Introduction
La fusion de intelligence artificielle (IA) et l’art dévoilent de nouvelles voies dans l’art numérique créatif, notamment à travers des modèles de diffusion. Ces modèles se démarquent dans la génération artistique créative de l’IA, offrant une approche distincte des réseaux de neurones conventionnels. Cet article vous emmène dans un voyage exploratoire dans les profondeurs des modèles de diffusion, élucidant leur mécanisme unique dans la création d'œuvres d'art visuellement époustouflantes et riches en créativité. Comprenez les nuances des modèles de diffusion et obtenez un aperçu de leur rôle dans la redéfinition de l'expression artistique à travers le prisme des technologies avancées d'IA.

Objectifs d'apprentissage
- Comprendre les concepts fondamentaux des modèles de diffusion en IA.
- Explorez la distinction entre les modèles de diffusion et les réseaux de neurones traditionnels dans la génération artistique.
- Analyser le processus de création artistique à l'aide de modèles de diffusion.
- Évaluer les implications créatives et esthétiques de l’IA dans l’art numérique.
- Discutez des considérations éthiques dans les œuvres d’art générées par l’IA.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Comprendre les modèles de diffusion

Les modèles de diffusion révolutionnent l'IA générative, présentant une méthode de création d'images unique, distincte des techniques conventionnelles telles que les réseaux contradictoires génératifs (GAN). En commençant par un bruit aléatoire, ces modèles l'affine progressivement, à la manière d'un artiste peaufinant un tableau, ce qui donne lieu à des images complexes et cohérentes.
Ce processus de raffinement progressif reflète la nature méthodique de la diffusion. Ici, chaque itération modifie subtilement le bruit, le rapprochant de la vision artistique finale. Le résultat n’est pas simplement un produit aléatoire mais une œuvre d’art évoluée, distincte dans sa progression et sa finition.
Le codage des modèles de diffusion nécessite une compréhension approfondie des réseaux de neurones et des cadres d'apprentissage automatique tels que TensorFlow ou PyTorch. Le code résultant est complexe, nécessitant une formation approfondie sur de vastes ensembles de données pour obtenir les effets nuancés observés dans l’art généré par l’IA.
Application de la diffusion stable dans l’art
L’avènement des générateurs d’art IA comme les modèles de diffusion stables nécessite un codage sophistiqué au sein de plateformes telles que TensorFlow ou PyTorch. Ces modèles se distinguent par leur capacité à transformer méthodiquement le hasard en structure, un peu comme un artiste qui peaufine une esquisse préliminaire pour en faire un chef-d'œuvre éclatant.
Les modèles de diffusion stables remodèlent la scène artistique de l’IA en sculptant des images ordonnées à partir du hasard, évitant ainsi la dynamique concurrentielle caractéristique des GAN. Ils excellent dans l’interprétation des invites conceptuelles dans les arts visuels, favorisant une danse synergique entre les capacités de l’IA et l’ingéniosité humaine. En exploitant PyTorch, nous observons comment ces modèles affinent de manière itérative le chaos en clarté, reflétant le parcours de l’artiste d’une idée naissante à une création raffinée.
Expérimenter l'art généré par l'IA
Cette démonstration plonge dans le monde fascinant de l'art généré par l'IA à l'aide d'un réseau neuronal convolutif appelé le ConvDiffusionModèle. Ce modèle est formé sur diverses images artistiques, comprenant des dessins, des peintures, des sculptures et des gravures, provenant de cet ensemble de données Kaggle. Notre objectif est d’explorer la capacité du modèle à capturer et reproduire l’esthétique complexe de ces œuvres d’art.
Architecture de modèle et formation
Conception architecturale
Le ConvDiffusionModel, à la base, est une merveille d’ingénierie neuronale, doté d’une architecture d’encodeur-décodeur sophistiquée adaptée aux exigences de la génération artistique. La structure du modèle est un réseau neuronal complexe, intégrant des mécanismes d’encodeur-décodeur raffinés spécialement conçus pour la génération artistique. Avec des couches convolutives supplémentaires et des connexions sautées qui imitent l'intuition artistique, le modèle peut disséquer et réassembler l'art avec une compréhension astucieuse de la composition et du style.
