Introduction
Les transformateurs et les grands modèles de langage ont pris d'assaut le monde après avoir été introduits dans le domaine de la Traitement du langage naturel (PNL). Depuis leur création, le domaine a évolué rapidement avec des innovations et des recherches qui rendent ces LLM plus efficaces. Ceux-ci incluent LoRA (Low-Rank Adaption), Flash Attention, Quantization et la récente approche de fusion des LLM notables. Dans ce guide, nous examinerons une nouvelle approche de la fusion LLM (Solar 10.7B) introduit par Upstage AI.

Objectifs d'apprentissage
- Comprendre l'architecture unique de Solar 10.7B et sa « mise à l'échelle en profondeur » innovante
- Explorez le processus de pré-formation du modèle et les diverses données qu'il consomme
- Analysez les performances impressionnantes de Solar 10.7B dans différentes tâches de PNL
- Comparez et contrastez Solar 10.7B avec d'autres LLM notables, comme Mixtral MoE
- Découvrez comment accéder et utiliser Solar 10.7B pour vos projets
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Qu’est-ce que SOLAIRE 10.7B ?
Upstange AI a présenté le nouveau modèle de 10.7 milliards de paramètres, SOLAR 10.7B. Ce modèle est le résultat de la fusion de deux modèles de paramètres de 7 milliards, en particulier deux modèles Llama 2 de 7 milliards, qui ont été pré-entraînés pour créer SOLAR 10.7B. L'aspect unique de cette fusion est l'application d'une nouvelle approche appelée Depth Up-Scaling (DUS), contrastant avec la méthode Mixtral où un mélange d'experts est utilisé.
Le nouveau modèle 10.7B a surpassé les Mistral 7B et Qwen 14B. Une version d'Instruct appelée SOLAR 10.7B Instruct a été publiée et, lors de sa sortie, elle est en tête du classement, dépassant à la fois le Qwen 72B et le Large Language Model Mixtral 8x7B. Bien qu'il s'agisse d'un modèle de 10.7 milliards de paramètres, le SOLAR a pu surpasser les LLM qui sont plusieurs fois sa taille.
Qu’est-ce que la mise à l’échelle en profondeur ?
Comprenons comment tout a commencé et la formation de SOLAR 10.7B. Tout commence avec un seul modèle de base. The Upstage a choisi le Llama 2 contenant 32 couches de transformateur pour son modèle de base en raison de ses contributeurs Open Source plus larges. Ensuite, une copie de ce modèle de base a été créée

Nous obtenons alors deux modèles de base. Quant aux poids, l'Upstage a repris les poids pré-entraînés du Mistral 7B car il était le plus performant à l'époque. Maintenant, nous commençons la mise à l'échelle en profondeur. Chacun des modèles de base contient 32 couches. De ces 32 calques, nous supprimons m calques, c'est-à-dire les m derniers calques du modèle original et les m premiers calques de la version copiée de celui-ci. Cela totalise 24 couches dans chacune d'elles. Ensuite nous fusionnons ces deux modèles :
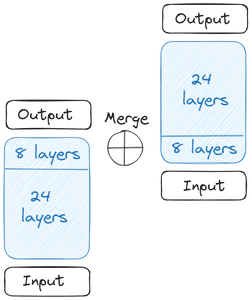
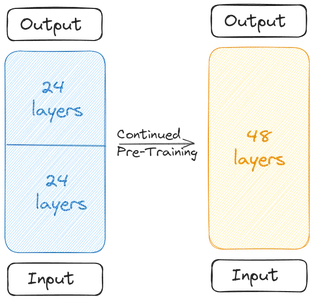
Les deux modèles de base sont concaténés pour former le modèle à l'échelle. Le modèle réduit contient désormais 48 calques. Le modèle réduit fonctionne mal en raison de la fusion. Par conséquent, le modèle réduit subit un pré-entraînement. Cette mise à l'échelle en profondeur suivie du pré-entraînement continu constitue la mise à l'échelle en profondeur (DUS).
