Introduction
Imaginez-vous debout dans une bibliothèque faiblement éclairée, luttant pour déchiffrer un document complexe tout en jonglant avec des dizaines d'autres textes. C'était le monde de Transformers avant que le journal « L'attention est tout ce dont vous avez besoin » ne dévoile son projecteur révolutionnaire : le mécanisme d'attention.
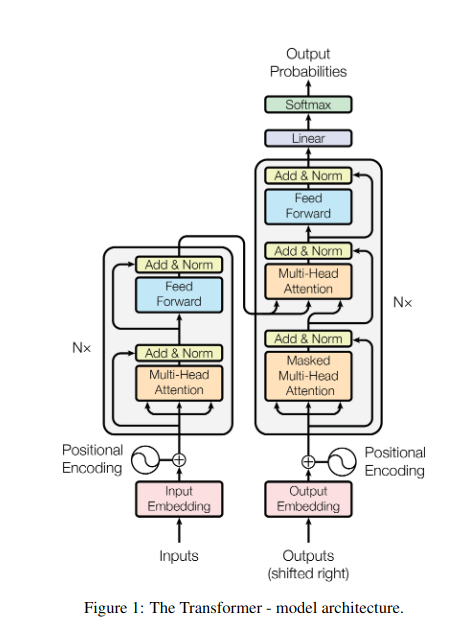
Table des matières
Limites des RNN
Modèles séquentiels traditionnels, comme Réseaux de neurones récurrents (RNN), langage traité mot par mot, entraînant plusieurs limitations :
- Dépendance à courte portée : Les RNN ont eu du mal à saisir les liens entre des mots éloignés, interprétant souvent mal le sens de phrases comme « l’homme qui a visité le zoo hier », où le sujet et le verbe sont très éloignés.
- Parallélisme limité : Le traitement séquentiel des informations est intrinsèquement lent, ce qui empêche une formation et une utilisation efficaces des ressources informatiques, en particulier pour les longues séquences.
- Focus sur le contexte local : Les RNN prennent principalement en compte les voisins immédiats, manquant potentiellement d'informations cruciales dans d'autres parties de la phrase.
Ces limitations ont entravé la capacité des Transformers à effectuer des tâches complexes telles que la traduction automatique et la compréhension du langage naturel. Puis vint le mécanisme d'attention, un projecteur révolutionnaire qui met en lumière les liens cachés entre les mots, transformant ainsi notre compréhension du traitement du langage. Mais qu’est-ce que l’attention a résolu exactement et comment a-t-elle changé le jeu pour Transformers ?
Concentrons-nous sur trois domaines clés :
Dépendance à long terme
- Problème: Les modèles traditionnels butaient souvent sur des phrases telles que « la femme qui vivait sur la colline a vu une étoile filante la nuit dernière ». Ils ont eu du mal à relier « femme » et « étoile filante » en raison de leur distance, ce qui a conduit à des interprétations erronées.
- Mécanisme d'attention : Imaginez le modèle projetant un faisceau lumineux sur la phrase, reliant « femme » directement à « étoile filante » et comprenant la phrase dans son ensemble. Cette capacité à capturer les relations quelle que soit la distance est cruciale pour des tâches telles que la traduction automatique et la synthèse.
Lisez aussi: Un aperçu de la mémoire à long court terme (LSTM)
Puissance de traitement parallèle
- Problème: Les modèles traditionnels traitaient les informations de manière séquentielle, comme la lecture d’un livre page par page. C'était lent et inefficace, surtout pour les textes longs.
- Mécanisme d'attention : Imaginez plusieurs projecteurs balayant simultanément la bibliothèque, analysant différentes parties du texte en parallèle. Cela accélère considérablement le travail du modèle, lui permettant de gérer efficacement de grandes quantités de données. Cette puissance de traitement parallèle est essentielle pour entraîner des modèles complexes et réaliser des prédictions en temps réel.
Conscience du contexte mondial
- Problème: Les modèles traditionnels se concentraient souvent sur des mots individuels, ignorant le contexte plus large de la phrase. Cela a conduit à des malentendus dans des cas comme le sarcasme ou le double sens.
