Introduction
Dans le paysage en évolution rapide de l’IA générative, le rôle central des bases de données vectorielles est devenu de plus en plus évident. Cet article plonge dans la synergie dynamique entre les bases de données vectorielles et les solutions d'IA générative, explorant comment ces fondements technologiques façonnent l'avenir de la créativité de l'intelligence artificielle. Rejoignez-nous pour un voyage à travers les subtilités de cette puissante alliance, qui vous permettra de mieux comprendre l'impact transformateur que les bases de données vectorielles apportent à l'avant-garde des solutions d'IA innovantes.
Objectifs d'apprentissage
Cet article vous aide à comprendre les aspects de la base de données vectorielles ci-dessous.
- Importance des bases de données vectorielles et de ses composants clés
- Étude détaillée de la comparaison de la base de données Vector avec la base de données traditionnelle
- Exploration des intégrations vectorielles du point de vue de l'application
- Création d'une base de données vectorielle à l'aide de Pincone
- Implémentation de la base de données Pinecone Vector à l'aide du modèle Langchain LLM
Cet article a été publié dans le cadre du Blogathon sur la science des données.
Table des matières
Qu'est-ce que la base de données vectorielles ?
Une base de données vectorielles est une forme de collecte de données stockée dans l'espace. Pourtant, ici, il est stocké dans des représentations mathématiques puisque le format stocké dans les bases de données facilite la mémorisation des entrées par les modèles d'IA ouverts et permet à notre application d'IA ouverte d'utiliser la recherche cognitive, les recommandations et la génération de texte pour divers cas d'utilisation dans les industries transformées numériquement. Le stockage et la récupération des données sont appelés « Embeddings vectoriels » ou « Embeddings ». De plus, ceci est représenté sous forme de tableau numérique. La recherche est beaucoup plus simple que les bases de données traditionnelles utilisées pour les perspectives de l'IA avec des capacités massives et indexées.
Caractéristiques des bases de données vectorielles
- Il exploite la puissance de ces intégrations vectorielles, conduisant à l'indexation et à la recherche sur un ensemble de données massif.
- Compactable avec tous les formats de données (images, texte ou données).
- Puisqu'il adapte les techniques d'intégration et les fonctionnalités hautement indexées, il peut offrir une solution complète de gestion des données et des entrées pour un problème donné.
- Une base de données vectorielles organise les données via des vecteurs de grande dimension contenant des centaines de dimensions. Nous pouvons les configurer très rapidement.
- Chaque dimension correspond à une caractéristique ou une propriété spécifique de l'objet de données qu'elle représente.
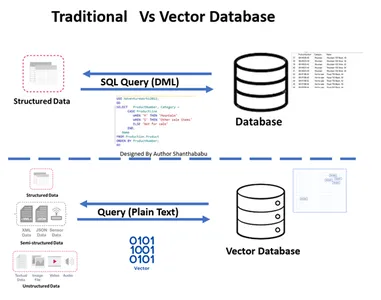
Traditionnel contre. Base de données vectorielles
- L'image montre le flux de travail de haut niveau des bases de données traditionnelles et vectorielles.
- Les interactions formelles avec les bases de données se produisent via SQL déclarations et données stockées au format de base de lignes et de tableau.
- Dans la base de données Vector, les interactions se produisent via du texte brut (par exemple en anglais) et des données stockées dans des représentations mathématiques.
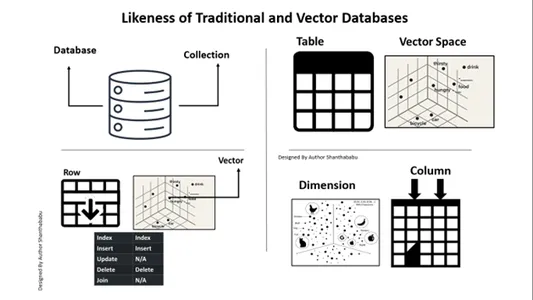
Ressemblance des bases de données traditionnelles et vectorielles
Nous devons considérer en quoi les bases de données Vector diffèrent des bases de données traditionnelles. Discutons-en ici. Une différence rapide que je peux donner est celle des bases de données conventionnelles. Les données sont stockées précisément telles quelles ; nous pourrions ajouter une logique métier pour ajuster les données et fusionner ou diviser les données en fonction des exigences ou des demandes de l'entreprise. Cependant, la base de données vectorielles subit une transformation massive et les données deviennent une représentation vectorielle complexe.
