Les intégrations jouent un rôle clé dans le traitement du langage naturel (NLP) et l'apprentissage automatique (ML). Incorporation de texte fait référence au processus de transformation du texte en représentations numériques résidant dans un espace vectoriel de grande dimension. Cette technique est réalisée grâce à l'utilisation d'algorithmes ML qui permettent de comprendre la signification et le contexte des données (relations sémantiques) et l'apprentissage de relations et de modèles complexes au sein des données (relations syntaxiques). Vous pouvez utiliser les représentations vectorielles résultantes pour un large éventail d'applications, telles que la recherche d'informations, la classification de texte, le traitement du langage naturel et bien d'autres.
Intégrations de texte Amazon Titan est un modèle d'intégration de texte qui convertit le texte en langage naturel (composé de mots simples, d'expressions ou même de documents volumineux) en représentations numériques pouvant être utilisées pour alimenter des cas d'utilisation tels que la recherche, la personnalisation et le regroupement basés sur la similarité sémantique.
Dans cet article, nous discutons du modèle Amazon Titan Text Embeddings, de ses fonctionnalités et d'exemples de cas d'utilisation.
Certains concepts clés incluent :
- La représentation numérique du texte (vecteurs) capture la sémantique et les relations entre les mots
- Des intégrations riches peuvent être utilisées pour comparer la similarité du texte
- Les intégrations de texte multilingues peuvent identifier la signification dans différentes langues
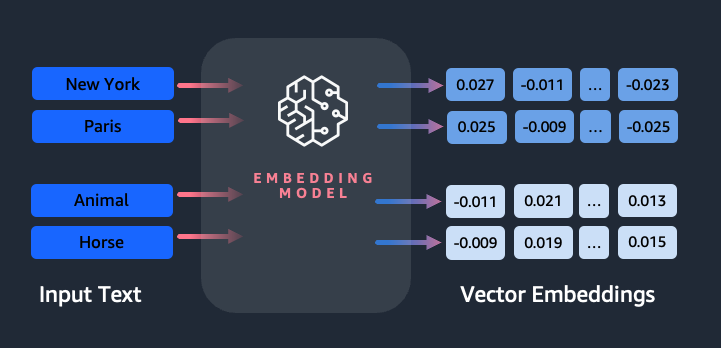
Comment un morceau de texte est-il converti en vecteur ?
Il existe plusieurs techniques pour convertir une phrase en vecteur. Une méthode populaire consiste à utiliser des algorithmes d'intégration de mots, tels que Word2Vec, GloVe ou FastText, puis à agréger les intégrations de mots pour former une représentation vectorielle au niveau de la phrase.
Une autre approche courante consiste à utiliser des modèles de langage étendus (LLM), comme BERT ou GPT, qui peuvent fournir des intégrations contextualisées pour des phrases entières. Ces modèles sont basés sur des architectures d'apprentissage en profondeur telles que Transformers, qui peuvent capturer plus efficacement les informations contextuelles et les relations entre les mots dans une phrase.
Pourquoi avons-nous besoin d’un modèle d’intégration ?
Les intégrations de vecteurs sont fondamentales pour que les LLM comprennent les degrés sémantiques du langage et permettent également aux LLM de bien fonctionner sur les tâches NLP en aval telles que l'analyse des sentiments, la reconnaissance d'entités nommées et la classification de texte.
En plus de la recherche sémantique, vous pouvez utiliser des intégrations pour augmenter vos invites et obtenir des résultats plus précis grâce à la génération augmentée de récupération (RAG). Mais pour les utiliser, vous devrez les stocker dans une base de données dotée de capacités vectorielles.
