Redshift d'Amazon est un entrepôt de données rapide, entièrement géré, à l'échelle du pétaoctet, qui offre la flexibilité d'utiliser un calcul provisionné ou sans serveur pour vos charges de travail analytiques. Utilisant Amazon Redshift sans serveur ainsi que le Éditeur de requête v2, vous pouvez charger et interroger de grands ensembles de données en quelques clics et ne payer que ce que vous utilisez. L'architecture de calcul et de stockage découplée d'Amazon Redshift vous permet de créer des charges de travail hautement évolutives, résilientes et rentables. De nombreux clients migrent leurs charges de travail d'entreposage de données vers Amazon Redshift et bénéficient des riches fonctionnalités qu'il offre. Voici quelques-unes des fonctionnalités notables :
- Amazon Redshift s'intègre de manière transparente à des services d'analyse sur AWS. Cela vous permet de choisir le bon outil pour le bon travail. L'analyse moderne est beaucoup plus large que l'entreposage de données basé sur SQL. Amazon Redshift vous permet de créer architectures de maisons du lac puis effectuer tout type d'analyse, comme analytique interactive, analyse opérationnelle, traitement de données volumineuses, préparation visuelle des données, analyse prédictive, apprentissage automatique (ML), et plus encore.
- Vous n'avez pas à vous soucier des charges de travail, telles que l'ETL, les tableaux de bord, les requêtes ad hoc, etc., qui interfèrent les unes avec les autres. Tu peux isoler les charges de travail en utilisant le partage de données, tout en utilisant les mêmes ensembles de données sous-jacents.
- Lorsque les utilisateurs exécutent de nombreuses requêtes aux heures de pointe, le calcul évolue de manière transparente en quelques secondes pour fournir des performances constantes avec une simultanéité élevée. Vous bénéficiez d'une heure de capacité de mise à l'échelle de la simultanéité gratuite pour 24 heures d'utilisation. Ce crédit gratuit répond à la demande de simultanéité de 97 % de la clientèle d'Amazon Redshift.
- Amazon Redshift est facile à utiliser avec auto-réglage et auto-optimisation capacités. Vous pouvez obtenir des informations plus rapidement sans perdre un temps précieux à gérer votre entrepôt de données.
- Tolérance aux pannes est intégré. Toutes les données écrites sur Amazon Redshift sont automatiquement et continuellement répliquées sur Service de stockage simple Amazon (Amazon S3). Toutes les pannes matérielles sont automatiquement remplacées.
- Amazon Redshift est simple à interagir comprenant. Vous pouvez accéder aux données avec des applications traditionnelles, natives du cloud, conteneurisées et basées sur des services Web ou pilotées par des événements, etc.
- Décalage vers le rouge ML permet aux data scientists de créer, former et déployer facilement des modèles ML à l'aide de SQL familier. Ils peuvent également exécuter des prédictions à l'aide de SQL.
- Amazon Redshift fournit sécurité complète des données sans frais supplémentaires. Vous pouvez configurer le chiffrement des données de bout en bout, configurer des règles de pare-feu, définir des contrôles de sécurité granulaires au niveau des lignes et des colonnes sur les données sensibles, etc.
- Redshift d'Amazon s'intègre de manière transparente aux autres services AWS et aux outils tiers. Vous pouvez déplacer, transformer, charger et interroger de grands ensembles de données rapidement et de manière fiable.
Dans cet article, nous fournissons une procédure pas à pas pour migrer un entrepôt de données de Google BigQuery vers Amazon Redshift à l'aide Outil de conversion de schéma AWS (AWS SCT) ainsi que le Agents d'extraction de données AWS SCT. AWS SCT est un service qui rend prévisibles les migrations de bases de données hétérogènes en convertissant automatiquement la majorité du code de la base de données et des objets de stockage dans un format compatible avec la base de données cible. Tous les objets qui ne peuvent pas être convertis automatiquement sont clairement marqués afin qu'ils puissent être convertis manuellement pour terminer la migration. De plus, AWS SCT peut analyser votre code d'application pour rechercher des instructions SQL intégrées et les convertir.
Vue d'ensemble de la solution
AWS SCT utilise un compte de service pour se connecter à votre projet BigQuery. Tout d'abord, nous créons une base de données Amazon Redshift dans laquelle les données BigQuery sont migrées. Ensuite, nous créons un compartiment S3. Ensuite, nous utilisons AWS SCT pour convertir les schémas BigQuery et les appliquer à Amazon Redshift. Enfin, pour migrer les données, nous utilisons les agents d'extraction de données AWS SCT, qui extraient les données de BigQuery, les chargent dans le compartiment S3, puis les copient sur Amazon Redshift.

