Pandas est une bibliothèque open source puissante et largement utilisée pour la manipulation et l'analyse de données à l'aide de Python. L'une de ses fonctionnalités clés est la possibilité de regrouper des données à l'aide de la fonction groupby en divisant un DataFrame en groupes basés sur une ou plusieurs colonnes, puis en appliquant diverses fonctions d'agrégation à chacune d'entre elles.

Image de Unsplash
La groupby est incroyablement puissante, car elle vous permet de résumer et d'analyser rapidement de grands ensembles de données. Par exemple, vous pouvez regrouper un ensemble de données par une colonne spécifique et calculer la moyenne, la somme ou le nombre des colonnes restantes pour chaque groupe. Vous pouvez également regrouper plusieurs colonnes pour obtenir une compréhension plus précise de vos données. De plus, il vous permet d'appliquer des fonctions d'agrégation personnalisées, qui peuvent être un outil très puissant pour les tâches d'analyse de données complexes.
Dans ce didacticiel, vous apprendrez à utiliser la fonction groupby dans Pandas pour regrouper différents types de données et effectuer différentes opérations d'agrégation. À la fin de ce didacticiel, vous devriez être en mesure d'utiliser cette fonction pour analyser et résumer les données de différentes manières.
Les concepts sont intériorisés lorsqu'ils sont bien pratiqués et c'est ce que nous allons faire ensuite, c'est-à-dire nous familiariser avec la fonction groupby de Pandas. Il est recommandé d'utiliser un Jupyter Notebook pour ce didacticiel, car vous pouvez voir le résultat à chaque étape.
Générer des exemples de données
Importez les bibliothèques suivantes :
- Pandas : pour créer un dataframe et appliquer group by
- Aléatoire – Pour générer des données aléatoires
- Pprint – Pour imprimer des dictionnaires
import pandas as pd
import random
import pprint
Ensuite, nous allons initialiser une trame de données vide et remplir les valeurs pour chaque colonne comme indiqué ci-dessous :
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Astuce bonus - une façon plus propre de faire la même tâche consiste à créer un dictionnaire de toutes les variables et valeurs et à le convertir plus tard en une base de données.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
La trame de données ressemble à celle illustrée ci-dessous. Lors de l'exécution de ce code, certaines des valeurs ne correspondent pas car nous utilisons un échantillon aléatoire.
