Cet article a été co-écrit avec Greg Benson, scientifique en chef ; Aaron Kesler, chef de produit principal ; et Rich Dill, architecte de solutions d'entreprise de SnapLogic.
De nombreux clients créent des applications d'IA générative sur Socle amazonien ainsi que Chuchoteur de code Amazon pour créer des artefacts de code basés sur le langage naturel. Ce cas d'utilisation met en évidence comment les grands modèles de langage (LLM) sont capables de devenir un traducteur entre les langues humaines (anglais, espagnol, arabe, etc.) et les langages interprétables par machine (Python, Java, Scala, SQL, etc.) ainsi que des outils sophistiqués. raisonnement interne. Cette capacité émergente des LLM a obligé les développeurs de logiciels à utiliser les LLM comme un outil d'automatisation et d'amélioration de l'UX qui transforme le langage naturel en un langage spécifique à un domaine (DSL) : instructions système, requêtes API, artefacts de code, etc. Dans cet article, nous vous montrons comment SnapLogique, un client AWS, a utilisé Amazon Bedrock pour alimenter son SnapGPT produit grâce à la création automatisée de ces artefacts DSL complexes à partir du langage humain.
Lorsque les clients créent des objets DSL à partir de LLM, le DSL résultant est soit une réplique exacte, soit un dérivé des données et du schéma d'une interface existante qui forme le contrat entre l'interface utilisateur et la logique métier du service de support. Ce modèle est particulièrement tendance auprès des éditeurs de logiciels indépendants (ISV) et des éditeurs de logiciels en tant que service (SaaS) en raison de leur manière unique de représenter les configurations via du code et de leur désir de simplifier l'expérience utilisateur pour leurs clients. Exemples de cas d'utilisation :
Le moyen le plus simple de créer et de mettre à l'échelle des applications texte-à-pipeline avec des LLM sur AWS consiste à utiliser Amazon Bedrock. Amazon Bedrock constitue le moyen le plus simple de créer et de faire évoluer des applications d'IA générative avec des modèles de base (FM). Il s'agit d'un service entièrement géré qui offre l'accès à un choix de FM de base très performants parmi les principales IA via une API unique, ainsi qu'un large ensemble de fonctionnalités dont vous avez besoin pour créer des applications d'IA génératives avec confidentialité et sécurité. Anthropic, un laboratoire de recherche et de sécurité en IA qui construit des systèmes d'IA fiables, interprétables et orientables, est l'une des principales sociétés d'IA qui offre l'accès à son LLM de pointe, Claude, sur Amazon Bedrock. Claude est un LLM qui excelle dans un large éventail de tâches, du dialogue réfléchi à la création de contenu, en passant par le raisonnement complexe, la créativité et le codage. Anthropic propose les modèles Claude et Claude Instant, tous disponibles via Amazon Bedrock. Claude a rapidement gagné en popularité dans ces applications text-to-pipeline en raison de sa capacité de raisonnement améliorée, qui lui permet d'exceller dans la résolution de problèmes techniques ambigus. Claude 2 sur Amazon Bedrock prend en charge une fenêtre contextuelle de 100,000 200 jetons, ce qui équivaut à environ XNUMX pages de texte anglais. Il s'agit d'une fonctionnalité particulièrement importante sur laquelle vous pouvez compter lors de la création d'applications texte-à-pipeline qui nécessitent un raisonnement complexe, des instructions détaillées et des exemples complets.
Arrière-plan SnapLogic
SnapLogic est un client AWS dont la mission est d'apporter l'automatisation d'entreprise au monde. La plate-forme d'intégration intelligente (IIP) SnapLogic permet aux organisations de réaliser une automatisation à l'échelle de l'entreprise en connectant l'ensemble de leur écosystème d'applications, de bases de données, de Big Data, de machines et d'appareils, d'API, etc. avec des connecteurs intelligents prédéfinis appelés Snaps. SnapLogic a récemment publié une fonctionnalité appelée SnapGPT, qui fournit une interface texte dans laquelle vous pouvez saisir le pipeline d'intégration souhaité que vous souhaitez créer dans un langage humain simple. SnapGPT utilise le modèle Claude d'Anthropic via Amazon Bedrock pour automatiser la création de ces pipelines d'intégration sous forme de code, qui sont ensuite utilisés via la solution d'intégration phare de SnapLogic. Cependant, le parcours de SnapLogic vers SnapGPT a été le point culminant de nombreuses années d'activité dans le domaine de l'IA.
Le parcours de l'IA de SnapLogic
Dans le domaine des plateformes d'intégration, SnapLogic a toujours été à l'avant-garde, exploitant le pouvoir transformateur de l'intelligence artificielle. Au fil des années, l'engagement de l'entreprise à innover avec l'IA est devenu évident, surtout lorsque l'on retrace le parcours depuis Iris à Lien automatique.
Les humbles débuts avec Iris
En 2017, SnapLogic a dévoilé Iris, le premier assistant d'intégration basé sur l'IA du secteur. Iris a été conçu pour utiliser des algorithmes d'apprentissage automatique (ML) afin de prédire les prochaines étapes de la création d'un pipeline de données. En analysant des millions d'éléments de métadonnées et de flux de données, Iris pourrait faire des suggestions intelligentes aux utilisateurs, démocratisant l'intégration des données et permettant même à ceux qui n'ont pas de connaissances techniques approfondies de créer des flux de travail complexes.
AutoLink : créer une dynamique
S'appuyant sur le succès et les enseignements d'Iris, SnapLogic a introduit AutoLink, une fonctionnalité visant à simplifier davantage le processus de mappage des données. La tâche fastidieuse consistant à mapper manuellement les champs entre les systèmes source et cible est devenue un jeu d'enfant avec AutoLink. Grâce à l'IA, AutoLink a automatiquement identifié et suggéré des correspondances potentielles. Des intégrations qui prenaient autrefois des heures pouvaient être exécutées en quelques minutes seulement.
