
20 septembre 2023
Modèles fondamentaux (FM) marquent le début d’une nouvelle ère dans apprentissage automatique (ML) ainsi que intelligence artificielle (IA), ce qui conduit à un développement plus rapide de l’IA qui peut être adaptée à un large éventail de tâches en aval et affinée pour un éventail d’applications.
Avec l'importance croissante du traitement des données là où le travail est effectué, la diffusion de modèles d'IA à la périphérie de l'entreprise permet des prédictions en temps quasi réel, tout en respectant les exigences de souveraineté et de confidentialité des données. En combinant les IBM Watsonx Grâce aux capacités de plate-forme de données et d'IA pour les FM avec Edge Computing, les entreprises peuvent exécuter des charges de travail d'IA pour le réglage fin et l'inférence FM à la périphérie opérationnelle. Cela permet aux entreprises de faire évoluer les déploiements d'IA à la périphérie, réduisant ainsi le temps et les coûts de déploiement avec des temps de réponse plus rapides.
Assurez-vous de consulter tous les articles de cette série d'articles de blog sur l'informatique de pointe :
Que sont les modèles fondateurs ?
Les modèles fondamentaux (FM), formés à grande échelle sur un large ensemble de données non étiquetées, sont à l'origine d'applications d'intelligence artificielle (IA) de pointe. Ils peuvent être adaptés à un large éventail de tâches en aval et optimisés pour un large éventail d'applications. Les modèles d’IA modernes, qui exécutent des tâches spécifiques dans un domaine unique, cèdent la place aux FM car ils apprennent de manière plus générale et travaillent sur plusieurs domaines et problèmes. Comme son nom l’indique, un FM peut constituer la base de nombreuses applications du modèle d’IA.
Les FM répondent à deux défis clés qui ont empêché les entreprises d’adopter à grande échelle l’IA. Premièrement, les entreprises produisent une grande quantité de données non étiquetées, dont seule une fraction est étiquetée pour la formation de modèles d’IA. Deuxièmement, cette tâche d'étiquetage et d'annotation est extrêmement gourmande en ressources humaines, nécessitant souvent plusieurs centaines d'heures de la part d'un expert en la matière (SME). Cela rend l'évolution à travers les cas d'utilisation d'un coût prohibitif, car cela nécessiterait des armées de PME et d'experts en données. En ingérant de grandes quantités de données non étiquetées et en utilisant des techniques auto-supervisées pour la formation des modèles, les FM ont supprimé ces goulots d'étranglement et ouvert la voie à une adoption à grande échelle de l'IA dans l'entreprise. Ces quantités massives de données qui existent dans chaque entreprise attendent d'être exploitées pour générer des informations.
Que sont les grands modèles de langage ?
Les grands modèles de langage (LLM) sont une classe de modèles fondamentaux (FM) constitués de couches de les réseaux de neurones qui ont été formés sur ces quantités massives de données non étiquetées. Ils utilisent des algorithmes d'apprentissage auto-supervisés pour effectuer diverses tâches. traitement du langage naturel (PNL) tâches d’une manière similaire à la façon dont les humains utilisent le langage (voir Figure 1).