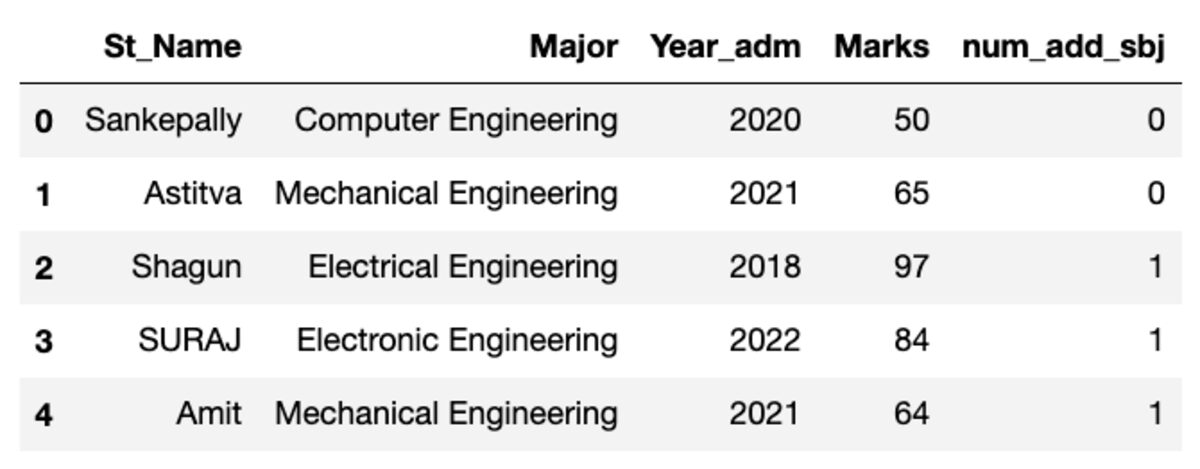
Faire des groupes
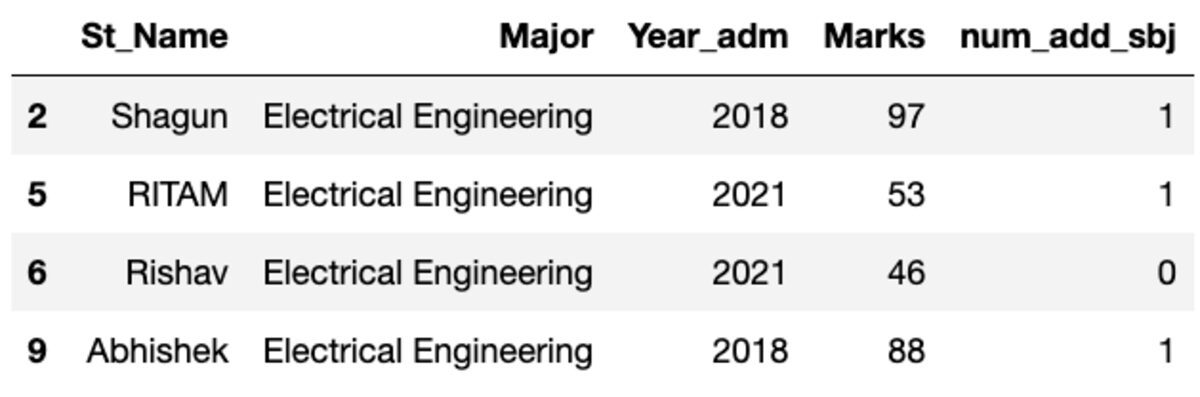
Regroupons les données par le sujet "Majeur" et appliquons le filtre de groupe pour voir combien d'enregistrements appartiennent à ce groupe.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Ainsi, quatre étudiants appartiennent à la majeure en génie électrique.
Vous pouvez également grouper par plusieurs colonnes (Major et num_add_sbj dans ce cas).
groups = df.groupby(['Major', 'num_add_sbj'])
Notez que toutes les fonctions d'agrégat qui peuvent être appliquées à des groupes avec une colonne peuvent être appliquées à des groupes avec plusieurs colonnes. Pour le reste du didacticiel, concentrons-nous sur les différents types d'agrégations en utilisant une seule colonne comme exemple.
Créons des groupes en utilisant groupby sur la colonne "Major".
groups = df.groupby('Major')Application de fonctions directes
Disons que vous voulez trouver les notes moyennes dans chaque majeure. Que feriez-vous?
- Choisissez la colonne Marques
- Appliquer la fonction moyenne
- Appliquer la fonction d'arrondi pour arrondir les marques à deux décimales (facultatif)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Total