- Codeur: L’encodeur est l’œil analytique du modèle, scrutant les moindres détails de chaque image d’entrée. Au fur et à mesure que les images traversent les couches convolutives de l’encodeur, elles sont progressivement compressées dans un espace latent : une représentation compacte et codée de l’œuvre d’art originale. Notre encodeur examine non seulement les images d'entrée, mais le fait désormais avec une profondeur de perception accrue, grâce à des couches supplémentaires et à des techniques de normalisation par lots. Cet examen approfondi permet une représentation plus riche et condensée au sein de l’espace latent, reflétant la profonde contemplation d’un artiste sur un sujet.
- Décodeur: En revanche, le décodeur sert de main créatrice au modèle, prenant les croquis abstraits de l’encodeur et leur insufflant vie. Il reconstruit l'œuvre d'art à partir de l'espace latent, couche par couche, détail par détail, jusqu'à ce qu'une image complète émerge. Notre décodeur bénéficie de connexions sautées et peut reconstruire les œuvres d’art avec une plus grande précision. Il revisite l’essence abstraite de l’entrée et l’embellit progressivement, obtenant un rendu plus fidèle au matériau source. Les calques améliorés fonctionnent de concert pour garantir que l’image finale est une pièce vivante et complexe qui reflète le talent artistique de l’entrée.
Processus de formation
La formation du ConvDiffusionModel est un voyage à travers un paysage artistique s'étendant sur 150 époques. Chaque époque représente un passage complet à travers l’ensemble de données, le modèle s’efforçant d’affiner sa compréhension et d’améliorer la fidélité de ses images générées.
- Fonction de perte hybride : Au cœur de la formation se trouve la fonction de perte d’erreur quadratique moyenne (MSE). Cette fonction quantifie la différence entre le chef-d’œuvre original et la recréation du modèle, fournissant une mesure claire à minimiser. Nous introduirons un composant de perte de perception dérivé d'un réseau VGG pré-entraîné qui complète la métrique d'erreur quadratique moyenne (MSE). Cette stratégie de double perte pousse le modèle à honorer l'intégrité artistique des originaux tout en perfectionnant la reproduction technique de leurs détails.
- Optimiseur: Avec son taux d’apprentissage ajusté dynamiquement par un ordonnanceur, l’optimiseur Adam guide l’apprentissage du modèle avec une sagacité accrue. Cette approche adaptative garantit que les progrès du modèle dans l’apprentissage de la reproduction et de l’innovation artistique sont à la fois stables et robustes.
- Itération et raffinement : Les itérations de formation sont une danse entre la préservation de l’essence artistique et la poursuite de la réplication technique. À chaque cycle, le modèle se rapproche d’une synthèse de fidélité et de créativité.
- Visualisation des progrès : des images sont enregistrées à intervalles réguliers pendant l'entraînement pour visualiser la progression du modèle.. Ces instantanés offrent une fenêtre sur la courbe d’apprentissage du modèle, montrant comment l’art généré évolue, devenant plus clair, plus détaillé et plus cohérent artistiquement avec chaque époque.



Ce qui précède est démontré via le morceau de code suivant :
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Visualiser l'illustration générée
Manifester le talent artistique créé par l'IA
Le ConvDiffusionModel étant désormais entièrement formé, l’accent passe de l’abstrait au concret, du potentiel à l’actualisation de l’art créé par l’IA. L’extrait de code suivant matérialise les capacités artistiques acquises du modèle, transformant les données d’entrée en une toile d’expression numérique.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()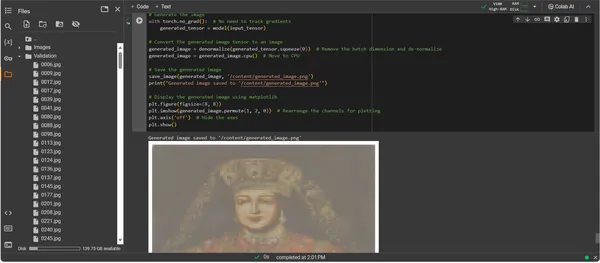

Procédure pas à pas du code de génération d’œuvres d’art
- Résurrection modèle : La première étape de la génération d'œuvres d'art consiste à relancer notre ConvDiffusionModel formé. Les poids appris du modèle sont chargés et mis en mode d’évaluation, ouvrant la voie à la création sans modifier davantage ses paramètres.