- Mécanisme d'attention : Imaginez que les projecteurs balayent toute la bibliothèque, examinant chaque livre et comprenant leurs relations les uns avec les autres. Cette connaissance du contexte global permet au modèle de prendre en compte l'intégralité du texte lors de l'interprétation de chaque mot, conduisant à une compréhension plus riche et plus nuancée.
Lever l’ambiguïté des mots polysémiques
- Problème: Des mots comme « banque » ou « pomme » peuvent être des noms, des verbes ou même des entreprises, créant une ambiguïté que les modèles traditionnels avaient du mal à résoudre.
- Mécanisme d'attention : Imaginez que le modèle met en lumière toutes les occurrences du mot « banque » dans une phrase, puis analyse le contexte environnant et les relations avec d'autres mots. En considérant la structure grammaticale, les noms proches et même les phrases passées, le mécanisme d’attention peut déduire le sens voulu. Cette capacité à lever l’ambiguïté des mots polysémiques est cruciale pour des tâches telles que la traduction automatique, le résumé de texte et les systèmes de dialogue.
Ces quatre aspects – dépendance à longue portée, puissance de traitement parallèle, conscience du contexte global et homonymie – mettent en valeur le pouvoir transformateur des mécanismes d’attention. Ils ont propulsé Transformers à l’avant-garde du traitement du langage naturel, leur permettant d’aborder des tâches complexes avec une précision et une efficacité remarquables.
À mesure que la PNL et plus particulièrement les LLM continuent d’évoluer, les mécanismes d’attention joueront sans aucun doute un rôle encore plus critique. Ils constituent le pont entre la séquence linéaire des mots et la riche tapisserie du langage humain et, en fin de compte, la clé pour libérer le véritable potentiel de ces merveilles linguistiques. Cet article approfondit les différents types de mécanismes d’attention et leurs fonctionnalités.
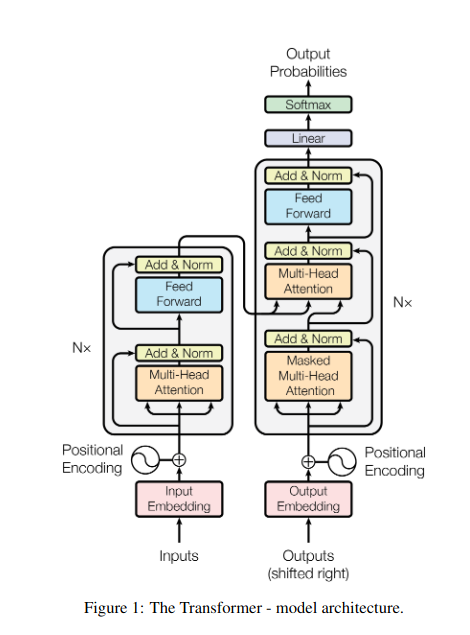
1. Attention personnelle : l'étoile directrice du transformateur
Imaginez jongler avec plusieurs livres et devoir référencer des passages spécifiques dans chacun tout en rédigeant un résumé. L'auto-attention ou l'attention Scaled Dot-Product agit comme un assistant intelligent, aidant les modèles à faire de même avec des données séquentielles telles que des phrases ou des séries chronologiques. Il permet à chaque élément de la séquence de s'occuper de tous les autres éléments, capturant ainsi efficacement les dépendances à long terme et les relations complexes.
Voici un aperçu plus approfondi de ses principaux aspects techniques :
Représentation vectorielle
Chaque élément (mot, point de données) est transformé en un vecteur de grande dimension, codant son contenu informationnel. Cet espace vectoriel sert de fondement à l’interaction entre les éléments.
Transformation QKV
Trois matrices clés sont définies :
- Requête (Q) : Représente la « question » que chaque élément pose aux autres. Q capture les besoins d'information de l'élément actuel et guide sa recherche d'informations pertinentes dans la séquence.
