La préparation des données est une étape cruciale dans tout flux de travail d'apprentissage automatique (ML), mais elle implique souvent des tâches fastidieuses et chronophages. Toile Amazon SageMaker prend désormais en charge des fonctionnalités complètes de préparation de données optimisées par Gestionnaire de données Amazon SageMaker. Grâce à cette intégration, SageMaker Canvas offre aux clients un espace de travail sans code de bout en bout pour préparer les données, créer et utiliser des modèles de ML et de fondations afin d'accélérer le passage des données aux informations commerciales. Vous pouvez désormais facilement découvrir et regrouper des données provenant de plus de 50 sources de données, et explorer et préparer des données à l'aide de plus de 300 analyses et transformations intégrées dans l'interface visuelle de SageMaker Canvas. Vous bénéficierez également de performances plus rapides pour les transformations et les analyses, ainsi que d'une interface en langage naturel pour explorer et transformer les données pour le ML.
Dans cet article, nous vous expliquons le processus de préparation des données pour la création de modèles de bout en bout dans SageMaker Canvas.
Vue d'ensemble de la solution
Pour notre cas d'utilisation, nous assumons le rôle d'un professionnel des données dans une société de services financiers. Nous utilisons deux exemples d'ensembles de données pour créer un modèle ML qui prédit si un prêt sera entièrement remboursé par l'emprunteur, ce qui est crucial pour la gestion du risque de crédit. L'environnement sans code de SageMaker Canvas nous permet de préparer rapidement les données, de concevoir des fonctionnalités, de former un modèle ML et de déployer le modèle dans un flux de travail de bout en bout, sans avoir besoin de codage.
Pré-requis
Pour suivre cette procédure pas à pas, assurez-vous d'avoir mis en œuvre les conditions préalables détaillées dans
