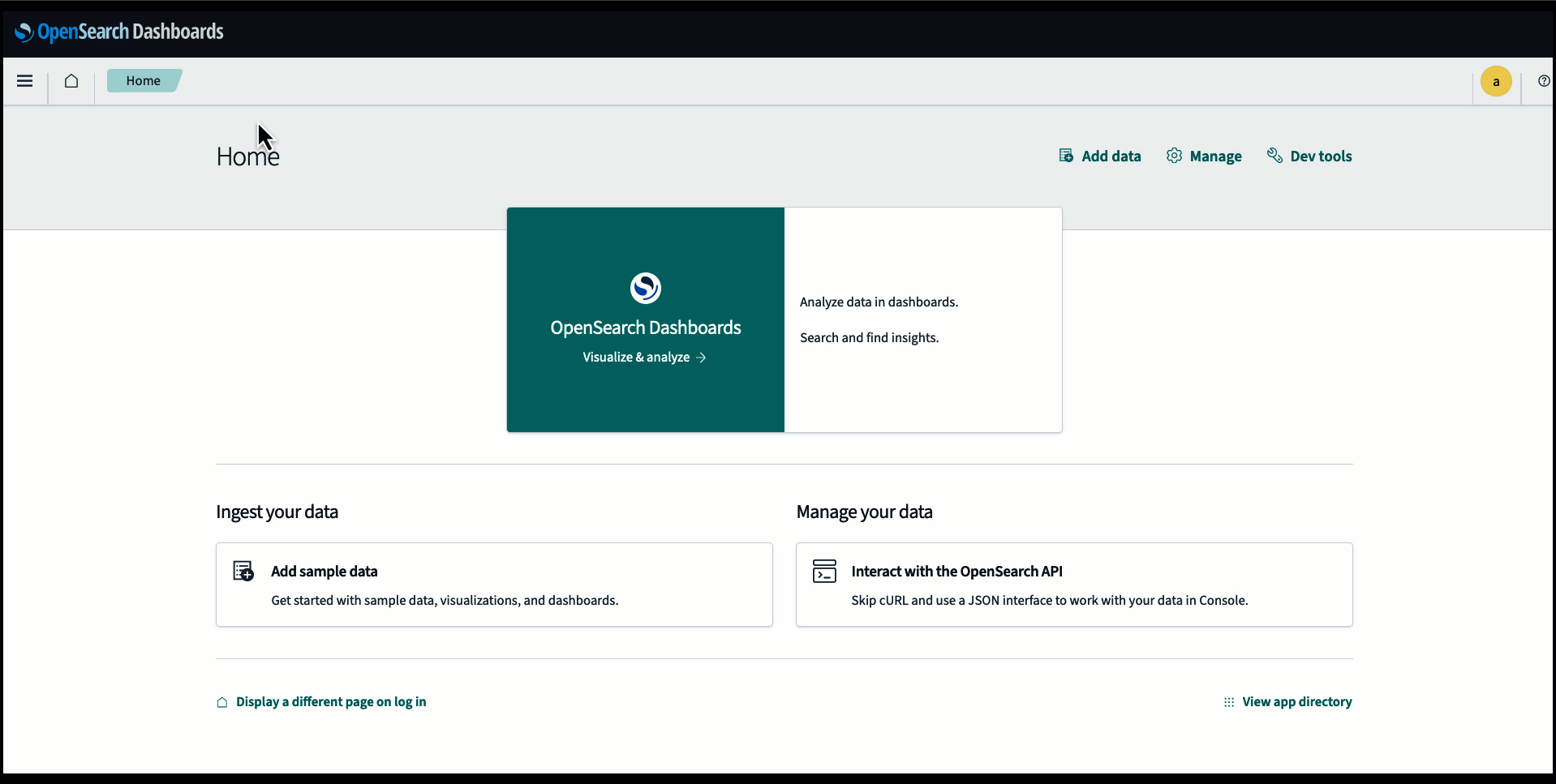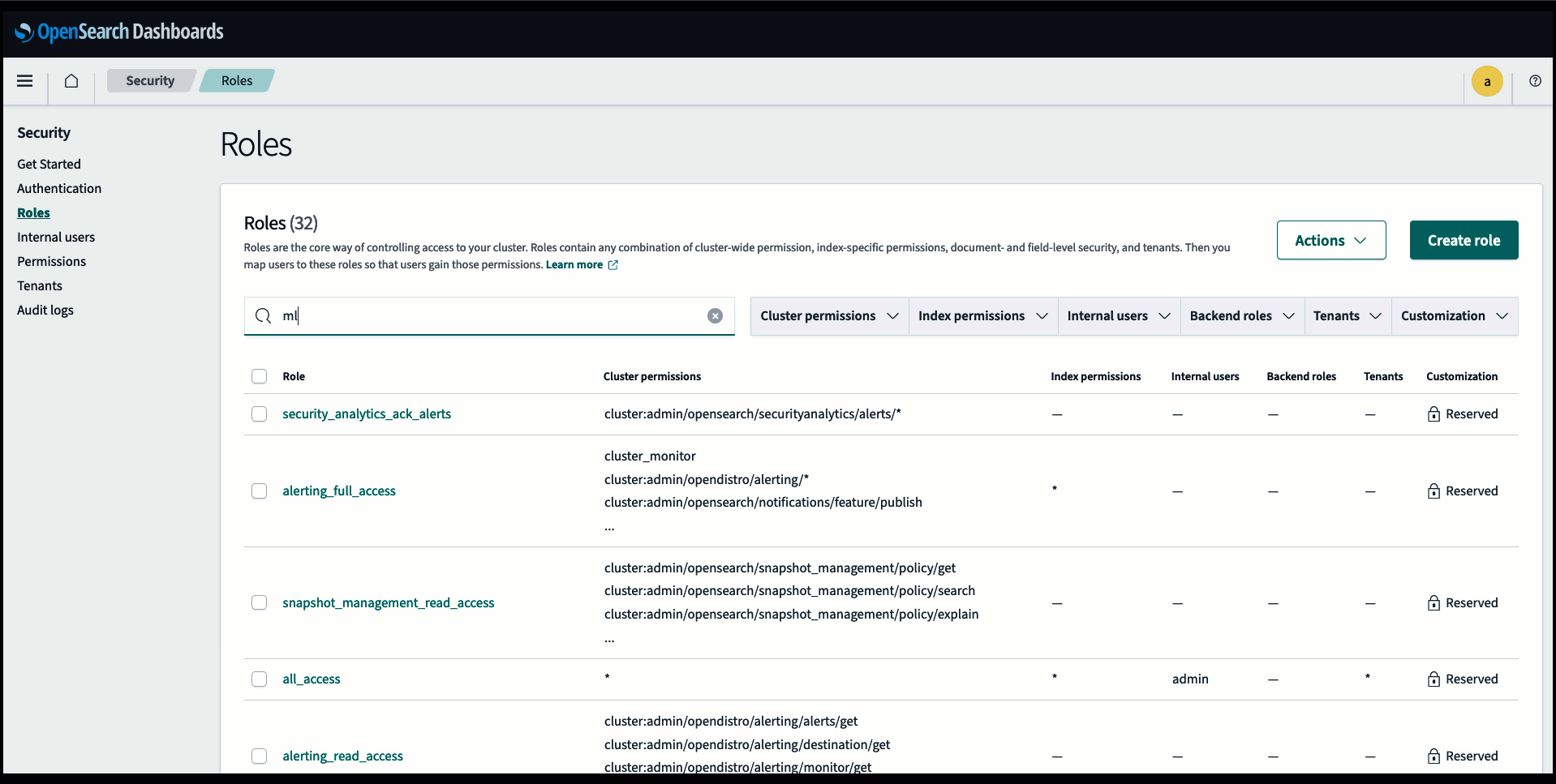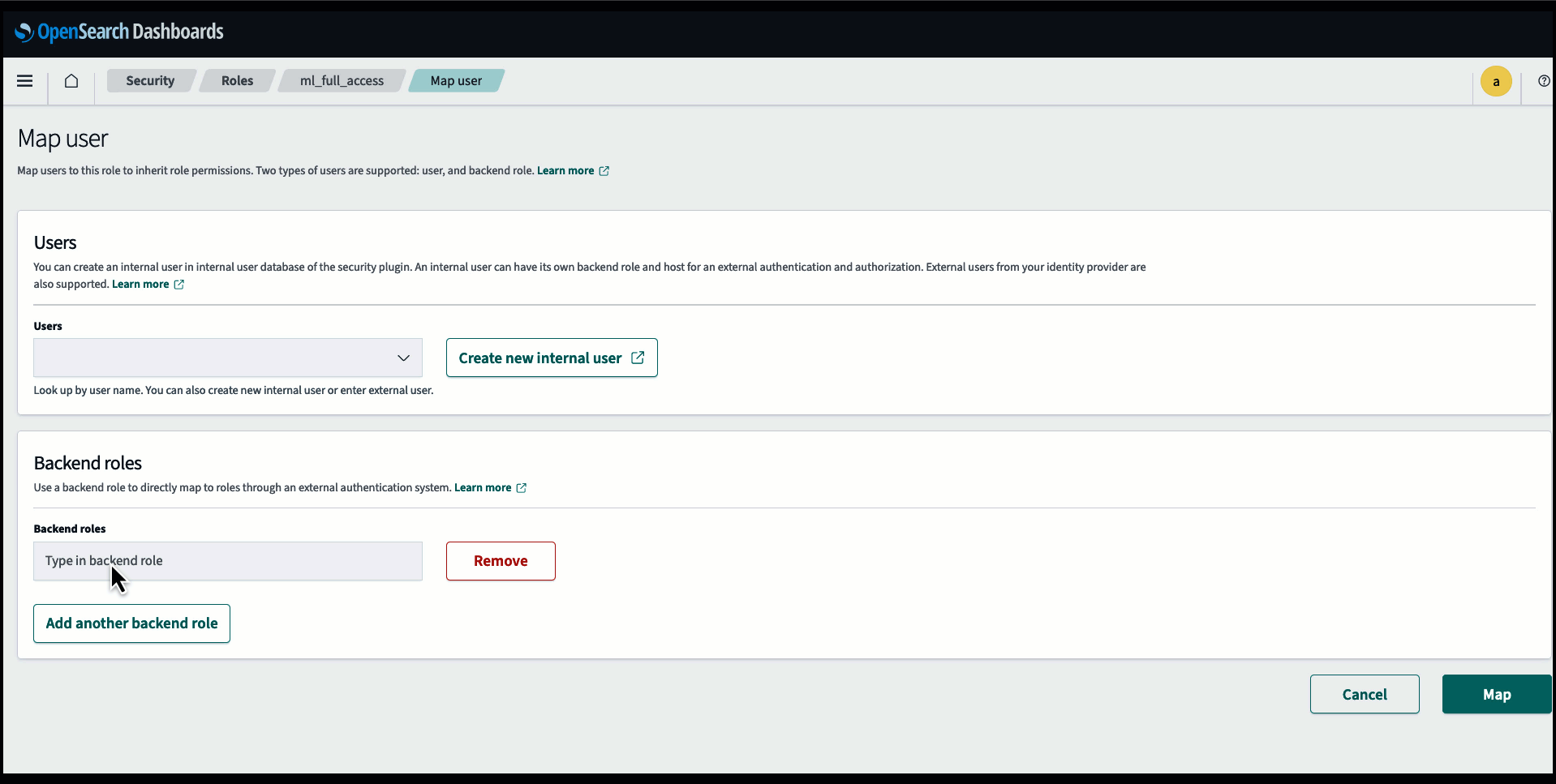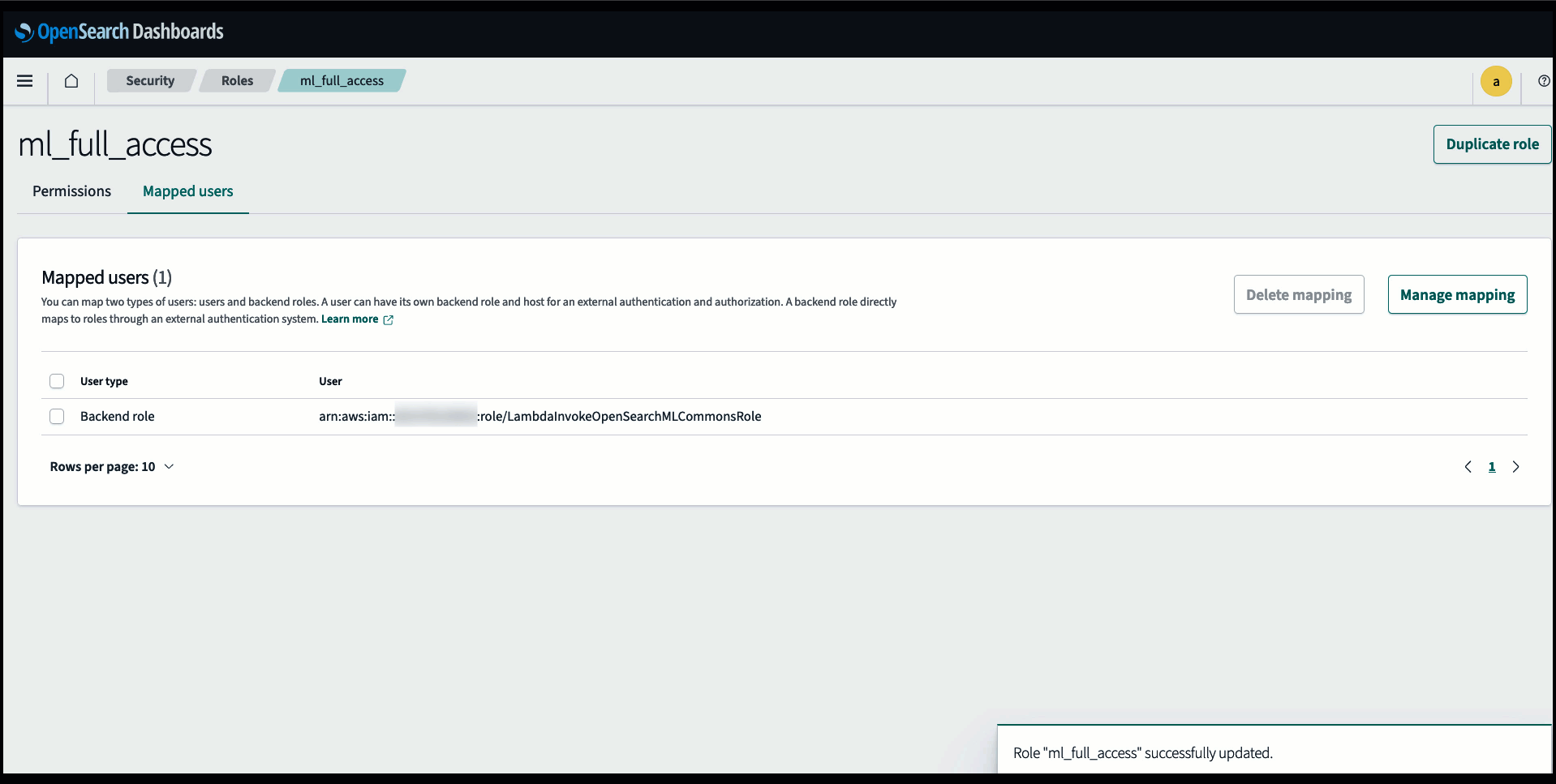
Avant de connecter le modèle via la console OpenSearch Service, créez un domaine OpenSearch Service. Cartographier un Gestion des identités et des accès AWS (IAM) rôle par le nom LambdaInvokeOpenSearchMLCommonsRole en tant que rôle backend sur le ml_full_access rôle à l'aide du plug-in de sécurité sur les tableaux de bord OpenSearch, comme le montre la vidéo suivante. Le workflow d'intégrations OpenSearch Service est pré-rempli pour utiliser le LambdaInvokeOpenSearchMLCommonsRole Rôle IAM par défaut pour créer le connecteur entre le domaine OpenSearch Service et le modèle