Pré-requis
Avant de commencer cette procédure pas à pas, vous devez avoir les prérequis suivants :
- Un poste de travail avec AWS SCT, Amazon Corretto 11et les pilotes Amazon Redshift.
- Vous pouvez utiliser un Amazon Elastic Compute Cloud (Amazon EC2) ou votre poste de travail local en tant que poste de travail. Dans cette procédure pas à pas, nous utilisons Instance Windows Amazon EC2. Pour le créer, utilisez .
- Pour télécharger et installer AWS SCT sur l'instance EC2 que vous avez précédemment créée, utilisez .
- Téléchargez le pilote Amazon Redshift JDBC à partir de ce lieu.
- Téléchargez et installez Amazon Corretto 11.
- Un compte de service GCP qu'AWS SCT peut utiliser pour se connecter à votre projet BigQuery source.
- Subvention Administrateur BigQuery ainsi que le Administrateur de stockage rôles au compte de service.
- Copiez le fichier de clé de compte de service, qui a été créé dans la console de gestion du cloud Google, sur l'instance EC2 qui a AWS SCT.
- Créez un bucket Cloud Storage dans GCP pour stocker vos données sources pendant la migration.
Cette procédure pas à pas couvre les étapes suivantes :
- Créer un groupe de travail et un espace de noms sans serveur Amazon Redshift
- Créer le compartiment et le dossier AWS S3
- Convertir et appliquer BigQuery Schema à Amazon Redshift à l'aide d'AWS SCT
- Connexion à la source Google BigQuery
- Connectez-vous à la cible Amazon Redshift
- Convertir le schéma BigQuery en Amazon Redshift
- Analyser le rapport d'évaluation et traiter les éléments d'action
- Appliquer le schéma converti pour cibler Amazon Redshift
- Migrer des données à l'aide des agents d'extraction de données AWS SCT
- Génération de confiance et de magasins de clés (facultatif)
- Installer et démarrer l'agent d'extraction de données
- Enregistrer l'agent d'extraction de données
- Ajouter des partitions virtuelles pour les grandes tables (facultatif)
- Créer une tâche de migration locale
- Démarrer la tâche de migration des données locales
- Afficher les données dans Amazon Redshift
Créer un groupe de travail et un espace de noms sans serveur Amazon Redshift
Dans cette étape, nous créons un groupe de travail et un espace de noms Amazon Redshift Serverless. Le groupe de travail est une collection de ressources de calcul et l'espace de noms est une collection d'objets et d'utilisateurs de base de données. Pour isoler les charges de travail et gérer différentes ressources dans Amazon Redshift Serverless, vous pouvez créer des espaces de noms et des groupes de travail et gérer les ressources de stockage et de calcul séparément.
Suivez ces étapes pour créer un groupe de travail et un espace de noms Amazon Redshift sans serveur :
- Accédez à la Console Amazon Redshift.
- En haut à droite, choisissez la région AWS que vous souhaitez utiliser.
- Développez le volet Amazon Redshift sur la gauche et choisissez Redshift sans serveur.
- Selectionnez Créer un groupe de travail.
- Pour Nom du groupe de travail, entrez un nom qui décrit les ressources de calcul.
- Vérifiez que le VPC est le même que le VPC de l'instance EC2 avec AWS SCT.
- Selectionnez Suivant.
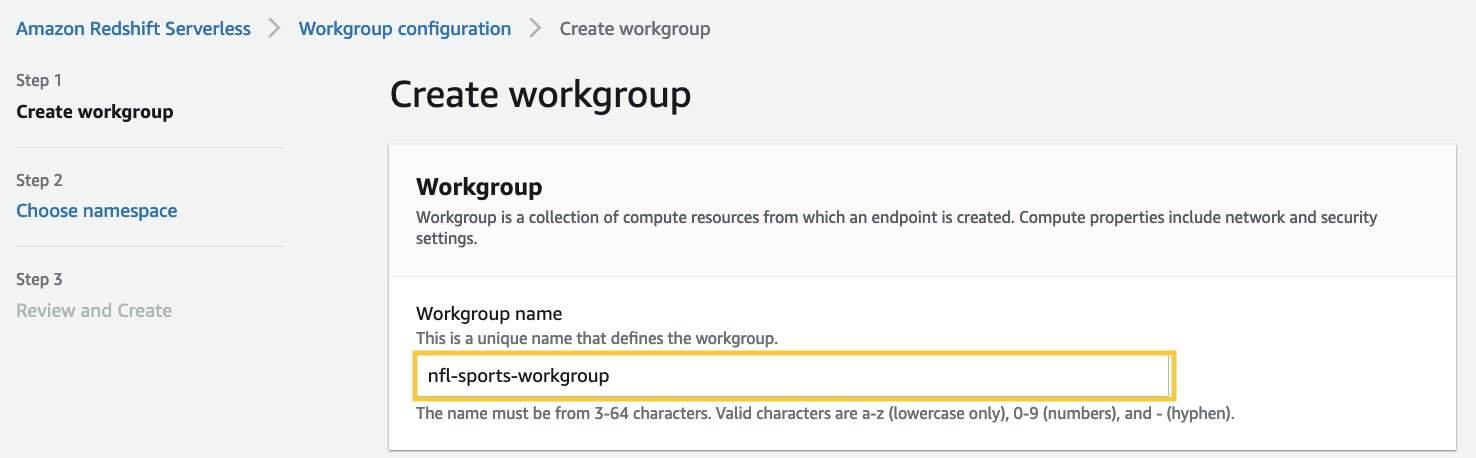
- Pour Nom de l'espace de noms, saisissez un nom qui décrit votre jeu de données.
- In Nom et mot de passe de la base de données section, cochez la case Personnaliser les informations d'identification de l'utilisateur administrateur.
- Pour nom d'utilisateur administrateur, entrez un nom d'utilisateur de votre choix, par exemple awsuser.
- Pour Mot de passe utilisateur administrateur: entrez un mot de passe de votre choix, par exemple MonRedShiftPW2022.
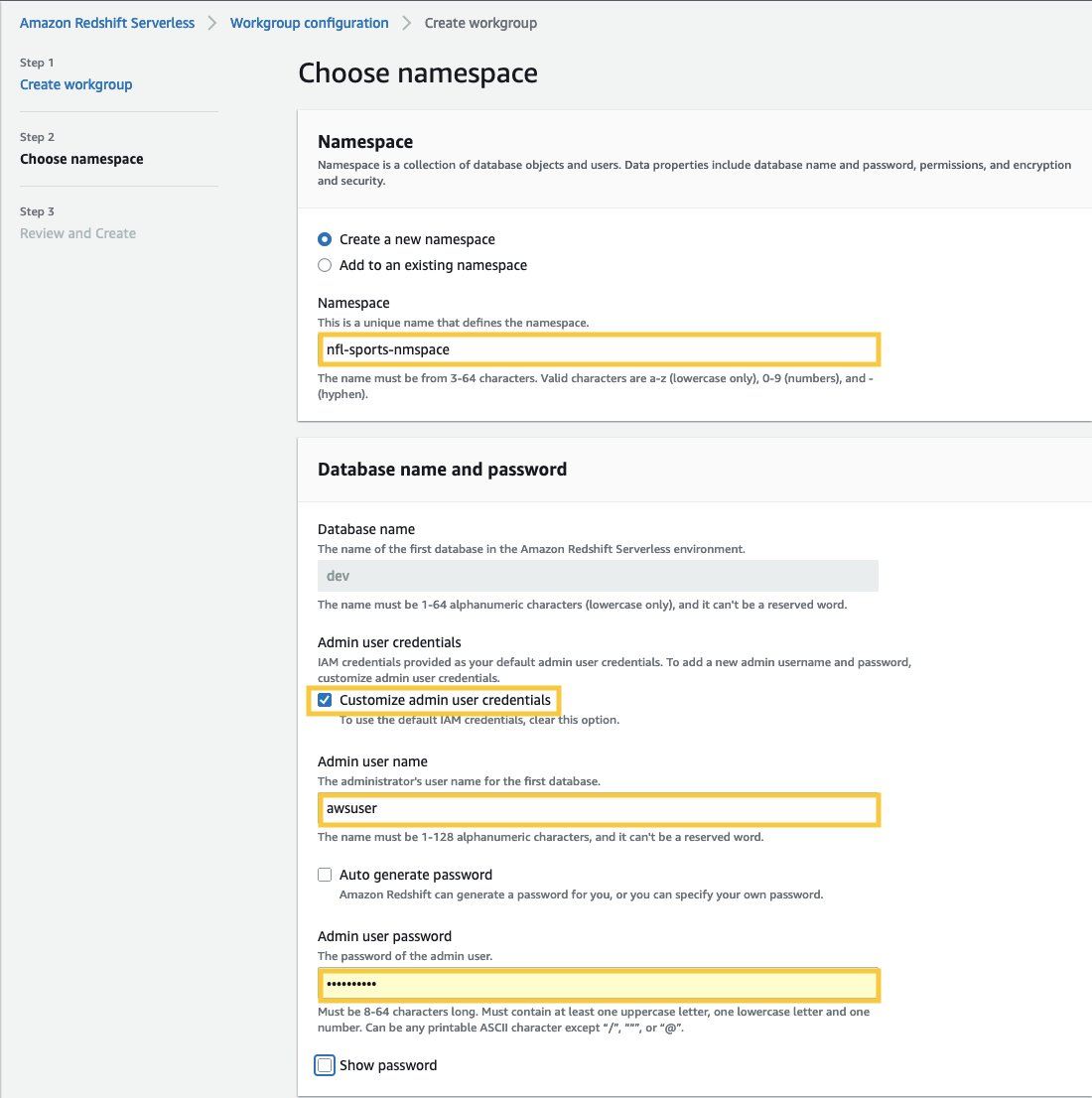
- Selectionnez Suivant. Notez que les données dans l'espace de noms Amazon Redshift Serverless sont chiffrées par défaut.
- Dans le Réviser et créer page, choisissez Création.
- Créer un Gestion des identités et des accès AWS (IAM) et définissez-le comme rôle par défaut sur votre espace de noms, comme décrit ci-dessous. Notez qu'il ne peut y avoir qu'un seul rôle IAM par défaut.
- Accédez à la Tableau de bord sans serveur Amazon Redshift.
- Sous Espaces de noms / Groupes de travail, choisissez l'espace de noms que vous venez de créer.
- Accédez àSécurité et cryptage.
- Sous Permissions, choisissez Gérer les rôles IAM.
- Accédez à Gérer les rôles IAM. Ensuite, choisissez le Gérer les rôles IAM déroulant et choisissez Créer un rôle IAM.
- Sous Spécifiez un compartiment Amazon S3 auquel le rôle IAM doit accéder, choisissez l'une des méthodes suivantes :
- Selectionnez Aucun compartiment Amazon S3 supplémentaire pour autoriser le rôle IAM créé à accéder uniquement aux compartiments S3 dont le nom commence par redshift.
- Selectionnez N'importe quel compartiment Amazon S3 pour autoriser le rôle IAM créé à accéder à tous les compartiments S3.
- Selectionnez Compartiments Amazon S3 spécifiques pour spécifier un ou plusieurs compartiments S3 auxquels le rôle IAM créé doit accéder. Choisissez ensuite un ou plusieurs compartiments S3 dans le tableau.
- Selectionnez Créer un rôle IAM par défaut. Amazon Redshift crée et définit automatiquement le rôle IAM par défaut.
- Capturez le point de terminaison pour le groupe de travail Amazon Redshift Serverless que vous venez de créer.
Créer le compartiment et le dossier S3
Pendant le processus de migration des données, AWS SCT utilise Amazon S3 comme zone intermédiaire pour les données extraites. Suivez ces étapes pour créer le bucket S3 :
- Accédez à la Console Amazon S3
- Selectionnez Créer un seauL’ Créer un seau l'assistant s'ouvre.
- Pour Nom du compartiment, saisissez un nom unique conforme au DNS pour votre compartiment (par exemple, nomunique-bq-rs). Voir les règles de dénomination des buckets lors du choix d'un nom.
- Pour AWS Region, choisissez la région dans laquelle vous avez créé le groupe de travail Amazon Redshift Serverless.
- Sélectionnez Créer un compartiment.
- Dans le Console Amazon S3, accédez au compartiment S3 que vous venez de créer (par exemple, nomunique-bq-rs).
- Selectionnez "Créer le dossier" pour créer un nouveau dossier.
- Pour Nom de dossier, entrer nouveau et choisissez Créer le dossier.
Convertir et appliquer BigQuery Schema à Amazon Redshift à l'aide d'AWS SCT
Pour convertir le schéma BigQuery au format Amazon Redshift, nous utilisons AWS SCT. Commencez par vous connecter à l'instance EC2 que nous avons créée précédemment, puis lancez AWS SCT.
Suivez ces étapes à l'aide d'AWS SCT :
Se connecter à la source BigQuery
- Extrait du Menu Fichier '; '; ; Créer un nouveau projet.
- Choisissez un emplacement pour stocker vos fichiers et données de projet.
- Fournissez un nom significatif mais mémorable pour votre projet, tel que BigQuery vers Amazon Redshift.
- Pour vous connecter à l'entrepôt de données source BigQuery, choisissez Ajouter une source à partir du menu principal.
- Selectionnez BigQuery et choisissez Suivant. le Ajouter une source La boîte de dialogue apparaît.
- Pour Nom de la connexion, saisissez un nom pour décrire la connexion BigQuery. AWS SCT affiche ce nom dans l'arborescence du panneau de gauche.
- Pour Chemin clé, fournissez le chemin du fichier de clé de compte de service qui a été précédemment créé dans la console de gestion Google Cloud.
- Selectionnez Test de connexion pour vérifier qu'AWS SCT peut se connecter à votre projet BigQuery source.
- Une fois la connexion validée avec succès, choisissez NOUS CONTACTER.

