La création de modèles de base (FM) nécessite la création, la maintenance et l'optimisation de grands clusters pour former des modèles comportant des dizaines, voire des centaines de milliards de paramètres sur de grandes quantités de données. Créer un environnement résilient capable de gérer les pannes et les changements environnementaux sans perdre des jours ou des semaines de progression de la formation du modèle est un défi opérationnel qui vous oblige à mettre en œuvre une mise à l'échelle du cluster, une surveillance proactive de l'état, des points de contrôle des tâches et des capacités pour reprendre automatiquement la formation en cas de pannes ou de problèmes. .
Nous sommes ravis de partager cela HyperPod Amazon SageMaker est désormais généralement disponible pour permettre la formation de modèles de base avec des milliers d'accélérateurs jusqu'à 40 % plus rapidement en fournissant un environnement de formation hautement résilient tout en éliminant le travail lourd et indifférencié impliqué dans l'exploitation de clusters de formation à grande échelle. Avec SageMaker HyperPod, les praticiens du machine learning (ML) peuvent former les FM pendant des semaines et des mois sans interruption et sans avoir à faire face à des problèmes de panne matérielle.
Des clients tels que Stability AI utilisent SageMaker HyperPod pour entraîner leurs modèles de base, notamment Stable Diffusion.
« En tant que leader de l’IA générative open source, notre objectif est de maximiser l’accessibilité de l’IA moderne. Nous construisons des modèles de base avec des dizaines de milliards de paramètres, qui nécessitent une infrastructure permettant d'adapter les performances de formation de manière optimale. Grâce à l'infrastructure gérée et aux bibliothèques d'optimisation de SageMaker HyperPod, nous pouvons réduire le temps et les coûts de formation de plus de 50 %. Cela rend notre formation de modèles plus résiliente et plus performante pour créer plus rapidement des modèles de pointe.
– Emad Mostaque, fondateur et PDG de Stability AI.
Pour rendre le cycle complet de développement de FM résilient aux pannes matérielles, SageMaker HyperPod vous aide à créer des clusters, à surveiller l'état du cluster, à réparer et remplacer les nœuds défectueux à la volée, à enregistrer les points de contrôle fréquents et à reprendre automatiquement l'entraînement sans perdre la progression. De plus, SageMaker HyperPod est préconfiguré avec Amazon Sage Maker bibliothèques de formation distribuées, y compris Bibliothèque de parallélisme de données SageMaker (SMDDP) ainsi que les Bibliothèque de parallélisme de modèles SageMaker (SMP), pour améliorer les performances de la formation FM en facilitant la division des données et des modèles de formation en morceaux plus petits et en les traitant en parallèle sur les nœuds du cluster, tout en utilisant pleinement l'infrastructure de calcul et de réseau du cluster. SageMaker HyperPod intègre Slurm Workload Manager pour l'orchestration des clusters et des tâches de formation.
Présentation de Slurm Workload Manager
grogner, anciennement connu sous le nom de Simple Linux Utility for Resource Management, est un planificateur de tâches permettant d'exécuter des tâches sur un cluster informatique distribué. Il fournit également un cadre pour exécuter des tâches parallèles à l'aide du Bibliothèque de communications collectives NVIDIA (NCCL) or Interface de transmission de messages (MPI) normes. Slurm est un système de gestion de ressources de cluster open source populaire largement utilisé par les charges de travail de calcul haute performance (HPC) et de formation générative d'IA et FM. SageMaker HyperPod offre un moyen simple de démarrer et de fonctionner avec un cluster Slurm en quelques minutes.
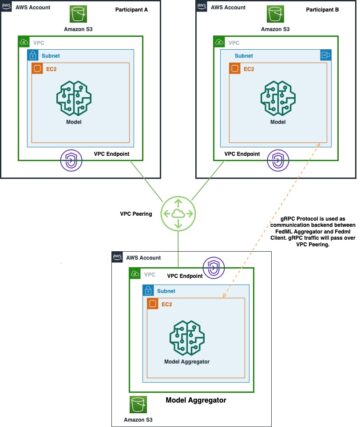
Ce qui suit est un diagramme architectural de haut niveau montrant comment les utilisateurs interagissent avec SageMaker HyperPod et comment les différents composants du cluster interagissent entre eux et avec d'autres services AWS, tels que Amazon FSx pour Lustre ainsi que les Service de stockage simple Amazon (Amazon S3).
