Introduction
grands modèles linguistiques (LLM) et l'IA générative représentent une percée transformatrice dans le domaine de l'intelligence artificielle et du traitement du langage naturel. Ils peuvent comprendre et générer du langage humain et produire du contenu tel que du texte, des images, de l’audio et des données synthétiques, ce qui les rend très polyvalents dans diverses applications. L'IA générative revêt une immense importance dans les applications du monde réel en automatisant et en améliorant la création de contenu, en personnalisant les expériences utilisateur, en rationalisant les flux de travail et en favorisant la créativité. Dans cette lecture, nous nous concentrerons sur la manière dont les entreprises peuvent s'intégrer aux Open LLM en ancré efficacement les invites à l'aide des Enterprise Knowledge Graphs.
Objectifs d'apprentissage
- Acquérir des connaissances sur la mise à la terre et la création d'invites tout en interagissant avec les systèmes LLM/Gen-AI.
- Comprendre la pertinence de Grounding pour l'entreprise, la valeur commerciale de l'intégration avec les systèmes ouverts Gen-AI avec un exemple.
- Analyser deux graphiques de connaissances et magasins de vecteurs de solutions concurrentes majeures sur différents fronts et comprendre lequel convient à quel moment.
- Étudiez un exemple de conception d'entreprise de mise à la terre et de création d'invites, en tirant parti des graphiques de connaissances, de la modélisation des données d'apprentissage et de la modélisation de graphiques en JAVA pour un scénario de recommandation client personnalisé.
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Que sont les grands modèles de langage ?
Un modèle de langage étendu est un modèle d'IA avancé formé à l'aide de techniques d'apprentissage en profondeur sur d'énormes quantités de texte et de données non structurées. Ces modèles sont capables d'interagir avec le langage humain, de générer du texte, des images et du son de type humain, et d'effectuer diverses tâches. traitement du langage naturel tâches.
En revanche, la définition d'un modèle linguistique fait référence à l'attribution de probabilités à des séquences de mots sur la base de l'analyse de corpus de textes. Un modèle de langage peut varier des simples modèles n-grammes aux modèles de réseaux neuronaux plus sophistiqués. Cependant, le terme « grand modèle de langage » fait généralement référence à des modèles qui utilisent des techniques d’apprentissage profond et comportent un grand nombre de paramètres, pouvant aller de millions à des milliards. Ces modèles peuvent capturer des modèles complexes de langage et produire un texte souvent impossible à distinguer de celui écrit par les humains.
Qu'est-ce qu'une invite ?
Une invite adressée à n'importe quel LLM ou à un système d'IA de chatbot similaire est une entrée ou un message textuel que vous fournissez pour lancer une conversation ou une interaction avec l'IA. Les LLM sont polyvalents, formés avec une grande variété de Big Data et peuvent être utilisés pour diverses tâches ; par conséquent, le contexte, la portée, la qualité et la clarté de votre invite influencent considérablement les réponses que vous recevez des systèmes LLM.
Qu’est-ce que la mise à la terre/RAG ?
Grounding, AKA Retrieval-Augmented Generation (RAG), dans le contexte du traitement LLM en langage naturel, fait référence à l'enrichissement de l'invite avec du contexte, des métadonnées supplémentaires et la portée que nous fournissons aux LLM pour améliorer et récupérer des réponses plus personnalisées et plus précises. Cette connexion aide les systèmes d’IA à comprendre et à interpréter les données d’une manière qui correspond à la portée et au contexte requis. Les recherches sur les LLM montrent que la qualité de leur réponse dépend de la qualité de l'invite.
Il s'agit d'un concept fondamental de l'IA, car il comble le fossé entre les données brutes et la capacité de l'IA à traiter et à interpréter ces données d'une manière cohérente avec la compréhension humaine et le contexte défini. Il améliore la qualité et la fiabilité des systèmes d’IA ainsi que leur capacité à fournir des informations ou des réponses précises et utiles.
Quels sont les inconvénients des LLM ?
Les grands modèles linguistiques (LLM), comme GPT-3, ont suscité une attention considérable et sont utilisés dans diverses applications, mais ils présentent également plusieurs inconvénients ou inconvénients. Certains des principaux inconvénients des LLM comprennent :
1. Parti pris et équité: Les LLM héritent souvent des biais des données de formation. Cela peut entraîner la génération de contenus biaisés ou discriminatoires, susceptibles de renforcer des stéréotypes préjudiciables et de perpétuer les préjugés existants.
