Image par auteur
De nombreux modèles avancés d'apprentissage automatique tels que les forêts aléatoires ou les algorithmes d'amplification de gradient tels que XGBoost, CatBoost ou LightGBM (et même auto-encodeurs!) s'appuient sur un ingrédient commun crucial : le arbre de décision!
Sans comprendre les arbres de décision, il est impossible de comprendre également l'un des algorithmes avancés de bagging ou de gradient-boosting susmentionnés, ce qui est une honte pour tout data scientist ! Alors, démystifions le fonctionnement interne d'un arbre de décision en en implémentant un en Python.
Dans cet article, vous apprendrez
- pourquoi et comment un arbre de décision divise les données,
- le gain d'informations, et
- comment implémenter des arbres de décision en Python à l'aide de NumPy.
Vous pouvez trouver le code sur mon Github.
Pour faire des prédictions, les arbres de décision s'appuient sur scission l'ensemble de données en parties plus petites de manière récursive.

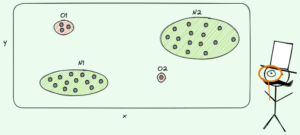
Image par auteur
Dans l'image ci-dessus, vous pouvez voir un exemple de division - l'ensemble de données d'origine est séparé en deux parties. À l'étape suivante, ces deux parties sont à nouveau divisées, et ainsi de suite. Cela continue jusqu'à ce qu'un certain critère d'arrêt soit rempli, par exemple,
- si la scission a pour résultat qu'une partie est vide
- si une certaine profondeur de récursivité a été atteinte
- si (après les fractionnements précédents) l'ensemble de données ne se compose que de quelques éléments, rendant inutiles les fractionnements supplémentaires.
Comment trouve-t-on ces clivages ? Et pourquoi s'en soucie-t-on ? Découvrons-le.
motivation
Supposons que l'on veuille résoudre un binaire problème de classement que nous nous créons maintenant :
import numpy as np
np.random.seed(0) X = np.random.randn(100, 2) # features
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)Les données bidimensionnelles ressemblent à ceci :

Image par auteur
Nous pouvons voir qu'il existe deux classes différentes - violet dans environ 75% et jaune dans environ 25% des cas. Si vous fournissez ces données à un arbre de décision classificateur, cet arbre a initialement les pensées suivantes :
« Il y a deux étiquettes différentes, ce qui est trop brouillon pour moi. Je veux nettoyer ce gâchis en divisant les données en deux parties - ces parties devraient être plus propres que les données complètes auparavant. — arbre qui a pris conscience
Et c'est ainsi que l'arbre fait.

Image par auteur
L'arbre décide de faire une scission approximativement le long de la x-axe. Cela a pour effet que la partie supérieure des données est maintenant parfaitement nettoyer, ce qui signifie que vous ne trouvez que une seule classe (violet dans ce cas) là.
Cependant, la partie inférieure est toujours malpropre, encore plus désordonné qu'avant dans un sens. Le rapport de classe était d'environ 75:25 dans l'ensemble de données complet, mais dans cette partie plus petite, il est d'environ 50:50, ce qui est aussi mélangé que possible.
Remarque: Ici, peu importe que le violet et le jaune soient bien séparés sur la photo. Seulement le quantité brute de différentes étiquettes dans les deux parties compter.

Image par auteur
Pourtant, c'est assez bon comme premier pas pour l'arbre, et ainsi de suite. Même si cela ne créerait pas une autre scission en haut, espace extérieur plus propre, partie plus, il peut créer une autre scission dans la partie inférieure pour la nettoyer.

Image par auteur
Et voilà, chacune des trois parties séparées est complètement propre, car on ne trouve qu'une seule couleur (étiquette) par partie.
Il est vraiment facile de faire des prédictions maintenant : si un nouveau point de données arrive, il vous suffit de vérifier dans lequel des trois parties il se trouve et donnez-lui la couleur correspondante. Cela fonctionne si bien maintenant parce que chaque partie est espace extérieur plus propre,. Facile, non ?