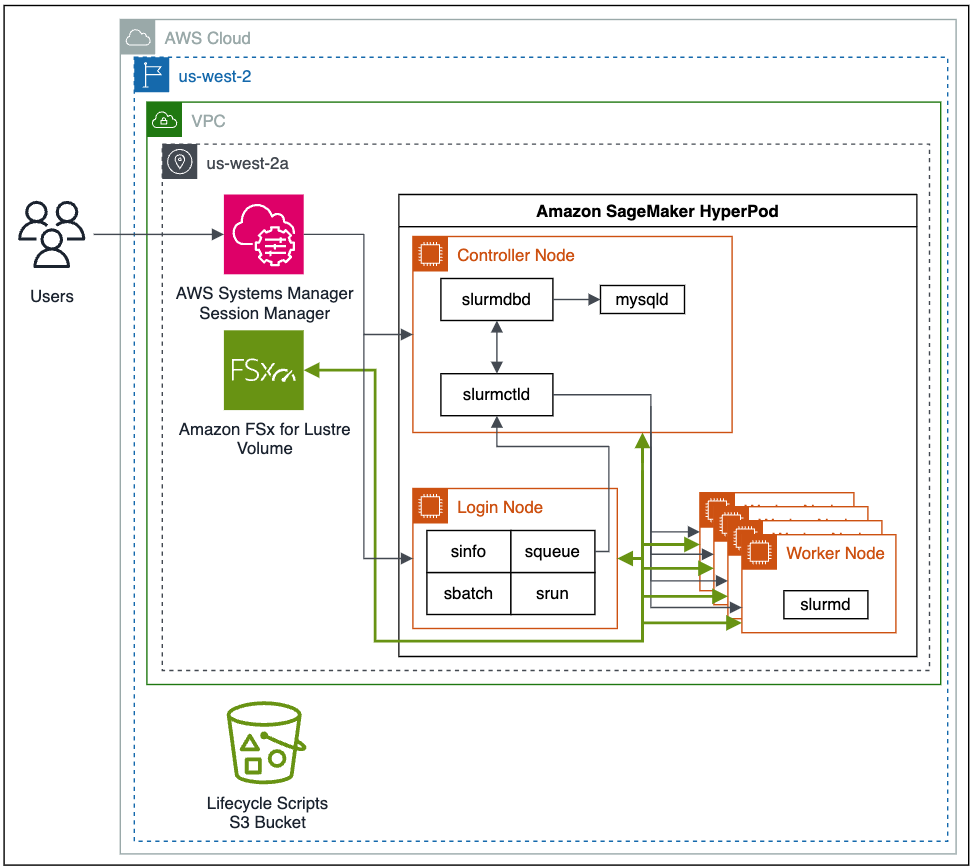
Les tâches Slurm sont soumises par des commandes sur la ligne de commande. Les commandes pour exécuter les tâches Slurm sont srun ainsi que les sbatchL’ srun La commande exécute la tâche de formation en mode interactif et bloquant, et sbatch s'exécute en traitement par lots et en mode non bloquant. srun est principalement utilisé pour exécuter des tâches immédiates, tandis que sbatch peut être utilisé pour des exécutions ultérieures de travaux.
Pour plus d'informations sur les commandes et la configuration Slurm supplémentaires, reportez-vous au Documentation sur le gestionnaire de charge de travail Slurm.
