Tämä viesti on kirjoittanut Pramod Nayak, LakshmiKanth Mannem ja Vivek Aggarwal LSEG:n Low Latency Groupista.
Kauppiaat, salkunhoitajat ja välittäjät käyttävät laajasti transaktiokustannusanalyysiä (TCA) kauppaa edeltävään ja kaupan jälkeiseen analysointiin, ja se auttaa heitä mittaamaan ja optimoimaan transaktiokustannuksia ja kaupankäyntistrategioidensa tehokkuutta. Tässä viestissä analysoimme vaihtoehtoja tarjous-kysymyseroja LSEG Tick History – PCAP tietojoukko käyttäen Amazon Athena Apache Sparkille. Näytämme sinulle, kuinka pääset käsiksi tietoihin, määrität tietoihin sovellettavia mukautettuja toimintoja, teemme kyselyjä ja suodatamme tietojoukkoja sekä visualisoimme analyysin tulokset ilman, että sinun tarvitsee huolehtia infrastruktuurin perustamisesta tai Sparkin määrittämisestä, jopa suurille tietojoukoille.
Tausta
Optioiden hintaraportointiviranomainen (OPRA) toimii tärkeänä arvopaperitietojen käsittelijänä, joka kerää, yhdistää ja jakaa viimeisimpiä myyntiraportteja, tarjouksia ja asiaankuuluvia tietoja Yhdysvaltain optioista. OPRAlla on 18 aktiivista Yhdysvaltain optiopörssiä ja yli 1.5 miljoonaa hyväksyttyä sopimusta, joten OPRAlla on keskeinen rooli kattavien markkinatietojen tarjoamisessa.
5. helmikuuta 2024 Securities Industry Automation Corporation (SIAC) päivittää OPRA-syötteen 48:sta 96 monilähetyskanavaan. Tällä parannuksella pyritään optimoimaan symbolien jakelu ja linjakapasiteetin käyttöaste vastauksena lisääntyvään kaupankäyntiin ja epävakauteen Yhdysvaltain optiomarkkinoilla. SIAC on suositellut, että yritykset valmistautuvat huippunopeuteen, joka on jopa 37.3 gigatavua sekunnissa.
Huolimatta siitä, että päivitys ei heti muuta julkaistujen tietojen kokonaismäärää, se antaa OPRAlle mahdollisuuden levittää tietoja huomattavasti nopeammin. Tämä siirtymä on ratkaisevan tärkeä dynaamisten optiomarkkinoiden vaatimuksiin vastaamiseksi.
OPRA erottuu joukosta yhdeksi laajimmista syötteistä, sillä sen huippu on 150.4 miljardia viestiä yhdessä päivässä vuoden 3 kolmannella neljänneksellä ja kapasiteettivaatimus 2023 miljardia viestiä yhden päivän aikana. Jokaisen viestin tallentaminen on tärkeää transaktiokustannusanalyysin, markkinoiden likviditeetin seurannan, kaupankäyntistrategian arvioinnin ja markkinatutkimuksen kannalta.
Tietoja tiedoista
LSEG Tick History – PCAP on pilvipohjainen arkisto, jossa on yli 30 PB ja joka sisältää erittäin korkealaatuista globaalia markkinatietoa. Nämä tiedot kerätään huolellisesti suoraan vaihtotietokeskuksissa käyttämällä redundantteja talteenottoprosesseja, jotka on strategisesti sijoitettu tärkeimpiin ensisijaisiin ja varatietokeskuksiin maailmanlaajuisesti. LSEG:n sieppaustekniikka varmistaa häviöttömän tiedonkeruun ja käyttää GPS-aikalähdettä nanosekunnin aikaleiman tarkkuuteen. Lisäksi kehittyneitä tiedon arbitraasitekniikoita käytetään saumattomasti täyttämään kaikki tietoaukot. Sieppauksen jälkeen tiedot käsitellään huolellisesti ja sovitetaan, minkä jälkeen ne normalisoidaan parkettimuotoon käyttämällä LSEG:n Real Time Ultra Direct (RTUD) rehunkäsittelijät.
