Analyse automatisée des données (ADA) sur AWS est une solution AWS qui vous permet de tirer des informations significatives des données en quelques minutes grâce à une interface utilisateur simple et intuitive. ADA propose une plate-forme d'analyse de données native AWS prête à l'emploi par les analystes de données pour une variété de cas d'utilisation. Avec ADA, les équipes peuvent ingérer, transformer, gouverner et interroger divers ensembles de données à partir d'une gamme de sources de données sans nécessiter de compétences techniques spécialisées. ADA fournit un ensemble de connecteurs pré-construits pour ingérer des données à partir d'un large éventail de sources, y compris Service de stockage simple Amazon (Amazon S3), Flux de données Amazon Kinesis, Amazon Cloud Watch, Amazon CloudTrailet une Amazon DynamoDB ainsi que beaucoup d'autres.
ADA fournit une plate-forme fondamentale qui peut être utilisée par les analystes de données dans un ensemble diversifié de cas d'utilisation, notamment l'informatique, la finance, le marketing, les ventes et la sécurité. Le connecteur de données CloudWatch prêt à l'emploi d'ADA permet l'ingestion de données à partir des journaux CloudWatch dans le même compte AWS dans lequel ADA a été déployé, ou à partir d'un autre compte AWS.
Dans cet article, nous montrons comment un développeur d'applications ou un testeur d'applications peut utiliser ADA pour obtenir des informations opérationnelles sur les applications exécutées dans AWS. Nous montrons également comment vous pouvez utiliser la solution ADA pour vous connecter à différentes sources de données dans AWS. Nous d'abord déployer la solution ADA dans un compte AWS et mettre en place la solution ADA en créant Produits de données à l'aide de connecteurs de données. Nous utilisons ensuite ADA Query Workbench pour joindre les ensembles de données séparés et interroger les données corrélées, à l'aide du langage SQL (Structured Query Language) familier, afin d'obtenir des informations. Nous montrons également comment ADA peut être intégré à des outils de Business Intelligence (BI) tels que Tableau pour visualiser les données et créer des rapports.
Vue d'ensemble de la solution
Dans cette section, nous présentons l'architecture de la solution pour la démonstration et expliquons le flux de travail. Aux fins de démonstration, l'application sur mesure est simulée à l'aide d'un AWS Lambda fonction qui émet des logs Format de journal Apache à un intervalle prédéfini à l'aide Amazon Event Bridge. Ce format standard peut être produit par de nombreux serveurs Web différents et être lu par de nombreux programmes d'analyse de journaux. Les journaux d'application (fonction Lambda) sont envoyés à un groupe de journaux CloudWatch. Les journaux d'application historiques sont stockés dans un compartiment S3 à des fins de référence et d'interrogation. Une table de recherche avec une liste de Codes d'état HTTP ainsi que les descriptions sont stockées dans une table DynamoDB. Ces trois éléments servent de sources à partir desquelles les données sont ingérées dans ADA pour la corrélation, la requête et l'analyse. Nous déployer la solution ADA dans un compte AWS et mettre en place ADA. Nous créons ensuite le Produits de données au sein de l'ADA pour la Groupe de journaux CloudWatch, Seau S3et une DynamoDB. Au fur et à mesure que les produits de données sont configurés, ADA fournit des pipelines de données pour ingérer les données des sources. Avec ADA Query Workbench, vous pouvez interroger les données ingérées à l'aide de SQL brut pour le dépannage des applications ou le diagnostic des problèmes.
Le diagramme suivant fournit une vue d'ensemble de l'architecture et du flux de travail d'utilisation d'ADA pour obtenir des informations sur les journaux d'application.
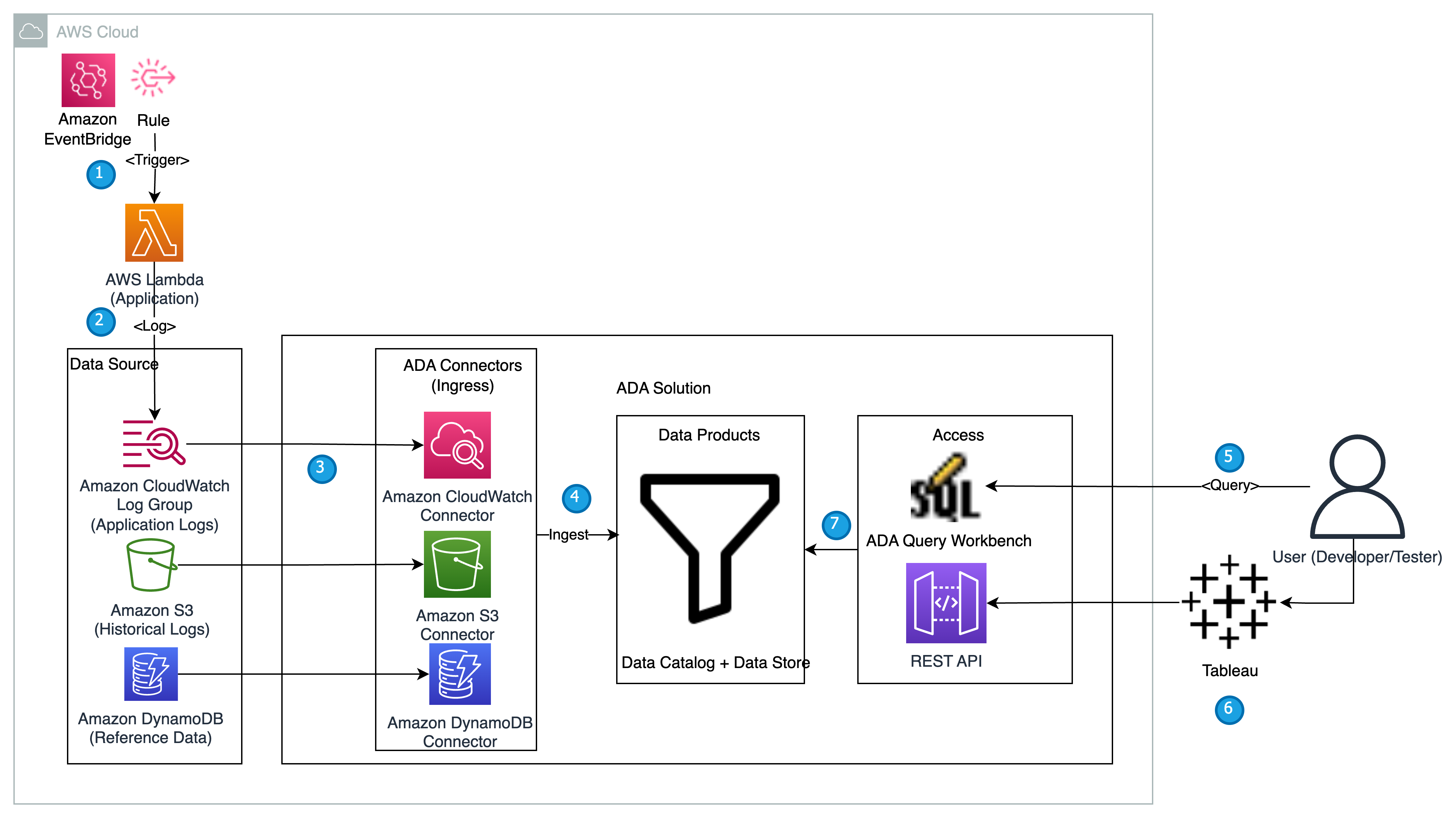
Le workflow comprend les étapes suivantes:
- Une fonction Lambda est planifiée pour être déclenchée toutes les 2 minutes à l'aide d'EventBridge.
- La fonction Lambda émet des journaux qui sont stockés dans un groupe de journaux CloudWatch spécifié sous
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Les journaux d'application sont générés à l'aide du schéma Apache Log Format mais stockés dans le groupe de journaux CloudWatch au format JSON. - Les produits de données pour CloudWatch, Amazon S3 et DynamoDB sont créés dans ADA. Le produit de données CloudWatch se connecte au groupe de journaux CloudWatch dans lequel les journaux d'application (fonction Lambda) sont stockés. Le connecteur Amazon S3 se connecte à un dossier de compartiment S3 dans lequel les journaux historiques sont stockés. Le connecteur DynamoDB se connecte à une table DynamoDB dans laquelle les codes d'état référencés par l'application et les journaux historiques sont stockés.
- Pour chacun des produits de données, ADA déploie l'infrastructure de pipeline de données pour ingérer les données des sources. Une fois l'ingestion des données terminée, vous pouvez écrire des requêtes à l'aide de SQL via ADA Query Workbench.
- Vous pouvez vous connecter au portail ADA et composer des requêtes SQL à partir de Query Workbench pour obtenir des informations sur les journaux d'application. Vous pouvez éventuellement enregistrer la requête et la partager avec d'autres utilisateurs ADA du même domaine. La fonction de requête ADA est alimentée par Amazone Athéna, qui est un service d'analyse interactif sans serveur qui offre un moyen simplifié et flexible d'analyser des pétaoctets de données.
- Tableau est configuré pour accéder aux produits de données ADA via des points de terminaison de sortie ADA. Vous créez ensuite un tableau de bord avec deux graphiques. Le premier graphique est une carte thermique qui montre la prévalence des codes d'erreur HTTP corrélés avec les points de terminaison de l'API de l'application. Le deuxième graphique est un graphique à barres qui affiche les 10 principales API d'application avec un nombre total de codes d'erreur HTTP à partir des données historiques.
Pré-requis
Pour ce poste, vous devez remplir les prérequis suivants :
- Installez l' Interface de ligne de commande AWS (AWS CLI), Kit de développement AWS Cloud (AWSCDK) conditions préalables, spécifique à TypeScript conditions préalableset une jet.
- Déployer la solution ADA dans votre compte AWS dans le
us-east-1Région.- Fournir un e-mail d'administrateur lors du lancement de l'ADA AWS CloudFormation empiler. Ceci est nécessaire pour qu'ADA envoie le mot de passe de l'utilisateur root. Un numéro de téléphone administrateur est requis pour recevoir un message de mot de passe à usage unique si l'authentification multifacteur (MFA) est activée. Pour cette démo, MFA n'est pas activé.
- Générez et déployez l'exemple d'application (disponible sur le GitHub repo) afin que les ressources suivantes puissent être provisionnées dans votre compte dans le
us-east-1Région:- Une fonction Lambda qui simule l'application de journalisation et une règle EventBridge qui appelle la fonction d'application à des intervalles de 2 minutes.
- Un compartiment S3 avec les stratégies de compartiment pertinentes et un fichier CSV contenant les journaux d'application historiques.
- Une table DynamoDB avec les données de recherche.
- Pertinent Gestion des identités et des accès AWS (IAM) rôles et autorisations requis pour les services.
- En option, installez Tableau Desktop, un fournisseur de BI tiers. Pour cet article, nous utilisons Tableau Desktop version 2021.2. L'utilisation d'une version sous licence de l'application Tableau Desktop entraîne des frais. Pour plus de détails, reportez-vous au Licence Tableau </br>L’Information.
Déployer et configurer ADA
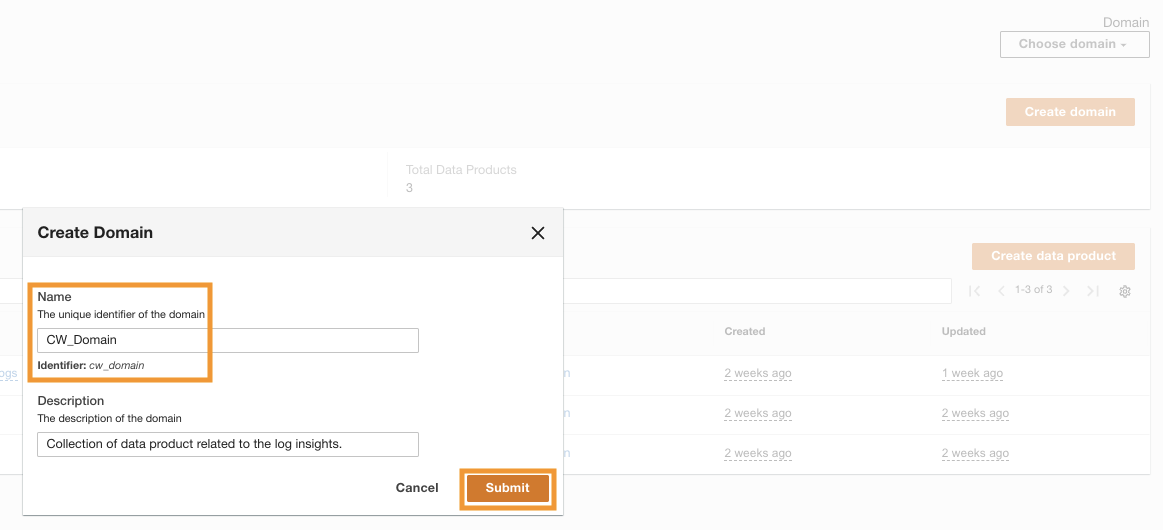
Une fois ADA déployé avec succès, vous pouvez vous identifier à l'aide de l'e-mail d'administration fourni lors de l'installation. Vous créez alors un domaine nommé CW_Domain. Un domaine est une collection définie par l'utilisateur de produits de données. Par exemple, un domaine peut être une équipe ou un projet. Les domaines offrent aux utilisateurs un moyen structuré d'organiser leurs produits de données et de gérer les autorisations d'accès.
- Sur la console ADA, choisissez Domaines dans le volet de navigation.
- Selectionnez Créer un domaine.
- Entrez un nom (
CW_Domain) et description, puis choisissez Envoyer.
Configurer l'exemple d'infrastructure d'application à l'aide d'AWS CDK
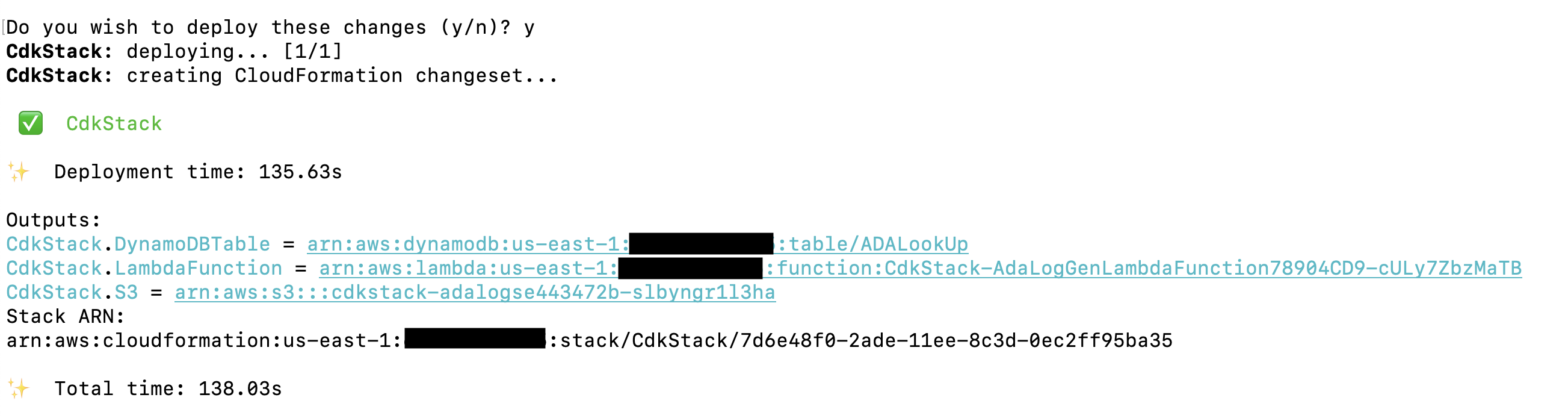
La solution AWS CDK qui déploie l'application de démonstration est hébergée sur GitHub. Les étapes de clonage du référentiel et de configuration du projet AWS CDK sont détaillées dans cette section. Avant d'exécuter ces commandes, assurez-vous de configurer vos informations d'identification AWS. Créez un dossier, ouvrez le terminal et accédez au dossier dans lequel la solution AWS CDK doit être installée. Exécutez le code suivant :
Ces étapes effectuent les actions suivantes :
- Installer les dépendances de la bibliothèque
- Construisez le projet
- Générer un modèle CloudFormation valide
- Déployez la pile à l'aide d'AWS CloudFormation dans votre compte AWS
Le déploiement prend environ 1 à 2 minutes et crée la table de recherche DynamoDB, la fonction Lambda et le compartiment S3 contenant les fichiers journaux historiques en tant que sorties. Copiez ces valeurs dans une application d'édition de texte, telle que le Bloc-notes.