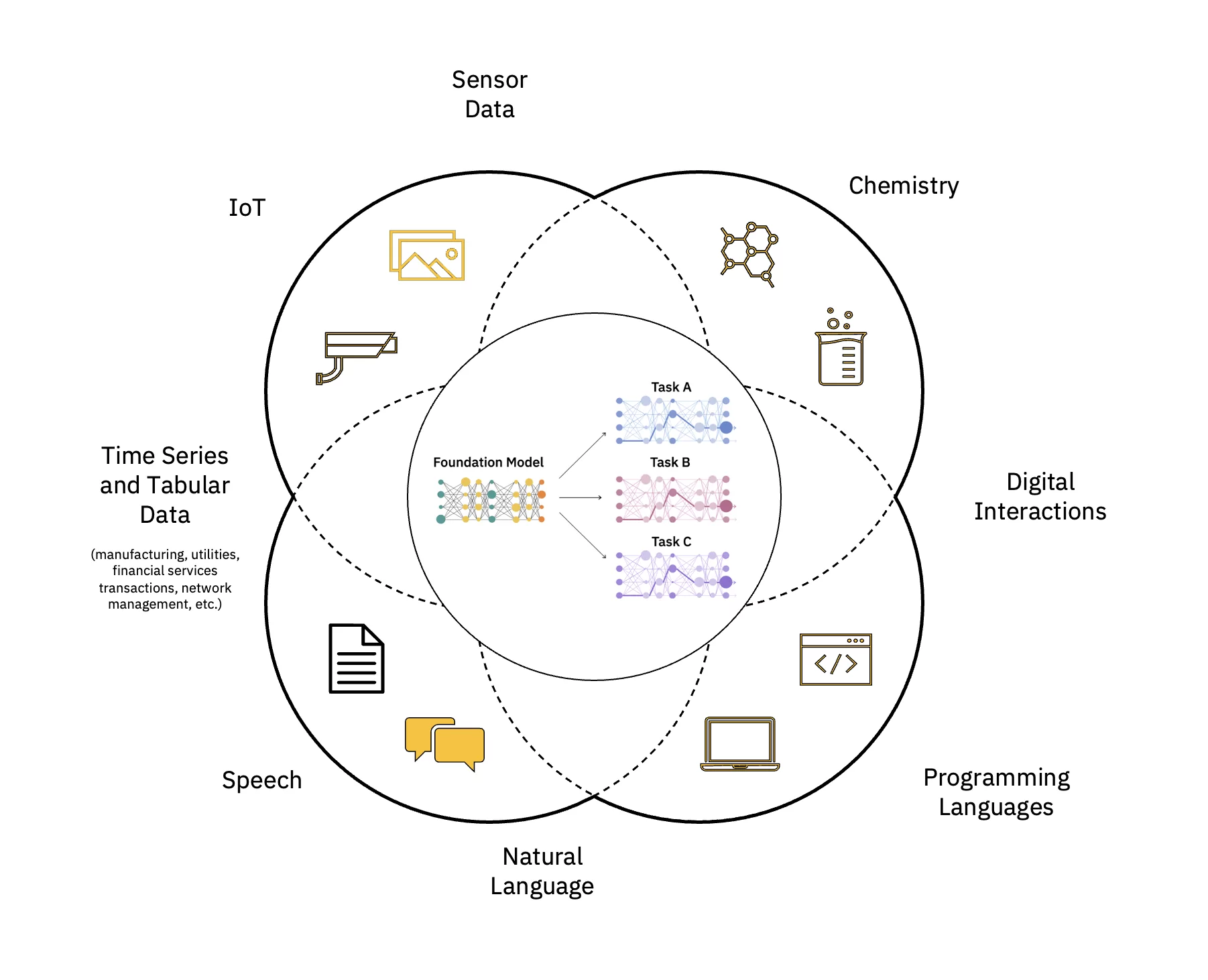
Faites évoluer et accélérez l’impact de l’IA
La création et le déploiement d'un modèle fondamental (FM) comportent plusieurs étapes. Ceux-ci incluent l'ingestion de données, la sélection de données, le prétraitement des données, la pré-formation FM, le réglage du modèle sur une ou plusieurs tâches en aval, la diffusion d'inférences, ainsi que la gouvernance et la gestion du cycle de vie des modèles de données et d'IA, qui peuvent tous être décrits comme FMOps.
Pour vous aider dans tout cela, IBM propose aux entreprises les outils et capacités nécessaires pour exploiter la puissance de ces FM via IBM Watsonx, une plateforme d'IA et de données conçue pour multiplier l'impact de l'IA au sein d'une entreprise. IBM Watsonx se compose des éléments suivants :
- IBM Watsonx.ai apporte du nouveau IA générative capacités, optimisées par les FM et l'apprentissage automatique (ML) traditionnel, dans un studio puissant couvrant le cycle de vie de l'IA.
- IBM Watsonx.data est un magasin de données adapté à vos besoins, construit sur une architecture Lakehouse ouverte pour faire évoluer les charges de travail d'IA pour toutes vos données, n'importe où.
- IBM Watsonx.gouvernance est une boîte à outils automatisée de bout en bout pour la gouvernance du cycle de vie de l'IA, conçue pour permettre des flux de travail d'IA responsables, transparents et explicables.