2. Hallucinations: Les LLM ne comprennent pas vraiment le contenu qu'ils génèrent ; ils génèrent du texte basé sur des modèles dans les données de formation. Cela signifie qu’ils peuvent produire des informations factuellement incorrectes ou absurdes, ce qui les rend impropres à des applications critiques telles que le diagnostic médical ou les conseils juridiques.
3. Ressources informatiques: La formation et l'exécution de LLM nécessitent d'énormes ressources informatiques, y compris du matériel spécialisé comme les GPU et les TPU. Cela les rend coûteux à développer et à entretenir.
4. Confidentialité et sécurité des données: Les LLM peuvent générer du faux contenu convaincant, notamment du texte, des images et de l'audio. Cela met en danger la confidentialité et la sécurité des données, car elles peuvent être exploitées pour créer du contenu frauduleux ou usurper l’identité d’individus.
5. Préoccupations éthiques: L'utilisation des LLM dans diverses applications, telles que les deepfakes ou la génération automatisée de contenu, soulève des questions éthiques quant à leur potentiel d'utilisation abusive et leur impact sur la société.
6. Défis réglementaires: Le développement rapide de la technologie LLM a dépassé les cadres réglementaires, ce qui rend difficile l'établissement de lignes directrices et de réglementations appropriées pour faire face aux risques et défis potentiels associés aux LLM.
Il est important de noter que bon nombre de ces inconvénients ne sont pas inhérents aux LLM mais reflètent plutôt la manière dont ils sont développés, déployés et utilisés. Des efforts sont en cours pour atténuer ces inconvénients et rendre les LLM plus responsables et plus bénéfiques pour la société. C’est ici que la mise à la terre et le masquage peuvent être exploités et constituer un énorme avantage pour les entreprises.
Pertinence de l'ancrage pour l'entreprise
Les entreprises prospèrent en introduisant des modèles de langage étendus (LLM) dans leurs applications critiques. Ils comprennent la valeur potentielle dont les LLM pourraient bénéficier dans divers domaines. Construire des LLM, les pré-former et les affiner est assez coûteux et fastidieux pour eux. Au lieu de cela, ils pourraient utiliser les systèmes d’IA ouverts disponibles dans l’industrie en mettant à la terre et en masquant les invites autour des cas d’utilisation en entreprise.
Par conséquent, la mise à la terre est une considération majeure pour les entreprises et est plus pertinente et utile pour elles à la fois pour améliorer la qualité des réponses et pour surmonter les préoccupations liées aux hallucinations, à la sécurité des données et à la conformité, car elle peut générer une valeur commerciale incroyable. Des LLM disponibles sur le marché pour de nombreux cas d'utilisation qu'ils ont aujourd'hui du mal à automatiser.
Avantages pour les entreprises
Il y a plusieurs avantages pour les entreprises à mettre en œuvre la mise à la terre avec les LLM :
1. Crédibilité améliorée : En garantissant que les informations et le contenu générés par les LLM reposent sur des sources de données vérifiées, les entreprises peuvent améliorer la crédibilité de leurs communications, rapports et contenus. Cela peut aider à établir la confiance avec les clients et les parties prenantes.
2. Prise de décision améliorée : Dans les applications d'entreprise, en particulier celles liées à l'analyse des données et à l'aide à la décision, l'utilisation de LLM avec mise à la terre des données peut fournir des informations plus fiables. Cela peut conduire à une prise de décision plus éclairée, ce qui est crucial pour la planification stratégique et la croissance de l’entreprise.
3. Conformité réglementaire: De nombreux secteurs sont soumis à des exigences réglementaires en matière d’exactitude et de conformité des données. La mise à la terre des données avec les LLM peut aider à respecter ces normes de conformité, réduisant ainsi le risque de problèmes juridiques ou réglementaires.
4. Génération de contenu de qualité : Les LLM sont souvent utilisés dans la création de contenu, par exemple pour le marketing, le support client et les descriptions de produits. La mise à la terre des données garantit que le contenu généré est factuellement exact, réduisant ainsi le risque de diffusion d'informations ou d'hallucinations fausses ou trompeuses.
5. Réduction de la désinformation : À l’ère des fausses nouvelles et de la désinformation, la mise à la terre des données peut aider les entreprises à lutter contre la propagation de fausses informations en garantissant que le contenu qu’elles génèrent ou partagent est basé sur des sources de données validées.
6. Satisfaction du client: Fournir aux clients des informations précises et fiables peut améliorer leur satisfaction et leur confiance dans les produits ou services d'une entreprise.
7. Atténuation des risques: La mise à la terre des données peut contribuer à réduire le risque de prendre des décisions fondées sur des informations inexactes ou incomplètes, ce qui pourrait entraîner un préjudice financier ou une atteinte à la réputation.
