Dans le monde d'aujourd'hui axé sur les données, la capacité de déplacer et d'analyser sans effort des données sur diverses plates-formes est essentielle. Flux d'application Amazon, un service d'intégration de données entièrement géré, a été à l'avant-garde de la rationalisation du transfert de données entre les services AWS, les applications Software as a Service (SaaS) et désormais Google BigQuery. Dans cet article de blog, vous explorez le nouveau Connecteur Google BigQuery dans Amazon AppFlow et découvrez comment il simplifie le processus de transfert de données de l'entrepôt de données de Google vers Service de stockage simple Amazon (Amazon S3), offrant des avantages significatifs aux professionnels des données et aux organisations, notamment la démocratisation de l'accès aux données multi-cloud.
Présentation d'Amazon AppFlow
Flux d'application Amazon est un service d'intégration entièrement géré que vous pouvez utiliser pour transférer en toute sécurité des données entre des applications SaaS telles que Google BigQuery, Salesforce, SAP, Hubspot et ServiceNow, et des services AWS tels qu'Amazon S3 et Redshift d'Amazon, en quelques clics. Avec Amazon AppFlow, vous pouvez exécuter des flux de données à presque n'importe quelle échelle et à la fréquence que vous choisissez : selon un planning, en réponse à un événement commercial ou à la demande. Vous pouvez configurer des fonctionnalités de transformation de données telles que le filtrage et la validation pour générer des données riches et prêtes à l'emploi dans le cadre du flux lui-même, sans étapes supplémentaires. Amazon AppFlow chiffre automatiquement les données en mouvement et vous permet d'empêcher la circulation des données sur l'Internet public pour les applications SaaS intégrées à Lien privé AWS, réduisant ainsi l'exposition aux menaces de sécurité.
Présentation du connecteur Google BigQuery
Le nouveau système d’ Connecteur Google BigQuery dans Amazon AppFlow dévoile des possibilités pour les organisations cherchant à utiliser la capacité analytique de l'entrepôt de données de Google et à intégrer, analyser, stocker ou traiter sans effort les données de BigQuery, les transformant en informations exploitables.
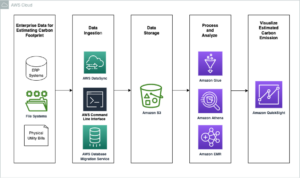
Architecture
Passons en revue l'architecture permettant de transférer des données de Google BigQuery vers Amazon S3 à l'aide d'Amazon AppFlow.

- Sélectionnez une source de données : Dans Flux d'application Amazon, sélectionnez Google BigQuery comme source de données. Spécifiez les tables ou les ensembles de données dont vous souhaitez extraire les données.
- Cartographie et transformation des champs : configurez le transfert de données à l'aide de l'interface visuelle intuitive d'Amazon AppFlow. Vous pouvez mapper les champs de données et appliquer les transformations nécessaires pour aligner les données sur vos besoins.
- Fréquence de transfert : décidez de la fréquence à laquelle vous souhaitez transférer les données (par exemple quotidiennement, hebdomadairement ou mensuellement), en favorisant la flexibilité et l'automatisation.
- Destination : spécifiez un compartiment S3 comme destination de vos données. Amazon AppFlow déplacera efficacement les données, les rendant accessibles dans votre stockage Amazon S3.
- Consommation : Utilisation Amazone Athéna pour analyser les données dans Amazon S3.
Pré-requis
Le jeu de données utilisé dans cette solution est généré par Synthéa, un simulateur synthétique de population de patients et un projet open source sous le Licence Apache 2.0. Chargez ces données dans Google BigQuery ou utilisez votre ensemble de données existant.
Connectez Amazon AppFlow à votre compte Google BigQuery
Pour cet article, vous utilisez un compte Google, un client OAuth avec les autorisations appropriées et des données Google BigQuery. Pour activer l'accès à Google BigQuery depuis Amazon AppFlow, vous devez configurer un nouveau client OAuth au préalable. Pour les instructions, voir Connecteur Google BigQuery pour Amazon AppFlow.