- Clé (K) : Contient la « clé » des informations de chaque élément. K code l'essence du contenu de chaque élément, permettant aux autres éléments d'identifier la pertinence potentielle en fonction de leurs propres besoins.
- Valeur (V): Stocke le contenu réel que chaque élément souhaite partager. V contient les informations détaillées auxquelles d'autres éléments peuvent accéder et exploiter en fonction de leurs scores d'attention.
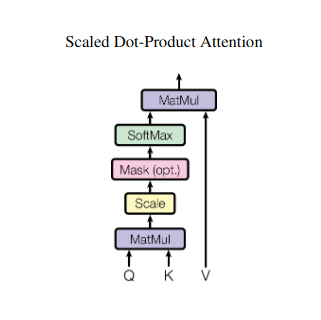
Calcul du score d'attention
La compatibilité entre chaque paire d'éléments est mesurée via un produit scalaire entre leurs vecteurs Q et K respectifs. Des scores plus élevés indiquent une pertinence potentielle plus forte entre les éléments.
Poids d'attention mis à l'échelle
Pour garantir une importance relative, ces scores de compatibilité sont normalisés à l'aide d'une fonction softmax. Il en résulte des pondérations d'attention, allant de 0 à 1, représentant l'importance pondérée de chaque élément pour le contexte de l'élément actuel.
Agrégation de contexte pondérée
Des pondérations d'attention sont appliquées à la matrice V, mettant essentiellement en évidence les informations importantes de chaque élément en fonction de leur pertinence par rapport à l'élément actuel. Cette somme pondérée crée une représentation contextualisée de l'élément actuel, intégrant les informations glanées à partir de tous les autres éléments de la séquence.
Représentation améliorée des éléments
Grâce à sa représentation enrichie, l'élément possède désormais une compréhension plus profonde de son propre contenu ainsi que de ses relations avec les autres éléments de la séquence. Cette représentation transformée constitue la base du traitement ultérieur au sein du modèle.
Ce processus en plusieurs étapes permet de s'intéresser à :
- Capturez les dépendances à long terme : Les relations entre éléments distants deviennent facilement apparentes, même si elles sont séparées par plusieurs éléments intermédiaires.
- Modélisez des interactions complexes : Des dépendances et corrélations subtiles au sein de la séquence sont mises en lumière, conduisant à une compréhension plus riche de la structure et de la dynamique des données.
- Contextualisez chaque élément : Le modèle analyse chaque élément non pas isolément mais dans le cadre plus large de la séquence, conduisant à des prédictions ou des représentations plus précises et nuancées.
L'attention personnelle a révolutionné la façon dont les modèles traitent les données séquentielles, ouvrant de nouvelles possibilités dans divers domaines tels que la traduction automatique, la génération de langage naturel, la prévision de séries chronologiques et au-delà. Sa capacité à dévoiler les relations cachées au sein des séquences constitue un outil puissant pour découvrir des informations et atteindre des performances supérieures dans un large éventail de tâches.
2. Attention multi-têtes : voir à travers différentes lentilles
L’attention personnelle offre une vision globale, mais il est parfois crucial de se concentrer sur des aspects spécifiques des données. C'est là qu'intervient l'attention multi-têtes. Imaginez avoir plusieurs assistants, chacun équipé d'un objectif différent :
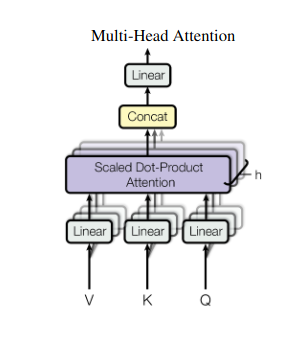
- Plusieurs « têtes » sont créés, chacun s'occupant de la séquence d'entrée à travers ses propres matrices Q, K et V.
- Chaque responsable apprend à se concentrer sur différents aspects des données, comme les dépendances à longue portée, les relations syntaxiques ou les interactions de mots locaux.
- Les sorties de chaque tête sont ensuite concaténées et projetées vers une représentation finale, capturant la nature multiforme de l'entrée.