Exemple : un scénario de recommandation de produit client
Voyons comment la mise à la terre des données pourrait aider dans un cas d'utilisation en entreprise utilisant openAI chatGPT
Invites de base
Generate a short email adding coupons on recommended products to customer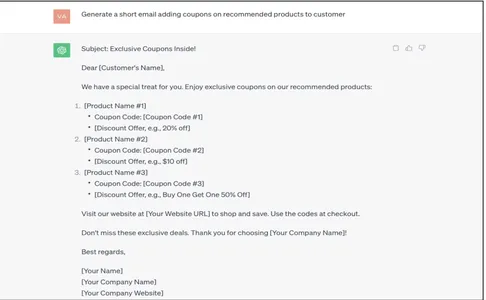
La réponse générée par ChatGPT est très générique, non contextualisée et brute. Cela doit être mis à jour/cartographié manuellement avec les bonnes données client de l'entreprise, ce qui coûte cher. Voyons comment cela pourrait être automatisé grâce à des techniques de mise à la terre des données.
Supposons que l'entreprise détienne déjà les données client de l'entreprise et un système de recommandation intelligent capable de générer des coupons et des recommandations pour les clients ; nous pourrions très bien étayer l'invite ci-dessus en l'enrichissant avec les bonnes métadonnées afin que le texte de l'e-mail généré à partir de chatGPT soit exactement le même que celui que nous souhaitons et puisse très bien être automatisé pour envoyer un e-mail au client sans intervention manuelle.
Supposons que notre moteur de mise à la terre obtienne les bonnes métadonnées d'enrichissement à partir des données client et mette à jour l'invite ci-dessous. Voyons comment serait la réponse ChatGPT pour l'invite mise à la terre.
Invite mise à la terre
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off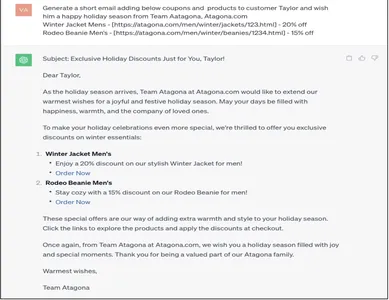
La réponse générée avec l'invite au sol correspond exactement à la manière dont l'entreprise souhaite que le client soit informé. Les données client enrichies intégrées dans une réponse par e-mail de Gen AI constituent une automatisation qui serait remarquable pour développer et pérenniser les entreprises.
Solutions de mise à la terre d'entreprise LLM pour les systèmes logiciels
Il existe plusieurs façons de mettre à la terre les données dans les systèmes d'entreprise, et une combinaison de ces techniques pourrait être utilisée pour une mise à la terre efficace des données et une génération rapide spécifique au cas d'utilisation. Les deux principaux concurrents en tant que solutions potentielles pour la mise en œuvre de la génération augmentée de récupération (mise à la terre) sont
- Données d'application|Graphiques de connaissances
- Intégrations vectorielles et recherche sémantique
L'utilisation de ces solutions dépend du cas d'utilisation et de la mise à la terre que vous souhaitez appliquer. Par exemple, les magasins de vecteurs fournissant des réponses peuvent être inexacts et vagues, alors que les graphiques de connaissances renverraient des réponses précises, exactes et stockées dans un format lisible par l'homme.
Quelques autres stratégies qui pourraient être combinées à celles ci-dessus pourraient être
- Liens vers des API externes, des moteurs de recherche
- Systèmes de masquage des données et de respect de la conformité
- Intégration avec les magasins de données internes et les systèmes
- Unification des données en temps réel provenant de plusieurs sources
Dans ce blog, examinons un exemple de conception logicielle sur la façon dont vous pouvez réaliser des graphiques de données d'application d'entreprise.
Graphiques de connaissances d'entreprise
Un graphe de connaissances peut représenter des informations sémantiques de diverses entités et des relations entre elles. Dans le monde de l'entreprise, ils stockent des connaissances sur les clients, les produits et au-delà. Les graphiques clients d'entreprise seraient un outil puissant pour ancrer efficacement les données et générer des invites enrichies. Les graphiques de connaissances permettent une recherche basée sur des graphiques, permettant aux utilisateurs d'explorer des informations à travers des concepts et des entités liés, ce qui peut conduire à des résultats de recherche plus précis et plus diversifiés.