Entraînement du SOLAR 10.7B
Le modèle réduit doit être pré-entraîné en raison de la diminution des performances due à la fusion. Les créateurs ont déclaré que les performances avaient augmenté rapidement grâce au pré-entraînement. La pré-formation/mise au point s'est déroulée en deux étapes
La première étape a été la mise au point des instructions. Dans ce type de réglage fin, le modèle a subi une formation sur des ensembles de données pour s'aligner sur les instructions. Le processus de réglage fin impliquait de travailler avec des ensembles de données Open Source populaires tels que Alpaca-GPT4 et OpenOrca. Le document note que seul un sous-ensemble de l'ensemble de données a été utilisé pour affiner le modèle fusionné. En plus des données Open Source, Upstage les a même entraînés avec des données mathématiques de source fermée.
Dans la deuxième étape, le réglage de l'alignement est effectué. Dans Alignment Tuning, nous prenons le modèle de première étape et l'affinons davantage pour qu'il soit davantage aligné sur les humains ou sur des IA puissantes comme GPT4. Cela a été fait grâce au DPOTrainer (Direct Preference Optimization), une technique de type RLHF (Reinforcement Learning with Human Feedback).
Dans Direct Preference Optimization, nous avons un ensemble de données contenant trois colonnes, une invite, une colonne de réponse préférée et une colonne de réponse rejetée. Ceci est ensuite utilisé pour entraîner le modèle à l'échelle afin de lui faire générer les réponses dont nous avons besoin. Les mêmes ensembles de données qui ont été formés pour le réglage fin des instructions sont utilisés ici.
Résultats d’évaluation et de référence
Le classement Hugging Face OpenLLM utilise plusieurs critères pour évaluer les capacités des grands modèles linguistiques (LLM). Chaque benchmark évalue différents aspects de la performance d’un LLM :
- ARC (Défi de raisonnement AI2) : Ce benchmark teste la capacité d'un LLM à répondre à des questions scientifiques de niveau élémentaire, fournissant ainsi un aperçu de la compréhension et du raisonnement du modèle sur les concepts scientifiques.
- MMLU (Compréhension du langage Massive MultiTask) : MMLU est un référentiel diversifié qui couvre 57 tâches différentes, y compris des questions liées aux mathématiques de base, à l'histoire, au droit, à l'informatique et autres. Il évalue la capacité du LLM à traiter et à comprendre des informations dans plusieurs disciplines.
- HellaSwag : Destiné à tester le raisonnement de bon sens d'un LLM, HellaSwag met les modèles au défi d'appliquer la logique quotidienne à une variété de scénarios, en évaluant leur capacité à porter des jugements intuitifs similaires aux processus de pensée humaine.
- Winogrande : Ce benchmark similaire au HellaSwag, se concentre sur le raisonnement de bon sens mais avec des nuances différentes par rapport à HellaSwag. Cela nécessite que les LLM démontrent un niveau sophistiqué de compréhension et de raisonnement logique.
- Vérification QA : TruthfulQA évalue l'exactitude et la fiabilité des informations fournies par les LLM. Il comprend des questions provenant de différents domaines, notamment la science, le droit, la politique, etc., testant la capacité du modèle à générer des réponses véridiques et factuelles.
- GSM8K : Spécialement conçu pour tester les capacités mathématiques, GSM8K comprend des problèmes mathématiques en plusieurs étapes qui nécessitent un raisonnement logique et une pensée informatique, mettant les LLM au défi d'évaluer leurs compétences en résolution de problèmes en mathématiques.
Le modèle de base SOLAR 10.7B a surpassé les modèles comme le modèle Mistral 7B Instruct v0.2 et le modèle Qwen 14B. La version Instruct du SOLAR 10.7B était même capable de battre les très grands modèles de langage comme le Mistral 8x7B, le Qwen 72B, le Falcon 180B et les autres énormes modèles de langage. Il était en avance sur tous les modèles de l'ARC et du benchmark TruthfulQA
Premiers pas avec SOLAR 10.7B
Le modèle SOLAR 10.7B est facilement disponible dans le hub HuggingFace pour fonctionner avec la bibliothèque de transformateurs. Même les modèles quantifiés du SOLAR 10.7B sont disponibles. Dans cette section, nous allons télécharger la version quantifiée et essayer de saisir le modèle avec différentes tâches et voir la sortie générée.
Pour tester avec la version quantifiée de SOLAR 10.7B, nous travaillerons avec la bibliothèque llama_cpp_python de Python qui nous permet d'exécuter des grands modèles de langage quantifiés. Pour cette démo, nous travaillerons avec la version gratuite de Google Colab.