- Lancer Amazon SageMaker Canvas. Si vous êtes déjà un utilisateur de SageMaker Canvas, assurez-vous de déconnecter et reconnectez-vous pour pouvoir utiliser cette nouvelle fonctionnalité.
- Pour importer des données depuis Snowflake, suivez les étapes de Configurer OAuth pour Snowflake.
Préparer des données interactives
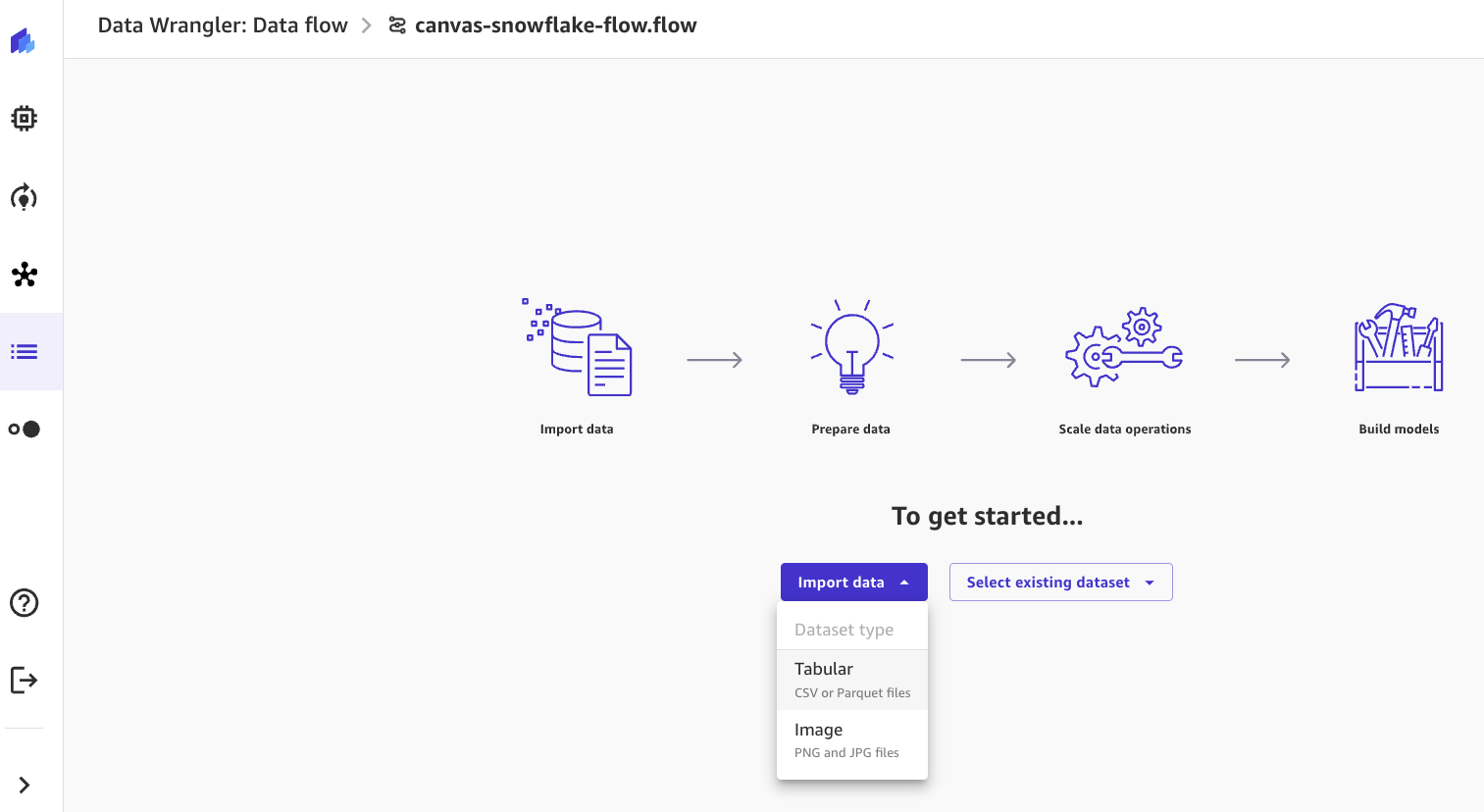
Une fois la configuration terminée, nous pouvons maintenant créer un flux de données pour permettre la préparation interactive des données. Le flux de données fournit des transformations intégrées et des visualisations en temps réel pour gérer les données. Effectuez les étapes suivantes :
- Créez un nouveau flux de données à l'aide de l'une des méthodes suivantes :
- Selectionnez Traqueur de données, Flux de données, Puis choisissez Création.
- Sélectionnez l'ensemble de données SageMaker Canvas et choisissez Créer un flux de données.
- Selectionnez Importer des dates et sélectionnez Tabulaire dans la liste déroulante.
- Vous pouvez importer des données directement via plus de 50 connecteurs de données tels que Service de stockage simple Amazon (Amazon S3), Amazone Athéna, Redshift d'Amazon, Flocon de neige et Salesforce. Dans cette procédure pas à pas, nous aborderons l'importation de vos données directement depuis Snowflake.
Vous pouvez également télécharger le même ensemble de données depuis votre ordinateur local. Vous pouvez télécharger l'ensemble de données prêts-partie-1.csv ainsi que les prêts-partie-2.csv.
- Sur la page Importer des données, sélectionnez Snowflake dans la liste et choisissez Ajouter une connexion.
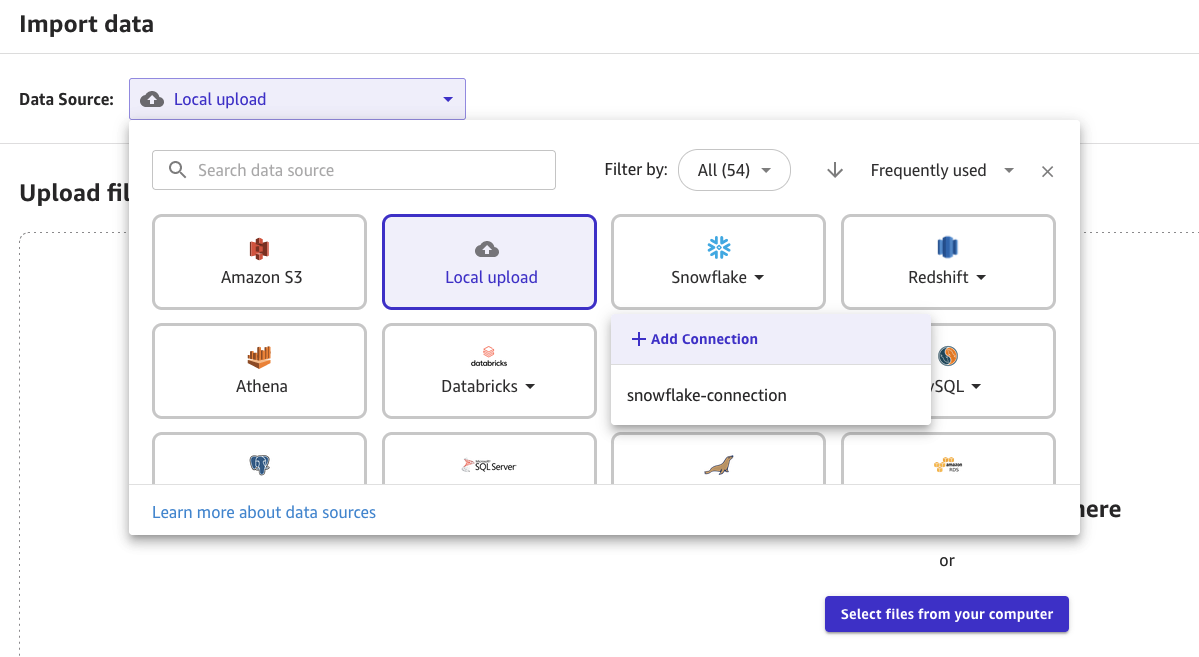
- Saisissez un nom pour la connexion, choisissez OAuth option dans la liste déroulante des méthodes d’authentification. Entrez votre identifiant de compte Okta et choisissez Ajouter une connexion.