Créer des produits de données ADA
Nous créons trois produits de données différents pour cette démonstration, un pour chaque source de données que vous interrogerez pour obtenir des informations opérationnelles. Un produit de données est un ensemble de données (une collection de données comme un tableau ou un fichier CSV) qui a été importé avec succès dans ADA et qui peut être interrogé.
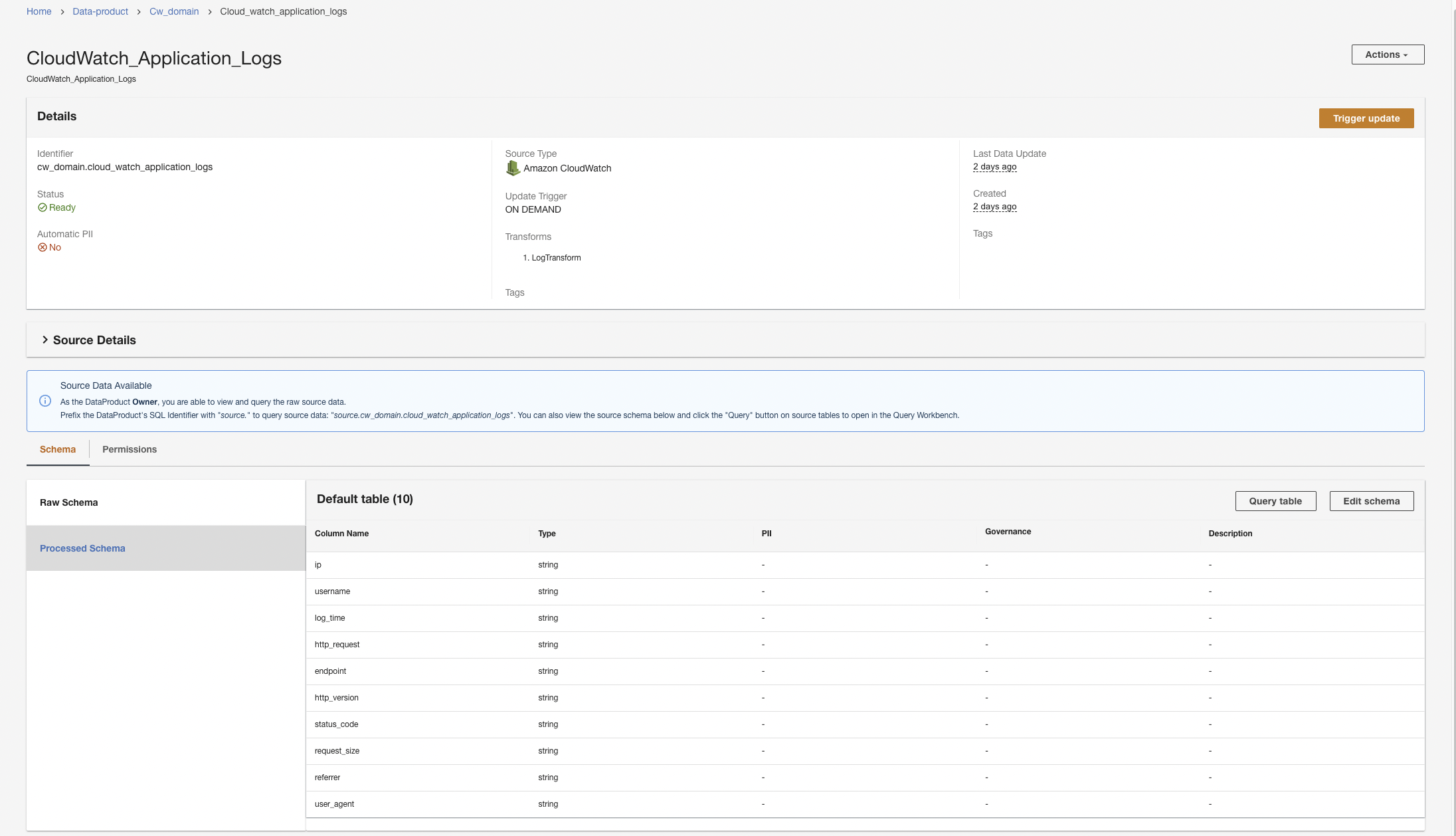
Créer un produit de données CloudWatch
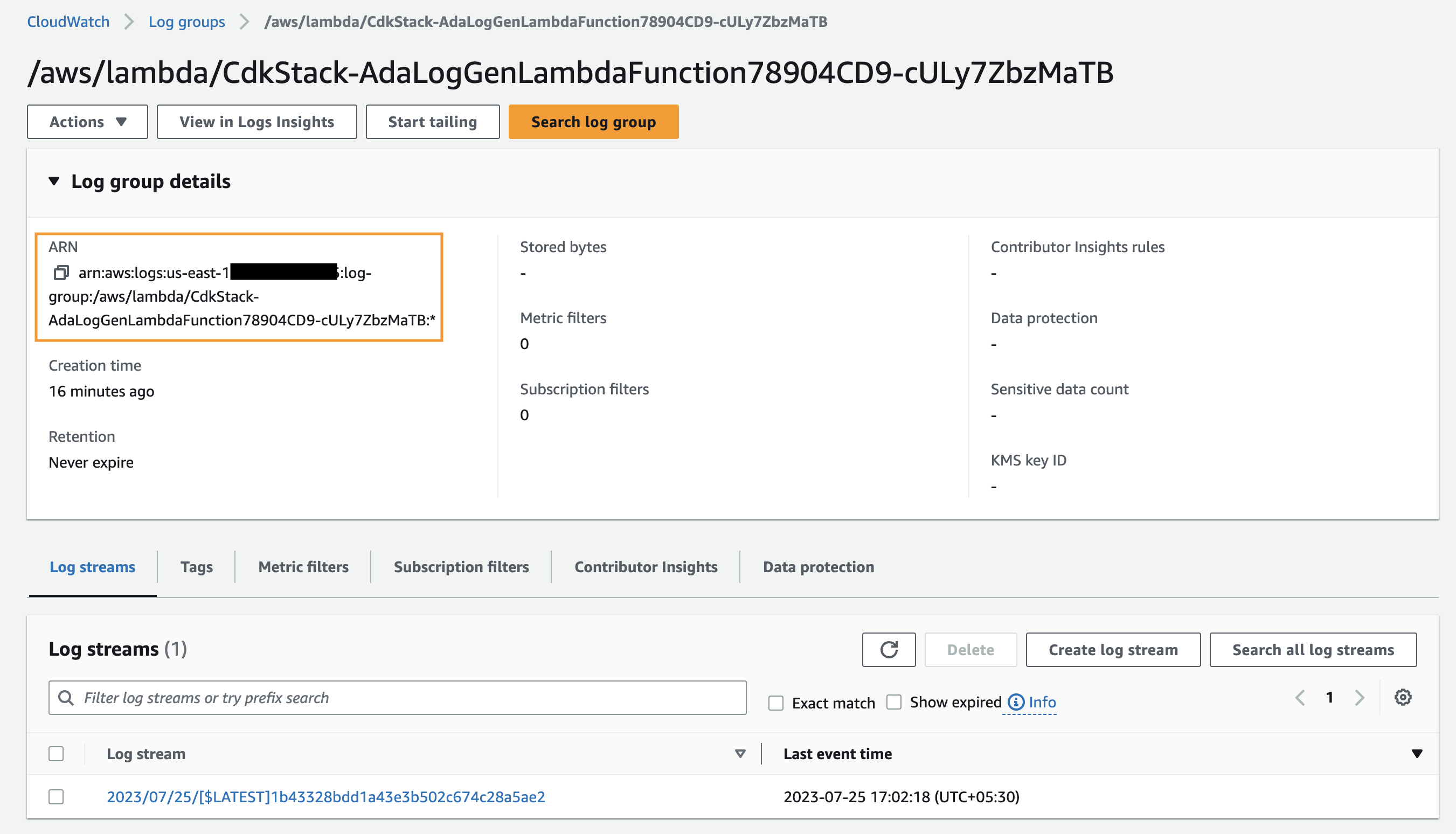
Tout d'abord, nous créons un produit de données pour les journaux d'application en configurant ADA pour ingérer le groupe de journaux CloudWatch pour l'exemple d'application (fonction Lambda). Utilisez le CdkStack.LambdaFunction pour obtenir l'ARN de la fonction Lambda et localiser l'ARN du groupe de journaux CloudWatch correspondant sur la console CloudWatch.
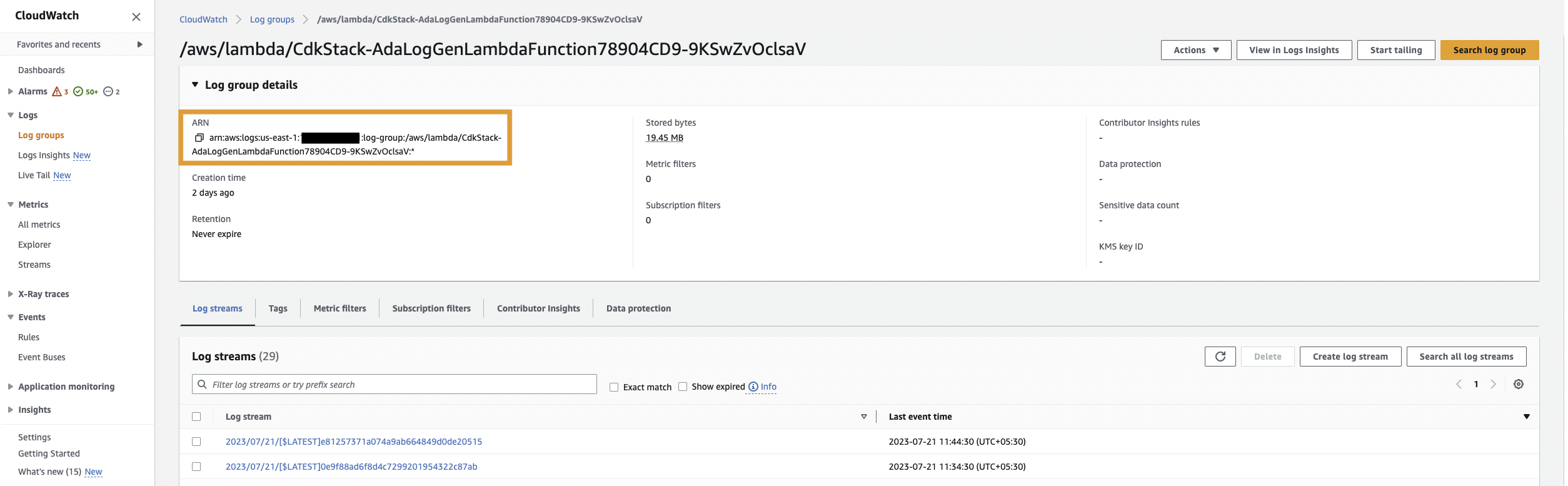
Suivez ensuite les étapes suivantes:
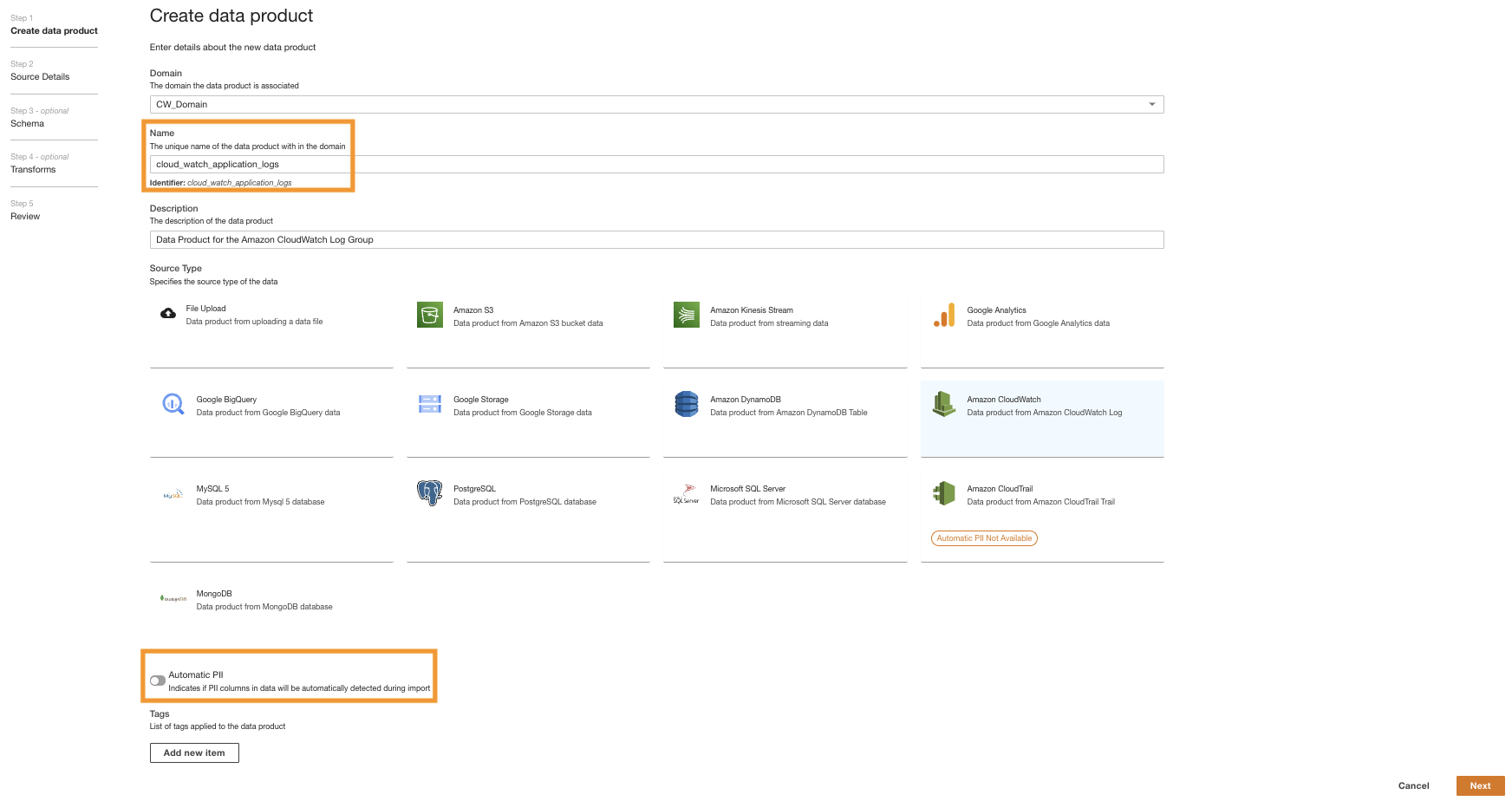
- Sur la console ADA, accédez au domaine ADA et créez un produit de données CloudWatch.
- Pour Nomentrez un nom.
- Pour Type de Source, '; '; ; Amazon Cloud Watch.
- Désactiver IIP automatique.
ADA a une fonctionnalité qui détecte automatiquement les données d'informations personnelles identifiables (PII) lors de l'importation qui est activée par défaut. Pour cette démo, nous désactivons cette option pour le produit de données, car la découverte des données PII n'entre pas dans le cadre de cette démo.
