Service Amazon OpenSearch récemment introduit Multi-AZ avec veille, une option de déploiement conçue pour offrir aux entreprises une disponibilité améliorée et des performances constantes pour les charges de travail critiques. Grâce à cette fonctionnalité, les clusters gérés peuvent atteindre une disponibilité de 99.99 % tout en restant résilients aux pannes de l'infrastructure zonale.
Dans cet article, nous explorons le fonctionnement de la recherche et de l'indexation avec Multi-AZ avec veille et approfondissons les mécanismes sous-jacents qui contribuent à sa fiabilité, sa simplicité et sa tolérance aux pannes.
Contexte
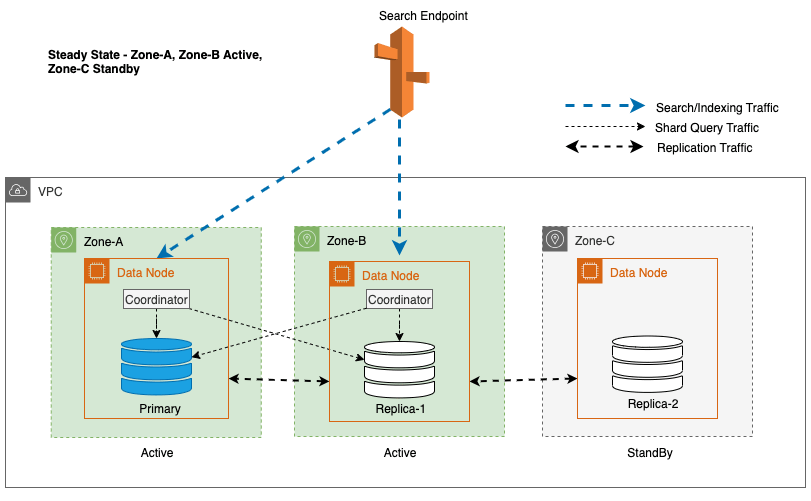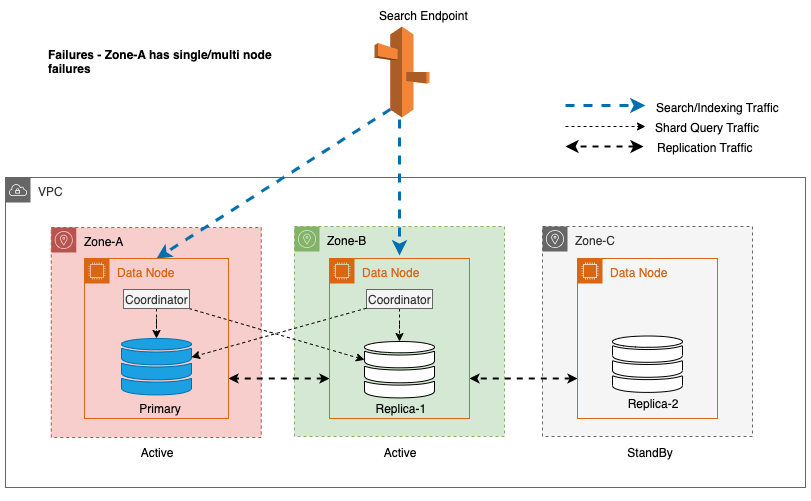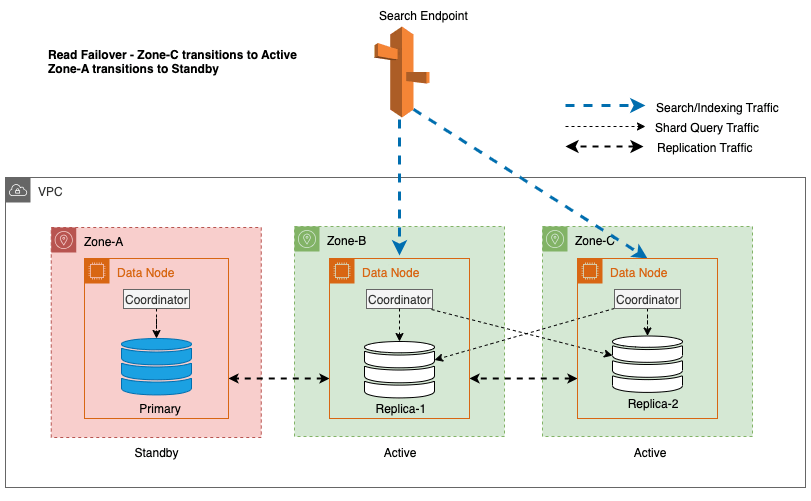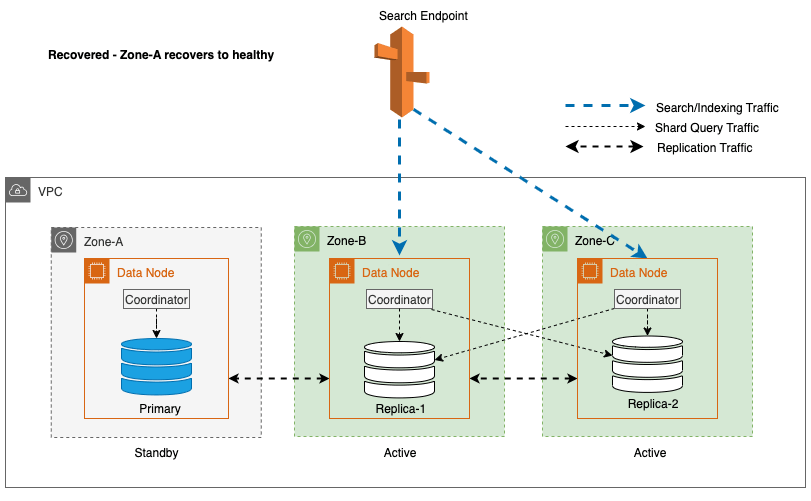
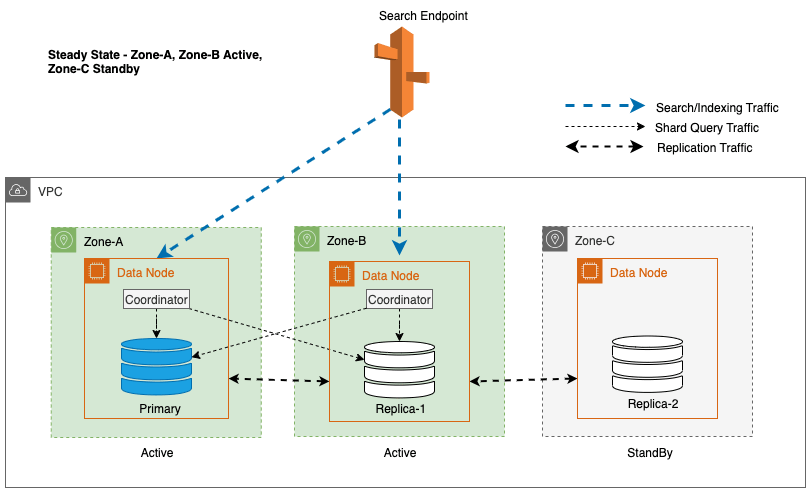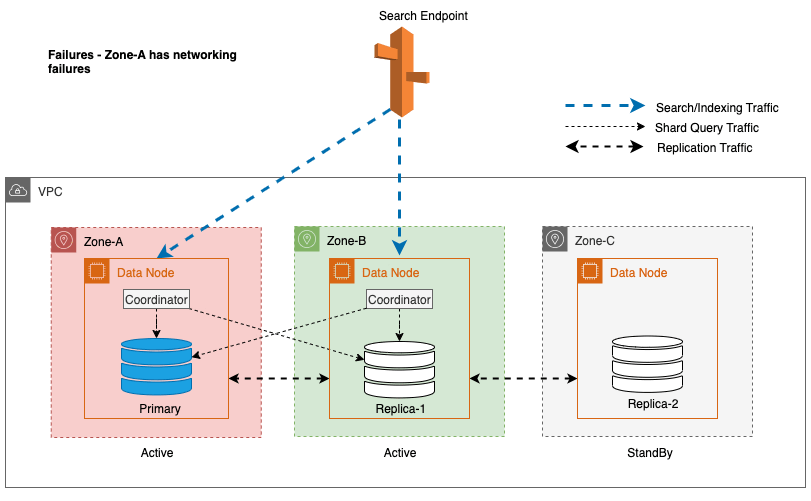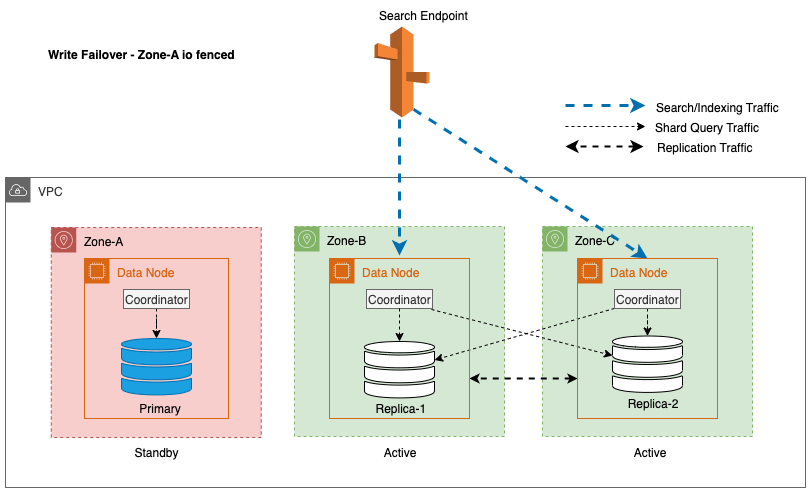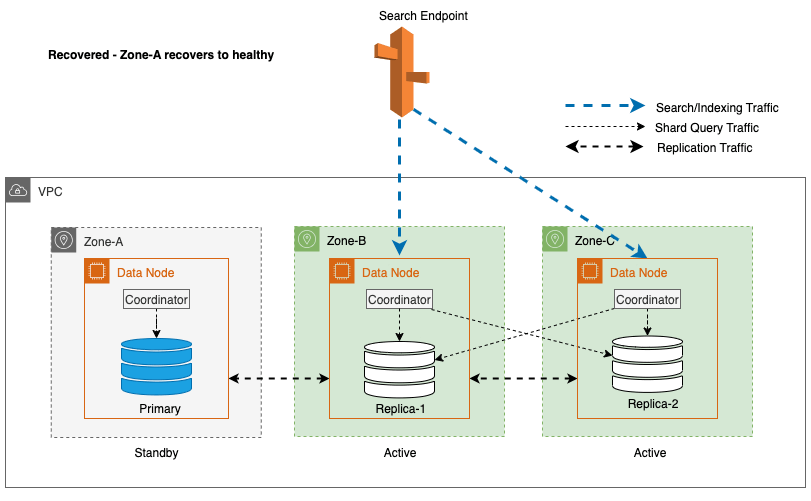
Multi-AZ avec veille déploie des instances de domaine OpenSearch Service sur trois zones de disponibilité, avec deux zones désignées comme actives et une comme veille. Cette configuration garantit des performances