- Vous serez redirigé vers l'écran de connexion Okta pour saisir les informations d'identification Okta pour vous authentifier. Une fois l'authentification réussie, vous serez redirigé vers la page du flux de données.
- Parcourez pour localiser l'ensemble de données de prêt à partir de la base de données Snowflake
Sélectionnez les deux ensembles de données de prêts en les faisant glisser et en les déposant du côté gauche de l'écran vers la droite. Les deux ensembles de données se connecteront et un symbole de jointure avec un point d'exclamation rouge apparaîtra. Cliquez dessus, puis sélectionnez pour les deux jeux de données le id clé. Laissez le type de jointure comme Inner. Ça devrait ressembler à ça:
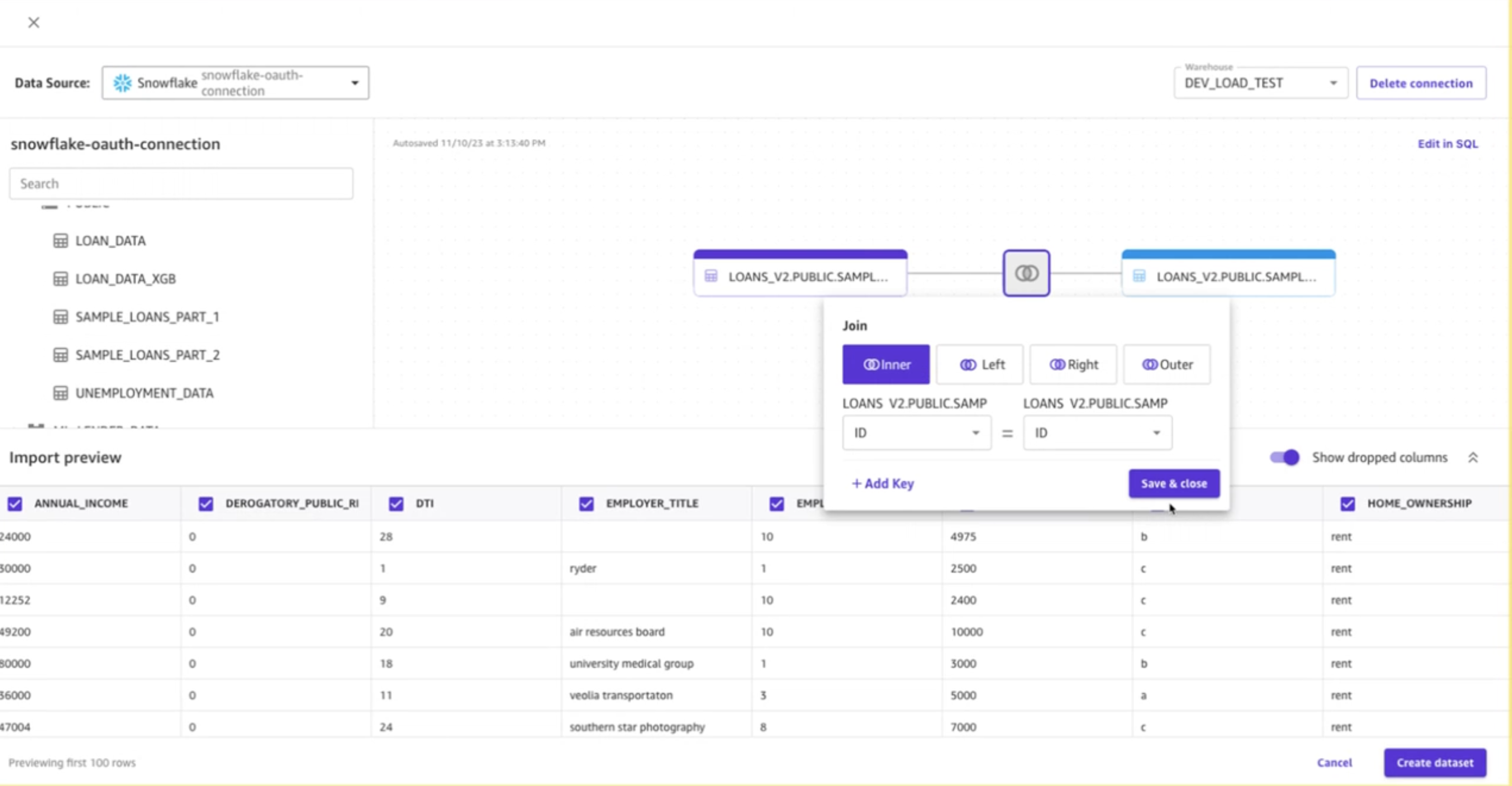
- Selectionnez Sauvegarder et fermer.