Configurer Amazon S3
Chaque objet dans Amazon S3 est stocké dans un compartiment. Avant de pouvoir stocker des données dans Amazon S3, vous devez créer un compartiment S3 pour stocker les résultats.
Créer un nouveau compartiment S3 pour les résultats Amazon AppFlow
Pour créer un compartiment S3, procédez comme suit :
- Sur la console de gestion AWS pour Amazon S3, choisissez Créer un seau.
- Entrez un nom unique au monde nom de votre seau; par exemple,
appflow-bq-sample. - Selectionnez Créez un seau.
Créer un nouveau compartiment S3 pour les résultats Amazon Athena
Pour créer un compartiment S3, procédez comme suit :
- Sur la console de gestion AWS pour Amazon S3, choisissez Créer un seau.
- Entrez un nom unique au monde nom de votre seau; par exemple,
athena-results. - Selectionnez Créez un seau.
Rôle d'utilisateur (rôle IAM) pour AWS Glue Data Catalog
Pour cataloguer les données que vous transférez avec votre flux, vous devez disposer du rôle d'utilisateur approprié dans Gestion des identités et des accès AWS (IAM). Vous fournissez ce rôle à Amazon AppFlow pour accorder les autorisations dont il a besoin pour créer un Catalogue de données AWS Glue, tables, bases de données et partitions.
Pour obtenir un exemple de stratégie IAM disposant des autorisations requises, consultez Exemples de politiques basées sur l'identité pour Amazon AppFlow.
Présentation pas à pas de la conception
Passons maintenant à un cas d'utilisation pratique pour voir comment fonctionne le connecteur Amazon AppFlow Google BigQuery vers Amazon S3. Pour le cas d'utilisation, vous utiliserez Amazon AppFlow pour archiver les données historiques de Google BigQuery vers Amazon S3 pour un stockage à long terme et une analyse.