- Selectionnez Suivant.
- Recherchez et choisissez l'ARN du groupe de journaux CloudWatch copié à partir de l'étape précédente.

- Copiez l'ARN du groupe de journaux.
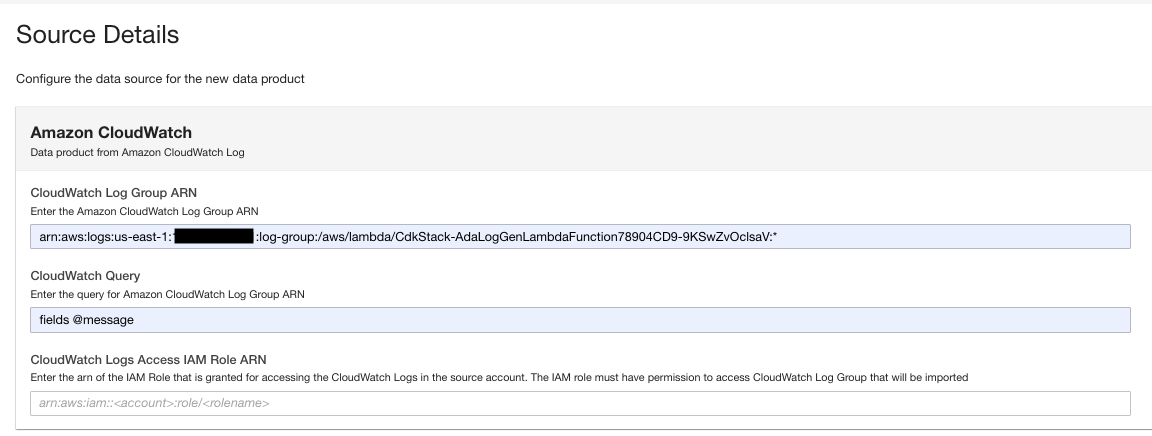
- Sur la page du produit de données, saisissez l'ARN du groupe de journaux.
- Pour Requête CloudWatch, entrez une requête que vous souhaitez qu'ADA obtienne du groupe de journaux.
Dans cette démonstration, nous interrogeons le champ @message car nous souhaitons obtenir les journaux d'application du groupe de journaux.
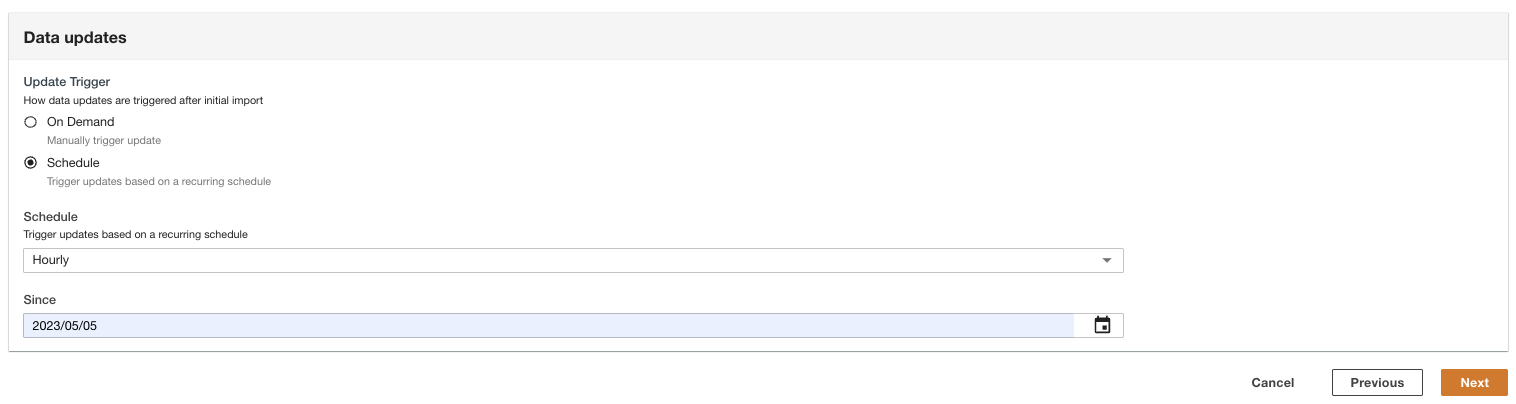
- Sélectionnez la manière dont les mises à jour des données sont déclenchées après l'importation initiale.
ADA peut être configuré pour ingérer les données de la source à des intervalles flexibles (jusqu'à 15 minutes ou plus) ou à la demande. Pour la démo, nous avons configuré les mises à jour des données pour qu'elles s'exécutent toutes les heures.
- Selectionnez Suivant.
Ensuite, ADA se connectera au groupe de journaux et interrogera le schéma. Étant donné que les journaux sont au format de journal Apache, nous transformons les journaux en champs distincts afin de pouvoir exécuter des requêtes sur les champs de journal spécifiques. ADA fournit quatre défaut transformations et prend en charge la transformation personnalisée via un script Python. Dans cette démo, nous exécutons un script Python personnalisé pour transformer le champ de message JSON en champs Apache Log Format.
- Selectionnez Schéma de transformation.
- Selectionnez Créer une nouvelle transformation.
- Télécharger le
apache-log-extractor-transform.pyscénario de la/asset/transform_logs/dossier. - Selectionnez Envoyer.
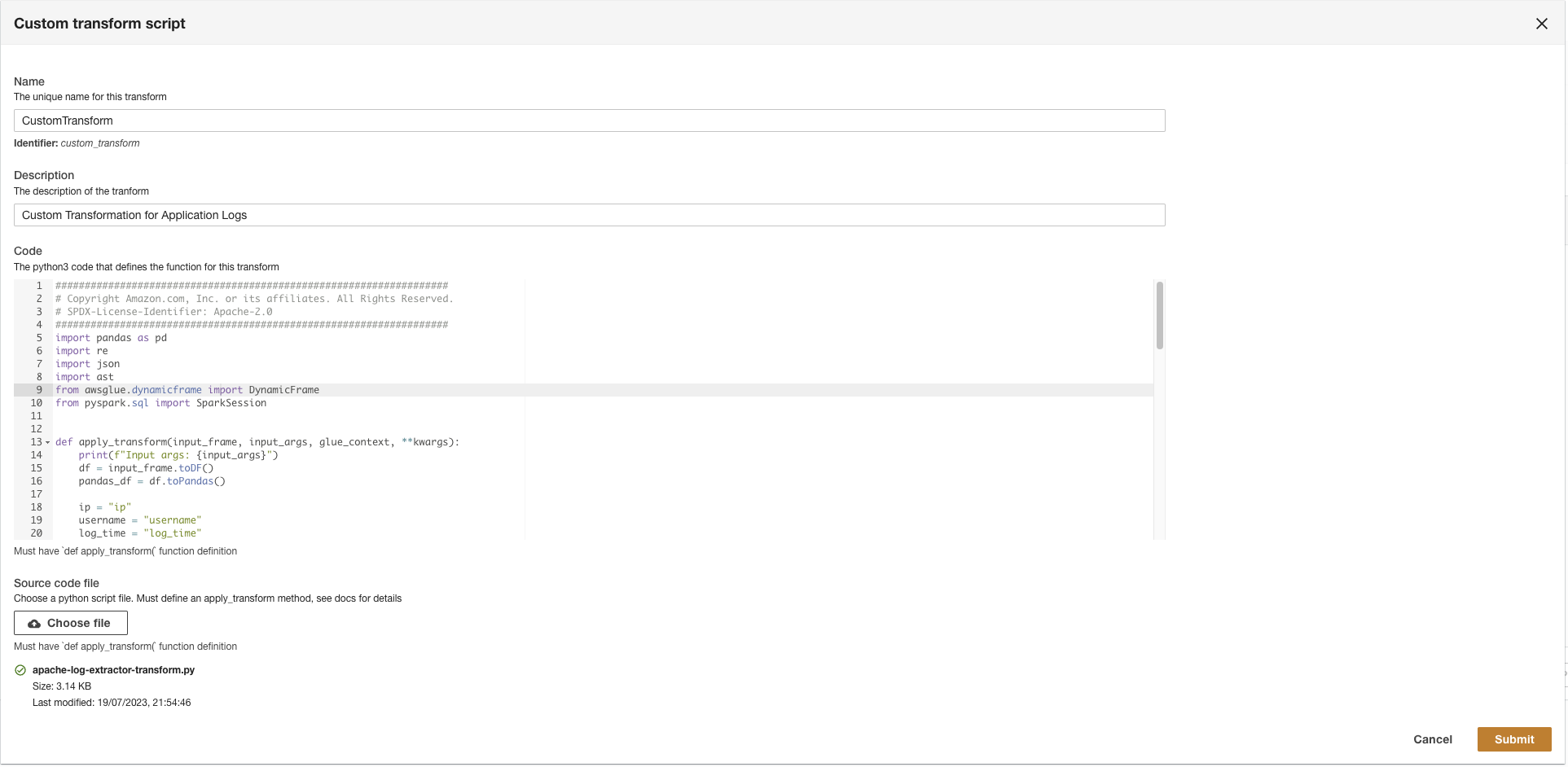
ADA transformera les journaux CloudWatch à l'aide du script et présentera le schéma traité.
- Selectionnez Suivant.
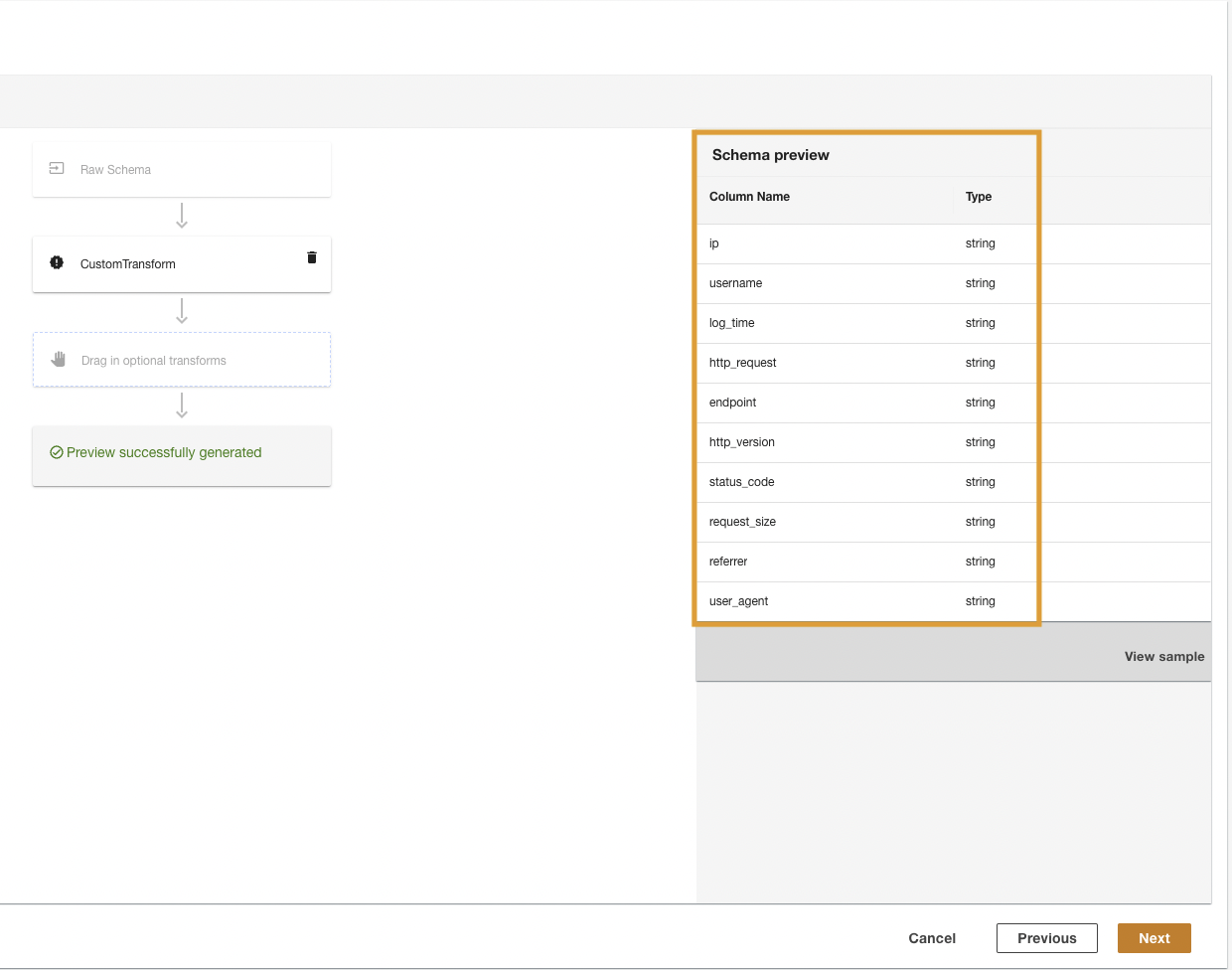
- Dans la dernière étape, passez en revue les étapes et choisissez Envoyer.
ADA démarrera le traitement des données, créera les pipelines de données et préparera les groupes de journaux CloudWatch à interroger à partir de Query Workbench. Ce processus prendra quelques minutes et sera affiché sur la console ADA sous Produits de données.
Créer un produit de données Amazon S3
Nous répétons les étapes pour ajouter les journaux historiques à partir de la source de données Amazon S3 et rechercher les données de référence à partir de la table DynamoDB. Pour ces deux sources de données, nous ne créons pas de transformations personnalisées, car les formats de données sont au format CSV (pour les journaux historiques) et les attributs clés (pour les données de recherche de référence).
- Sur la console ADA, créez un nouveau produit de données.