constantes, même en cas de pannes de zone, en conservant la même capacité dans toutes les zones. Il est important de noter que cette zone de veille suit un conception statiquement stable, éliminant ainsi le besoin de provisionnement de capacité ou de déplacement de données en cas de panne.
Lors des opérations normales, la zone active gère le trafic du coordinateur pour les demandes de lecture et d'écriture, ainsi que le trafic des requêtes de partition. La zone de veille, en revanche, reçoit uniquement le trafic de réplication. OpenSearch Service utilise un protocole de réplication synchrone pour les demandes d'écriture. Cela permet au service de promouvoir rapidement une zone de veille à l'état actif en cas de panne (durée moyenne de basculement <= 1 minute), connue sous le nom de basculement zonal. La zone précédemment active est alors rétrogradée en mode veille et les opérations de récupération commencent pour restaurer son état sain.
Recherchez le routage du trafic et le basculement pour garantir une haute disponibilité
Dans un domaine OpenSearch Service, un coordinateur est n'importe quel nœud qui gère les requêtes HTTP(S), en particulier les requêtes d'indexation et de recherche. Dans un domaine Multi-AZ avec Standby, les nœuds de données de la zone active agissent en tant que coordinateurs des requêtes de recherche.
Pendant la phase d'interrogation d'une requête de recherche, le coordinateur détermine les fragments à interroger et envoie une requête au nœud de données hébergeant la copie de fragment. La requête est exécutée localement sur chaque partition et les documents correspondants sont renvoyés au nœud coordinateur. Le nœud coordinateur, responsable de l'envoi de la requête aux nœuds contenant des copies matérielles, exécute le processus en deux étapes. Tout d'abord, il crée un itérateur qui définit l'ordre dans lequel les nœuds doivent être interrogés pour une copie de partition afin que le trafic soit réparti uniformément entre les copies de partition. Par la suite, la demande est envoyée aux nœuds concernés.
Afin de créer une liste ordonnée de nœuds à interroger pour une copie de partition, le nœud coordinateur utilise divers algorithmes. Ces algorithmes incluent la sélection circulaire, la sélection de répliques adaptatives, le routage de partitions basé sur les préférences et round robin pondéré.