Comparaison avec les bases de données vectorielles
Le choix de la solution de mise à la terre serait spécifique au cas d'utilisation. Cependant, les graphiques présentent de nombreux avantages par rapport aux vecteurs tels que
| Critères | Mise à la terre du graphique | Mise à la terre du vecteur |
| Requêtes analytiques | Les graphiques de données conviennent aux données structurées et aux requêtes analytiques, fournissant des résultats précis grâce à leur disposition graphique abstraite. | Les magasins de données vectorielles peuvent ne pas fonctionner aussi bien avec les requêtes analytiques, car ils fonctionnent principalement sur des données non structurées, sur une recherche sémantique avec des intégrations vectorielles et s'appuient sur un score de similarité. |
| Précision et crédibilité | les graphiques de connaissances utilisent des nœuds et des relations pour stocker des données, renvoyant uniquement les informations présentes. Ils évitent les résultats incomplets ou non pertinents. | Les bases de données vectorielles peuvent fournir des résultats incomplets ou non pertinents, principalement en raison de leur recours à des scores de similarité et à des limites de résultats prédéfinies. |
| Corriger les hallucinations | Les graphiques de connaissances sont transparents avec une représentation des données lisible par l'homme. Ils aident à identifier et à corriger les informations erronées, à retracer le cheminement de la requête et à y apporter des corrections, améliorant ainsi la précision du LLM (Large Language Model). | Les bases de données vectorielles sont souvent considérées comme des boîtes noires non stockées dans un format lisible et peuvent ne pas faciliter l'identification et la correction des informations erronées. |
| Sécurité et gouvernance | Les graphiques de connaissances offrent un meilleur contrôle sur la génération de données, la gouvernance et le respect de la conformité, y compris des réglementations telles que le RGPD. | Les bases de données vectorielles peuvent avoir du mal à imposer des restrictions et une gouvernance en raison de leur nature non transparente. |
Conception de haut niveau
Voyons à un niveau très élevé comment le système peut rechercher une entreprise qui utilise des graphes de connaissances et des LLM ouverts pour la mise à la terre.
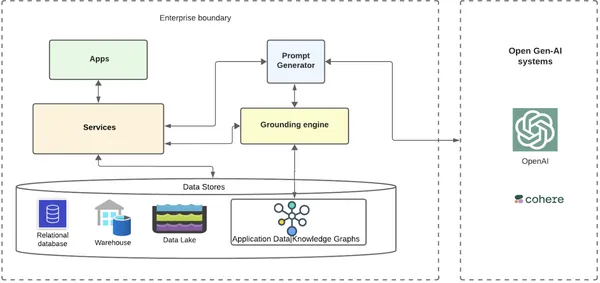
La couche de base est l'endroit où les données et métadonnées des clients de l'entreprise sont stockées dans diverses bases de données, entrepôts de données et lacs de données. Il peut y avoir un service créant les graphiques de connaissances des données à partir de ces données et les stockant dans une base de données graphique. Il peut exister de nombreux services d'entreprise|micros services dans un monde cloud natif distribué qui interagiraient avec ces magasins de données. Au-dessus de ces services pourraient se trouver diverses applications qui exploiteraient l’infrastructure sous-jacente.
Les applications peuvent avoir de nombreux cas d’utilisation pour intégrer l’IA dans leurs scénarios ou flux clients automatisés intelligents, ce qui nécessite d’interagir avec des systèmes d’IA internes et externes. Dans le cas de scénarios d'IA générative, prenons un exemple simple de workflow dans lequel une entreprise souhaite cibler des clients via un e-mail proposant quelques réductions sur des produits personnalisés recommandés pendant une période de fêtes. Ils peuvent y parvenir grâce à une automatisation de premier ordre, en exploitant plus efficacement l’IA.
Le flux de travail
- Le flux de travail qui souhaite envoyer un e-mail peut utiliser les systèmes ouverts Gen-AI en envoyant une invite fondée avec des données contextualisées du client.
- L'application de workflow enverrait une demande à son service backend pour obtenir le texte de l'e-mail en tirant parti des systèmes GenAI.
- Le service backend acheminerait le service vers un service de générateur d'invite, qui serait acheminé vers un moteur de mise à la terre.
- Le moteur de mise à la terre récupère toutes les métadonnées client de l'un de ses services et récupère le graphique de connaissance des données client.
- Le moteur de mise à la terre parcourt le graphique à travers les nœuds et les relations pertinentes extraient les informations finales requises et les renvoient au générateur d'invites.
- Le générateur d'invite ajoute les données fondées avec un modèle préexistant pour le cas d'utilisation et envoie l'invite fondée aux systèmes d'IA ouverts avec lesquels l'entreprise choisit de s'intégrer (par exemple, OpenAI/Cohere).
- Les systèmes Open GenAI renvoient une réponse beaucoup plus pertinente et contextualisée à l'entreprise, envoyée au client par e-mail.