- Entrez un nom (
hist_logs) et choisissez Amazon S3.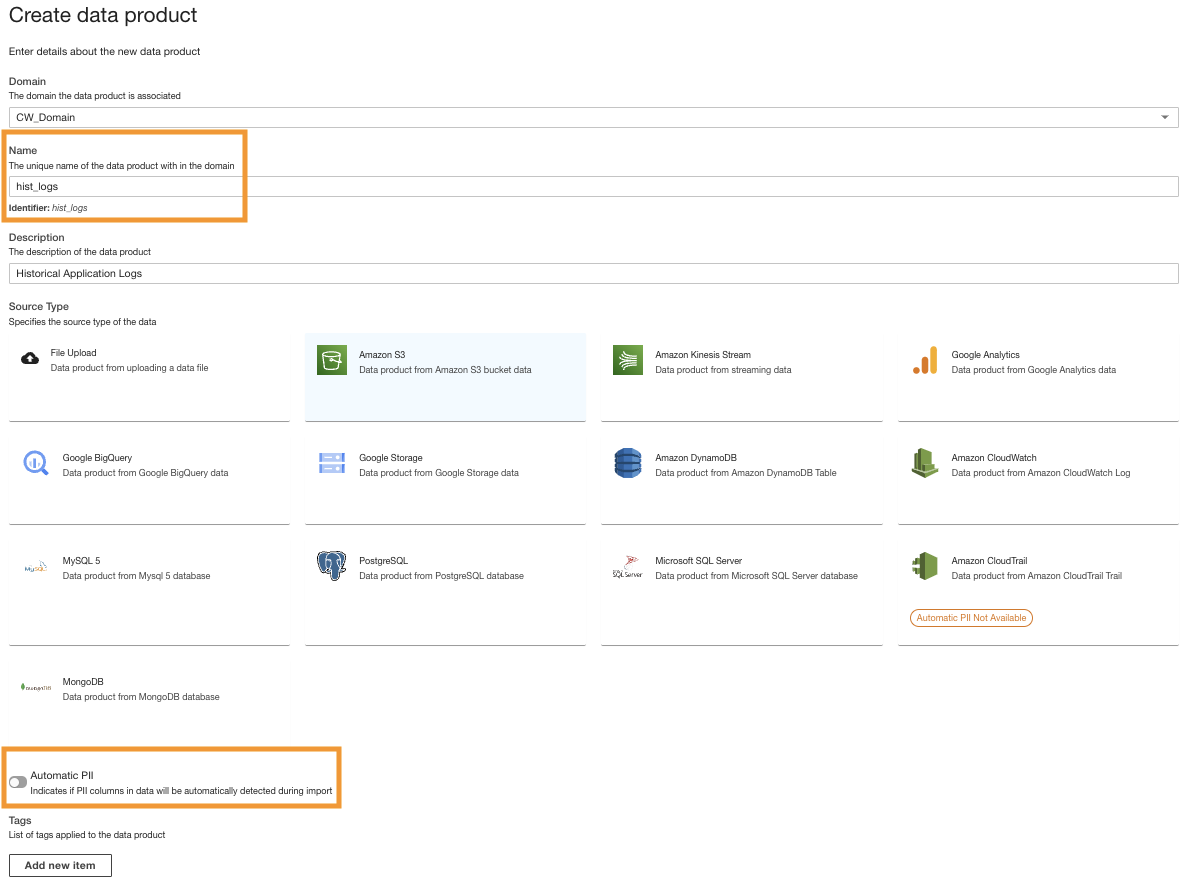
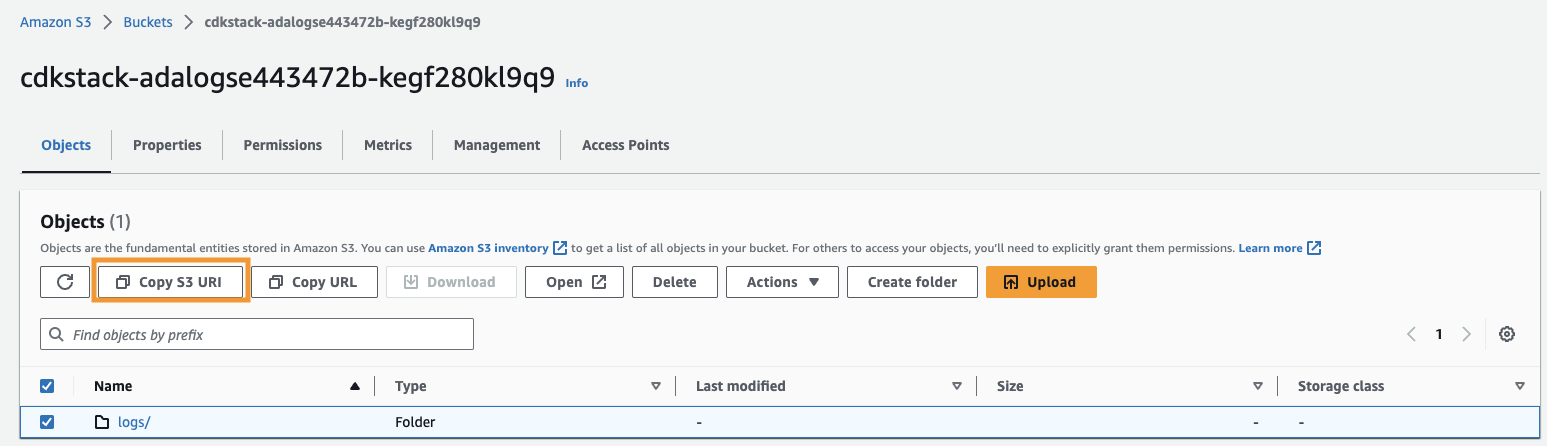
- Copiez l'URI Amazon S3 (le texte après
arn:aws:s3:::) duCdkStack.S3variable de sortie et accédez à la console Amazon S3. - Dans la zone de recherche, saisissez le texte copié, ouvrez le compartiment S3, sélectionnez le
/logsdossier, puis choisissez Copier l'URI S3.
Les journaux historiques sont stockés dans ce chemin.
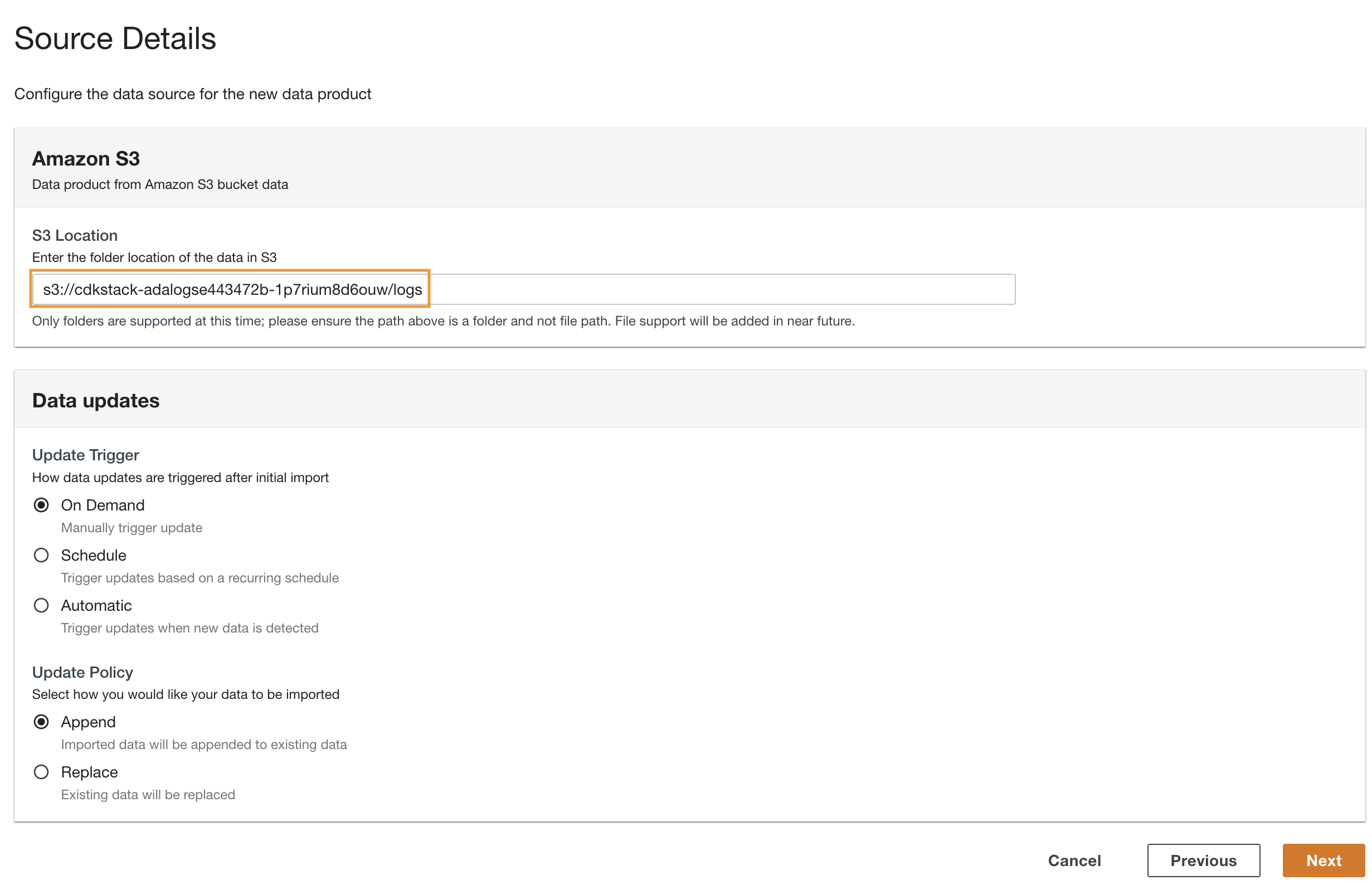
- Revenez à la console ADA et entrez l'URI S3 copié pour Emplacement S3.
- Pour Déclencheur de mise à jour, sélectionnez On Demand car les journaux historiques sont mis à jour à une fréquence indéterminée.
- Pour Politique de mise à jour, sélectionnez Ajouter pour ajouter des données nouvellement importées aux données existantes.
- Selectionnez Suivant.
ADA traite le schéma des fichiers dans le chemin du dossier sélectionné. Étant donné que les journaux sont au format CSV, ADA est capable de lire les noms de colonne sans nécessiter de transformations supplémentaires. Cependant, les colonnes status_code ainsi que request_size sont déduits comme étant de type long par ADA. Nous souhaitons conserver la cohérence des types de données de colonne parmi les produits de données afin de pouvoir joindre les tables de données et interroger les données. La colonne status_code sera utilisé pour créer des jointures entre les tables de données.
- Selectionnez Schéma de transformation pour changer les types de données des deux colonnes en type de données chaîne.
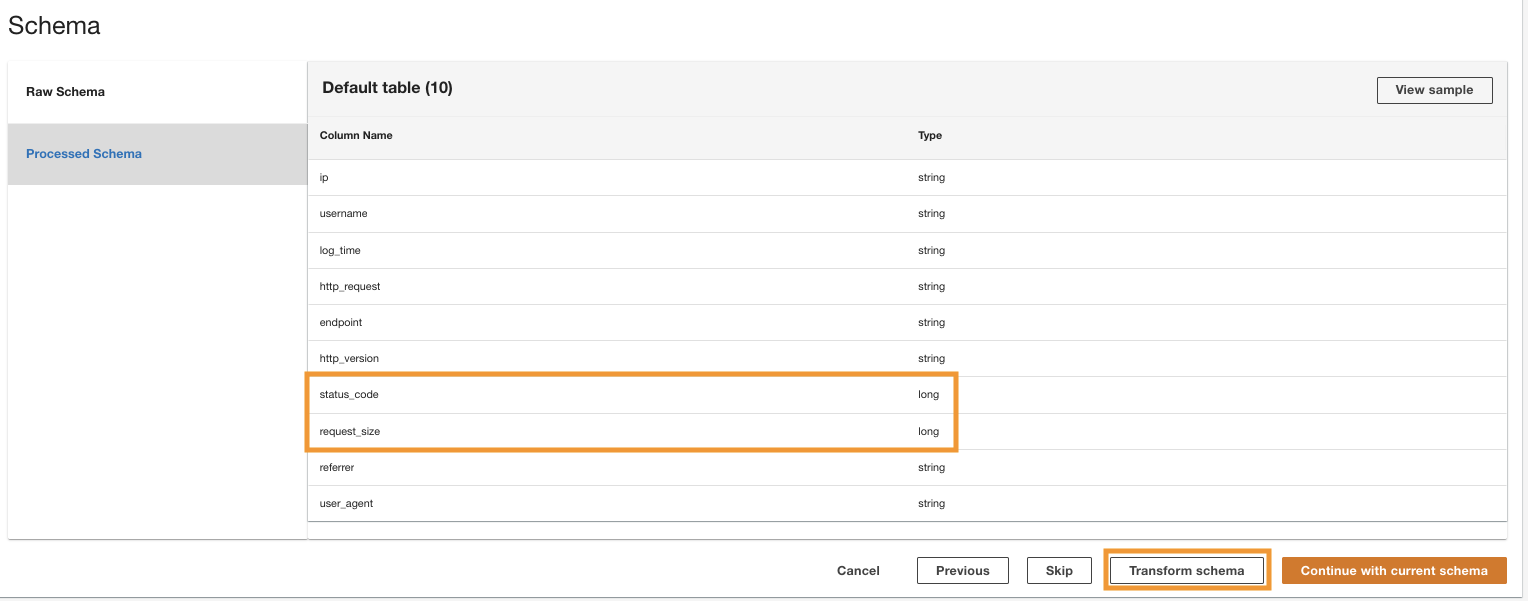
Notez les noms de colonne en surbrillance dans le Aperçu du schéma avant d'appliquer les transformations de type de données.
- Dans le Plan de transformation volet, sous Transformations intégrées, choisissez Appliquer le mappage.
Cette option vous permet de changer le type de données d'un type à un autre.
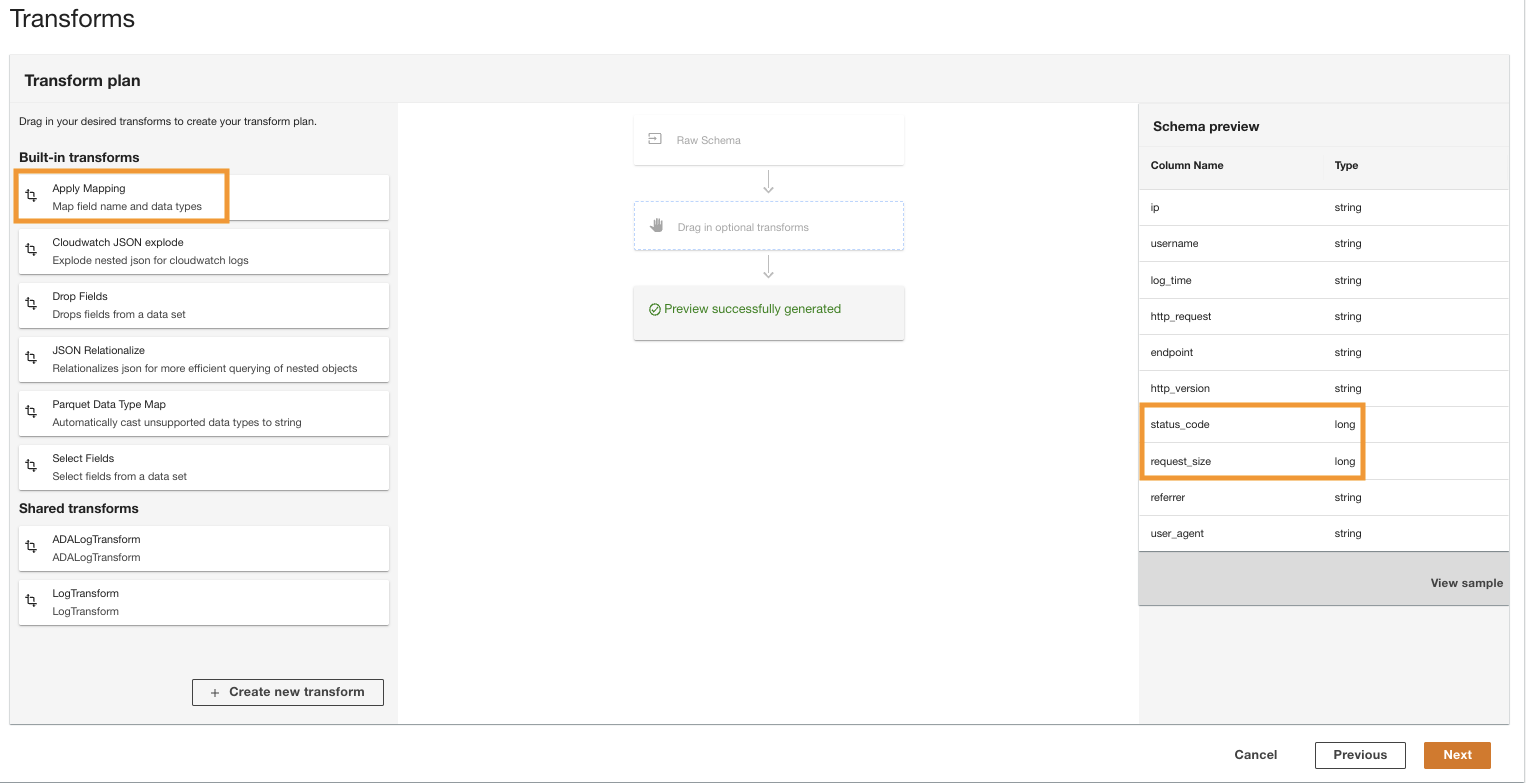
- Dans le Appliquer le mappage section, désélectionner Supprimer d'autres champs.
Si cette option n'est pas désactivée, seules les colonnes transformées seront conservées et toutes les autres colonnes seront supprimées. Comme nous voulons conserver toutes les colonnes, nous désactivons cette option.