Connectez-vous à la cible Amazon Redshift
Suivez ces étapes pour vous connecter à Amazon Redshift :
- Dans AWS SCT, choisissez Ajouter une cible à partir du menu principal.
- Selectionnez Redshift d'Amazon, Puis choisissez Suivant. La Ajouter une cible La boîte de dialogue apparaît.
- Pour Nom de la connexion, entrez un nom pour décrire la connexion Amazon Redshift. AWS SCT affiche ce nom dans l'arborescence du panneau de droite.
- Pour Nom du serveur, entrez le point de terminaison du groupe de travail Amazon Redshift Serverless capturé précédemment.
- Pour Port de serveur, entrer 5439.
- Pour Base de données, entrer dev.
- Pour Nom d'utilisateur, entrez le nom d'utilisateur choisi lors de la création du groupe de travail Amazon Redshift Serverless.
- Pour Mot de Passe, entrez le mot de passe choisi lors de la création du groupe de travail Amazon Redshift Serverless.
- Décocher la case « Utiliser AWS Glue ».
- Selectionnez Test de connexion pour vérifier qu'AWS SCT peut se connecter à votre groupe de travail Amazon Redshift cible.
- Selectionnez NOUS CONTACTER pour se connecter à la cible Amazon Redshift.
Notez que vous pouvez également utiliser des valeurs de connexion stockées dans Gestionnaire de secrets AWS.

Convertir le schéma BigQuery en Amazon Redshift
Une fois les connexions source et cible établies, vous voyez l'arborescence d'objets BigQuery source dans le volet de gauche et l'arborescence d'objets Amazon Redshift cible dans le volet de droite.
Suivez ces étapes pour convertir le schéma BigQuery au format Amazon Redshift :
- Dans le volet de gauche, cliquez avec le bouton droit sur le schéma que vous souhaitez convertir.
- Selectionnez Convertir le schéma.
- Une boîte de dialogue apparaît avec une question, Les objets peuvent déjà exister dans la base de données cible. Remplacer?. Selectionnez Oui.
Une fois la conversion terminée, vous voyez un nouveau schéma créé dans le volet Amazon Redshift (volet de droite) avec le même nom que votre schéma BigQuery.

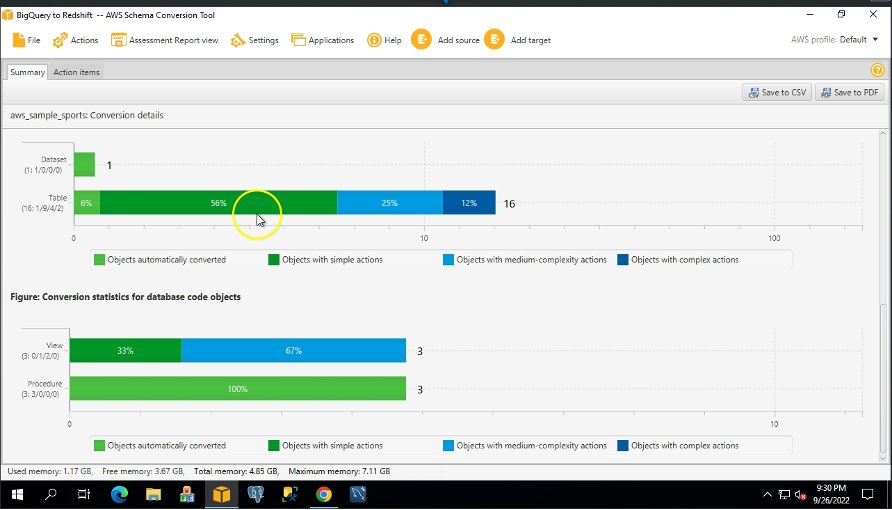
L'exemple de schéma que nous avons utilisé comporte 16 tables, 3 vues et 3 procédures. Vous pouvez voir ces objets au format Amazon Redshift dans le volet de droite. AWS SCT convertit tous les objets de code et de données BigQuery au format Amazon Redshift. De plus, vous pouvez utiliser AWS SCT pour convertir des scripts SQL externes, du code d'application ou des fichiers supplémentaires avec Embedded SQL.
Analyser le rapport d'évaluation et traiter les éléments d'action
AWS SCT crée un rapport d'évaluation pour évaluer la complexité de la migration. AWS SCT peut convertir la majorité des objets de code et de base de données. Cependant, certains objets peuvent nécessiter une conversion manuelle. AWS SCT met en surbrillance ces objets en bleu dans le diagramme des statistiques de conversion et crée des éléments d'action avec une complexité qui leur est attachée.
Pour afficher le rapport d'évaluation, passez du Vue principale à la Vue Rapport d'évaluation comme suit:
La Résumé L'onglet affiche les objets qui ont été convertis automatiquement et les objets qui n'ont pas été convertis automatiquement. Le vert représente automatiquement converti ou avec des éléments d'action simples. Le bleu représente les éléments d'action moyens et complexes qui nécessitent une intervention manuelle.
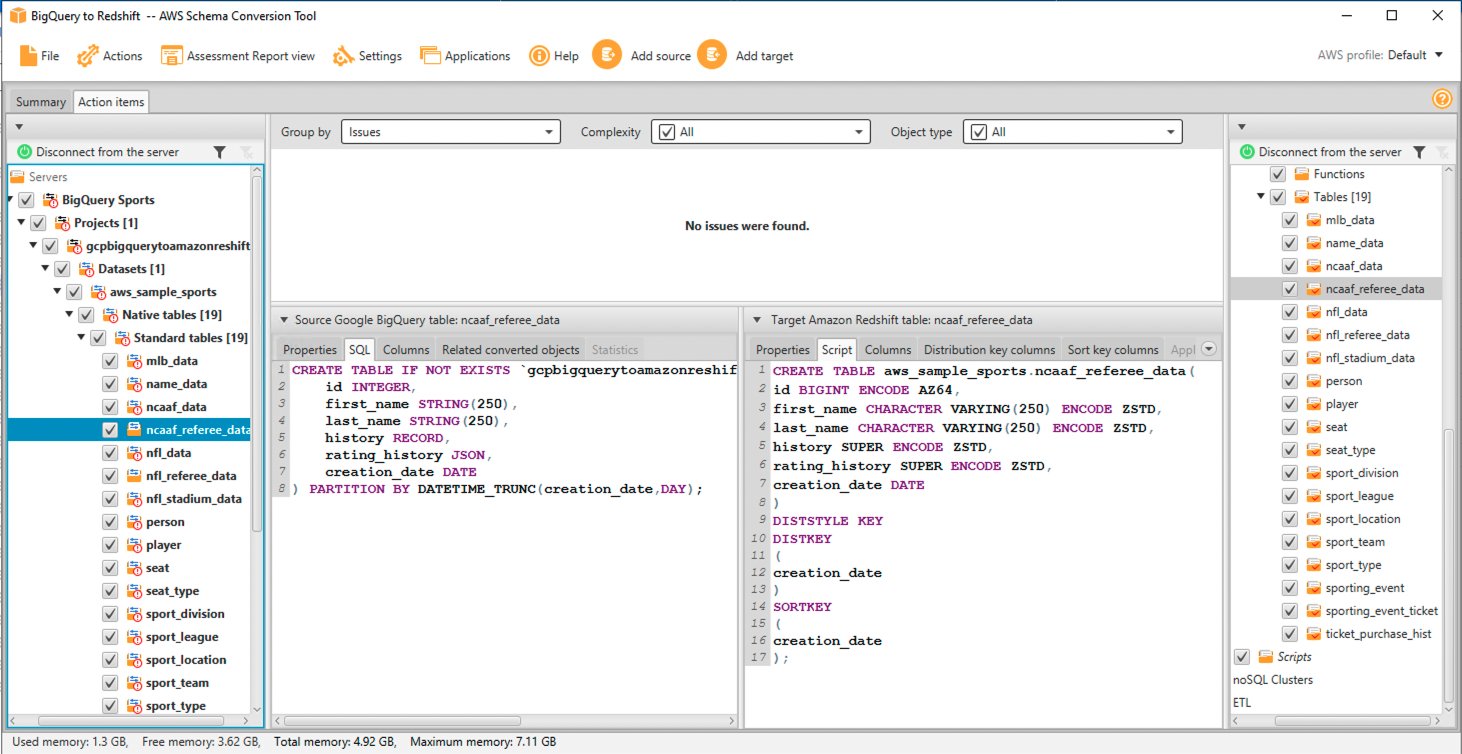
La Éléments d'action affiche les actions recommandées pour chaque problème de conversion. Si vous sélectionnez un élément d'action dans la liste, AWS SCT met en surbrillance l'objet auquel l'élément d'action s'applique.
Le rapport contient également des recommandations sur la manière de convertir manuellement l'élément de schéma. Par exemple, après l'exécution de l'évaluation, des rapports détaillés pour la base de données/le schéma vous montrent l'effort requis pour concevoir et mettre en œuvre les recommandations de conversion des éléments d'action. Pour plus d'informations sur la façon de gérer les conversions manuelles, consultez Gestion des conversions manuelles dans AWS SCT. Amazon Redshift effectue certaines actions automatiquement lors de la conversion du schéma vers Amazon Redshift. Les objets avec ces actions sont marqués d'un signe d'avertissement rouge.