Configurer Amazon AppFlow
Créez un nouveau flux Amazon AppFlow pour transférer des données de Google Analytics vers Amazon S3.
- Sur le Console Amazon AppFlow, choisissez Créer un flux.
- Saisissez un nom pour votre flux ; Par exemple,
my-bq-flow. - Ajouter nécessaire Tags; par exemple, pour ACTIVITES entrer
envet pour Valeur entrerdev.

- Selectionnez Suivant.
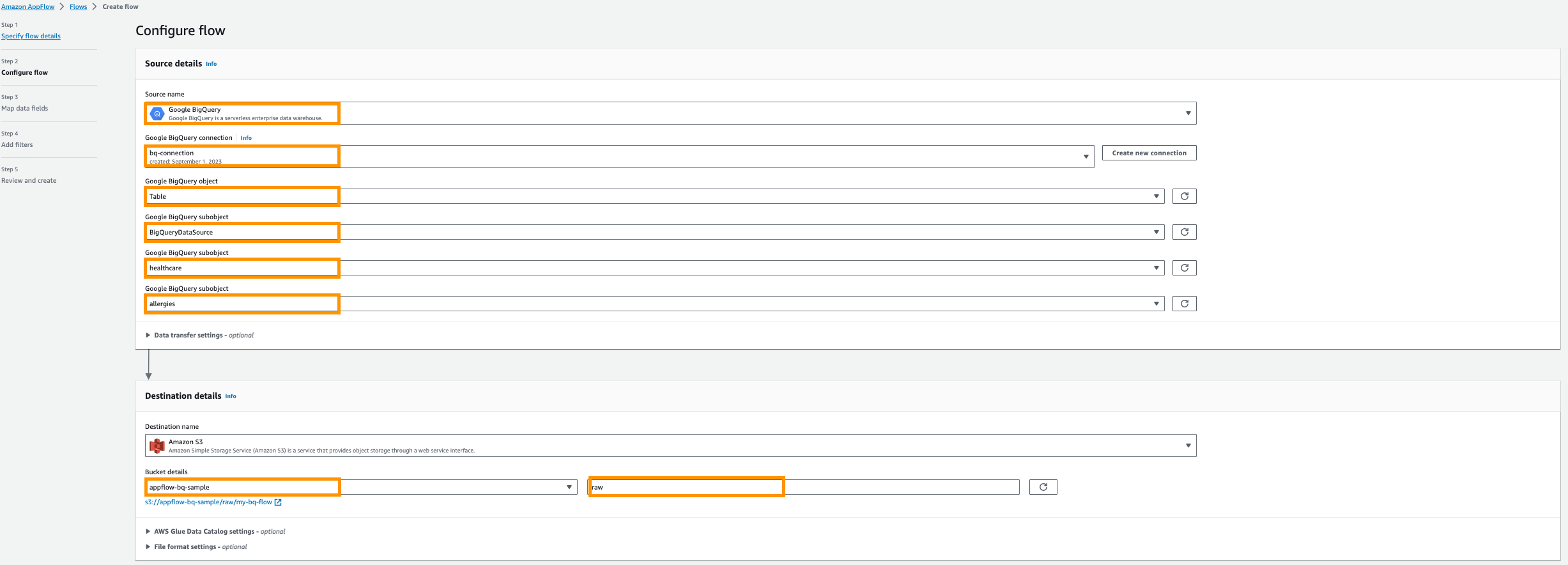
- Pour Nom de la source, choisissez Google BigQuery.
- Selectionnez Créer une nouvelle connexion.
- Entrez votre OAuth identité du client ainsi que Secret client, puis nommez votre connexion ; Par exemple,
bq-connection.

- Dans la fenêtre contextuelle, choisissez d'autoriser amazon.com à accéder à l'API Google BigQuery.

- Pour Choisissez l'objet Google BigQuery, choisissez lampe de table.
- Pour Choisissez le sous-objet Google BigQuery, choisissez Nom du projet BigQuery.
- Pour Choisissez le sous-objet Google BigQuery, choisissez Nom de la base de données.
- Pour Choisissez le sous-objet Google BigQuery, choisissez Nom de la table.
- Pour Nom de la destination, choisissez Amazon S3.
- Pour Détails du seau, choisissez le compartiment Amazon S3 que vous avez créé pour stocker les résultats Amazon AppFlow dans les conditions préalables.
- Entrer
rawen tant que préfixe.
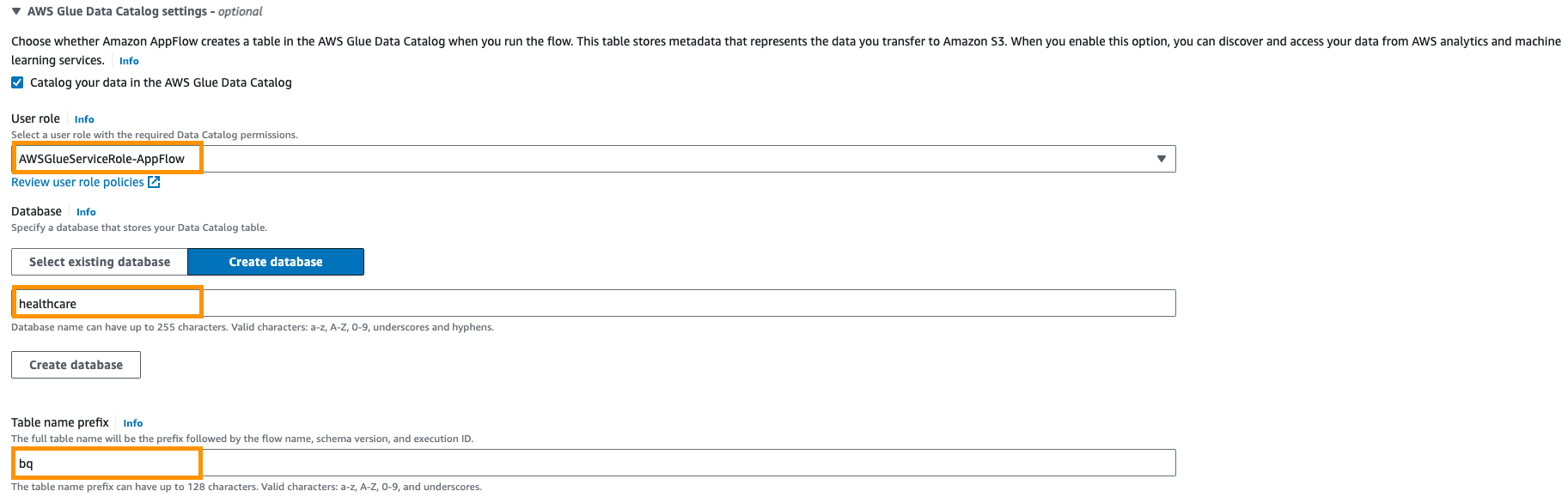
- Ensuite, fournissez Catalogue de données AWS Glue paramètres pour créer un tableau pour une analyse plus approfondie.