Cela permet au modèle de considérer simultanément diverses perspectives, conduisant à une compréhension plus riche et plus nuancée des données.
3. Attention croisée : construire des ponts entre les séquences
La capacité à comprendre les liens entre différentes informations est cruciale pour de nombreuses tâches de PNL. Imaginez que vous rédigiez une critique de livre : vous ne résumeriez pas simplement le texte mot pour mot, mais vous dessineriez plutôt des idées et des liens entre les chapitres. Entrer attention croisée, un mécanisme puissant qui établit des ponts entre les séquences, permettant aux modèles d'exploiter les informations provenant de deux sources distinctes.
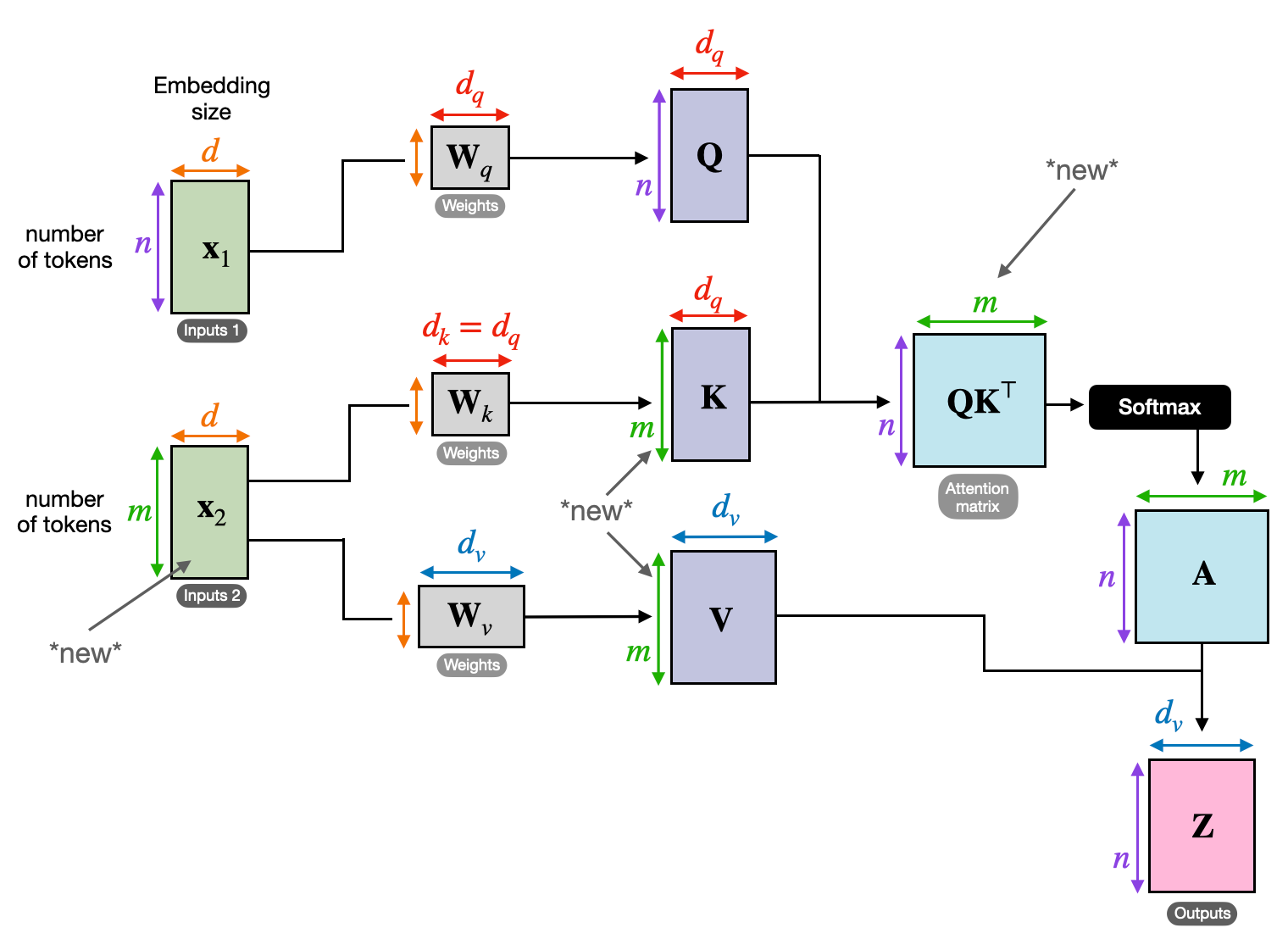
- Dans les architectures codeur-décodeur comme les Transformers, le codeur traite la séquence d'entrée (le livre) et génère une représentation cachée.