- Selectionnez Créer un jeu de données. Donnez un nom à l'ensemble de données.
- Accédez au flux de données, vous verrez ce qui suit.
- Pour explorer rapidement les données de prêt, choisissez Obtenez des informations sur les données et sélectionnez le
loan_statuscolonne cible et Classification type de problème.
Le généré Rapport sur la qualité et la connaissance des données fournit des statistiques clés, des visualisations et des analyses de l'importance des fonctionnalités.
- Consultez les avertissements sur les problèmes de qualité des données et les classes déséquilibrées pour comprendre et améliorer l'ensemble de données.
Pour l'ensemble de données dans ce cas d'utilisation, vous devez vous attendre à un avertissement de haute priorité « Score de modèle rapide très faible » et à une très faible efficacité du modèle sur les classes minoritaires (facturées et actuelles), indiquant la nécessité de nettoyer et d'équilibrer les données. Faire référence à Documentation sur toile pour en savoir plus sur le rapport d'analyse des données.


Avec plus de 300 transformations intégrées optimisées par SageMaker Data Wrangler, SageMaker Canvas vous permet de gérer rapidement les données de prêt. Vous pouvez cliquer sur Ajouter une étape, et parcourez ou recherchez les transformations appropriées. Pour cet ensemble de données, utilisez Goutte manquante ainsi que les Traiter les valeurs aberrantes pour nettoyer les données, puis appliquez Encodage à chaud, ainsi que les Vectoriser le texte pour créer des fonctionnalités pour ML.
Chat pour la préparation des données est une nouvelle fonctionnalité de langage naturel qui permet une analyse intuitive des données en décrivant les requêtes dans un anglais simple. Par exemple, vous pouvez obtenir des statistiques et proposer une analyse de corrélation sur les données de prêt à l’aide d’expressions naturelles. SageMaker Canvas comprend et exécute les actions via des interactions conversationnelles, faisant ainsi passer la préparation des données à un niveau supérieur.

Nous pouvons utiliser Chat pour la préparation des données et une transformation intégrée pour équilibrer les données de prêt.
- Tout d’abord, entrez les instructions suivantes :
replace “charged off” and “current” in loan_status with “default”
Chat pour la préparation des données génère du code pour fusionner deux classes minoritaires en une seule default classe.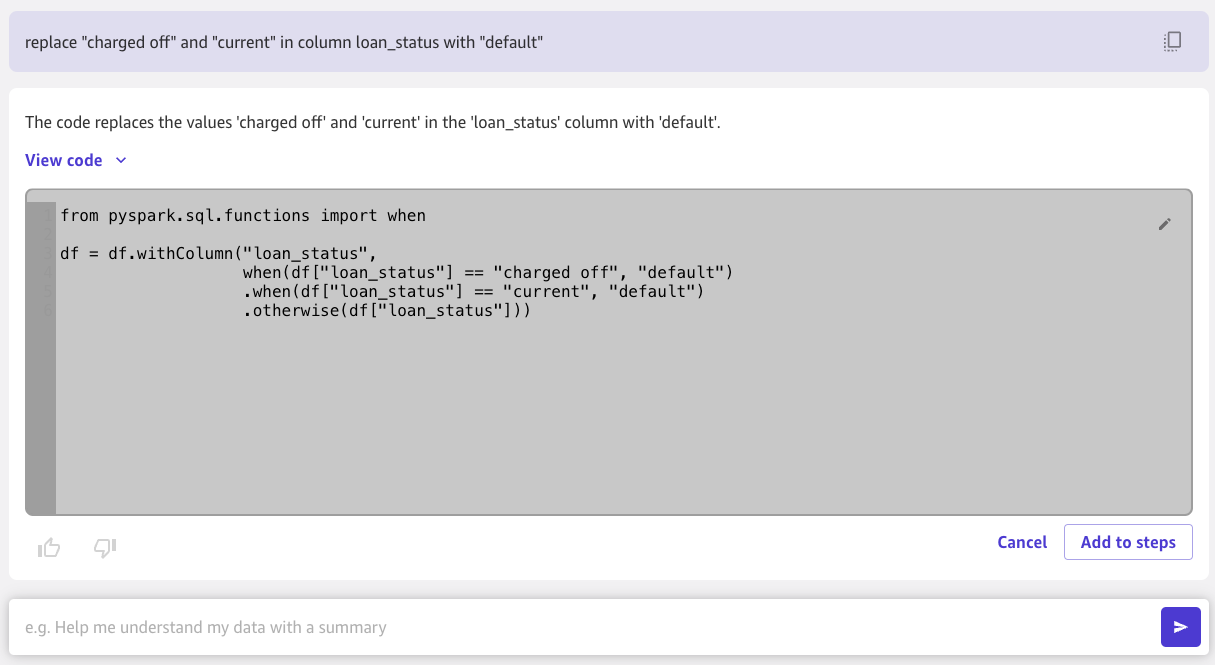
- Choisissez l'intégré SMOTÉ fonction de transformation pour générer des données synthétiques pour la classe par défaut.