- Sélectionnez le Rôle d'utilisateur (rôle IAM) créé dans les prérequis.
- Créer un nouveau base de données par exemple,
healthcare. - Fournir un préfixe de table réglage par exemple,
bq.
- Sélectionnez Fonctionne à la demande.
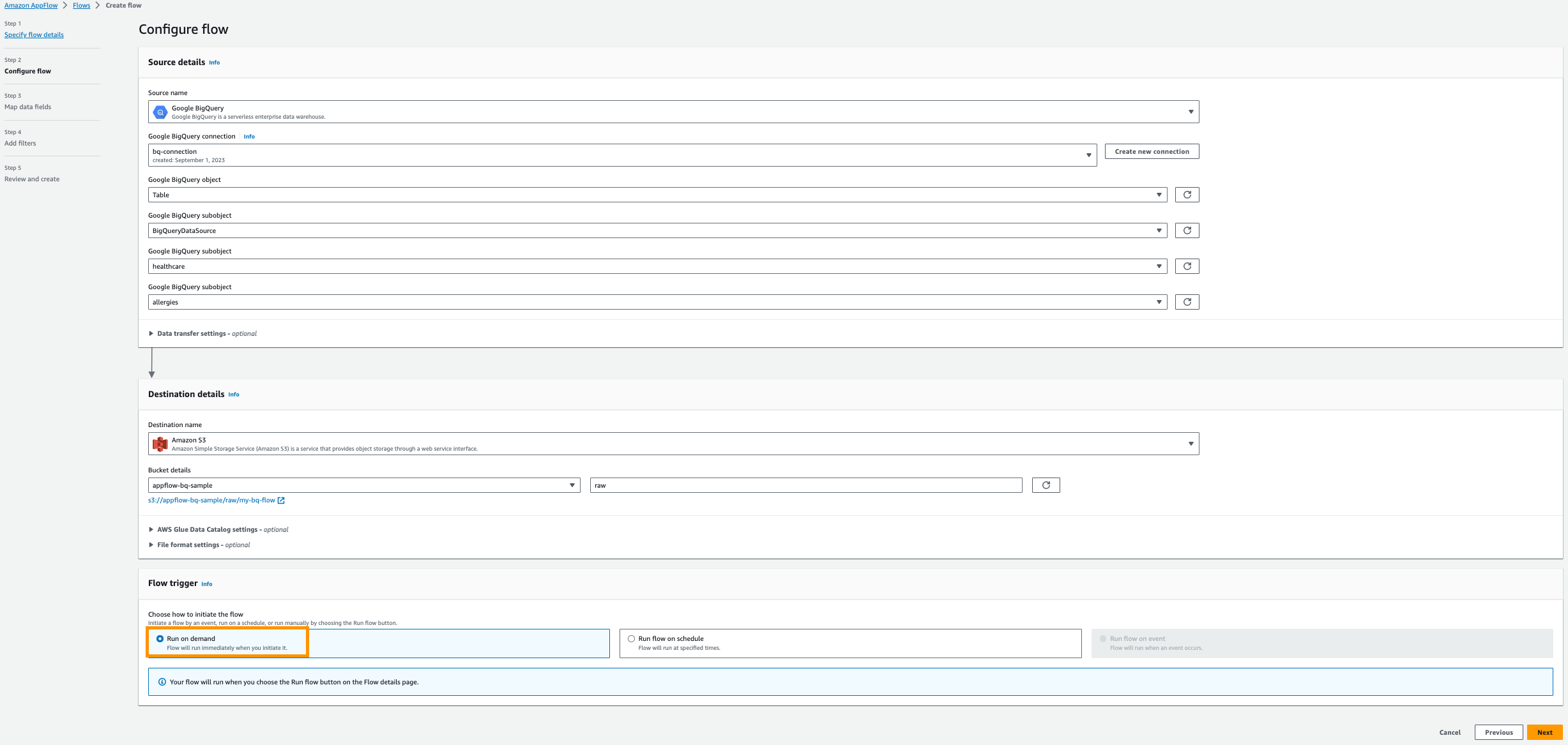
- Selectionnez Suivant.
