Amazon EMR -ajoaika Apache Sparkille on suorituskykyyn optimoitu Apache Spark -ajonaika, joka on 100-prosenttisesti API-yhteensopiva avoimen lähdekoodin Apache Sparkin kanssa. Kanssa Amazonin EMR julkaisu 6.9.0, Apache Sparkin EMR-ajoaika tukee vastaavaa Spark-versiota 3.3.0.
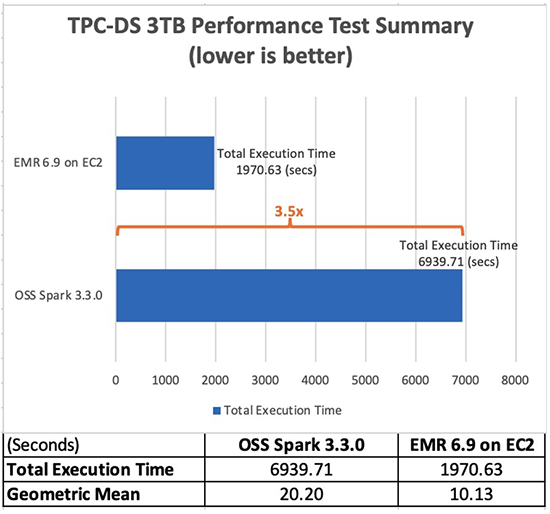
Amazon EMR 6.9.0:n avulla voit nyt ajaa Apache Spark 3.x -sovelluksiasi nopeammin ja edullisemmin ilman, että sinun tarvitsee tehdä muutoksia sovelluksiisi. Suorituskyvyn vertailutesteissämme, jotka johdettiin TPC-DS-suorituskykytesteistä 3 TB:n mittakaavassa, havaitsimme, että Apache Spark 3.3.0:n EMR-ajoaika tarjoaa keskimäärin 3.5-kertaisen suorituskyvyn (kokonaisajoaikaa käyttäen) avoimen lähdekoodin Apache Spark 3.3.0:een verrattuna. XNUMX.
Tässä viestissä analysoimme tuloksia vertailutesteistämme, joissa käytetään TPC-DS-sovellusta avoimen lähdekoodin Apache Spark ja sitten Amazon EMR 6.9:ssä, jossa on optimoitu Spark-ajoaika, joka on yhteensopiva avoimen lähdekoodin Sparkin kanssa. Käymme läpi yksityiskohtaisen kustannusanalyysin ja annamme lopuksi vaiheittaiset ohjeet vertailuarvon suorittamiseksi.
Havaitut tulokset
Suorituskyvyn parannusten arvioimiseksi käytimme avoimen lähdekoodin Spark-suorituskykytesti-apuohjelmaa, joka on johdettu TPC-DS-suorituskykytestityökalupakista. Suoritimme testit seitsemän solmun (kuusi ydinsolmua ja yksi ensisijainen solmu) c5d.9xlarge EMR-klusteri, jossa oli EMR-ajoaika Apache Sparkille, ja toinen seitsemän solmun itsehallittava klusteri Amazonin elastinen laskentapilvi (Amazon EC2) vastaavalla avoimen lähdekoodin Spark-versiolla. Suoritimme molemmat testit datalla Amazonin yksinkertainen tallennuspalvelu (Amazon S3).
Dynaaminen resurssien allokointi (DRA) on loistava ominaisuus käytettäväksi vaihtelevissa työkuormissa. Vertailuharjoituksessa, jossa vertaamme kahta alustaa puhtaasti suorituskyvyn perusteella ja testidatan määrät eivät muutu (tapauksessamme 3 TB), uskomme kuitenkin, että on parasta välttää vaihtelua omenoiden ja omenoiden välisen vertailun suorittamiseksi. Testeissämme sekä avoimen lähdekoodin Sparkissa että Amazon EMR:ssä poistimme DRA:n käytöstä, kun suoritimme benchmarking-sovellusta.