Capacités de reprise automatique et de guérison
L'une des nouvelles fonctionnalités de SageMaker HyperPod est la possibilité de reprendre automatiquement vos tâches. Auparavant, lorsqu'un nœud de travail échouait lors d'une exécution d'une tâche de formation ou de réglage fin, il appartenait à l'utilisateur de vérifier l'état de la tâche, de redémarrer la tâche à partir du dernier point de contrôle et de continuer à surveiller la tâche tout au long de l'exécution. Avec des tâches de formation ou de réglage fin devant s'exécuter pendant des jours, des semaines, voire des mois à la fois, cela devient coûteux en raison de la surcharge administrative supplémentaire de l'utilisateur qui doit passer des cycles pour surveiller et maintenir la tâche dans le cas où un les pannes de nœuds, ainsi que le coût du temps d'inactivité des instances de calcul accélérées coûteuses.
SageMaker HyperPod améliore la résilience des tâches en utilisant des vérifications d'état automatisées, le remplacement des nœuds et la récupération des tâches. Les tâches Slurm dans SageMaker HyperPod sont surveillées à l'aide d'un plugin Slurm personnalisé SageMaker utilisant le Cadre SPANK. Lorsqu'une tâche de formation échoue, SageMaker HyperPod inspecte l'état du cluster via une suite de vérifications de l'état. Si un nœud défectueux est détecté dans le cluster, SageMaker HyperPod supprimera automatiquement le nœud du cluster, le remplacera par un nœud sain et redémarrera la tâche de formation. Lorsque vous utilisez des points de contrôle dans des tâches de formation, toute tâche interrompue ou ayant échoué peut reprendre à partir du dernier point de contrôle.
Vue d'ensemble de la solution
Pour déployer votre SageMaker HyperPod, vous préparez d'abord votre environnement en configurant votre Cloud privé virtuel Amazon (Amazon VPC), en déployant des services de prise en charge tels que FSx for Lustre dans votre VPC et en publiant vos scripts de cycle de vie Slurm dans un compartiment S3. Vous déployez et configurez ensuite votre SageMaker HyperPod et vous connectez au nœud principal pour démarrer vos tâches de formation.
Pré-requis
Avant de créer votre SageMaker HyperPod, vous devez d'abord configurer votre VPC, créer un système de fichiers FSx for Lustre et établir un compartiment S3 avec les scripts de cycle de vie du cluster souhaités. Vous avez également besoin de la dernière version du Interface de ligne de commande AWS (AWS CLI) et le plug-in CLI installé pour Gestionnaire de sessions AWS, une capacité de Gestionnaire de systèmes AWS.
SageMaker HyperPod est entièrement intégré à votre VPC. Pour plus d'informations sur la création d'un nouveau VPC, consultez Créer un VPC par défaut or Créer un VPC. Pour permettre une connexion transparente avec les performances les plus élevées entre les ressources, vous devez créer toutes vos ressources dans la même région et la même zone de disponibilité, et vous assurer que les règles de groupe de sécurité associées autorisent la connexion entre les ressources du cluster.
Ensuite, vous créer un système de fichiers FSx pour Lustre. Cela servira de système de fichiers hautes performances à utiliser tout au long de notre formation sur les modèles. Assurez-vous que FSx for Lustre et les groupes de sécurité du cluster autorisent la communication entrante et sortante entre les ressources du cluster et le système de fichiers FSx for Lustre.
Pour configurer vos scripts de cycle de vie de cluster, qui sont exécutés lorsque des événements tels qu'une nouvelle instance de cluster se produisent, vous créez un compartiment S3, puis copiez et éventuellement personnalisez les scripts de cycle de vie par défaut. Pour cet exemple, nous stockons tous les scripts de cycle de vie dans un préfixe de compartiment de lifecycle-scripts.
Tout d'abord, vous téléchargez les exemples de scripts de cycle de vie à partir du GitHub repo. Vous devez les personnaliser en fonction des comportements de cluster souhaités.
Créez ensuite un compartiment S3 pour stocker les scripts de cycle de vie personnalisés.
