Alors que l’ingénierie des données devient de plus en plus complexe, les organisations recherchent de nouvelles façons de rationaliser leurs flux de travail de traitement des données. De nombreux ingénieurs de données utilisent aujourd'hui Apache Airflow pour créer, planifier et surveiller leurs pipelines de données.
Cependant, à mesure que le volume de données augmente, la gestion et la mise à l’échelle de ces pipelines peuvent devenir une tâche ardue. Flux de travail gérés par Amazon pour Apache Airflow (Amazon MWAA) peut contribuer à simplifier le processus de création, d'exécution et de gestion des pipelines de données. En fournissant Apache Airflow en tant que plate-forme entièrement gérée, Amazon MWAA permet aux ingénieurs de données de se concentrer sur la création de flux de travail de données au lieu de se soucier de l'infrastructure.
Aujourd’hui, les entreprises et les organisations ont besoin de moyens rentables et efficaces pour traiter de grandes quantités de données. Amazon EMR sans serveur est une solution rentable et évolutive pour le traitement du Big Data, capable de gérer de gros volumes de données. Le fournisseur Amazon dans Apache Airflow est fourni avec les opérateurs EMR Serverless et est déjà inclus dans Amazon MWAA, ce qui permet aux ingénieurs de données de créer facilement des pipelines de traitement de données évolutifs et fiables. Vous pouvez utiliser EMR Serverless pour exécuter des tâches Spark sur les données et utiliser Amazon MWAA pour gérer les flux de travail et les dépendances entre ces tâches. Cette intégration peut également contribuer à réduire les coûts en faisant automatiquement évoluer les ressources nécessaires au traitement des données.
Amazon Athena est un service d'analyse interactif sans serveur construit sur des frameworks open source, prenant en charge les formats de table ouverte et de fichier. Vous pouvez utiliser du SQL standard pour interagir avec les données. Athena, un service d'analyse interactif et sans serveur, rend cela possible sans avoir à gérer une infrastructure complexe.
Dans cet article, nous utilisons Amazon MWAA, EMR Serverless et Athena pour créer un pipeline complet de traitement de données de bout en bout.
Vue d'ensemble de la solution
Le diagramme suivant illustre l'architecture de la solution.
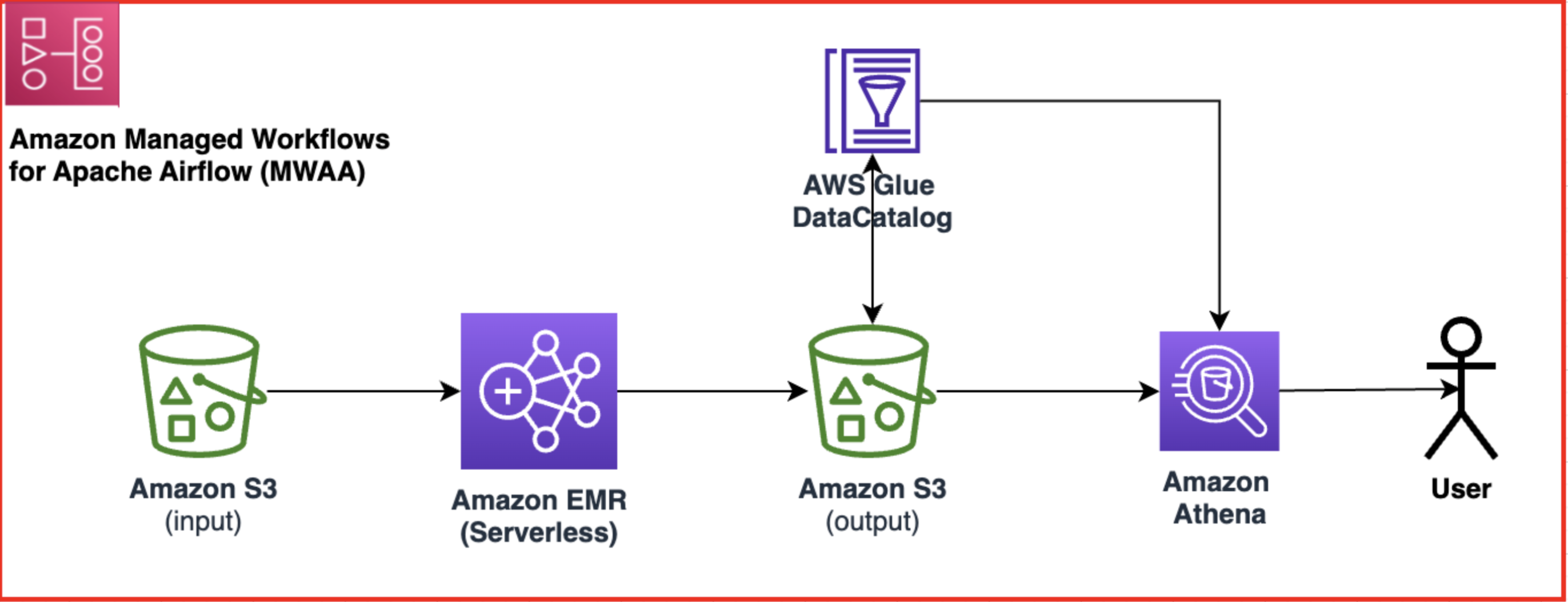
Le workflow comprend les étapes suivantes:
- Créez un flux de travail Amazon MWAA qui récupère les données de votre entrée Service de stockage simple Amazon (Amazon S3) seau.
- Utilisez EMR Serverless pour traiter les données stockées dans Amazon S3. EMR Serverless évolue automatiquement en fonction de la charge de travail, vous n'avez donc pas à vous soucier du provisionnement ou de la gestion d'une infrastructure.
- Utilisez EMR Serverless pour transformer les données à l'aide du code PySpark, puis stockez les données transformées dans votre compartiment S3.
- Utilisez Athena pour créer une table externe basée sur l'ensemble de données S3 et exécuter des requêtes pour analyser les données transformées. Athéna utilise le Colle AWS Data Catalog pour stocker les métadonnées de la table.
Pré-requis
Vous devez avoir les prérequis suivants :
Préparation des données
Pour illustrer l'utilisation de tâches EMR Serverless avec Apache Spark via Amazon MWAA et la validation des données à l'aide d'Athena, nous utilisons l'ensemble de données de taxi de New York accessible au public. Téléchargez les ensembles de données suivants sur votre ordinateur local :
- Registres des trajets en taxi vert et en taxi jaune – Dossiers de trajet des taxis jaunes et verts, qui incluent des informations telles que les dates et heures de prise en charge et de dépose, les lieux, les distances de trajet et les types de paiement. Dans notre exemple, nous utilisons les derniers fichiers Parquet pour 2022.
- Ensemble de données pour la recherche de zone de taxi – Un ensemble de données qui fournit les identifiants de localisation et les détails de zone correspondants pour les taxis.
Dans les étapes ultérieures, nous téléchargeons ces ensembles de données sur Amazon S3.
Créer des ressources de solution
Cette section décrit les étapes de configuration du traitement et de la transformation des données.