- Transformation d'image: Pour garantir la cohérence avec le régime de formation, les images d'entrée sont traitées via la même séquence de transformations. Cela inclut le redimensionnement pour correspondre aux dimensions d'entrée du modèle, la conversion du tenseur pour la compatibilité PyTorch et la normalisation basée sur le profil statistique des données d'entraînement.
- Utilitaire de dénormalisation : Une fonction personnalisée inverse les effets de prétraitement, en redimensionnant le tenseur selon la gamme de couleurs de l'image d'origine. Cette étape est essentielle pour rendre la sortie générée dans une représentation visuellement précise.
- Préparation des entrées : Une image est chargée et soumise aux transformations susmentionnées. Il est crucial de noter que cette image sert de muse dont l’IA s’inspirera : le murmure silencieux enflamme l’imagination synthétique du modèle.
- Synthèse des œuvres d'art : Dans une danse délicate de propagation vers l'avant, le modèle interprète le tenseur d'entrée, permettant à ses couches de collaborer pour produire une nouvelle vision artistique. Effectuez ce processus sans suivre les dégradés, car nous sommes maintenant dans le domaine de l'application, pas de la formation.
- Conversion d'image: La sortie tensorielle du modèle, qui contient désormais l’œuvre d’art née numériquement, est dénormalisée, traduisant la création du modèle dans l’espace familier de couleur et de lumière que nos yeux peuvent apprécier.
- Révélation de l’œuvre : Le tenseur transformé est disposé sur une toile numérique, aboutissant à un fichier image enregistré. Ce fichier est une fenêtre sur l’âme créatrice de l’IA, un écho statique du processus dynamique qui lui a donné vie.
- Récupération d'œuvres d'art : Le script se termine en enregistrant l'image générée dans un chemin désigné et en annonçant son achèvement. L’image enregistrée, synthèse de principes artistiques appris et de créativité émergente, est prête à être exposée et contemplée.
Analyser le résultat
La sortie du ConvDiffusionModel présente une figure avec un clin d’œil clair à l’art historique. Drapée dans une tenue élaborée, l'image rendue par l'IA fait écho à la grandeur des portraits classiques avec une touche moderne et distincte. La tenue vestimentaire du sujet est riche en textures, mêlant les modèles appris du modèle à une interprétation inédite. Les traits délicats du visage et un jeu subtil d’ombre et de lumière mettent en valeur la compréhension nuancée de l’IA des techniques artistiques traditionnelles. Cette œuvre d’art témoigne de la formation sophistiquée du modèle, reflétant une synthèse élégante de l’art historique à travers le prisme de l’apprentissage automatique avancé. Il s’agit essentiellement d’un hommage numérique au passé, conçu avec les algorithmes du présent.
Défis et considérations éthiques
La mise en œuvre de modèles de diffusion pour la génération artistique entraîne plusieurs défis et considérations éthiques que vous devez prendre en compte :
- Provenance des données : Les ensembles de données de formation doivent être conservés de manière responsable. Il est essentiel de vérifier que les données utilisées pour former les modèles de diffusion ne contiennent pas d'œuvres protégées par le droit d'auteur ou protégées sans autorisation appropriée.
- Biais et représentation : Les modèles d’IA peuvent perpétuer des biais dans leurs données d’entraînement. Il est important de garantir des ensembles de données diversifiés et inclusifs pour éviter de renforcer les stéréotypes dans l’art généré par l’IA.
- Contrôle de la sortie : Étant donné que les modèles de diffusion peuvent générer un large éventail de résultats, il est nécessaire de fixer des limites pour empêcher la création de contenus inappropriés ou offensants.
- Cadre juridique: L’absence d’un cadre juridique solide pour aborder les nuances de l’IA dans le processus créatif constitue un défi. La législation doit évoluer pour protéger les droits de toutes les parties impliquées.
Conclusion
L’essor des modèles de diffusion dans l’IA et l’art marque une ère de transformation, fusionnant précision informatique et exploration esthétique. Leur parcours dans le monde de l’art met en évidence un potentiel d’innovation important mais s’accompagne de complexités. L’équilibre entre originalité, influence, création éthique et respect des œuvres existantes fait partie intégrante du processus artistique.