Vous pouvez évaluer et inspecter l'objet DDL individuel en le sélectionnant dans le volet de droite, et vous pouvez également le modifier si nécessaire. Dans l'exemple suivant, AWS SCT modifie les colonnes de type de données RECORD et JSON dans la table BigQuery ncaaf_referee_data en type de données SUPER dans Amazon Redshift. La clé de partition dans la table ncaaf_referee_data est convertie en clé de distribution et clé de tri dans Amazon Redshift.
Appliquer le schéma converti pour cibler Amazon Redshift
Pour appliquer le schéma converti à Amazon Redshift, sélectionnez le schéma converti dans le volet de droite, cliquez avec le bouton droit, puis choisissez Appliquer à la base de données.
Migrer les données de BigQuery vers Amazon Redshift à l'aide des agents d'extraction de données AWS SCT
Les agents d'extraction AWS SCT extraient les données de votre base de données source et les migrent vers le cloud AWS. Dans cette procédure pas à pas, nous montrons comment configurer des agents d'extraction AWS SCT pour extraire des données de BigQuery et migrer vers Amazon Redshift.
Tout d'abord, installez l'agent d'extraction AWS SCT sur la même instance Windows sur laquelle AWS SCT est installé. Pour de meilleures performances, nous vous recommandons d'utiliser une instance Linux distincte pour installer les agents d'extraction si possible. Pour les grands ensembles de données, vous pouvez utiliser plusieurs agents d'extraction de données pour augmenter la vitesse de migration des données.
Génération d'approbations et de magasins de clés (facultatif)
Vous pouvez utiliser la communication chiffrée Secure Socket Layer (SSL) avec les extracteurs de données AWS SCT. Lorsque vous utilisez SSL, toutes les données transmises entre les applications restent privées et intégrales. Pour utiliser la communication SSL, vous devez générer des magasins de confiance et de clés à l'aide d'AWS SCT. Vous pouvez ignorer cette étape si vous ne souhaitez pas utiliser SSL. Nous vous recommandons d'utiliser SSL pour les charges de travail de production.
Suivez ces étapes pour générer des approbations et des magasins de clés :
- Dans AWS SCT, accédez à Paramètres → Paramètres globaux → Sécurité.
- Selectionnez Générer la confiance et le magasin de clés.

- Entrez le nom et le mot de passe pour les magasins de confiance et de clés et choisissez un emplacement où vous souhaitez les stocker.

- Selectionnez Générer.
Installer et configurer l'agent d'extraction de données
Dans le package d'installation d'AWS SCT, vous trouverez un sous-dossier agent (aws-schema-conversion-tool-1.0.latest.zipagents). Localisez et installez le fichier exécutable avec un nom comme aws-schema-conversion-tool-extractor-xxxxxxxx.msi.
Dans le processus d'installation, suivez ces étapes pour configurer AWS SCT Data Extractor :
- Pour Port d'écoute, entrez le numéro de port sur lequel l'agent écoute. C'est 8192 par défaut.
- Pour Ajouter un fournisseur source, Entrer non, car vous n'avez pas besoin de pilotes pour vous connecter à BigQuery.
- Pour Ajouter le pilote Amazon Redshift, Entrer OUI.
- Pour Entrez le ou les fichiers du pilote Redshift JDBC, entrez l'emplacement où vous avez téléchargé les pilotes Amazon Redshift JDBC.
- Pour Dossier de travail, entrez le chemin où l'agent d'extraction de données AWS SCT stockera les données extraites. Le dossier de travail peut se trouver sur un ordinateur différent de celui de l'agent, et un seul dossier de travail peut être partagé par plusieurs agents sur différents ordinateurs.
- Pour Activer la communication SSL, Entrer Oui. Choisissez Non ici si vous ne souhaitez pas utiliser SSL.
- Pour Magasin de clés, entrez l'emplacement de stockage choisi lors de la création de la confiance et du magasin de clés.
- Pour Mot de passe du magasin de clés, saisissez le mot de passe du magasin de clés.
- Pour Activer l'authentification SSL client, Entrer Oui.
- Pour Magasin de confiance, entrez l'emplacement de stockage choisi lors de la création de la confiance et du magasin de clés.
- Pour Mot de passe du magasin de confiance, entrez le mot de passe du magasin de confiance.
Démarrage des agents d'extraction de données
Utilisez la procédure suivante pour démarrer les agents d'extraction. Répétez cette procédure sur chaque ordinateur sur lequel un agent d'extraction est installé.
Les agents d'extraction jouent le rôle d'auditeurs. Lorsque vous démarrez un agent avec cette procédure, l'agent commence à écouter les instructions. Vous envoyez aux agents des instructions pour extraire les données de votre entrepôt de données dans une section ultérieure.
Pour démarrer l'agent d'extraction, accédez au répertoire AWS SCT Data Extractor Agent. Par exemple, dans Microsoft Windows, double-cliquez sur C:Program FilesAWS SCT Data Extractor AgentStartAgent.bat.
- Sur l'ordinateur sur lequel l'agent d'extraction est installé, à partir d'une invite de commande ou d'une fenêtre de terminal, exécutez la commande indiquée après votre système d'exploitation.
- Pour vérifier l'état de l'agent, exécutez la même commande mais remplacez start par status.
- Pour arrêter un agent, exécutez la même commande mais remplacez start par stop.
- Pour redémarrer un agent, exécutez le même fichier RestartAgent.bat.
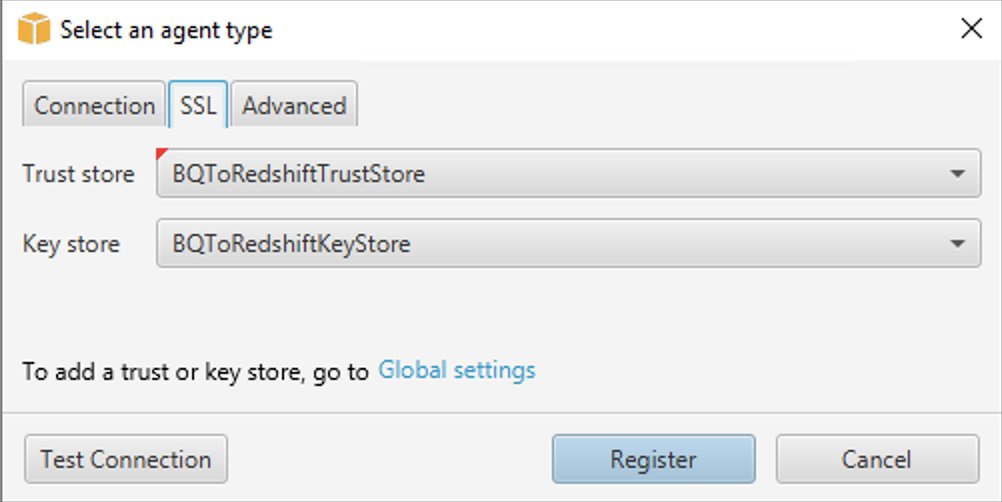
Enregistrer l'agent d'extraction de données
Suivez ces étapes pour enregistrer l'agent d'extraction de données :
- Dans AWS SCT, changez la vue en Vue Migration des données (autre) et choisissez + S'inscrire.
- Dans l'onglet connexion :

- Pour Description, entrez un nom pour identifier l'agent d'extraction de données.
- Pour Nom d'hôte, si vous avez installé l'agent d'extraction de données sur le même poste de travail qu'AWS SCT, entrez 0.0.0.0 pour indiquer l'hôte local. Sinon, entrez le nom d'hôte de la machine sur laquelle l'agent d'extraction de données AWS SCT est installé. Il est recommandé d'installer les agents d'extraction de données sur Linux pour de meilleures performances.
- Pour Port, entrez le numéro saisi pour le Port d'écoute lors de l'installation de l'agent d'extraction de données AWS SCT.
- Cochez la case pour utiliser SSL (si vous utilisez SSL) pour chiffrer la connexion AWS SCT à l'agent d'extraction de données.
- Si vous utilisez SSL, alors dans l'onglet SSL :
- Pour Magasin de confiance, choisissez le nom du magasin de confiance créé lorsque générer des magasins de confiance et de clés (éventuellement, vous pouvez ignorer cette opération si la connectivité SSL n'est pas nécessaire).
- Pour magasin de clés, choisissez le nom du magasin de clés créé lorsque générer des magasins de confiance et de clés (éventuellement, vous pouvez ignorer cette opération si la connectivité SSL n'est pas nécessaire).

- Selectionnez Test de connexion.
- Une fois la connexion validée avec succès, choisissez Inscription.
Ajouter des partitions virtuelles pour les grandes tables (facultatif)
Vous pouvez utiliser AWS SCT pour créer des partitions virtuelles afin d'optimiser les performances de migration. Lorsque des partitions virtuelles sont créées, AWS SCT extrait les données en parallèle pour les partitions. Nous vous recommandons de créer des partitions virtuelles pour les grandes tables.
Suivez ces étapes pour créer des partitions virtuelles :
- Désélectionnez tous les objets sur la vue de la base de données source dans AWS SCT.
- Choisissez la table pour laquelle vous souhaitez ajouter un partitionnement virtuel.
- Faites un clic droit sur le tableau et choisissez Ajouter un partitionnement virtuel.