Divisons cela en deux parties et comprenons en détail :
1. Génération de graphiques de connaissance client
La conception ci-dessous convient à l'exemple ci-dessus, la modélisation peut être effectuée de différentes manières selon les besoins.
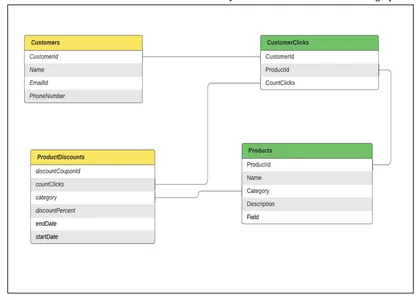
La modélisation des données: Supposons que nous ayons différentes tables modélisées sous forme de nœuds dans un graphique et que nous joignons les tables sous forme de relations entre les nœuds. Pour l'exemple ci-dessus, nous avons besoin
- une table qui contient les données du Client,
- un tableau qui contient les données du produit,
- un tableau contenant les données CustomerInterests (Clicks) pour des recommandations personnalisées
- une table qui contient les données ProductDiscounts
Il est de la responsabilité de l'entreprise de faire en sorte que toutes ces données soient ingérées à partir de plusieurs sources de données et mises à jour régulièrement pour atteindre efficacement les clients.
Voyons comment ces tableaux peuvent être modélisés et comment ils peuvent être transformés en graphique client.
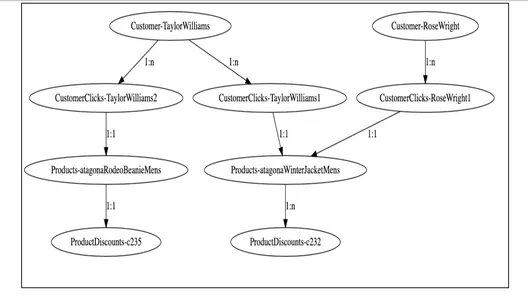
2. Modélisation graphique
À partir du visualiseur graphique ci-dessus, nous pouvons voir comment les nœuds clients sont liés à divers produits en fonction de leurs données d'engagement en matière de clics et ensuite aux nœuds de remises. Il est facile pour le service de mise à la terre d'interroger ces graphiques clients, de parcourir ces nœuds via des relations et d'obtenir les informations requises sur les remises éligibles aux clients respectifs.
Un exemple de nœud de graphique et de relations POJO JAVA pour ce qui précède pourraient ressembler à ce qui suit
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }Un exemple de graphique brut dans ce scénario pourrait ressembler à ci-dessous
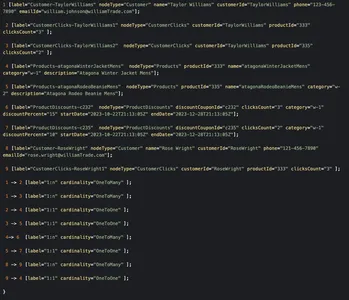
Parcourir le graphique à partir du nœud client « Taylor Williams » résoudrait le problème pour nous et récupérerait les bonnes recommandations de produits et les remises éligibles.
3. Magasins Graph populaires dans l’industrie
Il existe de nombreux magasins de graphiques disponibles sur le marché qui peuvent s'adapter aux architectures d'entreprise. Neo4j, TigerGraph, Amazon Neptune et OrientDB sont largement adoptés comme bases de données graphiques.
Nous introduisons le nouveau paradigme des Graph Data Lakes, qui permet des requêtes graphiques sur des données tabulaires (données structurées dans les lacs, les entrepôts et les Lakehouses). Ceci est réalisé grâce aux nouvelles solutions répertoriées ci-dessous, sans qu'il soit nécessaire d'hydrater ou de conserver les données dans des magasins de données graphiques, en tirant parti de Zero-ETL.
- PuppyGraph (lac de données graphique)
- Timbr.ai
Conformité et considérations éthiques
Protection des données: Les entreprises doivent être responsables du stockage et de l'utilisation des données clients conformément au RGPD et aux autres normes PII. Les données stockées doivent être régies et nettoyées avant d'être traitées et réutilisées à des fins d'analyse ou d'application de l'IA.
Hallucinations et réconciliation: Les entreprises peuvent également ajouter des services de rapprochement qui identifieraient les informations erronées dans les données, retraceraient le cheminement de la requête et y apporteraient des corrections, ce qui pourrait contribuer à améliorer la précision du LLM. Avec les graphes de connaissances, puisque les données stockées sont transparentes et lisibles par l’homme, cela devrait être relativement facile à réaliser.
