
Kuva Adobe Fireflystä
"Meitä oli liikaa. Meillä oli käytössä liikaa rahaa, liikaa laitteita, ja pikkuhiljaa tulimme hulluiksi."
Francis Ford Coppola ei luonut vertauskuvaa tekoälyyrityksille, jotka kuluttavat liikaa ja eksyvät, mutta hän olisi voinut olla. Apokalyysi nyt oli eeppinen, mutta myös pitkä, vaikea ja kallis projekti, aivan kuten GPT-4. Ehdotan, että LLM:ien kehittäminen on painottanut liikaa rahaa ja liikaa laitteita. Ja jotkut "keksimme juuri yleisen älykkyyden" hypeistä ovat hieman hulluja. Mutta nyt on avoimen lähdekoodin yhteisöjen vuoro tehdä sitä, mitä he osaavat parhaiten: toimittaa ilmaisia kilpailevia ohjelmistoja käyttämällä paljon vähemmän rahaa ja laitteita.
OpenAI on ottanut yli 11 miljardin dollarin rahoituksen, ja GPT-3.5:n arvioidaan maksavan 5–6 miljoonaa dollaria harjoittelua kohden. Tiedämme hyvin vähän GPT-4:stä, koska OpenAI ei kerro, mutta mielestäni on turvallista olettaa, että se ei ole pienempi kuin GPT-3.5. GPU-pula on tällä hetkellä maailmanlaajuisesti, eikä se vaihteeksi johdu uusimmasta kryptocoinista. Generatiivisen tekoälyn start-up-yritykset saavat yli 100 miljoonan dollarin sarjan A kierroksia valtavilla arvoilla, kun he eivät omista tuotteensa tehostamiseen käyttämänsä LLM:n IP-oikeuksia. LLM:n kelkka on kovassa vaihteessa ja rahat virtaavat.
It had looked like the die was cast: only deep-pocketed companies like Microsoft/OpenAI, Amazon, and Google could afford to train hundred-billion parameter models. Bigger models were assumed to be better models. GPT-3 got something wrong? Just wait until there's a bigger version and it’ll all be fine! Smaller companies looking to compete had to raise far more capital or be left building commodity integrations in the ChatGPT marketplace. Academia, with even more constrained research budgets, was relegated to the sidelines.
Onneksi joukko älykkäitä ihmisiä ja avoimen lähdekoodin projekteja otti tämän pikemminkin haasteena kuin rajoituksena. Stanfordin tutkijat julkaisivat Alpacan, 7 miljardin parametrin mallin, jonka suorituskyky on lähellä GPT-3.5:n 175 miljardin parametrimallia. Koska resursseja ei ollut OpenAI:n käyttämän kokoisen koulutussarjan rakentamiseen, he päättivät ovelasti ottaa koulutetun avoimen lähdekoodin LLM:n, LLaMA:n, ja hienosäätää sen sijaan sarjan GPT-3.5 kehotteita ja lähtöjä. Pohjimmiltaan malli oppi, mitä GPT-3.5 tekee, mikä osoittautuu erittäin tehokkaaksi strategiaksi toistaa sen käyttäytymistä.
Alpaca on lisensoitu vain ei-kaupalliseen käyttöön sekä koodissa että datassa, koska se käyttää avoimen lähdekoodin ei-kaupallista LLaMA-mallia, ja OpenAI nimenomaisesti kieltää sovellusliittymiensä käytön kilpailevien tuotteiden luomiseen. Tämä luo houkuttelevan mahdollisuuden hienosäätää erilaista avoimen lähdekoodin LLM:ää Alpacan kehotteiden ja tulosten perusteella… luoden kolmannen GPT-3.5:n kaltaisen mallin erilaisilla lisensointimahdollisuuksilla.
Tässä on toinenkin ironinen kerros, sillä kaikki suuret LLM:t koulutettiin tekijänoikeudella suojatuista teksteistä ja kuvista, jotka ovat saatavilla Internetissä, eivätkä he maksaneet penniäkään oikeuksien haltijoille. Yritykset vaativat Yhdysvaltain tekijänoikeuslain mukaista "reilun käytön" poikkeusta väittäen, että käyttö on "muuntavaa". Mitä tulee ilmaisella datalla rakentamiensa mallien tuottoon, he eivät todellakaan halua kenenkään tekevän heille samaa. Odotan, että tämä muuttuu oikeudenhaltijoiden viisastuessa ja saattaa jossain vaiheessa päätyä oikeuteen.