Normalisointiprosessi, joka on olennainen osa tietojen valmistelua analysointia varten, tuottaa jopa 6 Tt pakattuja parkettitiedostoja päivässä. Tietojen valtava määrä johtuu OPRA:n kattavasta luonteesta, joka kattaa useita vaihtoja ja sisältää lukuisia optiosopimuksia, joille on ominaista erilaiset attribuutit. Markkinoiden lisääntynyt volatiliteetti ja markkinatakaus optiopörsseissä lisäävät edelleen OPRAsta julkaistujen tietojen määrää.
Tick History – PCAP:n ominaisuudet antavat yrityksille mahdollisuuden suorittaa erilaisia analyyseja, mukaan lukien seuraavat:
- Kauppaa edeltävä analyysi – Arvioi mahdollisia kauppavaikutuksia ja tutki erilaisia toteutusstrategioita historiatietoihin perustuen
- Kaupan jälkeinen arviointi – Mittaa todelliset toteutuskustannukset vertailuarvoihin, jotta voit arvioida toteutusstrategioiden tehokkuutta
- optimoitu teloitus – Hienosäädä toteutusstrategioita, jotka perustuvat historiallisiin markkinamalleihin minimoidaksesi markkinavaikutuksen ja alentaaksesi kaupankäynnin kokonaiskustannuksia
- Riskienhallinta – Tunnista liukastumismallit, tunnista poikkeamat ja hallitse ennakoivasti kaupankäyntiin liittyviä riskejä
- Suorituskyvyn vaikuttavuus – Erottele kaupankäyntipäätösten vaikutus sijoituspäätöksistä, kun analysoit salkun kehitystä
LSEG Tick History – PCAP-tietojoukko on saatavilla AWS-tiedonvaihto ja niihin pääsee käsiksi AWS Marketplace. Kanssa AWS Data Exchange Amazon S3:lle, voit käyttää PCAP-tietoja suoraan LSEG:stä Amazonin yksinkertainen tallennuspalvelu (Amazon S3) -ämpärit, jolloin yritysten ei tarvitse tallentaa omia kopioja tiedoista. Tämä lähestymistapa virtaviivaistaa tietojen hallintaa ja tallennusta tarjoamalla asiakkaille välittömän pääsyn korkealaatuisiin PCAP- tai normalisoituihin tietoihin helppokäyttöisenä, integroitavina ja huomattavia säästöjä tiedontallennustilassa.
Athena Apache Sparkille
Analyyttisiin pyrkimyksiin Athena Apache Sparkille tarjoaa yksinkertaisen kannettavan käyttökokemuksen, joka on käytettävissä Athena-konsolin tai Athena-sovellusliittymien kautta, jolloin voit rakentaa interaktiivisia Apache Spark -sovelluksia. Optimoidun Spark-ajoajan ansiosta Athena auttaa petatavujen datan analysoinnissa skaalaamalla dynaamisesti Spark-moottoreiden määrää alle sekunnissa. Lisäksi yleiset Python-kirjastot, kuten pandas ja NumPy, on integroitu saumattomasti, mikä mahdollistaa monimutkaisen sovelluslogiikan luomisen. Joustavuus ulottuu mukautettujen kirjastojen maahantuontiin muistikirjoissa käytettäväksi. Athena for Spark tukee useimpia avoimen datan formaatteja ja on saumattomasti integroitu AWS-liima Data Katalogi.
