
À mesure que l'IA migre du cloud vers l'Edge, nous constatons que la technologie est utilisée dans une variété toujours croissante de cas d'utilisation, allant de la détection d'anomalies à des applications telles que les achats intelligents, la surveillance, la robotique et l'automatisation d'usine. Il n’existe donc pas de solution universelle. Mais avec la croissance rapide des appareils compatibles avec les caméras, l'IA a été plus largement adoptée pour analyser les données vidéo en temps réel afin d'automatiser la surveillance vidéo afin d'améliorer la sécurité, d'améliorer l'efficacité opérationnelle et d'offrir une meilleure expérience client, gagnant ainsi un avantage concurrentiel dans leurs secteurs. . Pour mieux prendre en charge l'analyse vidéo, vous devez comprendre les stratégies d'optimisation des performances du système dans les déploiements d'IA de pointe.
- Sélection des moteurs de calcul de bonne taille pour atteindre ou dépasser les niveaux de performances requis. Pour une application d'IA, ces moteurs de calcul doivent remplir les fonctions de l'ensemble du pipeline de vision (c'est-à-dire pré et post-traitement vidéo, inférence de réseau neuronal).
Un accélérateur d'IA dédié, qu'il soit discret ou intégré à un SoC (par opposition à l'exécution de l'inférence d'IA sur un CPU ou un GPU), peut être nécessaire.
- Comprendre la différence entre débit et latence ; où le débit est la vitesse à laquelle les données peuvent être traitées dans un système et la latence mesure le délai de traitement des données à travers le système et est souvent associée à une réactivité en temps réel. Par exemple, un système peut générer des données d'image à 100 images par seconde (débit), mais il faut 100 ms (latence) pour qu'une image traverse le système.
- Considérant la capacité d'adapter facilement les performances de l'IA à l'avenir pour répondre aux besoins croissants, aux exigences changeantes et aux technologies en évolution (par exemple, des modèles d'IA plus avancés pour une fonctionnalité et une précision accrues). Vous pouvez réaliser une mise à l'échelle des performances à l'aide d'accélérateurs IA au format module ou avec des puces accélératrices IA supplémentaires.
Les exigences de performances réelles dépendent de l'application. En règle générale, on peut s'attendre à ce que pour l'analyse vidéo, le système traite les flux de données provenant des caméras à une vitesse de 30 à 60 images par seconde et avec une résolution de 1080p ou 4k. Une caméra compatible avec l’IA traiterait un seul flux ; une appliance Edge traiterait plusieurs flux en parallèle. Dans les deux cas, le système Edge AI doit prendre en charge les fonctions de prétraitement pour transformer les données du capteur de la caméra dans un format qui correspond aux exigences d'entrée de la section d'inférence IA (Figure 1).
Les fonctions de prétraitement récupèrent les données brutes et effectuent des tâches telles que le redimensionnement, la normalisation et la conversion de l'espace colorimétrique, avant d'introduire les entrées dans le modèle exécuté sur l'accélérateur d'IA. Le prétraitement peut utiliser des bibliothèques de traitement d'image efficaces comme OpenCV pour réduire les temps de prétraitement. Le post-traitement implique l'analyse du résultat de l'inférence. Il utilise des tâches telles que la suppression non maximale (NMS interprète la sortie de la plupart des modèles de détection d'objets) et l'affichage d'images pour générer des informations exploitables, telles que des cadres de délimitation, des étiquettes de classe ou des scores de confiance.

Figure 1. Pour l'inférence de modèle d'IA, les fonctions de pré- et post-traitement sont généralement exécutées sur un processeur d'applications.
L'inférence de modèles d'IA peut présenter le défi supplémentaire de traiter plusieurs modèles de réseaux neuronaux par trame, en fonction des capacités de l'application. Les applications de vision par ordinateur impliquent généralement plusieurs tâches d'IA nécessitant un pipeline de plusieurs modèles. De plus, le résultat d’un modèle est souvent l’entrée du modèle suivant. En d’autres termes, les modèles d’une application dépendent souvent les uns des autres et doivent être exécutés séquentiellement. L’ensemble exact de modèles à exécuter peut ne pas être statique et peut varier de manière dynamique, même image par image.