Le saut génératif avec SnapGPT
La dernière incursion de SnapLogic dans l'IA nous amène SnapGPT, qui vise à révolutionner encore plus l'intégration. Avec SnapGPT, SnapLogic présente la première solution d'intégration générative au monde. Il ne s’agit pas seulement de simplifier les processus existants, mais de réinventer entièrement la façon dont les intégrations sont conçues. La puissance de l'IA générative peut créer des pipelines d'intégration complets à partir de zéro, optimisant le flux de travail en fonction du résultat souhaité et des caractéristiques des données.
SnapGPT a un impact extrêmement important pour les clients de SnapLogic car ils sont en mesure de réduire considérablement le temps requis pour générer leur premier pipeline SnapLogic. Traditionnellement, les clients SnapLogic devaient passer des jours ou des semaines à configurer les pipelines d'intégration à partir de zéro. Désormais, ces clients peuvent simplement demander à SnapGPT, par exemple, de « créer un pipeline qui déplacera tous mes clients SFDC actifs vers WorkDay ». Une première version fonctionnelle d'un pipeline est automatiquement créée pour ce client, réduisant considérablement le temps de développement requis pour la création de la base de son pipeline d'intégration. Cela permet au client final de consacrer plus de temps à se concentrer sur ce qui a un véritable impact commercial sur lui au lieu de travailler sur les configurations d'un pipeline d'intégration. L'exemple suivant montre comment un client SnapLogic peut saisir une description dans la fonctionnalité SnapGPT pour générer rapidement un pipeline, en utilisant un langage naturel.
![]()
AWS et SnapLogic ont collaboré étroitement tout au long de la création de ce produit et ont beaucoup appris en cours de route. Le reste de cet article se concentrera sur les apprentissages techniques qu'AWS et SnapLogic ont acquis concernant l'utilisation des LLM pour les applications text-to-pipeline.
Vue d'ensemble de la solution
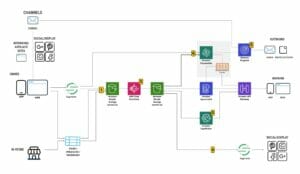
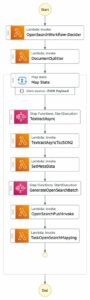
Pour résoudre ce problème de texte vers pipeline, AWS et SnapLogic ont conçu une solution complète présentée dans l'architecture suivante.
![]()
Une requête adressée à SnapGPT passe par le workflow suivant :
- Un utilisateur soumet une description à l'application.
- SnapLogic utilise une approche de génération augmentée de récupération (RAG) pour récupérer des exemples pertinents de pipelines SnapLogic similaires à la demande de l'utilisateur.
- Ces exemples pertinents extraits sont combinés avec les entrées de l'utilisateur et subissent un prétraitement de texte avant d'être envoyés à Claude sur Amazon Bedrock.
- Claude produit un artefact JSON qui représente un pipeline SnapLogic.
- L'artefact JSON est directement intégré à la plateforme d'intégration principale SnapLogic.
- Le pipeline SnapLogic est présenté à l'utilisateur de manière visuellement conviviale.
Grâce à diverses expérimentations entre AWS et SnapLogic, nous avons constaté que l'étape d'ingénierie rapide du diagramme de solution est extrêmement importante pour générer des sorties de haute qualité pour ces sorties texte vers pipeline. La section suivante approfondit certaines techniques spécifiques utilisées avec Claude dans cet espace.
Expérimentation rapide
Tout au long de la phase de développement de SnapGPT, AWS et SnapLogic ont constaté qu'une itération rapide des invites envoyées à Claude constituait une tâche de développement essentielle pour améliorer la précision et la pertinence des sorties texte vers pipeline dans les sorties de SnapLogic. En utilisant Amazon SageMakerStudio blocs-notes interactifs, l'équipe AWS et SnapLogic ont pu travailler rapidement sur différentes versions d'invites en utilisant le Connexion du SDK Boto3 à Amazon Bedrock. Le développement basé sur des blocs-notes a permis aux équipes de créer rapidement des connexions côté client à Amazon Bedrock, d'inclure des descriptions textuelles aux côtés du code Python pour envoyer des invites à Amazon Bedrock et d'organiser des sessions d'ingénierie d'invite conjointes au cours desquelles des itérations ont été effectuées rapidement entre plusieurs personnes.
Méthodes d'ingénierie anthropiques de Claude
Dans cette section, nous décrivons certaines des techniques itératives que nous avons utilisées pour créer une invite très performante basée sur une demande utilisateur illustrative : « Créez un pipeline qui utilise la base de données SampleCompany qui récupère tous les clients actifs. » Notez que cet exemple n'est pas le schéma sur lequel SnapGPT est alimenté et est uniquement utilisé pour illustrer une application texte vers pipeline.
Pour baser notre ingénierie d'invite, nous utilisons l'invite originale suivante :
Créez un pipeline qui utilise la base de données SampleCompany qui récupère tous les clients actifs
Le résultat attendu est le suivant :
{ "database": "ExampleCompany", "query": "SELECT * FROM ec_prod.customers WHERE status = 'active'" }
Amélioration n°1 : Utilisation des annotations Human et Assistant
La procédure de formation de Claude apprend au FM à comprendre le dialogue entre un humain et un assistant dans sa structure instantanée. Les utilisateurs de Claude peuvent profiter de cette structure en terminant leur invite dans Assistant :, ce qui incitera Claude à commencer à générer la réponse à une requête basée sur ce que l'humain a dit. Notez que, étant donné que Claude continuera à générer du texte jusqu'à ce qu'on lui dise d'arrêter, assurez-vous d'utiliser une séquence d'arrêt de nnHuman: dans la requête API adressée à Amazon Bedrock lorsque vous utilisez Claude. Cela garantira que vous recevrez uniquement la réponse de l'assistant et non la prochaine réponse prévue de l'humain dans la chaîne de dialogue. Ces indicateurs nnHuman et nnAssistant aident non seulement à limiter la réponse de Claude aux informations pertinentes, mais aident également à fournir une démarcation claire entre les entrées humaines primaires et les réponses de l'assistant provenant d'autres interactions. Cela est particulièrement utile dans un paramètre d'invite en quelques étapes où vous pouvez avoir plusieurs requêtes et réponses avec des requêtes étiquetées avec nnHuman et des réponses précédentes étiquetées avec nnAssistant. Examinons l'invite améliorée et l'appel d'API illustratif associé vers Amazon Bedrock via le SDK Boto3.