Créer une application sans serveur EMR
Vous pouvez créer une ou plusieurs applications EMR Serverless qui utilisent des frameworks d'analyse open source comme Apache Spark ou Apache Hive. Contrairement à EMR sur EC2, vous n'avez pas besoin de supprimer ou de mettre fin aux applications EMR Serverless. L'application EMR Serverless n'est qu'une définition et une fois créée, elle peut être réutilisée aussi longtemps que nécessaire. Cela simplifie le pipeline MWAA car il vous suffit désormais de soumettre des tâches à une application EMR Serverless pré-créée.
Par défaut, l'application EMR Serverless démarrera automatiquement lors de la soumission du travail et s'arrêtera automatiquement lorsqu'elle sera inactive pendant 15 minutes par défaut pour garantir la rentabilité. Vous pouvez modifier la durée d'inactivité ou choisir de désactiver la fonctionnalité.
Pour créer une application à l'aide de la console EMR Serverless, suivez les instructions dans «Créer une application sans serveur EMR ». Notez l'ID de l'application car nous l'utiliserons dans les étapes suivantes.
![]()
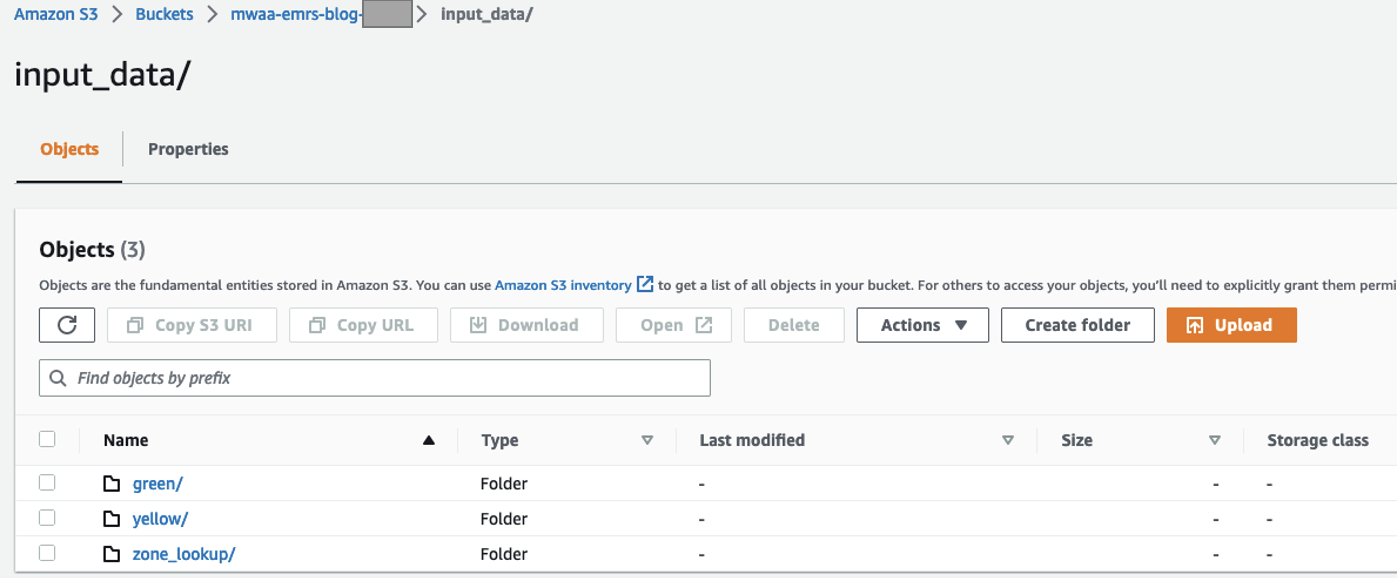
Créer un compartiment et des dossiers S3
Effectuez les étapes suivantes pour configurer votre compartiment et vos dossiers S3 :
- Sur la console Amazon S3, créer un compartiment S3 pour stocker l'ensemble de données.
- Notez le nom du compartiment S3 à utiliser dans les étapes ultérieures.
- Créer un
input_datadossier pour stocker les données d’entrée. - Dans ce dossier, créez trois dossiers distincts, un pour chaque ensemble de données :
green,yellowet unezone_lookup.
Vous pouvez télécharger et travailler avec les derniers ensembles de données disponibles. Pour nos tests, nous utilisons les fichiers suivants :
- Le
green/le dossier contient le fichiergreen_tripdata_2022-06.parquet - Le
yellow/le dossier contient le fichieryellow_tripdata_2022-06.parquet - Le
zone_lookup/le dossier contient le fichiertaxi_zone_lookup.csv
Configurer les scripts Amazon MWAA DAG
Effectuez les étapes suivantes pour configurer vos scripts DAG :
- Téléchargez les scripts suivants sur votre ordinateur local :
- conditions.txt – Une dépendance Python est tout package ou distribution qui n'est pas inclus dans l'installation de base d'Apache Airflow pour votre version d'Apache Airflow sur votre environnement Amazon MWAA. Pour cet article, nous utilisons Boto3
version >=1.23.9. - blog_dag_mwaa_emrs_ny_taxi.py – Ce script fait partie du DAG Amazon MWAA et comprend les tâches suivantes :
yellow_taxi_zone_lookup,green_taxi_zone_lookupet uneny_taxi_summary,. Ces tâches impliquent l'exécution de tâches Spark pour rechercher des zones de taxi et générer un résumé des données. - zone_verte.py – Ce script PySpark lit les fichiers de données pour les trajets en taxi vert et la recherche de zone, effectue une opération de jointure pour les combiner et génère un fichier de sortie contenant des trajets en taxi vert avec des informations sur la zone. Il utilise des vues temporaires pour le
df_greenet lesdf_zonedes trames de données, effectue des jointures basées sur des colonnes et regroupe des données telles que le nombre de passagers, la distance du trajet et le montant du tarif. Enfin, cela crée leoutput_datadossier dans le compartiment S3 spécifié pour écrire la trame de données résultante,df_green_zone, comme les dossiers Parquet. - jaune_zone.py – Ce script PySpark traite les fichiers de données de trajet en taxi jaune et de recherche de zone en les joignant pour générer un fichier de sortie contenant des trajets en taxi jaune avec des informations de zone. Le script accepte un nom de compartiment S3 fourni par l'utilisateur et lance une session Spark avec le nom de l'application.
yellow_zone. Il lit les fichiers de taxi jaune et le fichier de recherche de zone à partir du compartiment S3 spécifié, crée des vues temporaires, effectue une jointure basée sur l'ID d'emplacement et calcule des statistiques telles que le nombre de passagers, la distance parcourue et le montant du tarif. Enfin, cela crée leoutput_datadossier dans le compartiment S3 spécifié pour écrire la trame de données résultante,df_yellow_zone, comme les dossiers Parquet. - ny_taxi_summary.py – Ce script PySpark traite le
green_zoneet lesyellow_zonefichiers pour regrouper les statistiques sur les courses en taxi, en regroupant les données par zones de service et identifiants d'emplacement. Il nécessite un nom de compartiment S3 comme argument de ligne de commande et crée une SparkSession nomméeny_taxi_summary, lit les fichiers de S3, effectue une jointure et génère une nouvelle trame de données nomméeny_taxi_summary. Il crée un dossier output_data dans le compartiment S3 spécifié pour écrire la trame de données résultante dans de nouveaux fichiers Parquet.