Faits marquants
- Les modèles de diffusion sont à l’avant-garde d’un changement transformateur dans la création artistique. Ils offrent de nouveaux outils numériques qui élargissent le champ de l’expression artistique au-delà des frontières traditionnelles.
- Dans l’art amélioré par l’IA, il est impératif de donner la priorité à la collecte éthique des données de formation et de respecter la propriété intellectuelle des créateurs pour maintenir l’intégrité de l’art numérique.
- La convergence de la vision artistique et de l’innovation technologique ouvre les portes à une relation symbiotique entre artistes et développeurs d’IA. Favoriser un environnement collaboratif qui peut donner naissance à un art révolutionnaire.
- Il est essentiel de garantir que l’art généré par l’IA représente un large éventail de perspectives. Incorporer une gamme variée de données qui reflètent la richesse des différentes cultures et points de vue, favorisant ainsi l’inclusivité.
- L’intérêt croissant pour l’art créé par l’IA nécessite la mise en place de cadres juridiques solides. Ces cadres devraient clarifier les questions de droits d’auteur, reconnaître les contributions et régir l’utilisation commerciale des œuvres d’art générées par l’IA.
L’aube de cette évolution artistique offre un chemin débordant de potentiel créatif mais nécessite une tutelle attentive. Il nous incombe de cultiver un paysage où la fusion de l’IA et de l’art prospère, guidé par des pratiques responsables et culturellement sensibles.
Foire aux Questions
A. Les modèles de diffusion sont des algorithmes ML génératifs qui créent des images en commençant par un motif de bruit aléatoire et en le transformant progressivement en une image cohérente. Ce processus s’apparente à celui d’un artiste commençant avec une toile vierge et ajoutant lentement des couches de détails.
A. GAN, les modèles de diffusion ne nécessitent pas de réseau séparé pour juger du résultat. Ils fonctionnent en ajoutant et en supprimant du bruit de manière itérative, ce qui donne souvent lieu à des images plus détaillées et nuancées.
R. Oui, les modèles de diffusion peuvent générer des œuvres d’art originales en apprenant à partir d’un ensemble de données d’images. Cependant, l'originalité est influencée par la diversité et la portée des données de formation. Il y a un débat en cours sur l'éthique de l'utilisation d'œuvres d'art existantes pour former ces modèles.
A. Les préoccupations éthiques consistent à éviter toute violation du droit d’auteur sur les œuvres d’art générées par l’IA. Respecter l’originalité des artistes humains, empêcher la perpétuation des préjugés et garantir la transparence dans le processus créatif de l’IA.
A. L’avenir de l’art généré par l’IA semble prometteur, avec des modèles de diffusion offrant de nouveaux outils aux artistes et aux créateurs. Nous pouvons nous attendre à voir des œuvres d’art plus sophistiquées et plus complexes à mesure que la technologie progresse. Cependant, la communauté créative doit composer avec des considérations éthiques et travailler à l’élaboration de lignes directrices claires et de meilleures pratiques.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :est
- :ne pas
- :où
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- capacité
- A Propos
- au dessus de
- RÉSUMÉ
- Avec cette connaissance vient le pouvoir de prendre
- atteindre
- la réalisation de
- Adam
- adaptatif
- ajoutant
- Supplémentaire
- propos
- Ajusté
- Avancée
- avances
- avènement
- contradictoire
- AI
- art de l'IA
- apparenté
- algorithmes
- Tous
- Permettre
- permet
- an
- Analytique
- analytique
- Analytique Vidhya
- et les
- Annoncer
- Application
- apprécier
- une approche
- architecture
- SONT
- Art
- article
- artiste
- artistique
- artistiquement
- talent artistique
- Artistes
- œuvres d'art
- oeuvres d'art
- AS
- At
- augmentée
- autorisation
- disponibles
- pistes
- éviter
- en évitant
- HACHES
- RETOUR
- Mal
- équilibrage
- basé
- BE
- devenir
- avantages.