Pour Multi-AZ avec Standby, l’algorithme round-robin pondéré est utilisé pour la sélection des copies de partition. Dans cette approche, les zones actives se voient attribuer un poids de 1 et la zone de veille se voit attribuer un poids de 0. Cela garantit qu'aucun trafic de lecture n'est envoyé aux nœuds de données dans la zone de disponibilité de veille.
Les pondérations sont stockées dans les métadonnées d'état du cluster en tant qu'objet JSON :
Comme le montre la capture d'écran suivante, le us-east-1b La région a son statut de zone comme StandBy, indiquant que les nœuds de données de cette zone de disponibilité sont en état de veille et ne reçoivent pas de demandes de recherche ou d'indexation de l'équilibreur de charge.

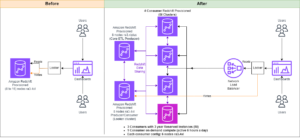
Pour maintenir des opérations stables, la zone de disponibilité de veille est alternée toutes les 30 minutes, garantissant ainsi que toutes les parties du réseau sont couvertes dans les zones de disponibilité. Cette approche proactive vérifie la disponibilité des chemins de lecture, améliorant ainsi la résilience du système en cas de pannes potentielles. Le diagramme suivant illustre cette architecture.
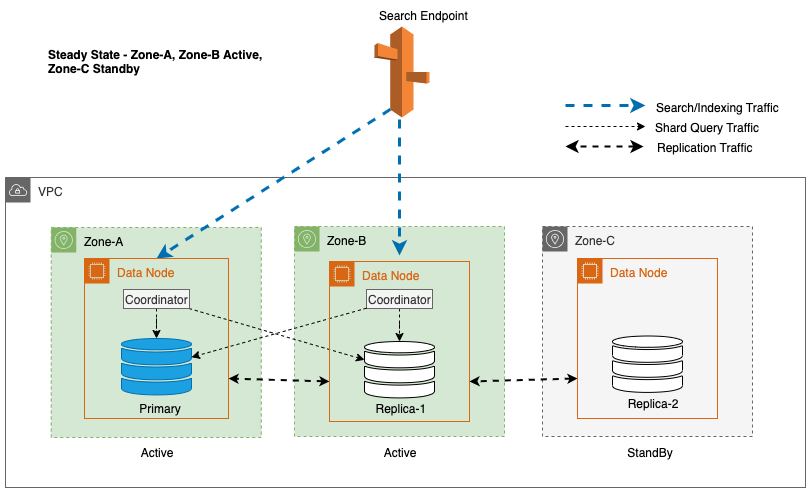
Dans le diagramme précédent, la Zone-C a un poids pondéré à tour de rôle fixé à zéro. Cela garantit que les nœuds de données de la zone de veille ne reçoivent aucun trafic d’indexation ou de recherche. Lorsque le coordinateur interroge les nœuds de données pour obtenir des copies de partition, il utilise une pondération circulaire pondérée pour décider de l'ordre dans lequel les nœuds doivent être interrogés. Étant donné que le poids est nul pour la zone de disponibilité en veille, les demandes du coordinateur ne sont pas envoyées.
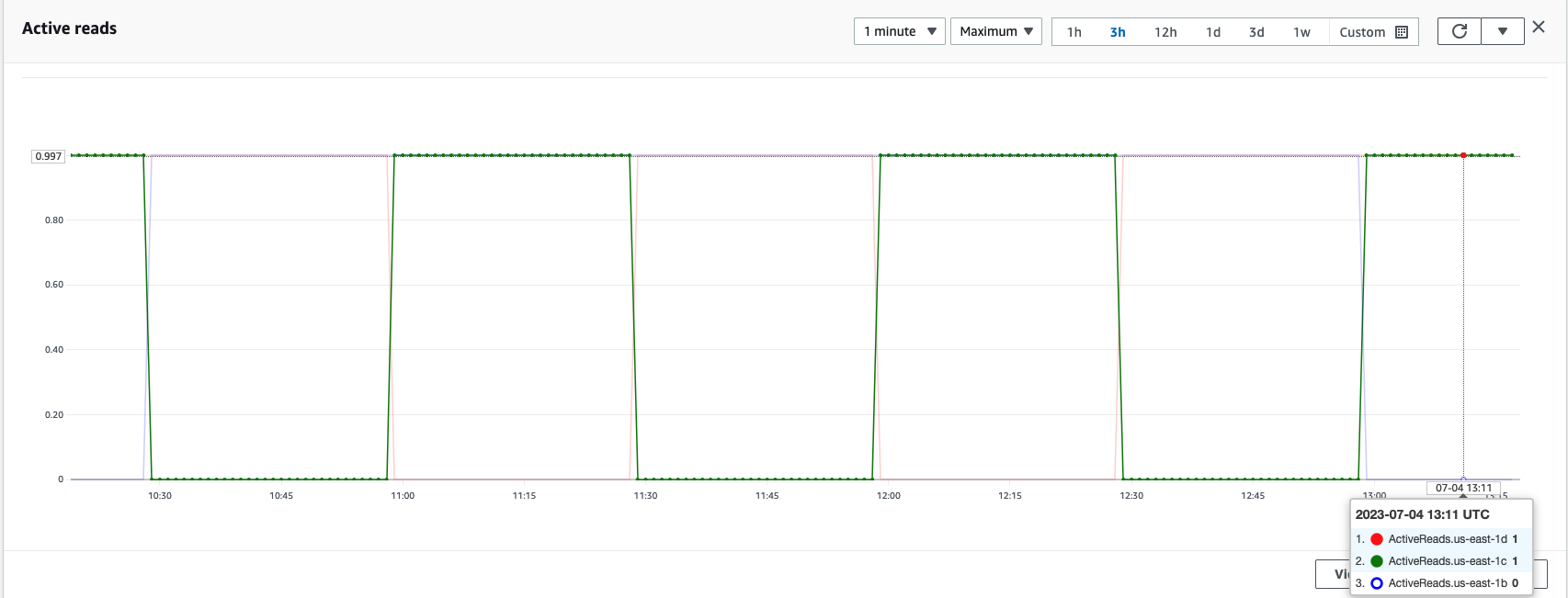
Dans un cluster OpenSearch Service, les zones actives et en veille peuvent être vérifiées à tout moment à l'aide des métriques de rotation des zones de disponibilité, comme indiqué dans la capture d'écran suivante.