Voici une carte pour votre compréhension et votre perspective de clarté avec bases de données relationnelles contre les bases de données vectorielles. L'image ci-dessous est explicite pour comprendre les bases de données vectorielles avec les bases de données traditionnelles. En bref, nous pouvons exécuter des insertions et des suppressions dans des bases de données vectorielles, pas des instructions de mise à jour.
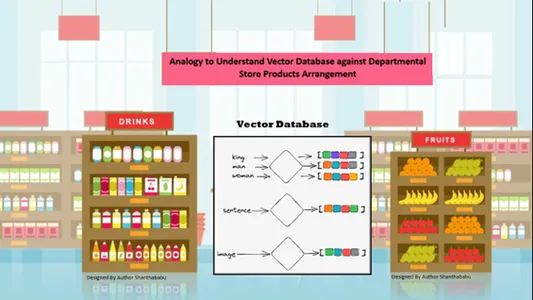
Analogie simple pour comprendre les bases de données vectorielles
Les données sont automatiquement organisées spatialement en fonction de la similarité du contenu des informations stockées. Considérons donc le grand magasin pour l'analogie avec la base de données vectorielles ; tous les produits sont disposés sur les étagères en fonction de leur nature, de leur objectif, de leur fabrication, de leur utilisation et de leur quantité. Dans un comportement similaire, les données sont
automatiquement organisés dans la base de données vectorielles par un tri similaire, même si le genre n'était pas bien défini lors du stockage ou de l'accès aux données.
Les bases de données vectorielles permettent une granularité et des dimensions importantes sur les similitudes spécifiques, de sorte que le client recherche le produit, le fabricant et la quantité souhaités et conserve l'article dans le panier. La base de données vectorielle stocke toutes les données dans une structure de stockage parfaite ; ici, les ingénieurs en Machine Learning et en IA n'ont pas besoin d'étiqueter ou d'étiqueter manuellement le contenu stocké.
Théories essentielles derrière les bases de données vectorielles
- Intégrations vectorielles et leur portée
- Exigences d'indexation
- Comprendre la recherche sémantique et de similarité
Incorporation de vecteurs et leur portée
Une intégration vectorielle est une représentation vectorielle en termes de valeurs numériques. Dans un format compressé, les intégrations capturent les propriétés et associations inhérentes aux données d'origine, ce qui en fait un incontournable dans les cas d'utilisation de l'intelligence artificielle et de l'apprentissage automatique. La conception d'intégrations pour coder des informations pertinentes sur les données d'origine dans un espace de dimension inférieure garantit une vitesse de récupération élevée, une efficacité de calcul et un stockage efficace.
Capturer l'essence des données d'une manière structurée de manière plus identique est le processus d'intégration vectorielle, formant un « modèle d'intégration ». En fin de compte, ces modèles prennent en compte tous les objets de données, extraient des modèles et des relations significatifs au sein de la source de données et les transforment en intégrations vectorielles. . Par la suite, les algorithmes exploitent ces intégrations vectorielles pour exécuter diverses tâches. De nombreux modèles d'intégration hautement développés, disponibles en ligne gratuitement ou avec paiement à l'utilisation, facilitent la réalisation de l'intégration de vecteurs.
Portée des intégrations vectorielles du point de vue de l'application
Ces intégrations sont compactes, contiennent des informations complexes, héritent des relations entre les données stockées dans une base de données vectorielle, permettent une analyse efficace du traitement des données pour faciliter la compréhension et la prise de décision, et créent dynamiquement divers produits de données innovants dans n'importe quelle organisation.
Les techniques d’intégration de vecteurs sont essentielles pour combler le fossé entre les données lisibles et les algorithmes complexes. Les types de données étant des vecteurs numériques, nous avons pu libérer le potentiel d'une grande variété d'applications d'IA générative ainsi que des modèles d'IA ouverte disponibles.