Téléchargez le package
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python
!pip3 install huggingface-hub- La CMAKE_ARGS=”-DLLAMA_CUBLAS=on” et de FORCE_CMAKE=1, permettra au lama_cpp_python pour faire fonctionner le GPU Nvidia disponible dans la version gratuite colab
- Ensuite, nous installons le lama_cpp_python paquet via pip3
- Nous téléchargeons même le câlin-hub, avec lequel nous téléchargerons le modèle quantifié SOLAR 10.7B
Pour travailler avec le modèle SOLAR 10.7B, nous devons d'abord en télécharger la version quantifiée. Pour le télécharger, nous exécuterons le code suivant :
from huggingface_hub import hf_hub_download
# specifying the model name
model_name = "TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF"
# specifying the type of quantization of the model
model_file = "solar-10.7b-instruct-v1.0.Q2_K.gguf"
# download the model by specifying the model name and quantized model name
model_path = hf_hub_download(model_name, filename=model_file)
Travailler avec Hugging Face Hub
Ici, nous travaillons avec le câlin_face_hub pour télécharger le modèle quantifié. Pour cela, nous importons le hf_hub_download qui prend en compte les paramètres suivants
- nom du modèle: C'est le type de modèle que nous souhaitons télécharger. Ici, nous souhaitons télécharger le modèle SOLAR 10.7B Instruct GGUF
- fichier_modèle : Ici, nous indiquons quelle version quantifiée nous voulons télécharger. Ici, nous allons télécharger la version quantifiée 2 bits de l'instruction SOLAR 10.7B
- Nous transmettons ensuite ces paramètres au hf_hub_download, qui prend en compte ces paramètres et télécharge le modèle spécifié. Après le téléchargement, il renvoie le chemin où le modèle est téléchargé
- Ce chemin renvoyé est enregistré dans le chemin_modèle variable
Maintenant, nous pouvons charger ce modèle via le lama_cpp_python bibliothèque. Le code de chargement du modèle sera comme celui ci-dessous
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=512, # the number of i/p tokens the model can take
n_threads=8, # the number of threads to use
n_gpu_layers=110 # how many layers of the model to offload to the GPU
)
Importer la classe Lama
Nous importons la classe Llama du lama_cpp, qui prend les paramètres suivants
- chemin_modèle : Cette variable prend le chemin où notre modèle est stocké. Nous avons le chemin de l'étape précédente, que nous fournirons ici
- n_ctx : Ici, nous donnons la longueur du contexte du modèle. Pour l'instant, nous fournissons 512 jetons pour la longueur du contexte
- n_threads : Nous mentionnons ici le nombre de threads que doit utiliser la classe Llama. Pour l'instant, nous lui passons 8, car nous avons un processeur à 4 cœurs, où chaque cœur peut exécuter 2 threads simultanément
- n_gpu_layers : Nous donnons cela si nous avons un GPU en marche, ce que nous faisons parce que nous travaillons avec la collaboration gratuite. À cela, nous passons 110, qui indique que nous voulons décharger l'intégralité du modèle dans le GPU et que nous ne voulons pas qu'une partie de celui-ci s'exécute dans la RAM du système.
- Enfin, nous créons un objet à partir de cette classe Lama et le donnons à la variable llm
L'exécution de ce code chargera le modèle quantifié SOLAR 10.7B sur le GPU et définira la longueur de contexte appropriée. Il est maintenant temps d’effectuer quelques inférences sur ce modèle. Pour cela, nous travaillons avec le code ci-dessous
output = llm(
"### User:nWho are you?nn### Assistant:", # User Prompt
max_tokens=512, # the number of output tokens generated
stop=["</s>"], # the token which tells the LLM to stop
)
print(output['choices'][0]['text']) # llm generated text
Déduire le modèle
Pour déduire le modèle, nous transmettons les paramètres suivants aux LLM :
- Modèle d'invite/de discussion : Il s'agit du modèle nécessaire pour discuter avec le modèle. Le modèle mentionné ci-dessus (### User:n{user_prompt}?nn### Assistant :) est celui qui fonctionne pour le modèle SOLAR 10.7B. Dans le modèle, la phrase après le Utilisateur est l'invite utilisateur et la génération sera générée après le Assistante gérante
- max_tokens : Il s'agit de la quantité maximale de jetons que le modèle de langage étendu peut générer lorsqu'une invite est émise. Pour l'instant, nous le limitons à 512 tokens
- arrêter C'est le jeton d'arrêt. Le jeton d'arrêt indique au Large Language Model qu'il doit cesser de générer d'autres jetons. Pour SOLAR 10.7B, le jeton d'arrêt est
L'exécuter stockera les résultats dans le sortie variable. Le résultat généré est similaire à l'appel de l'API OpenAI. Par conséquent, nous pouvons accéder à la génération via l'instruction print donnée, ce qui est similaire à la façon dont nous accédons à la génération à partir des réponses OpenAI. La sortie générée peut être vue ci-dessous

La phrase générée semble assez bonne sans l’apparition d’erreurs grammaticales majeures. Essayons la partie de bon sens du modèle en donnant les invites suivantes
output = llm(
"### User:nHow many eggs can a monkey lay in its lifetime?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:nHow many smartphones can a human eat?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Nous voyons ici deux exemples liés au bon sens et, étonnamment, SOLAR 10.7B le gère très bien. Le Large Language Model a pu fournir les bonnes réponses avec du contenu utile. Essayons de tester les capacités mathématiques et de raisonnement du modèle à travers les invites suivantes
output = llm(
"### User:nLook at this series: 80, 10, 70, 15, 60, ...