déployé sur SageMaker. Si vous utilisez un rôle IAM personnalisé sur les intégrations de la console OpenSearch Service, assurez-vous que le rôle personnalisé est mappé en tant que rôle backend avec ml_full_access autorisations avant de déployer le modèle.
Déployer le modèle à l'aide d'AWS CloudFormation
La vidéo suivante montre les étapes à suivre pour utiliser la console OpenSearch Service pour déployer un modèle en quelques minutes sur Amazon SageMaker et générer l'ID du modèle via les connecteurs AI. La première étape est de choisir Intégration dans le volet de navigation de la console OpenSearch Service AWS, qui mène à une liste des intégrations disponibles. L'intégration est configurée via une interface utilisateur, qui vous demandera les entrées nécessaires.
Pour configurer l'intégration, il vous suffit de fournir le point de terminaison du domaine OpenSearch Service et de fournir un nom de modèle pour identifier de manière unique la connexion du modèle. Par défaut, le modèle déploie le modèle de transformation de phrases Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
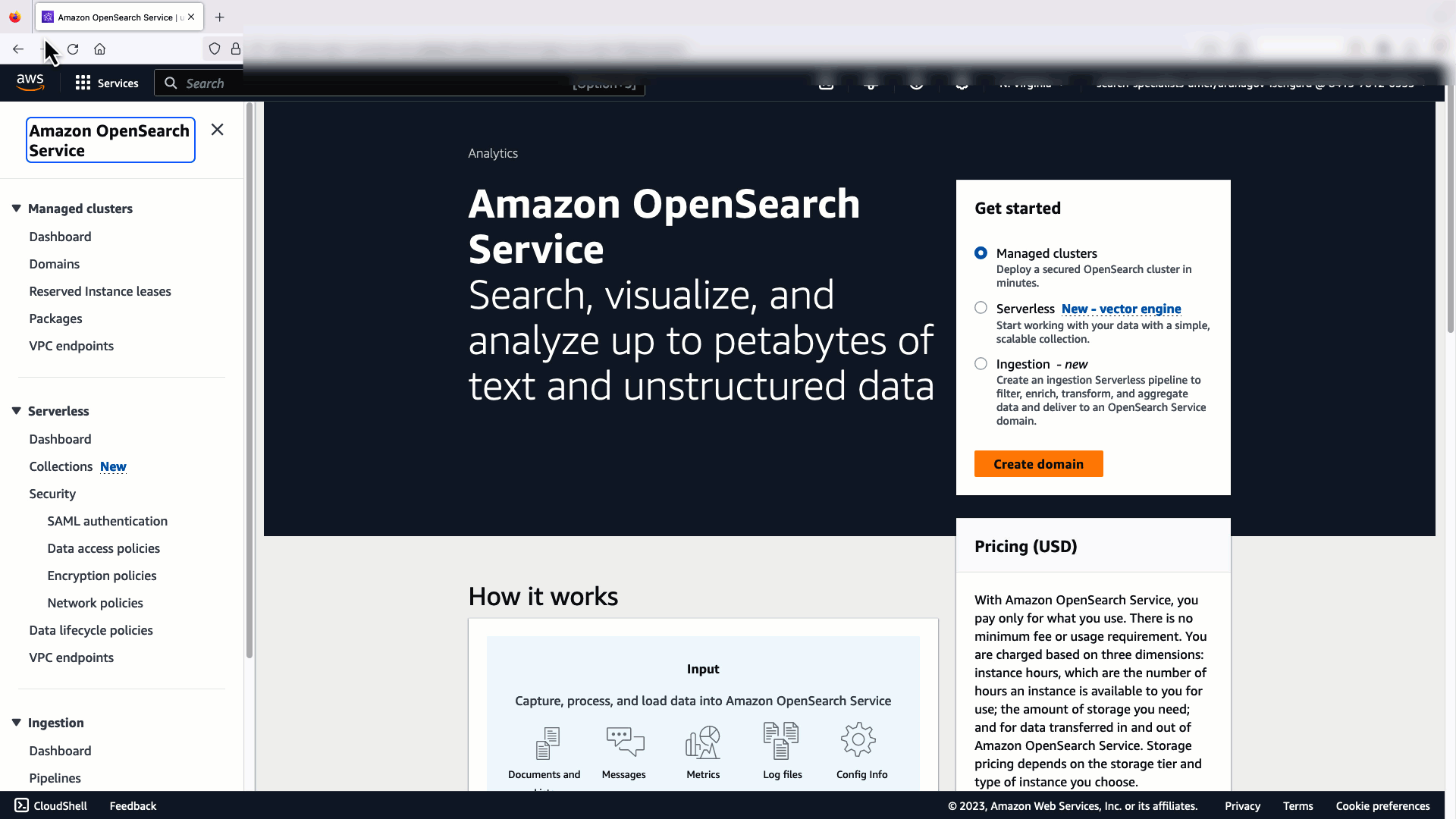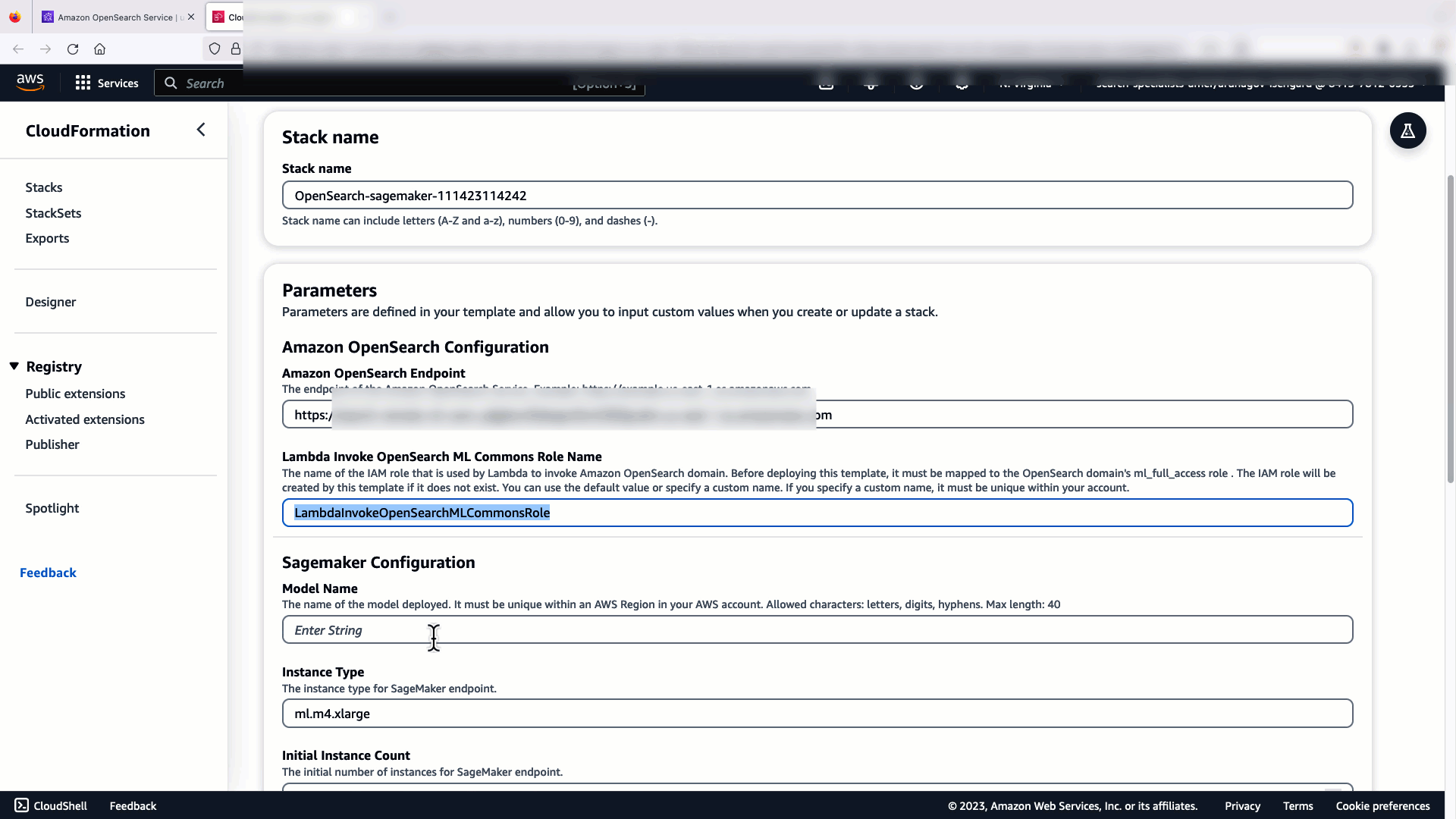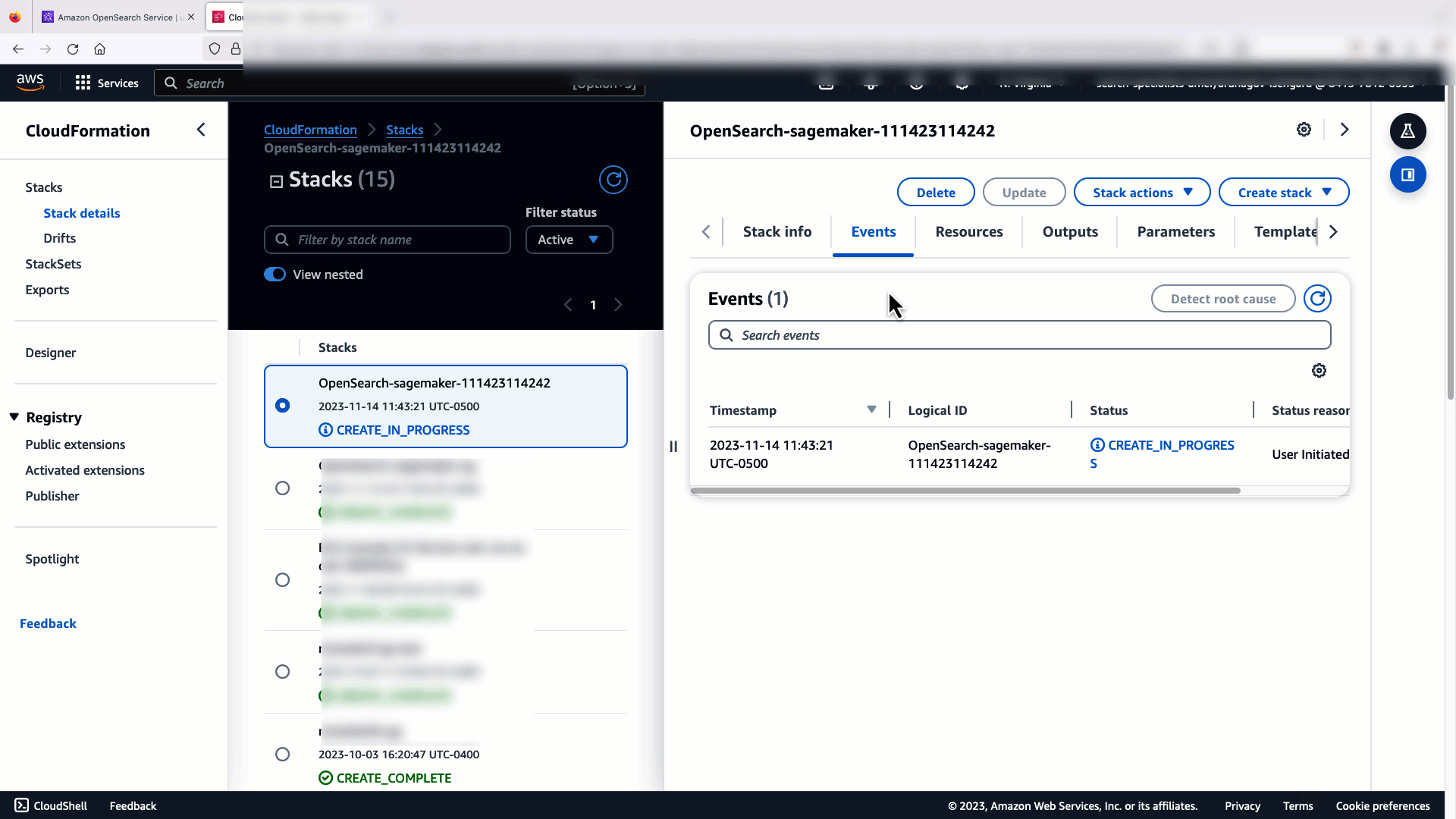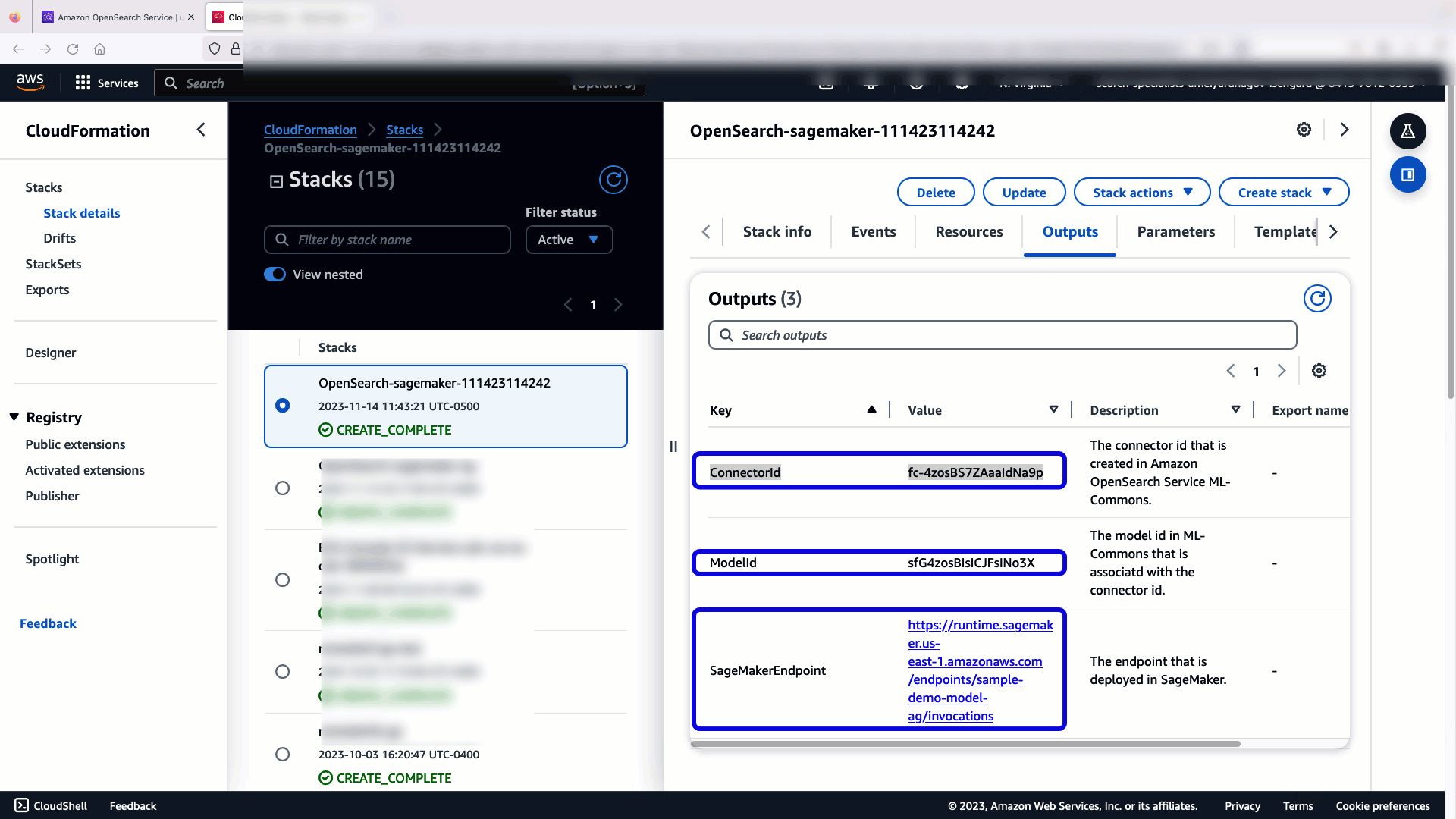
Quand vous choisissez Créer une pile, vous êtes dirigé vers le AWS CloudFormation console. Le modèle CloudFormation déploie l'architecture détaillée dans le diagramme suivant.