- Sélectionnez Mapper manuellement les champs.
- Sélectionnez les six champs suivants pour Nom du champ source de la table Allergies:
- Accueil
- Table de traitement
- Code
- Description
- Type
- Catégories
- Selectionnez Mapper les champs directement.

- Selectionnez Suivant.
- In l'Ajouter des filtres section, choisissez Suivant.
- Selectionnez Créer un flux.
Exécuter le flux
Après avoir créé votre nouveau flux, vous pouvez l'exécuter à la demande.
- Sur le Console Amazon AppFlow, choisissez
my-bq-flow. - Selectionnez Flux d'exécution.

Pour cette procédure pas à pas, choisissez exécuter la tâche à la demande pour faciliter la compréhension. En pratique, vous pouvez choisir une tâche planifiée et extraire périodiquement uniquement les données nouvellement ajoutées.
Requête via Amazon Athena
Lorsque vous sélectionnez les paramètres facultatifs d'AWS Glue Data Catalog, Data Catalog crée le catalogue pour les données, permettant à Amazon Athena d'effectuer des requêtes.
Si vous êtes invité à configurer un emplacement de résultats de requête, accédez au Paramètres onglet et choisissez Gérer. En dessous de Gérer les paramètres, choisissez le bucket de résultats Athena créé dans les prérequis et choisissez Épargnez.
- Sur le Console Amazon Athéna, sélectionnez la source de données comme
AWSDataCatalog. - Ensuite, sélectionnez Base de données as
healthcare. - Vous pouvez maintenant sélectionner la table créée par le robot d'exploration AWS Glue et la prévisualiser.

- Vous pouvez également exécuter une requête personnalisée pour rechercher les 10 principales allergies, comme indiqué dans la requête suivante.
Notes: Dans la requête ci-dessous, remplacez le nom de la table, dans ce cas bq_appflow_mybqflow_1693588670_latest, avec le nom de la table générée dans votre compte AWS.
- Selectionnez Exécuter une requête.

Ce résultat montre les 10 principales allergies par nombre de cas.
Nettoyer
Pour éviter d'encourir des frais, nettoyez les ressources de votre compte AWS en procédant comme suit :
- Sur la console Amazon AppFlow, choisissez Flux dans le volet de navigation.
- Dans la liste des flux, sélectionnez le flux
my-bq-flow, et supprimez-le. - Entrez delete pour supprimer le flux.
- Selectionnez Connexions dans le volet de navigation.
- Selectionnez Google BigQuery dans la liste des connecteurs, sélectionnez
bq-connector, et supprimez-le. - Entrez delete pour supprimer le connecteur.
- Sur la console IAM, choisissez Rôles dans la page de navigation, puis sélectionnez le rôle que vous avez créé pour le robot d'exploration AWS Glue et supprimez-le.
- Sur la console Amazon Athena :
- Supprimer les tables créées sous la base de données
healthcareà l'aide du robot d'exploration AWS Glue. - Supprimer la base de données
healthcare
- Supprimer les tables créées sous la base de données
- Sur la console Amazon S3, recherchez le compartiment de résultats Amazon AppFlow que vous avez créé, choisissez Vide pour supprimer les objets, puis supprimez le bucket.