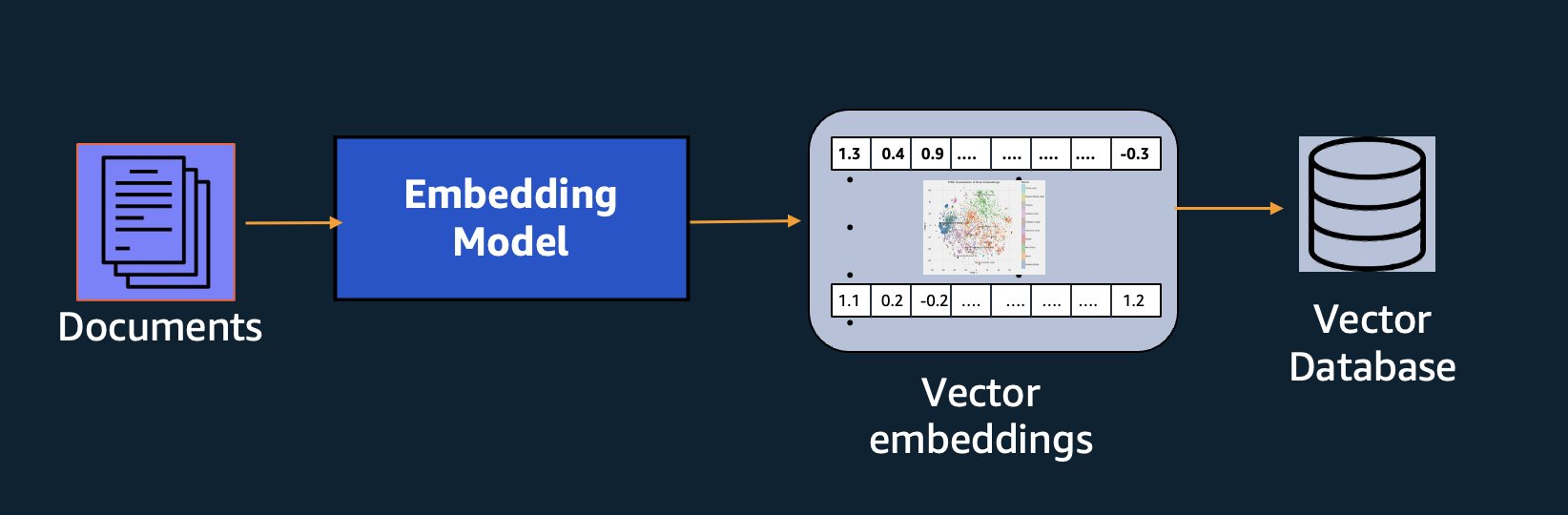
Le modèle Amazon Titan Text Embeddings est optimisé pour la récupération de texte afin de permettre les cas d'utilisation de RAG. Il vous permet de convertir d'abord vos données textuelles en représentations numériques ou vectorielles, puis d'utiliser ces vecteurs pour rechercher avec précision des passages pertinents à partir d'une base de données vectorielles, vous permettant ainsi de tirer le meilleur parti de vos données propriétaires en combinaison avec d'autres modèles de base.
Étant donné qu'Amazon Titan Text Embeddings est un modèle géré sur Socle amazonien, il est proposé comme une expérience entièrement sans serveur. Vous pouvez l'utiliser via Amazon Bedrock REST API ou le kit SDK AWS. Les paramètres requis sont le texte dont vous souhaitez générer les intégrations et le modelID paramètre, qui représente le nom du modèle Amazon Titan Text Embeddings. Le code suivant est un exemple utilisant le kit AWS SDK pour Python (Boto3) :
Le résultat ressemblera à ceci :
Reportez-vous à Configuration du boto3 d'Amazon Bedrock pour plus de détails sur la façon d'installer les packages requis, de vous connecter à Amazon Bedrock et d'appeler des modèles.
Caractéristiques des intégrations de texte Amazon Titan
Avec Amazon Titan Text Embeddings, vous pouvez saisir jusqu'à 8,000 1536 jetons, ce qui le rend parfaitement adapté pour travailler avec des mots simples, des phrases ou des documents entiers en fonction de votre cas d'utilisation. Amazon Titan renvoie des vecteurs de sortie de dimension XNUMX XNUMX, ce qui lui confère un haut degré de précision, tout en optimisant également les résultats à faible latence et rentables.
Amazon Titan Text Embeddings prend en charge la création et l'interrogation d'intégrations de texte dans plus de 25 langues différentes. Cela signifie que vous pouvez appliquer le modèle à vos cas d'utilisation sans avoir besoin de créer et de gérer des modèles distincts pour chaque langue que vous souhaitez prendre en charge.