Une autre façon d'obtenir le même résultat consiste à utiliser une fonction d'agrégation comme indiqué ci-dessous :
groups['Marks'].aggregate('mean').round(2)
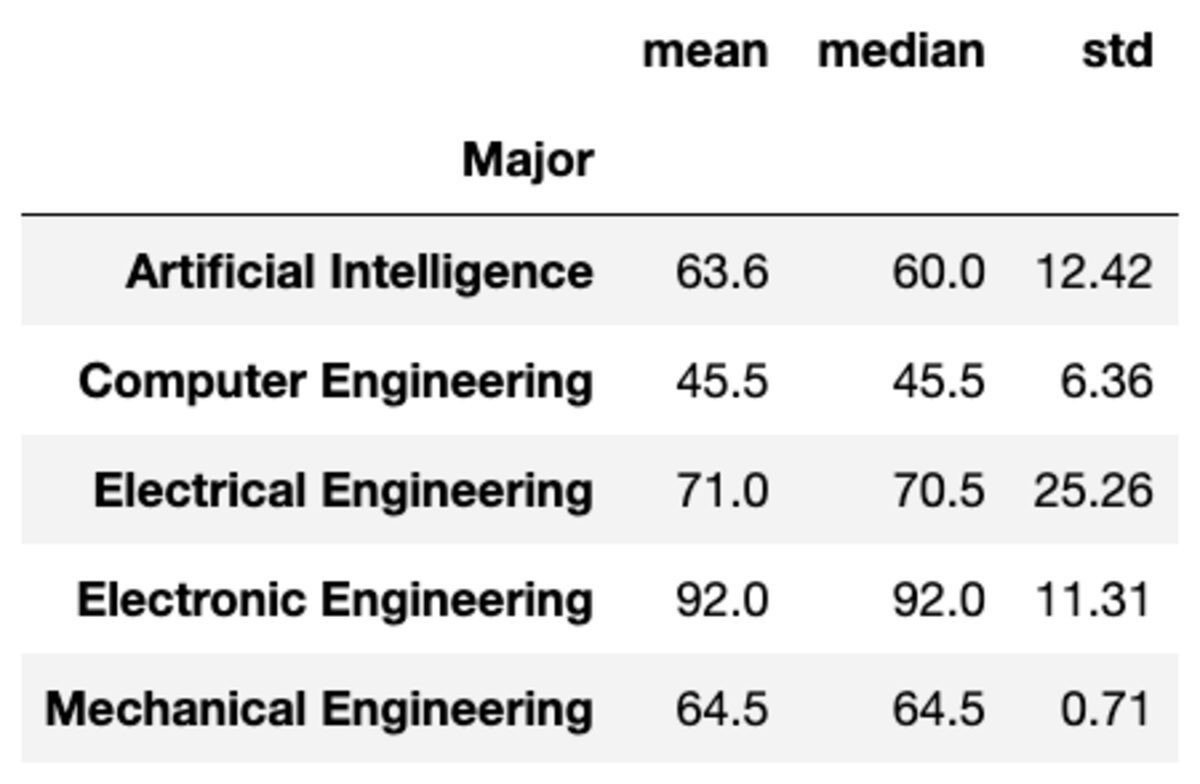
Vous pouvez également appliquer plusieurs agrégations aux groupes en transmettant les fonctions sous forme de liste de chaînes.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
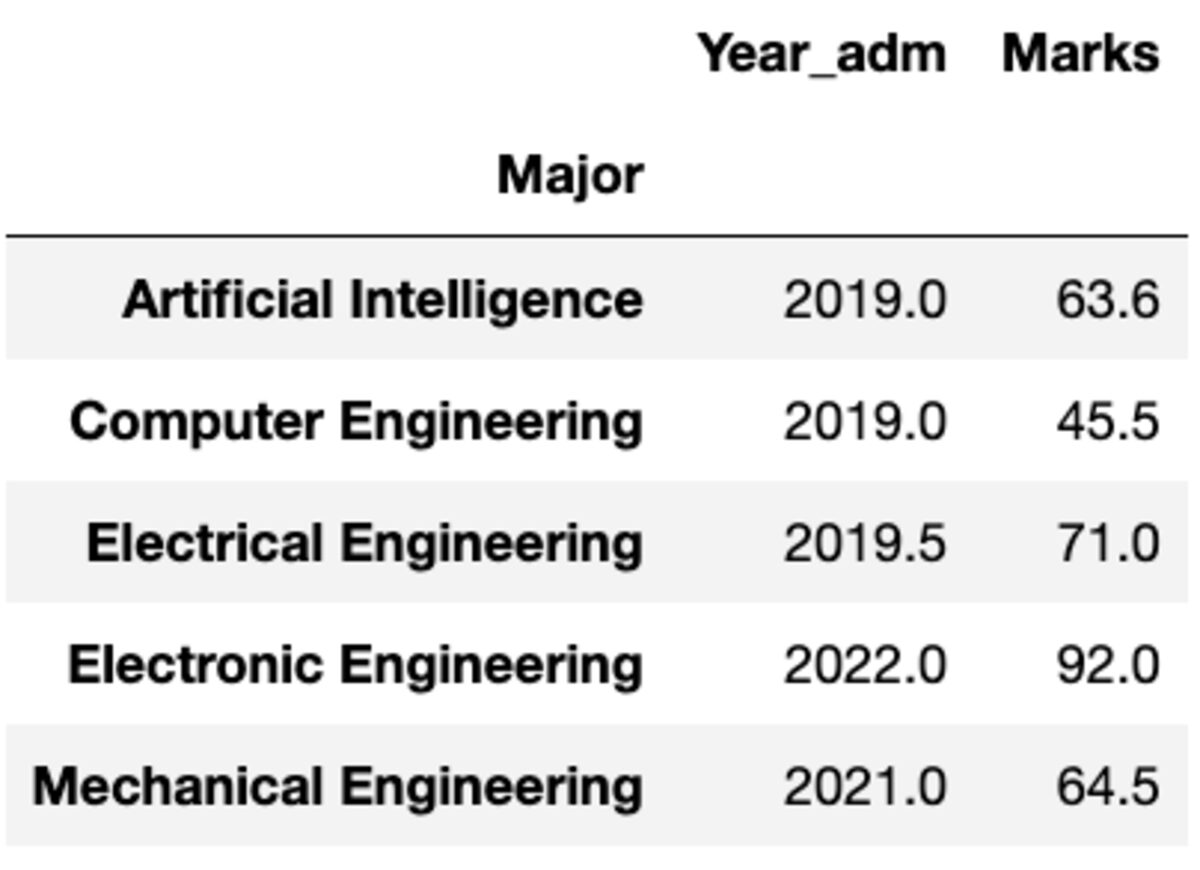
Mais que se passe-t-il si vous devez appliquer une fonction différente à une colonne différente. Ne t'inquiète pas. Vous pouvez également le faire en passant la paire {column : function}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Transforme
Vous devrez peut-être très bien effectuer des transformations personnalisées sur une colonne particulière, ce qui peut être facilement réalisé à l'aide de groupby(). Définissons un scalaire standard similaire à celui disponible dans le module de prétraitement de sklearn. Vous pouvez transformer toutes les colonnes en appelant la méthode de transformation et en transmettant la fonction personnalisée.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
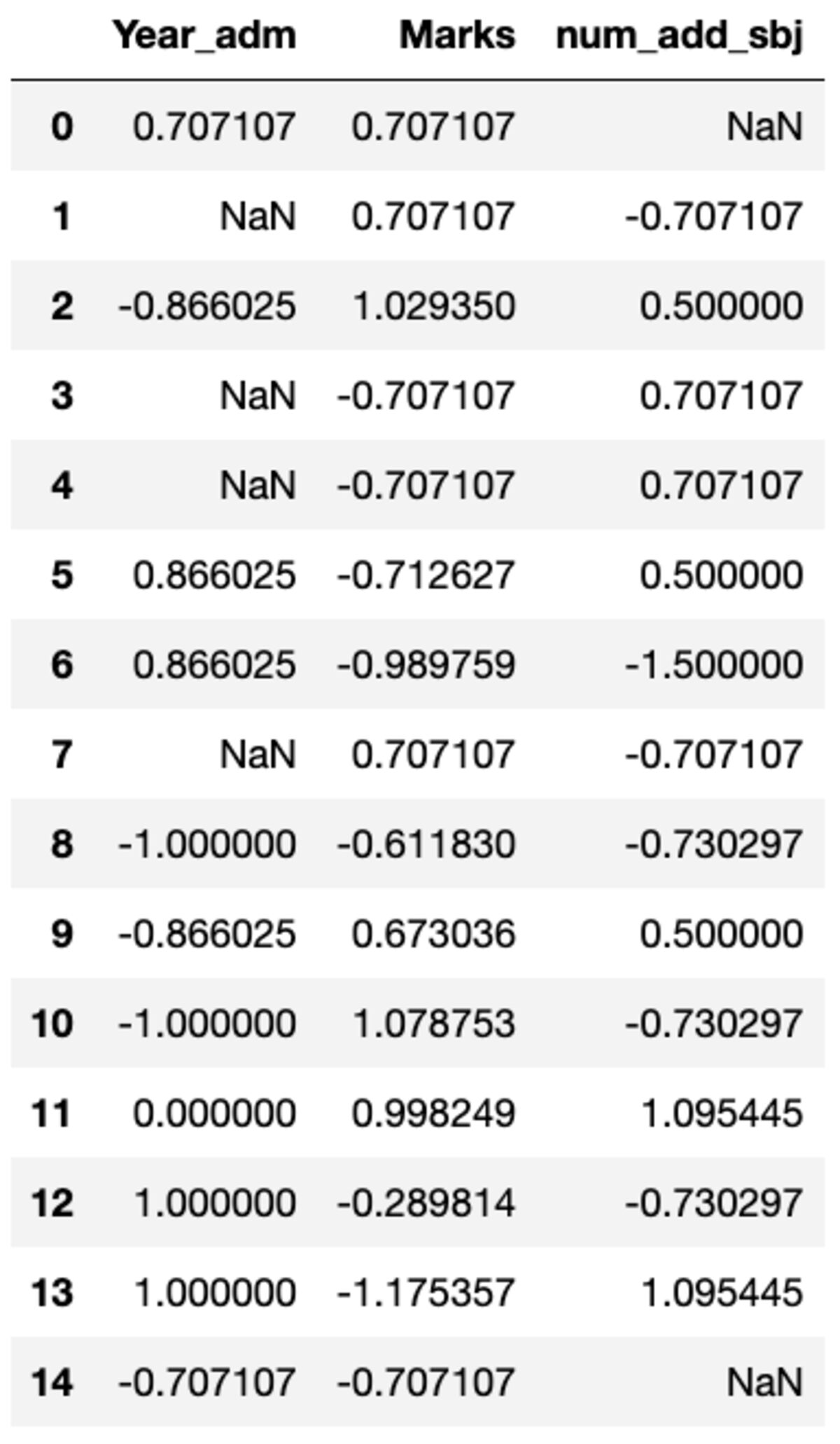
Notez que "NaN" représente des groupes avec un écart type nul.