Politiques de conservation restrictives : Pour respecter la protection des données et éviter toute utilisation abusive des données des clients lors de l'interaction avec des systèmes LLM ouverts, il est très important d'avoir des politiques de rétention zéro afin que les systèmes externes avec lesquels les entreprises interagissent ne conservent pas les données d'invite demandées à des fins analytiques ou commerciales ultérieures.
Conclusion
En conclusion, les grands modèles linguistiques (LLM) représentent une avancée remarquable dans l’intelligence artificielle et le traitement du langage naturel. Ils peuvent transformer diverses industries et applications, depuis la compréhension et la génération du langage naturel jusqu'à l'assistance dans la réalisation de tâches complexes. Cependant, le succès et l’utilisation responsable des LLM nécessitent une base solide et un ancrage dans divers domaines clés.
Faits marquants
- Les entreprises peuvent bénéficier énormément d’une mise à la terre et d’incitations efficaces lorsqu’elles utilisent les LLM pour divers scénarios.
- Les graphiques de connaissances et les magasins Vector sont des solutions Grounding populaires, et le choix d'en choisir un dépend de l'objectif de la solution.
- Les graphiques de connaissances peuvent contenir des informations plus précises et plus fiables sur les magasins de vecteurs, ce qui donne un avantage aux cas d'utilisation en entreprise sans avoir à ajouter de couches de sécurité et de conformité supplémentaires.
- Transformez la modélisation de données traditionnelle avec des entités et des relations en graphiques de connaissances avec des nœuds et des arêtes.
- Intégrez les graphiques de connaissances d'entreprise à diverses sources de données avec les entreprises de stockage Big Data existantes.
- Les graphiques de connaissances sont idéaux pour les requêtes analytiques. Les lacs de données graphiques permettent d'interroger des données tabulaires sous forme de graphiques dans le stockage de données d'entreprise.
Foire aux Questions
R. LLM est un algorithme d'IA qui utilise des techniques DL et des ensembles de données extrêmement volumineux pour comprendre, résumer, générer et prédire de nouveaux contenus.
A. Un graphe de données d'application est une structure de données stockant des données sous forme de nœuds et d'arêtes. Modélisez-les comme les relations entre différents nœuds de données.
A. Une base de données vectorielle stocke et gère des données non structurées telles que du texte, de l'audio et de la vidéo. Il excelle dans l'indexation et la récupération rapides pour des applications telles que les moteurs de recommandation, l'apprentissage automatique et Gen-AI.
A. Dans un magasin vectoriel, les incorporations sont des représentations numériques d'objets, de mots ou de points de données dans un espace vectoriel de grande dimension. Ces intégrations capturent les relations sémantiques et les similitudes entre les éléments, permettant une analyse efficace des données, des recherches de similarité et des tâches d'apprentissage automatique.
A. Les données structurées sont bien organisées avec des tables et un schéma définis. Les données non structurées, comme le texte, les images, l'audio ou la vidéo, sont plus difficiles à analyser en raison de leur manque de format.
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/
- :possède
- :est
- :ne pas
- :où
- $UP
- 11
- 12
- 13
- 15%
- 19
- 22
- 49
- 500
- 52
- 53
- 750
- 8
- 9
- a
- capacité
- Qui sommes-nous
- au dessus de
- RÉSUMÉ
- Selon
- précision
- Avec cette connaissance vient le pouvoir de prendre
- atteindre
- atteint
- à travers
- ajouter
- ajoutant
- Supplémentaire
- propos
- Ajoute
- adhérer
- adhérence
- adhérant
- adopté
- Avancée
- avancement
- Avantage
- avantages
- conseils
- AI
- Systèmes d'IA
- aka
- algorithme
- Aligne
- Tous
- Permettre
- déjà
- aussi
- incroyable
- Amazon
- Amazone Neptune
- parmi
- quantités
- an
- selon une analyse de l’Université de Princeton
- Analytique
- analytique
- Analytique Vidhya
- il analyse
- ainsi que les
- tous
- Apis
- Application
- applications
- Appliquer
- Application
- approprié
- SONT
- domaines
- autour
- article
- artificiel
- intelligence artificielle
- AS
- aider
- assistant
- associé
- assumer
- At
- précaution
- acoustique
- augmentée
- Automatisation
- automatiser
- Automation
- disponibles
- éviter
- RETOUR
- backend
- base
- basé
- BE
- before
- ci-dessous
- avantageux
- profiter
- avantages.