Disposer d'un seul modèle d'intégration formé sur de nombreuses langues offre les avantages clés suivants :
- Portée plus large – En prenant en charge plus de 25 langues dès le départ, vous pouvez étendre la portée de vos applications aux utilisateurs et au contenu sur de nombreux marchés internationaux.
- Des performances constantes – Avec un modèle unifié couvrant plusieurs langues, vous obtenez des résultats cohérents dans toutes les langues au lieu d’optimiser séparément par langue. Le modèle est formé de manière holistique afin que vous puissiez bénéficier d'un avantage dans toutes les langues.
- Prise en charge des requêtes multilingues – Amazon Titan Text Embeddings permet d'interroger des intégrations de texte dans n'importe quelle langue prise en charge. Cela offre la flexibilité de récupérer du contenu sémantiquement similaire dans plusieurs langues sans être limité à une seule langue. Vous pouvez créer des applications qui interrogent et analysent des données multilingues en utilisant le même espace d'intégration unifié.
Au moment d'écrire ces lignes, les langues suivantes sont prises en charge :
- Arabe
- Chinois simplifié)
- Chinois (traditionnel)
- Tchèque
- Néerlandais
- Anglais
- Français
- Allemand
- Hébreu
- Hindi
- Italien
- Japonais
- Kannada
- Coréen
- Malayalam
- Marathi
- Polonais
- Portugais
- Russe
- Espagnol
- Suédois
- Tagalog philippin
- Tamoul
- telugu
- Turc
Utilisation des intégrations de texte Amazon Titan avec LangChain
LangChaîne est un framework open source populaire pour travailler avec des modèles d'IA génératifs et des technologies de support. Il comprend un Client BedrockEmbeddings qui enveloppe commodément le SDK Boto3 avec une couche d'abstraction. Le BedrockEmbeddings Le client vous permet de travailler directement avec du texte et des intégrations, sans connaître les détails de la requête JSON ou des structures de réponse. Voici un exemple simple :
Vous pouvez également utiliser LangChain BedrockEmbeddings client aux côtés du client Amazon Bedrock LLM pour simplifier la mise en œuvre de RAG, de la recherche sémantique et d'autres modèles liés aux intégrations.
Cas d'utilisation pour les intégrations
Bien que RAG soit actuellement le cas d'utilisation le plus populaire pour travailler avec des intégrations, il existe de nombreux autres cas d'utilisation dans lesquels les intégrations peuvent être appliquées. Voici quelques scénarios supplémentaires dans lesquels vous pouvez utiliser les intégrations pour résoudre des problèmes spécifiques, seuls ou en coopération avec un LLM :
- Questions et réponses – Les intégrations peuvent aider à prendre en charge les interfaces de questions et réponses via le modèle RAG. La génération d'intégrations associée à une base de données vectorielle vous permet de trouver des correspondances étroites entre les questions et le contenu dans un référentiel de connaissances.
- Recommandations personnalisées – Semblable aux questions et réponses, vous pouvez utiliser les intégrations pour rechercher des destinations de vacances, des universités, des véhicules ou d'autres produits en fonction des critères fournis par l'utilisateur. Cela peut prendre la forme d'une simple liste de correspondances, ou vous pouvez ensuite utiliser un LLM pour traiter chaque recommandation et expliquer comment elle répond aux critères de l'utilisateur. Vous pouvez également utiliser cette approche pour générer les « 10 meilleurs » articles personnalisés pour un utilisateur en fonction de ses besoins spécifiques.
- Gestion de données – Lorsque vous disposez de sources de données qui ne correspondent pas clairement les unes aux autres, mais que vous disposez d'un contenu textuel décrivant l'enregistrement de données, vous pouvez utiliser les incorporations pour identifier les enregistrements en double potentiels. Par exemple, vous pouvez utiliser des intégrations pour identifier les candidats en double qui peuvent utiliser un formatage, des abréviations ou même des noms traduits.
- Rationalisation du portefeuille applicatif – Lorsqu'on cherche à aligner les portefeuilles d'applications au sein d'une société mère et d'une acquisition, il n'est pas toujours évident par où commencer pour détecter les chevauchements potentiels. La qualité des données de gestion de configuration peut être un facteur limitant, et il peut être difficile de coordonner les équipes pour comprendre le paysage des applications. En utilisant la correspondance sémantique avec les intégrations, nous pouvons effectuer une analyse rapide des portefeuilles d'applications afin d'identifier les applications candidates à fort potentiel pour la rationalisation.