aineisto
Tässä analyysissä käytimme LSEG Tick History – PCAP OPRA -tietojoukkoa 17. toukokuuta 2023. Tämä tietojoukko sisältää seuraavat osat:
- Paras tarjous (BBO) – Raportoi arvopaperin korkeimman tarjouksen ja alimman kysynnän tietyssä pörssissä
- Kansallinen paras tarjous (NBBO) – Raportoi korkeimman tarjouksen ja alhaisimman arvopaperipyynnön kaikissa pörsseissä
- kaupat – Kirjaa tehdyt kaupat kaikissa pörsseissä
Tietojoukko sisältää seuraavat tietomäärät:
- kaupat – 160 Mt jaettu noin 60 pakattuun Parquet-tiedostoon
- BBO – 2.4 TB jaettu noin 300 pakattuun parkettitiedostoon
- NBBO – 2.8 TB jaettu noin 200 pakattuun parkettitiedostoon
Analyysin yleiskatsaus
OPRA Tick History -tietojen analysointi Transaction Cost Analysis (TCA) -analyysiä varten sisältää markkinanoteerausten ja -kauppojen tarkastelun tietyn kauppatapahtuman ympärillä. Käytämme seuraavia mittareita osana tätä tutkimusta:
- Lainausero (QS) – Laskettu BBO-pyynnön ja BBO-tarjouksen erotuksena
- Tehokas leviäminen (ES) – Lasketaan kauppahinnan ja BBO:n keskipisteen erotuksena (BBO-tarjous + (BBO-hinta – BBO-tarjous)/2)
- Tehokas/lainattu ero (EQF) – Laskettu muodossa (ES / QS) * 100
Laskemme nämä erot ennen kauppaa ja lisäksi neljän välein kaupan jälkeen (juuri jälkeen, 1 sekunti, 10 sekuntia ja 60 sekuntia kaupan jälkeen).
Määritä Athena Apache Sparkille
Määritä Athena Apache Sparkille suorittamalla seuraavat vaiheet:
- Athena-konsolissa, alla Aloitavalitse Analysoi tietosi PySparkilla ja Spark SQL:llä.
- Jos tämä on ensimmäinen kerta, kun käytät Athena Sparkia, valitse Luo työryhmä.

- varten Työryhmän nimi¸ anna työryhmälle nimi, esim
tca-analysis. - In Analytics-moottori , valitse Apache Spark.
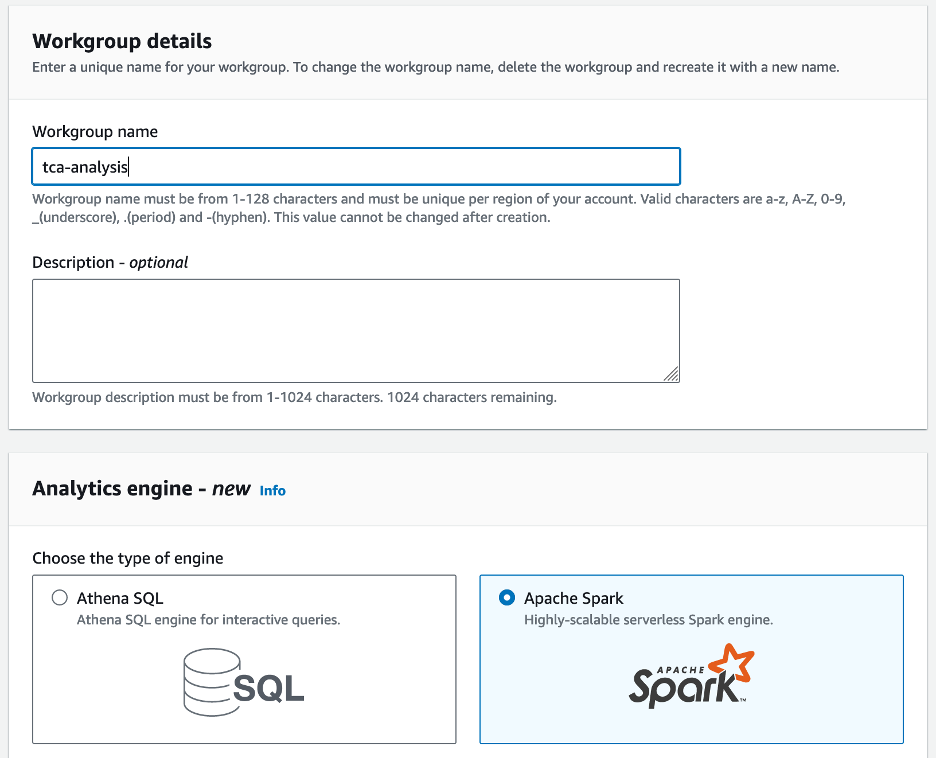
- In Lisäkokoonpanot osiosta, voit valita Käytä oletusasetuksia tai tarjoa mukautettua AWS-henkilöllisyyden ja käyttöoikeuksien hallinta (IAM) rooli ja Amazon S3 -sijainti laskentatuloksia varten.