Un autre vecteur clé est l'importance croissante de l'informatique à la périphérie de l'entreprise, comme les sites industriels, les ateliers de fabrication, les magasins de détail, les sites de télécommunications, etc. Plus précisément, l'IA à la périphérie de l'entreprise permet le traitement des données là où le travail est effectué pour analyse en temps quasi réel. La périphérie de l’entreprise est l’endroit où de grandes quantités de données d’entreprise sont générées et où l’IA peut fournir des informations commerciales précieuses, opportunes et exploitables.
La diffusion de modèles d'IA à la périphérie permet des prédictions en temps quasi réel tout en respectant les exigences de souveraineté et de confidentialité des données. Cela réduit considérablement la latence souvent associée à l’acquisition, la transmission, la transformation et le traitement des données d’inspection. Travailler à la périphérie nous permet de protéger les données sensibles de l'entreprise et de réduire les coûts de transfert de données avec des temps de réponse plus rapides.
Cependant, faire évoluer les déploiements d’IA à la périphérie n’est pas une tâche facile face aux défis liés aux données (hétérogénéité, volume et réglementation) et aux ressources limitées (calcul, connectivité réseau, stockage et même compétences informatiques). Ceux-ci peuvent globalement être décrits en deux catégories :
- Temps/coût de déploiement : Chaque déploiement se compose de plusieurs couches de matériel et de logiciels qui doivent être installés, configurés et testés avant le déploiement. Aujourd'hui, l'installation peut prendre jusqu'à une semaine ou deux à un professionnel du service. à chaque emplacement, ce qui limite considérablement la rapidité et la rentabilité avec lesquelles les entreprises peuvent étendre leurs déploiements au sein de leur organisation.
- Gestion du jour 2 : Le grand nombre de périphéries déployées et l'emplacement géographique de chaque déploiement peuvent souvent rendre prohibitif la fourniture d'un support informatique local sur chaque site pour surveiller, maintenir et mettre à jour ces déploiements.
Déploiements Edge AI
IBM a développé une architecture de périphérie qui répond à ces défis en apportant un modèle d'appliance matériel/logiciel (HW/SW) intégré aux déploiements d'IA de périphérie. Il se compose de plusieurs paradigmes clés qui facilitent l’évolutivité des déploiements d’IA :
- Approvisionnement sans intervention, basé sur des règles, de la pile logicielle complète.
- Surveillance continue de la santé du système Edge
- Capacités de gestion et de transmission des mises à jour de logiciels/sécurité/configuration vers de nombreux emplacements périphériques, le tout à partir d'un emplacement central basé sur le cloud pour une gestion dès le deuxième jour.
Une architecture distribuée en étoile peut être utilisée pour faire évoluer les déploiements d'IA d'entreprise à la périphérie, dans lesquels un cloud central ou un centre de données d'entreprise agit comme un hub et l'appliance Edge-in-a-box agit comme un rayon à un emplacement périphérique.. Ce modèle en étoile, qui s'étend aux environnements de cloud hybride et de périphérie, illustre le mieux l'équilibre nécessaire pour utiliser de manière optimale les ressources nécessaires aux opérations FM (voir Figure 2).