- Regroupement de contenu – Vous pouvez utiliser les intégrations pour faciliter le regroupement de contenus similaires en catégories que vous ne connaissez peut-être pas à l’avance. Par exemple, disons que vous disposez d'une collection d'e-mails de clients ou d'avis de produits en ligne. Vous pouvez créer des intégrations pour chaque élément, puis exécuter ces intégrations via k-signifie clustering pour identifier des regroupements logiques de préoccupations des clients, d'éloges ou de plaintes sur les produits, ou d'autres thèmes. Vous pouvez ensuite générer des résumés ciblés à partir du contenu de ces groupements à l'aide d'un LLM.
Exemple de recherche sémantique
Dans notre exemple sur GitHub, nous démontrons une application de recherche d'intégrations simple avec Amazon Titan Text Embeddings, LangChain et Streamlit.
L'exemple fait correspondre la requête d'un utilisateur aux entrées les plus proches dans une base de données vectorielle en mémoire. Nous affichons ensuite ces correspondances directement dans l'interface utilisateur. Cela peut être utile si vous souhaitez dépanner une application RAG ou évaluer directement un modèle d'intégration.
Pour plus de simplicité, nous utilisons le système en mémoire FAISS base de données pour stocker et rechercher des vecteurs d'intégration. Dans un scénario réel à grande échelle, vous souhaiterez probablement utiliser un magasin de données persistant tel que moteur vectoriel pour Amazon OpenSearch Serverless au sein de l’ pgvecteur extension pour PostgreSQL.
Essayez quelques invites de l'application Web dans différentes langues, telles que les suivantes :
- Comment puis-je suivre ma consommation ?
- Comment puis-je personnaliser les modèles ?
- Quels langages de programmation puis-je utiliser ?
- Comment mes données sont-elles sécurisées ?
- Est-ce que c'est vrai ?
- Quels fournisseurs de modèles sont disponibles pour moi à Bedrock ?
- Dans certaines régions, le substrat rocheux amazonien est-il disponible ?
- 有哪些级别的支持?
Notez que même si le matériel source était en anglais, les requêtes dans d'autres langues ont été mises en correspondance avec les entrées pertinentes.
Conclusion
Les capacités de génération de texte des modèles de base sont très intéressantes, mais il est important de se rappeler que comprendre le texte, trouver le contenu pertinent à partir d'un ensemble de connaissances et établir des liens entre les passages sont essentiels pour tirer pleinement parti de l'IA générative. Nous continuerons de voir émerger de nouveaux cas d’utilisation intéressants pour les intégrations au cours des prochaines années, à mesure que ces modèles continueront de s’améliorer.
Prochaines étapes
Vous pouvez trouver d’autres exemples d’intégrations sous forme de blocs-notes ou d’applications de démonstration dans les ateliers suivants :
À propos des auteurs
 Jason Stehle est un architecte de solutions senior chez AWS, basé dans la région de la Nouvelle-Angleterre. Il travaille avec les clients pour aligner les fonctionnalités AWS sur leurs plus grands défis commerciaux. En dehors du travail, il passe son temps à construire des objets et à regarder des films de bandes dessinées avec sa famille.
Jason Stehle est un architecte de solutions senior chez AWS, basé dans la région de la Nouvelle-Angleterre. Il travaille avec les clients pour aligner les fonctionnalités AWS sur leurs plus grands défis commerciaux. En dehors du travail, il passe son temps à construire des objets et à regarder des films de bandes dessinées avec sa famille.
 Nitin Eusèbe est un architecte de solutions d'entreprise senior chez AWS, expérimenté en génie logiciel, en architecture d'entreprise et en IA/ML. Il est profondément passionné par l’exploration des possibilités de l’IA générative. Il collabore avec les clients pour les aider à créer des applications bien architecturées sur la plateforme AWS, et se consacre à résoudre les défis technologiques et à les accompagner dans leur transition vers le cloud.