- conditions.txt – Une dépendance Python est tout package ou distribution qui n'est pas inclus dans l'installation de base d'Apache Airflow pour votre version d'Apache Airflow sur votre environnement Amazon MWAA. Pour cet article, nous utilisons Boto3
- Sur votre ordinateur local, mettez à jour le
blog_dag_mwaa_emrs_ny_taxi.pyscript avec les informations suivantes :- Mettez à jour le nom de votre compartiment S3 dans les deux lignes suivantes :
- Mettez à jour votre nom de rôle ARN :
- Mettez à jour l’ID de l’application sans serveur EMR. Utilisez l’ID d’application créé précédemment.
- Télécharger le
requirements.txtfichier dans le compartiment S3 créé précédemment
- Dans le compartiment S3, créez un dossier nommé
dagset téléchargez la mise à jourblog_dag_mwaa_emrs_ny_taxi.pyfichier à partir de votre ordinateur local.
- Sur la console Amazon S3, créez un nouveau dossier nommé
scriptsdans le compartiment S3 et téléchargez les scripts dans ce dossier à partir de votre ordinateur local.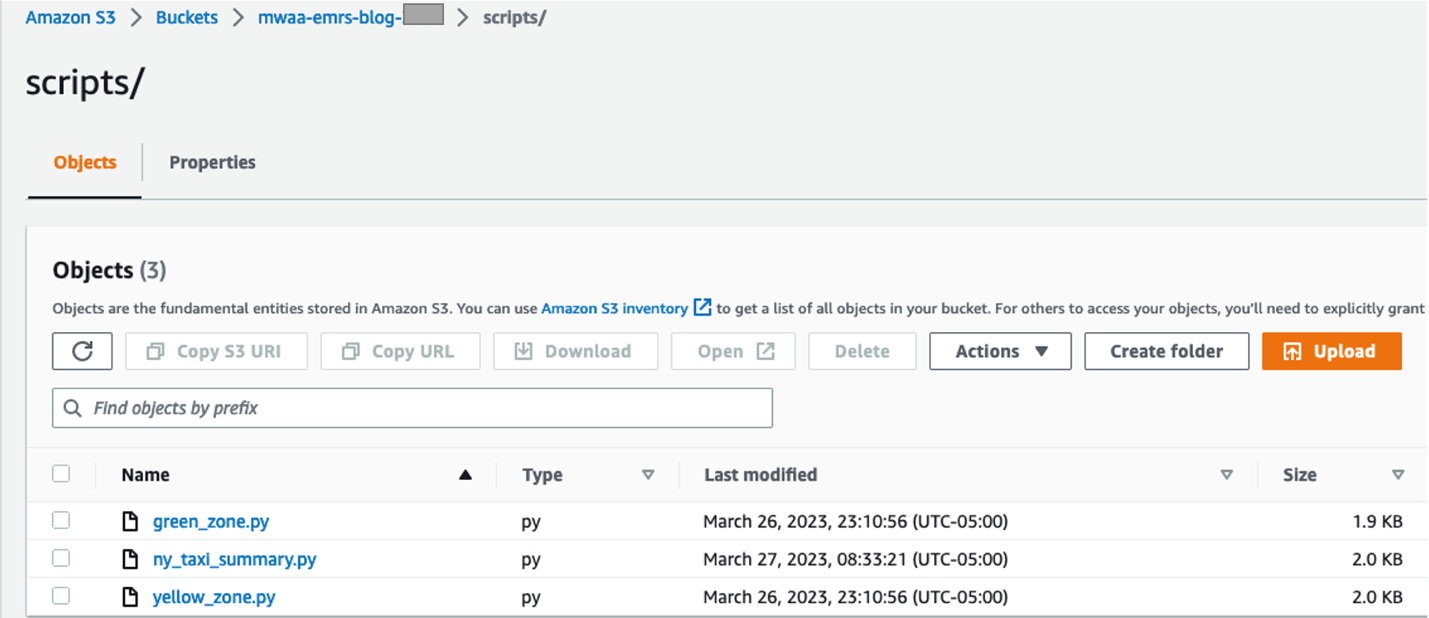
Créer un environnement Amazon MWAA
Pour créer un environnement Airflow, procédez comme suit :
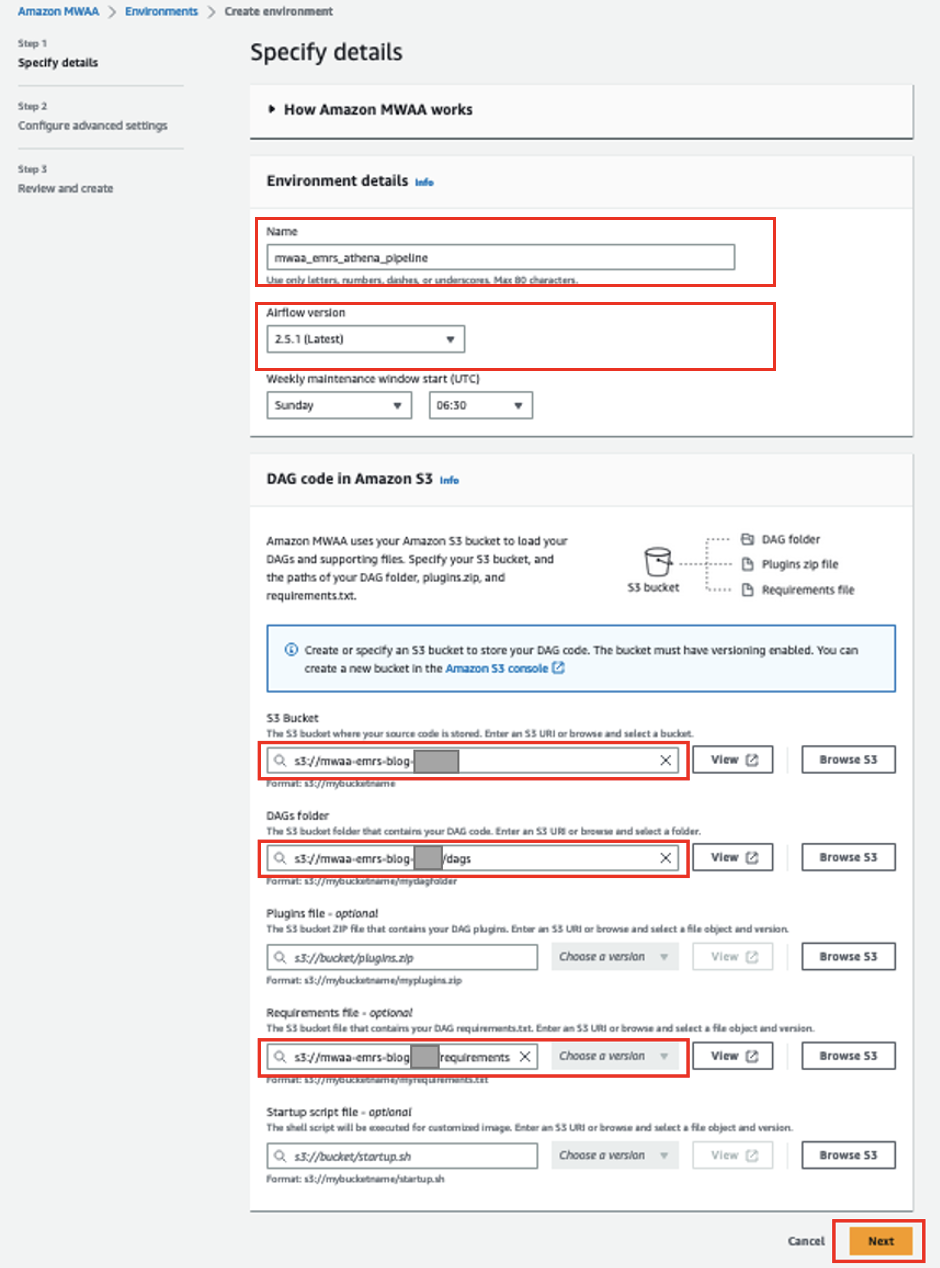
- Sur la console Amazon MWAA, choisissez Créer un environnement.