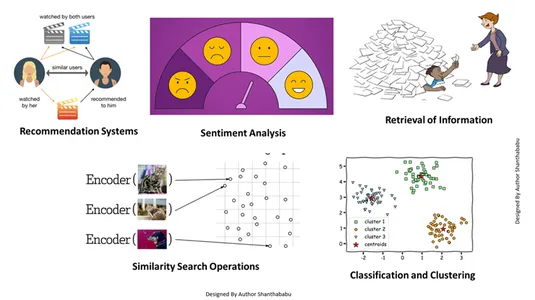
Plusieurs tâches avec intégration de vecteurs
Cette intégration vectorielle nous aide à effectuer plusieurs tâches :
- Récupération d'informations : Avec l'aide de ces techniques puissantes, nous pouvons créer des moteurs de recherche influents qui peuvent nous aider à trouver des réponses basées sur les requêtes des utilisateurs à partir de fichiers, de documents ou de médias stockés.
- Opérations de recherche de similarité : Celui-ci est bien organisé et indexé ; cela nous aide à trouver la similitude entre les différentes occurrences dans les données vectorielles.
- Classification et regroupement : Grâce à ces techniques d'intégration, nous pouvons exécuter ces modèles pour entraîner des algorithmes d'apprentissage automatique pertinents, les regrouper et les classer.
- Systèmes de recommandation : Étant donné que les techniques d'intégration sont correctement organisées, cela conduit à des systèmes de recommandation reliant avec précision les produits, les médias et les articles sur la base de données historiques.
- Analyse des sentiments: Ce modèle d'intégration nous aide à catégoriser et à dériver des solutions de sentiments.
Exigences d'indexation
Comme nous le savons, l'index améliorera la recherche de données à partir de la table dans les bases de données traditionnelles, similaires aux bases de données vectorielles, et fournira les fonctionnalités d'indexation.
Les bases de données vectorielles fournissent des « indices plats », qui sont la représentation directe de l'intégration vectorielle. La capacité de recherche est complète et n'utilise pas de clusters pré-entraînés. Il exécute le vecteur de requête sur chaque intégration de vecteur unique et K distances sont calculées pour chaque paire.
- En raison de la simplicité de cet index, un minimum de calculs est requis pour créer les nouveaux indices.
- En effet, un index plat peut gérer efficacement les requêtes et fournir des temps de récupération rapides.
Comprendre la recherche sémantique et de similarité
Nous effectuons deux recherches différentes dans les bases de données vectorielles : les recherches sémantiques et les recherches de similarité.
- Recherche sémantique: Lorsque vous recherchez des informations, au lieu de rechercher par mots-clés, vous pouvez les trouver sur la base d'une méthodologie de conversation significative. L'ingénierie rapide joue un rôle essentiel dans la transmission des informations au système. Cette recherche permet sans aucun doute une recherche et des résultats de meilleure qualité qui peuvent être alimentés pour des applications innovantes, le référencement, la génération de texte et la synthèse.
- Recherche de similarité : Toujours en analyse de données, la recherche de similarité permet d'obtenir des ensembles de données non structurés et bien mieux fournis. Concernant les bases de données vectorielles, il faut vérifier la proximité de deux vecteurs et leur ressemblance : tableaux, textes, documents, images, mots et fichiers audio. Dans le processus de compréhension, la similarité entre les vecteurs se révèle comme la similarité entre les objets de données dans l'ensemble de données donné. Cet exercice nous aide à comprendre les interactions, à identifier des modèles, à extraire des informations et à prendre des décisions du point de vue des applications. La recherche sémantique et similarité nous aiderait à créer les applications ci-dessous pour les avantages de l'industrie.
- Récupération de l'information: À l’aide d’Open AI et de bases de données vectorielles, nous créerions des moteurs de recherche pour la récupération d’informations à l’aide des requêtes des utilisateurs professionnels ou des utilisateurs finaux et des documents indexés dans la base de données vectorielle.
- Classification et regroupement :Classer ou regrouper des points de données ou des groupes d'objets similaires implique de les attribuer à plusieurs catégories en fonction de caractéristiques partagées.
- Détection d'une anomalie: Découvrir les anomalies par rapport aux modèles habituels en mesurant la similarité des points de données et en repérant les irrégularités.