Tämä on erillinen ja erillinen seikka verrattuna rajoittavasti lisensoitujen avoimen lähdekoodin tekijöiden esittämiin kysymyksiin, jotka vastustavat CoPilotin kaltaisten generatiivisten AI for Code -tuotteiden osalta koodin käyttämistä koulutukseen sillä perusteella, että lisenssiä ei noudateta. Yksittäisten avoimen lähdekoodin tekijöiden ongelmana on, että heidän on osoitettava asemansa – aineellista kopiointia – ja että heille on aiheutunut vahinkoja. Ja koska mallit vaikeuttavat tuloskoodin linkittämistä syötteeseen (tekijän lähdekoodirivit) ja taloudellisia menetyksiä (sen oletetaan olevan ilmainen), on paljon vaikeampaa tehdä asia. Tämä on toisin kuin voittoa tavoittelevat luojat (esim. valokuvaajat), joiden koko liiketoimintamalli on lisensointi/myynti työssään ja joita edustavat Getty Imagesin kaltaiset aggregaattorit, jotka voivat osoittaa todellista kopiointia.
Toinen mielenkiintoinen asia LLaMAssa on, että se tuli Metalta. Se julkaistiin alun perin vain tutkijoille, ja sitten se vuoti BitTorrentin kautta maailmalle. Meta on täysin erilainen liiketoiminta kuin OpenAI, Microsoft, Google ja Amazon, koska se ei yritä myydä sinulle pilvipalveluita tai ohjelmistoja, joten sillä on hyvin erilaisia kannustimia. Se on aiemmin käyttänyt avoimen lähdekoodin laskentasuunnitelmansa (OpenCompute) ja nähnyt yhteisön parantavan niitä – se ymmärtää avoimen lähdekoodin arvon.
Meta voi osoittautua yhdeksi tärkeimmistä avoimen lähdekoodin tekoälyn avustajista. Sillä ei ole vain valtavia resursseja, vaan se hyötyy, jos mahtavaa luovaa tekoälytekniikkaa leviää: sosiaalisessa mediassa on enemmän sisältöä, jota se voi kaupallistaa. Meta on julkaissut kolme muuta avoimen lähdekoodin tekoälymallia: ImageBind (moniulotteinen tietojen indeksointi), DINOv2 (tietokonenäkö) ja Segment Anything. Jälkimmäinen tunnistaa kuvissa olevat ainutlaatuiset kohteet, ja se julkaistaan erittäin sallivan Apache-lisenssin alaisena.
Lopuksi meillä oli myös väitetty vuoto sisäisestä Google-asiakirjasta "Meillä ei ole vallihauta, eikä myöskään OpenAI", joka antaa hämärän näkemyksen suljettuihin malleihin verrattuna innovaatioihin, joita yhteisöt tuottavat paljon pienempiä, halvempia malleja, jotka toimivat lähellä tai paremmin kuin niiden suljetun lähdekoodin vastineet. Sanon väitetyn, koska artikkelin lähdettä ei voida millään varmistaa Googlen sisäiseksi. Se sisältää kuitenkin tämän vakuuttavan kaavion:
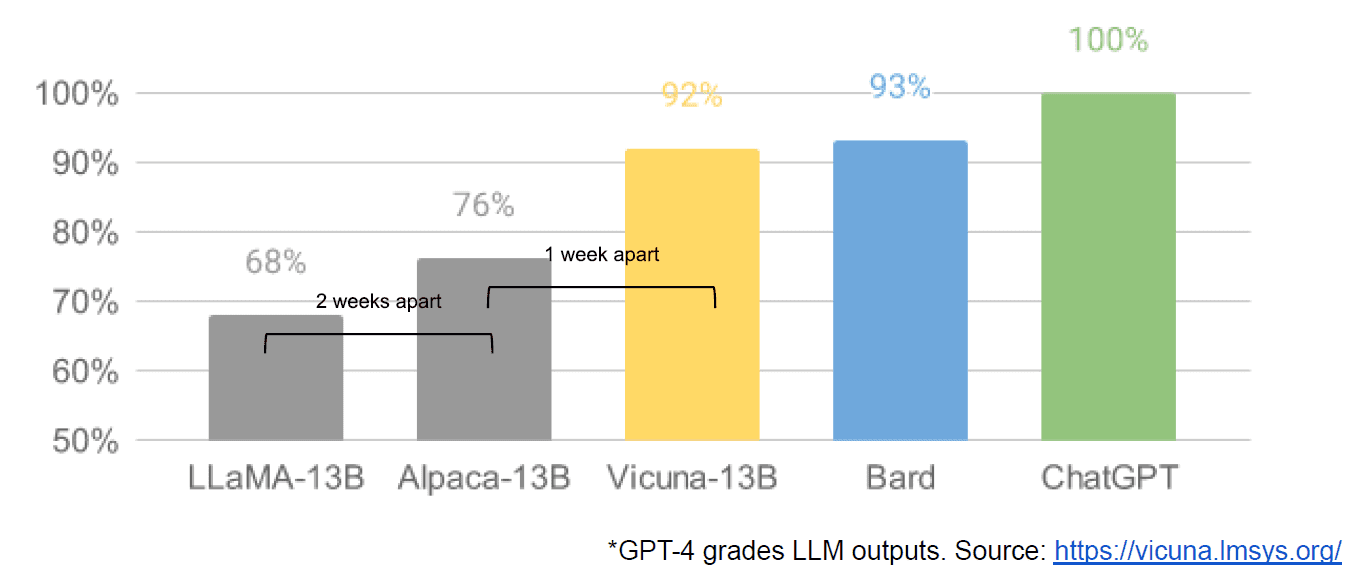
Pystyakseli on selkeästi GPT-4:n LLM-tulosteiden luokittelu.