Nitin Eusèbe est un architecte de solutions d'entreprise senior chez AWS, expérimenté en génie logiciel, en architecture d'entreprise et en IA/ML. Il est profondément passionné par l’exploration des possibilités de l’IA générative. Il collabore avec les clients pour les aider à créer des applications bien architecturées sur la plateforme AWS, et se consacre à résoudre les défis technologiques et à les accompagner dans leur transition vers le cloud.
 Raj Pathak est architecte de solutions principal et conseiller technique auprès de grandes entreprises Fortune 50 et d'institutions de services financiers (FSI) de taille moyenne au Canada et aux États-Unis. Il se spécialise dans les applications d'apprentissage automatique telles que l'IA générative, le traitement du langage naturel, le traitement intelligent de documents et le MLOps.
Raj Pathak est architecte de solutions principal et conseiller technique auprès de grandes entreprises Fortune 50 et d'institutions de services financiers (FSI) de taille moyenne au Canada et aux États-Unis. Il se spécialise dans les applications d'apprentissage automatique telles que l'IA générative, le traitement du langage naturel, le traitement intelligent de documents et le MLOps.
 Mani Khanouja est responsable technique – Spécialistes de l'IA générative, auteur du livre – Apprentissage automatique appliqué et calcul haute performance sur AWS, et membre du conseil d'administration de la Women in Manufacturing Education Foundation. Elle dirige des projets d'apprentissage automatique (ML) dans divers domaines tels que la vision par ordinateur, le traitement du langage naturel et l'IA générative. Elle aide les clients à créer, former et déployer de grands modèles d'apprentissage automatique à grande échelle. Elle intervient lors de conférences internes et externes telles que re:Invent, Women in Manufacturing West, les webinaires YouTube et GHC 23. Pendant son temps libre, elle aime faire de longues courses le long de la plage.
Mani Khanouja est responsable technique – Spécialistes de l'IA générative, auteur du livre – Apprentissage automatique appliqué et calcul haute performance sur AWS, et membre du conseil d'administration de la Women in Manufacturing Education Foundation. Elle dirige des projets d'apprentissage automatique (ML) dans divers domaines tels que la vision par ordinateur, le traitement du langage naturel et l'IA générative. Elle aide les clients à créer, former et déployer de grands modèles d'apprentissage automatique à grande échelle. Elle intervient lors de conférences internes et externes telles que re:Invent, Women in Manufacturing West, les webinaires YouTube et GHC 23. Pendant son temps libre, elle aime faire de longues courses le long de la plage.
 Marc Roy est un architecte principal d'apprentissage machine pour AWS, aidant les clients à concevoir et à créer des solutions d'IA/ML. Le travail de Mark couvre un large éventail de cas d'utilisation du ML, avec un intérêt principal pour la vision par ordinateur, l'apprentissage en profondeur et la mise à l'échelle du ML dans l'entreprise. Il a aidé des entreprises dans de nombreux secteurs, notamment l'assurance, les services financiers, les médias et le divertissement, la santé, les services publics et la fabrication. Mark détient six certifications AWS, y compris la certification de spécialité ML. Avant de rejoindre AWS, Mark a été architecte, développeur et leader technologique pendant plus de 25 ans, dont 19 ans dans les services financiers.
Marc Roy est un architecte principal d'apprentissage machine pour AWS, aidant les clients à concevoir et à créer des solutions d'IA/ML. Le travail de Mark couvre un large éventail de cas d'utilisation du ML, avec un intérêt principal pour la vision par ordinateur, l'apprentissage en profondeur et la mise à l'échelle du ML dans l'entreprise. Il a aidé des entreprises dans de nombreux secteurs, notamment l'assurance, les services financiers, les médias et le divertissement, la santé, les services publics et la fabrication. Mark détient six certifications AWS, y compris la certification de spécialité ML. Avant de rejoindre AWS, Mark a été architecte, développeur et leader technologique pendant plus de 25 ans, dont 19 ans dans les services financiers.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :possède
- :est
- :ne pas
- :où
- $UP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- Qui sommes-nous
- abstraction
- Accepter
- précision
- Avec cette connaissance vient le pouvoir de prendre
- avec précision
- atteint
- la réalisation de
- acquisition
- à travers
- ajout
- Supplémentaire
- Avantage
- conseiller
- devant
- AI
- Modèles AI
- AI / ML
- algorithmes
- aligner
- Tous
- permettre
- Permettre
- permet
- le long de
- aux côtés de
- aussi
- toujours
- Amazon
- Amazon Web Services
- an
- selon une analyse de l’Université de Princeton
- il analyse
- ainsi que le
- répondre
- tous
- Application
- applications
- appliqué
- Appliquer
- une approche
- architecture
- architectures
- SONT
- Réservé
- sur notre blog
- AS
- assistant
- At
- augmenter
- augmentée
- auteur
- disponibles
- AWS
- basé
- BE
- Plage
- va
- avantages.