- Pour Nom, Entrer
mwaa_emrs_athena_pipeline. - Pour Version débit d'air, choisissez la dernière version (pour cet article, 2.5.1).
- Pour Compartiment S3, entrez le chemin d'accès à votre compartiment S3.
- Pour dossier DAG, entrez le chemin d'accès à votre
dagsdossier. - Pour Fichier d'exigences, entrez le chemin vers le
requirements.txtfichier. - Selectionnez Suivant.
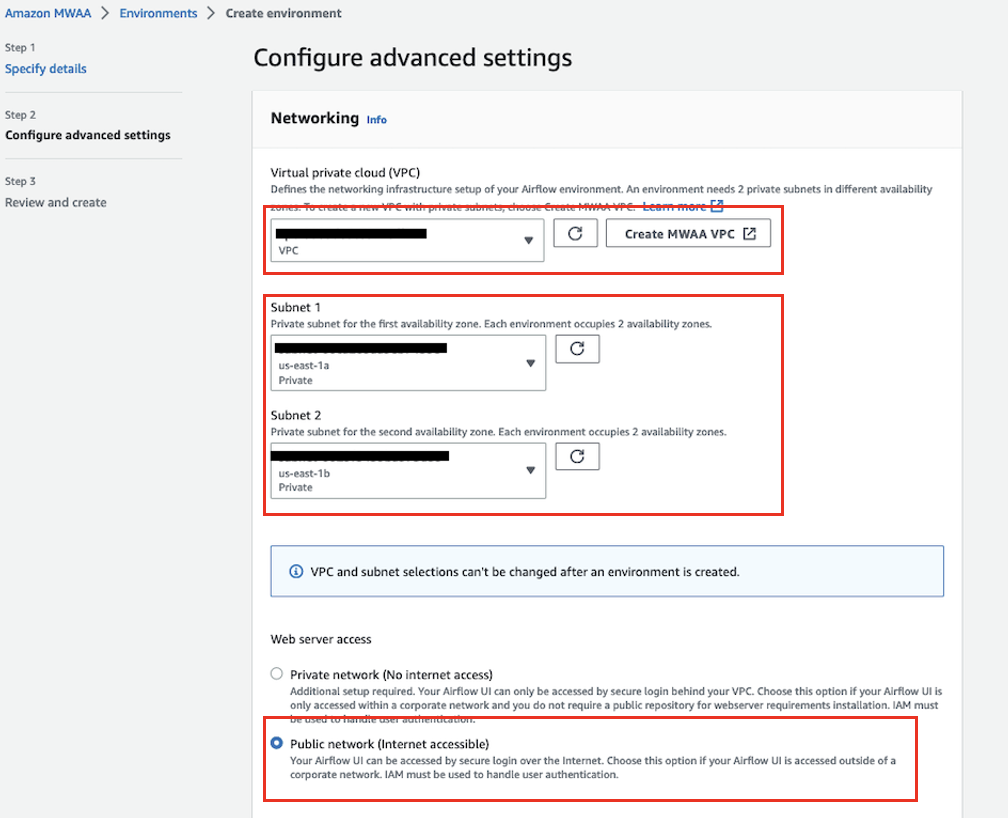
- Pour Cloud privé virtuel (VPC), choisissez un VPC doté d'au moins deux sous-réseaux privés.
Cela remplira deux des sous-réseaux privés de votre VPC.
- Sous Accès au serveur Web, sélectionnez Réseau public.
Cela permet à l'interface utilisateur Apache Airflow d'être accessible via Internet par les utilisateurs ayant accès au Politique IAM pour votre environnement.
- Pour Groupe (s) de sécurité, sélectionnez Créer un nouveau groupe de sécurité.
- Pour Classe d'environnement, sélectionnez mw1.petit.
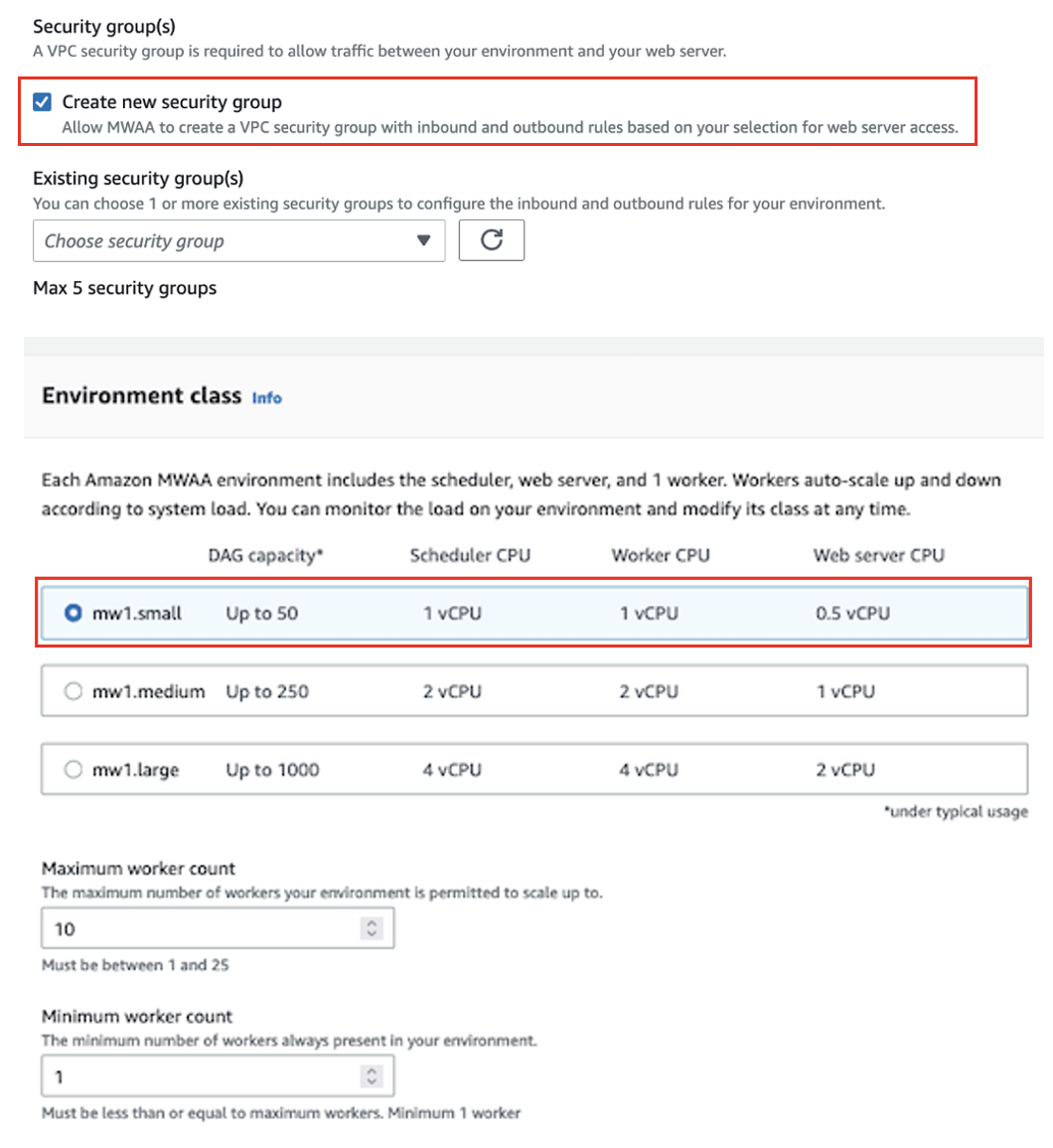
- Pour Rôle d'exécution, choisissez Créer un nouveau rôle.