- LES MEILLEURS
- les meilleures pratiques
- jusqu'à XNUMX fois
- Au-delà
- biais
- biais
- vide
- mélange
- blogathon
- né
- tous les deux
- frontières
- Respiration
- débordant
- Apportez le
- vaste
- Apporté
- en plein essor
- mais
- by
- calculer
- appelé
- CAN
- la toile
- capacités
- aptitude
- capturer
- challenge
- globaux
- Voies
- Chaos
- caractéristique
- vérifier
- vérification
- une pince
- clarté
- classe
- clair
- plus clair
- plus
- code
- Codage
- COHÉRENT
- collaborons
- collaborative
- Couleur
- vient
- commercial
- Communautés
- compact
- compatibilité
- compétitif
- complet
- achèvement
- complexe
- complexités
- composant
- composition
- calcul
- calcul
- concepts
- conceptuel
- Préoccupations
- concert
- conclut
- Connexions
- Considérer
- considérations
- contiennent
- contenu
- contraste
- contributions
- conventionnel
- Convergence
- Conversion
- conversion
- réseau de neurones convolutifs
- droit d'auteur
- Violation du droit d'auteur
- Core
- corrompu
- Processeur
- Fabriqué
- engendrent
- La création
- création
- Conception
- Créative
- notre créativité
- créateurs
- crucial
- culminant
- Cultiver
- culturellement
- organisée
- courbe
- Customiser
- cycle
- danser
- données
- ensembles de données
- débat
- profond
- définir
- demandes
- démontré
- profondeur
- Profondeurs
- Dérivé
- désigné
- détail
- détaillé
- détails
- mobiles
- dispositif
- différer
- différence
- différent
- La diffusion
- numérique
- Art numérique
- numériquement
- Dimension
- dimensions
- discrétion
- Commande
- afficher
- distinct
- distinction
- plusieurs
- Diversité
- do
- portes
- dessiner
- Dessins
- pendant
- Dynamic
- dynamiquement
- dynamique
- e
- chacun
- echo
- des échos
- les effets
- Élaborer
- d'autre
- émerge
- codée
- englober
- englobant
- ENGINEERING
- améliorée
- assurer
- Assure
- assurer
- Tout
- Environment
- époque
- époques
- Ère
- erreur
- essence
- essential
- établissement
- Ether (ETH)
- éthique
- éthique
- évaluation
- Chaque
- évolution
- évolue
- évolué
- évolue
- examen
- Excel
- Sauf
- existant
- Développer vous
- expansif
- attendre
- exploration
- explorez
- expression
- prolongé
- les
- œil
- Yeux
- Soin du visage
- fidèle
- non
- familier
- fascinant
- Fonctionnalités:
- Doté d'
- fidélité
- Figure
- Déposez votre dernière attestation
- Fichiers
- finale
- finition
- Prénom
- Focus
- Abonnement
- Pour
- Premier plan
- Avant
- Accueillir
- favoriser
- Framework
- cadres
- De
- d’étiquettes électroniques entièrement
- fonction
- fonctionnel
- fondamental
- plus
- la fusion
- avenir
- Gain
- GAN
- rassemblement
- a donné
- générer
- généré
- générateur
- génération
- génératif
- réseaux accusatoires génératifs
- IA générative
- générateurs
- Donner
- objectif
- GPU
- les gradients
- peu à peu
- grandeur
- saisir
- plus grand
- révolutionnaire
- guidé
- lignes directrices
- Guides
- main
- Exploiter
- Cœur
- ici
- Cacher
- Faits saillants
- historique
- tenue
- hommage
- honneur
- Comment
- Cependant
- HTTPS
- humain
- i
- idée
- if
- s'enflamme
- image
- satellite
- imagination
- impératif
- la mise en œuvre
- implications
- importer
- important
- améliorer
- in
- inclut
- Compris
- L'inclusivité
- intégrer
- increased
- incrémental
- Titulaire
- influencer
- influencé
- violation
- ingéniosité
- innovons
- Innovation
- contribution
- entrées
- perspicacité
- intégrale
- Intégration
- intégrité
- intellectuel
- propriété intellectuelle
- intérêt
- l'interprétation
- développement
- complexe
- introduire
- intuition
- impliqué
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- itération
- itérations
- SES
- chemin
- jpg
- juge
- Peindre
- paysage d'été
- couche
- poules pondeuses
- savant
- apprentissage
- Légal
- cadre juridique
- Législation
- Lens
- se trouve