- jusqu'à XNUMX fois
- planche
- conseil d'administration
- corps
- livre
- Box
- construire
- Développement
- la performance des entreprises
- mais
- by
- CAN
- Canada
- candidat
- candidats
- capacités
- capturer
- captures
- maisons
- cas
- catégories
- Certifications
- certifications
- globaux
- classification
- client
- Fermer
- le cloud
- regroupement
- code
- collection
- Collèges
- combinaison
- Commun
- Sociétés
- Société
- comparer
- plaintes
- complexe
- ordinateur
- Vision par ordinateur
- informatique
- concepts
- Préoccupations
- conférences
- configuration
- NOUS CONTACTER
- connexion
- Connexions
- cohérent
- contenu
- contexte
- contextuel
- continuer
- commodément
- convertir
- converti
- coopération
- coordination
- rentable
- pourriez
- couvrant
- couvre
- engendrent
- La création
- critères
- crucial
- Lecture
- Customiser
- des clients
- Clients
- personnaliser
- données
- Base de données
- de
- dévoué
- profond
- l'apprentissage en profondeur
- profondément
- Vous permet de définir
- Degré
- Démo
- démontrer
- déployer
- décrit
- Conception
- destinations
- détails
- Développeur
- différent
- difficile
- Dimension
- directement
- Administration
- discuter
- Commande
- do
- document
- INSTITUTIONNELS
- domaines
- Ne pas
- chacun
- Éducation
- de manière efficace
- non plus
- emails
- enrobage
- émerger
- permettre
- permet
- Moteur
- ENGINEERING
- de l'Angleterre
- Anglais
- Entreprise
- Solutions d'entreprise
- Divertissement
- Tout
- entièrement
- entité
- Ether (ETH)
- évaluer
- Pourtant, la
- exemple
- exemples
- passionnant
- Développer vous
- d'experience
- expérimenté
- Expliquer
- Explorer
- extension
- externe
- faciliter
- facteur
- famille
- Fonctionnalités:
- few
- la traduction de documents financiers
- services financiers
- Trouvez
- trouver
- Prénom
- Flexibilité
- concentré
- Abonnement
- Pour
- formulaire
- fortune
- Fondation
- Framework
- Gratuit
- De
- plein
- fondamental
- générer
- génération
- génératif
- IA générative
- obtenez
- obtention
- Don
- gant
- Go
- plus
- ait eu
- Vous avez
- he
- la médecine
- vous aider
- a aidé
- aider
- aide
- ici
- Haute
- Calcul Haute Performance
- sa
- détient
- Comment
- How To
- HTML
- HTTPS
- i
- identifier
- if
- la mise en œuvre
- importer
- important
- améliorer
- in
- Dans d'autres
- comprendre
- inclut
- Y compris
- secteurs
- d'information
- contribution
- installer
- plutôt ;
- les établissements privés
- Assurance
- Intelligent
- Traitement intelligent des documents
- intérêt
- intéressant
- Interfaces
- interfaces
- interne
- International
- développement
- IT
- SES
- joindre
- chemin
- jpg
- json
- ACTIVITES
- Savoir
- connaissance
- spécialisées
- paysage d'été
- langue
- Langues
- gros
- couche
- conduire
- leader
- Conduit
- apprentissage
- laisser
- comme
- Probable
- aime
- limiter
- Liste
- llm
- logique
- Location
- Style
- recherchez-
- click
- machine learning
- maintenir
- a prendre une
- Fabrication
- gérés
- gestion
- fabrication
- de nombreuses
- Localisation
- marque
- Des notes
- Marchés
- appariés
- allumettes
- assorti
- Matériel
- me
- sens
- veux dire
- Médias
- membre
- méthode
- pourrait
- ML
- Algorithmes ML
- MLOps
- modèle