- Pour Nom de rôle, entrez un nom.
- Laissez les autres configurations par défaut et choisissez Suivant.

- Sur la page suivante, choisissez Création sûr, heureux et sain.
La création de votre environnement Amazon MWAA peut prendre environ 20 à 30 minutes.
- Lorsque l'état de l'environnement Amazon MWAA passe à Disponible, accédez à la console IAM et mettez à jour le rôle d'exécution du cluster pour l'ajouter transmettre les privilèges du rôle à
emr_serverless_execution_role.
Déclenchez le DAG Amazon MWAA
Pour déclencher le DAG, procédez comme suit :
- Sur la console Amazon MWAA, choisissez Environnements dans le volet de navigation.
- Ouvrez votre environnement et choisissez Ouvrir l’interface utilisateur d’Airflow.
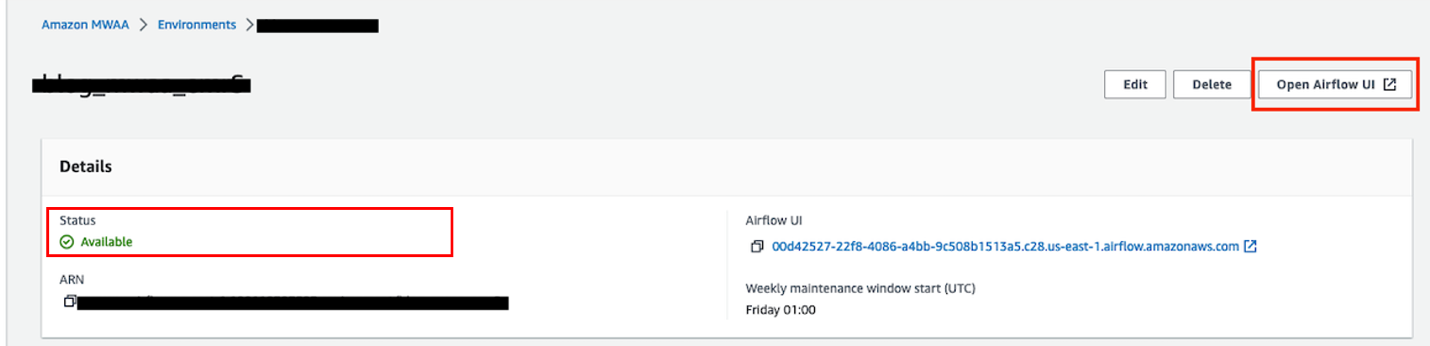
- Sélectionnez
blog_dag_mwaa_emr_ny_taxi, choisissez l'icône de lecture, puis choisissez Déclencher DAG.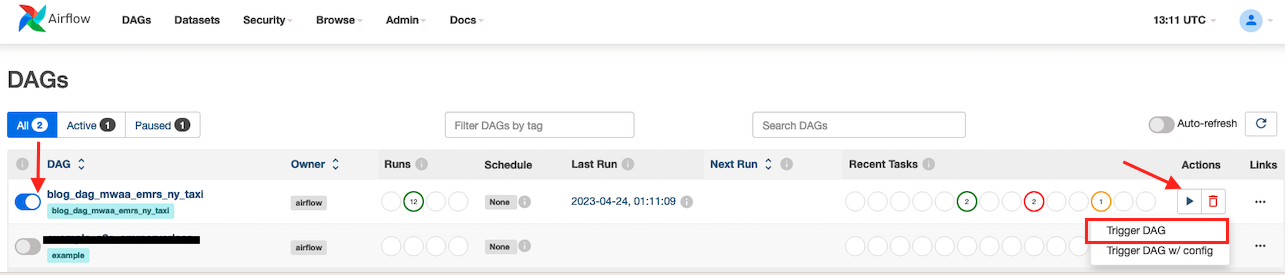
- Lorsque le DAG est en cours d'exécution, choisissez le DAG
blog_dag_mwaa_emrs_ny_taxiet choisissez Graphique pour localiser votre workflow d'exécution DAG.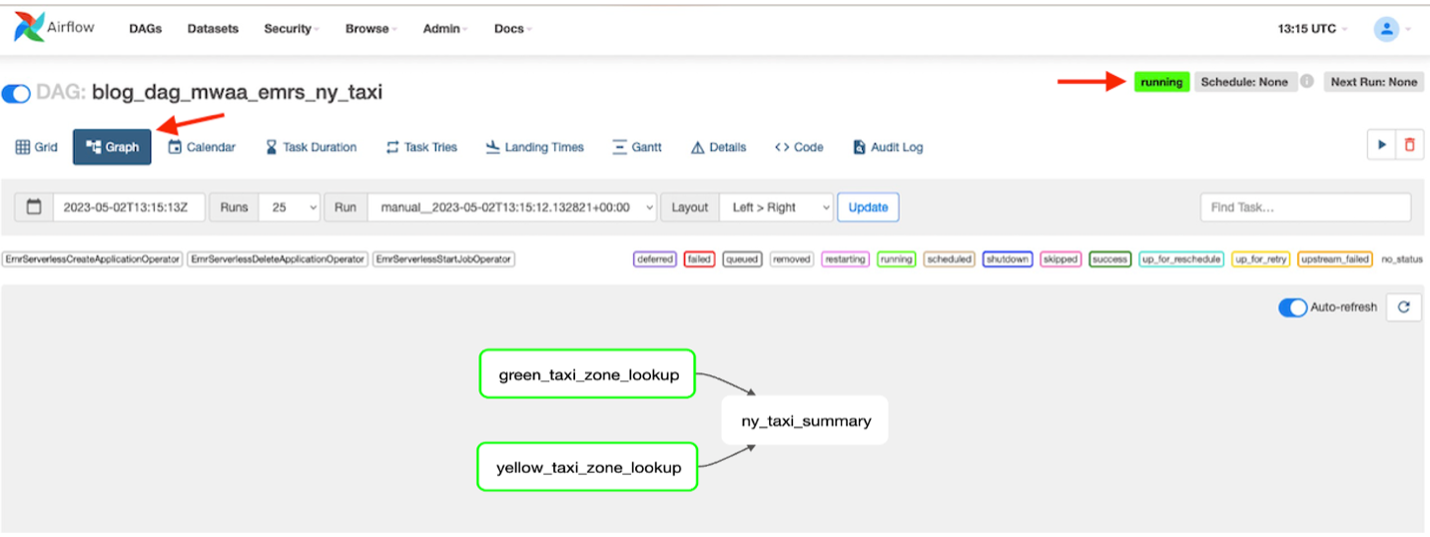
Le DAG prendra environ 4 à 6 minutes pour exécuter tous les scripts. Vous verrez toutes les tâches terminées et l'état global du DAG s'affichera comme suit : succès.