Nous utilisons l'invite suivante :
Humain : créez un pipeline qui utilise la base de données SampleCompany qui récupère tous les clients actifs
Assistants :
La sortie est la suivante:
Voici un pipeline MongoDB pour récupérer tous les clients actifs de la base de données SampleCompany :
pipeline = [ { '$match': { 'database': 'ExampleCompany', 'status': 'active' } } ] db.customers.aggregate(pipeline)Les étapes clés sont:
– `$match` pour filtrer les documents uniquement ceux de la base de données ExempleCompany et avec un statut égal à « actif ».
– `db.customers.aggregate()` exécute le pipeline sur la collection clients et renvoie les résultats filtrés.
Cela renverra donc tous les documents clients de la base de données SampleCompany où le champ de statut est défini sur « actif ».
Remarquez comment, dans le résultat, Claude invente une réponse à notre question sans aucun contexte. La réponse est potentiellement utile, mais elle n’est pas spécifique au problème que nous essayons de résoudre car elle n’est pas suffisamment contextuelle. Il est également important de noter qu'Anthropic nécessite ce format humain et assistant lors de l'utilisation des modèles Claude ; si vous n'incluez pas cette étape, Amazon Bedrock renverra une erreur.
Amélioration n°2 : Incluez un contexte hyper-spécifique pour Claude avant qu'on lui dise quoi faire
Claude obtient de meilleurs résultats lorsqu'on lui donne un bon contexte sur ce qu'il doit accomplir ainsi que sur la manière dont il est censé accomplir cette tâche. Voici quelques exemples d’éléments à inclure comme contexte pour Claude avant de lui confier la tâche :
- Décrivez la fonction que vous souhaitez que Claude occupe. En faisant cela, vous faites réfléchir Claude dans le rôle de quelqu'un qui travaille dans ce poste, ou plutôt comme quelqu'un qui vient d'être embauché dans ce rôle spécifique. Cela aidera Claude à formuler la réponse du point de vue de ce poste spécifique, réduisant ainsi les hallucinations et le caractère aléatoire de la réponse.
- Incluez des détails techniques concernant le format de sortie. Les modèles de base sont généralement efficaces pour suivre les actions, donc demander à Claude de générer la sortie dans un format ou un schéma spécifique avec un ou quelques exemples aidera Claude à fournir la réponse dans le bon format, réduisant ainsi le besoin de filtrage et de post-traitement de la sortie. L'exemple de l'invite suivante montre un schéma fictif qui correspond au résultat attendu.
Combinons ces suggestions pour améliorer notre invite d'origine :
Humain : Votre travail consiste à agir en tant qu’expert sur les pipelines ETL. Plus précisément, votre travail consiste à créer une représentation JSON d'un pipeline ETL qui résoudra la demande de l'utilisateur qui vous est fournie.
La sortie JSON doit suivre le format suivant :
Voici votre tâche : créer un pipeline qui utilise la base de données ExempleCompany qui récupère tous les clients actifs
Assistants :
La sortie est la suivante:
Voici une représentation JSON d'un pipeline ETL pour récupérer tous les clients actifs de la base de données SampleCompany :
Ce pipeline utilise la base de données SampleCompany et une requête SQL pour sélectionner tous les enregistrements de la table clients dont le statut est « actif ».
Avec l’ajout du contexte, le modèle est désormais en mesure d’obtenir l’essentiel de notre réponse. Il sait maintenant comment structurer la sortie et comprend qu’il doit écrire une instruction SQL pour résoudre la tâche. Cependant, vous remarquerez que le modèle n'utilise pas correctement la nomenclature ec_prod.customers que nous attendons. Marge d'amélioration! Notez également qu'en pratique, vous devrez inclure beaucoup plus de contexte que ce que nous avons fourni dans cet exemple pour obtenir des résultats de haute qualité dans les cas d'utilisation de texte vers pipeline.
Amélioration n°3 : inclure des exemples dans des balises XML
L'apprentissage en quelques étapes est un moyen populaire d'augmenter la précision avec les FM où vous disposez d'exemples pertinents pour guider le FM dans sa tâche. Ceci est particulièrement important lorsque vous travaillez dans des applications texte-à-pipeline, car ces sorties de pipeline hyper-spécifiques ne sont généralement incluses dans aucun ensemble de données public car elles sont spécifiques à la représentation des données d'un client individuel. En utilisant Claude, vous pouvez profiter de sa connaissance innée des balises XML arbitraires afin de fournir ces exemples en quelques clichés. Dans l'invite améliorée suivante, notez l'ajout d'exemples inclus entre Balises XML. De plus, vous pouvez utiliser des abréviations pour humain et assistant avec H et A pour fournir un contexte à Claude sans lui faire croire qu'il s'agit d'éléments spécifiques du dialogue qui ont déjà eu lieu.
Nous utilisons l'invite suivante :
Humain : Votre travail consiste à agir en tant qu’expert sur les pipelines ETL. Plus précisément, votre travail consiste à créer une représentation JSON d'un pipeline ETL qui résoudra la demande de l'utilisateur qui vous est fournie.
La sortie JSON doit suivre le format suivant :
Voici quelques exemples de demandes d'utilisateurs et d'artefacts JSON de sortie associés qui résolvent correctement la tâche fournie. Assurez-vous d'utiliser la même nomenclature que celle fournie dans les exemples si vous utilisez les mêmes bases de données.
H : interrogez la base de données SampleCompany pour toute commande active pour le client n° 1234.
A:
Le raisonnement de cette requête est que le client n° 1234 est filtré et que nous recherchons dans la table « commandes » tous les enregistrements existants après le filtre « actif ».