- Valita Luo työryhmä.
- Kun olet luonut työryhmän, siirry kohtaan Kannettavat välilehti ja valitse Luo muistikirja.
- Anna muistikirjallesi nimi, esim
tca-analysis-with-tick-history. - Valita luoda muistikirjan luomiseen.
Käynnistä muistikirjasi
Jos olet jo luonut Spark-työryhmän, valitse Käynnistä muistikirjan editori varten Aloita.
![]()
Kun muistikirja on luotu, sinut ohjataan interaktiiviseen muistikirjan editoriin.
![]()
Nyt voimme lisätä ja suorittaa seuraavan koodin muistikirjaamme.
Luo analyysi
Luo analyysi suorittamalla seuraavat vaiheet:
- Tuo yleiset kirjastot:
- Luo tietokehyksemme BBO:lle, NBBO:lle ja kaupoille:
- Nyt voimme tunnistaa kaupan, jota käytetään transaktiokustannusanalyysissä:
Saamme seuraavan tuloksen:
Käytämme jatkossa korostettuja kauppatietoja kauppatuotteelle (tp), kauppahinnalle (tpr) ja kauppaajalle (tt).
- Täällä luomme useita aputoimintoja analyysiämme varten
- Seuraavassa funktiossa luomme tietojoukon, joka sisältää kaikki tarjoukset ennen kauppaa ja sen jälkeen. Athena Spark määrittää automaattisesti, kuinka monta DPU:ta käynnistetään datajoukkomme käsittelyä varten.
- Kutsutaan nyt TCA-analyysitoimintoa valitun kaupan tiedoilla:
Visualisoi analyysin tulokset
Luodaan nyt tietokehykset, joita käytämme visualisointiimme. Jokainen datakehys sisältää lainausmerkit yhdelle viidestä aikavälistä jokaiselle tietosyötteen (BBO, NBBO):
Seuraavissa osioissa tarjoamme esimerkkikoodin erilaisten visualisointien luomiseen.
Piirrä QS ja NBBO ennen kauppaa
Käytä seuraavaa koodia piirtääksesi noteeratun eron ja NBBO:n ennen kauppaa:
![]()
Piirrä QS kullekin markkinalle ja NBBO kaupan jälkeen
Käytä seuraavaa koodia kuvaamaan kunkin markkinan ja NBBO:n noteerattu ero välittömästi kaupan jälkeen:
![]()
Piirrä QS kullekin aikavälille ja jokaiselle BBO-markkinalle
Käytä seuraavaa koodia piirtääksesi kunkin aikavälin ja kunkin BBO-markkinoiden noteeratun eron:
![]()
Piirrä ES kullekin aikavälille ja BBO-markkinalle
Käytä seuraavaa koodia piirtääksesi kunkin aikavälin ja BBO:n markkinoiden tehokkaan erotuksen:
Piirrä EQF kullekin aikavälille ja BBO-markkinalle
Käytä seuraavaa koodia piirtääksesi tehollisen/noteeratun eron kullekin aikavälille ja BBO:lle:
Athena Spark -laskennan suorituskyky
Kun suoritat koodilohkon, Athena Spark määrittää automaattisesti, kuinka monta DPU:ta se tarvitsee laskennan suorittamiseen. Viimeisessä koodilohkossa, jossa kutsumme tca_analysis toiminto, itse asiassa ohjeistamme Sparkia käsittelemään tiedot ja muunnamme sitten saadut Spark-tietokehykset Pandas-tietokehyksiksi. Tämä on analyysin intensiivisin käsittelyosa, ja kun Athena Spark suorittaa tämän lohkon, se näyttää edistymispalkin, kuluneen ajan ja kuinka monta DPU:ta käsittelee tietoja tällä hetkellä. Esimerkiksi seuraavassa laskelmassa Athena Spark käyttää 18 DPU:ta.