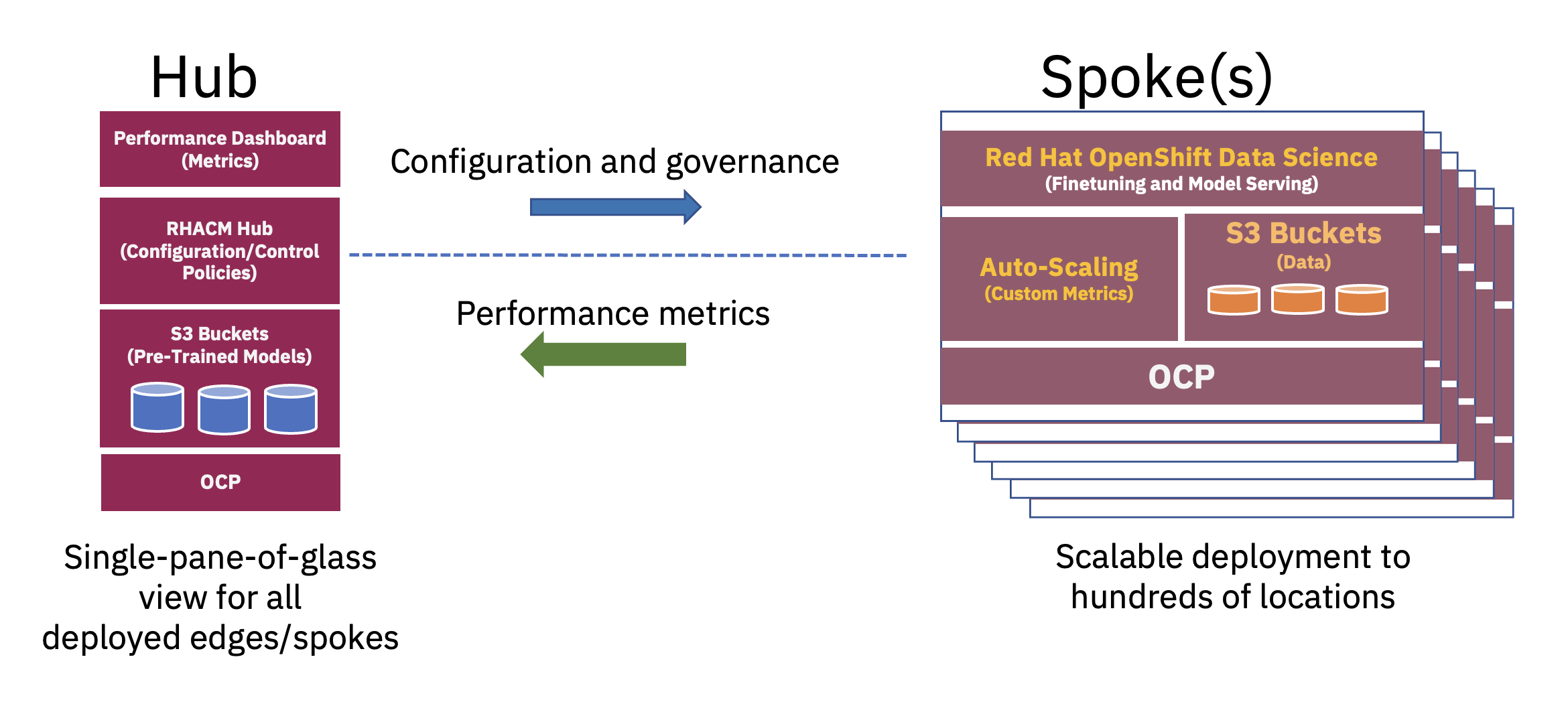
La pré-formation de ces grands modèles linguistiques de base (LLM) et d'autres types de modèles de base à l'aide de techniques auto-supervisées sur de vastes ensembles de données non étiquetés nécessite souvent des ressources de calcul (GPU) importantes et est mieux effectuée dans un hub. Les ressources de calcul pratiquement illimitées et les grandes piles de données souvent stockées dans le cloud permettent un pré-entraînement de modèles à grands paramètres et une amélioration continue de la précision de ces modèles de base.
D'un autre côté, le réglage de ces FM de base pour les tâches en aval, qui ne nécessitent que quelques dizaines ou centaines d'échantillons de données étiquetées et la diffusion d'inférences, peut être réalisé avec seulement quelques GPU à la périphérie de l'entreprise. Cela permet aux données sensibles étiquetées (ou données précieuses de l'entreprise) de rester en toute sécurité dans l'environnement opérationnel de l'entreprise tout en réduisant les coûts de transfert de données.
En utilisant une approche full-stack pour déployer des applications en périphérie, un data scientist peut affiner, tester et déployer les modèles. Cela peut être accompli dans un environnement unique tout en réduisant le cycle de vie de développement pour proposer de nouveaux modèles d'IA aux utilisateurs finaux. Des plates-formes telles que Red Hat OpenShift Data Science (RHODS) et Red Hat OpenShift AI récemment annoncées fournissent des outils permettant de développer et de déployer rapidement des modèles d'IA prêts pour la production dans nuage distribué et les environnements périphériques.