H : supprimer tous les clients de la base de données ExempleCompany qui n'ont pas été actifs au cours du mois dernier
A:
Le raisonnement de cette requête est que la table « ec_prod.customers » est la seule table de la base de données SampleCompany qui contient des enregistrements clients.
Voici votre tâche : créez un pipeline qui utilise la base de données SampleCompany qui récupère tous les clients actifs.
Assistants :
La sortie est la suivante:
Voici la représentation JSON d'un pipeline ETL permettant de récupérer tous les clients actifs de la base de données SampleCompany :
Le raisonnement est le suivant :
La base de données SampleCompany est spécifiée comme base de données à utiliser
La table ec_prod.customers contient les données client
Le champ d'état indique si un client est actif, la requête filtre donc uniquement les clients actifs.
Cela devrait récupérer tous les enregistrements clients actifs de la base de données SampleCompany. Faites-moi savoir si vous avez besoin de précisions ou si vous avez des exigences supplémentaires pour le pipeline ETL !
La sortie JSON a désormais la nomenclature de base de données correcte, que Claude a pu utiliser grâce aux exemples que nous avons fournis. Le couplage d'indicateurs humains et assistants avec des balises XML permet à Claude de comprendre plus facilement quelle est la tâche et quelle a été la réponse dans des exemples similaires avec une séparation très claire entre plusieurs exemples de quelques plans. Plus il est facile pour Claude de comprendre, plus la réponse sera meilleure et pertinente, réduisant encore davantage le risque pour le modèle d'halluciner et de fournir des réponses aléatoires non pertinentes.
Amélioration n°4 : Déclencher Claude pour commencer la génération JSON avec des balises XML
Un petit défi avec les applications de texte à pipeline utilisant des FM est la nécessité d'analyser exactement une sortie du texte résultant afin qu'elle puisse être interprétée comme du code dans une application en aval. Une façon de résoudre ce problème avec Claude consiste à tirer parti de sa compréhension des balises XML et à la combiner avec une séquence d'arrêt personnalisée. Dans l'invite suivante, nous avons demandé à Claude de placer la sortie dans Balises XML. Ensuite, nous avons ajouté le balise à la fin de l’invite. Cela garantit que le premier texte sortant de Claude sera le début de la sortie JSON. Si vous ne le faites pas, Claude répond souvent par un texte conversationnel, puis la véritable réponse codée. En demandant à Claude de commencer immédiatement à générer la sortie, vous pouvez facilement arrêter la génération lorsque vous voyez la fin étiqueter. Ceci est affiché dans l’appel API Boto3 mis à jour. Les avantages de cette technique sont doubles. Tout d’abord, vous êtes capable d’analyser exactement la réponse du code de Claude. Deuxièmement, vous êtes en mesure de réduire les coûts car Claude génère uniquement des sorties de code et aucun texte supplémentaire. Cela réduit les coûts sur Amazon Bedrock, car vous êtes facturé pour chaque jeton produit en sortie de tous les FM.
Nous utilisons l'invite suivante :
Humain : Votre travail consiste à agir en tant qu’expert sur les pipelines ETL. Plus précisément, votre travail consiste à créer une représentation JSON d'un pipeline ETL qui résoudra la demande de l'utilisateur qui vous est fournie.
La sortie JSON doit suivre le format suivant :
Voici quelques exemples de demandes d'utilisateurs et d'artefacts JSON de sortie associés qui résolvent correctement la tâche fournie. Assurez-vous d'utiliser la même nomenclature que celle fournie dans les exemples si vous utilisez les mêmes bases de données.
H : interrogez la base de données SampleCompany pour toute commande active pour le client n° 1234.
A:
Le raisonnement de cette requête est que le client n° 1234 est filtré et que nous recherchons dans la table « commandes » tous les enregistrements existants après le filtre « actif ».
H : supprimer tous les clients de la base de données ExempleCompany qui n'ont pas été actifs au cours du mois dernier
A:
Le raisonnement de cette requête est que la table « ec_prod.customers » est la seule table de la base de données SampleCompany qui contient des enregistrements clients.
N'oubliez jamais de placer vos sorties JSON dans Mots clés.
Voici votre tâche : créez un pipeline qui utilise la base de données SampleCompany qui récupère tous les clients actifs.
Assistants :
Nous utilisons le code suivant :
body = json.dumps({"prompt": prompt, "stop_sequences": ['nnHuman:', '</json>']})
response = bedrock.invoke_model(
body=body,
modelId='anthropic.claude-v2'
)La sortie est la suivante:
{ "database": "ExampleCompany", "query": "SELECT * FROM ec_prod.customers WHERE status = 'active'" }
Nous sommes maintenant arrivés au résultat attendu avec uniquement l'objet JSON renvoyé ! En utilisant cette méthode, nous sommes capables de générer un artefact technique immédiatement utilisable ainsi que de réduire le coût de génération en réduisant les jetons de sortie.
Conclusion
Pour commencer dès aujourd'hui avec SnapGPT, demandez un essai gratuit de SnapLogic or demander une démo du produit. Si vous souhaitez utiliser ces concepts pour créer des applications aujourd'hui, nous vous recommandons expérimenter sur le terrain avec la section d'ingénierie rapide de cet article, en utilisant le même flux sur un cas d'utilisation de génération DSL différent qui convient à votre entreprise et en approfondissant le sujet. Fonctionnalités RAG disponibles via Amazon Bedrock.
SnapLogic et AWS ont pu s'associer efficacement pour créer un traducteur avancé entre le langage humain et le schéma complexe des pipelines d'intégration SnapLogic alimentés par Amazon Bedrock. Tout au long de ce parcours, nous avons vu comment le résultat généré avec Claude peut être amélioré dans les applications text-to-pipeline à l'aide de techniques d'ingénierie d'invite spécifiques. AWS et SnapLogic sont ravis de poursuivre ce partenariat dans le domaine de l'IA générative et attendent avec impatience la collaboration et l'innovation futures dans cet espace en évolution rapide.