- Sous Mappages de champspour Ancien nom ainsi que Nouveau nom, Entrer
status_codeet pour Nouveau genre, Entrerstring.
- Selectionnez Ajouter un item.
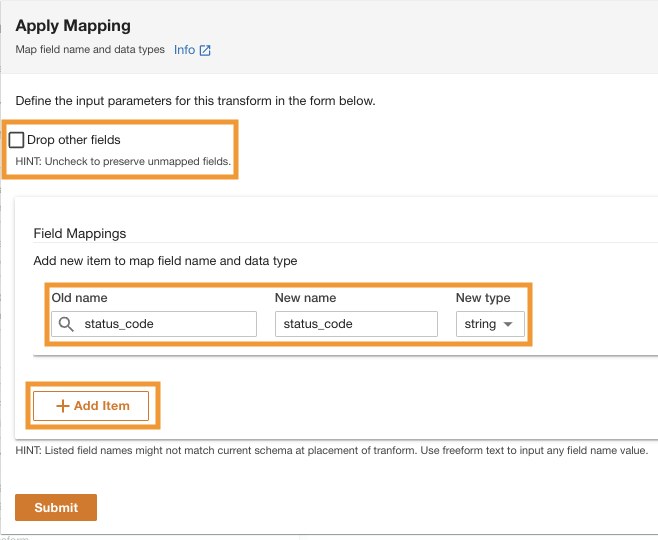
- Pour Ancien nom ainsi que Nouveau nom¸ entrez request_size et pour Nouveau type de données, entrez la chaîne.
- Selectionnez Envoyer.
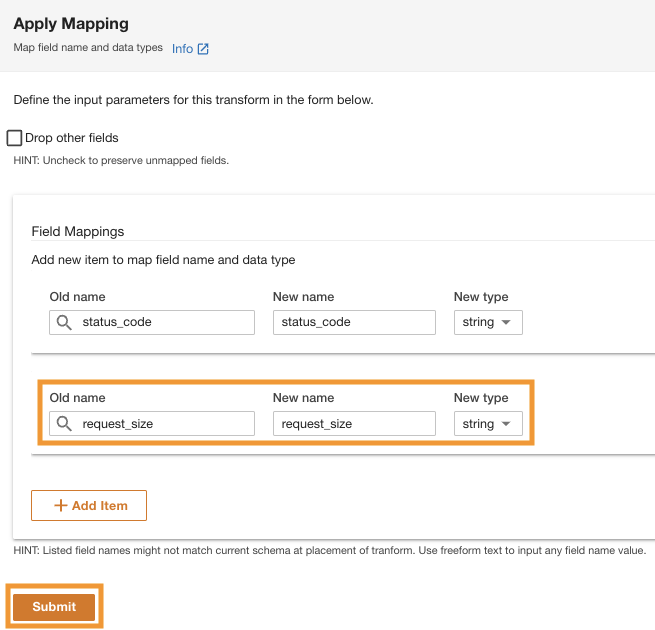
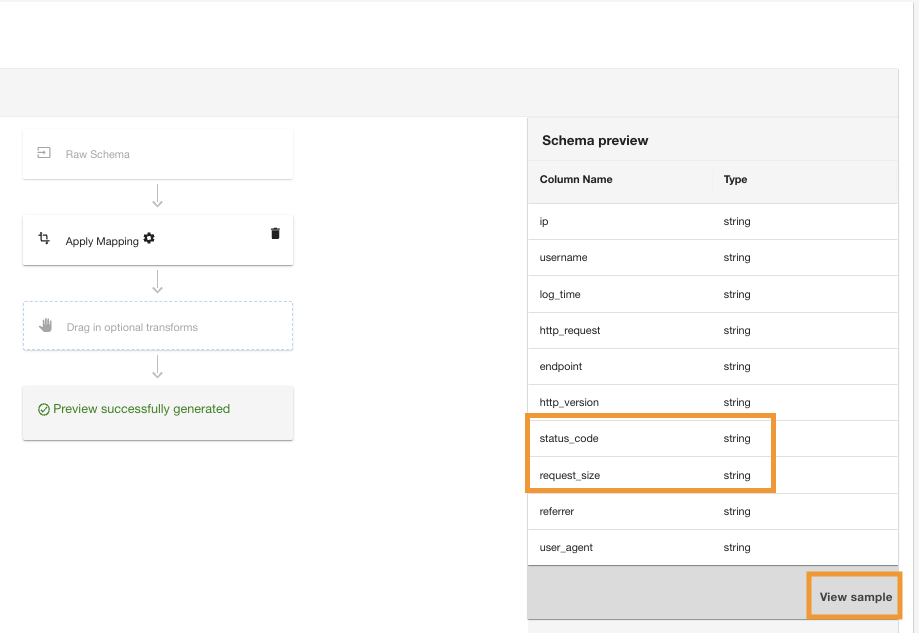
ADA appliquera la transformation de mappage sur la source de données Amazon S3. Notez les types de colonne dans le Aperçu du schéma vitre.
- Selectionnez Voir l'échantillon pour prévisualiser les données avec la transformation appliquée.
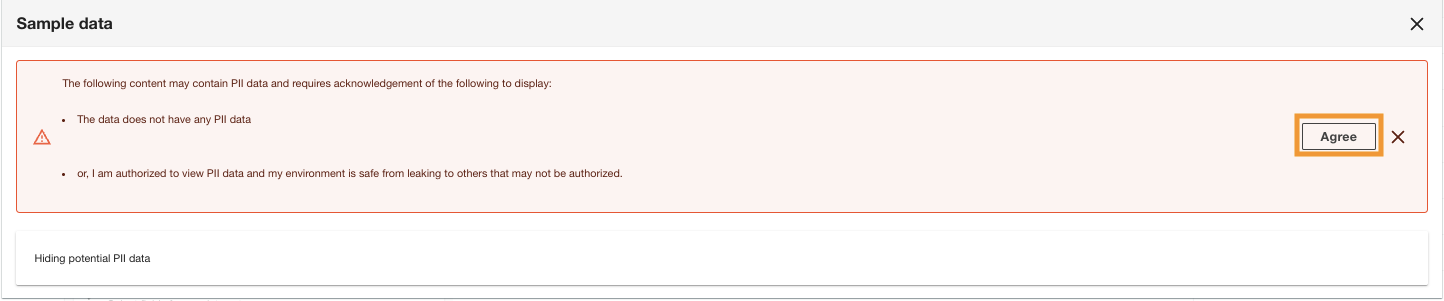
ADA affichera l'accusé de réception des données PII pour s'assurer que seuls les utilisateurs autorisés peuvent afficher les données ou que l'ensemble de données ne contient aucune donnée PII.
- Selectionnez Accepter pour continuer à afficher les exemples de données.
Notez que le schéma est identique au schéma de groupe de journaux CloudWatch, car les journaux d'application actuels et historiques sont au format de journal Apache.
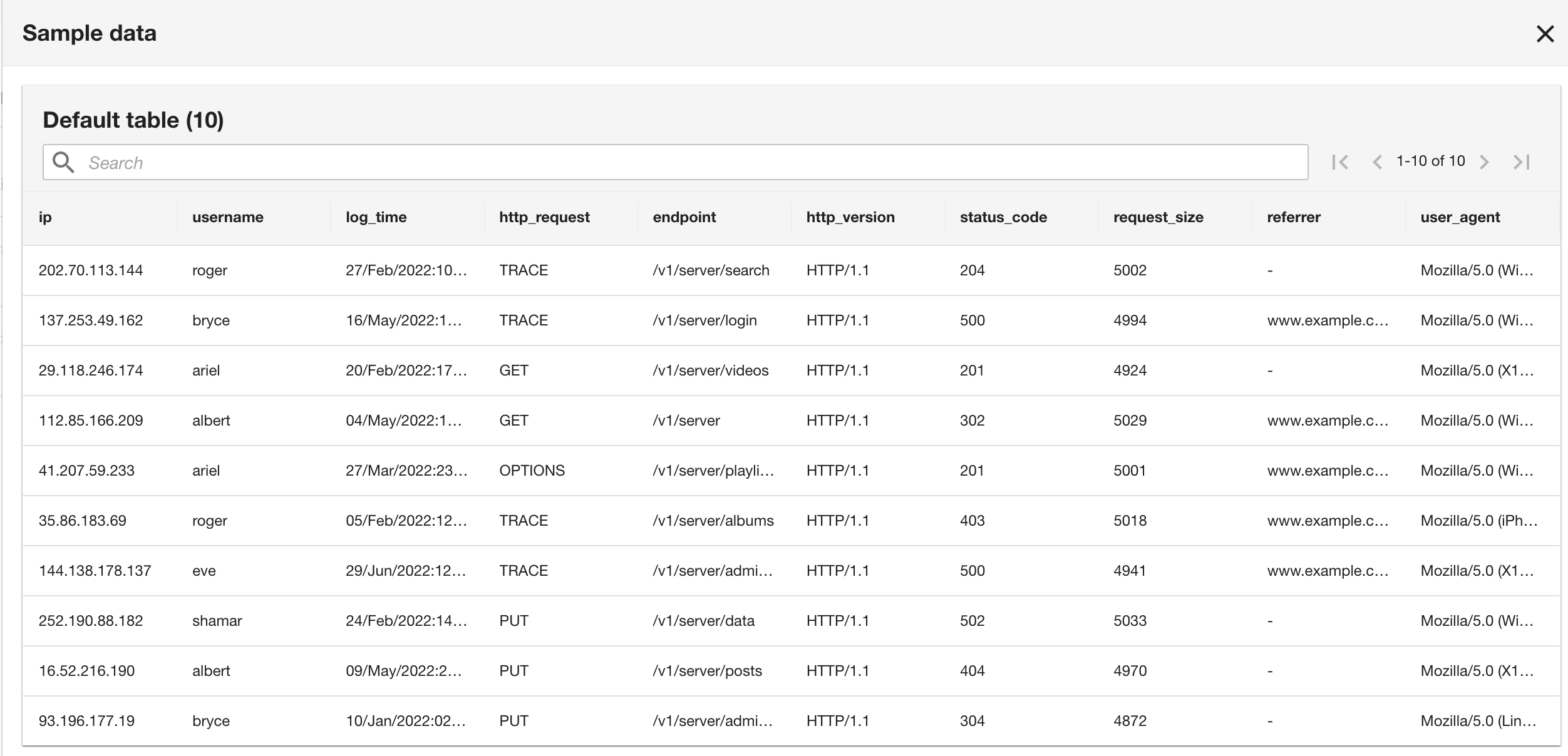
- Dans la dernière étape, passez en revue la configuration et choisissez Envoyer.
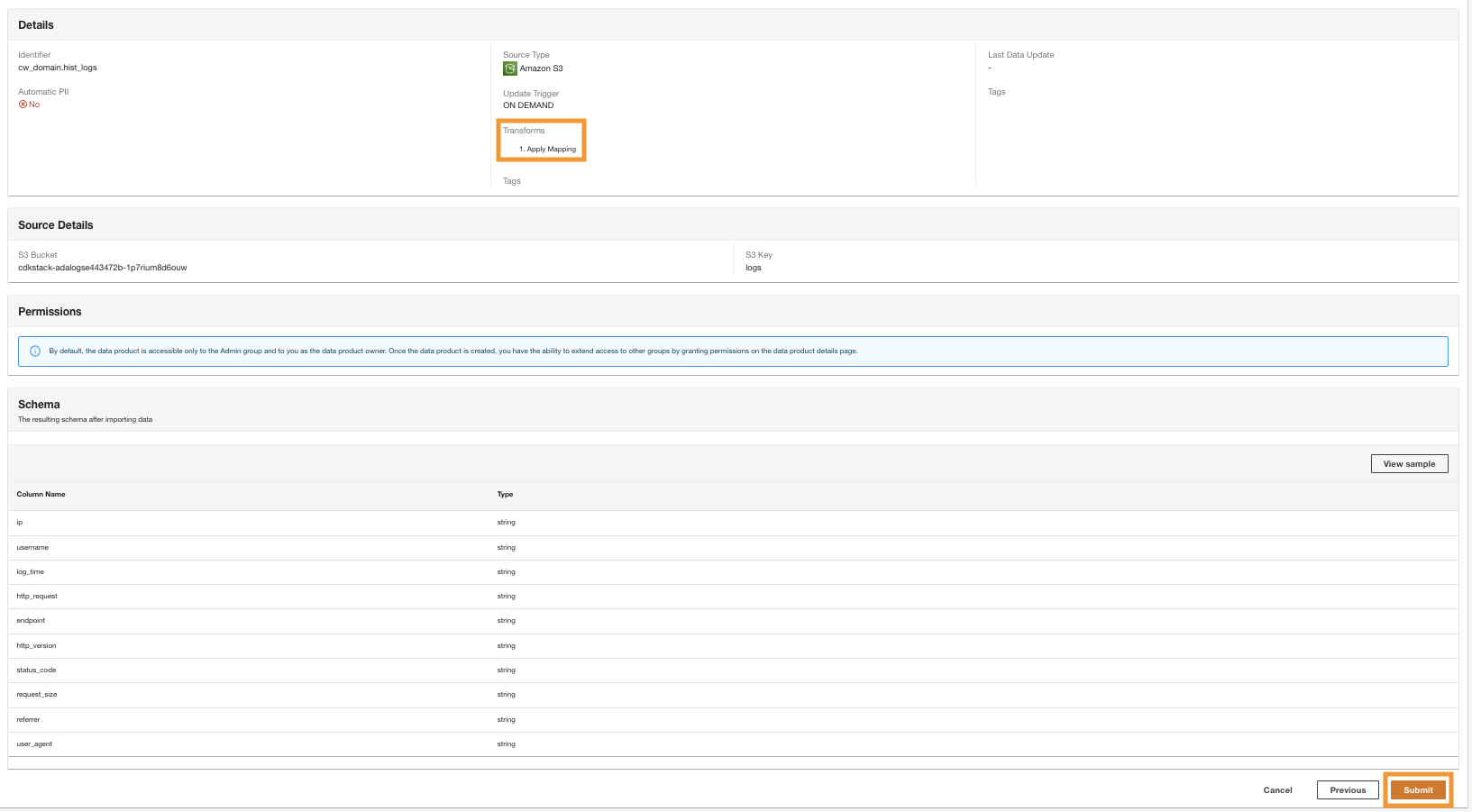
ADA commence à traiter les données à partir de la source Amazon S3, crée l'infrastructure principale et prépare le produit de données. Ce processus prend quelques minutes selon la taille des données.
Créer un produit de données DynamoDB
Enfin, nous créons un produit de données DynamoDB. Effectuez les étapes suivantes :
- Sur la console ADA, créez un nouveau produit de données.