Enfin, le fait de proposer le modèle d’IA affiné à la périphérie de l’entreprise réduit considérablement la latence souvent associée à l’acquisition, à la transmission, à la transformation et au traitement des données. Le découplage de la pré-formation dans le cloud du réglage fin et de l'inférence en périphérie réduit le coût opérationnel global en réduisant le temps requis et les coûts de déplacement des données associés à toute tâche d'inférence (voir Figure 3).
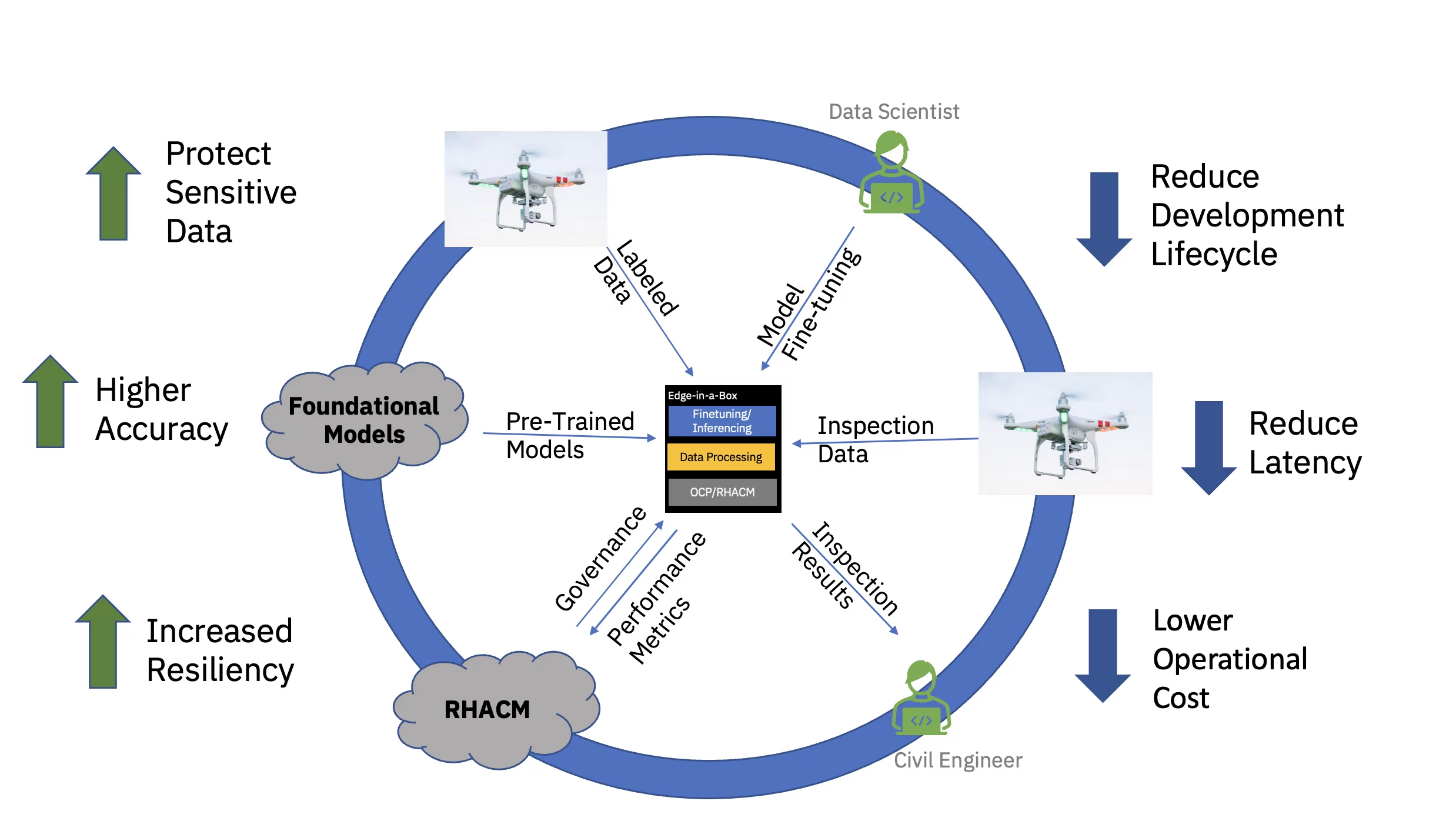
Pour démontrer cette proposition de valeur de bout en bout, un modèle de base exemplaire basé sur un transformateur de vision pour les infrastructures civiles (pré-entraîné à l'aide d'ensembles de données publics et personnalisés spécifiques à l'industrie) a été affiné et déployé pour l'inférence sur une périphérie à trois nœuds. (à rayons) cluster. La pile logicielle comprenait Red Hat OpenShift Container Platform et Red Hat OpenShift Data Science. Ce cluster périphérique était également connecté à une instance du hub Red Hat Advanced Cluster Management for Kubernetes (RHACM) exécuté dans le cloud.