Ensuite, copiez les scripts de cycle de vie par défaut de votre répertoire local vers le compartiment et le préfixe souhaités en utilisant aws s3 sync:
Enfin, pour configurer le client pour une connexion simplifiée au nœud principal du cluster, vous devez installer ou mettre à jour l'AWS CLI Et installez le Plug-in CLI AWS Session Manager pour permettre aux connexions de terminal interactif d'administrer le cluster et d'exécuter des tâches de formation.
Vous pouvez créer un cluster SageMaker HyperPod avec des ressources disponibles à la demande ou en demandant une réservation de capacité auprès de SageMaker. Pour créer une réservation de capacité, vous créez une demande d'augmentation de quota pour réserver des types d'instances de calcul spécifiques et une allocation de capacité sur le tableau de bord Quotas de service.
Configurez votre pôle de formation
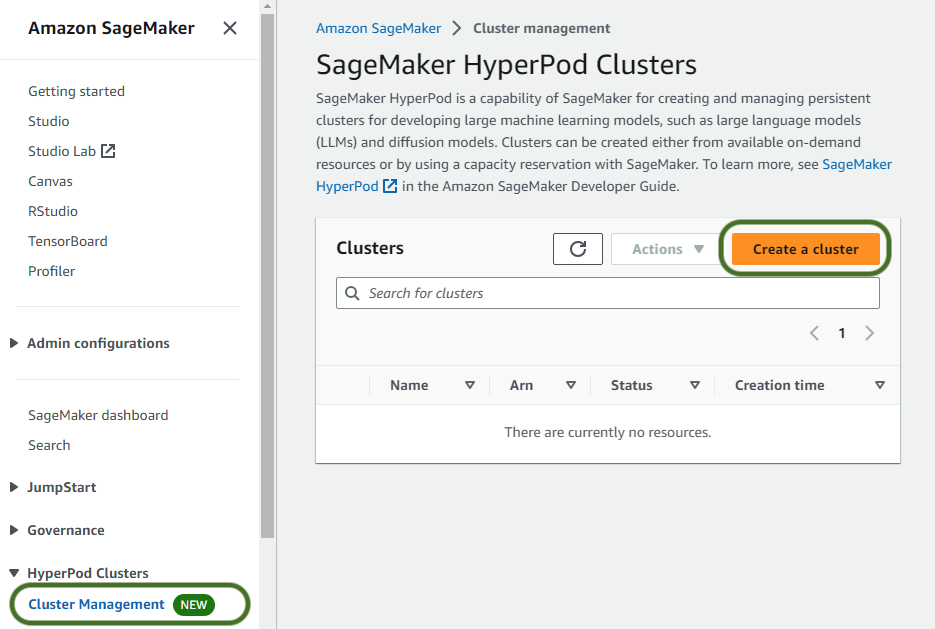
Pour créer votre cluster SageMaker HyperPod, procédez comme suit :
- Sur la console SageMaker, choisissez Gestion des grappes sous Clusters HyperPod dans le volet de navigation.
- Selectionnez Créer un cluster.
- Fournissez un nom de cluster et éventuellement des balises à appliquer aux ressources du cluster, puis choisissez Suivant.
- Sélectionnez Créer un groupe d'instances et spécifiez le nom du groupe d'instances, le type d'instance requis, la quantité d'instances souhaitée, ainsi que le chemin du compartiment S3 et du préfixe où vous avez copié précédemment vos scripts de cycle de vie de cluster.
Il est recommandé d'avoir différents groupes d'instances pour les nœuds de contrôleur utilisés pour administrer le cluster et soumettre des tâches et pour les nœuds de travail utilisés pour exécuter des tâches de formation à l'aide d'instances de calcul accélérées. Vous pouvez éventuellement configurer un groupe d'instances supplémentaire pour les nœuds de connexion.
- Vous créez d’abord le groupe d’instances de contrôleur, qui inclura le nœud principal du cluster.
- Pour ce groupe d'instances Gestion des identités et des accès AWS (IAM), choisissez Créer un nouveau rôle et spécifiez tous les compartiments S3 auxquels vous souhaitez que les instances de cluster du groupe d'instances aient accès.