À propos des auteurs
![]() Greg Benson est professeur d'informatique à l'Université de San Francisco et scientifique en chef chez SnapLogic. Il a rejoint le département d'informatique de l'USF en 1998 et a enseigné des cours de premier cycle et des cycles supérieurs, notamment sur les systèmes d'exploitation, l'architecture informatique, les langages de programmation, les systèmes distribués et la programmation d'introduction. Greg a publié des recherches dans les domaines des systèmes d'exploitation, de l'informatique parallèle et des systèmes distribués. Depuis qu'il a rejoint SnapLogic en 2010, Greg a contribué à la conception et à la mise en œuvre de plusieurs fonctionnalités clés de la plateforme, notamment le traitement des clusters, le traitement du Big Data, l'architecture cloud et l'apprentissage automatique. Il travaille actuellement sur l'IA générative pour l'intégration de données.
Greg Benson est professeur d'informatique à l'Université de San Francisco et scientifique en chef chez SnapLogic. Il a rejoint le département d'informatique de l'USF en 1998 et a enseigné des cours de premier cycle et des cycles supérieurs, notamment sur les systèmes d'exploitation, l'architecture informatique, les langages de programmation, les systèmes distribués et la programmation d'introduction. Greg a publié des recherches dans les domaines des systèmes d'exploitation, de l'informatique parallèle et des systèmes distribués. Depuis qu'il a rejoint SnapLogic en 2010, Greg a contribué à la conception et à la mise en œuvre de plusieurs fonctionnalités clés de la plateforme, notamment le traitement des clusters, le traitement du Big Data, l'architecture cloud et l'apprentissage automatique. Il travaille actuellement sur l'IA générative pour l'intégration de données.
![]() Aaron Kesler est chef de produit principal pour les produits et services d'IA chez SnapLogic, Aaron applique plus de dix ans d'expertise en gestion de produits pour être pionnier dans le développement de produits d'IA/ML et évangéliser les services dans toute l'organisation. Il est l'auteur du prochain livre « What's Your Problem ? » visant à guider les nouveaux chefs de produits tout au long de leur carrière en gestion de produits. Son parcours entrepreneurial a commencé avec sa startup universitaire, STAK, qui a ensuite été acquise par Carvertise, Aaron contribuant de manière significative à leur reconnaissance en tant que startup technologique de l'année 2015 dans le Delaware. Au-delà de ses activités professionnelles, Aaron trouve du plaisir à jouer au golf avec son père, à explorer de nouvelles cultures et de nouveaux aliments au cours de ses voyages et à pratiquer le ukulélé.
Aaron Kesler est chef de produit principal pour les produits et services d'IA chez SnapLogic, Aaron applique plus de dix ans d'expertise en gestion de produits pour être pionnier dans le développement de produits d'IA/ML et évangéliser les services dans toute l'organisation. Il est l'auteur du prochain livre « What's Your Problem ? » visant à guider les nouveaux chefs de produits tout au long de leur carrière en gestion de produits. Son parcours entrepreneurial a commencé avec sa startup universitaire, STAK, qui a ensuite été acquise par Carvertise, Aaron contribuant de manière significative à leur reconnaissance en tant que startup technologique de l'année 2015 dans le Delaware. Au-delà de ses activités professionnelles, Aaron trouve du plaisir à jouer au golf avec son père, à explorer de nouvelles cultures et de nouveaux aliments au cours de ses voyages et à pratiquer le ukulélé.
![]() Aneth riche est un architecte de solutions principal possédant une expérience couvrant de nombreux domaines de spécialisation. Un historique de réussite couvrant les logiciels d'entreprise multiplateformes et le SaaS. Bien connu pour transformer la défense des intérêts des clients (servant de voix au client) en de nouvelles fonctionnalités et produits générateurs de revenus. Capacité avérée à commercialiser des produits de pointe et à mener à bien des projets dans les délais et dans les limites du budget dans des environnements onshore et offshore en évolution rapide. Une façon simple de me décrire : l'esprit d'un scientifique, le cœur d'un explorateur et l'âme d'un artiste.
Aneth riche est un architecte de solutions principal possédant une expérience couvrant de nombreux domaines de spécialisation. Un historique de réussite couvrant les logiciels d'entreprise multiplateformes et le SaaS. Bien connu pour transformer la défense des intérêts des clients (servant de voix au client) en de nouvelles fonctionnalités et produits générateurs de revenus. Capacité avérée à commercialiser des produits de pointe et à mener à bien des projets dans les délais et dans les limites du budget dans des environnements onshore et offshore en évolution rapide. Une façon simple de me décrire : l'esprit d'un scientifique, le cœur d'un explorateur et l'âme d'un artiste.
![]() Argile Elmore est un architecte de solutions spécialisé en IA/ML chez AWS. Après avoir passé de nombreuses heures dans un laboratoire de recherche sur les matériaux, sa formation en génie chimique a rapidement été abandonnée pour poursuivre son intérêt pour l'apprentissage automatique. Il a travaillé sur des applications ML dans de nombreux secteurs différents, allant du commerce de l'énergie au marketing hôtelier. Le travail actuel de Clay chez AWS consiste à aider les clients à intégrer des pratiques de développement logiciel aux charges de travail de ML et d'IA générative, permettant ainsi aux clients de créer des solutions reproductibles et évolutives dans ces environnements complexes. Dans ses temps libres, Clay aime skier, résoudre des Rubik's cubes, lire et cuisiner.
Argile Elmore est un architecte de solutions spécialisé en IA/ML chez AWS. Après avoir passé de nombreuses heures dans un laboratoire de recherche sur les matériaux, sa formation en génie chimique a rapidement été abandonnée pour poursuivre son intérêt pour l'apprentissage automatique. Il a travaillé sur des applications ML dans de nombreux secteurs différents, allant du commerce de l'énergie au marketing hôtelier. Le travail actuel de Clay chez AWS consiste à aider les clients à intégrer des pratiques de développement logiciel aux charges de travail de ML et d'IA générative, permettant ainsi aux clients de créer des solutions reproductibles et évolutives dans ces environnements complexes. Dans ses temps libres, Clay aime skier, résoudre des Rubik's cubes, lire et cuisiner.