La pile CloudFormation crée un AWS Lambda application qui déploie un modèle à partir de Service de stockage simple Amazon (Amazon S3), crée le connecteur et génère l'ID de modèle dans la sortie. Vous pouvez ensuite utiliser cet ID de modèle pour créer un index sémantique.
Si le modèle par défaut entièrement MiniLM-L6-v2 ne répond pas à votre objectif, vous pouvez déployer n'importe quel modèle d'intégration de texte de votre choix sur l'hôte de modèle choisi (SageMaker ou Amazon Bedrock) en fournissant vos artefacts de modèle en tant qu'objet S3 accessible. Vous pouvez également sélectionner l'une des options suivantes modèles de langage pré-entraînés et déployez-le sur SageMaker. Pour obtenir des instructions sur la configuration de votre point de terminaison et de vos modèles, reportez-vous à Images Amazon SageMaker disponibles.
SageMaker est un service entièrement géré qui rassemble un large ensemble d'outils pour permettre un ML hautes performances et à faible coût pour tout cas d'utilisation, offrant des avantages clés tels que la surveillance des modèles, l'hébergement sans serveur et l'automatisation des flux de travail pour la formation et le déploiement continus. SageMaker vous permet d'héberger et de gérer le cycle de vie des modèles d'intégration de texte et de les utiliser pour alimenter les requêtes de recherche sémantique dans OpenSearch Service. Une fois connecté, SageMaker héberge vos modèles et OpenSearch Service est utilisé pour effectuer des requêtes basées sur les résultats d'inférence de SageMaker.