Le rôle généré se verra accorder par défaut un accès en lecture seule aux compartiments spécifiés.
- Selectionnez Créer un rôle.
- Entrez le nom du script à exécuter lors de chaque création d'instance dans l'invite de script de création. Dans cet exemple, le script de création est appelé
on_create.sh.
- Selectionnez Épargnez.
- Selectionnez Créer un groupe d'instances pour créer votre groupe d'instances de travail.
- Fournissez tous les détails demandés, y compris le type d’instance et la quantité souhaitée.
Cet exemple utilise quatre instances accélérées ml.trn1.32xl pour effectuer notre travail de formation. Vous pouvez utiliser le même rôle IAM qu'avant ou personnaliser le rôle pour les instances de travail. De même, vous pouvez utiliser des scripts de cycle de vie de création différents pour ce groupe d'instances de travail et pour le groupe d'instances précédent.
- Selectionnez Suivant procéder.
- Choisissez le VPC, le sous-réseau et les groupes de sécurité souhaités pour vos instances de cluster.
Nous hébergeons les instances de cluster dans une seule zone de disponibilité et un seul sous-réseau pour garantir une faible latence.
Notez que si vous accédez fréquemment aux données S3, il est recommandé de créer un point de terminaison VPC associé à la table de routage du sous-réseau privé afin de réduire les coûts potentiels de transfert de données.
- Selectionnez Suivant.

- Consultez le résumé des détails du cluster, puis choisissez Envoyer.
Alternativement, pour créer votre SageMaker HyperPod à l'aide de l'AWS CLI, personnalisez d'abord les paramètres JSON utilisés pour créer le cluster :
Utilisez ensuite la commande suivante pour créer le cluster à l'aide des entrées fournies :
Exécutez votre première tâche de formation avec Llama 2
A noter que l'utilisation du modèle Llama 2 est régie par la licence Meta. Pour télécharger les poids des modèles et le tokenizer, visitez le site de NDN Collective et acceptez la licence avant de demander l'accès sur Site Web de Meta's Hugging Face.
Une fois le cluster exécuté, connectez-vous à Session Manager à l'aide de l'ID du cluster, du nom du groupe d'instances et de l'ID de l'instance. Utilisez la commande suivante pour afficher les détails de votre cluster :
Notez l'ID de cluster inclus dans l'ARN du cluster dans la réponse.
Utilisez la commande suivante pour récupérer le nom du groupe d'instances et l'ID d'instance nécessaires pour vous connecter au cluster.
Prenez note du InstanceGroupName et par InstanceId dans la réponse car ceux-ci seront utilisés pour se connecter à l'instance avec Session Manager.
Vous utilisez maintenant Session Manager pour vous connecter au nœud principal ou à l'un des nœuds de connexion et exécuter votre tâche de formation :
Ensuite, nous allons préparer l'environnement et télécharger Llama 2 et l'ensemble de données RedPajama. Pour obtenir le code complet et une présentation étape par étape, suivez les instructions sur le Formation distribuée AWSome Repo GitHub.
Suivez les étapes détaillées dans le 2.test_cases/8.neuronx-nemo-megatron/README.md déposer. Après avoir suivi les étapes de préparation de l'environnement, de préparation du modèle, de téléchargement et de tokenisation de l'ensemble de données et de précompilation du modèle, vous devez modifier le fichier. 6.pretrain-model.sh scénario et le sbatch commande de soumission de tâches pour inclure un paramètre qui vous permettra de profiter de la fonctionnalité de reprise automatique de SageMaker HyperPod.