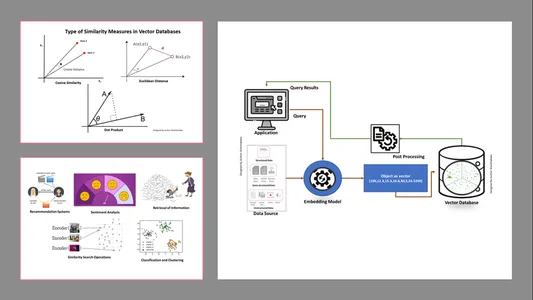
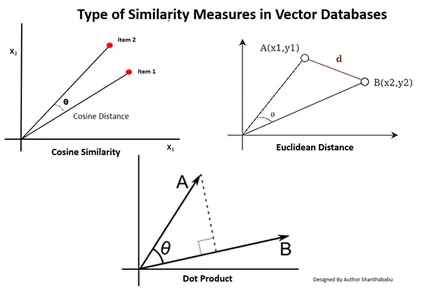
Types de mesures de similarité dans les bases de données vectorielles
Les méthodes de mesure dépendent de la nature des données et des spécificités de l'application. Généralement, trois méthodes sont utilisées pour mesurer la similarité et la familiarité avec le Machine Learning.
Distance euclidienne
En termes simples, la distance entre les deux vecteurs est la distance en ligne droite entre les deux points vectoriels qui mesurent le st.
Produit scalaire
Cela nous aide à comprendre l’alignement entre deux vecteurs, en indiquant s’ils pointent dans la même direction, dans des directions opposées ou s’ils sont perpendiculaires l’un à l’autre.
Similitude de cosinus
Il évalue la similarité de deux vecteurs en utilisant l'angle qui les sépare, comme le montre la figure. Dans ce cas, les valeurs et l'ampleur des vecteurs sont insignifiantes et n'affectent pas les résultats ; seul l'angle est pris en compte dans le calcul.
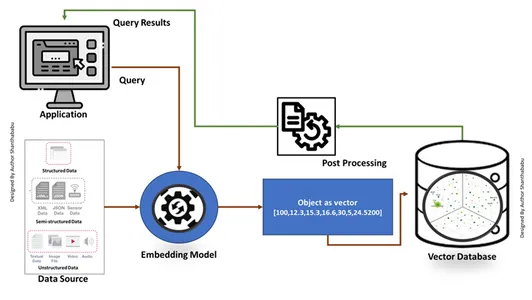
Bases de données traditionnelles Recherchez des correspondances exactes d'instructions SQL et récupérez les données sous forme de tableau. Dans le même temps, nous traitons des bases de données vectorielles recherchant le vecteur le plus similaire à la requête d'entrée en anglais simple en utilisant des techniques d'ingénierie rapide. La base de données utilise l'algorithme de recherche du voisin le plus proche (ANN) pour trouver des données similaires. Fournissez toujours des résultats raisonnablement précis avec des performances, une précision et un temps de réponse élevés.
Mécanisme de travail
- Les bases de données vectorielles convertissent d'abord les données en vecteurs d'intégration, les stockent dans des bases de données vectorielles et créent une indexation pour une recherche plus rapide.
- Une requête de l'application interagira avec le vecteur d'intégration, recherchant le voisin le plus proche ou des données similaires dans la base de données vectorielles à l'aide d'un index et récupérant les résultats transmis à l'application.
- En fonction des besoins de l'entreprise, les données récupérées seraient affinées, formatées et affichées du côté de l'utilisateur final ou du flux de requêtes ou d'actions.
Création d'une base de données vectorielles
Connectons-nous avec Pinecone.
Vous pouvez vous connecter à Pinecone en utilisant Google, GitHub ou Microsoft ID.
Créez une nouvelle connexion utilisateur pour votre utilisation.
Après une connexion réussie, vous arriverez sur la page Index ; vous pouvez créer un index à des fins de base de données vectorielles. Cliquez sur le bouton Créer un index.
Créez votre nouvel index en fournissant le nom et les dimensions.