![]() Sina Sojoodi est un responsable technologique, un ingénieur système, un chef de produit, un ancien fondateur et un conseiller en startup. Il a rejoint AWS en mars 2021 en tant qu'architecte de solutions principal. Sina est actuellement l'architecte de solutions principal de la région ISV des États-Unis. Il travaille avec des éditeurs de logiciels SaaS et B2B pour développer et développer leurs activités sur AWS. Avant son poste chez Amazon, Sina était responsable technologique chez VMware et Pivotal Software (introduction en bourse en 2018, VMware M&A en 2020) et a occupé plusieurs postes de direction, notamment celui d'ingénieur fondateur chez Xtreme Labs (acquisition de Pivotal en 2013). Sina a consacré les 15 dernières années de son expérience professionnelle à la création de plates-formes et de pratiques logicielles pour les entreprises, les éditeurs de logiciels et le secteur public. C'est un leader de l'industrie passionné par l'innovation. Sina est titulaire d'un baccalauréat de l'Université de Waterloo où il a étudié le génie électrique et la psychologie.
Sina Sojoodi est un responsable technologique, un ingénieur système, un chef de produit, un ancien fondateur et un conseiller en startup. Il a rejoint AWS en mars 2021 en tant qu'architecte de solutions principal. Sina est actuellement l'architecte de solutions principal de la région ISV des États-Unis. Il travaille avec des éditeurs de logiciels SaaS et B2B pour développer et développer leurs activités sur AWS. Avant son poste chez Amazon, Sina était responsable technologique chez VMware et Pivotal Software (introduction en bourse en 2018, VMware M&A en 2020) et a occupé plusieurs postes de direction, notamment celui d'ingénieur fondateur chez Xtreme Labs (acquisition de Pivotal en 2013). Sina a consacré les 15 dernières années de son expérience professionnelle à la création de plates-formes et de pratiques logicielles pour les entreprises, les éditeurs de logiciels et le secteur public. C'est un leader de l'industrie passionné par l'innovation. Sina est titulaire d'un baccalauréat de l'Université de Waterloo où il a étudié le génie électrique et la psychologie.
![]() Sandeep Rohilla est architecte de solutions senior chez AWS, prenant en charge les clients ISV dans la région ouest des États-Unis. Il s'efforce d'aider les clients à concevoir des solutions tirant parti des conteneurs et de l'IA générative sur le cloud AWS. Sandeep est passionné par la compréhension des problèmes commerciaux des clients et par les aider à atteindre leurs objectifs grâce à la technologie. Il a rejoint AWS après avoir travaillé plus d'une décennie en tant qu'architecte de solutions, mettant à profit ses 17 années d'expérience. Sandeep est titulaire d'une maîtrise en sciences. en génie logiciel de l’Université de l’Ouest de l’Angleterre à Bristol, Royaume-Uni.
Sandeep Rohilla est architecte de solutions senior chez AWS, prenant en charge les clients ISV dans la région ouest des États-Unis. Il s'efforce d'aider les clients à concevoir des solutions tirant parti des conteneurs et de l'IA générative sur le cloud AWS. Sandeep est passionné par la compréhension des problèmes commerciaux des clients et par les aider à atteindre leurs objectifs grâce à la technologie. Il a rejoint AWS après avoir travaillé plus d'une décennie en tant qu'architecte de solutions, mettant à profit ses 17 années d'expérience. Sandeep est titulaire d'une maîtrise en sciences. en génie logiciel de l’Université de l’Ouest de l’Angleterre à Bristol, Royaume-Uni.
![]() Dr Farooq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
Dr Farooq Sabir est architecte principal de solutions spécialisées en intelligence artificielle et en apprentissage automatique chez AWS. Il est titulaire d'un doctorat et d'une maîtrise en génie électrique de l'Université du Texas à Austin et d'une maîtrise en informatique du Georgia Institute of Technology. Il a plus de 15 ans d'expérience de travail et aime aussi enseigner et encadrer des étudiants. Chez AWS, il aide les clients à formuler et à résoudre leurs problèmes commerciaux dans les domaines de la science des données, de l'apprentissage automatique, de la vision par ordinateur, de l'intelligence artificielle, de l'optimisation numérique et des domaines connexes. Basé à Dallas, au Texas, lui et sa famille adorent voyager et faire de longs trajets en voiture.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/how-snaplogic-built-a-text-to-pipeline-application-with-amazon-bedrock-to-translate-business-intent-into-action/
- :possède
- :est
- :ne pas
- :où
- $UP
- 10
- 100
- 121
- 14
- 15 ans
- 15%
- 150
- 17
- 1998
- 200
- 2010
- 2013
- 2015
- 2017
- 2018
- 2020
- 2021
- 31
- 33
- 7
- 8
- 9
- a
- Aaron
- capacité
- Capable
- A Propos
- accès
- accomplir
- précision
- atteindre
- a acquise
- acquisition
- à travers
- Agis
- Action
- actes
- infection
- ajoutée
- ajout
- Supplémentaire
- Avancée
- Avantage
- conseiller
- plaidoyer
- Après
- AI
- Systèmes d'IA
- Alimenté par l'IA
- AI / ML
- Destinée
- vise
- algorithmes
- Tous
- permis
- Permettre
- permet
- le long de
- aux côtés de
- déjà
- aussi
- Amazon
- Amazon Web Services
- montant
- an
- l'analyse
- ainsi que
- répondre
- réponses
- Anthropique
- tous
- api
- Apis
- Application
- applications
- s'applique
- une approche
- applications
- Arabe
- architecture
- SONT
- Réservé
- domaines
- autour
- arrivé
- Art
- artificiel
- intelligence artificielle
- L'INTELLIGENCE ARTIFICIELLE ET LE MACHINE LEARNING
- artiste
- AS
- demander
- demandant
- Assistante gérante
- associé
- At
- augmentée
- austin
- auteur
- automatiser
- Automatisation
- automatiquement
- Automation
- disponibles
- AWS
- Client AWS
- B2B
- fond
- support
- base
- basé
- Baseline
- BE
- Gardez
- est devenu
- car
- devenez
- était
- before
- a commencé
- commencer
- derrière
- va
- avantages.