- Entrez un nom (
lookup) et choisissez Amazon DynamoDB.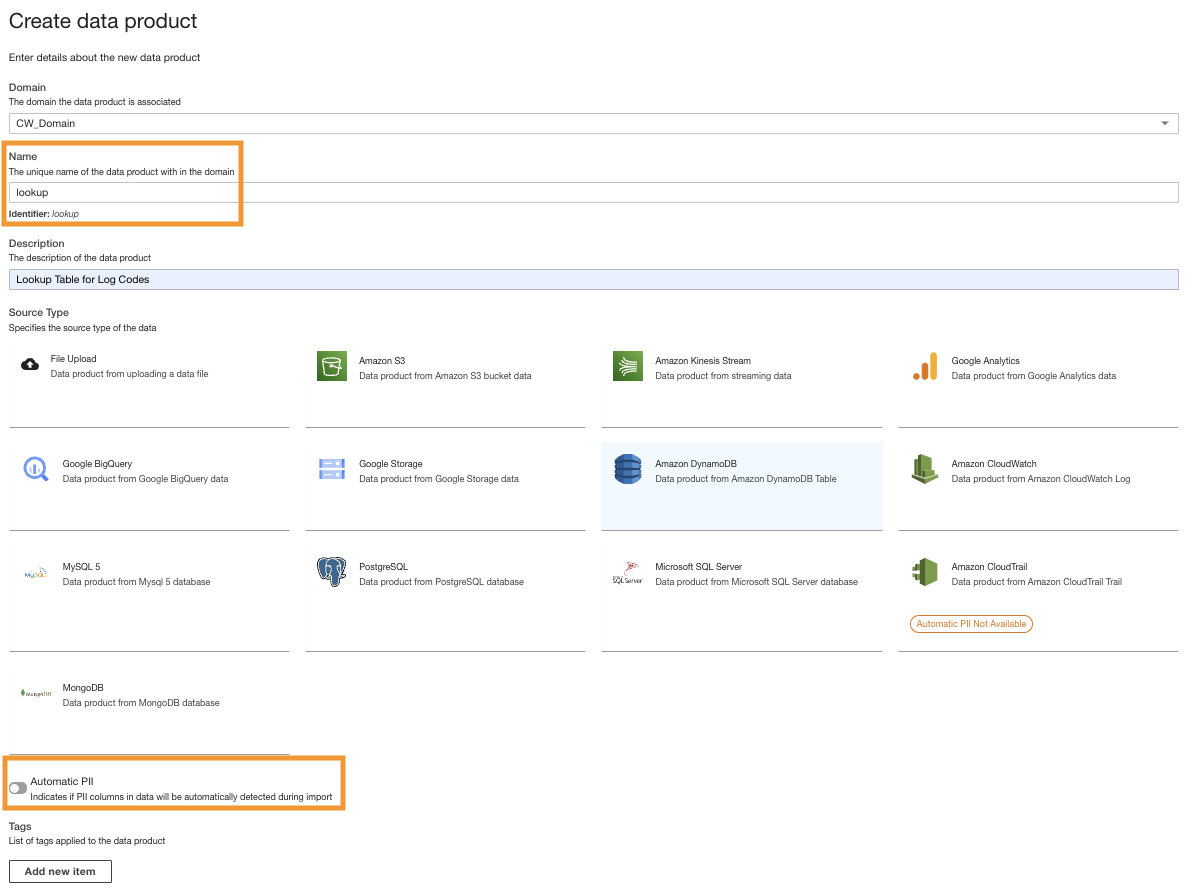
- Entrer le
Cdk.DynamoDBTablevariable de sortie pour ARN de la table DynamoDB.
Cette table contient des attributs clés qui seront utilisés comme table de recherche dans cette démo. Pour les données de recherche, nous utilisons les codes HTTP et les descriptions longues et courtes des codes. Vous pouvez également utiliser PostgreSQL, MySQL ou une source de fichier CSV comme alternative.
- Pour Déclencheur de mise à jour, sélectionnez À la demande.
Les mises à jour seront à la demande car la recherche est principalement à des fins de référence lors de l'interrogation et toutes les mises à jour des données de recherche peuvent être mises à jour dans ADA à l'aide de déclencheurs à la demande.
- Selectionnez Suivant.
ADA lit le schéma à partir du schéma DynamoDB sous-jacent et présente le nom et le type de la colonne pour une transformation facultative. Nous allons continuer avec la sélection de schéma par défaut car les types de colonne sont cohérents avec les types du groupe de journaux CloudWatch et de la source de données Amazon S3 CSV. Avoir des types de données cohérents dans toutes les sources de données nous permet d'écrire des requêtes pour récupérer des enregistrements en joignant les tables à l'aide des champs de colonne. Par exemple, la colonne key dans le schéma DynamoDB correspond à la status_code dans les produits de données Amazon S3 et CloudWatch. Nous pouvons écrire des requêtes qui peuvent joindre les trois tables en utilisant le nom de la colonne key. Un exemple est présenté dans la section suivante.
- Selectionnez Continuer avec le schéma actuel.
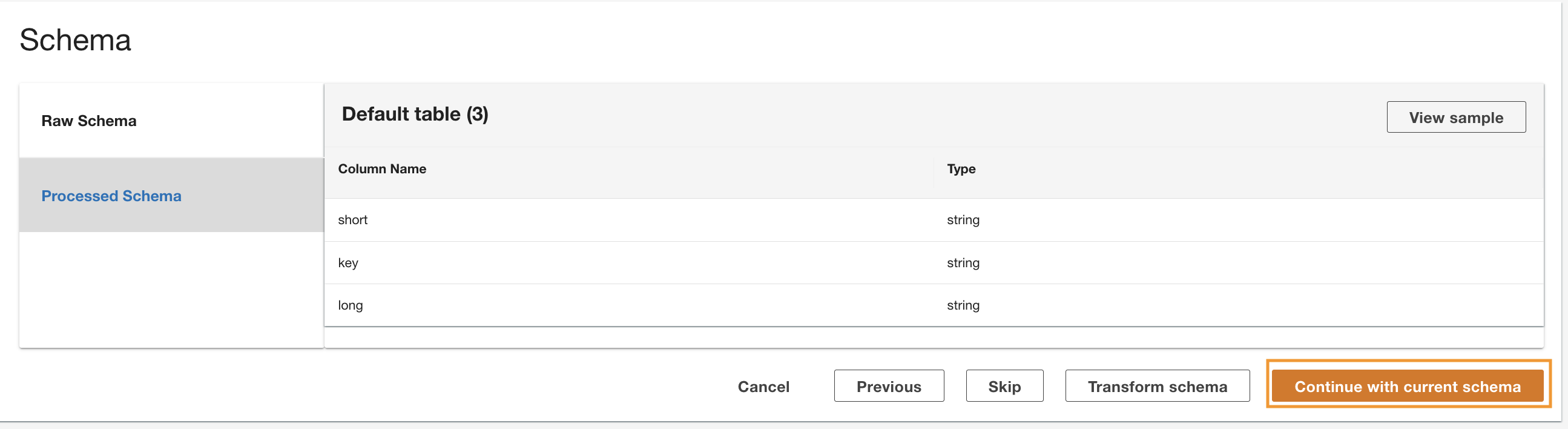
- Passez en revue la configuration et choisissez Envoyer.
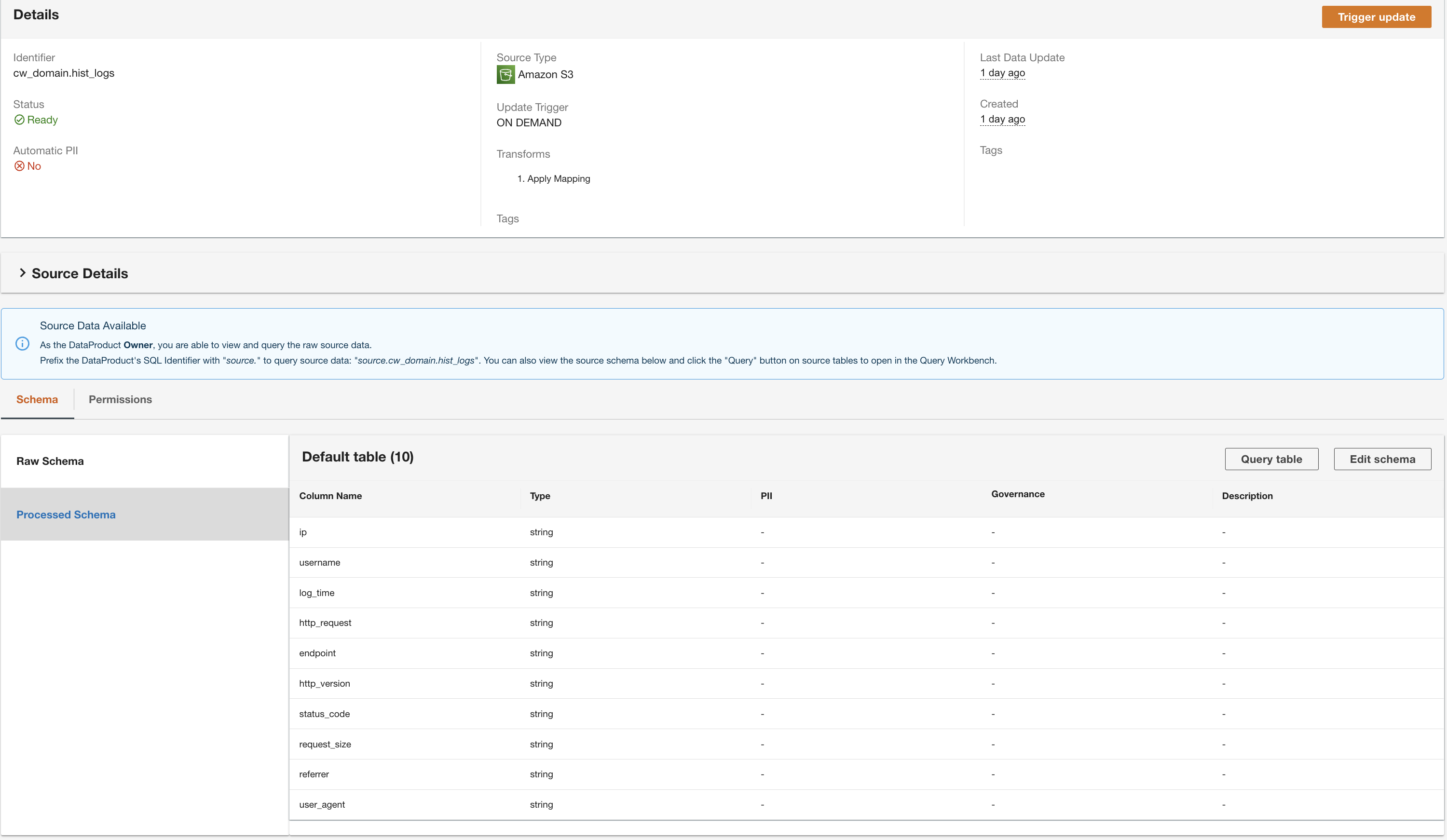
ADA traitera les données de la source de données de la table DynamoDB et préparera le produit de données. Selon la taille des données, ce processus prend quelques minutes.
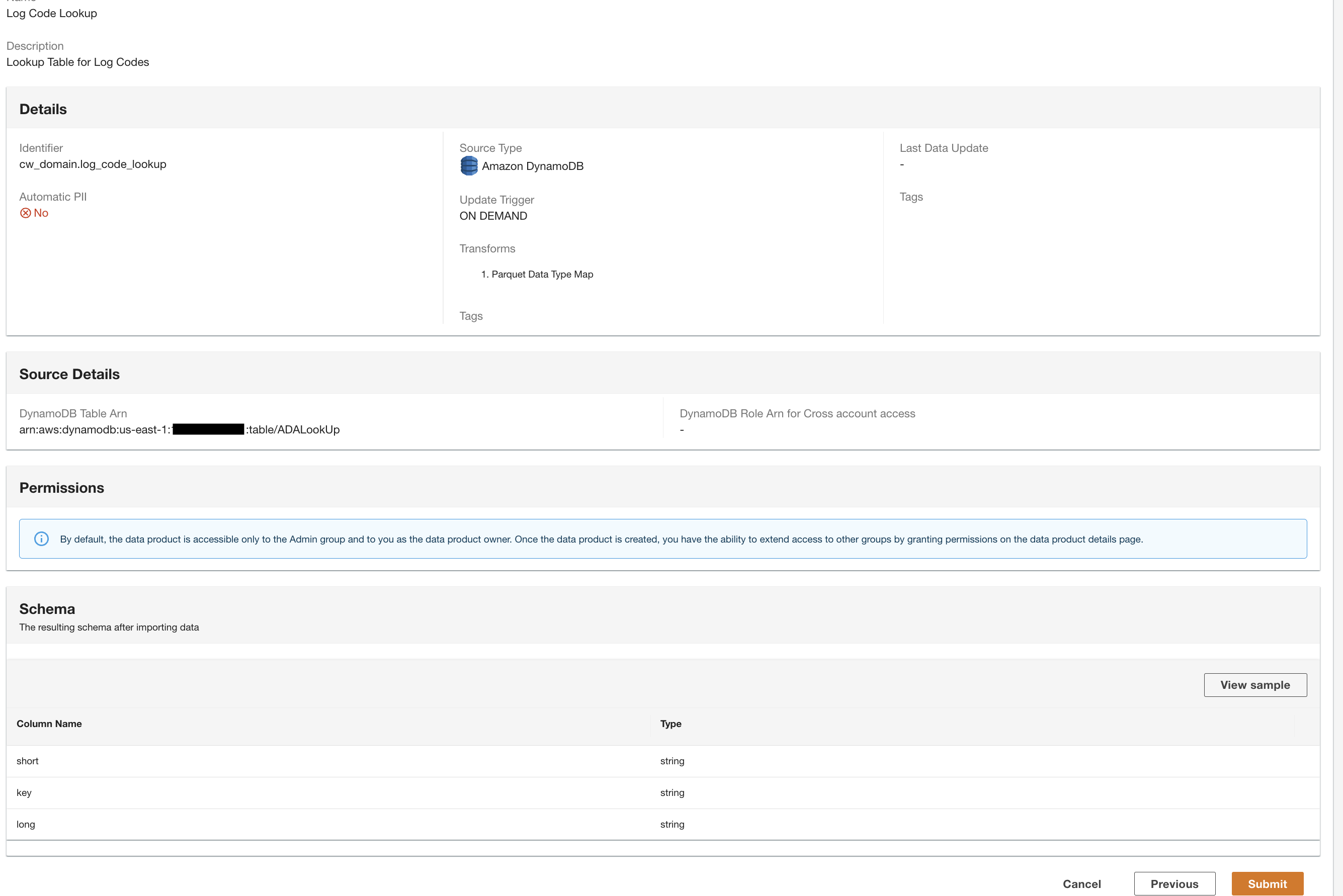
Nous avons maintenant les trois produits de données traités par ADA et disponibles pour que vous puissiez exécuter des requêtes.