- Les décodeur utilise une attention croisée pour s'occuper de la représentation cachée de l'encodeur à chaque étape tout en générant la séquence de sortie (la révision).
- La matrice Q du décodeur interagit avec les matrices K et V de l'encodeur, lui permettant de se concentrer sur les parties pertinentes du livre lors de la rédaction de chaque phrase de la critique.
Ce mécanisme est inestimable pour des tâches telles que la traduction automatique, le résumé et la réponse aux questions, où la compréhension des relations entre les séquences d'entrée et de sortie est essentielle.
4. Attention causale : préserver l’écoulement du temps
Imaginez prédire le mot suivant dans une phrase sans regarder devant vous. Les mécanismes d'attention traditionnels ont du mal à gérer les tâches qui nécessitent de préserver l'ordre temporel des informations, telles que la génération de texte et la prévision de séries chronologiques. Ils « jettent un coup d’œil en avant » dans la séquence, ce qui conduit à des prédictions inexactes. L'attention causale résout cette limitation en garantissant que les prédictions dépendent uniquement d'informations préalablement traitées.
Voilà comment cela fonctionne
- Mécanisme de masquage : Un masque spécifique est appliqué aux poids d'attention, bloquant efficacement l'accès du modèle aux futurs éléments de la séquence. Par exemple, lors de la prédiction du deuxième mot de « la femme qui… », le modèle ne peut considérer que « la » et non « qui » ou les mots suivants.
- Traitement autorégressif : L'information circule de manière linéaire, la représentation de chaque élément étant construite uniquement à partir des éléments apparaissant devant lui. Le modèle traite la séquence mot par mot, générant des prédictions basées sur le contexte établi jusque-là.
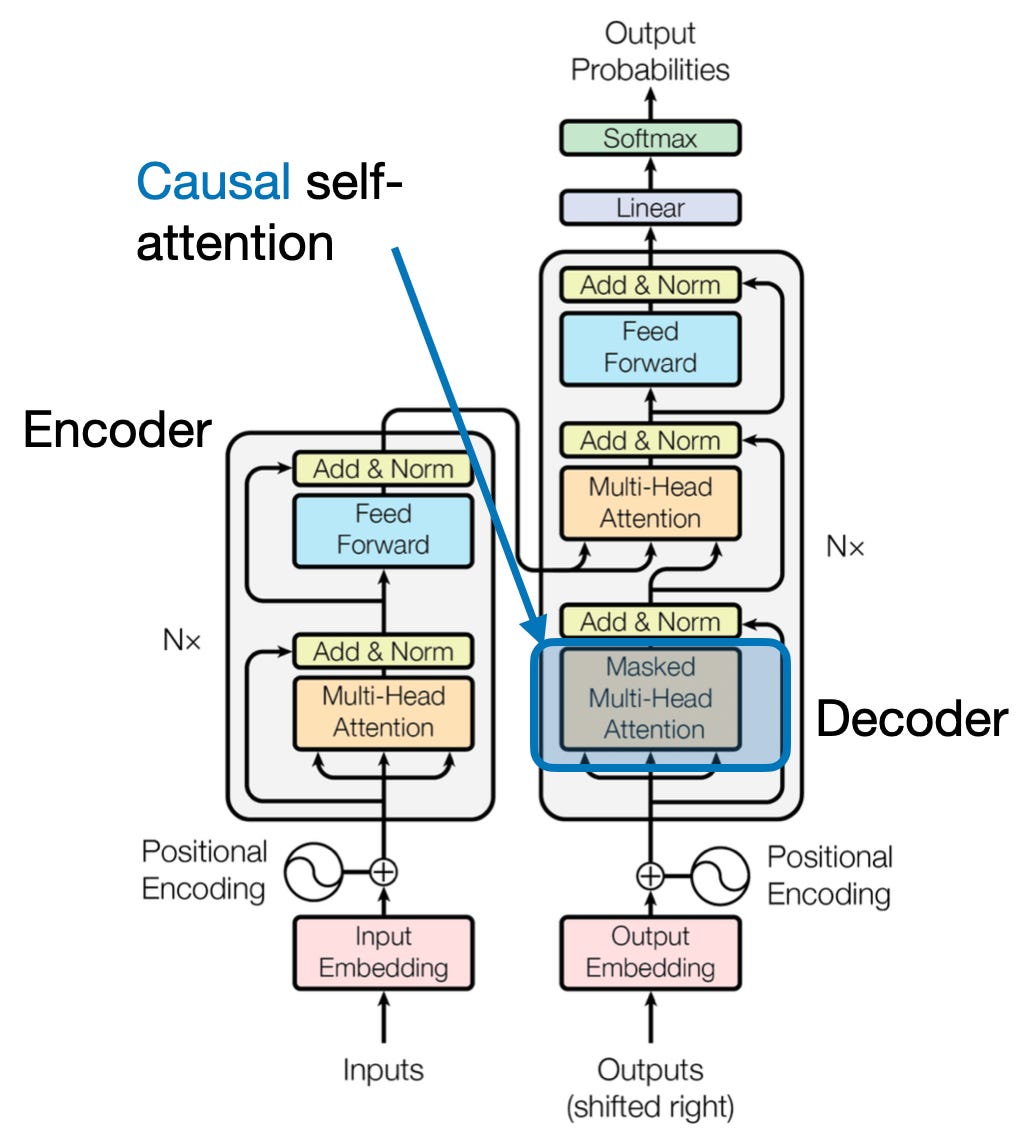