Le défi de l’exécution dynamique de plusieurs modèles nécessite un accélérateur d’IA externe doté d’une mémoire dédiée et suffisamment grande pour stocker les modèles. Souvent, l'accélérateur d'IA intégré à un SoC est incapable de gérer la charge de travail multimodèle en raison des contraintes imposées par le sous-système de mémoire partagée et d'autres ressources du SoC.
Par exemple, le suivi d'objets basé sur la prédiction de mouvement repose sur des détections continues pour déterminer un vecteur utilisé pour identifier l'objet suivi à une position future. L’efficacité de cette approche est limitée car elle ne dispose pas d’une véritable capacité de réidentification. Avec la prédiction de mouvement, la trace d'un objet peut être perdue en raison de détections manquées, d'occlusions ou de la sortie de l'objet du champ de vision, même momentanément. Une fois perdu, il n'y a aucun moyen de réassocier la trace de l'objet. L'ajout de la réidentification résout cette limitation mais nécessite une intégration de l'apparence visuelle (c'est-à-dire une empreinte digitale d'image). Les intégrations d'apparence nécessitent un deuxième réseau pour générer un vecteur de caractéristiques en traitant l'image contenue à l'intérieur de la boîte englobante de l'objet détecté par le premier réseau. Cette intégration peut être utilisée pour réidentifier l'objet, indépendamment du temps ou de l'espace. Étant donné que des intégrations doivent être générées pour chaque objet détecté dans le champ de vision, les exigences de traitement augmentent à mesure que la scène devient plus occupée. Le suivi d'objets avec réidentification nécessite un examen attentif entre la réalisation d'une détection de haute précision/haute résolution/fréquence d'images élevée et la réservation d'une surcharge suffisante pour l'évolutivité des intégrations. Une façon de résoudre les exigences de traitement consiste à utiliser un accélérateur d’IA dédié. Comme mentionné précédemment, le moteur IA du SoC peut souffrir du manque de ressources de mémoire partagée. L'optimisation du modèle peut également être utilisée pour réduire les exigences de traitement, mais cela pourrait avoir un impact sur les performances et/ou la précision.
Dans une caméra intelligente ou un appareil Edge, le SoC intégré (c'est-à-dire le processeur hôte) acquiert les images vidéo et effectue les étapes de prétraitement décrites précédemment. Ces fonctions peuvent être exécutées avec les cœurs de processeur ou le GPU du SoC (le cas échéant), mais elles peuvent également être exécutées par des accélérateurs matériels dédiés dans le SoC (par exemple, un processeur de signal d'image). Une fois ces étapes de prétraitement terminées, l'accélérateur d'IA intégré au SoC peut alors accéder directement à cette entrée quantifiée à partir de la mémoire système, ou dans le cas d'un accélérateur d'IA discret, l'entrée est ensuite fournie pour inférence, généralement sur le Interface USB ou PCIe.
Un SoC intégré peut contenir une gamme d'unités de calcul, notamment des processeurs, des GPU, un accélérateur d'IA, des processeurs de vision, des encodeurs/décodeurs vidéo, un processeur de signal d'image (ISP), etc. Ces unités de calcul partagent toutes le même bus mémoire et accèdent par conséquent à la même mémoire. De plus, le CPU et le GPU pourraient également devoir jouer un rôle dans l'inférence et ces unités seront occupées à exécuter d'autres tâches dans un système déployé. C'est ce que nous entendons par surcharge au niveau du système (Figure 2).
De nombreux développeurs évaluent à tort les performances de l'accélérateur d'IA intégré au SoC sans prendre en compte l'effet de la surcharge au niveau du système sur les performances totales. À titre d'exemple, envisagez d'exécuter un benchmark YOLO sur un accélérateur d'IA 50 TOPS intégré dans un SoC, qui pourrait obtenir un résultat de benchmark de 100 inférences/seconde (IPS). Mais dans un système déployé avec toutes ses autres unités de calcul actives, ces 50 TOPS pourraient être réduits à quelque chose comme 12 TOPS et les performances globales ne donneraient que 25 IPS, en supposant un facteur d'utilisation généreux de 25 %. La surcharge du système est toujours un facteur si la plate-forme traite en permanence des flux vidéo. Alternativement, avec un accélérateur d'IA discret (par exemple, Kinara Ara-1, Hailo-8, Intel Myriad X), l'utilisation au niveau du système pourrait être supérieure à 90 %, car une fois que le SoC hôte lance la fonction d'inférence et transfère l'entrée du modèle d'IA. données, l'accélérateur fonctionne de manière autonome en utilisant sa mémoire dédiée pour accéder aux poids et paramètres du modèle.