- Améliorée
- jusqu'à XNUMX fois
- Au-delà
- biaisé
- biais
- Big
- Big Data
- stockage de données volumineuses
- milliards
- Noir
- Blog
- tous les deux
- boîtes
- Pause
- percée
- ponts
- construire
- construire la confiance
- Développement
- la performance des entreprises
- mais
- by
- CAN
- capable
- capturer
- maisons
- cas
- Catégories
- challenge
- globaux
- difficile
- Chatbot
- ChatGPT
- choose
- clarté
- classe
- CLIENTS
- le cloud
- nuage natif
- COM
- lutter contre la
- combinaison
- comment
- Communications
- complexe
- conformité
- calcul
- concept
- concepts
- PROBLÈMES DE PEAU
- conclusion
- connexion
- Inconvénients
- considération
- cohérent
- contenu
- création de contenu
- contexte
- contraste
- des bactéries
- Conversation
- correct
- Corrections
- pourriez
- engendrent
- création
- notre créativité
- Crédibilité
- critique
- crucial
- lourd
- des clients
- données client
- Support à la clientèle
- Clients
- données
- l'analyse des données
- Lac de données
- points de données
- confidentialité des données
- Confidentialité et sécurité des données
- protection des données
- la sécurité des données
- ensembles de données
- stockage de données
- entrepôts de données
- Base de données
- bases de données
- datetime
- décision
- La prise de décision
- décisions
- profond
- l'apprentissage en profondeur
- deepfakes
- défini
- définition
- livrer
- dépend
- déployé
- la description
- Conception
- détail
- développer
- développé
- Développement
- diagnostic
- différence
- différent
- remises
- discrétion
- distribué
- plusieurs
- do
- domaines
- fait
- désavantages
- motivation
- deux
- pendant
- e
- Easy
- Edge
- Efficace
- de manière efficace
- efficace
- efforts
- admissibles
- enchâsser
- enrobage
- permettre
- permet
- permettant
- participation
- Moteur
- Moteurs
- de renforcer
- améliorée
- Améliore
- améliorer
- énorme
- enrichi
- enrichissant
- Assure
- assurer
- Entreprise
- entreprises
- entités
- Ère
- notamment
- établir
- Ether (ETH)
- éthique
- exactement
- exemple
- existant
- cher
- Expériences
- Exploités
- explorez
- externe
- Extraits
- Visage
- faciliter
- faux
- fausses nouvelles
- non
- few
- finale
- la traduction de documents financiers
- Flux
- Focus
- Pour
- formulaire
- le format
- favoriser
- Fondation
- cadres
- frauduleux
- de
- fondamental
- plus
- gagné
- écart
- RGPD
- Gen
- générer
- généré
- générateur
- génération
- génératif
- IA générative
- générateur
- donne
- gouvernance
- régie
- GPU
- gagner
- graphique
- graphiques
- Sol
- Croissance
- lignes directrices
- heureux vous
- Plus fort
- Matériel
- nuire
- nuisible
- Vous avez
- ayant
- vous aider
- utile
- aide
- d'où
- ici
- Haute
- de haut niveau
- très
- lui
- appuyez en continu
- détient
- Idées
- Comment
- Cependant
- HTML
- HTTPS
- majeur
- Extrêmement
- humain
- lisible par l'homme
- Les êtres humains
- idéal
- Identification
- identifier
- satellite
- immense
- Impact
- la mise en œuvre
- met en oeuvre
- importance
- important
- imposant
- améliorer
- l'amélioration de
- in
- inexacte
- comprendre
- Y compris
- individus
- secteurs
- industrie
- influencer
- d'information
- inhérent
- initier
- contribution
- idées.
- intégrer
- l'intégration
- Intelligence
- Intelligent
- interagir
- interagissant
- l'interaction
- Interfaces
- interne
- intervention
- développement
- introduire
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- articles
- SES
- Java
- rejoindre
- jpg
- ACTIVITES
- Zones-clés
- spécialisées
- Peindre
- lac
- des lacs
- langue
- gros
- couche
- poules pondeuses
- Disposition
- conduire
- conduisant
- apprentissage
- Légal
- Niveau
- Levier
- à effet de levier
- en tirant parti
- comme
- limites
- lié
- Listé
- Style
- ressembler
- click
- machine learning
- Entrée
- principalement
- maintenir
- majeur
- a prendre une
- FAIT DU
- Fabrication
- gère
- Manuel
- manuellement
- de nombreuses
- Marché
- Stratégie
- massif
- massivement
- largeur maximale
- Mai..