Image par auteur
Bon, on parlait de espace extérieur plus propre, ainsi que malpropre données, mais jusqu'à présent, ces mots ne représentent qu'une vague idée. Pour mettre en œuvre quoi que ce soit, nous devons trouver un moyen de définir propreté.
Mesures de propreté
Supposons que nous ayons des étiquettes, par exemple
y_1 = [0, 0, 0, 0, 0, 0, 0, 0] y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]Intuitivement, y₁ est le jeu d'étiquettes le plus propre, suivi de y₂ et alors y₃. Jusqu'ici tout va bien, mais comment pouvons-nous chiffrer ce comportement ? Peut-être que la chose la plus simple qui vous vient à l'esprit est la suivante :
Comptez simplement le nombre de zéros et le nombre de uns. Calculez leur différence absolue. Pour le rendre plus agréable, normalisez-le en divisant la longueur des tableaux.
Par exemple, y₂ a 8 entrées au total - 6 zéros et 2 uns. Par conséquent, notre personnalisé défini note de propreté serait |6 – 2| / 8 = 0.5. Il est facile de calculer que les scores de propreté de y₁ ainsi que y₃ sont respectivement de 1.0 et 0.0. Ici, nous pouvons voir la formule générale :

Image par auteur
Ici, n₀ ainsi que n₁ sont respectivement les nombres de zéros et de uns, n = n₀ + n₁ est la longueur du tableau et p₁ = n₁ / n est la part des 1 étiquettes.
Le problème avec cette formule est qu'elle est spécifiquement adapté au cas de deux classes, mais très souvent on s'intéresse à la classification multi-classes. Une formule qui fonctionne assez bien est la Mesure d'impureté Gini :

Image par auteur
ou le cas général :

Image par auteur
Ça marche si bien que scikit-learn l'a adopté comme mesure par défaut pour son DecisionTreeClassifier classe.

Image par auteur
Remarque: Mesures de Gini désordre au lieu de la propreté. Exemple : si une liste ne contient qu'une seule classe (=données très propres !), alors tous les termes de la somme sont nuls, donc la somme est nulle. Le pire des cas est si toutes les classes apparaissent le nombre exact de fois, auquel cas le Gini est de 1–1/C De C est le nombre de classes.
Maintenant que nous avons une mesure pour la propreté/le désordre, voyons comment elle peut être utilisée pour trouver de bonnes séparations.
Trouver des fractionnements
Il y a beaucoup de splits parmi lesquels choisir, mais lequel est le bon ? Utilisons à nouveau notre ensemble de données initial, ainsi que la mesure d'impureté de Gini.

Image par auteur
Nous ne compterons pas les points maintenant, mais supposons que 75 % sont violets et 25 % sont jaunes. En utilisant la définition de Gini, l'impureté de l'ensemble de données complet est

Image par auteur
Si nous divisons l'ensemble de données le long de la x-axe, comme fait avant :

Image par auteur
La la partie supérieure a une impureté Gini de 0.0 et la partie inférieure