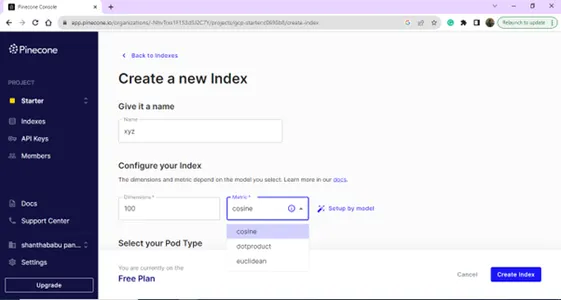
Page de liste d'index,
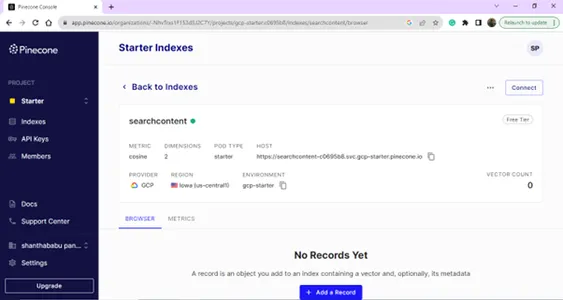
Détails de l'index – Nom, région et environnement – Nous avons besoin de tous ces détails pour connecter notre base de données vectorielles à partir du code de construction du modèle.
Détails des paramètres du projet,
Vous pouvez mettre à niveau vos préférences pour plusieurs index et clés à des fins de projet.
Jusqu'à présent, nous avons discuté de la création de l'index et des paramètres de la base de données vectorielles dans Pinecone.
Implémentation d'une base de données vectorielles à l'aide de Python
Faisons un peu de codage maintenant.
Importer des bibliothèques
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIFournir une clé API pour la base de données OpenAI et Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Initier le LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Initier la pomme de pin
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Chargement du fichier .csv pour créer une base de données vectorielles
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Divisez le texte en morceaux
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Trouver le texte dans text_chunk
text_chunksSortie
[Document(page_content='name: 100% Brannmfr: Nntype: Cncalories: 70nprotéines: 4nlipides: 1nsodium: 130nfibres: 10ncarbones: 5nsucres: 6npotasse: 280nvitamines: 25nétagère: 3npoids: 1ntasses: 0.33nnote: 68.402973nrecomme ndation : Enfants, métadonnées = { 'source' : '100% Son', 'ligne' : 0}), , …..
Intégration du bâtiment
embeddings = OpenAIEmbeddings()Créer une instance Pinecone pour la base de données vectorielles à partir de « données »
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Créez un récupérateur pour interroger la base de données vectorielles.
retriever = vectordb.as_retriever(score_threshold = 0.7)Récupération de données à partir d'une base de données vectorielles
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsUtiliser l'invite et récupérer les données
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Interrogons les données.
chain('Can you please provide cereal recommendation for Kids?')Résultat de la requête
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Conclusion
J'espère que vous comprendrez le fonctionnement des bases de données vectorielles, leurs composants, leur architecture et les caractéristiques des bases de données vectorielles dans les solutions d'IA générative. Comprendre en quoi la base de données vectorielle est différente de la base de données traditionnelle et comparaison avec les éléments de base de données conventionnels. En effet, l’analogie vous aide à mieux comprendre la base de données vectorielles. La base de données vectorielles Pinecone et les étapes d'indexation vous aideraient à créer une base de données vectorielles et à apporter la clé pour l'implémentation du code suivant.
Faits marquants
- Compactable avec des données structurées, non structurées et semi-structurées.
- Il adapte les techniques d'intégration et les fonctionnalités hautement indexées.
- Les interactions se produisent sous forme de texte brut à l'aide d'une invite (par exemple, en anglais). Et les données stockées dans des représentations mathématiques.
- La similarité est calibrée dans les bases de données vectorielles via la distance euclidienne, la similarité cosinus et le produit scalaire.
Foire aux Questions
A. Une base de données vectorielles stocke une collection de données dans l'espace. Il conserve les données dans des représentations mathématiques. puisque le format stocké dans les bases de données permet aux modèles d'IA ouverts de mémoriser plus facilement les entrées précédentes et permet à notre application d'IA ouverte d'utiliser la recherche cognitive, les recommandations et la génération de texte précis pour divers cas d'utilisation dans les industries transformées numériquement.
A. Certaines des caractéristiques sont les suivantes : 1. Il exploite la puissance de ces intégrations vectorielles, conduisant à l'indexation et à la recherche sur un ensemble de données massif. 2. Compactable avec des données structurées, non structurées et semi-structurées. 3. Une base de données vectorielles organise les données à travers des vecteurs de grande dimension contenant des centaines de dimensions
A. Base de données ==> Collections
Tableau ==> Espace vectoriel
Ligne==>Cecteur
Colonne==>Dimension
L'insertion et la suppression sont possibles dans les bases de données vectorielles, tout comme dans une base de données traditionnelle.