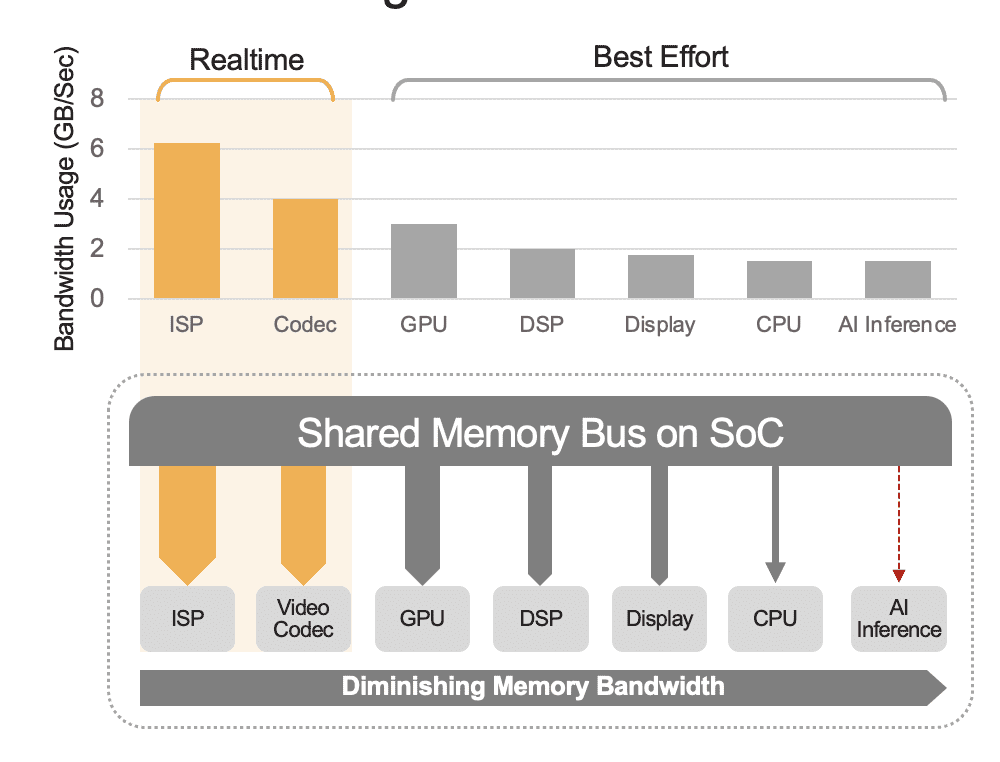
Figure 2. Le bus de mémoire partagée régira les performances au niveau du système, présentées ici avec des valeurs estimées. Les valeurs réelles varient en fonction du modèle d'utilisation de votre application et de la configuration de l'unité de calcul du SoC.
Jusqu'à présent, nous avons discuté des performances de l'IA en termes d'images par seconde et de TOPS. Mais une faible latence est une autre condition importante pour assurer la réactivité en temps réel d'un système. Par exemple, dans le domaine des jeux, une faible latence est essentielle pour une expérience de jeu fluide et réactive, en particulier dans les jeux contrôlés par le mouvement et les systèmes de réalité virtuelle (VR). Dans les systèmes de conduite autonome, une faible latence est essentielle pour la détection d'objets en temps réel, la reconnaissance des piétons, la détection des voies et la reconnaissance des panneaux de signalisation afin d'éviter de compromettre la sécurité. Les systèmes de conduite autonome nécessitent généralement une latence de bout en bout inférieure à 150 ms entre la détection et l'action réelle. De même, dans le secteur manufacturier, une faible latence est essentielle pour la détection des défauts en temps réel, la reconnaissance des anomalies et le guidage robotique qui dépendent d'analyses vidéo à faible latence pour garantir un fonctionnement efficace et minimiser les temps d'arrêt de production.