Image par auteur
En moyenne, les deux parties ont une impureté Gini de (0.0 + 0.5) / 2 = 0.25, ce qui est mieux que les 0.375 de l'ensemble de données d'avant. Nous pouvons également l'exprimer en termes de ce qu'on appelle gain d'information:
Le gain d'information de cette division est de 0.375 - 0.25 = 0.125.
Facile comme ça. Plus le gain d'information est élevé (c'est-à-dire plus l'impureté Gini est faible), mieux c'est.
Remarque: Une autre division initiale tout aussi bonne serait le long de l'axe y.
Une chose importante à garder à l'esprit est qu'il est utile de peser les impuretés Gini des pièces par la taille des pièces. Par exemple, supposons que
- la partie 1 se compose de 50 points de données et a une impureté Gini de 0.0 et
- la partie 2 se compose de 450 points de données et a une impureté Gini de 0.5,
alors l'impureté Gini moyenne ne devrait pas être (0.0 + 0.5) / 2 = 0.25 mais plutôt 50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = 0.45.
D'accord, et comment trouvons-nous la meilleure répartition ? La réponse simple mais qui donne à réfléchir est :
Essayez simplement toutes les divisions et choisissez celle avec le gain d'informations le plus élevé. C'est essentiellement une approche par force brute.
Pour être plus précis, les arbres de décision standard utilisent divise le long des axes de coordonnées, À savoir xᵢ = c pour certaines fonctionnalités i et seuil c. Cela signifie que
- une partie des données fractionnées se compose de tous les points de données x comprenant xᵢcainsi que
- l'autre partie de tous les points x comprenant xᵢ ≥ c.
Ces règles de fractionnement simples se sont avérées suffisantes dans la pratique, mais vous pouvez bien sûr également étendre cette logique pour créer d'autres fractionnements (c'est-à-dire des lignes diagonales comme xᵢ + 2xⱼ = 3, par exemple).
Super, ce sont tous les ingrédients dont nous avons besoin pour commencer maintenant !
Nous allons implémenter l'arbre de décision maintenant. Puisqu'il est constitué de nœuds, définissons un Node classe en premier.
from dataclasses import dataclass @dataclass
class Node: feature: int = None # feature for the split value: float = None # split threshold OR final prediction left: np.array = None # store one part of the data right: np.array = None # store the other part of the dataUn nœud connaît la fonctionnalité qu'il utilise pour le fractionnement (feature) ainsi que la valeur de fractionnement (value). value est également utilisé comme stockage pour la prédiction finale de l'arbre de décision. Puisque nous allons construire un arbre binaire, chaque nœud doit connaître ses enfants gauche et droit, tels qu'ils sont stockés dans left ainsi que right .
Passons maintenant à l'implémentation réelle de l'arbre de décision. Je le rends compatible scikit-learn, donc j'utilise certaines classes de sklearn.base . Si vous n'êtes pas familier avec cela, consultez mon article sur comment construire des modèles compatibles scikit-learn.
Mettons en œuvre !
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin class DecisionTreeClassifier(BaseEstimator, ClassifierMixin): def __init__(self): self.root = Node() @staticmethod def _gini(y): """Gini impurity.""" counts = np.bincount(y) p = counts / counts.sum() return (p * (1 - p)).sum() def _split(self, X, y): """Bruteforce search over all features and splitting points.""" best_information_gain = float("-inf") best_feature = None best_split = None for feature in range(X.shape[1]): split_candidates = np.unique(X[:, feature]) for split in split_candidates: left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] information_gain = self._gini(y) - ( len(X_left) / len(X) * self._gini(y_left) + len(X_right) / len(X) * self._gini(y_right) ) if information_gain > best_information_gain: best_information_gain = information_gain best_feature = feature best_split = split return best_feature, best_split def _build_tree(self, X, y): """The heavy lifting.""" feature, split = self._split(X, y) left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] if len(X_left) == 0 or len(X_right) == 0: return Node(value=np.argmax(np.bincount(y))) else: return Node( feature, split, self._build_tree(X_left, y_left), self._build_tree(X_right, y_right), ) def _find_path(self, x, node): """Given a data point x, walk from the root to the corresponding leaf node. Output its value.""" if node.feature == None: return node.value else: if x[node.feature] node.value: return self._find_path(x, node.left) else: return self._find_path(x, node.right) def fit(self, X, y): self.root = self._build_tree(X, y) return self def predict(self, X): return np.array([self._find_path(x, self.root) for x in X])Et c'est tout! Vous pouvez faire toutes les choses que vous aimez à propos de scikit-learn maintenant :
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy # Output
# 1.0Étant donné que l'arbre n'est pas régularisé, il est beaucoup surajusté, d'où le score de train parfait. La précision serait pire sur des données invisibles. Nous pouvons également vérifier à quoi ressemble l'arbre via
print(dt.root) # Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )En image, ce serait ça :