Pour réexécuter le DAG, supprimez s3://<<your_s3_bucket here >>/output_data/.
Si vous le souhaitez, pour comprendre comment Amazon MWAA exécute ces tâches, choisissez la tâche que vous souhaitez inspecter.

Selectionnez Courir pour afficher les détails de l'exécution de la tâche.
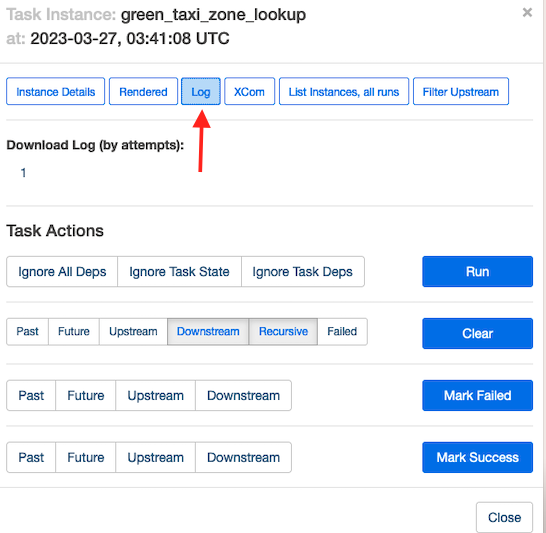
La capture d'écran suivante montre un exemple de journaux de tâches.
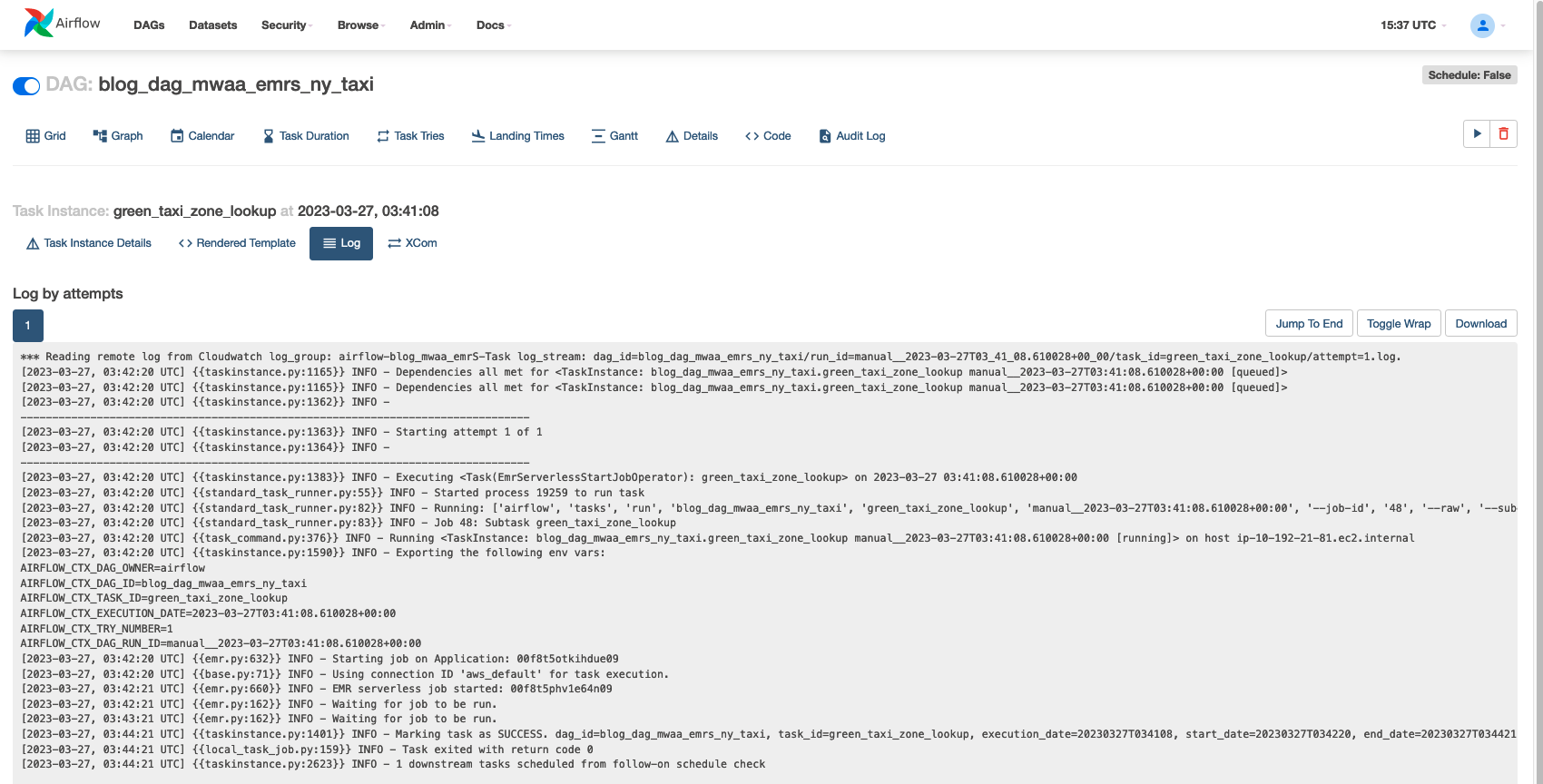
Si vous souhaitez approfondir les journaux d'exécution, alors sur la console EMR Serverless, accédez à « Applications ». Les journaux du pilote Apache Spark indiqueront le lancement de votre tâche ainsi que les détails des exécuteurs, des étapes et des tâches créés par EMR Serverless. Ces journaux peuvent être utiles pour surveiller la progression de votre tâche et résoudre les échecs.