Seuraavassa taulukossa näkyy työn kokonaisajoaika kaikille kyselyille (sekunteina) 3 Tt:n kyselytietojoukossa Amazon EMR -version 6.9.0 ja avoimen lähdekoodin Spark-version 3.3.0 välillä. Havaitsimme, että TPC-DS-testeissämme Amazon EMR:ssä Amazon EC2:ssa suoritettu kokonaistyöaika oli 3.5 kertaa nopeampi kuin saman kokoonpanon avoimen lähdekoodin Spark-klusterin käyttöaika.
Amazon EMR 6.9:n kyselykohtainen nopeus Apache Sparkin EMR-ajoajan kanssa ja ilman sitä on kuvattu seuraavassa kaaviossa. Vaaka-akselilla näkyy jokainen kysely 3 Tt:n vertailussa. Pystyakselilla näkyy kunkin kyselyn nopeutuminen EMR-ajoajasta johtuen. Huomattavat suorituskyvyn lisäykset ovat yli 10 kertaa nopeampia TPC-DS-kyselyillä 24b, 72, 95 ja 96.

Kustannus analyysi
Apache Sparkin EMR-ajoajan suorituskyvyn parannukset johtavat suoraan kustannusten laskuun. Pystyimme saavuttamaan 67 %:n kustannussäästöt Amazon EMR:n vertailusovelluksen käyttämisessä verrattuna kustannuksiin, jotka aiheutuvat saman sovelluksen käyttämisestä avoimen lähdekoodin Sparkissa Amazon EC2:ssa samalla klusterikoolla Amazon EMR:n ja Amazonin lyhentyneiden tuntien vuoksi. EC2:n käyttö. Amazon EMR -hinnoittelu koskee EMR-sovelluksia, jotka toimivat EMR-klustereissa EC2-esiintymillä. Amazon EMR -hinta lisätään taustalla oleviin laskenta- ja tallennushintoihin, kuten EC2-instanssin hintaan ja Amazonin elastisten lohkojen myymälä (Amazon EBS) hinta (jos liitetään EBS-määrät). Kaiken kaikkiaan arvioitu vertailuhinta US East (N. Virginia) -alueella on 27.01 dollaria ajoa kohti avoimen lähdekoodin Sparkille Amazon EC2:ssa ja 8.82 dollaria ajoa kohden Amazon EMR:lle.
| Vertailutyö | Kesto (tunti) | Kustannusarvio | EC2-instanssi yhteensä | vCPU yhteensä | Kokonaismuisti (GiB) | Päälaite (Amazon EBS) |
|
Avoimen lähdekoodin Spark Amazon EC2:ssa (1 ensisijainen ja 6 ydinsolmua) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR Amazon EC2:ssa (1 ensisijainen ja 6 ydinsolmua) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Kustannusten jakautuminen
Seuraava on avoimen lähdekoodin Spark on Amazon EC2 -työn kustannuserittely (27.01 dollaria):
- Amazon EC2:n kokonaiskustannukset – (7 * 1.728 $ * 2.23) = (esiintymien määrä * c5d.9xsuuri tuntihinta * työn suoritusaika tunneissa) = 26.97 $
- Amazon EBS:n hinta – (0.1 $/730 * 20 * 7 * 2.23) = (Amazon EBS per GB-tuntihinta * EBS:n juurikoko * esiintymien määrä * työn suoritusaika tunneissa) = 0.042 dollaria
Seuraava on Amazon EMR:n kustannuserittely Amazon EC2 -työssä (8.82 dollaria):
- Amazon EMR:n kokonaiskustannukset – (7 * 0.27 $ * 0.63) = ((ydinsolmujen lukumäärä + ensisijaisten solmujen lukumäärä)* c5d.9xlarge Amazon EMR -hinta * työn suoritusaika tunneissa) = 1.19 $
- Amazon EC2:n kokonaiskustannukset – (7 * 1.728 $ * 0.63) = ((ydinsolmujen lukumäärä + ensisijaisten solmujen määrä)* c5d.9xsuuri ilmentymän hinta * työn suoritusaika tunneissa) = 7.62 $
- Amazon EBS:n hinta – (0.1 $/730 * 20 GiB * 7 * 0.63) = (Amazon EBS per GB-tuntihinta * EBS:n koko * esiintymien määrä * työn suoritusaika tunneissa) = 0.012 dollaria
Määritä OSS Spark -vertailu
Seuraavissa osioissa annamme lyhyen yleiskatsauksen benchmarkingin määrittämiseen liittyvistä vaiheista. Katso yksityiskohtaiset ohjeet esimerkkeineen osoitteesta GitHub repo.