- Sur la console Amazon S3, recherchez le compartiment de résultats Amazon Athena que vous avez créé, choisissez Vide pour supprimer les objets, puis supprimez le bucket.
- Nettoyez les ressources de votre compte Google en supprimant le projet contenant les ressources Google BigQuery. Suivez la documentation pour nettoyer les ressources Google.
Conclusion
Le connecteur Google BigQuery dans Amazon AppFlow rationalise le processus de transfert de données de l'entrepôt de données de Google vers Amazon S3. Cette intégration simplifie l'analyse et l'apprentissage automatique, l'archivage et le stockage à long terme, offrant des avantages significatifs aux professionnels des données et aux organisations cherchant à exploiter les capacités analytiques des deux plateformes.
Avec Amazon AppFlow, les complexités de l'intégration des données sont éliminées, vous permettant de vous concentrer sur l'obtention d'informations exploitables à partir de vos données. Que vous archiviez des données historiques, effectuiez des analyses complexes ou prépariez des données pour l'apprentissage automatique, ce connecteur simplifie le processus, le rendant accessible à un plus large éventail de professionnels des données.
Si vous souhaitez voir comment le transfert de données de Google BigQuery vers Amazon S3 à l'aide d'Amazon AppFlow, consultez étape par étape tutoriel vidéo. Dans ce didacticiel, nous parcourons l'ensemble du processus, de la configuration de la connexion à l'exécution du flux de transfert de données. Pour plus d'informations sur Amazon AppFlow, visitez Flux d'application Amazon.
À propos des auteurs
![]() Kartikaï Khator est architecte de solutions pour les sciences de la vie mondiales chez Amazon Web Services. Il se passionne pour aider les clients dans leur parcours cloud en mettant l'accent sur les services d'analyse AWS. C'est un coureur passionné et aime la randonnée.
Kartikaï Khator est architecte de solutions pour les sciences de la vie mondiales chez Amazon Web Services. Il se passionne pour aider les clients dans leur parcours cloud en mettant l'accent sur les services d'analyse AWS. C'est un coureur passionné et aime la randonnée.
 Kamen Sharlandjiev est un architecte principal de solutions Big Data et ETL et un expert Amazon AppFlow. Il a pour mission de faciliter la vie des clients confrontés à des défis complexes d'intégration de données. Son arme secrète ? Services AWS entièrement gérés et low-code qui peuvent effectuer le travail avec un minimum d'effort et sans codage.
Kamen Sharlandjiev est un architecte principal de solutions Big Data et ETL et un expert Amazon AppFlow. Il a pour mission de faciliter la vie des clients confrontés à des défis complexes d'intégration de données. Son arme secrète ? Services AWS entièrement gérés et low-code qui peuvent effectuer le travail avec un minimum d'effort et sans codage.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/simplify-data-transfer-google-bigquery-to-amazon-s3-using-amazon-appflow/
- :possède
- :est
- $UP
- 10
- 100
- 14
- 16
- 17
- 22
- 321
- 8
- 9
- a
- capacité
- A Propos
- accès
- Gestion des accès
- accessible
- Compte
- à travers
- ajouter
- ajoutée
- Supplémentaire
- avancer
- aligner
- Allergies
- permettre
- Permettre
- permet
- aussi
- Amazon
- Amazone Athéna
- Amazon Web Services
- -
- an
- selon une analyse de l’Université de Princeton
- Analytique
- analytique
- il analyse
- ainsi que
- tous
- api
- applications
- Appliquer
- approprié
- architecture
- Archive
- SONT
- AS
- At
- automatiquement
- Automation
- éviter
- AWS
- Colle AWS
- Console de gestion AWS
- était
- before
- ci-dessous
- avantages.
