Synopsys a récemment organisé un panel intersectoriel sur l'état des systèmes multi-puces que j'ai trouvé intéressant notamment pour sa pertinence par rapport à l'accélération rapide du matériel centré sur l'IA. Plus d’informations à ce sujet ci-dessous. Les panélistes, tous occupant des rôles importants dans les systèmes multi-puces, étaient Shekhar Kapoor (directeur principal de la gestion des produits, Synopsys), Cheolmin Park (vice-président de l'entreprise, Samsung), Lalitha Immaneni (vice-présidente de l'architecture, de la conception et des solutions technologiques, Intel), Michael Schaffert. (vice-président senior, Bosch) et Murat Becer (vice-président R&D, Ansys). Le panel était modéré par Marco Chiappetta (co-fondateur et analyste principal, HotTech Vision and Analysis).

Un moteur de grande demande
Il est courant de déployer sous cette rubrique tous les suspects habituels (HPC, automobile, etc.), mais cette liste vend à découvert peut-être le facteur sous-jacent le plus important : la ruée actuelle pour la domination dans tout ce qui concerne le LLM et l'IA générative. Les grands modèles linguistiques offrent de nouveaux niveaux de services SaaS en matière de recherche, de création de documents et d'autres capacités, avec des avantages concurrentiels majeurs pour celui qui réussit en premier. Sur les appareils mobiles et dans la voiture, un contrôle et un feedback supérieurs basés sur le langage naturel donneront aux options vocales existantes un aspect primitif en comparaison. Parallèlement, les méthodes génératives de création de nouvelles images utilisant les modèles de flux de diffusion et de Poisson peuvent produire des graphiques spectaculaires s'appuyant sur du texte ou une photographie complétés par des bibliothèques d'images. En tant que consommateur, cela pourrait s'avérer être la prochaine grande nouveauté pour les futures versions de téléphones.
Bien que l’IA basée sur les transformateurs présente une énorme opportunité, elle comporte également des défis. Les technologies qui rendent de telles méthodes possibles ont déjà fait leurs preuves dans le cloud et émergent à la périphérie, mais elles sont notoirement gourmandes en mémoire. Les LLM de production fonctionnent entre des milliards, voire des milliards de paramètres qui doivent être chargés dans le transformateur. La demande d'espace de travail en cours de processus est tout aussi élevée ; L'imagerie basée sur la diffusion ajoute progressivement du bruit à une image complète, puis revient à une image modifiée, toujours via des plates-formes basées sur des transformateurs.
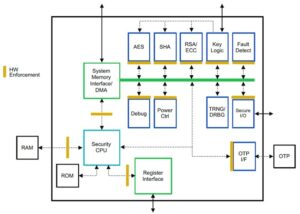
Hormis une charge initiale, aucun de ces processus ne peut supporter la surcharge liée à l’interaction avec la DRAM externe. Les latences seraient inacceptables et la demande d’énergie épuiserait la batterie d’un téléphone ou ferait exploser le budget énergétique d’un centre de données. Toute la mémoire doit être proche – très proche – du calcul. Une solution consiste à empiler la SRAM au-dessus de l'accélérateur (comme AMD et maintenant Intel l'ont démontré pour leurs puces de serveur). La mémoire à large bande passante intégrée au package ajoute une autre option un peu plus lente, mais toujours pas aussi lente que la DRAM hors puce.
Tout cela nécessite des systèmes multi-matrices. Alors, où en sommes-nous pour préparer cette option à la production ?
Opinions sur où nous en sommes
J'ai entendu beaucoup d'enthousiasme pour la croissance dans ce domaine, en termes d'adoption, d'applications et d'outils. Intel, AMD, Qualcomm, Samsung sont tous clairement très actifs dans ce domaine. Apple M2 Ultra est connu pour être une conception à double puce et AWS Graviton 3 est un système multi-matrices. Je suis sûr qu'il existe de nombreux autres exemples parmi les grands fabricants de systèmes et de semi-conducteurs. J'ai l'impression que les matrices proviennent toujours principalement de sources internes (sauf peut-être pour les piles HBM) et assemblées dans les technologies d'emballage en fonderie de TSMC, Samsung ou Intel. Cependant, Tenstorrent vient d'annoncer qu'il a choisi Samsung pour fabriquer sa conception d'IA de nouvelle génération sous forme de chiplet (une puce pouvant être utilisée dans un système multi-matrices), donc cet espace s'oriente déjà vers un approvisionnement plus large en puces.
Tous les panélistes étaient naturellement enthousiasmés par l'orientation générale, et il est clair que les technologies et les outils évoluent rapidement, ce qui explique ce buzz. Lalitha a fondé cet enthousiasme en soulignant que la manière dont les systèmes multi-puces actuellement architecturés et conçus en est encore à ses balbutiements, et qu'elle n'est pas encore prête à lancer un vaste marché réutilisable pour les puces. Cela ne me surprend pas. Une technologie d’une telle complexité semble devoir mûrir d’abord dans le cadre de partenariats étroits entre les concepteurs de systèmes, les fonderies et les sociétés d’EDA, peut-être sur plusieurs années avant de pouvoir s’étendre à un public plus large.