Par défaut, EMR Serverless stockera les journaux d'application en toute sécurité dans le stockage géré Amazon EMR pendant une période de 30 jours. Cependant, vous pouvez également préciser Amazon S3 ou Amazon CloudWatch comme options de livraison de journaux lors de la soumission du travail.

Valider le résultat final avec Athena
Vérifions les données chargées par le processus à l'aide des requêtes Athena SQL.
- Sur la console Athena, choisissez Éditeur de requête dans le volet de navigation.
- Si vous utilisez Athena pour la première fois, sous Paramètres, choisissez Gérer et entrez l'emplacement du compartiment S3 que vous avez créé précédemment (
<S3_BUCKET_NAME>/athena), Alors choisi Épargnez.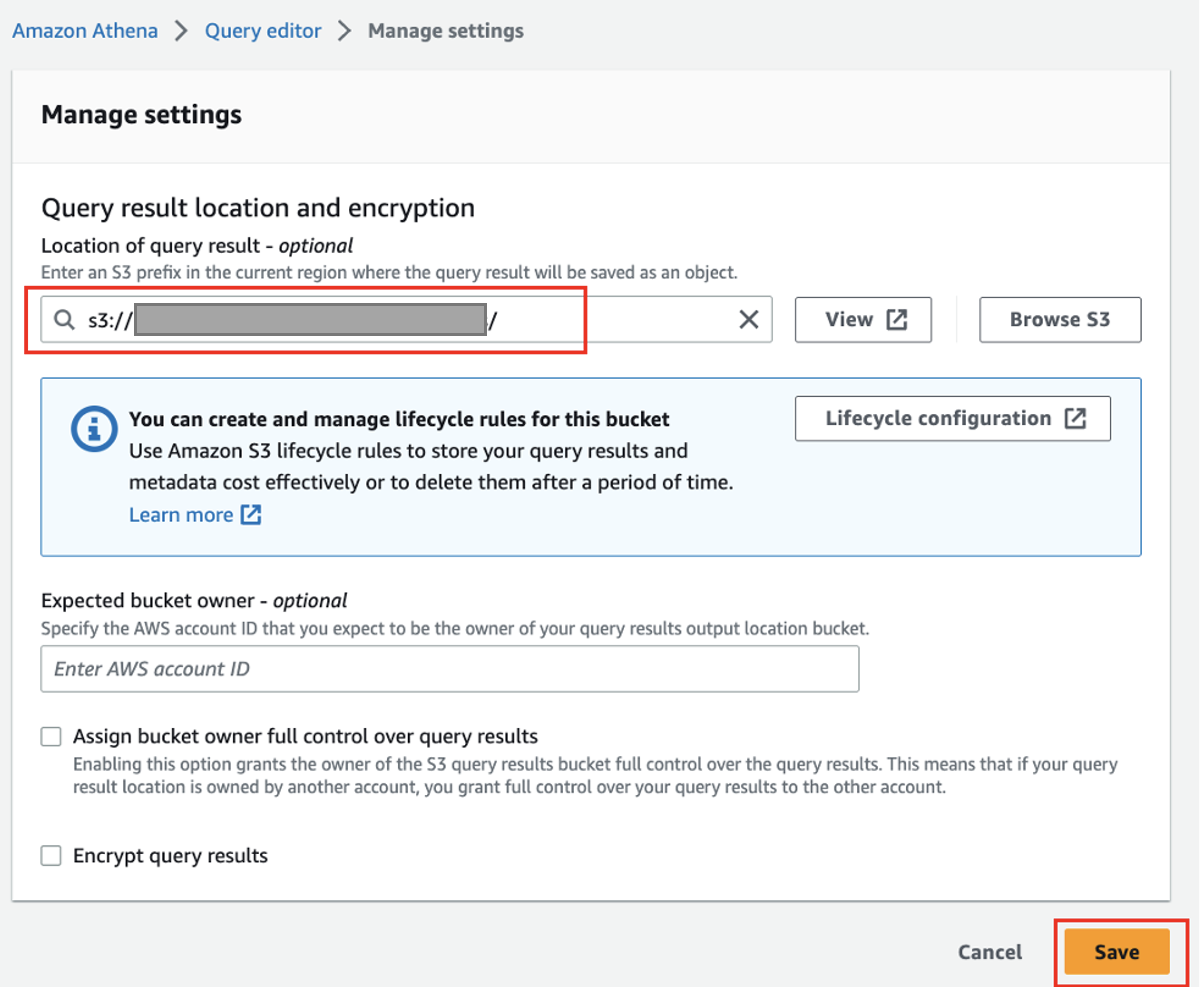
- Dans l'éditeur de requêtes, saisissez la requête suivante pour créer une table externe :

Exécutez la requête suivante sur le fichier récemment créé ny_taxi_summary table pour récupérer les 10 premières lignes pour valider les données :

Nettoyer
Pour éviter des frais futurs, procédez comme suit :
- Sur la console Amazon S3, supprimez le compartiment S3 que vous avez créé pour stocker le DAG, les scripts et les journaux Amazon MWAA.
- Sur la console Athena, déposez la table que vous avez créée :
- Sur la console Amazon MWAA, accédez à l'environnement que vous avez créé et choisissez Supprimer.

- Sur la console EMR Studio, supprimez l'application.
Pour supprimer l'application, accédez au Liste des candidatures page. Sélectionnez l'application que vous avez créée et choisissez Actions → Arrêter pour arrêter l'application. Une fois l'application à l'état STOPPED, sélectionnez la même application et choisissez Actions → Supprimer.

Conclusion
L’ingénierie des données est un élément essentiel pour de nombreuses organisations et, à mesure que les volumes de données continuent de croître, il est essentiel de trouver des moyens de rationaliser les flux de traitement des données. La combinaison d'Amazon MWAA, d'EMR Serverless et d'Athena fournit une solution puissante pour créer, exécuter et gérer efficacement des pipelines de données. Grâce à ce pipeline de traitement de données de bout en bout, les ingénieurs de données peuvent facilement traiter et analyser de grandes quantités de données, rapidement et de manière rentable, sans avoir besoin de gérer une infrastructure complexe. L'intégration de ces services AWS fournit une solution robuste et évolutive pour le traitement des données, aidant les organisations à prendre des décisions éclairées basées sur leurs informations sur les données.
Maintenant que vous avez vu comment soumettre des tâches Spark sur EMR Serverless via Amazon MWAA, nous vous encourageons à utiliser Amazon MWAA pour créer un flux de travail qui exécutera des tâches PySpark via EMR Serverless.
Nous apprécions vos commentaires et vos demandes de renseignements. N'hésitez pas à nous contacter si vous avez des questions ou des commentaires.
À propos des auteurs
 Rahul Sonawane est un architecte principal de solutions d'analyse chez AWS avec l'IA/ML et l'analyse comme domaine de spécialité.
Rahul Sonawane est un architecte principal de solutions d'analyse chez AWS avec l'IA/ML et l'analyse comme domaine de spécialité.