- jusqu'à XNUMX fois
- Big
- Big Data
- bigquery
- Blog
- tous les deux
- plus large
- la performance des entreprises
- by
- CAN
- Peut obtenir
- capacités
- aptitude
- maisons
- cas
- catalogue
- Catégories
- globaux
- des charges
- Selectionnez
- client
- le cloud
- Codage
- COM
- complet
- compléter
- complexe
- complexités
- connexion
- Console
- contient
- chenilles
- engendrent
- créée
- crée des
- La création
- Customiser
- Clients
- Tous les jours
- données
- accès aux données
- intégration de données
- entrepôt de données
- data-driven
- Base de données
- bases de données
- ensembles de données
- décider
- Demande
- démocratisation
- la description
- destination
- découvrez
- plusieurs
- Documentation
- fait
- facilité
- plus facilement
- efficacement
- effort
- d'effort
- éliminée
- permettre
- permettant
- Tout
- essential
- Ether (ETH)
- événement
- exemple
- exemples
- existant
- expert
- explorez
- Exposition
- extrait
- few
- champ
- Des champs
- filtration
- Trouvez
- Flexibilité
- flux
- Écoulement
- Flux
- Focus
- suivre
- Abonnement
- Pour
- Premier plan
- La fréquence
- fréquemment
- De
- d’étiquettes électroniques entièrement
- plus
- générer
- généré
- obtenez
- Global
- À l'échelle mondiale
- Google Analytics
- subvention
- Réservation de groupe
- harnais
- Vous avez
- he
- la médecine
- aider
- randonnée
- sa
- historique
- Comment
- HTML
- http
- HTTPS
- HubSpot
- IAM
- Identite
- gestion des identités et des accès
- in
- Y compris
- d'information
- idées.
- Des instructions
- intégrer
- des services
- l'intégration
- intéressé
- Interfaces
- Internet
- développement
- intuitif
- IT
- lui-même
- Emploi
- chemin
- juste
- apprentissage
- Licence
- VIE
- Sciences de la vie
- LIMIT
- Liste
- charge
- emplacement
- long-term
- Style
- click
- machine learning
- a prendre une
- Fabrication
- gérés
- gestion
- Localisation
- cartographie
- minimal
- Mission
- PLUS
- mouvement
- Bougez
- must
- prénom
- NAVIGUER
- Navigation
- presque
- nécessaire
- nécessaire
- Besoins
- Nouveauté
- nouvellement
- aucune
- maintenant
- nombre
- oauth
- objet
- objets
- of
- on
- À la demande
- uniquement
- opensource
- or
- de commander
- organisations
- plus de
- page
- pain
- partie
- passionné
- patientforward
- effectuer
- effectuer
- autorisations
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- politique
- pop-up
- population
- possibilités
- Post
- Méthode
- pratique
- en train de préparer
- conditions préalables
- Aperçu
- processus
- ,une équipe de professionnels qualifiés
- Projet
- fournir
- aportando
- public
- requêtes
- gamme
- réduire
- remplacer
- conditions
- Exigences
- Resources
- réponse
- restreindre
- résultat
- Résultats
- Avis
- Rich
- Rôle
- Courir
- coureur
- pour le running
- SaaS.
- force de vente
- sève
- Escaliers intérieurs
- calendrier
- prévu
- Sciences
- Rechercher
- secret
- Section
- en toute sécurité
- sécurité
- Les menaces de sécurité
- sur le lien
- recherche
- service
- ServiceNow
- Services
- set
- mise
- Paramétres
- montré
- Spectacles
- significative
- étapes
- simplifier
- simulateur
- SIX
- Logiciels
- logiciel en tant que service
- sur mesure
- Solutions
- Identifier
- Étapes
- storage
- Boutique
- stockée
- la rationalisation
- tel
- haute
- table
- Prenez
- qui
- La
- leur
- puis
- this
- des menaces
- Avec
- à
- aujourd'hui
- top
- Top 10
- transférer
- Transfert
- De La Carrosserie
- transformations
- transformer
- tutoriel
- type
- sous
- compréhension
- expérience unique et authentique
- Dévoile
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- en utilisant
- validation
- Plus-value
- Visiter
- marcher
- walkthrough
- souhaitez
- Entrepots
- we
- web
- services Web
- hebdomadaire
- que
- WHO
- sera
- fenêtre
- comprenant
- sans
- vos contrats
- world
- you
- Votre
- Youtube
- zéphyrnet