Pendant les pannes de zone, la zone de disponibilité de veille passe de manière transparente en mode d'ouverture après échec pour les demandes de recherche. Cela signifie que le trafic des requêtes de partition est acheminé vers toutes les zones de disponibilité, même celles en veille, lorsqu'une copie de partition saine n'est pas disponible dans la zone de disponibilité active. Cette approche d'ouverture en cas de panne protège les demandes de recherche contre toute interruption en cas de panne, garantissant ainsi un service continu. Le diagramme suivant illustre cette architecture.
Dans le diagramme précédent, pendant l'état stable, le trafic des requêtes de partition est envoyé au nœud de données dans les zones de disponibilité actives (Zone-A et Zone-B). En raison de pannes de nœuds dans la zone A, la zone de disponibilité de veille (zone C) ne s'ouvre pas pour prendre en charge le trafic des requêtes de partition, de sorte qu'il n'y a aucun impact sur les demandes de recherche. Finalement, la Zone-A est détectée comme défectueuse et le basculement en lecture fait passer la zone de veille à la Zone-A.
Comment le basculement garantit la haute disponibilité en cas de déficience en écriture
Le modèle de réplication OpenSearch Service suit un modèle de sauvegarde principal, caractérisé par sa nature synchrone, dans lequel l'accusé de réception de toutes les copies matérielles est nécessaire avant qu'une demande d'écriture puisse être reconnue à l'utilisateur. Un inconvénient notable de ce modèle de réplication est sa susceptibilité aux ralentissements en cas de déficience du chemin d'écriture. Ces systèmes s'appuient sur un nœud leader actif pour identifier les pannes ou les retards, puis diffuser ces informations à tous les nœuds. Le temps nécessaire pour détecter ces problèmes (temps moyen de détection) et ensuite les résoudre (temps moyen de réparation) détermine en grande partie la durée pendant laquelle le système fonctionnera dans un état détérioré. De plus, tout événement réseau affectant les communications entre zones peut entraver considérablement les demandes d'écriture en raison de la nature synchrone de la réplication.
OpenSearch Service utilise un protocole de communication interne de nœud à nœud pour répliquer le trafic d'écriture et coordonner les mises à jour des métadonnées par l'intermédiaire d'un leader élu. Par conséquent, mettre en veille la zone soumise à un stress ne résoudrait pas efficacement le problème des déficiences en écriture.