Afficher le modèle déployé via les tableaux de bord OpenSearch
Pour vérifier que le modèle CloudFormation a déployé avec succès le modèle sur le domaine OpenSearch Service et obtenir l'ID du modèle, vous pouvez utiliser l'API REST GET ML Commons via les outils de développement OpenSearch Dashboards.
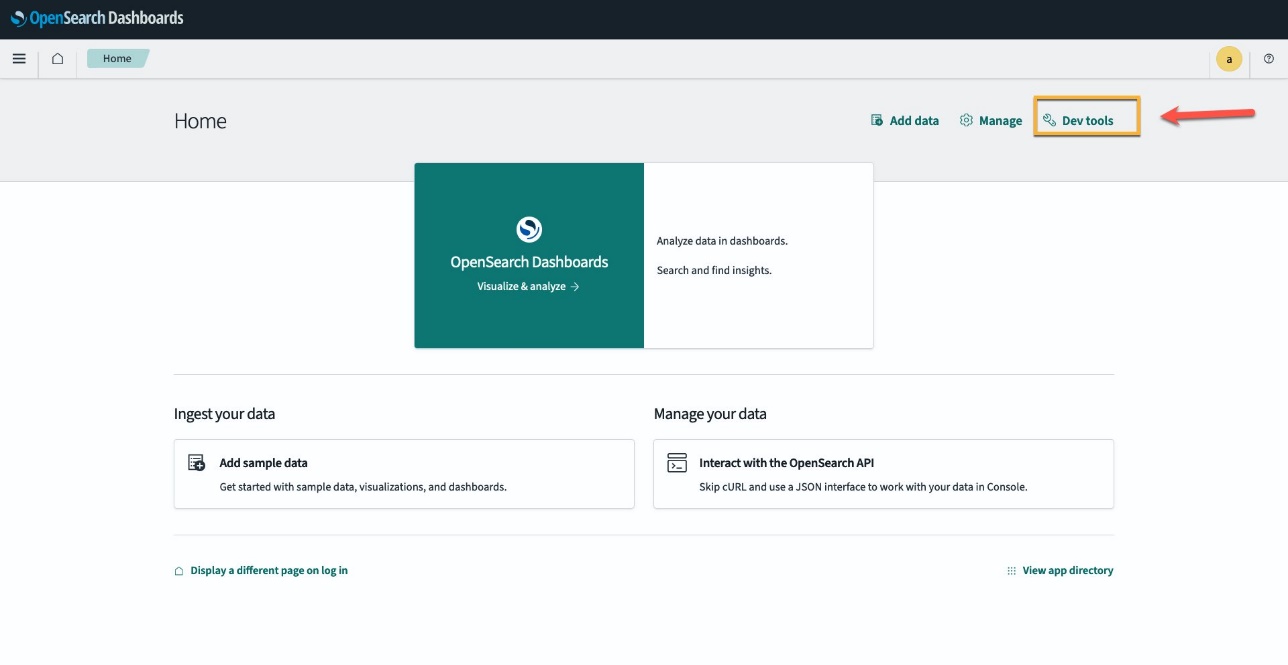
L'API REST GET _plugins fournit désormais des API supplémentaires pour afficher également l'état du modèle. La commande suivante vous permet de voir l'état d'un modèle distant :
Comme le montre la capture d'écran suivante, un DEPLOYED L'état dans la réponse indique que le modèle est déployé avec succès sur le cluster OpenSearch Service.

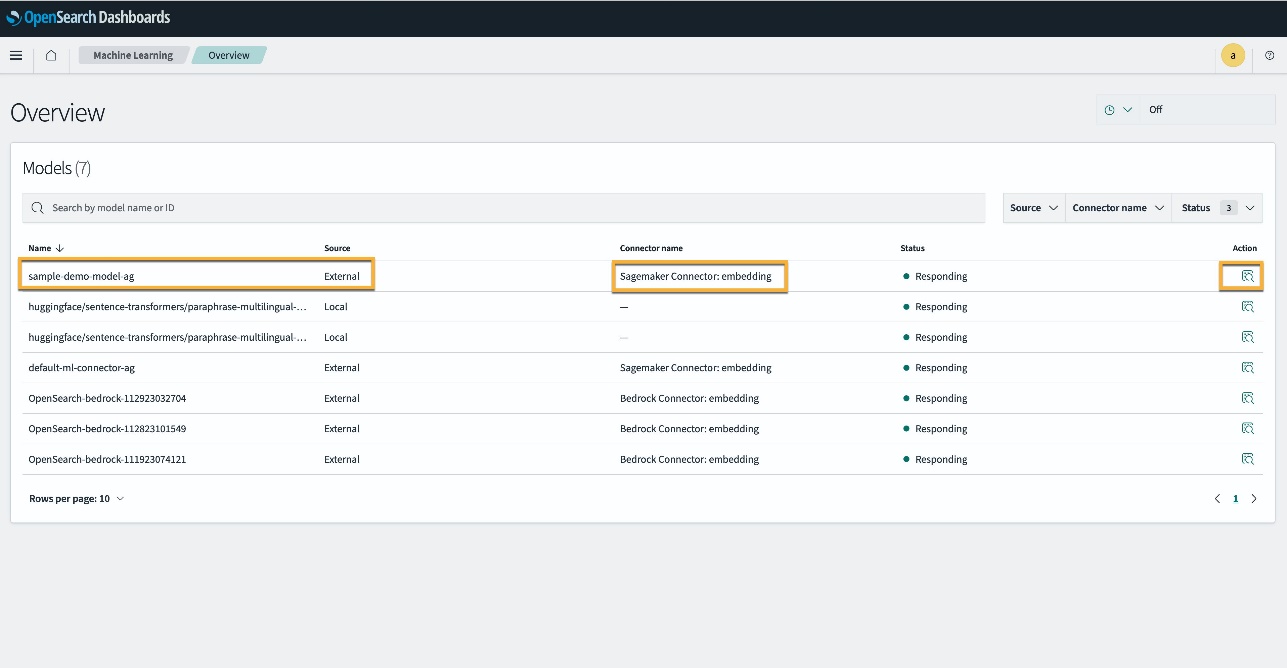
Vous pouvez également afficher le modèle déployé sur votre domaine OpenSearch Service à l'aide de l'outil Machine Learning page des tableaux de bord OpenSearch.

Cette page répertorie les informations sur le modèle et les statuts de tous les modèles déployés.

Créer le pipeline neuronal à l'aide de l'ID du modèle
Lorsque l'état du modèle s'affiche comme suit : DEPLOYED dans Dev Tools ou vert et Répondant dans les tableaux de bord OpenSearch, vous pouvez utiliser l'ID de modèle pour créer votre pipeline d'ingestion neuronale. Le pipeline d’ingestion suivant est exécuté dans les outils de développement OpenSearch Dashboards de votre domaine. Assurez-vous de remplacer l'ID du modèle par l'ID unique généré pour le modèle déployé sur votre domaine.