Modifiez le sbatch ligne pour ressembler à ce qui suit :
Après avoir soumis le travail, vous recevrez un JobID que vous pouvez utiliser pour vérifier l'état du travail à l'aide du code suivant :
De plus, vous pouvez surveiller la tâche en suivant le journal de sortie de la tâche à l'aide du code suivant :
Nettoyer
Pour supprimer votre cluster SageMaker HyperPod, utilisez la console SageMaker ou la commande AWS CLI suivante :
Conclusion
Cet article vous a montré comment préparer votre environnement AWS, déployer votre premier cluster SageMaker HyperPod et former un modèle Llama 7 de 2 milliards de paramètres. SageMaker HyperPod est aujourd'hui généralement disponible dans les régions Amériques (Virginie du Nord, Ohio et Oregon), Asie-Pacifique (Singapour, Sydney et Tokyo) et Europe (Francfort, Irlande et Stockholm). Ils peuvent être déployés via la console SageMaker, l'AWS CLI et les SDK AWS, et prennent en charge les familles d'instances p4d, p4de, p5, trn1, inf2, g5, c5, c5n, m5 et t3.
Pour en savoir plus sur SageMaker HyperPod, visitez HyperPod Amazon SageMaker.
À propos des auteurs
 Brad Doran est responsable de compte technique senior chez Amazon Web Services, axé sur l'IA générative. Il est chargé de résoudre les défis d’ingénierie pour les clients de l’IA générative dans le segment du marché des entreprises numériques natives. Il est issu du milieu des infrastructures et du développement de logiciels et poursuit actuellement des études doctorales et des recherches en intelligence artificielle et en apprentissage automatique.
Brad Doran est responsable de compte technique senior chez Amazon Web Services, axé sur l'IA générative. Il est chargé de résoudre les défis d’ingénierie pour les clients de l’IA générative dans le segment du marché des entreprises numériques natives. Il est issu du milieu des infrastructures et du développement de logiciels et poursuit actuellement des études doctorales et des recherches en intelligence artificielle et en apprentissage automatique.
 Keïta Watanabe est architecte de solutions spécialiste senior GenAI chez Amazon Web Services, où il aide à développer des solutions d'apprentissage automatique à l'aide de projets OSS tels que Slurm et Kubernetes. Son expérience est dans la recherche et le développement en apprentissage automatique. Avant de rejoindre AWS, Keita a travaillé dans le secteur du commerce électronique en tant que chercheur scientifique développant des systèmes de récupération d'images pour la recherche de produits. Keita est titulaire d'un doctorat en sciences de l'Université de Tokyo.
Keïta Watanabe est architecte de solutions spécialiste senior GenAI chez Amazon Web Services, où il aide à développer des solutions d'apprentissage automatique à l'aide de projets OSS tels que Slurm et Kubernetes. Son expérience est dans la recherche et le développement en apprentissage automatique. Avant de rejoindre AWS, Keita a travaillé dans le secteur du commerce électronique en tant que chercheur scientifique développant des systèmes de récupération d'images pour la recherche de produits. Keita est titulaire d'un doctorat en sciences de l'Université de Tokyo.
 Justin Pirtle est architecte de solutions principal chez Amazon Web Services. Il conseille régulièrement les clients de l'IA générative dans la conception, le déploiement et la mise à l'échelle de leur infrastructure. Il intervient régulièrement lors des conférences AWS, notamment re:Invent, ainsi que d'autres événements AWS. Justin est titulaire d'un baccalauréat en systèmes d'information de gestion de l'Université du Texas à Austin et d'une maîtrise en génie logiciel de l'Université de Seattle.