Filtre
Vous voudrez peut-être vérifier quelle «majeure» est sous-performante, c'est-à-dire celle où les «notes» moyennes des étudiants sont inférieures à 60. Cela vous oblige à appliquer une méthode de filtrage aux groupes contenant une fonction. Le code ci-dessous utilise un fonction lambda pour obtenir les résultats filtrés.
groups.filter(lambda x: x['Marks'].mean() 60)

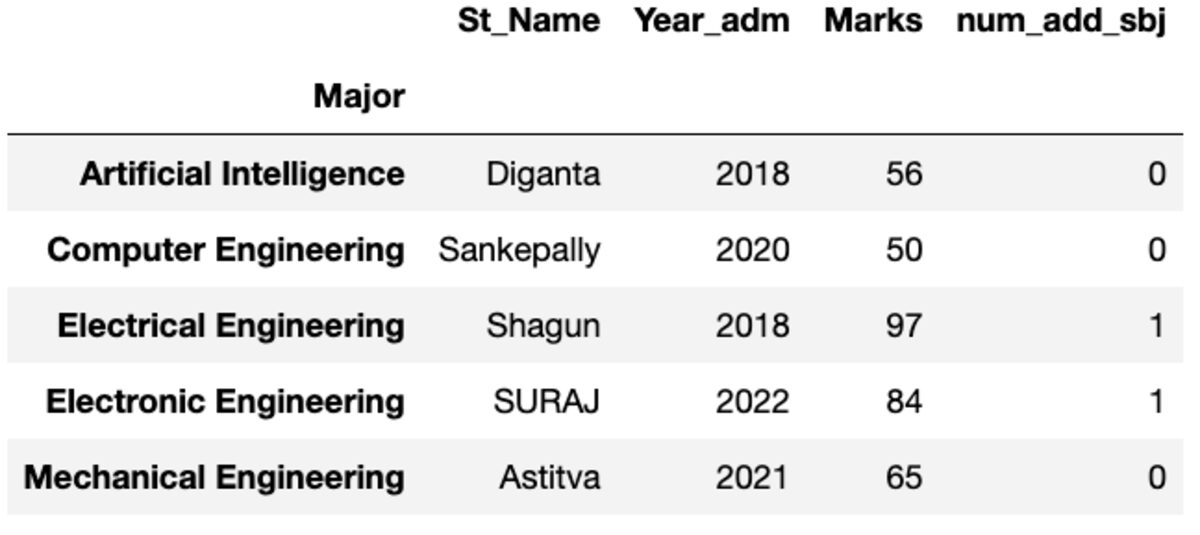
Prénom
Il vous donne sa première instance triée par index.