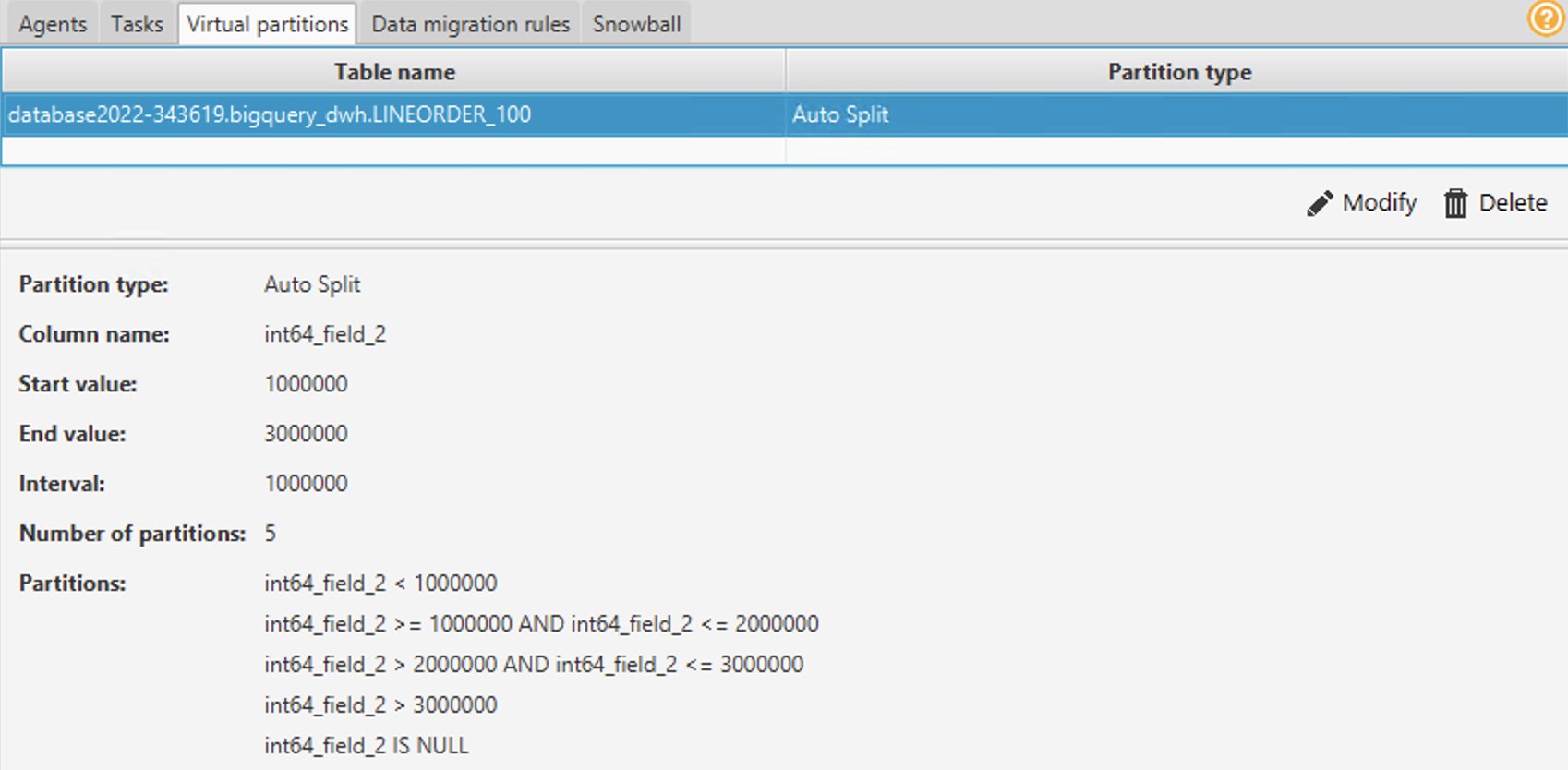
- Vous pouvez utiliser les partitions List, Range ou Auto Split. Pour en savoir plus sur le partitionnement virtuel, reportez-vous à Utiliser le partitionnement virtuel dans AWS SCT. Dans cet exemple, nous utilisons le partitionnement fractionné automatique, qui génère automatiquement des partitions de plage. Vous spécifiez la valeur de début, la valeur de fin et la taille de la partition. AWS SCT détermine automatiquement les partitions. Pour une démonstration, sur la table Lineorder :
- Pour Valeur de départ, entrez 1000000.
- Pour Valeur finale, entrez 3000000.
- Pour intervalle, entrez 1000000 pour indiquer la taille de la partition.
- Selectionnez D'accord.

Vous pouvez voir les partitions générées automatiquement sous le Partitions virtuelles languette. Dans cet exemple, AWS SCT a automatiquement créé les cinq partitions suivantes pour le champ :
-
- >=1000000 et <=2000000
- > 2000000 et <= 3000000
- > 3000000
- EST NULL
Créer une tâche de migration locale
Pour migrer des données de BigQuery vers Amazon Redshift, créez, exécutez et surveillez la tâche de migration locale depuis AWS SCT. Cette étape utilise l'agent d'extraction de données pour migrer les données en créant une tâche.
Suivez ces étapes pour créer une tâche de migration locale :
- Dans AWS SCT, sous le nom du schéma dans le volet de gauche, cliquez avec le bouton droit sur Tableaux standards.
- Selectionnez Créer une tâche locale.

- Il existe trois modes de migration parmi lesquels vous pouvez choisir :
- Extrayez les données source et stockez-les sur un PC/machine virtuelle (VM) local sur lequel l'agent s'exécute.
- Extrayez les données et chargez-les sur un compartiment S3.
- Choisissez Extract upload and copy, qui extrait les données dans un compartiment S3, puis les copie dans Amazon Redshift.