Käytämme OSS Spark -vertailututkimuksessamme avoimen lähdekoodin työkalua Flintrock käynnistääksemme Amazon EC2 -pohjaisen Apache Spark klusterin. Flintrock tarjoaa nopean tavan käynnistää Apache Spark -klusteri Amazon EC2:ssa komentorivin avulla.
Edellytykset
Suorita seuraavat edellytysvaiheet:
- Python 3.7.x tai uudempi.
- Pip3 22.2.2 tai uudempi.
- Lisää Python bin -hakemisto ympäristöpolkuun. Flintrock-binaari asennetaan tälle polulle.
- ajaa
aws configuremäärittääksesi sinun AWS-komentoriviliitäntä (AWS CLI) -kuoren osoittamaan vertailutiliin. Viitata Nopea määritys aws-määrityksellä ohjeita. - Onko näppäinpari joilla on rajoittavat tiedostooikeudet päästäkseen OSS Spark -ensisijaiseen solmuun.
- Luo uusi S3-ämpäri testitilillesi tarvittaessa.
- Kopioi TPC-DS-lähdetiedot syötteeksi S3-ämpäriisi.
- Luo vertailusovellus noudattamalla kohdassa annettuja ohjeita Vaiheet kipinä-benchmark-kokoonpanosovelluksen rakentamiseksi. Vaihtoehtoisesti voit ladata valmiiksi kootun kipinä-benchmark-kokoonpano-3.3.0.jar jos haluat Spark 3.3.0 -pohjaisen sovelluksen.
Ota Spark-klusteri käyttöön ja suorita vertailutyö
Suorita seuraavat vaiheet:
- Asenna Flintrock-työkalu pipin kautta kuvan osoittamalla tavalla OSS Spark Benchmarkingin määrittämisen vaiheet.
- Suorita komento flintrock configur, joka avaa oletusasetustiedoston.
- Muokkaa oletusasetusta
config.yamltiedosto tarpeidesi mukaan. Vaihtoehtoisesti kopioi ja liitä config.yaml tiedosto sisältö oletusasetustiedostoon. Tallenna sitten tiedosto sinne, missä se oli. - Lopuksi käynnistä 7-solmun Spark-klusteri Amazon EC2:ssa Flintrockin kautta.
Tämän pitäisi luoda Spark-klusteri, jossa on yksi ensisijainen solmu ja kuusi työntekijäsolmua. Jos näet virheilmoituksia, tarkista määritystiedostojen arvot, erityisesti Spark- ja Hadoop-versiot sekä latauslähteen ja AMI:n attribuutit.
OSS Spark -klusterin mukana ei tule YARN-resurssienhallintaa. Jotta se voidaan ottaa käyttöön, meidän on määritettävä klusteri.
- Lataa lanka-sivusto.xml ja enable-yarn.sh tiedostot GitHub-reposta.
- Korvata Flintrock-klusterisi ensisijaisen solmun IP-osoitteen kanssa.
Voit hakea IP-osoitteen Amazon EC2 -konsolista.
- Lataa tiedostot kaikkiin Spark-klusterin solmuihin.
- Suorita enable-yarn-skripti.
- Ota Snappy-tuki käyttöön Hadoopissa (vertailutyö lukee Snappy-pakatut tiedot).
- Lataa benchmark-apuohjelman JAR-tiedosto kipinä-benchmark-kokoonpano-3.3.0.jar paikalliseen koneeseesi.
- Kopioi tämä tiedosto klusteriin.
- Kirjaudu sisään ensisijaiseen solmuun ja käynnistä YARN.
- Lähetä vertailutyö avoimen lähdekoodin Spark-klusteriin kuvan osoittamalla tavalla Lähetä vertailutyö.