- LES MEILLEURS
- Améliorée
- jusqu'à XNUMX fois
- Au-delà
- Big
- Big Data
- livre
- tous les deux
- apporter
- Apporter
- Apportez le
- Bristol
- vaste
- largement
- budget
- construire
- Développement
- construit
- construit
- la performance des entreprises
- impact sur les entreprises
- entreprises
- mais
- by
- Appelez-nous
- appelé
- CAN
- capacités
- Carrière
- maisons
- cas
- Centres
- chaîne
- challenge
- Chance
- caractéristiques
- accusé
- la chimie
- chef
- le choix
- clair
- étroitement
- fermeture
- le cloud
- Grappe
- code
- Codage
- collaboré
- collaboration
- collection
- Université
- combiner
- combiné
- vient
- engagement
- Sociétés
- De l'entreprise
- contraint
- achèvement
- complexe
- complet
- ordinateur
- Informatique
- Vision par ordinateur
- informatique
- concepts
- Configurer
- Connecter les
- connexion
- Connexions
- régulièrement
- Conteneurs
- contient
- contenu
- création de contenu
- contexte
- continuer
- contrat
- contribuant
- de la conversation
- cuisine
- Core
- correct
- correctement
- Prix
- pourriez
- cours
- engendrent
- créée
- création
- notre créativité
- critique
- Courant
- Lecture
- Customiser
- des clients
- Clients
- Coupe
- En investissant dans une technologie de pointe, les restaurants peuvent non seulement rester compétitifs dans un marché en constante évolution, mais aussi améliorer significativement l'expérience de leurs clients.
- Dallas
- données
- intégration de données
- informatique
- science des données
- Base de données
- bases de données
- jours
- décennie
- diminuer
- dévoué
- profond
- profond
- Delaware
- Démo
- Démocratiser
- Département
- dérivé
- décrire
- la description
- Conception
- un
- désir
- voulu
- détaillé
- détails
- mobiles
- Développement
- Compatibles
- Dialogue
- différent
- directement
- distribué
- systèmes distribués
- plongée
- do
- INSTITUTIONNELS
- Ne fait pas
- faire
- domaines
- Ne pas
- down
- avant-projet
- drastiquement
- motivation
- deux
- chacun
- plus facilement
- plus facile
- même
- risque numérique
- de manière efficace
- non plus
- ingénierie électrique
- éléments
- permet
- fin
- fin
- énergie
- ingénieur
- ENGINEERING
- de l'Angleterre
- Anglais
- Ce renforcement
- assez
- assurer
- Assure
- Entrer
- Entreprise
- logiciels d'entreprise
- Solutions d'entreprise
- entreprises
- Tout
- entièrement
- entrepreneurial
- environnements
- égal
- Équivalent
- erreur
- notamment
- Ether (ETH)
- Pourtant, la
- évident
- exactement
- exemple
- exemples
- Excel
- excité
- exécutif
- existant
- attendu
- attend
- d'experience
- expert
- nous a permis de concevoir
- explorateur
- Explorer
- supplémentaire
- extrêmement
- famille
- rapide
- rapide
- Fonctionnalité
- Fonctionnalités:
- few
- champ
- Des champs
- une fonction filtre
- filtration
- filtres
- trouve
- Prénom
- vaisseau amiral
- flux
- Flux
- Focus
- se concentre
- mettant l'accent
- suivre
- Abonnement
- suit
- aliments
- Pour
- Incursion
- Premier plan
- le format
- document
- Avant
- trouvé
- Fondation
- fonder
- Francisco
- friendly
- De
- Remplir
- d’étiquettes électroniques entièrement
- fonction
- plus
- avenir
- gagné
- généralement
- générer
- généré
- génère
- générateur
- génération
- génératif
- IA générative
- État de la Georgie
- Georgia Institute of Technology
- obtenez
- gif
- donné
- Go
- Objectifs
- Goes
- Bien
- diplôme
- Croître
- guide
- ait eu
- main
- Exploiter
- Vous avez
- he
- Cœur
- vous aider
- a aidé
- utile
- aider
- aide
- ici
- haute performance
- de haute qualité
- Faits saillants
- sa
- appuyez en continu
- détient
- hospitalité
- HEURES
- Comment
- How To
- Cependant
- HTML
- HTTPS
- humain
- humble
- identifié
- if
- illustrer
- immédiatement
- Impact
- percutants
- Mettre en oeuvre
- important
- améliorer
- amélioré
- l'amélioration de
- in
- comprendre
- inclus
- Y compris
- Améliore
- indépendant
- indique
- Indicateurs
- individuel
- secteurs
- industrie
- leader de l'industrie
- d'information
- inné
- innover
- Innovation
- contribution
- entrées
- instantané
- plutôt ;
- Institut
- Des instructions
- des services
- l'intégration
- intégrations
- Intelligence
- Intelligent
- intention
- interactions
- Interactif
- intérêt
- Interfaces
- interne
- développement
- introduit
- Introduit
- d'introduction
- IPO
- Isv
- IT
- itération
- itérations
- SES
- Java
- Emploi
- rejoint
- joindre
- joint
- chemin
- joie
- jpg
- json
- juste
- ACTIVITES
- Savoir
- spécialisées
- connu
- sait
- laboratoire
- Labs
- langue
- Langues
- gros
- Nom de famille
- plus tard
- Nouveautés
- conduire
- leader
- Leadership
- conduisant
- Sauter
- savant
- apprentissage
- à gauche
- laisser
- en tirant parti
- comme
- aime
- logique
- Location
- Style
- Lot
- love
- M&A
- click
- machine learning
- Les machines
- LES PLANTES
- a prendre une
- FAIT DU
- Fabrication
- gérés
- gestion
- manager
- Gestionnaires
- manière
- manuellement
- de nombreuses
- cartographie
- Mars
- Marché
- Stratégie
- allumettes
- matières premières.