What number should come next?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])
output = llm(
"### User:nJohn runs faster than Ken. Magnus runs faster than John.
Does Ken run faster than Magnus?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

À partir de l'exemple d'invite donné, le SOLAR 10.7B a généré une bonne réponse. Il était capable de répondre correctement aux raisonnements mathématiques et logiques donnés et même aux questions liées au bon sens. Dans l'ensemble, nous pouvons conclure que le grand modèle linguistique SOLAR 10.7B génère de bonnes réponses.
SOLAR 10.7B et Mixtral MoE
Mistral 8x7B MoE est créé par l'IA Mistral avec l'architecture Mixture of Experts. En bref, ce Mélange d'Experts, le Mistral emploie 8 Modèles de 7 Milliards de Paramètres. Chacun de ces modèles voit certains de ses réseaux de rétroaction remplacés par d'autres couches appelées experts. Le Mistral 8x7B est donc considéré comme disposant de 8 experts. Et pour toutes les personnes que le modèle prend dans l'invite d'entrée, il y aura un mécanisme de contrôle qui sélectionne seulement 2 de ces experts parmi les 8. Les 2 experts prennent ensuite en compte cette invite d'entrée et génèrent des jetons de sortie finaux. Nous pouvons donc voir qu'il y a un peu de complexité impliqué dans ce type de fusion, où nous devons remplacer les couches de feed-forward par d'autres couches et introduire un mécanisme de sélection qui sélectionne entre ces experts.
Tandis que le modèle SOLAR 10.7B d'Upstage exploite la méthode de mise à l'échelle de la profondeur. Dans l'augmentation de la profondeur, nous supprimons simplement un certain nombre de couches de départ d'un modèle de base et le même nombre de couches finales de sa version de copie. Ensuite, nous fusionnons simplement les modèles en les empilant les uns sur les autres. Et avec seulement quelques périodes de réglage fin, le modèle fusionné peut afficher une croissance rapide de ses performances. Ici, nous ne remplaçons pas les calques existants par d’autres calques. Ici aussi, nous n’avons pas de mécanisme de déclenchement. Dans l’ensemble, la mise à l’échelle de la profondeur est un moyen simple et efficace de fusionner des modèles qui n’impliquent pas de complexités.
En comparant également les performances, l'augmentation de la profondeur, bien qu'en combinant simplement deux modèles de 7 milliards, le SOLAR 10.7B a pu clairement surpasser le Mixtral 8x7B, qui est un modèle beaucoup plus grand en comparaison. Cela prouve l'efficacité d'une méthode de fusion simple par rapport à une méthode complexe comme le Mixtral d'Experts.
Limites et considérations
- Exploration des hyperparamètres : Une limitation cruciale est l’exploration insuffisante des hyperparamètres dans l’approche DHS. En raison de limitations matérielles, 8 couches ont été supprimées aux deux extrémités du modèle de base sans vérifier si ce nombre est optimal pour obtenir les meilleures performances. Les travaux futurs visent à mener des expériences plus rigoureuses et à effectuer une analyse pour résoudre ce problème.