L'attention causale est cruciale pour des tâches telles que la génération de texte et la prévision de séries chronologiques, où le maintien de l'ordre temporel des données est vital pour des prédictions précises.
5. Attention mondiale ou attention locale : trouver un équilibre
Les mécanismes d’attention sont confrontés à un compromis clé : capturer les dépendances à longue portée ou maintenir un calcul efficace. Cela se manifeste par deux approches principales : attention globale ainsi que les attention locale. Imaginez lire un livre entier au lieu de vous concentrer sur un chapitre spécifique. L'attention globale traite toute la séquence en même temps, tandis que l'attention locale se concentre sur une fenêtre plus petite :
- Attention mondiale capture les dépendances à longue portée et le contexte global, mais peut être coûteux en calcul pour les longues séquences.
- Attention locale est plus efficace mais risque de passer à côté de relations à distance.
Le choix entre une attention globale et locale dépend de plusieurs facteurs :
- Exigences de la tâche: Des tâches telles que la traduction automatique nécessitent de capturer des relations distantes, favorisant ainsi l'attention globale, tandis que l'analyse des sentiments peut favoriser l'attention locale.
- Longueur de séquence: Des séquences plus longues rendent l'attention globale coûteuse en termes de calcul, nécessitant des approches locales ou hybrides.
- Capacité du modèle: Les contraintes de ressources peuvent nécessiter une attention locale, même pour les tâches nécessitant un contexte global.
Pour atteindre l’équilibre optimal, les modèles peuvent utiliser :
- Commutation dynamique: utiliser l’attention globale pour les éléments clés et l’attention locale pour les autres, en s’adaptant en fonction de l’importance et de la distance.
- Approches hybrides: combiner les deux mécanismes au sein d’une même couche, en tirant parti de leurs atouts respectifs.
