Image générée avec DALL-E
À une époque où le traitement analytique des données constitue la différence cruciale entre une entreprise prospère et non, nous avons besoin d'une pile d'outils capable de répondre à ces besoins. Les progrès de la technologie ont contribué à faire progresser tous ces outils de données dont nous avons besoin, à savoir DuckDB et MotherDuck.
CanardDB est un système de gestion de base de données OLAP (SQL Online Analytical Processing) open source et en cours. Le système de base de données est conçu pour traiter rapidement les requêtes analytiques de données, quelle que soit la taille des données. Le système implémente un traitement en mémoire et des systèmes OLAP qui améliorent efficacement notre processus d'analyse des données.
DuckDB est parfait pour stocker et traiter des données tabulaires impliquant une analyse de données (jointure de table, agrégation de données, etc.) et lorsque notre flux de travail implique généralement des changements importants dans la table. D'un autre côté, DuckDB n'est pas adapté aux activités de données volumineuses et à plusieurs processus simultanés dans une seule base de données.
MamanDuck est un service géré DuckDB-in-the-cloud. Son utilisation est gratuite et open source, tout en étant maintenu par la communauté DuckDB. Il s'agit d'un service construit en partenariat avec DuckDB Lab pour créer une plate-forme de services cloud que le public peut utiliser.
Avec une combinaison de DuckDB et Motherduck, nous pouvons créer un moteur d'analyse facilement utilisable dans tous les scénarios. Comment fait-on cela? Allons-y.