Image par auteur
Dans cet article, nous avons vu en détail le fonctionnement des arbres de décision. Nous sommes partis de quelques idées vagues mais intuitives et les avons transformées en formules et en algorithmes. Au final, nous avons pu implémenter un arbre de décision à partir de rien.
Un mot d'avertissement cependant : Notre arbre de décision ne peut pas encore être régularisé. Habituellement, nous voudrions spécifier des paramètres tels que
- profondeur max
- la taille des feuilles
- et gain d'information minimal
parmi beaucoup d'autres. Heureusement, ces choses ne sont pas si difficiles à mettre en œuvre, ce qui en fait un devoir parfait pour vous. Par exemple, si vous spécifiez leaf_size=10 en tant que paramètre, les nœuds contenant plus de 10 échantillons ne doivent plus être divisés. De plus, cette implémentation est pas efficace. Habituellement, vous ne voudriez pas stocker des parties des ensembles de données dans des nœuds, mais uniquement les index à la place. Ainsi, votre ensemble de données (potentiellement volumineux) n'est en mémoire qu'une seule fois.
La bonne chose est que vous pouvez devenir fou maintenant avec ce modèle d'arbre de décision. Vous pouvez:
- mettre en œuvre des divisions diagonales, c'est-à-dire xᵢ + 2xⱼ = 3 au lieu de juste xᵢ = 3,
- changer la logique qui se produit à l'intérieur des feuilles, c'est-à-dire que vous pouvez exécuter une régression logistique dans chaque feuille au lieu de simplement faire un vote à la majorité, ce qui vous donne un arbre linéaire
- changez la procédure de fractionnement, c'est-à-dire qu'au lieu de faire de la force brute, essayez des combinaisons aléatoires et choisissez la meilleure, ce qui vous donne un classificateur extra-arbre
- et plus.
Dr Robert Kübler est Data Scientist chez Publicis Media et Auteur chez Towards Data Science.
ORIGINALE. Republié avec permission.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html?utm_source=rss&utm_medium=rss&utm_campaign=understanding-by-implementing-decision-tree
- 1
- 10
- 100
- 11
- 28
- 7
- 9
- a
- Capable
- A Propos
- au dessus de
- Absolute
- précision
- Avancée
- Après
- algorithmes
- Tous
- montant
- ainsi que
- Une autre
- répondre
- apparaître
- une approche
- d'environ
- autour
- tableau
- article
- auteur
- moyen
- base
- En gros
- car
- before
- va
- LES MEILLEURS
- Améliorée
- stimuler
- Bas et Leggings
- la force brute
- construire
- ne peut pas
- les soins
- maisons
- cas
- certaines
- vérifier
- Enfants
- Selectionnez
- classe
- les classes
- classification
- code
- Couleur
- комбинации
- Commun
- compatible
- complet
- complètement
- calcul
- Conscience
- continue
- coordonner
- Correspondant
- cours
- engendrent
- crucial
- données
- science des données
- Data Scientist
- ensembles de données
- décision
- arbre de décision
- Réglage par défaut
- profondeur
- détail
- différence
- différent
- difficile
- Ne fait pas
- faire
- chacun
- plus facile
- effet
- éléments
- assez
- Tout
- également
- Ether (ETH)
- Pourtant, la
- exemple
- express
- étendre
- familier
- Mode
- Fonctionnalité
- Fonctionnalités:
- few
- finale
- Trouvez
- Prénom
- flotteur
- suivi
- Abonnement
- Force
- formule
- De
- plus
- Gain
- Général
- obtenez
- comme ça
- Donner
- donné
- donne
- Go
- aller
- Bien
- arrive
- ici
- augmentation
- le plus élevé
- devoirs
- Comment
- HTML
- HTTPS
- idée
- et idées cadeaux
- Mettre en oeuvre
- la mise en oeuvre
- la mise en œuvre
- importer
- important
- impossible
- in
- Indices
- d'information
- initiale
- possible
- plutôt ;
- intéressé
- intuitif
- IT
- KDnuggetsGenericName
- XNUMX éléments à
- Genre
- Savoir
- Libellé
- Etiquettes
- gros
- apprentissage
- Longueur
- lifting
- lignes
- Liste
- LOOKS
- Lot
- love
- click
- machine learning
- Majorité
- a prendre une
- FAIT DU
- Fabrication
- manuellement
- de nombreuses
- Matière
- veux dire
- mesurer
- Médias
- Mémoire
- l'esprit
- minimal
- mixte
- numériques jumeaux (digital twin models)
- PLUS
- Besoin
- Besoins
- Nouveauté
- next
- nœud
- nœuds
- nombre
- numéros
- numpy
- ONE
- de commander
- original
- Autre
- Autres
- paramètre
- paramètres
- partie
- les pièces
- parfaite
- autorisation
- en particulier pendant la préparation
- image
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Point
- des notes bonus
- l'éventualité
- pratique
- prédiction
- Prédictions
- précédent
- Problème
- proven
- mettre
- Python
- aléatoire
- rapport
- atteint
- Récursif
- régression
- représentent
- respectivement
- Résultats
- retourner
- ROBERT
- racine
- Courir
- Sciences
- Scientifique
- scikit-apprendre
- Rechercher
- AUTO
- sens
- séparé
- set
- Partager
- devrait
- étapes
- depuis
- unique
- Taille
- faibles
- So
- jusqu'à présent
- RÉSOUDRE
- quelques
- scission
- splits
- Standard
- j'ai commencé
- étapes
- arrêt
- storage
- Boutique
- stockée
- tel
- parlant
- modèle
- conditions
- La
- les informations
- leur
- chose
- des choses
- trois
- порог
- Avec
- fois
- à
- ensemble
- trop
- top
- Total
- vers
- Train
- Arbres
- Tourné
- comprendre
- compréhension
- us
- utilisé
- d'habitude
- Plus-value
- Vote
- qui
- tout en
- sera
- dans les
- Word
- des mots
- activités principales
- fonctionnement
- vos contrats
- pire
- pourra
- X
- XGBoost
- Votre
- zéphyrnet
- zéro