En général, il existe trois composants de latence dans une application d'analyse vidéo (Figure 3) :
- La latence de capture des données correspond au temps écoulé entre le capteur de la caméra capturant une image vidéo et la disponibilité de l'image pour le système d'analyse pour traitement. Vous pouvez optimiser cette latence en choisissant une caméra dotée d'un capteur rapide et d'un processeur à faible latence, en sélectionnant des fréquences d'images optimales et en utilisant des formats de compression vidéo efficaces.
- La latence du transfert de données est le temps nécessaire aux données vidéo capturées et compressées pour voyager de la caméra vers les appareils périphériques ou les serveurs locaux. Cela inclut les retards de traitement du réseau qui se produisent à chaque point final.
- La latence du traitement des données fait référence au temps nécessaire aux appareils périphériques pour effectuer des tâches de traitement vidéo telles que la décompression d'image et les algorithmes d'analyse (par exemple, suivi d'objets basé sur la prédiction de mouvement, reconnaissance faciale). Comme indiqué précédemment, la latence de traitement est encore plus importante pour les applications qui doivent exécuter plusieurs modèles d'IA pour chaque image vidéo.
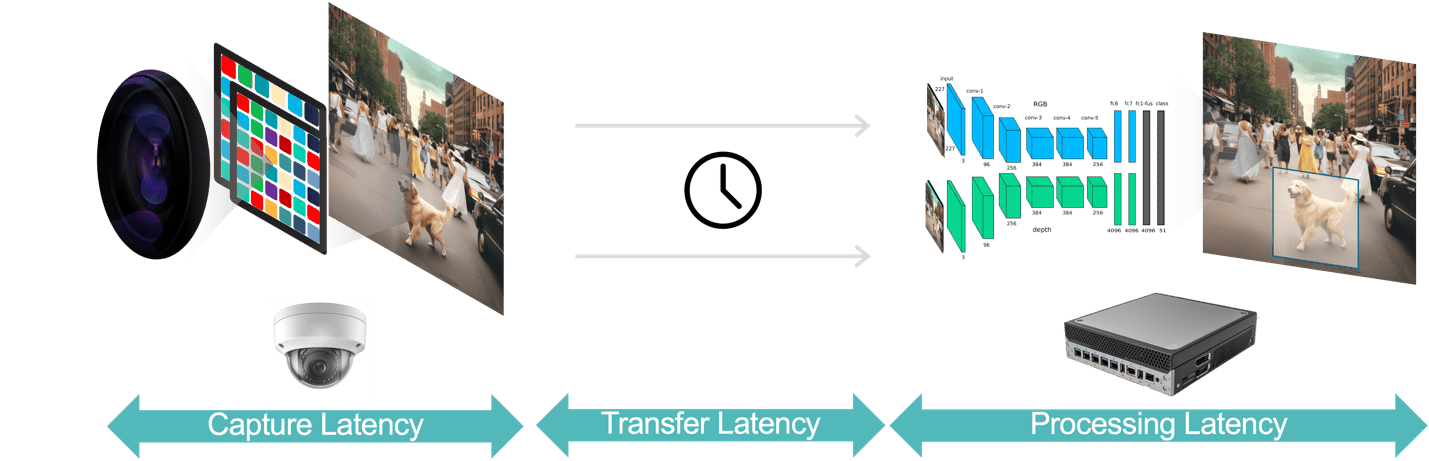
Figure 3. Le pipeline d'analyse vidéo comprend la capture, le transfert et le traitement des données.
La latence du traitement des données peut être optimisée à l'aide d'un accélérateur d'IA doté d'une architecture conçue pour minimiser le mouvement des données à travers la puce et entre le calcul et les différents niveaux de la hiérarchie de la mémoire. De plus, pour améliorer la latence et l'efficacité au niveau du système, l'architecture doit prendre en charge un temps de commutation nul (ou proche de zéro) entre les modèles, afin de mieux prendre en charge les applications multimodèles dont nous avons parlé plus tôt. Un autre facteur d’amélioration des performances et de la latence concerne la flexibilité algorithmique. En d’autres termes, certaines architectures sont conçues pour un comportement optimal uniquement sur des modèles d’IA spécifiques, mais avec l’évolution rapide de l’environnement de l’IA, de nouveaux modèles offrant des performances plus élevées et une meilleure précision apparaissent presque tous les deux jours. Par conséquent, sélectionnez un processeur Edge AI sans restrictions pratiques sur la topologie du modèle, les opérateurs et la taille.