 Gaurav Parekh est un architecte de solutions qui aide les clients AWS à créer une architecture moderne à grande échelle. Il se spécialise dans l'analyse de données et les réseaux. En dehors du travail, Gaurav aime jouer au cricket, au football et au volley-ball.
Gaurav Parekh est un architecte de solutions qui aide les clients AWS à créer une architecture moderne à grande échelle. Il se spécialise dans l'analyse de données et les réseaux. En dehors du travail, Gaurav aime jouer au cricket, au football et au volley-ball.
Historique des audits
Décembre 2023 : l'exactitude technique de cet article a été vérifiée par Santosh Gantam, responsable de compte technique principal.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-spark-jobs-with-amazon-mwaa-and-data-validation-using-amazon-athena/
- :possède
- :est
- :ne pas
- $UP
- 1
- 10
- 100
- 118
- 15%
- 16
- 2022
- 2023
- 23
- 25
- 30
- 300
- 7
- 700
- 8
- 9
- 990
- a
- A Propos
- Accepte
- accès
- accédé
- Compte
- précision
- ajouter
- Après
- agrégat
- AI / ML
- Tous
- permet
- le long de
- déjà
- aussi
- Amazon
- Amazone Athéna
- Amazon DME
- Amazon Web Services
- montant
- quantités
- an
- analytique
- il analyse
- et les
- tous
- Apache
- Apache Spark
- Application
- applications
- d'environ
- architecture
- SONT
- Réservé
- argument
- AS
- At
- automatiquement
- disponibles
- AWS
- RETOUR
- base
- basé
- BE
- devenez
- devient
- jusqu'à XNUMX fois
- Big
- Big Data
- construire
- Développement
- construit
- entreprises
- by
- calcule
- CAN
- catalogue
- Change
- Modifications
- des charges
- Selectionnez
- classification
- le cloud
- Grappe
- code
- combinaison
- combiner
- vient
- commentaires
- complet
- complexe
- composant
- consiste
- Console
- continuer
- Correspondant
- Prix
- rentable
- Costs
- engendrent
- créée
- crée des
- cricket
- critique
- Clients
- JOUR
- données
- Analyse de Donnée
- informatique
- ensembles de données
- Dates
- jours
- décisions
- profond
- Réglage par défaut
- définition
- page de livraison.
- dépendances
- Dépendance
- détails
- distance
- distribution
- plongeon
- do
- Ne pas
- double
- down
- download
- driver
- Goutte
- pendant
- e
- chacun
- Plus tôt
- même
- Easy
- éditeur
- efficace
- efficace
- efficacement
- encourager
- end-to-end
- ENGINEERING
- Les ingénieurs
- assurer
- Entrer
- Environment
- essential
- Ether (ETH)
- exemple
- exécution
- externe
- supplémentaire
- échecs
- Fonctionnalité
- Réactions
- ressentir
- Déposez votre dernière attestation
- Fichiers
- finale
- Trouvez
- Prénom
- première fois
- Focus
- suivre
- Abonnement
- Pour
- le format
- CADRE
- cadres
- gratuitement ici
- De
- d’étiquettes électroniques entièrement
- avenir
- générer
- génère
- générateur
- accordée
- Vert
- Croître
- Pousse
- Hadoop
- manipuler
- Vous avez
- he
- vous aider
- utile
- aider
- ici
- sa
- Ruche
- Comment
- How To
- Cependant
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Idle
- ids
- if
- illustrer
- illustre
- in
- comprendre
- inclus
- inclut
- de plus en plus
- indiquer
- d'information
- Actualités
- Infrastructure
- Initie
- initiation
- contribution
- Messages
- à l'intérieur
- idées.
- installer
- plutôt ;
- Des instructions
- l'intégration
- interagir
- Interactif
- Internet
- impliquer
- IT
- Emploi
- Emplois
- rejoindre
- joindre
- Joint
- jpg
- juste
- gros
- enfin
- plus tard
- Nouveautés
- comme
- LIMIT
- Gamme
- lignes
- locales
- emplacement
- emplacements
- enregistrer
- Location
- recherchez-
- rechercher
- click
- a prendre une
- FAIT DU
- Fabrication
- gérer
- gérés
- manager
- les gérer
- de nombreuses
- Mai..
- Métadonnées
- minimum
- minutes
- Villas Modernes
- modifier
- Surveiller
- PLUS
- prénom
- Nommé
- NAVIGUER
- Navigation
- Besoin
- nécessaire
- de mise en réseau
- Nouveauté
- next
- Aucun
- maintenant
- NYC
- of
- de rabais
- on
- une fois
- ONE
- uniquement
- ouvert
- open source
- opération
- opérateurs
- Options
- or
- organisations
- Autre
- nos
- ande
- grandes lignes
- sortie
- au contrôle
- plus de
- global
- paquet
- page
- pain
- partie
- chemin
- Paiement
- effectue
- période
- pipeline
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- jouer
- veuillez cliquer
- politique
- possible
- Post
- solide
- conditions préalables
- empêcher
- Directeur
- Privé
- processus
- les process
- traitement
- Progrès
- de voiture.
- fournit
- aportando
- publiquement
- Python
- requêtes
- fréquemment posées
- vite.
- nous joindre
- récemment
- Articles
- réduire
- fiable
- supprimez
- exigent
- a besoin
- Resources
- résultat
- résultant
- examiné
- Rouler
- manèges
- robuste
- Rôle
- RANGÉE
- Courir
- pour le running
- fonctionne
- s
- même
- évolutive
- Escaliers intérieurs
- Balance
- mise à l'échelle
- calendrier
- scénario
- scripts
- Section
- en toute sécurité
- sécurité
- sur le lien
- vu
- Sélectionner
- séparé
- serveur
- Sans serveur
- service
- Services
- Session
- set
- mise
- devrait
- montrer
- Spectacles
- étapes
- simplifier
- So
- Football
- sur mesure
- Solutions
- Identifier
- Spark
- spécialise
- Hébergement spécial
- spécifié
- SQL
- étapes
- Standard
- Région
- statistiques
- Statut
- Étapes
- Arrêter
- arrêté
- storage
- Boutique
- stockée
- rationaliser
- Chaîne
- studio
- Soumission
- soumettre
- sous-réseaux
- tel
- RÉSUMÉ
- Appuyer
- table
- Prenez
- Tâche
- tâches
- Technique
- temporaire
- Essais
- qui
- Le
- leur
- Les
- puis
- Ces
- this
- trois
- fiable
- fois
- à
- aujourd'hui
- Transformer
- De La Carrosserie
- transformé
- déclencher
- voyage
- TOUR
- deux
- types
- ui
- sous
- comprendre
- contrairement à
- Mises à jour
- a actualisé
- us
- utilisé
- utilisateurs
- Usages
- en utilisant
- utilise
- VALIDER
- validation
- version
- via
- Voir
- vues
- le volume
- volumes
- souhaitez
- était
- façons
- we
- web
- services Web
- bienvenu
- ont été
- quand
- qui
- sera
- comprenant
- sans
- activités principales
- workflow
- workflows
- s'inquiéter
- inquiétant
- écrire
- jaune
- you
- Votre
- zéphyrnet
- zones