Vous disposez désormais d’une colonne cible équilibrée.
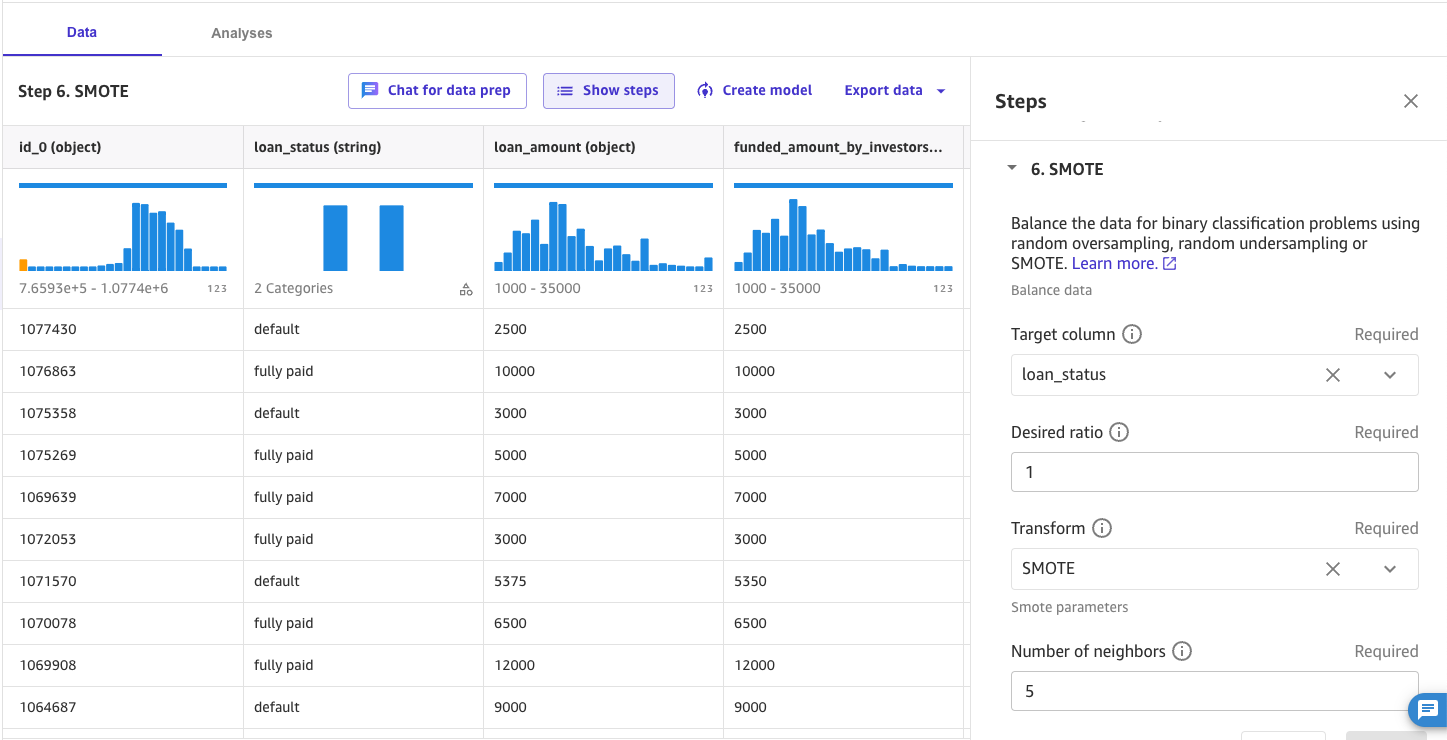
- Après avoir nettoyé et traité les données du prêt, régénérez le Rapport sur la qualité et la connaissance des données pour examiner les améliorations.
L'avertissement de haute priorité a disparu, indiquant une amélioration de la qualité des données. Vous pouvez ajouter d'autres transformations si nécessaire pour améliorer la qualité des données pour la formation du modèle.


Faites évoluer et automatisez le traitement des données
Pour automatiser la préparation des données, vous pouvez exécuter ou planifier l'intégralité du flux de travail en tant que tâche de traitement Spark distribuée pour traiter l'intégralité de l'ensemble de données ou tout nouvel ensemble de données à grande échelle.