Mettre à jour et rejoindre ne sont pas concernés.
– Récupération d’informations pour une collecte massive de données rapidement.
– Opérations de recherche sémantique et de similarité à partir de documents de grande taille.
– Application de classification et de regroupement.
– Systèmes de recommandation et d’analyse des sentiments.
A5 : Vous trouverez ci-dessous les trois méthodes pour mesurer la similarité :
- Distance euclidienne
– Similitude cosinus
- Produit scalaire
Les médias présentés dans cet article n'appartiennent pas à Analytics Vidhya et sont utilisés à la discrétion de l'auteur.
Services Connexes
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :possède
- :est
- :ne pas
- $UP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Capable
- A Propos
- accès
- précision
- Avec cette connaissance vient le pouvoir de prendre
- avec précision
- à travers
- s'adapte
- ajouter
- affecter
- AI
- Modèles AI
- algorithme
- algorithmes
- alignement
- Tous
- Alliance
- permettre
- permet
- le long de
- toujours
- parmi
- an
- selon une analyse de l’Université de Princeton
- analytique
- Analytique Vidhya
- ainsi que
- répondre
- tous
- api
- apparent
- Application
- spécifique à l'application
- applications
- approximatif
- architecture
- SONT
- arrangé
- tableau
- article
- sur notre blog
- artificiel
- intelligence artificielle
- L'INTELLIGENCE ARTIFICIELLE ET LE MACHINE LEARNING
- AS
- aspects
- évalue
- associations
- At
- acoustique
- automatiquement
- disponibles
- basé
- BE
- devenez
- devient
- comportement
- derrière
- va
- ci-dessous
- avantages.
- Améliorée
- jusqu'à XNUMX fois
- blogathon
- apporter
- construire
- Développement
- la performance des entreprises
- bouton (dans la fenêtre de contrôle qui apparaît maintenant)
- by
- calculé
- calcul
- appelé
- CAN
- capacités
- aptitude
- capturer
- maisons
- cas
- catégories
- chaîne
- Chaînes
- caractéristiques
- clarté
- classification
- Classer
- cliquez
- regroupement
- code
- Codage
- cognitif
- collection
- communément
- compact
- comparer
- Comparaison
- complet
- complexe
- composants électriques
- complet
- calcul
- calcul
- NOUS CONTACTER
- Connecter les
- Considérer
- considéré
- contiennent
- contenu
- contexte
- conventionnel
- Conversation
- convertir
- correspond
- pourriez
- engendrent
- La création
- notre créativité
- des clients
- données
- l'analyse des données
- points de données
- informatique
- Base de données
- bases de données
- ensembles de données
- affaire
- La prise de décision
- décisions
- demandes
- dériver
- conception
- voulu
- détails
- Détection
- développé
- différer
- différence
- différent
- numériquement
- Dimension
- dimensions
- direction
- instructions
- découverte
- discrétion
- discuter
- discuté
- dans
- distance
- do
- INSTITUTIONNELS
- Don
- DOT
- Dynamic
- dynamiquement
- e
- chacun
- facilité
- plus facilement
- de manière efficace
- efficace
- efficace
- non plus
- éléments
- enrobage
- permettre
- fin
- ENGINEERING
- Les ingénieurs
- Moteurs
- Anglais
- Assure
- Environment
- essence
- essential
- Ether (ETH)
- Pourtant, la
- évolution
- exécuter
- Exercises
- Explorer
- extrait
- faciliter
- Familiarité
- loin
- Fonctionnalité
- Fonctionnalités:
- Fed
- Figure
- Déposez votre dernière attestation
- Fichiers
- Trouvez
- Prénom
- plat
- Abonnement
- Pour
- Premier plan
- formulaire
- le format
- Gratuit
- De
- avenir
- écart
- générer
- génération
- génératif
- IA générative
- genre
- GitHub
- Donner
- donné
- Réservation de groupe
- Groupes
- manipuler
- arriver
- Vous avez
- vous aider
- aide
- ici
- Haute
- de haut niveau
- très
- historique
- Comment
- Cependant
- HTTPS
- majeur
- Des centaines
- i
- ID
- identifier
- if
- satellite
- Impact
- la mise en oeuvre
- importer
- améliorer
- in
- de plus en plus
- indice
- indexé
- index
- indiquant
- Indices
- secteurs
- industrie
- Influent
- d'information
- inhérent
- technologie innovante
- contribution
- entrées
- Inserts
- à l'intérieur
- idées.