Provisionnement sans intervention
Un provisionnement sans intervention basé sur des politiques a été réalisé avec Red Hat Advanced Cluster Management for Kubernetes (RHACM) via des politiques et des balises de placement, qui lient des clusters Edge spécifiques à un ensemble de composants logiciels et de configurations. Ces composants logiciels, s'étendant sur l'ensemble de la pile et couvrant le calcul, le stockage, le réseau et la charge de travail de l'IA, ont été installés à l'aide de divers opérateurs OpenShift, de la fourniture des services d'application requis et du compartiment S3 (stockage).
Le modèle fondamental (FM) pré-entraîné pour les infrastructures civiles a été affiné via un Jupyter Notebook dans Red Hat OpenShift Data Science (RHODS) à l'aide de données étiquetées pour classer six types de défauts trouvés sur les ponts en béton. Le service d'inférence de ce FM affiné a également été démontré à l'aide d'un serveur Triton. De plus, la surveillance de la santé de ce système de périphérie a été rendue possible en regroupant les métriques d'observabilité des composants matériels et logiciels via Prometheus vers le tableau de bord central RHACM dans le cloud. Les entreprises d'infrastructures civiles peuvent déployer ces FM sur leurs sites périphériques et utiliser l'imagerie de drone pour détecter les défauts en temps quasi réel, accélérant ainsi le délai d'obtention d'informations et réduisant le coût du déplacement de grands volumes de données haute définition vers et depuis le Cloud.
Résumé
La combinaison IBM Watsonx Les capacités de la plate-forme de données et d'IA pour les modèles de base (FM) avec une appliance Edge-in-a-box permettent aux entreprises d'exécuter des charges de travail d'IA pour le réglage fin et l'inférence FM à la périphérie opérationnelle. Cette appliance peut gérer des cas d'utilisation complexes dès le départ et construit le cadre en étoile pour la gestion centralisée, l'automatisation et le libre-service. Les déploiements Edge FM peuvent être réduits de quelques semaines à quelques heures avec un succès reproductible, une résilience et une sécurité accrues.
En savoir plus sur les modèles fondamentaux
Assurez-vous de consulter tous les articles de cette série d'articles de blog sur l'informatique de pointe :
Plus de Cloud




- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :possède
- :est
- :ne pas
- :où
- $UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- A Propos
- accélérer
- accès
- accompli
- précision
- acquisition
- à travers
- actes
- adapté
- En outre
- propos
- adresses
- Adoption
- Avancée
- progrès
- Numérique
- AI
- Adoption de l'IA
- Modèles AI
- Plateforme IA
- Aide
- algorithmes
- Tous
- permettre
- permet
- aussi
- Au milieu de
- montant
- quantités
- amp
- an
- selon une analyse de l’Université de Princeton
- analytique
- ainsi que
- annoncé
- tous
- de n'importe où
- Application
- applications
- une approche
- architecture
- SONT
- tableau
- article
- artificiel
- intelligence artificielle
- Intelligence artificielle (AI)
- AS
- associé
- At
- auteur
- Automatisation
- Automation
- disponibles
- avenue
- RETOUR
- Balance
- Banque
- Banks
- base
- BE
- car
- devenez
- devenir
- était
- Début
- va
- CROYONS
- LES MEILLEURS
- lier
- Blog
- Blogue
- blogue
- tous les deux
- Box
- ponts
- Apporter
- Apportez le
- vaste
- largement
- Développement
- construit
- construit
- la performance des entreprises
- by
- CAN
- capacités
- capital