Stable Diffusion, joka syntetisoi kuvia tekstistä, on toinen esimerkki siitä, missä avoimen lähdekoodin generatiivinen tekoäly on pystynyt edenmään nopeammin kuin patentoidut mallit. Tuon projektin äskettäinen iteraatio (ControlNet) on parantanut sitä niin, että se on ylittänyt Dall-E2:n ominaisuudet. Tämä johtui suuresta puuhastelusta ympäri maailmaa, mikä johti sellaiseen etenemisvauhtiin, johon yhdenkään toimielimen on vaikea vastata. Jotkut heistä keksivät, kuinka saada Stable Diffusion -järjestelmästä nopeampi harjoittelemaan ja toimimaan halvemmalla laitteistolla, mikä mahdollistaa lyhyemmät iterointijaksot useammalle ihmiselle.
Ja niin olemme tulleet täyteen ympyrään. Liian rahan ja laitteiston puute on inspiroinut ovelaa innovaatiotasoa koko tavallisten ihmisten yhteisössä. Mikä aika olla AI-kehittäjä.
Mathew Lodge on Diffbluen, AI For Code -aloitusyrityksen, toimitusjohtaja. Hänellä on yli 25 vuoden monipuolinen kokemus tuotejohtajuudesta sellaisissa yrityksissä kuin Anaconda ja VMware. Lodge toimii tällä hetkellä Good Law Projectin hallituksessa ja on Royal Photographic Societyn hallituksen varapuheenjohtaja.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoAiStream. Web3 Data Intelligence. Tietoa laajennettu. Pääsy tästä.
- Tulevaisuuden lyöminen Adryenn Ashley. Pääsy tästä.
- Osta ja myy osakkeita PRE-IPO-yhtiöissä PREIPO®:lla. Pääsy tästä.
- Lähde: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :on
- :On
- :ei
- :missä
- $ YLÖS
- 9
- a
- pystyy
- Meistä
- Academia
- pääsy
- Adobe
- edistää
- Kerääjät
- AI
- Kaikki
- väitetty
- väitetään
- Myös
- Amazon
- an
- ja
- Toinen
- Kaikki
- joku
- mitään
- Apache
- API
- OVAT
- perustelu
- artikkeli
- AS
- oletettu
- At
- kirjoittaja
- Tekijät
- saatavissa
- Akseli
- BE
- koska
- ollut
- ovat
- Hyödyt
- PARAS
- Paremmin
- suurempi
- BitTorrent
- hallitus
- sekä
- Talousarviot
- rakentaa
- Rakentaminen
- Nippu
- liiketoiminta
- liiketoimintamalli
- mutta
- by
- tuli
- CAN
- kyvyt
- pääoma
- tapaus
- toimitusjohtaja
- Tuoli
- haaste
- muuttaa
- ChatGPT
- halvempaa
- valitsi
- Ympyrä
- vaatia
- selkeä
- lähellä
- suljettu
- pilvi
- pilvipalvelut
- koodi
- Tulla
- tulee
- hyödyke
- yhteisöjen
- yhteisö
- Yritykset
- pakottava
- kilpailla
- kilpailevien
- Laskea
- tietokone
- Tietokoneen visio
- pitoisuus
- avustajat
- kopiointi
- tekijänoikeus
- kustannukset
- voisi
- Tuomioistuin
- luoda
- Luominen
- luojat
- kryptoiini
- Tällä hetkellä
- jaksoa
- tiedot
- tuottaa
- sijainen
- mallit
- Kehittäjä
- Kehitys
- Kuolla
- eri
- vaikea
- Diffuusio
- selvä
- useat
- do
- asiakirja
- ei
- Dont
- e
- Taloudellinen
- Tehokas
- mahdollistaa
- loppu
- Koko
- EPIC
- laitteet
- olennaisesti
- arvioidaan
- Jopa
- esimerkki
- odottaa
- kallis
- experience