groups.first()
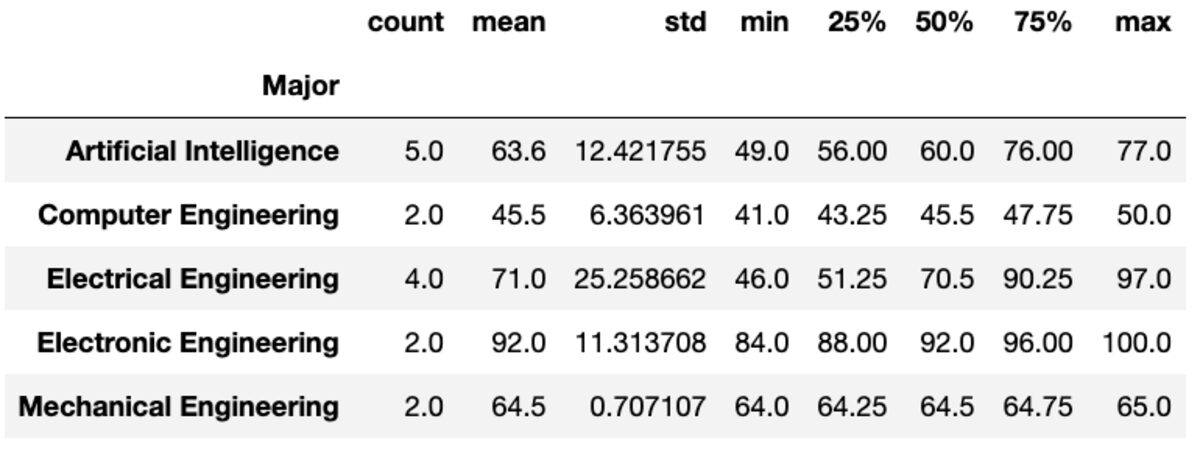
Décrire
La méthode "describe" renvoie des statistiques de base telles que count, mean, std, min, max, etc. pour les colonnes données.
groups['Marks'].describe()
Taille
La taille, comme son nom l'indique, renvoie la taille de chaque groupe en termes de nombre d'enregistrements.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64Comte et Nunique
"Count" renvoie toutes les valeurs tandis que "Nunique" ne renvoie que les valeurs uniques de ce groupe.
groups.count()
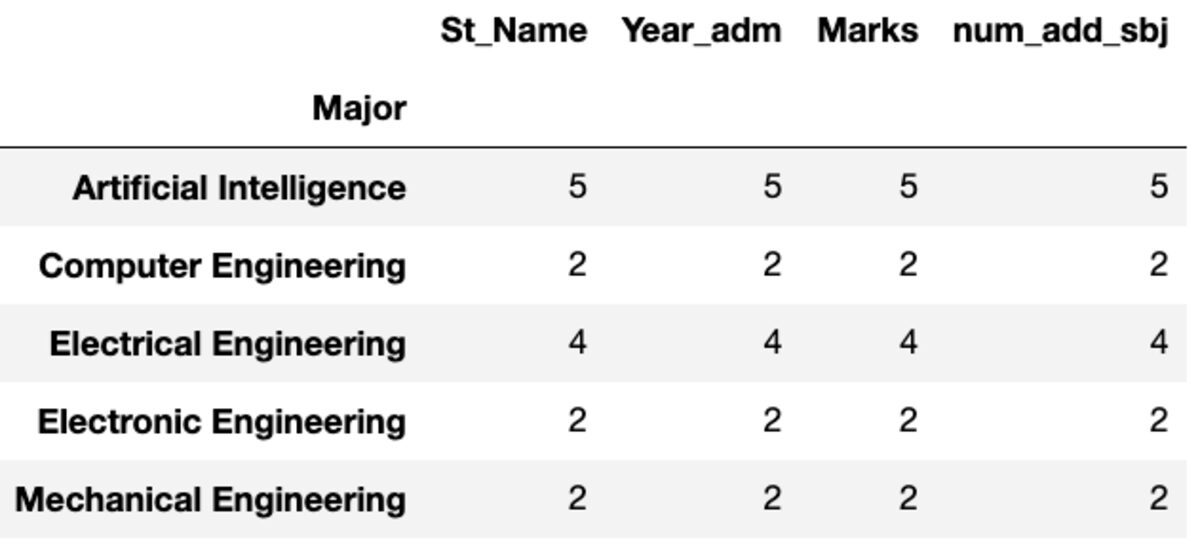
groups.nunique()
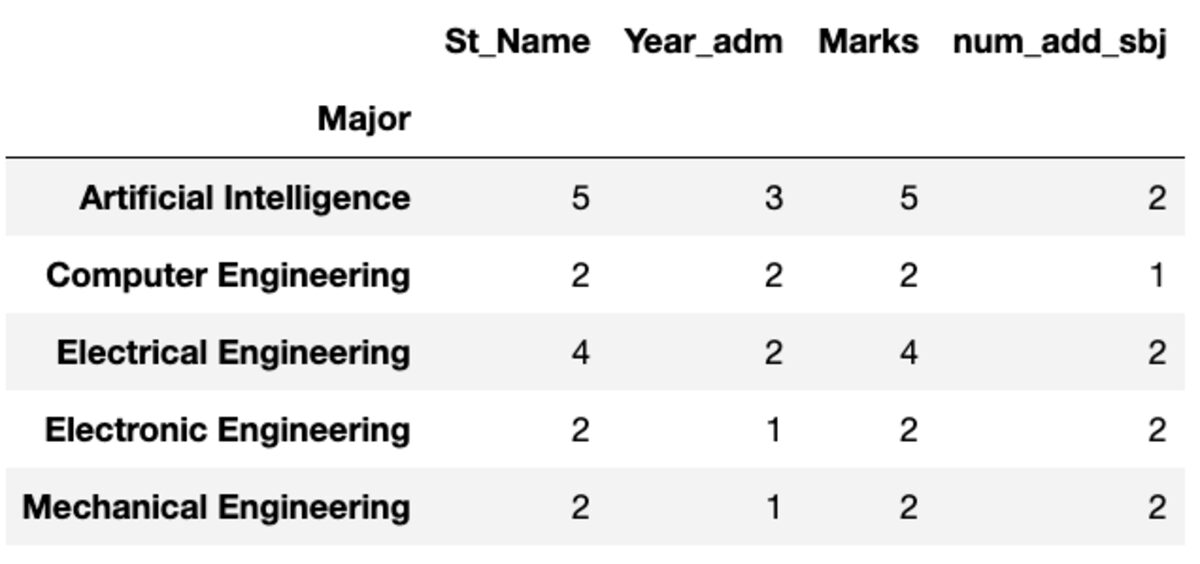
renommer
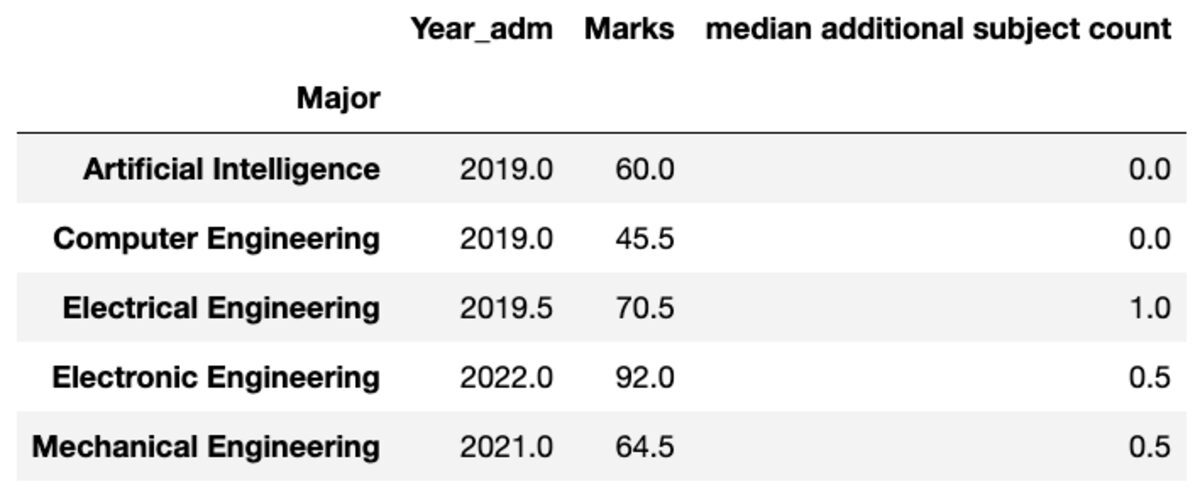
Vous pouvez également renommer le nom des colonnes agrégées selon vos préférences.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- Soyez clair sur le but du groupby : Essayez-vous de regrouper les données dans une colonne pour obtenir la moyenne d'une autre colonne ? Ou essayez-vous de regrouper les données en plusieurs colonnes pour obtenir le nombre de lignes dans chaque groupe ?
- Comprendre l'indexation de la trame de données : La fonction groupby utilise l'index pour regrouper les données. Si vous souhaitez regrouper les données par une colonne, assurez-vous que la colonne est définie comme index ou vous pouvez utiliser .set_index()
- Utiliser la fonction d'agrégation appropriée: Il peut être utilisé avec diverses fonctions d'agrégation comme mean(), sum(), count(), min(), max()
- Utilisez le paramètre as_index : Lorsqu'il est défini sur False, ce paramètre indique à pandas d'utiliser les colonnes groupées comme des colonnes régulières au lieu d'index.