Tee yhteenveto tuloksista
Lataa testitulostiedosto tulosteesta S3 s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Korvata $YOUR_S3_BUCKET S3-alustallasi.) Voit käyttää Amazon S3 -konsolia ja navigoida S3-lähtökohtaan tai käyttää AWS CLI:tä.
Spark-benchmark-sovellus luo aikaleimakansion ja kirjoittaa yhteenvetotiedoston summary.csv-etuliitteelle. Aikaleimasi ja tiedostonimesi ovat erilaiset kuin edellisessä esimerkissä.
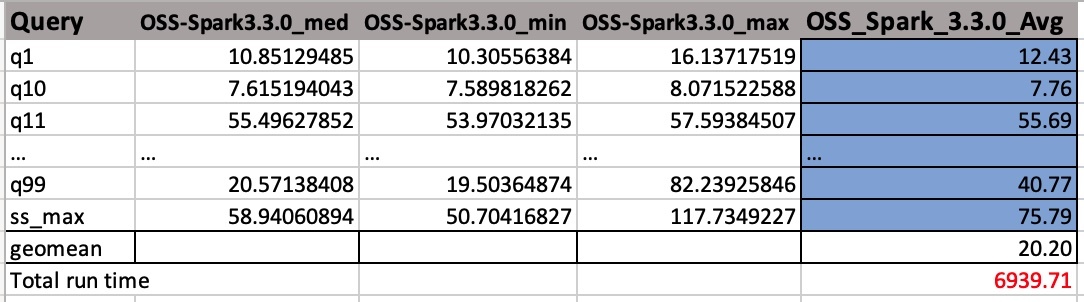
Tulostettavissa CSV-tiedostoissa on neljä saraketta ilman otsikon nimiä. He ovat:
- Kyselyn nimi
- Mediaaniaika
- Vähimmäisaika
- Enimmäisaika
Seuraava kuvakaappaus näyttää näytetulosteen. Olemme lisänneet sarakkeiden nimet manuaalisesti. Tapa, jolla laskemme geokeskiarvon ja työn kokonaisajoajan, perustuu aritmeettisiin keskiarvoihin. Otetaan ensin med-, min- ja max-arvojen keskiarvo käyttämällä kaavaa AVERAGE(B2:D2). Sitten otetaan Avg-sarakkeen geometrinen keskiarvo kaavalla GEOMEAN(E2:E105).
Määritä Amazon EMR -vertailu
Katso tarkemmat ohjeet EMR-benchmarkingin määrittämisen vaiheet.
Edellytykset
Suorita seuraavat edellytysvaiheet:
- ajaa
aws configuremäärittääksesi AWS CLI -kuoren osoittamaan vertailutiliin. Viitata Nopea määritys aws-määrityksellä ohjeita. - Lataa vertailusovellus Amazon S3:een.
Ota EMR-klusteri käyttöön ja suorita vertailutyö
Suorita seuraavat vaiheet:
- Pyöritä Amazon EMR AWS CLI -kuoressa käyttämällä komentoriviä kuvan osoittamalla tavalla Ota EMR-klusteri käyttöön ja suorita vertailutyö.
- Määritä Amazon EMR yhdellä ensisijaisella (c5d.9xlarge) ja kuudella ydinsolmulla (c5d.9xlarge). Viitata luo-klusteri saadaksesi yksityiskohtaisen kuvauksen AWS CLI -vaihtoehdoista.
- Tallenna vastauksesta saatu klusterin tunnus. Tarvitset tämän seuraavassa vaiheessa.
- Lähetä vertailutyö Amazon EMR:ssä AWS CLI:n lisäysvaiheilla.
Tee yhteenveto tuloksista
Tee yhteenveto tulostusalueen tuloksista s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT samalla tavalla kuin teimme OSS-tuloksille ja vertaa.
Puhdistaa
Vältä myöhempiä maksuja poistamalla resurssit, jotka loit ohjeiden mukaan GitHub-repon puhdistusosio.
- Pysäytä EMR- ja OSS Spark -klusterit. Voit myös poistaa ne, jos et halua säilyttää sisältöä. Voit poistaa nämä resurssit suorittamalla komentosarjan cleanup-benchmark-env.sh vertailuympäristösi päätteestä.