- paljon
- nopeampi
- kuviollinen
- Virtaava
- seurannut
- varten
- kahlaamo
- Ilmainen
- alkaen
- koko
- pohjimmiltaan
- rahoitus
- vaihde
- general
- generatiivinen
- Generatiivinen AI
- hyvä
- GPU
- kaavio
- suuri
- HAD
- Kova
- Tarvikkeet
- Olla
- ottaa
- he
- tätä
- Korkea
- erittäin
- haltijat
- Miten
- Miten
- Kuitenkin
- HTTPS
- valtava
- mainostemppu
- i
- tunnistaa
- if
- kuvien
- tärkeä
- parantaa
- parani
- in
- kannustimet
- henkilökohtainen
- Innovaatio
- panos
- HULLU
- innoittamana
- sen sijaan
- Laitos
- integraatiot
- mielenkiintoinen
- sisäinen
- Internet
- keksi
- IP
- ironia
- IT
- iteraatio
- SEN
- vain
- KDnuggets
- Tietää
- lasku
- uusin
- Laki
- kerros
- Johto
- oppinut
- vasemmalle
- vähemmän
- Taso
- Lisenssi
- Licensed
- Licensing
- pitää
- linjat
- LINK
- vähän
- liekki
- Pitkät
- Katsoin
- näköinen
- menettää
- pois
- Erä
- merkittävä
- tehdä
- Tekeminen
- monet
- markkinat
- massiivinen
- ottelu
- Saattaa..
- Media
- Meta
- Microsoft
- malli
- mallit
- kaupallistaa
- raha
- lisää
- eniten
- paljon
- Tarve
- Eikä
- Nro
- ei-kaupallinen
- nyt
- objekti
- esineet
- of
- on
- ONE
- vain
- avata
- avoimen lähdekoodin
- avoimen lähdekoodin projektit
- OpenAI
- or
- tavallinen
- alun perin
- Muut
- ulos
- ulostulo
- yli
- oma
- Rauha
- parametri
- Ohi
- Maksaa
- Ihmiset
- suorittaa
- suorituskyky
- Platon
- Platonin tietotieto
- PlatonData
- Kohta
- mahdollisuuksia
- teho
- Ongelma
- Tuotteet
- Tuotteemme
- projekti
- hankkeet
- patentoitu
- näkymä
- nostaa
- esille
- pikemminkin
- ihan oikeesti
- äskettäinen
- julkaistu
- edustettuina
- tutkimus
- Tutkijat
- Esittelymateriaalit
- rajoitus
- Saatu ja
- oikeudet
- kierrosta
- kuninkaallinen
- ajaa
- s
- turvallista
- sama
- sanoa
- nähneet
- segmentti
- Myydään
- erillinen
- Sarjat
- Sarja A
- palvelee
- Palvelut
- setti
- puute
- näyttää
- koska
- single
- Koko
- pienempiä
- fiksu
- So
- sosiaalinen
- sosiaalinen media
- yhteiskunta
- Tuotteemme
- jonkin verran
- jotain
- lähde
- lähdekoodi
- viettää
- vakaa
- Stanford
- aloituksia
- käynnistyksen
- Strategia
- niin
- ehdottaa
- tarkoitus
- ylitti
- ottaa
- otettava
- vie
- Elektroniikka
- kuin
- että
- -
- Lähde
- maailma
- heidän
- Niitä
- sitten
- Siellä.
- ne
- asia
- ajatella
- kolmas
- tätä
- ne
- kolmella
- aika
- että
- liian
- otti
- Juna
- koulutettu
- koulutus
- VUORO
- kääntyy
- varten
- ymmärtää
- unique
- toisin kuin
- asti
- us
- käyttää
- käytetty
- käyttötarkoituksiin
- käyttämällä
- Arvostukset
- arvo
- todentaa
- versio
- pystysuora
- hyvin
- kautta
- Näytä
- visio
- vMware
- vs
- odottaa
- haluta
- oli
- Tapa..
- we
- meni
- olivat
- Mitä
- kun
- joka
- KUKA
- koko
- jonka
- tulee
- VIISAS
- with
- Referenssit
- maailman-
- Väärä
- te
- zephyrnet