Lisez aussi: Analyser les types de réseaux de neurones dans le Deep Learning
Conclusion
En fin de compte, l’approche idéale se situe sur un spectre allant de l’attention mondiale à l’attention locale. Comprendre ces compromis et adopter des stratégies appropriées permet aux modèles d'exploiter efficacement les informations pertinentes à différentes échelles, conduisant à une compréhension plus riche et plus précise de la séquence.
Bibliographie
- Raschka, S. (2023). "Comprendre et coder l'attention personnelle, l'attention multi-têtes, l'attention croisée et l'attention causale dans les LLM."
- Vaswani, A., et coll. (2017). "L'attention est tout ce dont vous avez besoin."
- Radford, A. et coll. (2019). «Les modèles linguistiques sont des apprenants multitâches non supervisés.»
Services Connexes
Je suis un amoureux des données et j'aime extraire et comprendre les modèles cachés dans les données. Je souhaite apprendre et évoluer dans le domaine du Machine Learning et de la Data Science.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :possède
- :est
- :ne pas
- :où
- $UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- capacité
- accès
- précision
- Avec cette connaissance vient le pouvoir de prendre
- atteindre
- la réalisation de
- à travers
- actes
- présenter
- adresses
- L'adoption d'
- devant
- AL
- Tous
- Permettre
- permet
- am
- Ambiguïté
- quantités
- an
- selon une analyse de l’Université de Princeton
- des analyses
- l'analyse
- ainsi que les
- répondre
- A PART
- apparent
- appliqué
- une approche
- approches
- SONT
- domaines
- article
- AS
- aspects
- Assistante gérante
- assistants
- At
- pour participer
- assister à
- précaution
- Balance
- basé
- base
- BE
- Faisceau
- devenez
- before
- jusqu'à XNUMX fois
- Au-delà
- blocage
- livre
- Livres
- tous les deux
- PONT
- ponts
- Brillanti
- plus large
- Apporté
- Développement
- construit
- construit
- mais
- by
- venu
- CAN
- capturer
- captures
- Capturer
- cas
- Change
- Chapitre
- chapitres
- le choix
- plus
- Codage
- combiner
- vient
- Sociétés
- compatibilité
- complexe
- calcul
- calcul
- NOUS CONTACTER
- Connecter les
- Connexions
- Considérer
- considérant
- contraintes
- contient
- contenu
- contexte
- continuer
- Core
- corrélations
- créée
- crée des
- La création
- critique
- crucial
- Courant
- données
- science des données
- Déchiffrer
- profond
- profond
- défini
- Delves
- dépendre
- dépendance
- dépendances
- Dépendance
- dépend
- détaillé
- Dialogue
- DID
- différent
- directement
- distance
- Loin
- distinct
- plusieurs
- do
- document
- DOT
- double
- des dizaines
- Dramatiquement
- dessiner
- deux
- dynamique
- E & T
- chacun
- de manière efficace
- efficace
- efficace
- efficacement
- élément
- éléments
- l'autonomisation des
- permet
- permettant
- codage
- enrichi
- assurer
- assurer
- Entrer
- Tout
- intégralité
- équipé
- notamment
- essence
- essential
- essentiellement
- établies
- Pourtant, la
- Chaque
- évolue
- exactement
- cher
- Exploiter
- extrait
- Visage
- facteurs
- loin
- favoriser
- champ
- Des champs
- finale
- flux
- Flux
- Focus
- concentré
- se concentre
- mettant l'accent
- Pour
- Premier plan
- document
- Fondation
- quatre
- Framework
- de
- fonction
- fonctionnalités
- avenir
- jeu
- génère
- générateur
- génération
- Global
- contexte mondial
- saisir
- Croître
- Guides
- guidage
- manipuler
- Vous avez
- ayant
- front
- aider
- caché
- Haute
- augmentation
- Soulignant
- détient
- holistique
- Comment
- HTTPS
- humain
- Hybride
- i
- idéal
- identifier
- if
- image
- Immédiat
- importance
- important
- in
- inexacte
- incorporation
- indiquer
- individuel
- inefficace
- d'information
- intrinsèquement
- contribution
- idées.