Créez l'index de recherche sémantique en utilisant le pipeline neuronal comme pipeline par défaut
Vous pouvez maintenant définir votre mappage d'index avec le pipeline par défaut configuré pour utiliser le nouveau pipeline neuronal que vous avez créé à l'étape précédente. Assurez-vous que les champs vectoriels sont déclarés comme knn_vector et les dimensions sont appropriées au modèle déployé sur SageMaker. Si vous avez conservé la configuration par défaut pour déployer le modèle all-MiniLM-L6-v2 sur SageMaker, conservez les paramètres suivants tels quels et exécutez la commande dans Dev Tools.

Ingérer des exemples de documents pour générer des vecteurs
Pour cette démo, vous pouvez ingérer le exemple de catalogue de produits de démonstration au détail à la nouvelle semantic_demostore indice. Remplacez le nom d'utilisateur, le mot de passe et le point de terminaison du domaine par les informations de votre domaine et ingérez les données brutes dans OpenSearch Service :

Valider le nouvel index semantic_demostore
Maintenant que vous avez ingéré votre ensemble de données dans le domaine OpenSearch Service, vérifiez si les vecteurs requis sont générés à l'aide d'une simple recherche pour récupérer tous les champs. Validez si les champs définis comme knn_vectors avoir les vecteurs requis.

Comparez la recherche lexicale et la recherche sémantique optimisée par la recherche neuronale à l'aide de l'outil Comparer les résultats de recherche
La Outil Comparer les résultats de recherche sur les tableaux de bord OpenSearch est disponible pour les charges de travail de production. Vous pouvez naviguer vers le Comparer les résultats de recherche page et comparez les résultats de la requête entre la recherche lexicale et la recherche neuronale configurée pour utiliser l'ID de modèle généré précédemment.

Nettoyer
Vous pouvez supprimer les ressources que vous avez créées en suivant les instructions de cet article en supprimant la pile CloudFormation. Cela supprimera les ressources Lambda et le compartiment S3 qui contiennent le modèle déployé sur SageMaker. Effectuez les étapes suivantes :
- Sur la console AWS CloudFormation, accédez à la page de détails de votre pile.
- Selectionnez Supprimer.

- Selectionnez Supprimer pour confirmer.

Vous pouvez surveiller la progression de la suppression de la pile sur la console AWS CloudFormation.
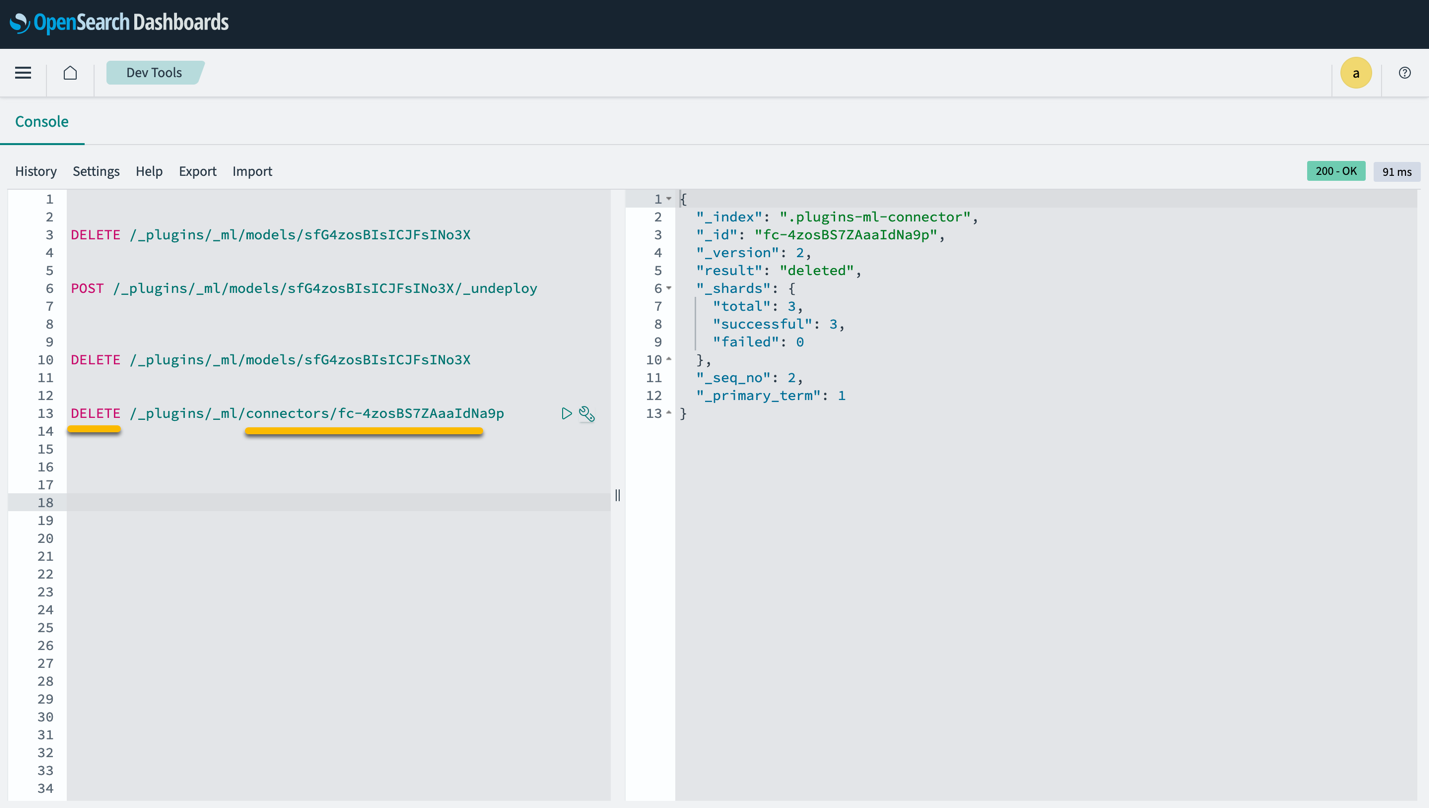
Notez que la suppression de la pile CloudFormation ne supprime pas le modèle déployé sur le domaine SageMaker et le connecteur AI/ML créé. En effet, ces modèles et le connecteur peuvent être associés à plusieurs index au sein du domaine. Pour supprimer spécifiquement un modèle et son connecteur associé, utilisez les API du modèle comme indiqué dans les captures d'écran suivantes.