Utiliser le Query Workbench pour interroger les données
ADA vous permet d'exécuter des requêtes sur les produits de données tout en extrayant la source de données et en la rendant accessible à l'aide de SQL (Structured Query Language). Vous pouvez écrire des requêtes et joindre les tables comme vous le feriez pour interroger des tables dans une base de données relationnelle. Nous démontrons la capacité d'interrogation d'ADA via deux scénarios utilisateur. Dans les deux scénarios, nous joignons un ensemble de données de journal d'application à la table de recherche des codes d'erreur. Dans le premier cas d'utilisation, nous interrogeons les journaux d'application actuels pour identifier les 10 points de terminaison d'application les plus consultés, ainsi que les codes d'état HTTP correspondants :
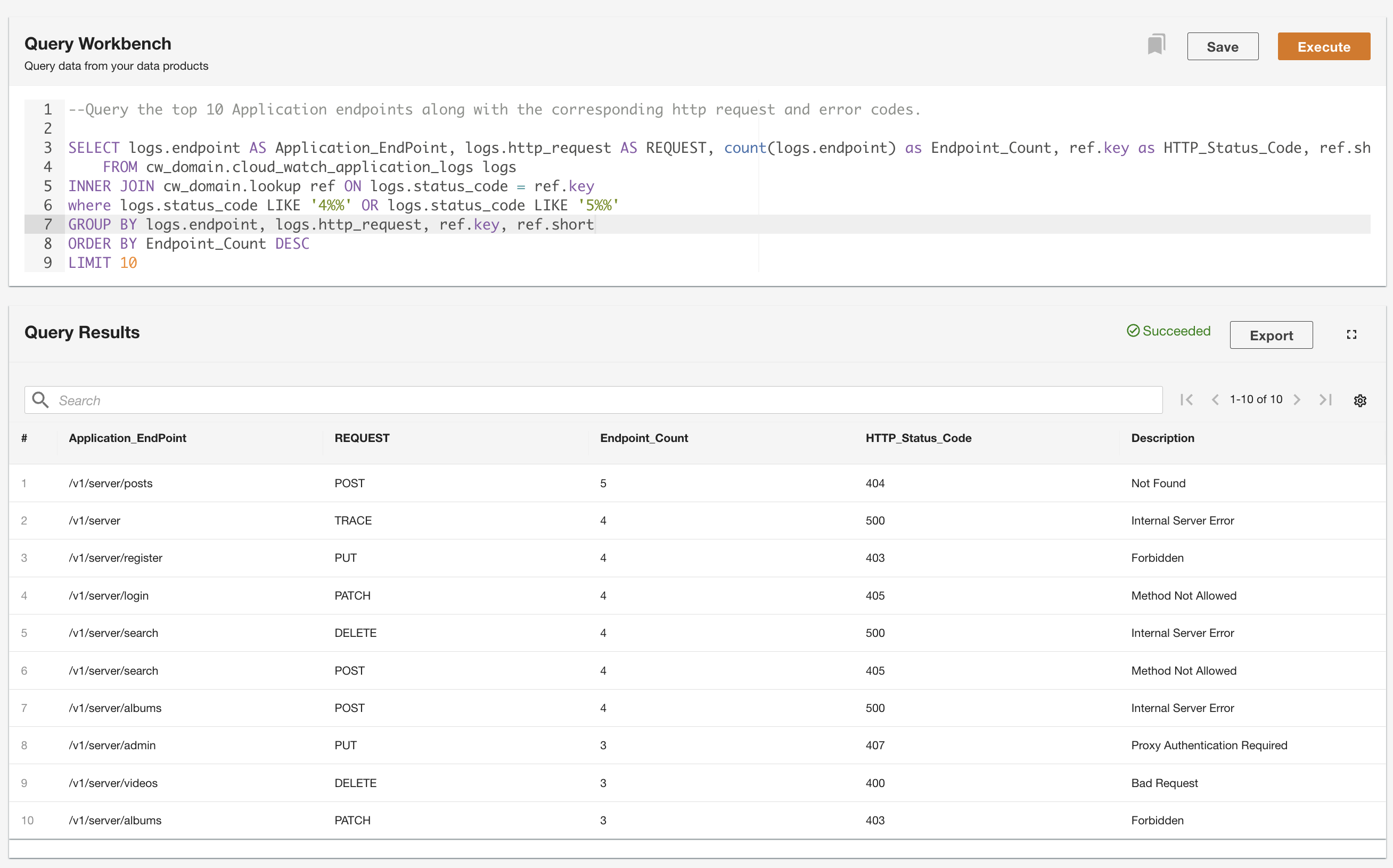
Dans le deuxième exemple, nous interrogeons la table des journaux historiques pour obtenir les 10 principaux points de terminaison d'application avec le plus d'erreurs afin de comprendre le modèle d'appel du point de terminaison :
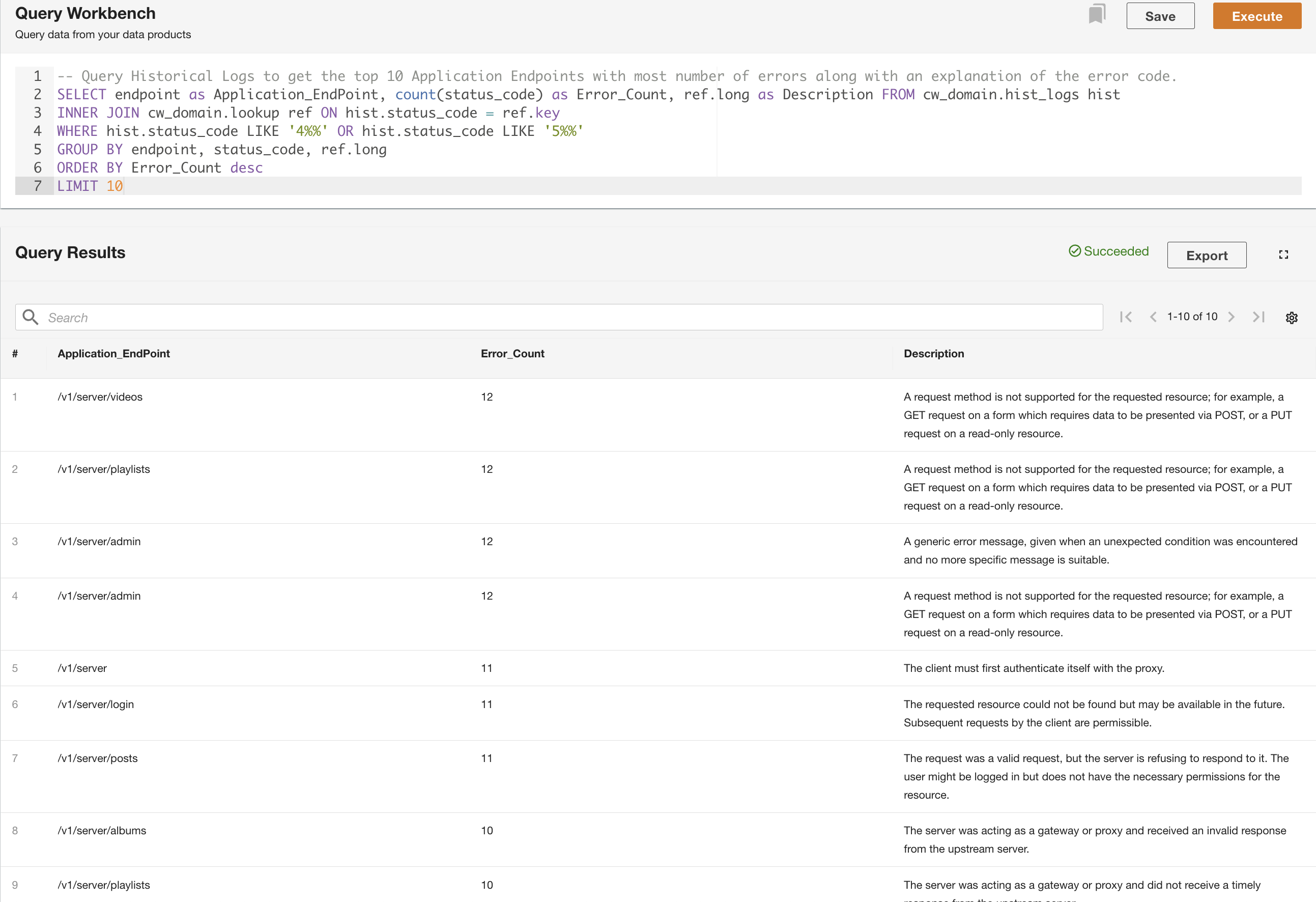
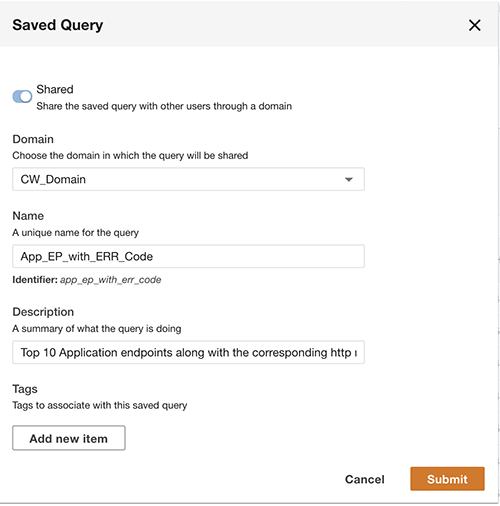
Outre l'interrogation, vous pouvez éventuellement enregistrer la requête et partager la requête enregistrée avec d'autres utilisateurs du même domaine. Les requêtes partagées sont accessibles directement depuis le Query Workbench. Les résultats de la requête peuvent également être exportés au format CSV.
Visualisez les produits de données ADA dans Tableau
ADA offre la possibilité de connect à des outils de BI tiers pour visualiser les données et créer des rapports à partir des produits de données ADA. Dans cette démo, nous utilisons l'intégration native d'ADA avec Tableau pour visualiser les données des trois produits de données que nous avons configurés précédemment. En utilisant le connecteur Athena de Tableau et en suivant les étapes de Configuration du tableau, vous pouvez configurer ADA comme source de données dans Tableau. Une fois qu'une connexion réussie a été établie entre Tableau et ADA, Tableau remplira les trois produits de données sous le catalogue Tableau cw_domain.
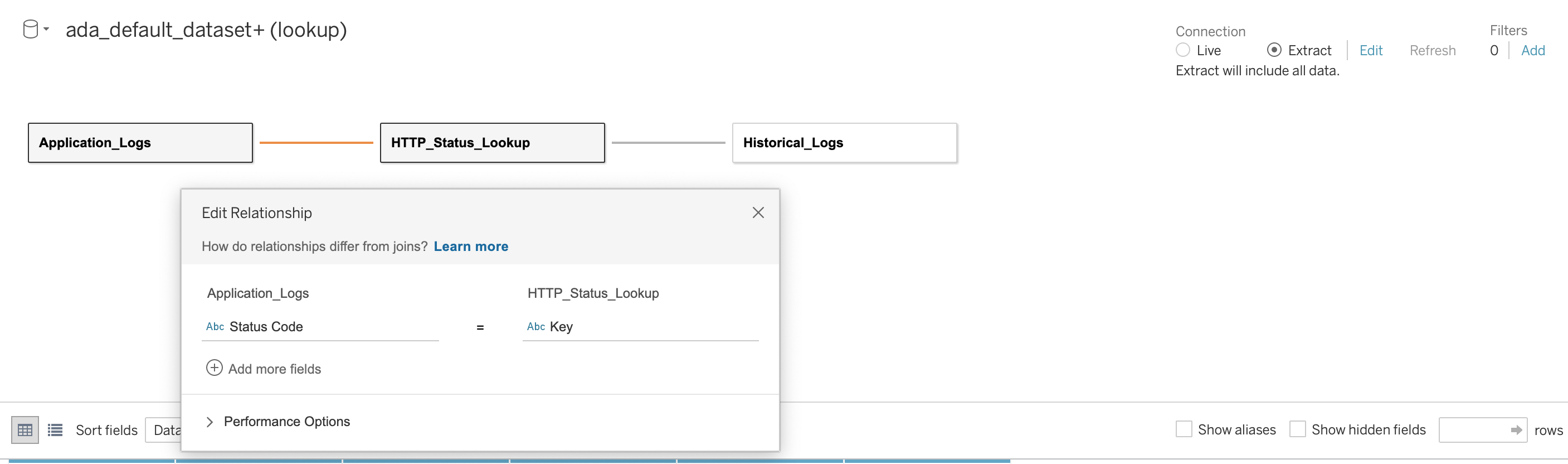
Nous établissons ensuite une relation entre les trois bases de données en utilisant le code d'état HTTP comme colonne de jonction, comme illustré dans la capture d'écran suivante. Tableau nous permet de travailler en mode en ligne et hors ligne avec les sources de données. En mode en ligne, Tableau se connectera à ADA et interrogera les produits de données en direct. En mode hors ligne, nous pouvons utiliser le Extraction option pour extraire les données d'ADA et importer les données dans Tableau. Dans cette démo, nous importons les données dans Tableau pour rendre l'interrogation plus réactive. Nous enregistrons ensuite le classeur Tableau. Nous pouvons inspecter les données des sources de données en choisissant la base de données et Mettre à jour maintenant.
Avec les configurations de source de données en place dans Tableau, nous pouvons créer des rapports, des graphiques et des visualisations personnalisés sur les produits de données ADA. Considérons deux cas d'utilisation pour les visualisations.
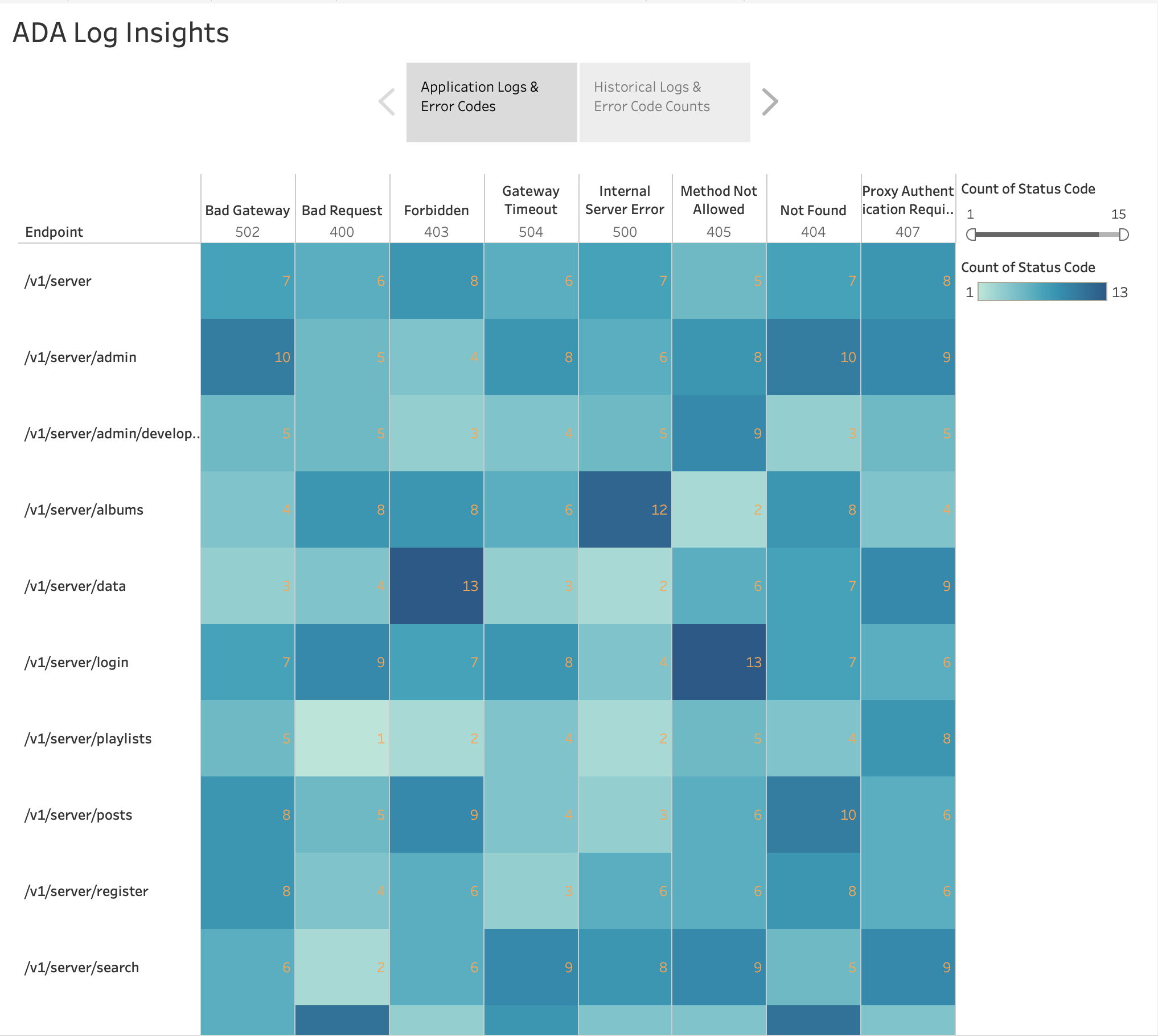
Comme le montre la figure suivante, nous avons visualisé la fréquence des erreurs HTTP par points de terminaison d'application à l'aide de la fonction intégrée de Tableau. carte thermique graphique. Nous avons filtré les codes d'état HTTP pour n'inclure que les codes d'erreur dans la plage 4xx et 5xx.