![]()
Kun määrität Athena Spark -kannettavan, voit määrittää sen käyttämien DPU-yksiköiden enimmäismäärän. Oletusarvo on 20 DPU:ta, mutta testasimme tämän laskelman 10, 20 ja 40 DPU:lla osoittaaksemme, kuinka Athena Spark skaalautuu automaattisesti suorittaakseen analyysimme. Havaitsimme, että Athena Spark skaalautuu lineaarisesti, ja kesti 15 minuuttia ja 21 sekuntia, kun kannettavassa tietokoneessa oli enintään 10 DPU:ta, 8 minuuttia ja 23 sekuntia, kun kannettavassa oli 20 DPU:ta, ja 4 minuuttia ja 44 sekuntia, kun tietokone oli konfiguroitu 40 DPU:lla. Koska Athena Spark veloittaa DPU:n käytön perusteella, sekuntitarkkuudella, näiden laskelmien kustannukset ovat samanlaiset, mutta jos asetat korkeamman DPU:n maksimiarvon, Athena Spark voi palauttaa analyysin tuloksen paljon nopeammin. Saat lisätietoja Athena Spark -hinnoittelusta napsauttamalla tätä.
Yhteenveto
Tässä viestissä osoitimme, kuinka voit käyttää LSEG:n Tick History-PCAP:n korkealaatuisia OPRA-tietoja suorittaaksesi transaktiokustannusten analytiikkaa Athena Sparkilla. OPRA-tietojen oikea-aikainen saatavuus yhdistettynä AWS Data Exchangen saavutettavuusinnovaatioihin Amazon S3:lle vähentää strategisesti analytiikkaan kuluvaa aikaa yrityksillä, jotka haluavat luoda käyttökelpoisia oivalluksia kriittisiin kaupankäyntipäätöksiin. OPRA tuottaa noin 7 teratavua normalisoitua parkettidataa joka päivä, ja infrastruktuurin hallinta OPRA-dataan perustuvan analytiikan tarjoamiseksi on haastavaa.
Athenen skaalautuvuus Tick History - PCAP for OPRA -tietojen suuren mittakaavan tietojenkäsittelyssä tekee siitä houkuttelevan valinnan organisaatioille, jotka etsivät nopeita ja skaalautuvia analytiikkaratkaisuja AWS:ssä. Tämä viesti näyttää saumattoman vuorovaikutuksen AWS-ekosysteemin ja Tick History-PCAP -tietojen välillä ja kuinka rahoituslaitokset voivat hyödyntää tätä synergiaa ohjatakseen tietopohjaista päätöksentekoa kriittisissä kaupankäynti- ja sijoitusstrategioissa.
Tietoja Tekijät
![]() Pramod Nayak on LSEG:n Low Latency Groupin tuotehallinnan johtaja. Pramodilla on yli 10 vuoden kokemus rahoitusteknologia-alalta, keskittyen ohjelmistokehitykseen, analytiikkaan ja tiedonhallintaan. Pramod on entinen ohjelmistosuunnittelija ja intohimoinen markkinatiedoista ja kvantitatiivisesta kaupankäynnistä.