- VIE
- lumière
- comme
- chargement
- LOOKS
- perte
- pertes
- click
- machine learning
- maintenir
- merveille
- chef-d'œuvre
- Match
- Matériel
- matplotlib
- signifier
- mécanisme
- mécanismes
- Médias
- seulement
- fusion
- méthode
- méthodique
- métrique
- minimiser
- minute
- miroir
- ML
- Algorithmes ML
- Mode
- modèle
- numériques jumeaux (digital twin models)
- Villas Modernes
- module
- PLUS
- Bougez
- beaucoup
- MUSE
- must
- noms
- naissant
- Nature
- NAVIGUER
- nécessaire
- Besoins
- réseau et
- réseaux
- Neural
- Ingénierie neuronale
- Réseau neuronal
- les réseaux de neurones
- Nouveauté
- Bruit
- noter
- roman
- maintenant
- nuances
- observer
- observée
- of
- de rabais
- offensive
- code
- offrant
- Offres Speciales
- souvent
- on
- en cours
- uniquement
- ouvre
- Optimiser
- or
- original
- originalité
- Originaux
- OS
- Autre
- nos
- ande
- sortie
- sorties
- plus de
- propriété
- peinture
- peintures
- paramètre
- paramètres
- partie
- les parties
- pass
- passé
- chemin
- Patron de Couture
- motifs
- perception
- perfection
- effectuer
- perspectives
- image
- pièce
- pièces
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- portraits
- défaillances
- pratiques
- La précision
- préliminaire
- représentent
- cadeaux
- conservation
- empêcher
- prévention
- principes
- impression
- priorisation
- processus
- traité
- produire
- Produit
- Profil
- profond
- Progrès
- progression
- progressivement
- prometteur
- la promotion de
- instructions
- propagation
- correct
- propriété
- protéger
- protégé
- provenance
- aportando
- publié
- la poursuite de
- pytorch
- quantifie
- aléatoire
- aléatoire
- gamme
- Tarif
- solutions
- royaume
- reconnaître
- Redéfinir
- affiner
- raffiné
- reflétant
- reflète
- régime
- Standard
- relation amoureuse
- enlever
- rendu
- réplication
- représentation
- représente
- reproduction
- exigent
- a besoin
- ressemblant
- remodeler
- respect
- respectant
- responsables
- de manière responsable
- résultant
- retourner
- révélation
- Relancer
- révolutionner
- RGB
- Rich
- droits
- Augmenter
- robuste
- Rôle
- même
- sauvé
- économie
- scène
- Sciences
- portée
- scénario
- sur le lien
- AUTO
- sensible
- séparé
- Séquence
- sert
- set
- mise
- installation
- plusieurs
- Shadow
- mise en forme
- décalage
- Changements
- devrait
- vitrine
- mettre en valeur
- montré
- significative
- depuis
- Lentement
- Fragment
- So
- sophistiqué
- Âme
- Identifier
- source
- l'espace
- enjambant
- spécifiquement
- Spectre
- quadrillé
- stable
- Étape
- Utilisation d'un
- Commencez
- statistique
- stable
- étapes
- de Marketing
- s'efforcer
- structure
- Étourdissant
- Catégorie
- sujet
- ultérieur
- tel
- Symbiotique
- synergique
- synthèse
- haute
- prend
- prise
- Target
- Technique
- techniques
- technologique
- Les technologies
- Technologie
- tensorflow
- testament
- qui
- La
- El futuro
- La Source
- leur
- Les
- Là.
- Ces
- l'ont
- this
- prospère
- Avec
- Ainsi
- à
- les outils
- torche
- Vision de la torche
- -nous
- vers
- Tracking
- traditionnel
- Train
- qualifié
- Formation
- Transformer
- De La Carrosserie
- transformations
- transformation
- transformé
- transformer
- se transforme
- Transparence
- oui
- Essai
- comprendre
- compréhension
- expérience unique et authentique
- jusqu'à
- Dévoile
- la mise à jour
- sur
- us
- utilisé
- d'utiliser
- en utilisant
- utilitaire
- Info de contact.
- vérifier
- via
- visualisation
- points de vue
- vision
- visuel
- art visuel
- visualisation
- visualiser
- visuellement
- vital
- était
- we
- webp
- Quoi
- Qu’est ce qu'
- qui
- tout en
- Chuchotement
- WHO
- large
- Large gamme
- sera
- fenêtre
- comprenant
- dans les
- sans
- activités principales
- vos contrats
- world
- X
- Oui
- encore
- you
- zéphyrnet
- zéro