- me
- mentor
- simple
- Métadonnées
- méthode
- des millions
- l'esprit
- minutes
- Mission
- ML
- modèle
- numériques jumeaux (digital twin models)
- MongoDB
- PLUS
- (en fait, presque toutes)
- Bougez
- MS
- Multi-plate-forme
- plusieurs
- my
- prénom
- Nature
- Langage naturel
- Besoin
- Besoins
- Nouveauté
- Nouvelles fonctionnalités
- nouveau produit
- next
- aucune
- noter
- ordinateurs portables
- Remarquer..
- maintenant
- objet
- objets
- a eu lieu
- of
- Offres Speciales
- souvent
- on
- une fois
- ONE
- uniquement
- d'exploitation
- systèmes d'exploitation
- à mettre en œuvre pour gérer une entreprise rentable. Ce guide est basé sur trois décennies d'expérience
- l'optimisation
- or
- de commander
- passer commande
- organisation
- organisations
- original
- Autre
- nos
- ande
- Résultat
- sortie
- sorties
- plus de
- pages
- Parallèle
- particulièrement
- les partenaires
- Partenariat
- passion
- passionné
- passé
- Patron de Couture
- effectue
- objectifs
- phase
- phd
- pièces
- Pioneer
- pipeline
- pivot
- Place
- plateforme
- Plateformes
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Populaire
- popularité
- Post
- défaillances
- l'éventualité
- power
- alimenté
- pratique
- pratiques
- prévoir
- prédit
- précédent
- primaire
- Directeur
- la confidentialité
- Confidentialité et sécurité
- Problème
- d'ouvrabilité
- procédure
- processus
- les process
- traitement
- Produit
- produit
- Produit
- le développement de produits
- gestion des produits
- chef de produit
- Produits
- Produits et services
- professionels
- Professeur
- Programmation
- langages de programmation
- projets
- instructions
- proven
- fournir
- à condition de
- fournit
- aportando
- Psychologie
- public
- publié
- Recherche publiée
- poursuivre
- Python
- requêtes
- question
- vite.
- aléatoire
- aléatoire
- gamme
- allant
- Nos tests de diagnostic produisent des résultats rapides et précis sans nécessiter d'équipement de laboratoire complexe et coûteux,
- en cours
- réaliser
- royaume
- recevoir
- récemment
- reconnaissance
- recommander
- record
- Articles
- réduire
- réduit
- réduire
- en ce qui concerne
- région
- repenser
- en relation
- libéré
- pertinent
- fiable
- compter
- rappeler
- supprimez
- rendu
- répétable
- répondre
- représentation
- représentation
- représente
- nécessaire
- demandes
- exigent
- conditions
- Exigences
- a besoin
- un article
- réponse
- réponses
- REST
- résultant
- Résultats
- retourner
- Retours
- révolutionner
- Rich
- bon
- routières
- Rôle
- rôle
- Salle
- Courir
- fonctionne
- SaaS.
- Sécurité
- sagemaker
- Saïd
- même
- San
- San Francisco
- Scala
- évolutive
- Escaliers intérieurs
- calendrier
- Sciences
- Scientifique
- gratter
- Sdk
- recherche
- Deuxièmement
- Section
- secteur
- sécurité
- sur le lien
- vu
- Sélectionner
- envoi
- supérieur
- envoyé
- Séquence
- servi
- service
- Services
- service
- brainstorming
- set
- mise
- plusieurs
- devrait
- montrer
- montré
- Spectacles
- de façon significative
- similaires
- étapes
- simplifier
- simplifiant
- simplement
- depuis
- unique
- petit
- So
- Logiciels
- logiciel en tant que service
- Développeurs de logiciels
- développement de logiciels
- génie logiciel
- sur mesure
- Solutions
- RÉSOUDRE
- Résoudre
- quelques
- Quelqu'un
- sophistiqué
- Âme
- Identifier
- Space
- Espagnol
- enjambant
- spécialiste
- groupe de neurones
- spécifiquement
- spécifié
- passer
- Dépenses
- SQL
- Commencer
- j'ai commencé
- Commencez
- Déclaration
- Statut
- étapes
- Étapes
- Arrêter
- simple
- structure
- Étudiante
- étudié
- succès
- Appuyer
- Les soutiens
- supposé
- sûr
- combustion propre
- Système
- table
- TAG
- Prenez
- Target
- Tâche
- tâches
- enseigné
- équipe
- équipes
- technologie
- démarrage tech
- Technique
- technique
- techniques
- Technologie
- dire
- Dix
- Texas
- texte
- que
- qui
- La
- L'Occident
- le monde
- leur
- Les
- puis
- Ces
- l'ont
- des choses
- penser
- this
- ceux
- Avec
- tout au long de
- fiable
- à
- aujourd'hui
- jeton
- Tokens
- dit
- a
- outil
- tracer
- suivre
- Commerce
- traditionnellement
- Formation
- transformation
- se transforme
- traduire
- Voyage
- voyage
- tendances
- procès
- déclencher
- déclenchement
- oui
- Vrai code
- essayer
- Tournant
- type
- ui
- Uk
- sous
- comprendre
- compréhension
- comprend
- expérience unique et authentique
- université
- jusqu'à
- dévoilé
- prochain
- a actualisé
- sur
- us
- utilisable
- utilisé
- cas d'utilisation
- d'utiliser
- Utilisateur
- Expérience utilisateur
- utilisateurs
- Usages
- en utilisant
- d'habitude
- ux
- divers
- fournisseurs
- très
- via
- vision
- visuel
- vmware
- Voix
- souhaitez
- était
- Façon..
- we
- web
- services Web
- Semaines
- WELL
- ont été
- Ouest
- Quoi
- Qu’est ce qu'
- quand
- qui
- large
- Large gamme
- sera
- fenêtre
- comprenant
- sans
- activités principales
- travaillé
- workflow
- workflows
- de travail
- vos contrats
- world
- monde
- pourra
- écrire
- XML
- an
- années
- you
- Votre
- Youtube
- zéphyrnet