De nombreux facteurs doivent être pris en compte pour optimiser les performances d’une appliance Edge AI, notamment les exigences de performances et de latence et la surcharge du système. Une stratégie réussie doit envisager un accélérateur d'IA externe pour surmonter les limitations de mémoire et de performances du moteur d'IA du SoC.
CH Chee est un responsable accompli du marketing et de la gestion de produits, Chee possède une vaste expérience dans la promotion de produits et de solutions dans l'industrie des semi-conducteurs, en se concentrant sur l'IA basée sur la vision, la connectivité et les interfaces vidéo pour plusieurs marchés, notamment les entreprises et les consommateurs. En tant qu'entrepreneur, Chee a cofondé deux start-ups de semi-conducteurs vidéo qui ont été rachetées par une société publique de semi-conducteurs. Chee a dirigé des équipes de marketing produit et aime travailler avec une petite équipe qui se concentre sur l'obtention d'excellents résultats.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :possède
- :est
- :ne pas
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- capacité
- accélérateur
- accélérateurs
- accès
- accès
- accommoder
- accomplir
- précision
- la réalisation de
- a acquise
- L'acquisition de
- à travers
- Action
- infection
- présenter
- ajoutant
- Supplémentaire
- adopté
- Avancée
- Après
- encore
- AI
- moteur d'IA
- Modèles AI
- algorithmique
- algorithmes
- Tous
- aussi
- toujours
- an
- selon une analyse de l’Université de Princeton
- analytique
- l'analyse
- ainsi que
- Détection d'une anomalie
- Une autre
- Application
- applications
- une approche
- architecture
- SONT
- AS
- associé
- At
- automatiser
- Automation
- autonome
- de manière autonome
- disponibilité
- disponibles
- éviter
- basé
- base
- BE
- car
- devient
- était
- before
- va
- référence
- Améliorée
- jusqu'à XNUMX fois
- tous les deux
- Box
- boîtes
- intégré
- bus
- occupé
- mais
- by
- appareil photo
- de CAMÉRAS de surveillance
- CAN
- capacités
- aptitude
- capturer
- capturé
- Capturer
- prudent
- maisons
- cas
- challenge
- en changeant
- puce
- chips
- choose
- classe
- le cloud
- Couleur
- Venir
- Société
- compétitif
- Complété
- composants électriques
- compromettre
- calcul
- calcul
- calcul
- ordinateur
- Vision par ordinateur
- Applications de vision par ordinateur
- confiance
- configuration
- Connectivité
- par conséquent
- Considérer
- considération
- considéré
- considérant
- consiste
- contraintes
- consommateur
- contiennent
- contenu
- continu
- continuellement
- Conversion
- pourriez
- Processeur
- critique
- des clients
- données
- informatique
- journée
- dévoué
- retarder
- retards
- livrer
- livré
- dépendant
- Selon
- déployé
- déploiements
- décrit
- un
- détecté
- Détection
- Déterminer
- mobiles
- Compatibles
- différence
- directement
- discuté
- Commande
- les temps d'arrêt
- conduite
- deux
- dynamiquement
- e
- chacun
- Plus tôt
- même
- Edge
- effet
- efficacité
- efficacité
- efficace
- efficace
- non plus
- enrobage
- fin
- end-to-end
- Moteur
- Moteurs
- de renforcer
- assurer
- Entreprise
- Tout
- Entrepreneur
- Environment
- essential
- estimé
- évaluer
- Pourtant, la
- Chaque
- évolution
- exemple
- dépassent
- exécuter
- réalisé
- exécutif
- attendre
- d'experience
- Expériences
- les
- Une vaste expérience
- externe
- Visage
- reconnaissance de visage
- facteur
- facteurs
- PERSONNEL
- RAPIDE
- Fonctionnalité
- alimentation
- champ
- Figure
- empreinte digitale
- Prénom
- Flexibilité
- se concentre
- mettant l'accent
- Pour
- le format
- CADRE
- De
- fonction
- fonctions
- En outre
- avenir
- gagner
- Games
- jeux
- expérience de jeu
- Général
- générer
- généré
- généreux
- Go
- GPU
- GPU
- l'
- plus grand
- Croissance
- Croissance
- l'orientation
- Matériel
- Vous avez
- d'où
- ici
- hiérarchie
- Haute
- augmentation
- hôte
- HTTPS
- i
- identifier
- if
- image
- Impact
- important
- imposé
- améliorer
- amélioré
- in
- Dans d'autres
- inclut
- Y compris
- Améliore
- increased
- secteurs
- industrie
- Initie
- contribution
- à l'intérieur
- idées.