- Jos käytit AWS-pilvi9 IDE:näsi vertailusovelluksen JAR-tiedoston rakentamiseen Vaiheet kipinä-benchmark-kokoonpanosovelluksen rakentamiseksi, saatat haluta poistaa myös ympäristön.
Yhteenveto
Amazon EMR 3.5:n avulla voit suorittaa Apache Spark -työkuormasi 6.9.0 kertaa (kokonaisajoajan perusteella) nopeammin ja halvemmalla ilman muutoksia sovelluksiisi.
Pysy ajan tasalla tilaamalla Big Data -blogin RSS-syöte saadaksesi lisätietoja Apache Sparkin EMR-ajoajasta, konfiguroinnin parhaista käytännöistä ja viritysohjeista.
Katso aiemmat vertailutestit Suorita Apache Spark 3.0 -työkuormia 1.7 kertaa nopeammin Amazon EMR -ajoajan avulla Apache Sparkille. Huomaa, että aiempi vertailutulos 1.7-kertainen suorituskyky perustui geometriseen keskiarvoon. Geometrisen keskiarvon perusteella Amazon EMR 6.9:n suorituskyky oli kaksi kertaa nopeampi.
Tietoja kirjoittajista
 Sekar Srinivasan on AWS:n vanhempi asiantuntijaratkaisuarkkitehti, joka keskittyy suurdataan ja analytiikkaan. Sekarilla on yli 20 vuoden kokemus tiedon parissa. Hän haluaa auttaa asiakkaita rakentamaan skaalautuvia ratkaisuja, jotka modernisoivat heidän arkkitehtuuriaan ja luovat oivalluksia heidän tiedoistaan. Vapaa-ajallaan hän työskentelee mielellään voittoa tavoittelemattomissa projekteissa, erityisesti niissä, jotka keskittyvät vähäosaisten lasten koulutukseen.
Sekar Srinivasan on AWS:n vanhempi asiantuntijaratkaisuarkkitehti, joka keskittyy suurdataan ja analytiikkaan. Sekarilla on yli 20 vuoden kokemus tiedon parissa. Hän haluaa auttaa asiakkaita rakentamaan skaalautuvia ratkaisuja, jotka modernisoivat heidän arkkitehtuuriaan ja luovat oivalluksia heidän tiedoistaan. Vapaa-ajallaan hän työskentelee mielellään voittoa tavoittelemattomissa projekteissa, erityisesti niissä, jotka keskittyvät vähäosaisten lasten koulutukseen.
 Prabu Ravichandran on vanhempi data-arkkitehti Amazon Web Services -palvelussa, keskittyen Analyticsiin, data Lake -arkkitehtuuriin ja toteutukseen. Hän auttaa asiakkaita suunnittelemaan ja rakentamaan skaalautuvia ja kestäviä ratkaisuja AWS-palveluiden avulla. Vapaa-ajallaan Prabu nauttii matkustamisesta ja perheen kanssa viettämisestä.