Pramod Nayak on LSEG:n Low Latency Groupin tuotehallinnan johtaja. Pramodilla on yli 10 vuoden kokemus rahoitusteknologia-alalta, keskittyen ohjelmistokehitykseen, analytiikkaan ja tiedonhallintaan. Pramod on entinen ohjelmistosuunnittelija ja intohimoinen markkinatiedoista ja kvantitatiivisesta kaupankäynnistä.
![]() LakshmiKanth Mannem on tuotepäällikkö LSEG:n Low Latency Groupissa. Hän keskittyy data- ja alustatuotteisiin alhaisen latenssin markkinoiden datateollisuudelle. LakshmiKanth auttaa asiakkaita rakentamaan optimaaliset ratkaisut markkinatietotarpeisiinsa.
LakshmiKanth Mannem on tuotepäällikkö LSEG:n Low Latency Groupissa. Hän keskittyy data- ja alustatuotteisiin alhaisen latenssin markkinoiden datateollisuudelle. LakshmiKanth auttaa asiakkaita rakentamaan optimaaliset ratkaisut markkinatietotarpeisiinsa.
![]() Vivek Aggarwal on vanhempi tietoinsinööri LSEG:n Low Latency Groupissa. Vivek kehittää ja ylläpitää dataputkia kaapattujen markkinatietosyötteiden ja viitetietosyötteiden käsittelyä ja toimitusta varten.
Vivek Aggarwal on vanhempi tietoinsinööri LSEG:n Low Latency Groupissa. Vivek kehittää ja ylläpitää dataputkia kaapattujen markkinatietosyötteiden ja viitetietosyötteiden käsittelyä ja toimitusta varten.
![]() Alket Memushaj on pääarkkitehti AWS:n rahoituspalvelumarkkinoiden kehitystiimissä. Alket vastaa teknisestä strategiasta ja työskentelee kumppaneiden ja asiakkaiden kanssa vaativimpienkin pääomamarkkinoiden työkuormien käyttöönottamiseksi AWS-pilveen.
Alket Memushaj on pääarkkitehti AWS:n rahoituspalvelumarkkinoiden kehitystiimissä. Alket vastaa teknisestä strategiasta ja työskentelee kumppaneiden ja asiakkaiden kanssa vaativimpienkin pääomamarkkinoiden työkuormien käyttöönottamiseksi AWS-pilveen.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Meistä
- pääsy
- Accessed
- saavutettavuus
- saatavilla
- poikki
- aktiivinen
- toiminta
- todellinen
- todella
- lisätä
- Lisäksi
- käsitellään
- Etu
- Jälkeen
- vastaan
- Aggarwal
- tavoitteet
- Kaikki
- Salliminen
- jo
- Amazon
- Amazon Athena
- Amazon Web Services
- an
- analyysit
- analyysi
- analyyttinen
- Analytics
- analysoida
- analysointi
- ja
- Kaikki
- Apache
- Apache Spark
- API
- Hakemus
- sovellukset
- käyttää
- lähestymistapa
- suunnilleen
- katvealueiden
- välimiesmenettely
- OVAT
- noin
- AS
- kysyä
- arvioida
- liittyvä
- At
- attribuutteja
- viranomaisen
- automaattisesti
- Automaatio
- saatavuus
- saatavissa
- AWS
- Varmuuskopiointi
- baari
- perustua
- BE
- koska
- ennen
- Viitearvot
- PARAS
- välillä
- tarjous
- Miljardi
- Tukkia
- välittäjät
- rakentaa
- mutta
- by
- laskea
- laskettu
- laskeminen
- soittaa
- CAN
- Koko
- pääoma
- Pääomamarkkinat
- kaapata
- kiinni
- Kaappaaminen
- luettelo