- Exigences informatiques : Le modèle nécessite une énorme quantité de ressources informatiques pour la formation et l’inférence. Cela pourrait limiter son utilisation, principalement pour ceux qui ont des capacités de calcul limitées.
- Biais dans les données de formation : comme tous les modèles d'apprentissage automatique, il est sensible aux biais présents dans les données de formation, conduisant potentiellement à des résultats faussés dans certains scénarios.
- Impact environnemental: Même la consommation d’énergie nécessaire à la formation et au fonctionnement du modèle pose des problèmes environnementaux, soulignant l’importance du développement durable de l’IA.
- Implications plus larges du modèle : Bien que le modèle affiche des performances améliorées dans les instructions suivantes, il nécessite toujours un réglage précis spécifique à la tâche pour des performances optimales dans les applications spécialisées. Ce processus de mise au point nécessite beaucoup de ressources et n’est pas toujours efficace.
Conclusion
Dans ce guide, nous avons examiné le modèle de paramètres SOLAR 10.7 milliards récemment publié par Upstage AI. Upstage AI a adopté une nouvelle approche pour fusionner et mettre à l’échelle des modèles. Le document a utilisé une nouvelle approche appelée Depth Up-Scaling pour fusionner deux modèles de paramètres de 2 milliards de Llama-7 en supprimant certaines des couches de transformateur de départ et de fin. Ensuite, il a affiné le modèle sur des ensembles de données Open Source et l'a testé sur le classement OpenLLM, obtenant le score H6 le plus élevé et arrivant en tête du classement.
Faits marquants
- SOLAR 10.7B introduit Depth Up-Scaling, une approche de fusion unique, remettant en question les méthodes traditionnelles et montrant les progrès de l'architecture des modèles.
- Malgré ses 10.7 milliards de paramètres, SOLAR 10.7B surpasse les modèles plus grands, surpassant Mistral 7B, Qwen 14B et même en tête des classements avec des versions comme SOLAR 10.7B Instruct.
- Le processus de réglage fin en deux étapes impliquant le réglage des instructions et de l'alignement garantit l'adaptabilité du modèle à différentes tâches, ce qui le rend très efficace pour suivre les instructions et s'aligner sur les préférences humaines.
- SOLAR 10.7B excelle dans divers critères, démontrant ainsi sa compétence dans des tâches allant des mathématiques de base et de la compréhension du langage au raisonnement de bon sens et à l'évaluation de la véracité.
- Facilement disponible sur le Hub HuggingFace, SOLAR 10.7B fournit aux développeurs et aux chercheurs un outil efficace et disponible pour les applications de traitement du langage.
- Vous pouvez affiner le modèle à l’aide des méthodes habituelles utilisées pour affiner les grands modèles de langage. Par exemple, vous pouvez utiliser le Supervised Fine-Tune Trainer (SFTrainer) de Hugging Face pour affiner le modèle SOLAR 10.7B.
Foire aux Questions
R. SOLAR 10.7B est un modèle de 10.7 milliards de paramètres créé par Upstage AI, utilisant une technique de fusion unique appelée Depth Up-Scaling. Il se distingue en surpassant les plus grands LLM et en présentant les progrès réalisés dans la fusion de modèles.
R. La mise à l'échelle en profondeur implique deux modèles de base. Le processus consiste à fusionner directement ces deux modèles de base en les empilant l’un sur l’autre. Avant la fusion, les couches initiales d'un modèle et les couches finales de l'autre modèle sont supprimées.
A. SOLAR 10.7B subit un processus de pré-formation en deux étapes. Le réglage fin de l'instruction implique la formation du modèle sur des ensembles de données en mettant l'accent sur le suivi des instructions. Le réglage de l'alignement affine l'alignement du modèle avec les préférences humaines à l'aide d'une technique appelée Direct Preference Optimization (DPO).
R. SOLAR 10.7B excelle dans divers tests de référence, notamment ARC (AI2 Reasoning Challenge), MMLU (Massive MultiTask Language Understanding), HellaSwag, Winogrande, TruthfulQA et GSM8K. Il obtient des scores élevés, démontrant sa polyvalence dans la gestion de différentes tâches linguistiques.