- instance
- Intelligent
- prévu
- l'interaction
- interactions
- interagit
- intervenant
- développement
- inestimable
- seul
- IT
- SES
- jpg
- juste
- ACTIVITES
- Zones-clés
- langue
- Nom de famille
- couche
- conduisant
- APPRENTISSAGE
- Apprenez et grandissez
- apprenants
- apprentissage
- LED
- Lens
- lentilles
- Levier
- en tirant parti
- Bibliothèque
- se trouve
- lumière
- comme
- limitation
- limites
- locales
- Location
- plus long
- Style
- love
- click
- machine learning
- traduction automatique
- le maintien
- a prendre une
- Fabrication
- man
- de nombreuses
- masque
- Matrice
- largeur maximale
- sens
- significations
- mesuré
- mécanisme
- mécanismes
- Mémoire
- pourrait
- manquer
- manquant
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- plus efficace
- multiforme
- plusieurs
- Nature
- Langage naturel
- Génération de Langage Naturel
- Traitement du langage naturel
- Compréhension du langage naturel
- Nature
- Besoin
- besoin
- Besoins
- voisins
- réseaux
- Neural
- les réseaux de neurones
- Nouveauté
- next
- nuit
- nlp
- noms
- maintenant
- nuance
- of
- souvent
- on
- une fois
- uniquement
- optimaux
- or
- de commander
- Autre
- Autres
- nos
- ande
- sortie
- sorties
- global
- vue d'ensemble
- propre
- page
- paire
- Papier
- Parallèle
- les pièces
- des billets
- passé
- motifs
- effectuer
- performant
- perspectives
- pièces
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- Point
- pose
- possède
- possibilités
- puissant
- défaillances
- l'éventualité
- power
- solide
- prévoir
- Prédictions
- conservation
- prévention
- précédemment
- qui se déroulent
- primaire
- processus
- traité
- les process
- traitement
- Puissance de calcul
- Produit
- projetée
- propulsé
- fournit
- question
- gamme
- allant
- plutôt
- Lire
- facilement
- en cours
- en temps réel
- référence
- Indépendamment
- Les relations
- relatif
- pertinence
- pertinent
- remarquables
- représentation
- représentation
- représente
- exigent
- résoudre
- ressource
- Resources
- ceux
- Résultats
- Avis
- révolutionnaire
- révolutionné
- Rich
- Rôle
- s
- même
- Sarcasme
- scie
- Balance
- balayage
- Sciences
- But
- scores
- Rechercher
- Deuxièmement
- voir
- phrase
- sentiment
- Séquence
- Série
- sert
- plusieurs
- Partager
- brillant
- tournage
- Shorts
- vitrine
- simultanément
- lent
- faibles
- uniquement
- RÉSOUDRE
- parfois
- Sources
- Space
- groupe de neurones
- spécifiquement
- Spectre
- vitesses
- Spotlight
- permanent
- Étoile
- étapes
- STORES
- les stratégies
- forces
- plus efficacement
- structure
- Lutter
- Luttant
- sujet
- ultérieur
- tel
- convient
- somme
- résumé
- RÉSUMÉ
- haut
- Alentours
- Système
- tacle
- prise
- tapisserie
- tâches
- Technique
- terme
- texte
- génération de texte
- qui
- Les
- le monde
- leur
- Les
- puis
- Ces
- l'ont
- this
- trois
- Avec
- fiable
- Des séries chronologiques
- à
- outil
- traditionnel
- Formation
- transformation
- transformé
- transformateur
- transformateurs
- transformer
- Traduction
- oui
- deux
- types
- En fin de compte
- comprendre
- compréhension
- indubitablement
- déverrouillage
- dévoiler
- dévoilé
- utilisé
- Usages
- en utilisant
- divers
- Vaste
- Versus
- Voir
- visité
- vital
- vs
- souhaitez
- veut
- était
- WELL
- Quoi
- quand
- tout en
- WHO
- la totalité
- large
- Large gamme
- sera
- fenêtre
- comprenant
- dans les
- sans
- femme
- Word
- des mots
- activités principales
- world
- écriture
- hier
- you
- zéphyrnet
- ZOO