Vous pouvez également utiliser groupby() en conjonction avec d'autres fonctions pandas comme pivot_table(), crosstab() et cut() pour extraire plus d'informations de vos données.
Une fonction groupby est un outil puissant pour l'analyse et la manipulation des données car elle vous permet de regrouper des lignes de données en fonction d'une ou plusieurs colonnes, puis d'effectuer des calculs agrégés sur les groupes. Le didacticiel a démontré différentes manières d'utiliser la fonction groupby à l'aide d'exemples de code. J'espère qu'il vous permettra de comprendre les différentes options qui l'accompagnent et comment elles aident à l'analyse des données.
Vidhi Chugh est un stratège de l'IA et un leader de la transformation numérique travaillant à l'intersection des produits, des sciences et de l'ingénierie pour créer des systèmes d'apprentissage automatique évolutifs. Elle est une leader de l'innovation primée, une auteure et une conférencière internationale. Elle a pour mission de démocratiser l'apprentissage automatique et de casser le jargon pour que chacun fasse partie de cette transformation.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- Platoblockchain. Intelligence métaverse Web3. Connaissance Amplifiée. Accéder ici.
- La source: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- capacité
- Capable
- atteindre
- atteint
- Supplémentaire
- En outre
- agrégation
- AI
- Tous
- permet
- selon une analyse de l’Université de Princeton
- il analyse
- ainsi que
- Une autre
- appliqué
- Appliquer
- Application
- approprié
- artificiel
- intelligence artificielle
- auteur
- disponibles
- moyen
- primé
- basé
- Essentiel
- ci-dessous
- biotechnologie
- Pause
- construire
- calculer
- appel
- maisons
- vérifier
- clair
- code
- Colonne
- Colonnes
- comment
- complexe
- ordinateur
- Ingénierie informatique
- engendrent
- La création
- Customiser
- données
- l'analyse des données
- ensembles de données
- démocratiser
- démontré
- déviation
- différent
- numérique
- Transformation numérique
- Ne pas
- chacun
- même
- de manière efficace
- ingénierie électrique
- Electronique
- ENGINEERING
- etc
- tout le monde
- exemple
- exemples
- extrait
- Automne
- Fonctionnalités:
- remplir
- une fonction filtre
- Trouvez
- Prénom
- Focus
- Abonnement
- CADRE
- De
- fonction
- fonctions
- générer
- obtenez
- donné
- donne
- aller
- Réservation de groupe
- Groupes
- hands-on
- vous aider
- d'espérance
- Comment
- How To
- HTML
- HTTPS
- importer
- in
- incroyablement
- indice
- Innovation
- idées.
- instance
- plutôt ;
- Intelligence
- International
- intersection
- IT
- jargon
- KDnuggetsGenericName
- ACTIVITES
- gros
- leader
- APPRENTISSAGE
- apprentissage
- bibliothèques
- Bibliothèque
- Liste
- LOOKS
- click
- machine learning
- majeur
- a prendre une
- Manipulation
- de nombreuses
- Match
- max
- mécanique
- ingénierie mécanique
- moyenne
- méthode
- Mission
- module
- PLUS
- plusieurs
- prénom
- noms
- Besoin
- next
- nombre
- ONE
- open source
- Opérations
- Options
- Autre
- pandas
- paramètre
- partie
- particulier
- En passant
- effectuer
- Des endroits
- Platon
- Intelligence des données Platon
- PlatonDonnées
- solide
- Imprimé
- Produit
- fournit
- but
- Python
- vite.
- aléatoire
- recommandé
- Articles
- Standard
- restant
- représente
- a besoin
- REST
- résultat
- Résultats
- retourner
- Retours
- Richard
- Round
- pour le running
- même
- évolutive
- STARFLEET SCIENCES
- set
- devrait
- montré
- similaires
- unique
- Taille
- quelques
- Speaker
- groupe de neurones
- Standard
- statistiques
- étapes
- Stratège
- Étudiant
- Étudiante
- sujet
- Suggère
- résumé
- Système
- Tâche
- tâches
- raconte
- conditions
- La
- pointe
- à
- outil
- Transformer
- De La Carrosserie
- transformations
- tutoriel
- types
- compréhension
- expérience unique et authentique
- utilisé
- Valeurs
- divers
- façons
- Quoi
- qui
- sera
- de travail
- pourra
- X
- an
- Votre
- zéphyrnet
- zéro