- des services
- Intel
- Interfaces
- interfaces
- développement
- impliquer
- implique
- indépendamment
- ISP
- IT
- SES
- KDnuggetsGenericName
- Etiquettes
- Peindre
- Voie
- gros
- Latence
- départ
- LED
- moins
- niveaux
- bibliothèques
- comme
- limitation
- limites
- limité
- locales
- perdu
- Faible
- baisser
- gérer
- gestion
- fabrication
- de nombreuses
- Stratégie
- Marchés
- Maximisez
- maximisant
- Mai..
- signifier
- les mesures
- Découvrez
- Mémoire
- mentionné
- pourrait
- manqué
- modèle
- numériques jumeaux (digital twin models)
- module
- Stack monitoring
- PLUS
- (en fait, presque toutes)
- mouvement
- mouvement
- plusieurs
- must
- myriade
- Près
- Besoins
- réseau et
- Neural
- Réseau neuronal
- Nouveauté
- next
- aucune
- objet
- Détection d'objet
- se produire
- of
- souvent
- on
- une fois
- ONE
- uniquement
- OpenCV
- opération
- opérationnel
- opérateurs
- opposé
- optimaux
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- Optimiser
- optimisé
- l'optimisation
- or
- Autre
- ande
- sortie
- plus de
- global
- Overcome
- Parallèle
- paramètres
- particulièrement
- /
- effectuer
- performant
- effectué
- effectuer
- effectue
- pipeline
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- Point
- position
- post-traitement
- Méthode
- prédiction
- processus
- traité
- traitement
- Processeur
- processeurs
- Produit
- Vidéo
- Produits
- la promotion de
- fournir
- public
- gamme
- allant
- Nos tests de diagnostic produisent des résultats rapides et précis sans nécessiter d'équipement de laboratoire complexe et coûteux,
- rapidement
- Tarif
- Tarifs
- raw
- les données brutes
- réal
- en temps réel
- Réalité
- reconnaissance
- réduire
- se réfère
- exigent
- conditions
- exigence
- Exigences
- a besoin
- Résolution
- Resources
- sensible
- restrictions
- résultat
- Résultats
- robotique
- Rôle
- Courir
- pour le running
- fonctionne
- Sécurité
- même
- Évolutivité
- Escaliers intérieurs
- échelle ai
- mise à l'échelle
- scène
- scores
- fluide
- Deuxièmement
- Section
- sur le lien
- semble
- la sélection
- semi-conducteur
- set
- Partager
- commun
- Shopping
- devrait
- montré
- signer
- Signal
- De même
- depuis
- unique
- Taille
- petit
- smart
- sur mesure
- Solutions
- RÉSOUDRE
- Résout
- quelques
- quelque chose
- Space
- groupe de neurones
- start-ups
- Étapes
- Boutique
- les stratégies
- de Marketing
- courant
- flux
- réussi
- tel
- suffisant
- Support
- suppression
- surveillance
- combustion propre
- Système
- Prenez
- prend
- tâches
- équipe
- équipes
- Les technologies
- Technologie
- conditions
- que
- qui
- La
- El futuro
- leur
- puis
- Là.
- donc
- Ces
- l'ont
- this
- ceux
- trois
- Avec
- débit
- fiable
- fois
- à
- Hauts
- Total
- suivre
- Tracking
- circulation
- transférer
- transferts
- Transformer
- Voyage
- oui
- deux
- typiquement
- En fin de compte
- incapable
- comprendre
- unité
- unités
- Utilisation
- usb
- utilisé
- d'utiliser
- Usages
- en utilisant
- d'habitude
- Utilisant
- Valeurs
- variété
- divers
- Vidéo
- Voir
- Salle de conférence virtuelle
- La réalité virtuelle
- vision
- vital
- vr
- Façon..
- we
- ont été
- Quoi
- que
- qui
- largement
- sera
- comprenant
- sans
- des mots
- de travail
- pourra
- X
- Rendement
- Yolo
- you
- Votre
- zéphyrnet
- zéro