Nous utiliserions l'interface utilisateur native de MotherDuck pour vous donner un exemple du fonctionnement du service et pourquoi DuckDB est un outil puissant pour l'analyse de données. Veuillez vous inscrire sur le site Web et acquérir le compte MotherDuck si vous ne l'avez pas déjà fait.
Une fois que vous vous êtes inscrit avec succès au compte MotherDuck, nous serons redirigés vers l'interface utilisateur MotherDuck. Essayez de vous familiariser avec l'interface utilisateur et vous vous rendrez compte que l'interface utilisateur est similaire au Jupyter Notebook si jamais vous en utilisez un.
Nous expérimenterons la puissance de DBduck dans l'interface utilisateur de MotherDuck avec les données DS Salary de Kaggle. Téléchargez les données à l'aide du bouton Ajouter des fichiers et une nouvelle cellule s'affichera avec la requête à exécuter. La requête devrait ressembler à ceci.
CREATE OR REPLACE TABLE ds_salaries AS SELECT * FROM read_csv_auto(['ds_salaries.csv']);
Une fois la table créée, essayez d'interroger les données avec le code suivant.
select * from my_db.ds_salaries limit 10;
Comme vous pouvez le voir, MotherDuck ressemble un peu à l'analyse de données dans Notebook, mais avec des requêtes SQL. Essayons la requête pour effectuer une analyse de données dans MotherDuck.
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
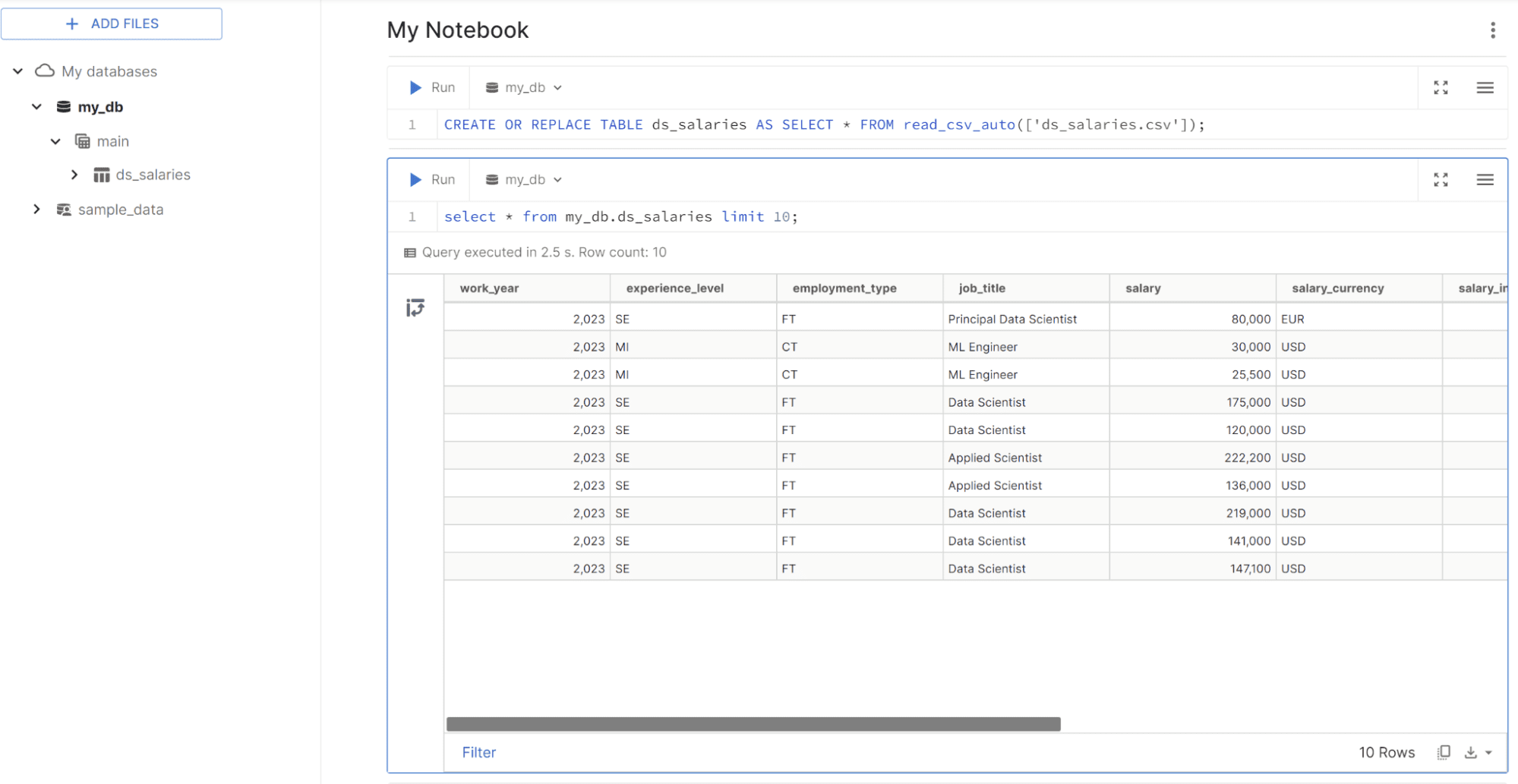
Vous pouvez exécuter la requête dans la cellule ; le résultat du tableau est affiché de la même manière que l'image ci-dessous.
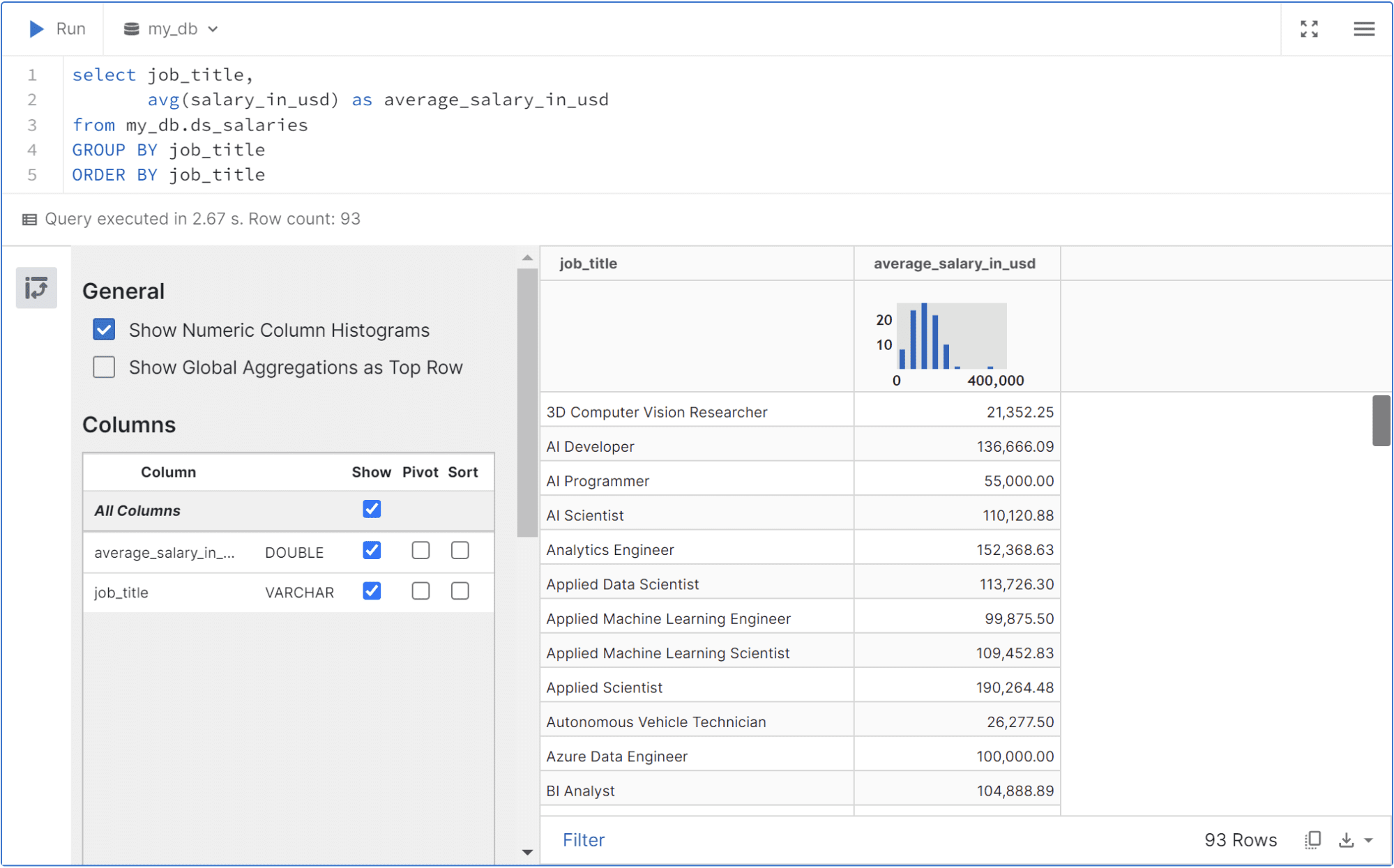
Vous pouvez filtrer les données, faire pivoter le tableau ou télécharger le résultat avec le bouton de sélection disponible dans l'interface utilisateur.