Justin Pirtle est architecte de solutions principal chez Amazon Web Services. Il conseille régulièrement les clients de l'IA générative dans la conception, le déploiement et la mise à l'échelle de leur infrastructure. Il intervient régulièrement lors des conférences AWS, notamment re:Invent, ainsi que d'autres événements AWS. Justin est titulaire d'un baccalauréat en systèmes d'information de gestion de l'Université du Texas à Austin et d'une maîtrise en génie logiciel de l'Université de Seattle.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-hyperpod-to-train-foundation-models-at-scale/
- :est
- :où
- $UP
- 1
- 100
- 12
- 14
- 24
- 7
- a
- capacité
- Qui sommes-nous
- accéléré
- accélérateurs
- Accepter
- accès
- accessibilité
- accès
- Compte
- à travers
- ajout
- Supplémentaire
- adresses
- administrer
- administratif
- Avantage
- Après
- AI
- Tous
- allocation
- permettre
- permet
- aussi
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- Amériques
- quantités
- an
- ainsi que les
- tous
- Appliquer
- architectural
- SONT
- survenir
- artificiel
- intelligence artificielle
- L'INTELLIGENCE ARTIFICIELLE ET LE MACHINE LEARNING
- AS
- Asie
- Asie-Pacifique
- associé
- At
- austin
- Automatisation
- automatiquement
- disponibilité
- disponibles
- AWS
- fond
- BE
- devient
- before
- jusqu'à XNUMX fois
- milliards
- blocage
- construire
- Développement
- la performance des entreprises
- by
- appelé
- CAN
- capacités
- aptitude
- Compétences
- CEO
- challenge
- globaux
- Modifications
- vérifier
- Contrôles
- Selectionnez
- client
- Grappe
- code
- Collective
- vient
- Communication
- Communications
- Société
- complet
- composants électriques
- calcul
- informatique
- conférences
- configuration
- Configurer
- NOUS CONTACTER
- connexion
- Connexions
- Console
- continuer
- contrôleur
- Prix
- cher
- Costs
- engendrent
- La création
- création
- Lecture
- Customiser
- Clients
- personnaliser
- sont adaptées
- cycle
- cycles
- tableau de bord
- données
- jours
- affaire
- Réglage par défaut
- Degré
- déployer
- déployé
- déployer
- conception
- voulu
- détaillé
- détails
- développer
- développement
- Développement
- différent
- La diffusion
- numérique
- Perturbation
- distribué
- informatique distribuée
- formation distribuée
- download
- deux
- pendant
- chacun
- e-commerce
- non plus
- l'élimination
- permettre
- Endpoint
- ENGINEERING
- assurer
- Tout
- Environment
- environnementales
- établir
- Ether (ETH)
- Europe
- Pourtant, la
- événement
- événements
- exemple
- excité
- cher
- supplémentaire
- Visage
- Échoué
- échoue
- Échec
- échecs
- familles
- plus rapide
- défectueux
- Fonctionnalité
- Fonctionnalités:
- Déposez votre dernière attestation
- Prénom
- concentré
- suivre
- Abonnement
- Pour
- anciennement
- trouvé
- Fondation
- fondateur
- Fondateur et PDG
- quatre
- Framework
- Francfort
- fréquent
- fréquemment
- de
- plein
- d’étiquettes électroniques entièrement
- généralement
- généré
- génératif
- IA générative
- obtenez
- GitHub
- objectif
- aller
- régie
- accordée
- Réservation de groupe
- Groupes
- manipuler
- Matériel
- Vous avez
- ayant
- he
- front
- Elle nettoie et amplifie les énergies et les cristaux
- Santé
- la santé
- lourd
- levage de charges lourdes
- aide
- Haute
- Calcul Haute Performance
- de haut niveau
- haute performance
- le plus élevé
- très
- sa
- détient
- hôte
- Comment
- How To
- hpc
- HTML
- http
- HTTPS
- Des centaines
- IAM
- ID
- Identite
- Idle
- if
- image
- Immédiat
- Mettre en oeuvre
- améliorer
- in
- comprendre
- inclus
- Y compris
- Améliore
- industrie
- d'information
- Systèmes D'Information
- Infrastructure
- entrées
- installer
- instance
- cas