Tout d'abord, undeploy le modèle de la mémoire du domaine OpenSearch Service :

Ensuite, vous pouvez supprimer le modèle de l'index du modèle :

Enfin, supprimez le connecteur de l'index du connecteur :
Conclusion
Dans cet article, vous avez appris à déployer un modèle dans SageMaker, à créer le connecteur AI/ML à l'aide de la console OpenSearch Service et à créer l'index de recherche neuronale. La possibilité de configurer des connecteurs AI/ML dans OpenSearch Service simplifie le processus d'hydratation des vecteurs en rendant natives les intégrations aux modèles externes. Vous pouvez créer un index de recherche neuronale en quelques minutes à l'aide du pipeline d'ingestion neuronale et de la recherche neuronale qui utilise l'ID de modèle pour générer l'intégration vectorielle à la volée pendant l'ingestion et la recherche.
Pour en savoir plus sur ces connecteurs AI/ML, reportez-vous à Connecteurs Amazon OpenSearch Service AI pour les services AWS, Intégrations de modèles AWS CloudFormation pour la recherche sémantiqueet une Création de connecteurs pour les plates-formes ML tierces.
À propos des auteurs
 Aruna Govindaraju est un architecte de solutions spécialisé Amazon OpenSearch et a travaillé avec de nombreux moteurs de recherche commerciaux et open source. Elle est passionnée par la recherche, la pertinence et l'expérience utilisateur. Son expertise dans la corrélation des signaux des utilisateurs finaux avec le comportement des moteurs de recherche a aidé de nombreux clients à améliorer leur expérience de recherche.
Aruna Govindaraju est un architecte de solutions spécialisé Amazon OpenSearch et a travaillé avec de nombreux moteurs de recherche commerciaux et open source. Elle est passionnée par la recherche, la pertinence et l'expérience utilisateur. Son expertise dans la corrélation des signaux des utilisateurs finaux avec le comportement des moteurs de recherche a aidé de nombreux clients à améliorer leur expérience de recherche.
 Dagney Braun est un chef de produit principal chez AWS axé sur OpenSearch.
Dagney Braun est un chef de produit principal chez AWS axé sur OpenSearch.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :possède
- :est
- :ne pas
- $UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- capacité
- A Propos
- accès
- accessible
- Supplémentaire
- AI
- AI / ML
- Tous
- permet
- aussi
- des alternatives
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- ainsi que
- tous
- api
- Apis
- Application
- approprié
- architecture
- SONT
- AS
- associé
- At
- Automation
- disponibles
- AWS
- AWS CloudFormation
- backend
- basé
- BE
- car
- humain
- avantages.
- jusqu'à XNUMX fois
- tous les deux
- Apportez le
- vaste
- construire
- Développement
- by
- CAN
- maisons
- cas
- catalogue
- le choix
- Selectionnez
- choisi
- Grappe
- commercial
- Chambre des communes
- comparer
- complet
- complexité
- configuration
- configurée
- Configurer
- Confirmer
- connecté
- Connecter les
- connexion
- Console
- contiennent
- continuer
- continu
- corréler
- engendrent
- créée
- crée des
- Lecture
- Customiser
- Clients
- tableaux de bord
- données
- Réglage par défaut
- Vous permet de définir
- défini
- livrer
- Démo
- démontrer
- démontre
- déployer
- déployé
- déployer
- déploiement
- déploie
- la description
- détaillé
- détails
- dev
- Dimension
- dimensions
- INSTITUTIONNELS
- Ne fait pas
- domaine
- pendant
- chacun
- Plus tôt
- sans effort
- non plus
- enrobage
- permettre
- Endpoint
- Moteur
- Moteurs
- assurer
- Ether (ETH)
- exemple
- d'experience
- nous a permis de concevoir
- externe
- Visage
- facilite
- Fonctionnalité
- Des champs
- Trouvez
- Prénom
- concentré
- Abonnement
- Pour
- Framework
- De
- d’étiquettes électroniques entièrement
- générer
- généré
- génère
- obtenez
- gif
- GitHub
- Vert
- Croître
- guide
- Vous avez
- a aidé
- ici
- haute performance
- hôte
- hébergement
- hôtes
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- Étreindre
- hydratation
- IAM
- ID
- identifier
- Identite
- if
- améliorer
- in
- indice
- index
- indique
- d'information
- entrées
- plutôt ;
- Des instructions
- intégrer
- l'intégration
- intégrations
- développement
- Introduction
- IT
- SES
- jpg
- json
- XNUMX éléments à
- ACTIVITES
- langue
- lancer
- APPRENTISSAGE
- savant
- apprentissage
- vos produits
- Liste
- Liste
- low cost
- click
- machine learning
- a prendre une
- Fabrication
- gérer
- gérés
- manager
- de nombreuses
- Localisation
- cartographie
- Mémoire
- méthode
- minutes
- ML
- modèle
- numériques jumeaux (digital twin models)
- Surveiller
- Stack monitoring
- PLUS
- beaucoup
- plusieurs
- must
- prénom
- indigène
- NAVIGUER
- Navigation
- nécessaire
- Besoin
- Neural
- Nouveauté
- maintenant
- objet
- of
- on
- ONE
- uniquement
- ouvert
- open source
- or
- Autre
- sortie
- page
- pain
- passionné
- Mot de Passe
- autorisations
- pipeline
- Platon
- Intelligence des données Platon
- PlatonDonnées
- plug-in
- Post
- power
- alimenté
- précédent
- Directeur
- Avant
- processus
- processeurs
- Produit
- chef de produit
- Vidéo
- Progrès
- propriétés
- fournir
- fournit
- aportando
- but
- requêtes
- raw
- les données brutes
- recommander
- reportez-vous
- éloigné
- enlever
- remplacer
- conditions
- Resources
- réponse
- REST
- Résultats
- détail
- retenu
- retourner
- Rôle
- routes
- Courir
- sagemaker
- screenshots
- Rechercher
- moteur de recherche
- Les moteurs de recherche
- sécurité
- sur le lien
- Sélectionner
- besoin
- Sans serveur
- service
- Services
- set
- Paramétres
- elle
- montré
- Spectacles
- signaux
- étapes
- simplifie
- simplifier
- depuis
- Solutions
- Identifier
- spécialiste
- spécifiquement
- empiler
- Commencez
- Statut
- étapes
- Étapes
- storage
- Avec succès
- tel
- Appareils
- sûr
- modèle
- texte
- qui
- La
- leur
- Les
- puis
- ainsi
- Ces
- des tiers.
- this
- Avec
- à
- ensemble
- les outils
- Formation
- De La Carrosserie
- Traduction
- oui
- type
- ui
- expérience unique et authentique
- uniquement
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- Expérience utilisateur
- en utilisant
- VALIDER
- vérifier
- version
- via
- Vidéo
- Voir
- marche
- était
- we
- web
- services Web
- quand
- qui
- sera
- comprenant
- dans les
- travaillé
- workflow
- l'automatisation du workflow
- you
- Votre
- zéphyrnet