MotherDuck permet également à l'utilisateur d'accéder à la base de données via Python sur votre ordinateur portable. Nous devons installer le package DuckDB en utilisant le code suivant.
pip install duckdb==v0.9.2
La version actuelle prise en charge par MotherDuck est DuckDB 0.9.2 ; c'est pourquoi nous avons installé cette version.
Une fois l'installation réussie, nous devons connecter le DuckDB au Motherduck. Il existe plusieurs façons d'authentifier la connexion, mais nous utiliserions le jeton de service. Ce jeton est acquis dans vos paramètres MotherDuck.
import duckdb
token = "insert token here"
# initiate the MotherDuck connection
con = duckdb.connect(f'md:?motherduck_token={token}')
Si nous n'avons défini aucun nom de base de données, MotherDuck accéderait en utilisant la base de données par défaut, qui est my_db. Ensuite, utilisons la même requête que celle que nous avons effectuée précédemment dans le Notebook.
q = """
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
"""
con.sql(q).show()
Vous verrez le résultat similaire au tableau ci-dessous.
┌─────────────────────────────────────┬───────────────────────┐
│ job_title │ average_salary_in_usd │
│ varchar │ double │
├─────────────────────────────────────┼───────────────────────┤
│ 3D Computer Vision Researcher │ 21352.25 │
│ AI Developer │ 136666.0909090909 │
│ AI Programmer │ 55000.0 │
│ AI Scientist │ 110120.875 │
│ Analytics Engineer │ 152368.63106796116 │
│ Applied Data Scientist │ 113726.3 │
│ Applied Machine Learning Engineer │ 99875.5 │
│ Applied Machine Learning Scientist │ 109452.83333333333 │
│ Applied Scientist │ 190264.4827586207 │
│ Autonomous Vehicle Technician │ 26277.5 │
│ · │ · │
│ · │ · │
│ · │ · │
│ Principal Data Engineer │ 192500.0 │
│ Principal Data Scientist │ 198171.125 │
│ Principal Machine Learning Engineer │ 190000.0 │
│ Product Data Analyst │ 56497.2 │
│ Product Data Scientist │ 8000.0 │
│ Research Engineer │ 163108.37837837837 │
│ Research Scientist │ 161214.19512195123 │
│ Software Data Engineer │ 62510.0 │
│ Staff Data Analyst │ 15000.0 │
│ Staff Data Scientist │ 105000.0 │
├─────────────────────────────────────┴───────────────────────┤
│ 93 rows (20 shown) 2 columns │
└─────────────────────────────────────────────────────────────┘
Avec la requête ci-dessus, vous pouvez utiliser le code suivant pour les traiter dans le Pandas DataFrame.
import pandas as pd
df = con.sql(q).fetchdf()
Enfin, vous pouvez charger un autre ensemble de données dans la base de données à l'aide de la requête suivante.
con.sql("CREATE TABLE mytable AS SELECT * FROM '~/filepath.csv'")
La requête ci-dessus suppose que vos données sont un fichier CSV. D'autres options incluent S3 ou le DuckDB local vers la base de données MotherDuck.
DuckDB est un système de base de données open source développé spécifiquement pour l'analyse des données. Le système est conçu pour gérer le traitement des données de manière rapide et efficace. MotherDuck est un service cloud géré open source pour DuckDB.