- Capturer
- carbone
- carte
- Cartes
- cas
- CHAT
- catégories
- Causes
- Canaux centraux
- central
- Banque centrale
- monnaies numériques de la banque centrale
- centralisée
- chaîne
- globaux
- Change
- en changeant
- vérifier
- choix
- cercles
- CIS
- civil
- classe
- Classer
- clair
- CLIENTS
- étroitement
- le cloud
- Grappe
- Couleur
- coloré
- combinant
- compétitif
- complexe
- complexité
- conformité
- composants électriques
- calcul
- informatique
- configuration
- configurée
- connecté
- Connectivité
- consiste
- Contenant
- continuer
- des bactéries
- Prix
- Costs
- pourriez
- couvrant
- crypto-monnaie
- CSS
- devises
- Customiser
- des clients
- expérience client
- Clients
- tableau de bord
- données
- Centre de données
- Plateforme de données
- science des données
- Data Scientist
- ensembles de données
- Date
- dévoué
- Réglage par défaut
- définitions
- livrer
- démontrer
- démontré
- déployer
- déployé
- déployer
- déploiement
- déploiements
- décrit
- la description
- un
- développer
- développé
- Développement
- numérique
- devises numériques
- numérisation
- Perturbation
- perturbateur
- Disrupteurs
- distribué
- quartier
- domaine
- domaines
- fait
- motivation
- conduite
- drone
- chacun
- Easy
- risque numérique
- Edge
- informatique de pointe
- LE NIVEAU SUPÉRIEUR
- élevée
- permettre
- permet
- fin
- end-to-end
- ingénieur
- ENGINEERING
- Entrer
- Entreprise
- entreprises
- les participants
- Environment
- environnements
- Ère
- notamment
- etc
- Ether (ETH)
- Pourtant, la
- événements
- Chaque
- évolué
- Examiner
- exemples
- exécuter
- exister
- Sortie
- cher
- d'experience
- de santé
- IA explicable
- expliquant
- extension
- extrêmement
- facteurs
- RAPIDE
- plus rapide
- few
- champ
- Figure
- la traduction de documents financiers
- Institutions financières
- financement
- Prénom
- étages
- suivre
- Abonnement
- polices
- Pour
- Premier plan
- trouvé
- Fondation
- fraction
- Framework
- De
- plein
- Un paquet entier
- En outre
- généralement
- généré
- générateur
- géographique
- Géopolitique
- Don
- Global
- commerce international
- gouvernance
- GPU
- GPU
- Grille
- main
- manipuler
- Matériel
- chapeau
- Vous avez
- Santé
- la taille
- vous aider
- aider
- aide
- haute définition
- augmentation
- très
- Histoire
- hôte
- HEURES
- Comment
- How To
- Cependant
- HTTPS
- Moyeu
- Les êtres humains
- Des centaines
- Hybride
- nuage hybride
- IBM
- IBM Cloud
- ICO
- ICON
- illustre
- image
- Impact
- importance
- amélioration
- in
- comprendre
- inclus
- croissant
- de plus en plus
- indice
- industriel
- secteurs
- industrie
- spécifique à l'industrie
- inflation
- inflexion
- Point d'inflexion
- influencé
- Infrastructure
- initiative
- Innovation
- technologie innovante
- entrées
- idées.
- instance
- les établissements privés
- des services
- Intelligence
- intrinsèque
- Découvrez le tout nouveau
- IT
- IT Support
- Voyages
- jpg
- saut
- Jupyter Notebook
- juste
- juste un
- conservé
- ACTIVITES
- Kubernetes
- l'étiquetage
- langue
- gros
- principalement
- Latence
- Nouveautés
- poules pondeuses
- conduisant
- APPRENTISSAGE
- apprentissage
- Levier
- vos produits
- comme
- illimité
- linux
- locales
- local
- emplacement
- emplacements
- Location
- Style
- click
- machine learning
- LES PLANTES
- maintenir
- a prendre une
- FAIT DU
- gérer
- gestion
- fabrication
- de nombreuses
- des
- massif
- maître
- Matière
- largeur maximale
- mécanismes
- méthodes
- Métrique
- m.