A. SOLAR 10.7B surpasse les modèles comme Mistral 7B et Qwen 14B, affichant des performances supérieures malgré moins de paramètres. La version instructive rivalise et surpasse même les très grands modèles, notamment Mistral 8x7B et Qwen 72B, sur divers benchmarks.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/01/solar-10-7b-comparing-its-performance-to-other-notable-llms/
- :possède
- :est
- :ne pas
- :où
- $UP
- 10
- 110
- 12
- 15%
- 16
- 24
- 300
- 32
- 60
- 7
- 70
- 8
- 80
- 9
- a
- capacités
- capacité
- Capable
- accès
- précision
- Atteint
- la réalisation de
- à travers
- propos
- Ajoute
- progrès
- Après
- devant
- AI
- AI2
- Destinée
- vise
- aligner
- aligné
- aligner
- alignement
- Tous
- permettre
- le long de
- aussi
- toujours
- montant
- an
- selon une analyse de l’Université de Princeton
- analytique
- Analytique Vidhya
- et de
- Une autre
- répondre
- réponses
- api
- Application
- applications
- Appliquer
- une approche
- approprié
- Arc
- architecture
- SONT
- domaines
- article
- AS
- d'aspect
- aspects
- évalue
- Évaluation
- Assistante gérante
- At
- précaution
- disponibles
- base
- Essentiel
- BE
- battre
- car
- était
- before
- a commencé
- va
- ci-dessous
- référence
- repères
- LES MEILLEURS
- jusqu'à XNUMX fois
- biais
- Milliards
- Bit
- blogathon
- tous les deux
- plus large
- mais
- by
- Appelez-nous
- appelé
- CAN
- capacités
- certaines
- challenge
- globaux
- difficile
- le chat
- choix
- choisi
- classe
- clairement
- fonds à capital fermé
- code
- Colonne
- Colonnes
- combinant
- comment
- Commun
- Bon sens
- comparer
- par rapport
- comparant
- Comparaison
- concurrence
- complexe
- complexités
- complexité
- calcul
- ordinateur
- Informatique
- concepts
- Préoccupations
- conclut
- Conduire
- considéré
- consommation
- contient
- contenu
- contexte
- a continué
- contraste
- contributeurs
- Core
- correctement
- pourriez
- couvre
- Processeur
- engendrent
- créée
- crucial
- données
- ensembles de données
- diminuer
- livrer
- demandes
- Démo
- démontrer
- démontrer
- profondeur
- un
- Malgré
- mobiles
- Développement
- différent
- directement
- disciplines
- discrétion
- distingue
- plusieurs
- do
- fait
- download
- téléchargements
- deux
- chacun
- manger
- Efficace
- efficacité
- efficace
- œufs
- mettant l'accent
- employés
- emploie
- se termine
- énergie
- Consommation d'énergie
- assez
- Assure
- Tout
- environnementales
- les préoccupations environnementales
- époques
- Ether (ETH)
- évaluer
- évaluations
- Pourtant, la
- de tous les jours
- tout le monde
- évolution
- exemple
- exemples
- existant
- expériences
- de santé
- exploration
- Visage
- Les faits
- faucon
- loin
- plus rapide
- Réactions
- few
- moins
- champ
- finale
- Prénom
- Flash
- se concentre
- suivi
- Abonnement
- Pour
- formulaire
- formation
- gratuitement ici
- De
- plus
- avenir
- générer
- généré
- générateur
- génération
- obtenez
- obtention
- Donner
- donné
- Don
- Bien
- eu
- GPU
- Croissance
- guide
- Poignées
- Maniabilité
- Matériel
- Vous avez
- ayant
- d'où
- ici
- Haute
- le plus élevé
- Soulignant
- Histoire
- Comment
- How To
- HTTPS
- Moyeu
- majeur
- Étreindre
- humain
- Les êtres humains
- if
- Impact
- implications
- importer
- importance
- impressionnant
- amélioré
- in
- début
- comprendre
- inclut
- Y compris
- d'information
- initiale
- innovations
- technologie innovante
- contribution
- idées.
- installer
- instance
- Des instructions
- développement
- introduire
- introduit
- Introduit
- intuitif
- impliquer
- impliqué
- implique
- impliquant
- IT
- SES
- lui-même
- John
- jugements
- juste
- kumar
- langue
- gros
- plus importantes
- Droit applicable et juridiction compétente
- poser
- poules pondeuses
- classements
- conduisant
- apprentissage
- Longueur
- Allons-y
- Niveau
- les leviers
- Bibliothèque
- durée de vie
- comme
- LIMIT
- limitation
- limites
- limité
- Flamme
- charge
- chargement
- logique
- logique
- Style
- click
- machine learning
- principalement
- majeur
- a prendre une
- Décideurs
- FAIT DU
- Fabrication
- de nombreuses
- massif
- math
- mathématique
- mathématiques
- largeur maximale
- maximales
- quantité maximale
- Mai..