Basculement d'écriture zonal : couper le trafic de réplication inter-zones
Pour Multi-AZ avec veille, afin d'atténuer les problèmes de performances potentiels provoqués lors d'événements imprévus tels que des pannes de zone et des événements réseau, le basculement d'écriture zonal est une approche efficace. Cette approche implique la suppression progressive des nœuds de la zone impactée du cluster, coupant ainsi efficacement le trafic d'entrée et de sortie entre les zones. En interrompant le trafic de réplication inter-zones, l'impact des pannes de zone peut être contenu dans la zone affectée. Cela offre une expérience plus prévisible aux clients et garantit que le système continue de fonctionner de manière fiable.
Basculement d'écriture gracieux
L'orchestration d'un basculement d'écriture au sein d'OpenSearch Service est effectuée par le nœud leader élu via un mécanisme bien défini. Ce mécanisme implique un protocole de consensus pour la publication de l'état du cluster, garantissant un accord unanime entre tous les nœuds pour désigner une seule zone (à tout moment) pour le déclassement. Il est important de noter que les métadonnées liées à la zone affectée sont répliquées sur tous les nœuds pour garantir leur persistance, même lors d'un redémarrage complet en cas de panne.
De plus, le nœud leader assure une transition fluide et gracieuse en plaçant initialement les nœuds dans les zones impactées en veille pendant une durée de 5 minutes avant de lancer le cloisonnement des E/S. Cette approche délibérée empêche tout nouveau trafic de coordinateur ou trafic de requête de partition d'être dirigé vers les nœuds de la zone impactée. Ceci, à son tour, permet à ces nœuds d'accomplir leurs tâches en cours avec élégance et de traiter progressivement toutes les demandes en vol avant d'être mis hors service. Le diagramme suivant illustre cette architecture.
Lors du processus de mise en œuvre d'un basculement en écriture pour un nœud leader, OpenSearch Service suit ces étapes clés :
- Abdication du chef – Si le nœud leader se trouve dans une zone programmée pour le basculement en écriture, le système garantit que le nœud leader quitte volontairement son rôle de leader. Cette abdication s'effectue de manière contrôlée et l'ensemble du processus est confié à un autre nœud éligible, qui prend alors en charge les actions requises.
- Empêcher la réélection du futur leader démis de ses fonctions – Pour empêcher la réélection d'un leader d'une zone marquée pour le basculement en écriture, lorsque le nœud leader éligible lance l'action de basculement en écriture, il prend des mesures pour garantir que tout nœud leader à mettre hors service ne participe à aucune autre élection. Ceci est réalisé en excluant le nœud leader à mettre hors service de la configuration de vote, l'empêchant ainsi de voter pendant toute phase critique du fonctionnement du cluster.
Les métadonnées liées à la zone de basculement en écriture sont stockées dans l'état du cluster et ces informations sont publiées sur tous les nœuds du cluster OpenSearch Service distribué comme suit :
La capture d'écran suivante montre que lors d'un ralentissement du réseau dans une zone, le basculement en écriture permet de récupérer la disponibilité.
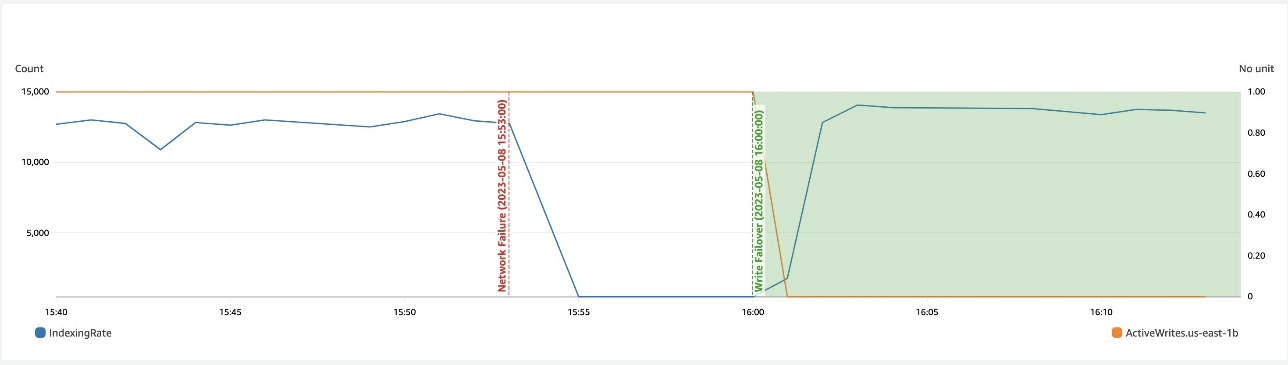
Récupération zonale après le basculement en écriture
Le processus de remise en service zonale joue un rôle crucial dans la phase de récupération suite à un basculement d'écriture zonal. Une fois la zone impactée restaurée et considérée comme stable, les nœuds précédemment mis hors service rejoindront le cluster. Cette remise en service a généralement lieu dans un délai de 2 minutes après la remise en service de la zone.