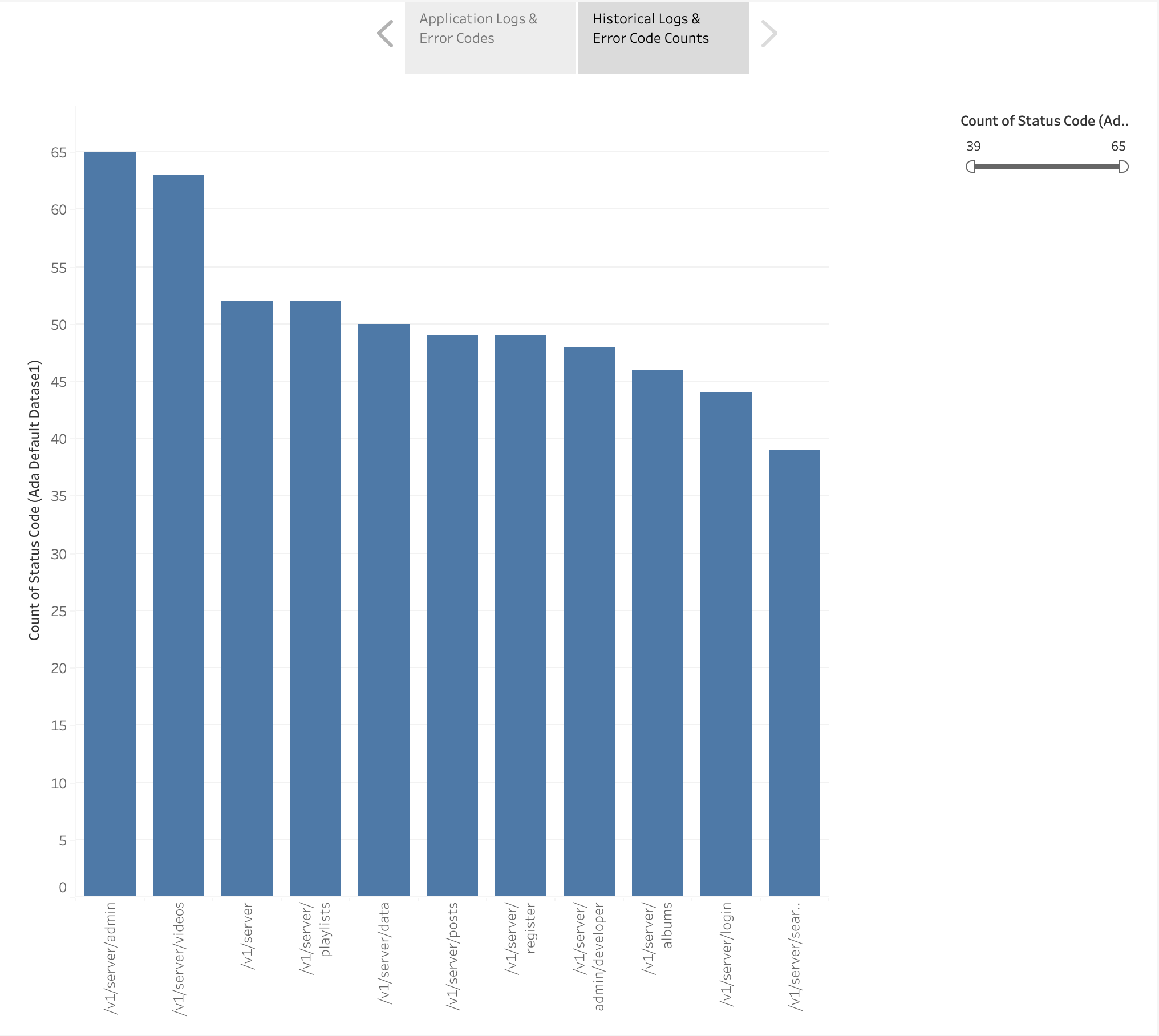
Nous avons également créé un graphique à barres pour représenter les points de terminaison de l'application à partir des journaux historiques classés par nombre de codes d'erreur HTTP. Dans ce graphique, nous pouvons voir que le /v1/server/admin point de terminaison a généré le plus de codes d'état d'erreur HTTP.
Nettoyer
Le nettoyage de l'exemple d'infrastructure d'application est un processus en deux étapes. Tout d'abord, pour supprimer l'infrastructure provisionnée pour les besoins de cette démo, exécutez la commande suivante dans le terminal :
Pour la question suivante, entrez y et AWS CDK supprimera les ressources déployées pour la démo :
Vous pouvez également supprimer les ressources via la console AWS CloudFormation en accédant à la pile CdkStack et en choisissant Supprimer.
La deuxième étape consiste à désinstaller ADA. Pour obtenir des instructions, reportez-vous à Désinstaller la solution.
Conclusion
Dans cet article, nous avons montré comment utiliser la solution ADA pour obtenir des informations à partir des journaux d'application stockés sur deux sources de données différentes. Nous avons montré comment installer ADA sur un compte AWS et déployer les composants de démonstration à l'aide d'AWS CDK. Nous avons créé des produits de données dans ADA et configuré les produits de données avec les sources de données respectives à l'aide des connecteurs de données intégrés d'ADA. Nous avons montré comment interroger les produits de données à l'aide de requêtes SQL standard et générer des informations sur les données de journal. Nous avons également connecté le client Tableau Desktop, un produit de BI tiers, à ADA et montré comment créer des visualisations par rapport aux produits de données.
ADA automatise le processus d'ingestion, de transformation, de gouvernance et d'interrogation de divers ensembles de données et simplifie la gestion du cycle de vie des données. Les connecteurs prédéfinis d'ADA vous permettent d'ingérer des données provenant de diverses sources de données. Les équipes logicielles ayant une connaissance de base des produits et services AWS seront en mesure de mettre en place une plateforme d'analyse de données opérationnelle en quelques heures et de fournir un accès sécurisé aux données. Les données peuvent ensuite être interrogées facilement et rapidement à l'aide d'une interface utilisateur Web intuitive et autonome.
Essayez ADA dès aujourd'hui pour gérer facilement et obtenir des informations à partir des données.
À propos des auteurs
 Aparajithan Vaidyanathan est architecte principal de solutions d'entreprise chez AWS. Il aide les entreprises clientes à migrer et à moderniser leurs charges de travail sur le cloud AWS. Il est un architecte cloud avec plus de 23 ans d'expérience dans la conception et le développement de systèmes logiciels d'entreprise, à grande échelle et distribués. Il est spécialisé dans l'apprentissage automatique et l'analyse de données, en mettant l'accent sur le domaine de l'ingénierie des données et des fonctionnalités. Il est un coureur de marathon en herbe et ses passe-temps incluent la randonnée, le vélo et passer du temps avec sa femme et ses deux garçons.
Aparajithan Vaidyanathan est architecte principal de solutions d'entreprise chez AWS. Il aide les entreprises clientes à migrer et à moderniser leurs charges de travail sur le cloud AWS. Il est un architecte cloud avec plus de 23 ans d'expérience dans la conception et le développement de systèmes logiciels d'entreprise, à grande échelle et distribués. Il est spécialisé dans l'apprentissage automatique et l'analyse de données, en mettant l'accent sur le domaine de l'ingénierie des données et des fonctionnalités. Il est un coureur de marathon en herbe et ses passe-temps incluent la randonnée, le vélo et passer du temps avec sa femme et ses deux garçons.
 Rachim Rahman est un développeur de logiciels basé à Sydney, en Australie, avec plus de 10 ans d'expérience dans le développement et l'architecture de logiciels. Il travaille principalement sur la création de solutions AWS open source à grande échelle pour les cas d'utilisation courants des clients et les problèmes commerciaux. Dans ses temps libres, il aime faire du sport et passer du temps avec ses amis et sa famille.
Rachim Rahman est un développeur de logiciels basé à Sydney, en Australie, avec plus de 10 ans d'expérience dans le développement et l'architecture de logiciels. Il travaille principalement sur la création de solutions AWS open source à grande échelle pour les cas d'utilisation courants des clients et les problèmes commerciaux. Dans ses temps libres, il aime faire du sport et passer du temps avec ses amis et sa famille.
 Hafiz Saadullah est chef de produit technique principal chez Amazon Web Services. Hafiz se concentre sur les solutions AWS, conçues pour aider les clients en résolvant les problèmes commerciaux courants et les cas d'utilisation.
Hafiz Saadullah est chef de produit technique principal chez Amazon Web Services. Hafiz se concentre sur les solutions AWS, conçues pour aider les clients en résolvant les problèmes commerciaux courants et les cas d'utilisation.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- GraphiquePrime. Élevez votre jeu de trading avec ChartPrime. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :possède
- :est
- :ne pas
- :où
- $UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- capacité
- Capable
- A Propos
- accès
- accédé
- accessible
- Compte
- à travers
- actes
- ADA
- ajouter
- ajout
- Supplémentaire
- adresser
- admin
- Après
- à opposer à
- Tous
- permettre
- permet
- le long de
- aussi
- alternative
- Amazon
- Amazon Web Services
- parmi
- an
- selon une analyse de l’Université de Princeton
- Analystes
- analytique
- il analyse
- ainsi que
- Une autre
- tous
- Apache
- api
- Apis
- Application
- applications
- appliqué
- Appliquer
- Application
- architecture
- SONT
- AS
- en herbe
- At
- attributs
- Australie
- Authentification
- autorisé
- Automatisation
- Automates
- automatiquement
- disponibles
- AWS
- AWS CloudFormation
- RETOUR
- backend
- barre
- basé
- Essentiel
- BE
- car
- était
- before
- sur mesure
- jusqu'à XNUMX fois
- tous les deux
- Box
- construire
- Développement
- intégré
- la performance des entreprises
- l'intelligence d'entreprise
- mais
- by
- Appelez-nous
- CAN
- aptitude
- maisons
- cas
- catalogue
- CD
- Change
- Graphique
- Charts
- Selectionnez
- choose
- client
- le cloud
- code
- codes
- collection
- Colonne
- Colonnes
- Commun
- complet
- composants électriques
- configuration
- configurée
- NOUS CONTACTER
- connecté
- connexion
- connecte
- Considérer
- cohérent
- Console
- contient
- continuer
- corrélée
- Corrélation
- Correspondant
- correspond
- Prix
- engendrent
- créée
- crée des
- La création
- Lettres de créance
- Courant
- Customiser
- des clients
- Clients
- tableau de bord
- données
- Analyse de Donnée
- informatique
- Base de données
- bases de données
- ensembles de données
- Réglage par défaut
- Demande
- Démo
- démontrer
- démontré
- Selon
- déployer
- déployé
- déploiement
- déploie
- la description
- un
- conception
- à poser
- détaillé
- détails
- Développeur
- développement
- Développement
- diagnostic
- différent
- directement
- handicapé
- découverte
- Commande
- distribué
- plusieurs
- Ne fait pas
- domaine
- domaines
- Ne pas
- chuté
- pendant
- chacun
- Plus tôt
- même
- édition
- non plus
- activé
- permet
- Endpoint
- critères
- ENGINEERING
- assurer
- Entrer
- Entreprise
- clients entreprise
- Solutions d'entreprise
- erreur
- Erreurs
- établir
- établies
- Ether (ETH)
- exemple
- existant
- d'experience
- Expliquer
- explication
- extrait
- extraire les données
- familier
- famille
- Fonctionnalité
- few
- champ
- Des champs
- Figure
- Déposez votre dernière attestation
- Fichiers
- finale
- finance
- Prénom
- flexible
- Focus
- se concentre
- Abonnement
- Pour
- le format
- quatre
- La fréquence
- amis
- De
- fonction
- Gain
- générer
- généré
- obtenez
- obtention
- gouvernant
- Réservation de groupe
- Groupes
- Vous avez
- ayant
- he
- vous aider
- Surbrillance
- randonnée
- sa
- historique
- Passe-temps
- organisé
- HEURES
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- IAM
- identique
- identifier
- Identite
- if
- importer
- in
- comprendre
- inclut
- Y compris
- d'information
- Infrastructure
- initiale
- idées.
- installer
- installation
- Des instructions
- des services
- l'intégration
- Intelligence
- Interactif
- intéressé
- Interfaces
- développement
- intuitif
- invoque
- impliqué
- aide
- IT
- rejoindre
- joindre
- Joint
- jpg
- json
- juste
- XNUMX éléments à
- ACTIVITES
- spécialisées
- langue
- gros
- grande échelle
- Nom
- plus tard
- lancement
- apprentissage
- Bibliothèque
- Autorisé
- vos produits
- comme
- LIMIT
- Gamme
- Liste
- le travail
- enregistrer
- enregistrement
- Location
- Style
- rechercher
- click
- machine learning
- a prendre une
- Fabrication
- gérer
- gestion
- manager
- de nombreuses
- Localisation
- cartographie
- Marathon
- Stratégie
- Matière
- significative
- message
- MFA
- pourrait
- émigrer
- minutes
- Mode
- moderniser
- PLUS
- (en fait, presque toutes)
- la plupart
- Mozilla
- authentification multi-facteurs
- MySQL
- prénom
- Nommé
- noms
- indigène
- NAVIGUER
- navigation
- Navigation
- Besoin
- nécessaire
- Besoins
- Nouveauté
- nouvellement
- next
- nombre
- of
- Offres Speciales
- direct
- Vieux
- on
- À la demande
- ONE
- en ligne
- uniquement
- ouvert
- open source
- opérationnel
- Option
- or
- de commander
- Autre
- Autres
- ande
- sortie
- vue d'ensemble
- page
- pain
- Mot de Passe
- chemin
- Patron de Couture
- effectuer
- autorisations
- Personnellement
- Téléphone
- pii
- pipeline
- Place
- Plaine
- plan
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- politiques
- Portail
- Post
- Postgresql
- alimenté
- Préparer
- Prépare
- conditions préalables
- représentent
- cadeaux
- Aperçu
- précédent
- qui se déroulent
- Directeur
- Avant
- d'ouvrabilité
- procéder
- processus
- traité
- les process
- traitement
- Produit
- Produit
- chef de produit
- Produits
- Produits et services
- Programmes
- Projet
- fournir
- à condition de
- de voiture.
- fournit
- but
- des fins
- Python
- requêtes
- question
- vite.
- gamme
- Lire
- solutions
- recevoir
- Articles
- visée
- région
- relation amoureuse
- pertinent
- supprimez
- répéter
- Rapports
- nécessaire
- conditions
- Resources
- ceux
- sensible
- Résultats
- conserver
- Avis
- équitation
- rôle
- racine
- Règle
- Courir
- coureur
- pour le running
- vente
- même
- Épargnez
- Escaliers intérieurs
- scénarios
- prévu
- portée
- Rechercher
- Deuxièmement
- Section
- sécurisé
- sécurité
- sur le lien
- choisi
- sélection
- envoyer
- envoyé
- séparé
- besoin
- Sans serveur
- service
- Services
- set
- mise
- Partager
- commun
- Shorts
- montré
- Spectacles
- étapes
- simplifié
- simplifiant
- Taille
- compétences
- So
- Logiciels
- développement de logiciels
- sur mesure
- Solutions
- Identifier
- Sources
- spécialiste
- spécialise
- groupe de neurones
- spécifié
- Dépenses
- Sports
- SQL
- empiler
- autonome
- Standard
- Commencer
- départs
- Statut
- étapes
- Étapes
- storage
- stockée
- Chaîne
- structuré
- réussi
- Avec succès
- tel
- Les soutiens
- sûr
- sydney
- Système
- table
- Tableau
- Prenez
- prend
- équipe
- équipes
- Technique
- compétences techniques
- terminal
- qui
- La
- La Source
- leur
- puis
- Là.
- Ces
- des tiers.
- this
- trois
- Avec
- fiable
- à
- aujourd'hui
- les outils
- top
- Top 10
- Total
- Transformer
- De La Carrosserie
- transformations
- transformé
- transformer
- se transforme
- déclenché
- deux
- type
- types
- sous
- sous-jacent
- comprendre
- a actualisé
- Actualités
- sur
- URI
- us
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- Interface utilisateur
- utilisateurs
- en utilisant
- Valeurs
- variable
- variété
- version
- via
- Voir
- souhaitez
- Façon..
- we
- web
- services Web
- WELL
- quand
- qui
- tout en
- large
- Large gamme
- femme
- sera
- comprenant
- dans les
- sans
- activités principales
- workflow
- vos contrats
- pourra
- écrire
- années
- you
- Votre
- zéphyrnet