- Dans le flux de données, ajoutez un nœud de destination Amazon S3.
- Lancez une tâche SageMaker Processing en choisissant Créer un emploi.
- Configurez le travail de traitement et choisissez Création, permettant au flux de s'exécuter sur des centaines de Go de données sans échantillonnage.
Les flux de données peuvent être incorporés dans des pipelines MLOps de bout en bout pour automatiser le cycle de vie du ML. Les flux de données peuvent alimenter les notebooks SageMaker Studio en tant qu'étape de traitement des données dans un pipeline SageMaker ou pour déployer un pipeline d'inférence SageMaker. Cela permet d'automatiser le flux depuis la préparation des données jusqu'à la formation et l'hébergement SageMaker.

Créer et déployer le modèle dans SageMaker Canvas
Après la préparation des données, nous pouvons exporter en toute transparence l'ensemble de données final vers SageMaker Canvas pour créer, former et déployer un modèle de prédiction des remboursements de prêt.
- Selectionnez Créer un modèle dans le dernier nœud du flux de données ou dans le volet des nœuds.
Cela exporte l'ensemble de données et lance le flux de travail de création de modèle guidé.
- Nommez l'ensemble de données exporté et choisissez Exportations.

- Selectionnez Créer un modèle à partir de la notification.

- Nommez le modèle, sélectionnez Analyse prédictiveet choisissez Création.
Cela vous redirigera vers la page de création de modèles.

- Poursuivez l'expérience de création de modèle SageMaker Canvas en choisissant la colonne cible et le type de modèle, puis choisissez Construction rapide or Construction standard.
Pour en savoir plus sur l'expérience de création de modèles, reportez-vous à Construire un modèle.
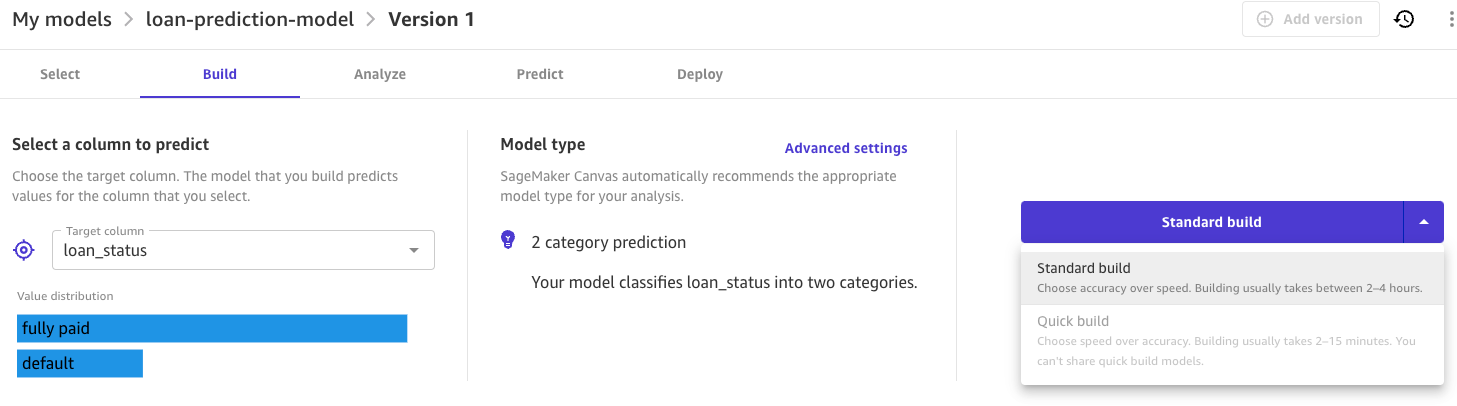
Une fois la formation terminée, vous pouvez utiliser le modèle pour prédire de nouvelles données ou les déployer. Faire référence à Déployer des modèles ML créés dans Amazon SageMaker Canvas sur des points de terminaison en temps réel Amazon SageMaker pour en savoir plus sur le déploiement d'un modèle à partir de SageMaker Canvas.
Conclusion
Dans cet article, nous avons démontré les capacités de bout en bout de SageMaker Canvas en assumant le rôle d'un professionnel des données financières préparant des données pour prédire le remboursement d'un prêt, optimisé par SageMaker Data Wrangler. La préparation interactive des données a permis de nettoyer, transformer et analyser rapidement les données de prêt pour concevoir des fonctionnalités informatives. En supprimant les complexités de codage, SageMaker Canvas nous a permis d'itérer rapidement pour créer un ensemble de données de formation de haute qualité. Ce flux de travail accéléré mène directement à la création, à la formation et au déploiement d'un modèle de ML performant pour un impact commercial. Grâce à sa préparation complète des données et à son expérience unifiée, des données aux informations, SageMaker Canvas vous permet d'améliorer vos résultats en matière de ML. Pour plus d’informations sur la façon d’accélérer votre passage des données aux informations commerciales, consultez Journée d'immersion SageMaker Canvas ainsi que les Guide de l'utilisateur AWS.