- Des instructions
- des services
- Intègre
- Intelligence
- interagir
- Interactif
- Interfaces
- interrompu
- développement
- Découvrez le tout nouveau
- impliqué
- Irlande
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- Emploi
- Emplois
- joindre
- jpg
- json
- Justin
- connu
- Kubernetes
- gros
- grande échelle
- Latence
- plus tard
- Nouveautés
- conduisant
- APPRENTISSAGE
- apprentissage
- bibliothèques
- Bibliothèque
- Licence
- vos produits
- lifting
- comme
- Gamme
- linux
- Flamme
- locales
- enregistrer
- vous connecter
- Style
- ressembler
- pas à perdre
- Faible
- click
- machine learning
- maintenir
- le maintien
- a prendre une
- FAIT DU
- Fabrication
- gérés
- gestion
- Système de gestion
- manager
- Marché
- maîtrise
- Matière
- Maximisez
- Meta
- minutes
- ML
- Mode
- modèle
- numériques jumeaux (digital twin models)
- Villas Modernes
- Surveiller
- surveillé
- Stack monitoring
- mois
- PLUS
- la plupart
- prénom
- indigène
- Navigation
- Besoin
- nécessaire
- besoin
- réseau et
- Nouveauté
- Nouvelles fonctionnalités
- nœud
- nœuds
- noter
- maintenant
- Nvidia
- se produire
- of
- Ohio
- on
- À la demande
- ONE
- ouvert
- open source
- d'exploitation
- opérationnel
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- l'optimisation
- or
- orchestration
- Oregon
- Oss
- Autre
- nos
- sortie
- plus de
- Pacifique
- pain
- Parallèle
- paramètre
- paramètres
- En passant
- chemin
- effectuer
- performant
- phd
- Platon
- Intelligence des données Platon
- PlatonDonnées
- plug-in
- Populaire
- Post
- défaillances
- Préparer
- précédent
- précédemment
- Directeur
- Avant
- Privé
- Cybersécurité
- procéder
- traitement
- Produit
- Progrès
- projets
- à condition de
- fournit
- aportando
- Édition
- la poursuite de
- Quantité
- RE
- recommandé
- récupération
- réduire
- reportez-vous
- région
- régions
- Standard
- régulièrement
- supprimez
- réparation
- remplacer
- remplacement
- nécessaire
- demandé
- exigent
- a besoin
- un article
- Recherche et développement
- réservation
- Réserver
- résilient
- ressource
- Resources
- réponse
- responsables
- CV
- Rôle
- routage
- Courir
- pour le running
- fonctionne
- sagemaker
- même
- Épargnez
- Escaliers intérieurs
- mise à l'échelle
- Sciences
- Scientifique
- scénario
- scripts
- SDK
- fluide
- Rechercher
- Seattle
- sécurité
- sur le lien
- clignotant
- supérieur
- besoin
- service
- Services
- Session
- set
- Partager
- devrait
- montré
- De même
- étapes
- simplifié
- Singapour
- unique
- faibles
- Logiciels
- développement de logiciels
- génie logiciel
- Solutions
- Résoudre
- Identifier
- Speaker
- spécialiste
- groupe de neurones
- spécifié
- passer
- scission
- Stabilité
- stable
- Normes
- Commencer
- state-of-the-art
- Statut
- Étapes
- storage
- Boutique
- simple
- études
- Soumission
- soumettre
- soumis
- sous-réseau
- tel
- Combinaison
- suite
- RÉSUMÉ
- Support
- Appuyer
- sûr
- sydney
- synchroniser.
- combustion propre
- Système
- table
- Prenez
- Technique
- dizaines
- terminal
- Texas
- que
- qui
- Les
- leur
- Les
- puis
- Ces
- l'ont
- this
- milliers
- Avec
- tout au long de
- fiable
- à
- aujourd'hui
- tokenize
- tokyo
- Train
- Formation
- transférer
- type
- types
- sous
- université
- Université de Tokyo
- Mises à jour
- utilisé
- d'utiliser
- Utilisateur
- utilisateurs
- Usages
- en utilisant
- utilitaire
- Utilisant
- divers
- Vaste
- version
- via
- Voir
- Virginie
- Salle de conférence virtuelle
- Visiter
- walkthrough
- était
- Façon..
- we
- web
- services Web
- Semaines
- WELL
- quand
- qui
- tout en
- largement
- Wikipédia
- sera
- comprenant
- dans les
- sans
- travaillé
- travailleur
- pourra
- you
- Votre
- zéphyrnet