- réduisant au minimum
- minutes
- ML
- Breeze Mobile
- modèle
- numériques jumeaux (digital twin models)
- Villas Modernes
- modernisation
- moderniser
- Surveiller
- Stack monitoring
- PLUS
- mouvement
- en mouvement
- prénom
- Navigation
- Près
- nécessaire
- Besoin
- nécessaire
- Besoins
- réseau et
- Nouveauté
- next
- nlp
- cahier
- rien
- maintenant
- nombre
- nombreux
- of
- offrant
- souvent
- on
- ONE
- uniquement
- ouvert
- ouvert
- opérationnel
- Opérations
- opérateurs
- optimisé
- or
- organisation
- Autre
- nos
- ande
- global
- Forfaits
- page
- paramètre
- Paiement
- Moyens de paiement
- Paiements
- effectuer
- effectué
- PHP
- placement
- plateforme
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- plug-in
- Point
- politiques
- politique
- position
- possible
- Post
- Poteaux
- défaillances
- power
- solide
- Prédictions
- Avant
- la confidentialité
- Privé
- d'ouvrabilité
- traitement
- produire
- professionels
- proposition
- fournir
- public
- Push
- gamme
- rapidement
- en cours
- en temps réel
- récemment
- record
- l'enregistrement
- Rouge
- Red Hat
- réduire
- Prix Réduit
- réduit
- réduire
- règlements
- Régulateurs
- régulateurs
- en relation
- Supprimé
- répétable
- exigent
- conditions
- Exigences
- requis
- un article
- Resources
- réponse
- responsables
- sensible
- détail
- Augmenter
- Collaboratif
- Courir
- pour le running
- en toute sécurité
- même
- Évolutivité
- Escaliers intérieurs
- échelle ai
- mise à l'échelle
- Sciences
- Scientifique
- pour écran
- scripts
- Deuxièmement
- en toute sécurité
- sécurité
- sur le lien
- voir
- sélection
- En libre service
- sensible
- seo
- Septembre
- Série
- serveur
- service
- Services
- service
- Session
- brainstorming
- set
- plusieurs
- Partager
- montrer
- significative
- de façon significative
- similaires
- depuis
- Singapour
- unique
- environnement unique
- site
- Sites
- SIX
- compétences
- petit
- PME
- PME
- Logiciels
- composants logiciels
- sur mesure
- souveraineté
- Space
- enjambant
- groupe de neurones
- spécifiquement
- Sponsorisé
- empiler
- Commencer
- state-of-the-art
- rester
- Étapes
- storage
- Boutique
- stockée
- STORES
- tempête
- studio
- sujet
- succès
- tel
- Suggère
- la quantité
- chaîne d'approvisionnement
- Support
- sûr
- combustion propre
- Prenez
- tâches
- Tâche
- tâches
- techniques
- Technologie
- Telco
- Temenos
- dizaines
- Terraform
- examiné
- Essais
- qui
- La
- leur
- thème
- Là.
- Ces
- l'ont
- this
- Avec
- fiable
- opportun
- fois
- Titre
- à
- aujourd'hui
- ensemble
- Boîte à outils
- les outils
- top
- commerce
- traditionnel
- Train
- qualifié
- Formation
- transférer
- Transformer
- De La Carrosserie
- transformations
- communication
- Triton
- deux
- type
- types
- déchaîné
- Mises à jour
- Actualités
- URL
- us
- utilisé
- d'utiliser
- utilisateurs
- en utilisant
- utiliser
- utilisé
- Précieux
- Plus-value
- proposition de valeur
- variété
- divers
- Vaste
- via
- Voir
- pratiquement
- le volume
- volumes
- W
- Attendre
- Wallet
- était
- Vague
- Façon..
- façons
- we
- semaine
- Semaines
- Quoi
- Qu’est ce qu'
- quand
- qui
- tout en
- WHO
- why
- large
- Large gamme
- comprenant
- dans les
- femme
- Outils de gestion
- activités principales
- workflows
- de travail
- pourra
- code écrit
- Votre
- zéphyrnet