À propos des auteurs
 la Dre Changsha Ma est un spécialiste IA/ML chez AWS. Elle est technologue avec un doctorat en informatique, une maîtrise en psychologie de l'éducation et des années d'expérience en science des données et en conseil indépendant en IA/ML. Elle est passionnée par la recherche d’approches méthodologiques pour l’intelligence artificielle et humaine. En dehors du travail, elle aime faire de la randonnée, cuisiner, chasser de la nourriture et passer du temps avec ses amis et sa famille.
la Dre Changsha Ma est un spécialiste IA/ML chez AWS. Elle est technologue avec un doctorat en informatique, une maîtrise en psychologie de l'éducation et des années d'expérience en science des données et en conseil indépendant en IA/ML. Elle est passionnée par la recherche d’approches méthodologiques pour l’intelligence artificielle et humaine. En dehors du travail, elle aime faire de la randonnée, cuisiner, chasser de la nourriture et passer du temps avec ses amis et sa famille.
 Ajjay Govindaram est architecte de solutions senior chez AWS. Il travaille avec des clients stratégiques qui utilisent l'IA/ML pour résoudre des problèmes commerciaux complexes. Son expérience consiste à fournir une direction technique ainsi qu'une assistance à la conception pour les déploiements d'applications AI/ML à petite et grande échelle. Ses connaissances vont de l'architecture d'application au big data, à l'analyse et à l'apprentissage automatique. Il aime écouter de la musique tout en se reposant, profiter du plein air et passer du temps avec ses proches.
Ajjay Govindaram est architecte de solutions senior chez AWS. Il travaille avec des clients stratégiques qui utilisent l'IA/ML pour résoudre des problèmes commerciaux complexes. Son expérience consiste à fournir une direction technique ainsi qu'une assistance à la conception pour les déploiements d'applications AI/ML à petite et grande échelle. Ses connaissances vont de l'architecture d'application au big data, à l'analyse et à l'apprentissage automatique. Il aime écouter de la musique tout en se reposant, profiter du plein air et passer du temps avec ses proches.
 Huong Nguyen est chef de produit senior chez AWS. Elle dirige la préparation des données ML pour SageMaker Canvas et SageMaker Data Wrangler, avec 15 ans d'expérience dans la création de produits centrés sur le client et basés sur les données.
Huong Nguyen est chef de produit senior chez AWS. Elle dirige la préparation des données ML pour SageMaker Canvas et SageMaker Data Wrangler, avec 15 ans d'expérience dans la création de produits centrés sur le client et basés sur les données.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/accelerate-data-preparation-for-ml-with-comprehensive-data-preparation-capabilities-and-a-natural-language-interface-in-amazon-sagemaker-canvas/
- :possède
- :est
- $UP
- 100
- 12
- 13
- 14
- 15 ans
- 15%
- 300
- 50
- 8
- a
- Capable
- Qui sommes-nous
- accélérer
- accéléré
- Compte
- actes
- ajouter
- agrégat
- AI / ML
- permis
- permet
- le long de
- déjà
- aussi
- Amazon
- Amazon Sage Maker
- Toile Amazon SageMaker
- Amazon Web Services
- an
- analyses
- selon une analyse de l’Université de Princeton
- analytique
- l'analyse
- ainsi que les
- tous
- apparaître
- Application
- approches
- architecture
- SONT
- AS
- Assistance
- At
- authentifier
- Authentification
- automatiser
- automatiser
- AWS
- RETOUR
- Balance
- Équilibré
- BE
- Big
- Big Data
- goupille
- emprunteur
- tous les deux
- construire
- Développement
- construit
- intégré
- la performance des entreprises
- impact sur les entreprises
- by
- CAN
- Peut obtenir
- la toile
- capacités
- aptitude
- maisons
- accusé
- Selectionnez
- choose
- classe
- les classes
- espace extérieur plus propre,
- Nettoyage
- cliquez
- code
- Codage
- Colonne
- Société
- complet
- complexe
- complexités
- complet
- ordinateur
- Informatique
- NOUS CONTACTER
- connexion
- consulting
- de la conversation
- cuisine
- Corrélation
- couverture
- engendrent
- création
- Lettres de créance
- crédit
- crucial
- Courant
- Clients
- données
- l'analyse des données
- Préparation des données
- informatique
- qualité des données
- science des données
- data-driven
- ensembles de données
- Réglage par défaut
- Degré
- démontré
- déployer
- déployer
- déploiements
- décrivant
- Conception
- destination
- détaillé
- direction
- directement
- découvrez
- distribué
- down
- download
- Goutte
- Goutte
- même
- Éducation
- efficacité
- responsabilise
- permettre
- activé
- permet
- permettant
- end-to-end
- ingénieur
- Anglais
- de renforcer
- assurer
- Entrer
- Tout
- Environment
- Ether (ETH)
- exemple
- attendre
- d'experience
- l'expérience
- explorez
- Exporter
- exportations
- familles
- plus rapide
- Fonctionnalité
- Fonctionnalités:
- finale
- la traduction de documents financiers
- données financières
- services financiers
- société de services financiers
- flux
- Flux
- suivre
- Abonnement
- nourriture
- Pour
- Fondations
- fraiche entreprise
- amis
- de
- d’étiquettes électroniques entièrement
- fonction
- plus
- générer
- généré
- génère
- obtenez
- Donner
- guidé
- Vous avez
- he
- Haute
- de haute qualité
- randonnée
- sa
- hébergement
- Comment
- How To
- HTML
- http
- HTTPS
- humain
- intelligence humaine
- Des centaines
- Chasse
- ID
- if
- déséquilibré
- immersion
- Impact
- mis en œuvre
- importer
- importance
- l'importation
- améliorer
- amélioré
- améliorations
- in
- Incorporée
- indépendant
- indiquant
- d'information
- informatif
- perspicacité
- idées.