- numériques jumeaux (digital twin models)
- Surveiller
- PLUS
- (en fait, presque toutes)
- Le Plus Populaire
- Films
- plusieurs
- my
- prénom
- Nommé
- noms
- Nature
- Langage naturel
- Traitement du langage naturel
- Besoin
- besoin
- Besoins
- Nouveauté
- next
- nlp
- ordinateurs portables
- évident
- of
- présenté
- on
- ONE
- en ligne
- ouvert
- open source
- optimisé
- l'optimisation
- or
- de commander
- Autre
- Autres
- nos
- ande
- sortie
- au contrôle
- plus de
- propre
- Forfaits
- apparié
- paramètre
- paramètres
- société mère
- des billets
- passionné
- Patron de Couture
- motifs
- /
- effectuer
- performant
- Personnalisation
- les expressions clés
- pièce
- plateforme
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Jouez
- veuillez cliquer
- Populaire
- PAR
- portefeuille
- portefeuilles
- possibilités
- Post
- Postgresql
- défaillances
- power
- primaire
- Directeur
- Imprimé
- Avant
- d'ouvrabilité
- processus
- traitement
- Produit
- Comparatifs
- Produits
- Programmation
- langages de programmation
- projets
- instructions
- propriétaire
- fournir
- à condition de
- fournit
- Python
- qualité
- requêtes
- question
- question
- fréquemment posées
- Rapide
- chiffon
- gamme
- RE
- nous joindre
- monde réel
- reconnaissance
- Recommandation
- recommandations
- record
- Articles
- se réfère
- Les relations
- pertinent
- rappeler
- dépôt
- représentation
- représente
- nécessaire
- conditions
- réponse
- REST
- limité
- résultant
- Résultats
- récupération
- Retours
- Avis
- Rôle
- Courir
- fonctionne
- s
- même
- dire
- Escaliers intérieurs
- mise à l'échelle
- scénario
- scénarios
- Sdk
- Rechercher
- sur le lien
- sémantique
- sémantique
- supérieur
- phrase
- sentiment
- séparé
- Sans serveur
- Services
- elle
- similaires
- étapes
- simplicité
- simplifié
- simplifier
- unique
- SIX
- So
- Logiciels
- génie logiciel
- Solutions
- RÉSOUDRE
- Résoudre
- quelques
- quelque chose
- Identifier
- Sources
- Space
- parle
- spécialistes
- spécialise
- Hébergement spécial
- groupe de neurones
- Commencer
- j'ai commencé
- États
- Boutique
- structures
- tel
- Support
- Appareils
- Appuyer
- Les soutiens
- Prenez
- tâches
- équipes
- technologie
- Technique
- technique
- techniques
- Les technologies
- Technologie
- dire
- texte
- Classification du texte
- génération de texte
- qui
- Les
- La Source
- leur
- Les
- thèmes
- puis
- Là.
- Ces
- des choses
- this
- ceux
- bien que?
- Avec
- fiable
- Titan
- à
- Tokens
- traditionnel
- Train
- qualifié
- transformateurs
- transformer
- comprendre
- compréhension
- unifiée
- Uni
- États-Unis
- Utilisation
- utilisé
- cas d'utilisation
- d'utiliser
- incontournable
- Utilisateur
- Interface utilisateur
- utilisateurs
- en utilisant
- les services publics
- vacances
- Plus-value
- divers
- Véhicules
- très
- via
- vision
- souhaitez
- était
- personne(s) regarde(nt) cette fiche produit
- we
- web
- application Web
- services Web
- Webinaires
- WELL
- ont été
- Ouest
- quand
- qui
- tout en
- large
- Large gamme
- sera
- comprenant
- dans les
- sans
- Femme
- Word
- des mots
- activités principales
- de travail
- vos contrats
- Ateliers
- pourra
- écrire
- écriture
- années
- you
- Votre
- Youtube
- zéphyrnet