Je suis sûr que les fonderies, les constructeurs de systèmes et les sociétés d'EDA ne montrent pas toutes leurs cartes et sont peut-être plus avancés que ce qu'ils choisissent de prétendre. J'ai hâte d'en savoir plus. Vous pouvez regarder la table ronde ICI.
Partagez cet article via:
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://semiwiki.com/artificial-intelligence/336319-synopsys-panel-updates-on-the-state-of-multi-die-systems/
- :est
- :ne pas
- :où
- 180
- 300
- a
- A Propos
- accélération
- accélérateur
- hybrides
- infection
- Ajoute
- Adoption
- avantages
- La publicité
- encore
- AI
- Tous
- le long de
- déjà
- am
- AMD
- parmi
- an
- selon une analyse de l’Université de Princeton
- analyste
- ainsi que le
- annoncé
- Une autre
- de n'importe où
- Apple
- applications
- architecture
- SONT
- AS
- assemblé
- At
- public
- l'automobile
- AWS
- RETOUR
- Bande passante
- batterie
- BE
- before
- va
- ci-dessous
- jusqu'à XNUMX fois
- Big
- Le plus grand
- milliards
- faire sauter
- Bosch
- plus large
- budget
- constructeurs
- mais
- by
- CAN
- capacités
- fournisseur
- Cartes
- globaux
- chips
- Selectionnez
- choisi
- clairement
- le cloud
- Co-fondateur
- vient
- Commun
- Sociétés
- Comparaison
- compétitif
- complexité
- calcul
- consommateur
- des bactéries
- Entreprises
- pourriez
- La création
- création
- Courant
- Lecture
- Datacenter
- Demande
- démontré
- Conception
- un
- designers
- Compatibles
- J'ai noté la
- La diffusion
- direction
- Directeur
- spirituelle
- document
- Ne fait pas
- domaine
- Dominance
- vidanger
- dessiner
- dessin
- Edge
- économies émergentes.
- à leurs besoins.
- enthousiaste
- également
- etc
- peut
- évolution
- exemples
- Sauf
- existant
- étendre
- les
- externe
- facteur
- fameusement
- RAPIDE
- Réactions
- Prénom
- flux
- Pour
- Avant
- trouvé
- Fonderie
- De
- plein
- plus
- avenir
- Général
- génération
- génératif
- IA générative
- obtenez
- graphique
- Croissance
- Matériel
- Vous avez
- Titre
- entendu
- entendre
- Haute
- organisé
- maisons
- Cependant
- hpc
- HTML
- HTTPS
- majeur
- Avide
- i
- image
- satellite
- Imagerie
- in
- initiale
- Intel
- interagissant
- intéressant
- intérieurement
- IT
- SES
- jpg
- juste
- Kapoor
- connu
- langue
- gros
- plus importantes
- lancer
- au
- niveaux
- bibliothèques
- lumière
- comme
- Liste
- charge
- Style
- Lot
- M2
- majeur
- a prendre une
- Fabrication
- gestion
- Marco
- Marché
- mature
- largeur maximale
- Mai..
- peut être
- me
- En attendant
- Mémoire
- méthodes
- Michael
- Breeze Mobile
- appareils mobiles
- numériques jumeaux (digital twin models)
- modifié
- PLUS
- multi
- must
- Nature
- Près
- Besoins
- Nouveauté
- next
- Bruit
- Aucun
- notant
- maintenant
- of
- code
- on
- ONE
- Opportunités
- Option
- Options
- or
- Autre
- ande
- plus de
- l'emballage
- panneau
- panel de discussion
- paramètres
- Parc
- partenariats
- être
- Téléphone
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Beaucoup
- possible
- Post
- power
- principalement
- cadeaux
- primitif
- Directeur
- les process
- Produit
- gestion des produits
- Vidéo
- progressivement
- Prouver
- proven
- pompe
- Qualcomm
- R & D
- Nos tests de diagnostic produisent des résultats rapides et précis sans nécessiter d'équipement de laboratoire complexe et coûteux,
- solutions
- récemment
- de Presse
- pertinence
- a besoin
- réutilisable
- bon
- rôle
- Roulent
- Courir
- SaaS.
- Samsung
- Rechercher
- semble
- Sells
- semi-conducteur
- supérieur
- serveur
- Services
- plusieurs
- Shorts
- devrait
- montrant
- significative
- lent
- So
- sur mesure
- Solutions
- quelque peu
- source
- Approvisionnement
- Space
- spectaculaire
- empiler
- Combos
- Région
- Encore
- tel
- convient
- haut
- sûr
- surprise
- combustion propre
- Système
- Les technologies
- Technologie
- texte
- que
- qui
- La
- Le Buzz
- L'État
- leur
- puis
- Là.
- Ces
- l'ont
- chose
- this
- Avec
- à
- les outils
- top
- vers
- transformateur
- trillions
- TSMC
- Ultra
- sous
- sous-jacent
- Actualités
- d'utiliser
- en utilisant
- habituel
- très
- via
- vision
- vp
- était
- Montres
- Façon..
- we
- ont été
- qui
- quiconque
- sera
- comprenant
- vos contrats
- pourra
- années
- encore
- you
- zéphyrnet