En combinant DuckDB et MotherDuck, nous pouvons transformer nos ordinateurs portables en un moteur d'analyse personnel en plaçant nos données dans le cloud et en les traitant rapidement avec DuckDB.
Cornellius Yudha Wijaya est un gestionnaire adjoint en science des données et un rédacteur de données. Tout en travaillant à plein temps chez Allianz Indonesia, il aime partager des conseils Python et Data via les réseaux sociaux et les supports d'écriture.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/turn-your-laptop-into-a-personal-analytics-engine-with-duckdb-and-motherduck?utm_source=rss&utm_medium=rss&utm_campaign=turn-your-laptop-into-a-personal-analytics-engine-with-duckdb-and-motherduck
- :possède
- :est
- :ne pas
- :où
- 10
- 125
- 15000
- 20
- 25
- 3d
- 7
- 8
- 8000
- 9
- a
- au dessus de
- accès
- Compte
- acquérir
- a acquise
- activité
- ajouter
- avancer
- avancement
- agrégation
- AI
- Tous
- Allianz
- permet
- déjà
- aussi
- an
- selon une analyse de l’Université de Princeton
- analyste
- Analytique
- Analytique
- analytique
- et les
- Une autre
- tous
- appliqué
- SONT
- AS
- Assistante gérante
- suppose
- At
- authentifier
- autonome
- véhicule autonome
- disponibles
- BE
- ci-dessous
- jusqu'à XNUMX fois
- construit
- la performance des entreprises
- mais
- bouton (dans la fenêtre de contrôle qui apparaît maintenant)
- by
- CAN
- cellule
- Modifications
- le cloud
- code
- Colonnes
- combinaison
- combinant
- Communautés
- ordinateur
- Vision par ordinateur
- concurrent
- NOUS CONTACTER
- connexion
- pourriez
- engendrent
- critique
- Courant
- données
- l'analyse des données
- analyste de données
- Analyse de Donnée
- ingénieur de données
- informatique
- science des données
- Data Scientist
- Base de données
- Réglage par défaut
- un
- développé
- Développeur
- DID
- différence
- do
- faire
- double
- download
- de manière efficace
- efficacement
- Moteur
- ingénieur
- etc
- Ether (ETH)
- JAMAIS
- Chaque
- exemple
- exécuter
- expérience
- se familiariser
- few
- Déposez votre dernière attestation
- Fichiers
- une fonction filtre
- Abonnement
- Pour
- gratuitement ici
- De
- généré
- obtenez
- Donner
- Réservation de groupe
- main
- manipuler
- Maniabilité
- ayant
- he
- a aidé
- ici
- Comment
- HTTPS
- if
- image
- met en oeuvre
- améliorer
- in
- comprendre
- Indonésie
- initier
- installer
- installation
- développement
- implique
- impliquant
- IT
- rejoindre
- Jupyter Notebook
- KDnuggetsGenericName
- laboratoire
- portatif
- ordinateurs portables
- apprentissage
- comme
- LIMIT
- charge
- locales
- Style
- ressembler
- aime
- click
- machine learning
- gérés
- gestion
- Système de gestion
- manager
- Médias
- beaucoup
- plusieurs
- prénom
- à savoir
- indigène
- Besoin
- Besoins
- Nouveauté
- next
- cahier
- of
- on
- ONE
- en ligne
- open source
- Options
- or
- de commander
- Autre
- nos
- ande
- sortie
- paquet
- pandas
- Partenariat
- parfaite
- personnel
- Pivoter
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- veuillez cliquer
- power
- solide
- assez
- précédemment
- Directeur
- processus
- les process
- traitement
- Produit
- Programmeur
- public
- Python
- requêtes
- vite.
- facilement
- réaliser
- Indépendamment
- vous inscrire
- remplacer
- un article
- chercheur
- résultat
- salaire
- même
- scénario
- Sciences
- Scientifique
- sur le lien
- Sélectionner
- sélection
- service
- set
- Paramétres
- Partager
- devrait
- montré
- significative
- similaires
- De même
- Taille
- Réseaux sociaux
- réseaux sociaux
- Logiciels
- spécifiquement
- SQL
- empiler
- L'équipe
- réussi
- Avec succès
- convient
- Support
- Les soutiens
- rapidement
- combustion propre
- Système
- table
- tâches
- Technologie
- qui
- Le
- Les
- Là.
- Ces
- this
- fiable
- conseils
- à
- jeton
- outil
- les outils
- Essai
- TOUR
- ui
- utilisé
- Utilisateur
- en utilisant
- d'habitude
- véhicule
- version
- via
- vision
- était
- façons
- we
- Site Web
- quand
- qui
- tout en
- why
- sera
- comprenant
- workflow
- de travail
- vos contrats
- pourra
- écrivain
- écriture
- you
- Votre
- vous-même
- zéphyrnet