Cela leur permet de se synchroniser avec leurs nœuds homologues et de lancer le processus de récupération des fragments de réplique, restaurant ainsi efficacement le cluster à l'état souhaité.
Conclusion
L'introduction d'OpenSearch Service Multi-AZ avec Standby offre aux entreprises une solution puissante pour atteindre une haute disponibilité et des performances constantes pour les charges de travail critiques. Avec cette option de déploiement, les entreprises peuvent améliorer la résilience de leur infrastructure, simplifier la configuration et la gestion des clusters et appliquer les meilleures pratiques. Avec des fonctionnalités telles que la sélection pondérée de copies de partition à tour de rôle, des mécanismes de basculement proactifs et des zones de disponibilité en veille à ouverture en cas de panne, OpenSearch Service Multi-AZ avec veille garantit une expérience de recherche fiable et efficace pour les environnements d'entreprise exigeants.
Pour plus d'informations sur Multi-AZ avec veille, reportez-vous à Service Amazon OpenSearch sous le capot : multi-AZ avec veille.
À propos de l’auteur
 Anshu Agarwal est un ingénieur logiciel senior travaillant sur AWS OpenSearch chez Amazon Web Services. Elle est passionnée par la résolution de problèmes liés à la construction de systèmes évolutifs et hautement fiables.
Anshu Agarwal est un ingénieur logiciel senior travaillant sur AWS OpenSearch chez Amazon Web Services. Elle est passionnée par la résolution de problèmes liés à la construction de systèmes évolutifs et hautement fiables.
 Rishab Nahata est un ingénieur logiciel travaillant sur OpenSearch chez Amazon Web Services. Il est fasciné par la résolution de problèmes dans les systèmes distribués. Il est un contributeur actif à OpenSearch.
Rishab Nahata est un ingénieur logiciel travaillant sur OpenSearch chez Amazon Web Services. Il est fasciné par la résolution de problèmes dans les systèmes distribués. Il est un contributeur actif à OpenSearch.
 Boukhtawar Khan est un ingénieur principal travaillant sur Amazon OpenSearch Service. Il s'intéresse aux systèmes distribués et autonomes. Il est un contributeur actif à OpenSearch.
Boukhtawar Khan est un ingénieur principal travaillant sur Amazon OpenSearch Service. Il s'intéresse aux systèmes distribués et autonomes. Il est un contributeur actif à OpenSearch.
 Ranjith Ramachandra est un responsable de l'ingénierie travaillant sur Amazon OpenSearch Service chez Amazon Web Services.
Ranjith Ramachandra est un responsable de l'ingénierie travaillant sur Amazon OpenSearch Service chez Amazon Web Services.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- :possède
- :est
- :ne pas
- :où
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Qui sommes-nous
- atteindre
- atteint
- reconnu
- à travers
- Agis
- Action
- actes
- infection
- adaptatif
- En outre
- propos
- affecté
- Après
- contrat
- algorithme
- algorithmes
- Tous
- permettre
- Amazon
- Amazon Web Services
- parmi
- an
- ainsi que le
- Une autre
- tous
- une approche
- architecture
- SONT
- AS
- attribué
- At
- autonome
- systèmes autonomes
- disponibilité
- AWS
- sauvegarde
- balancier
- BE
- car
- était
- before
- va
- LES MEILLEURS
- les meilleures pratiques
- jusqu'à XNUMX fois
- tous les deux
- diffusion
- Développement
- entreprises
- by
- CAN
- Compétences
- réalisée
- causé
- caractérisé
- charge
- vérifié
- Grappe
- Communication
- Communications
- complet
- configuration
- Consensus
- par conséquent
- considéré
- cohérent
- Console
- contenu
- continue
- continu
- contribuer
- contributeur
- contrôlée
- coordination
- Coordinatrice
- coordinateurs
- copies
- couvert
- engendrent
- crée des
- critique
- crucial
- Clients
- Coupe
- données
- décider
- profond
- plongée profonde
- Définit
- retards
- delve
- exigeant
- déploiement