- veux dire
- Médias
- médical
- réunion
- message
- Métadonnées
- des millions
- Désinformation
- trompeur
- une mauvaise utilisation
- Réduire les
- atténuation
- modèle
- modélisation statistique
- numériques jumeaux (digital twin models)
- PLUS
- la plupart
- beaucoup
- plusieurs
- must
- prénom
- indigène
- Nature
- Langage naturel
- Traitement du langage naturel
- Compréhension du langage naturel
- Nature
- Besoin
- Besoins
- Neptune
- réseau et
- Neural
- Réseau neuronal
- Nouveauté
- nouvelles solutions
- nouvelles
- nœud
- nœuds
- noter
- nombre
- nombreux
- objets
- obtenir
- of
- de rabais
- code
- offrant
- souvent
- on
- ONE
- en cours
- uniquement
- ouvert
- OpenAI
- fonctionner
- or
- Autre
- nos
- ande
- plus de
- surmonter
- propriété
- paradigme
- paramètres
- partie
- les pièces
- chemin
- motifs
- effectuer
- effectuer
- Personnalisé
- Téléphone
- pii
- et la planification de votre patrimoine
- Platon
- Intelligence des données Platon
- PlatonDonnées
- des notes bonus
- politiques
- Populaire
- défaillances
- solide
- précis
- prévoir
- représentent
- empêcher
- prix
- primaire
- la confidentialité
- Confidentialité et sécurité
- Privé
- Problème
- processus
- traitement
- produire
- Produit
- Produits
- protection
- fournir
- à condition de
- aportando
- public
- publié
- but
- des fins
- qualité
- requêtes
- fréquemment posées
- Rapide
- assez
- soulève
- gamme
- Nos tests de diagnostic produisent des résultats rapides et précis sans nécessiter d'équipement de laboratoire complexe et coûteux,
- plutôt
- raw
- les données brutes
- nous joindre
- Lire
- monde réel
- recevoir
- Recommandation
- recommandations
- recommandé
- réconcilier
- réduire
- réduire
- se réfère
- refléter
- régulièrement
- règlements
- régulateurs
- renforcer
- en relation
- relation amoureuse
- Les relations
- relativement
- pertinence
- pertinent
- fiabilité
- fiable
- dépendance
- compter
- remarquables
- Rapports
- représentent
- représentation
- nécessaire
- demandé
- exigent
- conditions
- exigence
- Exigences
- a besoin
- un article
- Resources
- ceux
- réponse
- réponses
- responsabilité
- responsables
- restrictions
- résultat
- Résultats
- rétention
- retourner
- retour
- bon
- Analyse
- risques
- Rôle
- Itinéraire
- routes
- pour le running
- même
- client
- Escaliers intérieurs
- scénario
- scénarios
- Sciences
- portée
- marquant
- Rechercher
- recherches
- Saison
- sécurité
- sur le lien
- vu
- envoyer
- envoi
- envoie
- envoyé
- service
- Services
- Sets
- plusieurs
- Partager
- Shorts
- devrait
- montré
- Spectacles
- significative
- de façon significative
- similaires
- similitudes
- étapes
- depuis
- So
- Société
- Logiciels
- sur mesure
- Solutions
- RÉSOUDRE
- quelques
- sophistiqué
- Sources
- Space
- spécialisé
- groupe de neurones
- propagation
- parties prenantes
- Normes
- storage
- Boutique
- stockée
- STORES
- Stratégique
- les stratégies
- la rationalisation
- Chaîne
- STRONG
- structure
- structuré
- données structurées et non structurées
- sujet
- succès
- tel
- Combinaison
- convient
- résumé
- Support
- haute
- données synthétiques
- combustion propre
- Système
- table
- Prenez
- Target
- tâches
- taylor
- équipe
- techniques
- Technologie
- modèle
- terme
- texte
- qui
- Les
- Le graphique
- les informations
- leur
- Les
- Là.
- Ces
- l'ont
- this
- ceux
- Prospérer
- Avec
- à
- aujourd'hui
- outil
- top
- tracer
- traditionnel
- qualifié
- Formation
- Transformer
- transformation
- transformé
- communication
- traverser
- vraiment
- La confiance
- deux
- ultime
- sous-jacent
- comprendre
- compréhension
- Mises à jour
- a actualisé
- us
- utilisé
- cas d'utilisation
- d'utiliser
- informations utiles
- Utilisateur
- utilisateurs
- Usages
- en utilisant
- d'habitude
- validé
- Plus-value
- variété
- divers
- vérifié
- polyvalente
- très
- via
- Vidéo
- souhaitez
- veut
- était
- Façon..
- façons
- we
- webp
- WELL
- Quoi
- Qu’est ce qu'
- quand
- Les
- qui
- tout en
- large
- largement
- sera
- Hiver
- comprenant
- sans
- des mots
- workflow
- workflows
- world
- pourra
- code écrit
- you
- Votre
- zéphyrnet
- zéro