- keskuksissa
- haastava
- kanavat
- tunnettu siitä,
- maksut
- valinta
- Valita
- asiakkaat
- pilvi
- koodi
- Kerääminen
- Yhteinen
- pakottava
- täydellinen
- Valmistunut
- osat
- kattava
- käsittää
- Suorittaa
- määritetty
- konfigurointi
- Console
- lujittaa
- sisältää
- sopimukset
- edistävät
- muuntaa
- YHTIÖ
- Hinta
- kustannukset
- kirjoittanut
- luoda
- luotu
- luominen
- kriittinen
- ratkaiseva
- Tällä hetkellä
- asiakassuhde
- Asiakkaat
- Ajatusviiva
- tiedot
- datakeskukset
- tietotekniikka
- Tiedonvaihto
- tiedonhallinta
- tietojenkäsittely
- tietovarasto
- data-driven
- aineistot
- päivä
- Päätöksenteko
- päätökset
- oletusarvo
- määritellä
- toimitus
- vaativa
- vaatii
- osoittaa
- osoittivat
- sijoittaa
- yksityiskohdat
- määrittää
- kehittämällä
- Kehitys
- kehitystiimi
- ero
- eri
- suoraan
- Johtaja
- jaettu
- jakelu
- useat
- kaksinkertainen
- ajaa
- dynaaminen
- dynaamisesti
- dynamiikka
- kukin
- helpottaa
- helppokäyttöisyys
- ekosysteemi
- toimittaja
- Tehokas
- tehokkuuden
- oikeutettu
- poistamalla
- Työllisiä
- käyttämällä
- mahdollistaa
- mahdollistaa
- kattaa
- pyrkii
- Moottori
- insinööri
- Moottorit
- lisälaite
- varmistaa
- enter
- laajeneminen
- Eetteri (ETH)
- arvioida
- arviointi
- Jopa
- tapahtuma
- Joka
- esimerkki
- Vaihdetaan
- Vaihto
- teloitus
- experience
- tutkia
- ilmaista
- ulottuu
- nopeampi
- Featuring
- helmikuu
- Viikuna
- Asiakirjat
- täyttää
- suodattaa
- taloudellinen
- Rahoituslaitokset
- rahoituspalvelut
- finanssitekniikka
- yritykset
- Etunimi
- ensimmäistä kertaa
- viisi
- Joustavuus
- keskittyy
- tarkennus
- jälkeen
- varten
- muoto
- Entinen
- Eteenpäin
- neljä
- FRAME
- alkaen
- toiminto
- tehtävät
- edelleen
- aukkoja
- synnyttää
- saada
- tietty
- Global
- maailmanmarkkinoilla
- Go
- menee
- GPS
- Ryhmä
- Käsittely
- Olla
- ottaa
- he
- sisäkorkeus
- auttaa
- korkealaatuisia
- korkeampi
- suurin
- Korostettu
- historiallinen
- historia
- kotelo
- Miten
- Miten
- http
- HTTPS
- IAM
- tunnistaa
- Identiteetti
- if
- Välitön
- heti
- Vaikutus
- tuoda
- in
- Mukaan lukien
- kasvoi
- teollisuus
- tiedot
- Infrastruktuuri
- innovaatiot
- oivalluksia
- laitokset
- kiinteä
- integroitu
- integraatio
- vuorovaikutus
- vuorovaikutteinen
- tulee
- monimutkainen
- investointi
- liittyy
- IT
- jpg
- vain
- suuri
- laaja
- Sukunimi
- Viive
- käynnistää
- vähemmän
- kirjastot
- linja
- likviditeetti
- sijainti
- logiikka
- näköinen
- Matala
- alin
- ylläpitäminen
- merkittävä
- TEE
- Tekeminen
- hoitaa
- johto
- johtaja
- Päättäjät
- toimitusjohtaja
- tapa
- monet
- markkinat
- Markkinatiedot
- vaikutus markkinoihin
- markkinatutkimus
- Markkinoiden volatiliteetti
- markkinatuotanto
- markkinat
- massiivinen
- masterointi
- maksimi
- Saattaa..