- mécanisme
- Médias
- mentionner
- aller
- fusion
- méthode
- méthodes
- erreurs
- mélange
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- plus efficace
- plusieurs
- prénom
- nécessaire
- Besoin
- nécessaire
- Besoins
- réseaux
- Nouveauté
- next
- nlp
- notable
- noté
- maintenant
- nuances
- nombre
- Nvidia
- objet
- of
- on
- ONE
- uniquement
- ouvert
- open source
- OpenAI
- d'exploitation
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- or
- original
- Autre
- Autres
- nos
- ande
- les résultats
- Surpasser
- surperformé
- surperformant
- Surperforme
- sortie
- plus de
- global
- propriété
- Papier
- paramètre
- paramètres
- partie
- pass
- chemin
- effectuer
- performant
- performances
- effectué
- effectuer
- effectue
- Place
- Platon
- Intelligence des données Platon
- PlatonDonnées
- politique
- Populaire
- pose
- l'éventualité
- solide
- préférences
- préféré
- représentent
- précédent
- Imprimé
- résolution de problèmes
- d'ouvrabilité
- processus
- les process
- instructions
- Prouve
- à condition de
- fournit
- aportando
- publié
- Python
- fréquemment posées
- vite.
- allant
- Nos tests de diagnostic produisent des résultats rapides et précis sans nécessiter d'équipement de laboratoire complexe et coûteux,
- facilement
- récent
- récemment
- Standard
- apprentissage par renforcement
- Rejeté..
- en relation
- libérer
- libéré
- fiabilité
- supprimez
- Supprimé
- enlever
- remplacer
- remplacé
- a besoin
- un article
- chercheurs
- gourmande en ressources
- Resources
- réponse
- réponses
- résultat
- Résultats
- Retours
- bon
- rigoureux
- Ressuscité
- Courir
- pour le running
- fonctionne
- Saïd
- même
- sauvé
- Escaliers intérieurs
- mise à l'échelle
- scénarios
- Sciences
- sur une base scientifique
- But
- scores
- Deuxièmement
- Section
- sur le lien
- voir
- semble
- vu
- sens
- phrase
- Série
- set
- plusieurs
- devrait
- montrer
- mettre en valeur
- montrant
- montré
- Spectacles
- similaires
- étapes
- depuis
- unique
- compétences
- smartphones
- So
- solaire
- quelques
- sophistiqué
- Identifier
- spécialisé
- spécifiquement
- spécifié
- empilage
- Étape
- Utilisation d'un
- Commencer
- j'ai commencé
- Commencez
- départs
- Déclaration
- étapes
- Encore
- Arrêter
- Boutique
- stockée
- tempête
- tel
- haut
- surpasse
- incomparable
- sensible
- durable
- SVG
- combustion propre
- Prenez
- tâches
- prend
- tâches
- technique
- dire
- raconte
- modèle
- tester
- examiné
- Essais
- tests
- texte
- que
- qui
- La
- le monde
- leur
- Les
- puis
- Là.
- Ces
- l'ont
- En pensant
- this
- ceux
- bien que?
- pensée
- trois
- Avec
- Ainsi
- fiable
- fois
- à
- ensemble
- jeton
- Tokens
- outil
- top
- surmonté
- traditionnel
- Train
- qualifié
- Formation
- transformateur
- transformateurs
- Essai
- deux
- type
- subit
- comprendre
- compréhension
- a subi
- expérience unique et authentique
- sur
- us
- Utilisation
- utilisé
- d'utiliser
- incontournable
- Utilisateur
- Usages
- en utilisant
- utiliser
- utilisé
- Utilisant
- variable
- variété
- divers
- vérifier
- la versatilité
- version
- très
- vs
- souhaitez
- était
- Façon..
- we
- webp
- WELL
- ont été
- Quoi
- Qu’est ce qu'
- quand
- qui
- tout en
- plus large
- sera
- comprenant
- sans
- activités principales
- de travail
- vos contrats
- world
- you
- Votre
- zéphyrnet