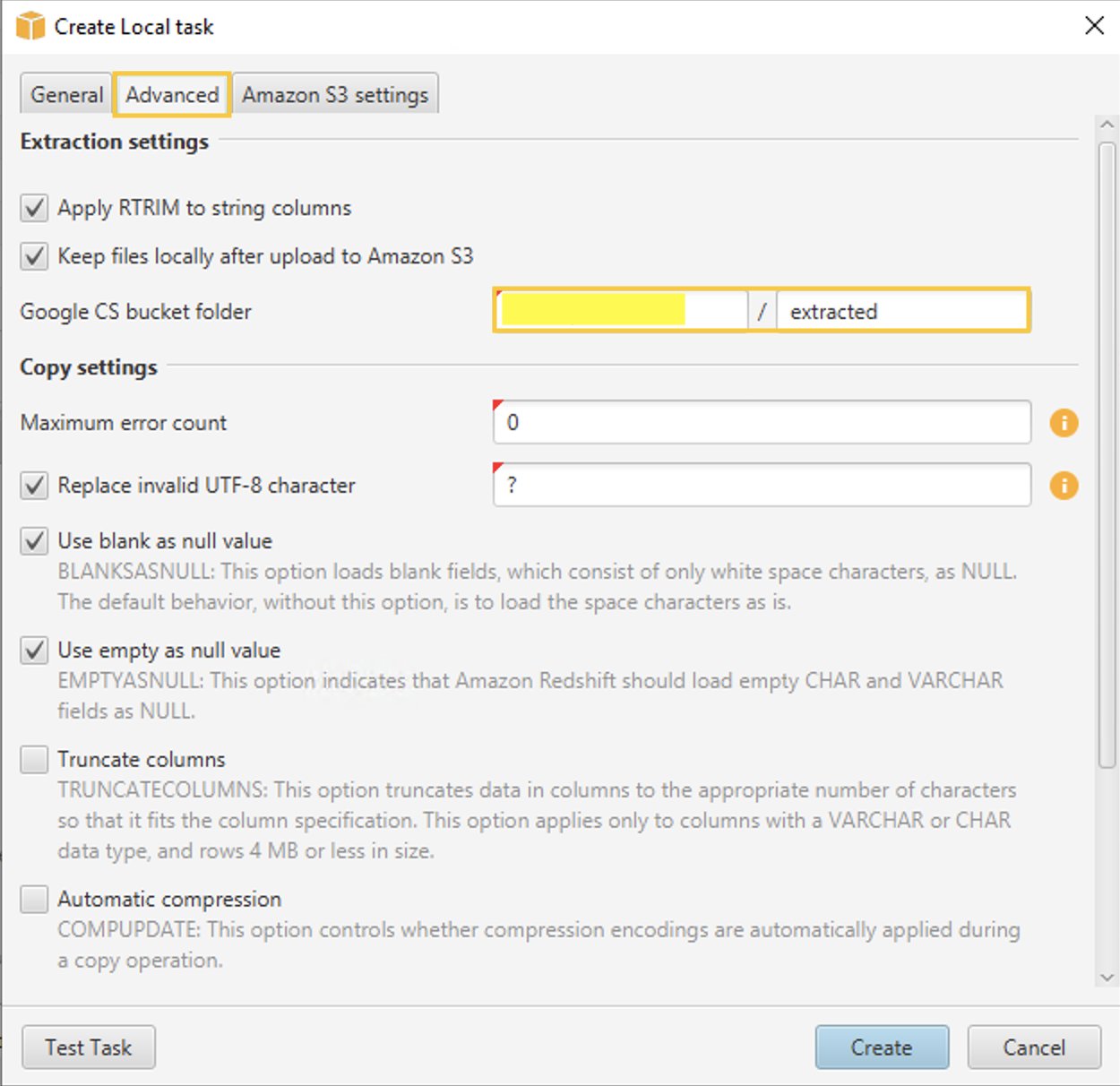
- Dans le Avancé onglet, pour Dossier de compartiment Google CS saisissez le bucket/dossier Google Cloud Storage que vous avez créé précédemment dans la console de gestion GCP. AWS SCT stocke les données extraites à cet emplacement.
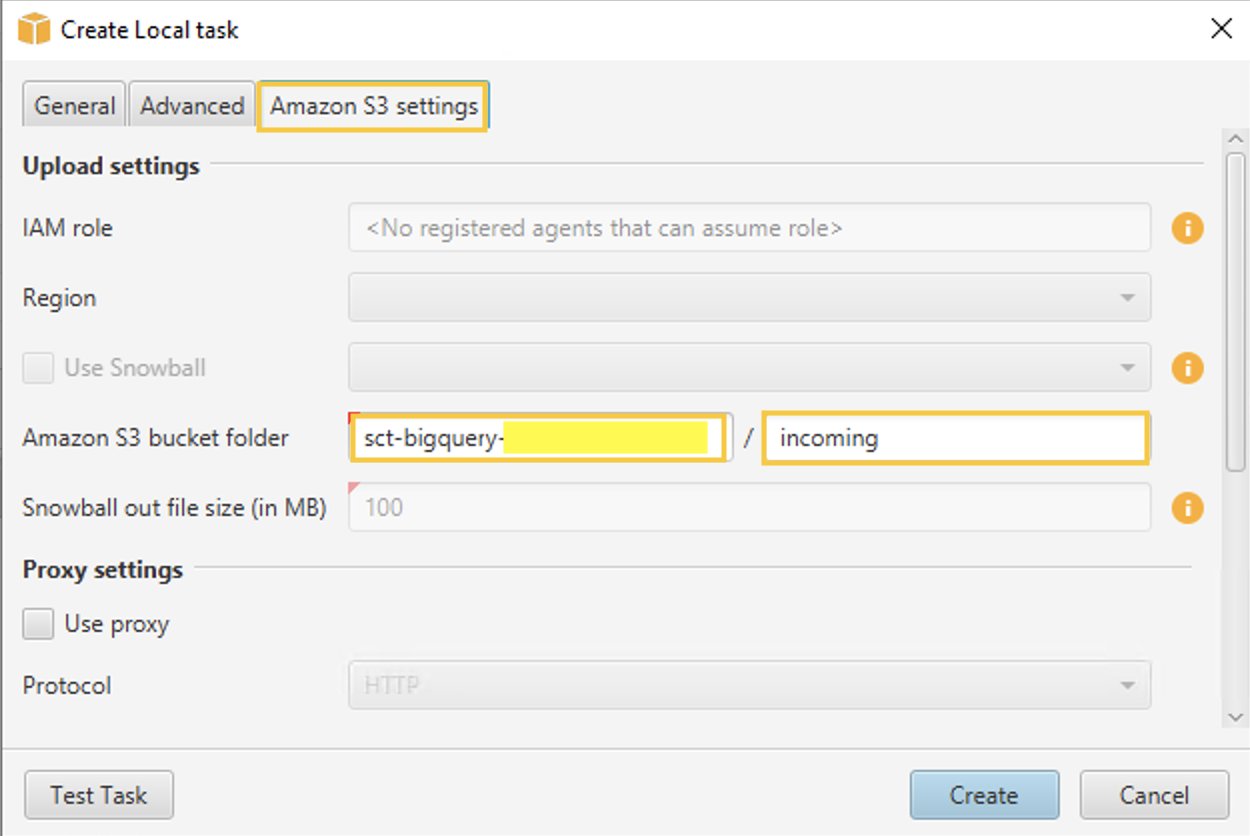
- Dans le Paramètres Amazon S3 onglet, pour dossier de compartiment Amazon S3, fournissez les noms de compartiment et de dossier du compartiment S3 que vous avez créé précédemment. L'agent d'extraction de données AWS SCT charge les données dans le compartiment/dossier S3 avant de les copier vers Amazon Redshift.
- Selectionnez Tâche d'essai.
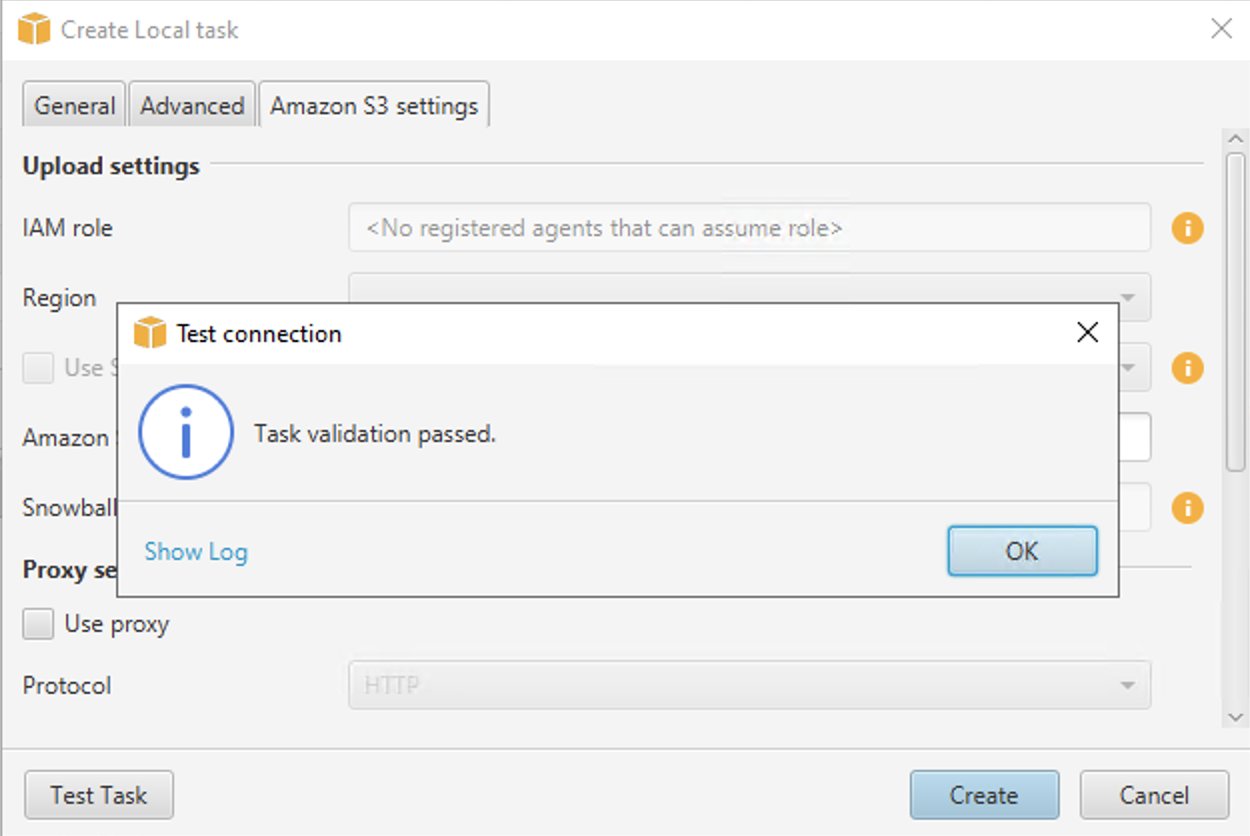
- Une fois la tâche validée avec succès, choisissez Création.
Démarrer la tâche de migration des données locales
Pour démarrer la tâche, choisissez le Accueil bouton dans le Tâches languette.