Prabu Ravichandran on vanhempi data-arkkitehti Amazon Web Services -palvelussa, keskittyen Analyticsiin, data Lake -arkkitehtuuriin ja toteutukseen. Hän auttaa asiakkaita suunnittelemaan ja rakentamaan skaalautuvia ja kestäviä ratkaisuja AWS-palveluiden avulla. Vapaa-ajallaan Prabu nauttii matkustamisesta ja perheen kanssa viettämisestä.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 vuotta
- 7
- 9
- a
- pystyy
- Meistä
- edellä
- pääsy
- Tili
- lisä-
- osoite
- neuvot
- Kaikki
- jako
- Amazon
- Amazon EC2
- Amazonin EMR
- Amazon Web Services
- analyysi
- Analytics
- analysoida
- ja
- Apache
- Apache Spark
- api
- Hakemus
- sovellukset
- arkkitehtuuri
- attribuutteja
- keskimäärin
- AVG
- AWS
- Akseli
- perustua
- Uskoa
- benchmark
- PARAS
- parhaat käytännöt
- välillä
- Iso
- Big Data
- Tukkia
- Erittely
- rakentaa
- Rakentaminen
- tapaus
- muuttaa
- Muutokset
- maksut
- Kaavio
- Cluster
- Sarake
- Pylväät
- Tulla
- verrata
- vertailu
- yhteensopiva
- Laskea
- Konfigurointi
- Console
- pitoisuus
- Ydin
- Hinta
- kustannussäästöjä
- kustannukset
- luoda
- luotu
- luo
- Asiakkaat
- tiedot
- Datajärvi
- Päivämäärä
- oletusarvo
- johdettu
- kuvaus
- yksityiskohtainen
- laite
- DID
- eri
- suoraan
- vammaiset
- ei
- Dont
- download
- kukin
- Itään
- EBS
- koulutus
- mahdollistaa
- ympäristö
- Vastaava
- virhe
- erityisesti
- arvioidaan
- Eetteri (ETH)
- arvioida
- esimerkki
- Esimerkit
- Käyttää
- experience
- perhe
- nopeampi
- Ominaisuus
- filee
- Asiakirjat
- Vihdoin
- Etunimi
- keskityttiin
- kohdennettua
- jälkeen
- kaava
- löytyi
- Ilmainen
- alkaen
- tulevaisuutta
- voitto
- tuottaa
- GitHub
- suuri
- Hadoop
- auttaa
- auttaa
- Vaakasuora
- TUNTIA
- Kuitenkin
- HTML
- HTTPS
- täytäntöönpano
- parannus
- parannuksia
- in
- panos
- oivalluksia
- esimerkki
- ohjeet
- osallistuva
- IP
- IP-osoite
- IT
- Job
- Pitää
- järvi
- käynnistää
- OPPIA
- linja
- paikallinen
- sijainti
- kone
- Tekeminen
- johtaja
- tapa
- käsin
- max
- välineet
- Muisti
- viestien
- lisää
- nimi
- nimet
- Navigoida
- Tarve
- tarvitaan
- tarpeet
- Uusi
- seuraava
- solmu
- solmut
- voittoa tavoittelematon
- merkittävä
- numero
- ONE
- avoimen lähdekoodin
- optimoitu
- Vaihtoehdot
- tilata
- Meitä
- ääriviivat
- yleinen
- intohimoinen
- Ohi
- polku
- suorituskyky
- Oikeudet
- Platforms
- Platon
- Platonin tietotieto
- PlatonData
- Kohta
- Pops
- Kirje
- käytännöt
- hinta
- Hinnat
- hinnoittelu
- ensisijainen
- yksityinen
- hankkeet
- toimittaa
- mikäli
- tarjoaa
- puhtaasti
- Python
- nopea
- hinta
- ymmärtää
- Vähentynyt
- alue
- vapauta
- korvata
- resurssi
- Esittelymateriaalit
- vastaus
- rajoittava
- johtua
- tulokset
- luja
- juuri
- ajaa
- juoksu
- sama
- Säästä
- Säästöt
- skaalautuva
- Asteikko
- Toinen
- sekuntia
- Osa
- osiot
- vanhempi
- Palvelut
- asetus
- setup
- Kuori
- shouldnt
- esitetty
- Näytä
- Yksinkertainen
- SIX
- Koko
- Ratkaisumme
- lähde
- Kipinä
- asiantuntija
- menot
- Alkaa
- Vaihe
- Askeleet
- Levytila
- merkitä
- niin
- YHTEENVETO
- tuki
- Tukee
- taulukko
- ottaa
- terminaali
- testi
- testit
- -
- heidän
- Kautta
- aika
- kertaa
- aikaleima
- että
- työkalu
- työkalupakki
- Yhteensä
- Kääntää
- Matkustaminen
- taustalla oleva
- vähäosainen
- us
- Käyttö
- käyttää
- hyödyllisyys
- arvot
- versio
- kautta
- virginia
- volyymit
- verkko
- verkkopalvelut
- joka
- vaikka
- tulee
- ilman
- Referenssit
- työntekijä
- työskentely
- X
- XML
- yaml
- vuotta
- Sinun
- zephyrnet