- instance
- plutôt ;
- Intelligence
- interagir
- l'interaction
- interactions
- développement
- subtilités
- implique
- IT
- SES
- Emplois
- rejoindre
- Rejoignez-nous
- chemin
- juste
- ACTIVITES
- clés
- mots clés
- enfants
- Savoir
- Libellé
- Transport routier
- paysage d'été
- gros
- conduisant
- Conduit
- apprentissage
- Levier
- les leviers
- comme
- Liste
- chargeur
- logique
- vous connecter
- click
- machine learning
- majeur
- a prendre une
- FAIT DU
- Fabrication
- les gérer
- manière
- manuellement
- Fabricants
- Localisation
- massif
- allumettes
- mathématique
- significative
- mesurer
- les mesures
- mesure
- mécanisme
- Médias
- aller
- Méthodologie
- méthodes
- Microsoft
- minimal
- modèle
- numériques jumeaux (digital twin models)
- PLUS
- Par ailleurs
- (en fait, presque toutes)
- beaucoup
- plusieurs
- must
- prénom
- Nature
- Besoin
- Nouveauté
- maintenant
- nombreux
- objet
- objets
- of
- code
- on
- ONE
- et, finalement,
- en ligne
- uniquement
- ouvert
- OpenAI
- Opérations
- opposé
- or
- organisation
- Organisé
- organise
- original
- OS
- Autre
- nos
- propriété
- page
- paire
- partie
- passé
- En passant
- motifs
- parfaite
- effectuer
- performant
- effectué
- effectue
- objectifs
- perspectives
- image
- pivot
- Plaine
- Platon
- Intelligence des données Platon
- PlatonDonnées
- joue
- veuillez cliquer
- Point
- des notes bonus
- possible
- défaillances
- power
- solide
- Méthode
- Applications pratiques
- précis
- précisément
- préférences
- précédent
- Problème
- processus
- Produit
- Produits
- Projet
- important
- instructions
- correctement
- propriétés
- propriété
- fournir
- aportando
- disposition
- publié
- Bouffée
- but
- des fins
- Quantité
- requêtes
- question
- Rapide
- plus rapidement
- vite.
- rapidement
- Recommandation
- recommandations
- en ce qui concerne
- région
- rapports
- Les relations
- pertinent
- représentation
- représenté
- représente
- conditions
- Exigences
- réponse
- réponses
- résultat
- Résultats
- Révélé
- Rôle
- RANGÉE
- s
- même
- Sciences
- portée
- Rechercher
- Les moteurs de recherche
- recherches
- recherche
- sentiment
- seo
- Paramétres
- Forme
- mise en forme
- commun
- Étagère
- Shorts
- montré
- Spectacles
- côté
- similaires
- similitudes
- étapes
- depuis
- unique
- Taille
- So
- sur mesure
- Solutions
- quelques
- Identifier
- Space
- groupe de neurones
- vitesse
- scission
- repérage
- SQL
- Région
- Déclaration
- déclarations
- Étapes
- Encore
- storage
- Boutique
- stockée
- STORES
- structure
- structuré
- Étude
- Par la suite
- réussi
- synergie
- combustion propre
- Système
- T
- table
- TAG
- tâches
- techniques
- technologique
- conditions
- texte
- génération de texte
- que
- qui
- La
- El futuro
- leur
- Les
- Ces
- l'ont
- this
- trois
- Avec
- fiable
- fois
- à
- traditionnel
- Train
- Transformer
- De La Carrosserie
- transformation
- transformé
- Essai
- deux
- types
- En fin de compte
- comprendre
- compréhension
- indubitablement
- ouvrir
- déverrouillage
- Mises à jour
- améliorer
- us
- Utilisation
- utilisé
- d'utiliser
- Utilisateur
- Usages
- en utilisant
- habituel
- Valeurs
- variété
- divers
- très
- vital
- vs
- était
- we
- webp
- bien défini
- ont été
- Quoi
- Qu’est ce qu'
- que
- qui
- tout en
- sera
- comprenant
- dans les
- des mots
- activités principales
- de travail
- pourra
- you
- Votre
- zéphyrnet