- Tout d'abord, l'agent d'extraction de données extrait les données de BigQuery dans le bucket de stockage GCP.
- Ensuite, l'agent charge les données sur Amazon S3 et lance une commande de copie pour déplacer les données vers Amazon Redshift.
- À ce stade, AWS SCT a réussi à migrer les données de la table BigQuery source vers la table Amazon Redshift.
Afficher les données dans Amazon Redshift
Une fois la tâche de migration des données exécutée avec succès, vous pouvez vous connecter à Amazon Redshift et valider les données.
Suivez ces étapes pour valider les données dans Amazon Redshift :
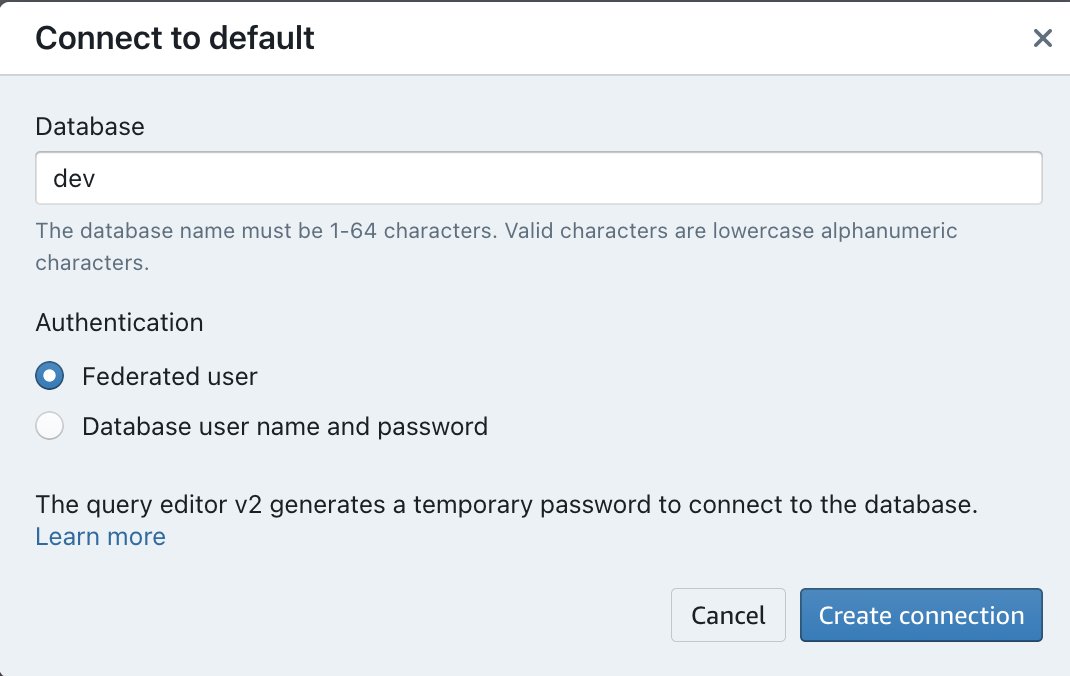
- Accédez à la Éditeur de requête Amazon Redshift V2.
- Double-cliquez sur le nom du groupe de travail Amazon Redshift Serverless que vous avez créé.
- Choisissez le Utilisateur fédéré option sous Authentification.
- Selectionnez Créer une connexion.
- Créez un nouvel éditeur en choisissant le + icône.
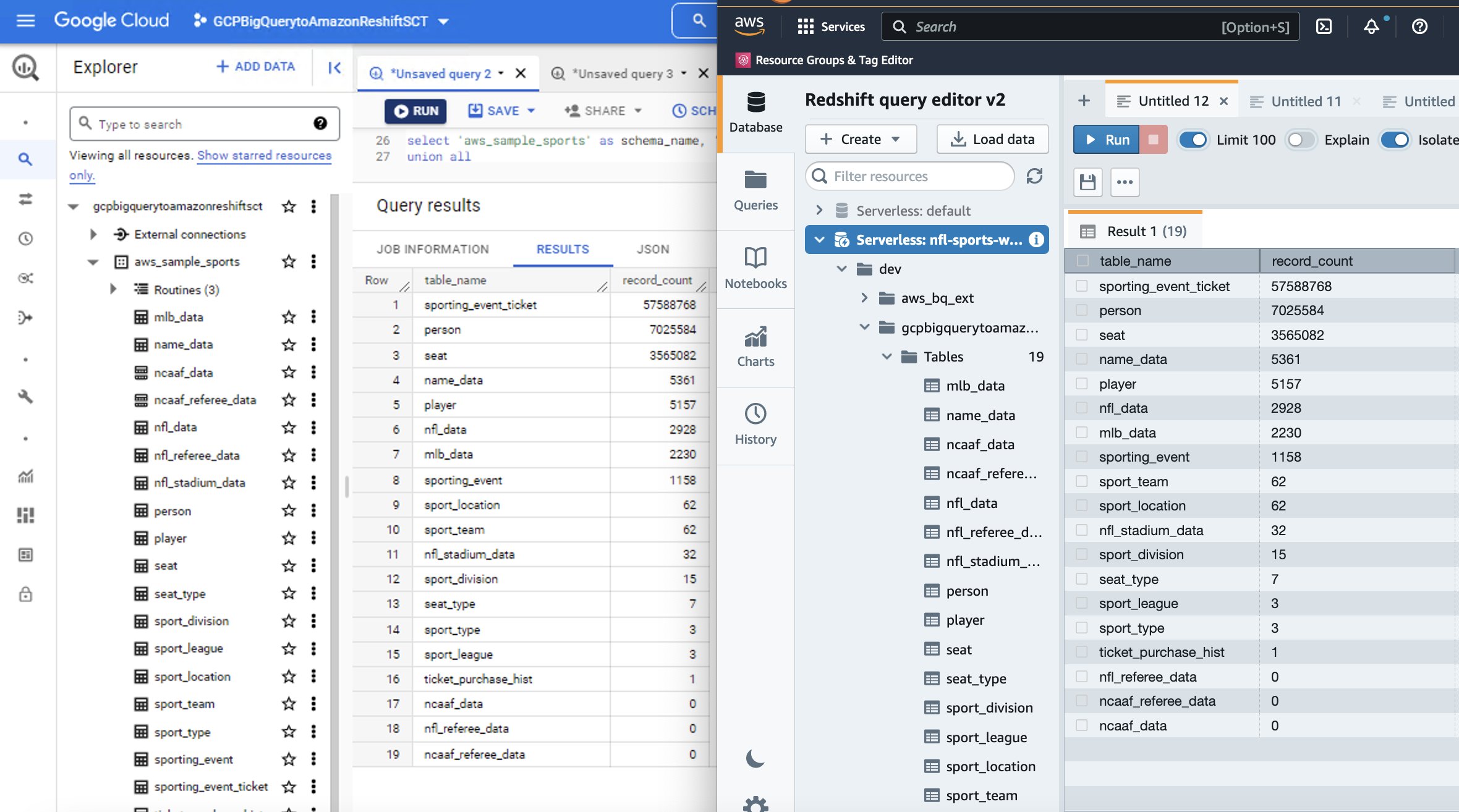
- Dans l'éditeur, écrivez une requête pour sélectionner le nom du schéma et le nom de la table/nom de la vue que vous souhaitez vérifier. Explorez les données, exécutez des requêtes ad hoc et créez des visualisations, des graphiques et des vues.

Voici une comparaison côte à côte entre la source BigQuery et la cible Amazon Redshift pour l'ensemble de données sportives que nous avons utilisé dans cette procédure pas à pas.
Nettoyez toutes les ressources AWS que vous avez créées pour cet exercice
Suivez ces étapes pour résilier l'instance EC2 :
- Accédez à la Console Amazon EC2.
- Dans le volet de navigation, choisissez Cas.
- Cochez la case de l'instance EC2 que vous avez créée.
- Selectionnez État de l'instance, et alors Mettre fin à l'instance.
- Selectionnez Mettre fin lorsque vous êtes invité à confirmer.
Suivez ces étapes pour supprimer le groupe de travail et l'espace de noms Amazon Redshift Serverless
- Accédez à Tableau de bord sans serveur Amazon Redshift.
- Sous Espaces de noms / Groupes de travail, choisissez l'espace de travail que vous avez créé.
- Sous Actions, choisissez Supprimer le groupe de travail.
- Cochez la case Supprimez l'espace de noms associé.
- Décocher Créez l'instantané final.
- Entrer effacer dans la zone de texte de confirmation de suppression et choisissez Supprimer.