- mitata
- viesti
- viestien
- huolellinen
- pikkutarkasti
- Metrics
- miljoona
- minimoida
- pöytäkirja
- seuranta
- lisää
- Lisäksi
- eniten
- paljon
- moninkertainen
- nimi
- luonto
- Navigoida
- Tarve
- tarpeet
- Ei eristetty
- muistikirja
- kannettavat tietokoneet
- numero
- useat
- numpy
- Havaittu
- of
- kampanja
- Tarjoukset
- on
- ONE
- optimaalinen
- Optimoida
- optimoitu
- Vaihtoehto
- Vaihtoehdot
- or
- organisaatioiden
- meidän
- ulos
- ulostulo
- yli
- yleinen
- oma
- pandas
- osa
- kumppani
- intohimoinen
- kuviot
- Peak
- varten
- suorittaa
- suorituskyky
- keskeinen
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- soittaa
- Ole hyvä
- juoni
- salkku
- salkunhoitajat
- asemoitu
- Kirje
- kaupan jälkeinen
- mahdollinen
- Tarkkuus
- Valmistella
- valmistelee
- hinta
- hinnoittelu
- ensisijainen
- Pääasiallinen
- prosessi
- Prosessit
- käsittely
- Suoritin
- Tuotteet
- tuotehallinta
- tuotepäällikkö
- Tuotteemme
- Edistyminen
- toimittaa
- tarjoamalla
- julkaistu
- Python
- Q3
- määrällinen
- määrä
- kysymys
- lainausmerkit
- hinta
- Hinnat
- Lue
- todellinen
- reaaliaikainen
- suositeltu
- asiakirjat
- punainen
- vähentää
- vähentää
- viite
- refinitiv
- Raportointi
- Raportit
- säilytyspaikka
- vaatimus
- Vaatii
- tutkimus
- vastaus
- vastuullinen
- johtua
- Saatu ja
- tulokset
- palata
- riskit
- Rooli
- ajaa
- toimii
- myynti
- skaalautuvuus
- skaalautuva
- asteikot
- skaalaus
- saumaton
- saumattomasti
- Toinen
- sekuntia
- Osa
- osiot
- Arvopaperit
- turvallisuus
- etsiä
- valita
- valittu
- vanhempi
- erillinen
- palvelee
- Palvelut
- setti
- asetus
- näyttää
- Näytä
- merkittävästi
- samankaltainen
- Yksinkertainen
- yksinkertaistettu
- single
- lipsumista
- Tuotteemme
- ohjelmistokehitys
- Software Engineer
- Ratkaisumme
- hienostunut
- jännitys
- Kipinä
- erityinen
- levitä
- levitteet
- seisoo
- Askeleet
- Levytila
- verkkokaupasta
- strategisesti
- strategiat
- Strategia
- virtaviivaistaa
- tutkimus
- myöhempi
- niin
- SWIFT
- symboli
- synergia
- ottaa
- ottaen
- joukkue-
- Tekninen
- tekniikat
- Elektroniikka
- testattu
- kuin
- että
- -
- tiedot
- heidän
- Niitä
- sitten
- Nämä
- tätä
- Kautta
- rasti
- aika
- ajankohtainen
- aikaleima
- Otsikko
- että
- Yhteensä
- tp
- TPR
- kauppaa
- Traders
- kaupat
- kaupankäynti
- Trading Strategies
- kaupankäynnin strategiaa
- kauppa
- transaktiokustannukset
- muuttamassa
- siirtyminen
- Ultra
- varten
- läpikäy
- parantaa
- us
- Käyttö
- käyttää
- käytetty
- käyttötarkoituksiin
- käyttämällä
- Hyödyntämällä
- arvo
- eri
- visualisointi
- havainnollistaa
- Haihtuvuus
- tilavuus
- volyymit
- oli
- we
- verkko
- verkkopalvelut
- kun
- joka
- laajalti
- tulee
- with
- sisällä
- ilman
- Workgroup
- työskentely
- toimii
- maailmanlaajuisesti
- huoli
- X
- vuotta
- te
- Sinun
- zephyrnet