- déploie
- désigné
- un
- voulu
- détecter
- détecté
- détermine
- dirigé
- Perturbation
- distribué
- systèmes distribués
- plongeon
- do
- INSTITUTIONNELS
- domaine
- domaines
- Ne pas
- down
- deux
- durée
- pendant
- chacun
- Efficace
- de manière efficace
- efficace
- élu
- Élections
- admissibles
- l'élimination
- activé
- permet
- imposer
- ingénieur
- ENGINEERING
- de renforcer
- améliorée
- améliorer
- assurer
- Assure
- assurer
- Entreprise
- Tout
- environnements
- notamment
- Ether (ETH)
- Pourtant, la
- événement
- événements
- faire une éventuelle
- Chaque
- à l'exclusion
- d'experience
- l'expérience
- explorez
- échoue
- Échec
- échecs
- Fonctionnalité
- Fonctionnalités:
- escrime
- Prénom
- Abonnement
- suit
- Pour
- CADRE
- De
- plein
- plus
- gif
- Gracieux
- peu à peu
- guarantir
- main
- manipuler
- Poignées
- arrive
- he
- la santé
- aide
- Haute
- très
- capuche
- hébergement
- Comment
- http
- HTTPS
- identifier
- if
- illustre
- Impact
- impact
- détérioration
- la mise en œuvre
- surtout
- in
- comprendre
- indiquant
- d'information
- Infrastructure
- possible
- Initie
- initier
- cas
- intéressé
- interne
- développement
- introduit
- Introduction
- implique
- aide
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- SES
- jpg
- json
- ACTIVITES
- connu
- principalement
- leader
- Leadership
- comme
- Liste
- charge
- localement
- situé
- Location
- maintenir
- le maintien
- gérés
- gestion
- manager
- manière
- marqué
- appariés
- signifier
- veux dire
- les mesures
- mécanisme
- mécanismes
- Métadonnées
- Métrique
- minute
- minutes
- Réduire les
- Mode
- modèle
- PLUS
- mouvement
- Nature
- nécessaire
- Besoin
- réseau et
- de mise en réseau
- Nouveauté
- aucune
- nœud
- nœuds
- notable
- objet
- of
- de rabais
- on
- ONE
- en cours
- uniquement
- ouvert
- fonctionner
- opération
- Opérations
- Option
- or
- orchestration
- de commander
- Autre
- ande
- coupure de courant
- Les pannes
- plus de
- participer
- les pièces
- passionné
- chemin
- chemins
- par les pairs
- performant
- persistance
- phase
- placement
- Platon
- Intelligence des données Platon
- PlatonDonnées
- joue
- Post
- défaillances
- solide
- pratiques
- précédant
- Prévisible
- empêcher
- prévention
- empêche
- précédemment
- primaire
- Directeur
- Cybersécurité
- d'ouvrabilité
- processus
- promouvoir
- protocole
- fournir
- fournit
- Publication
- publié
- Putting
- requêtes
- Lire
- recevoir
- reçoit
- récemment
- Récupérer
- récupération
- récupération
- reportez-vous
- région
- Standard
- en relation
- pertinent
- fiabilité
- fiable
- compter
- restant
- enlèvement
- réparation
- répondre
- répliquées
- réplication
- nécessaire
- demandes
- conditions
- la résilience
- résilient
- résoudre
- responsables
- restaurer
- restauré
- restauration
- Rôle
- routage
- Courir
- fonctionne
- s
- garanties
- même
- évolutive
- prévu
- de façon transparente
- Rechercher
- sélection
- envoi
- envoie
- supérieur
- envoyé
- service
- Services
- set
- elle
- montré
- de façon significative
- simplicité
- simplifier
- unique
- Ralentissez
- ralentissements
- lisse
- So
- Logiciels
- Software Engineer
- sur mesure
- Résoudre
- stable
- Région
- Statut
- stable
- Étapes
- stockée
- stress
- Par la suite
- réussi
- susceptibilité
- combustion propre
- Système
- Prenez
- tâches
- prend
- tâches
- qui
- Les
- leur
- Les
- puis
- Là.
- Ces
- this
- ceux
- trois
- Avec
- fiable
- fois
- à
- tolérance
- circulation
- transition
- TOUR
- deux
- typiquement
- sous
- sous-jacent
- imprévu
- Actualités
- d'utiliser
- Utilisateur
- Usages
- en utilisant
- utilise
- divers
- volontairement
- Vote
- we
- web
- services Web
- poids
- WELL
- bien défini
- ont été
- quand
- qui
- tout en
- sera
- comprenant
- dans les
- de travail
- vos contrats
- écrire
- zéphyrnet
- zéro
- zones