Suivez ces étapes pour supprimer le compartiment S3
- Accédez à Console Amazon S3.
- Choisissez le bucket que vous avez créé.
- Selectionnez Supprimer.
- Pour confirmer la suppression, saisissez le nom du compartiment dans le champ de saisie de texte.
- Selectionnez Supprimer le bucket.
Conclusion
La migration d'un entrepôt de données peut être un projet difficile, complexe et pourtant gratifiant. AWS SCT réduit la complexité des migrations d'entrepôts de données. En suivant cette procédure pas à pas, vous pouvez comprendre comment une tâche de migration de données extrait, télécharge, puis migre des données de BigQuery vers Amazon Redshift. La solution que nous avons présentée dans cet article effectue une migration unique des objets et des données de la base de données. Les modifications de données effectuées dans BigQuery lorsque la migration est en cours ne seront pas reflétées dans Amazon Redshift. Lorsque la migration des données est en cours, mettez vos tâches ETL vers BigQuery en attente ou réexécutez les ETL en pointant vers Amazon Redshift après la migration. Pensez à utiliser le bonnes pratiques pour AWS SCT.
AWS SCT présente certaines limitations lors de l'utilisation de BigQuery en tant que source. Par exemple, AWS SCT ne peut pas convertir les sous-requêtes en fonctions analytiques, fonctions géographiques, fonctions d'agrégation statistiques, etc. Retrouvez la liste complète des limitations dans le Guide de l'utilisateur AWS SCT. Nous prévoyons de remédier à ces limitations dans les prochaines versions. Malgré ces limitations, vous pouvez utiliser AWS SCT pour convertir automatiquement la plupart de votre code BigQuery et de vos objets de stockage.
Téléchargez et installez AWS SCT, connectez-vous au AWS Console, découvrez Amazon Redshift Serverless et commencez à migrer !
À propos des auteurs
 Cédrick Sweat à capuche est un architecte de solutions spécialisé dans les migrations de bases de données à l'aide d'AWS Database Migration Service (DMS) et d'AWS Schema Conversion Tool (SCT) chez AWS. Il travaille sur les défis liés aux migrations de bases de données. Il travaille en étroite collaboration avec les clients du secteur des entreprises EdTech, Energy et ISV pour les aider à réaliser le véritable potentiel du service DMS. Il a aidé à migrer des centaines de bases de données vers le cloud AWS à l'aide de DMS et SCT.
Cédrick Sweat à capuche est un architecte de solutions spécialisé dans les migrations de bases de données à l'aide d'AWS Database Migration Service (DMS) et d'AWS Schema Conversion Tool (SCT) chez AWS. Il travaille sur les défis liés aux migrations de bases de données. Il travaille en étroite collaboration avec les clients du secteur des entreprises EdTech, Energy et ISV pour les aider à réaliser le véritable potentiel du service DMS. Il a aidé à migrer des centaines de bases de données vers le cloud AWS à l'aide de DMS et SCT.
 Amit Arora est un architecte de solutions spécialisé dans les bases de données et l'analyse chez AWS. Il travaille avec nos clients Financial Technology et Global Energy et nos partenaires certifiés AWS pour fournir une assistance technique et concevoir des solutions client sur des projets de migration vers le cloud, aidant les clients à migrer et à moderniser leurs bases de données existantes vers le cloud AWS.
Amit Arora est un architecte de solutions spécialisé dans les bases de données et l'analyse chez AWS. Il travaille avec nos clients Financial Technology et Global Energy et nos partenaires certifiés AWS pour fournir une assistance technique et concevoir des solutions client sur des projets de migration vers le cloud, aidant les clients à migrer et à moderniser leurs bases de données existantes vers le cloud AWS.
 Jagadish Kumar est un architecte de solution spécialiste de l'analyse chez AWS, spécialisé dans Amazon Redshift. Il est profondément passionné par l'architecture de données et aide les clients à créer des solutions d'analyse à grande échelle sur AWS.
Jagadish Kumar est un architecte de solution spécialiste de l'analyse chez AWS, spécialisé dans Amazon Redshift. Il est profondément passionné par l'architecture de données et aide les clients à créer des solutions d'analyse à grande échelle sur AWS.
 Anusha Challa est un architecte de solution spécialiste principal de l'analytique chez AWS, spécialisé dans Amazon Redshift. Elle a aidé de nombreux clients à créer des solutions d'entrepôt de données à grande échelle dans le cloud et sur site. Anusha est passionnée par l'analyse de données et la science des données et permet aux clients de réussir leurs projets de données à grande échelle.
Anusha Challa est un architecte de solution spécialiste principal de l'analytique chez AWS, spécialisé dans Amazon Redshift. Elle a aidé de nombreux clients à créer des solutions d'entrepôt de données à grande échelle dans le cloud et sur site. Anusha est passionnée par l'analyse de données et la science des données et permet aux clients de réussir leurs projets de données à grande échelle.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/migrate-google-bigquery-to-amazon-redshift-using-aws-schema-conversion-tool-sct/
- 1
- 10
- 100
- 9
- a
- A Propos
- accès
- Compte
- atteindre
- Agis
- Action
- actes
- Supplémentaire
- propos
- admin
- Après
- Agent
- agents
- Tous
- déjà
- Amazon
- Analytique
- Analytique
- analytique
- ainsi que le
- Application
- applications
- Appliquer
- architecture
- Réservé
- Évaluation de risque climatique
- Assistance
- associé
- Authentification
- auto
- automatiquement
- AWS
- base
- MTD
- before
- profiter
- Améliorée
- jusqu'à XNUMX fois
- Big
- Bleu
- Box
- construire
- la performance des entreprises
- bouton (dans la fenêtre de contrôle qui apparaît maintenant)
- Peut obtenir
- ne peut pas
- capacités
- Compétences
- Support et maintenance de Salesforce
- globaux
- difficile
- Change
- Modifications
- Charts
- vérifier
- Passer au paiement
- le choix
- Selectionnez
- choose
- choisi
- clairement
- client
- étroitement
- le cloud
- stockage cloud
- code
- collection
- Colonne
- Colonnes
- Communication
- Comparaison
- compatible
- complet
- complexe
- complexité
- calcul
- ordinateur
- ordinateurs
- configuration
- Confirmer
- NOUS CONTACTER
- connexion
- Connexions
- Connectivité
- Considérer
- cohérent
- Console
- contient
- contrôles
- Conversion
- conversions
- convertir
- converti
- copier
- Prix
- rentable
- engendrent
- créée
- crée des
- La création
- crédit
- des clients
- Solutions clients
- Clients
- données
- Analyse de Donnée
- science des données
- partage de données
- Base de données
- bases de données
- ensembles de données
- Décider
- Réglage par défaut
- Demande
- déployer
- décrire
- décrit
- Conception
- à poser
- Malgré
- détaillé
- détermine
- dialogue
- différent
- affiche
- distribution
- Ne pas
- download
- téléchargements
- driver
- conducteurs
- pendant
- chacun
- Plus tôt
- facile à utiliser
- éditeur
- effort
- intégré
- permettre
- permet
- permettant
- crypté
- chiffrement
- end-to-end
- Endpoint
- énergie
- Entrer
- entré
- Environment
- Ether (ETH)
- évaluer
- exemple
- Exécute
- existant
- explorez
- externe
- supplémentaire
- extrait
- Extraits
- familier
- RAPIDE
- plus rapide
- few
- champ
- Déposez votre dernière attestation
- Fichiers
- finale
- finalement
- la traduction de documents financiers
- technologie financière
- Trouvez
- pare-feu
- Prénom
- Flexibilité
- Focus
- concentré
- suivre
- Abonnement
- suit
- le format
- Gratuit
- De
- plein
- fonctions
- En outre
- avenir
- générer
- généré
- génère
- géographie
- obtenez
- Global
- Google Cloud
- Vert
- manipuler
- Matériel
- vous aider
- a aidé
- aider
- aide
- ici
- Haute
- Faits saillants
- très
- appuyez en continu
- Accueil
- hôte
- HEURES
- Villa
- Comment
- How To
- Cependant
- HTML
- HTTPS
- ICON
- identifier
- Identite
- Mettre en oeuvre
- in
- Améliore
- indiquer
- individuel
- d'information
- contribution
- idées.
- installer
- installer
- instance
- Des instructions
- intégrale
- Intègre
- interagir
- interférer
- intervention
- aide
- IT
- articles
- Emploi
- Emplois
- json
- ACTIVITES
- Genre
- gros
- grande échelle
- Nouveautés
- lancer
- lance
- couche
- APPRENTISSAGE
- Allons-y
- Niveau
- limites
- linux
- Liste
- Listé
- Écoute
- charge
- locales
- emplacement
- click
- LES PLANTES
- Entrée
- Majorité
- a prendre une
- FAIT DU
- gérer
- gestion
- manager
- les gérer
- Manuel
- manuellement
- de nombreuses
- significative
- moyenne
- Se rencontre
- Menu
- méthodes
- Microsoft
- Microsoft Windows
- pourrait
- émigrer
- migration
- ML
- numériques jumeaux (digital twin models)
- Villas Modernes
- moderniser
- Surveiller
- PLUS
- (en fait, presque toutes)
- Bougez
- msi
- plusieurs
- prénom
- noms
- nommage
- NAVIGUER
- Navigation
- Besoin
- Nouveauté
- next
- notable
- nombre
- objet
- objets
- Offres Speciales
- ONE
- ouvre
- d'exploitation
- le système d'exploitation
- Optimiser
- Autre
- autrement
- paquet
- pain
- panneau
- Parallèle
- partenaires,
- passé
- passionné
- Mot de Passe
- chemin
- Payer
- Courant
- effectuer
- performant
- effectue
- plan
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- possible
- Post
- défaillances
- pratiques
- Prévisible
- Prédictions
- conditions préalables
- présenté
- précédemment
- Privé
- procédures
- processus
- Vidéo
- Programme
- Progrès
- Projet
- projets
- fournir
- fournit
- mettre
- question
- vite.
- gamme
- réaliser
- recommander
- recommandations
- recommandé
- record
- Rouge
- réduit
- reflété
- région
- vous inscrire
- en relation
- de Presse
- reste
- répéter
- remplacer
- remplacé
- répliquées
- rapport
- Rapports
- représente
- demandes
- exigent
- conditions
- résilient
- Resources
- récompense
- Rich
- Faites un clic droit
- Rôle
- rôle
- RANGÉE
- Courir
- même
- évolutive
- Escaliers intérieurs
- Balance
- mise à l'échelle
- balayage
- Sciences
- scientifiques
- scripts
- de façon transparente
- secondes
- Section
- secteur
- sécurisé
- sécurité
- la sélection
- sensible
- Sans serveur
- service
- Services
- set
- Sets
- mise
- Paramétres
- plusieurs
- commun
- partage
- devrait
- montrer
- Spectacles
- signer
- étapes
- unique
- Taille
- Instantané
- So
- sur mesure
- Solutions
- quelques
- Identifier
- spécialiste
- vitesse
- Dépenses
- scission
- Sports
- SSL
- mise en scène
- Commencer
- Commencez
- départs
- déclarations
- statistique
- statistiques
- Statut
- étapes
- Étapes
- Arrêter
- storage
- Boutique
- stockée
- STORES
- succès
- Avec succès
- tel
- Super
- Interrupteur
- combustion propre
- table
- Prenez
- prend
- Target
- Tâche
- Technique
- Technologie
- terminal
- La
- La Source
- leur
- des tiers.
- trois
- fiable
- fois
- à
- tolérance
- outil
- les outils
- traditionnel
- Train
- Transformer
- oui
- La confiance
- sous
- sous-jacent
- comprendre
- expérience unique et authentique
- Utilisation
- utilisé
- Utilisateur
- utilisateurs
- VALIDER
- validé
- Précieux
- Plus-value
- Valeurs
- vendeur
- fournisseurs
- vérifier
- version
- Voir
- vues
- Salle de conférence virtuelle
- walkthrough
- avertissement
- web
- Quoi
- qui
- tout en
- plus large
- sera
- fenêtres
- dans les
- sans
- Groupe De Travail
- de travail
- vos contrats
- poste de travail
- pourra
- écrire
- code écrit
- Votre
- zéphyrnet