- Des instructions
- l'intégration
- Intelligence
- interactions
- Interactif
- Interfaces
- développement
- intuitif
- implique
- vous aider à faire face aux problèmes qui vous perturbent
- IT
- SES
- Emploi
- rejoindre
- Voyages
- jpg
- ACTIVITES
- spécialisées
- langue
- grande échelle
- Nom de famille
- lance
- conduisant
- Conduit
- APPRENTISSAGE
- apprentissage
- Laisser
- à gauche
- Niveau
- se trouve
- vos produits
- comme
- Liste
- Écoute
- prêt
- Prêts
- locales
- enregistrer
- vous connecter
- Style
- ressembler
- aimé
- aime
- Faible
- click
- machine learning
- a prendre une
- manager
- les gérer
- marque
- maîtrise
- aller
- méthode
- méthodes
- minorité
- ML
- MLOps
- modèle
- numériques jumeaux (digital twin models)
- modeste
- PLUS
- Musique
- prénom
- Nature
- Langage naturel
- Besoin
- nécessaire
- Nouveauté
- nouvelle fonctionnalité
- next
- nœud
- nœuds
- ordinateurs portables
- déclaration
- maintenant
- oauth
- of
- de rabais
- souvent
- OKTA
- on
- ONE
- et, finalement,
- Option
- or
- nos
- les résultats
- l'extérieur
- au contrôle
- plus de
- page
- pain
- passionné
- Paiement
- performant
- phd
- les expressions clés
- pipeline
- Plaine
- Platon
- Intelligence des données Platon
- PlatonDonnées
- Post
- alimenté
- prévoir
- prédiction
- Prévoit
- préparation
- Préparer
- en train de préparer
- conditions préalables
- priorité
- Problème
- d'ouvrabilité
- processus
- traitement
- Produit
- chef de produit
- Produits
- professionels
- fournit
- aportando
- Psychologie
- qualité
- vite.
- rapidement
- en temps réel
- Rouge
- réorienter
- reportez-vous
- enlever
- rapport
- demandes
- reposant
- Avis
- bon
- Analyse
- Rôle
- Courir
- fonctionne
- sagemaker
- Inférence SageMaker
- force de vente
- même
- Escaliers intérieurs
- calendrier
- Sciences
- pour écran
- de façon transparente
- Rechercher
- sur le lien
- Sélectionner
- supérieur
- Services
- société de services
- installation
- elle
- devrait
- côté
- étapes
- Solutions
- RÉSOUDRE
- Sources
- Spark
- spécialiste
- Dépenses
- statistiques
- étapes
- Étapes
- storage
- Stratégique
- studio
- réussi
- tel
- Les soutiens
- sûr
- symbole
- haute
- données synthétiques
- prise
- Target
- tâches
- Technique
- technologue
- qui
- Les
- Les
- puis
- this
- Avec
- fiable
- long
- à
- Train
- Formation
- Transformer
- transformations
- transformer
- se transforme
- deux
- type
- comprendre
- comprend
- unifiée
- us
- utilisé
- cas d'utilisation
- Utilisateur
- en utilisant
- très
- visuel
- marcher
- walkthrough
- avertissement
- we
- web
- services Web
- WELL
- que
- qui
- tout en
- WHO
- la totalité
- sera
- comprenant
- sans
- activités principales
- workflow
- vos contrats
- Ateliers
- pourra
- années
- encore
- you
- Votre
- zéphyrnet