Amazonin punainen siirto, laajalti käytetty pilvitietovarasto, on kehittynyt merkittävästi vastaamaan vaativimpien työkuormien suorituskykyvaatimuksia. Tämä viesti kattaa yhden tällaisen uuden ominaisuuden - moniulotteisen tietojen asettelun lajitteluavaimen.
Amazon Redshift parantaa nyt kyselysi suorituskykyä tukemalla moniulotteisia tietojen asettelun lajitteluavaimia, jotka ovat uudentyyppisiä lajitteluavaimia, jotka lajittelevat taulukon tiedot suodatinpredikaattien mukaan taulukon fyysisten sarakkeiden sijaan. Moniulotteiset tietojen asettelun lajitteluavaimet parantavat merkittävästi taulukkotarkistusten suorituskykyä, varsinkin kun kyselyn työmäärä sisältää toistuvia tarkistussuodattimia.
Amazon Redshift tarjoaa jo valmiudet automaattinen pöydän optimointi (ATO), joka optimoi taulukoiden suunnittelun automaattisesti käyttämällä lajittelu- ja jakeluavaimia ilman järjestelmänvalvojan toimia. Tässä viestissä esittelemme moniulotteiset tietojen asettelun lajitteluavaimet ATO:n tarjoamana lisäominaisuudena, jota vahvistaa Amazon Redshiftin lajitteluavaimen neuvonta-algoritmi.
Moniulotteiset tietojen asettelun lajitteluavaimet
Kun määrität taulukon AUTOMAATTisella lajitteluavaimella, Amazon Redshift ATO analysoi kyselyhistoriasi ja valitsee automaattisesti joko yhden sarakkeen lajitteluavaimen tai moniulotteisen tietojen asettelun lajitteluavaimen taulukollesi sen mukaan, kumpi vaihtoehto on parempi työkuormillesi. Kun moniulotteinen tietojen asettelu on valittu, Amazon Redshift rakentaa moniulotteisen lajittelufunktion, joka paikantaa samaan aikaan rivit, joihin tyypillisesti päästään samoilla kyselyillä, ja lajittelutoimintoa käytetään myöhemmin kyselyn aikana tietolohkojen ohittamiseen ja jopa yksittäisen predikaatin skannauksen ohittamiseen. sarakkeita.
Harkitse seuraavaa käyttäjän kyselyä, joka on hallitseva kyselymalli käyttäjän työkuormassa:
Amazon Redshift tallentaa kunkin sarakkeen tiedot 1 Mt:n levylohkoihin ja tallentaa kunkin lohkon vähimmäis- ja enimmäisarvot osana taulukon metatietoja. Jos kyselyssä käytetään a aluerajoitettu predikaatti, Amazon Redshift voi käyttää minimi- ja maksimiarvoja ohittaakseen nopeasti suuren lohkomäärän taulukkoskannauksen aikana. Tämän kyselyn alialuesarakkeen suodatinta ei kuitenkaan voida käyttää määrittämään, mitkä lohkot ohitetaan vähimmäis- ja enimmäisarvojen perusteella, ja tämän seurauksena Amazon Redshift skannaa kaikki otsikkotaulukon rivit:
Kun käyttäjän kysely suoritettiin titles käyttämällä yhden sarakkeen lajittelunäppäintä subregion, edellisen kyselyn tulos on seuraava:
Tämä osoittaa, että taulukon skannaus luki 2,164,081,640 XNUMX XNUMX XNUMX riviä.
Voit parantaa skannauksia titles taulukkoon, Amazon Redshift saattaa automaattisesti päättää käyttää moniulotteista tietojen asettelun lajitteluavainta. Kaikki rivit, jotka täyttävät lower(subregion) like '%United States%' predikaatti sijaitsisi samassa paikassa taulukon erillisellä alueella, ja siksi Amazon Redshift skannaa vain predikaatin täyttäviä tietolohkoja.
Kun käyttäjän kysely suoritetaan titles käyttämällä moniulotteista tietojen asettelun lajitteluavainta, joka sisältää lower(subregion) like '%United States%' predikaattina tulos sys_query_detail kysely on seuraava:
Tämä osoittaa, että taulukon skannaus luki 152,324,046 7 XNUMX riviä, mikä on vain XNUMX % alkuperäisestä, ja siinä käytettiin moniulotteisen tietojen asettelun lajitteluavainta.
Huomaa, että tässä esimerkissä käytetään yhtä kyselyä moniulotteisen tietojen asetteluominaisuuden esittelemiseen, mutta Amazon Redshift ottaa huomioon kaikki taulukossa suoritettavat kyselyt ja voi luoda useita alueita täyttääkseen yleisimmin suoritetut predikaatit.
Otetaan toinen esimerkki monimutkaisemmista predikaateista ja useista kyselyistä tällä kertaa.
Kuvittele, että sinulla on pöytä items (cost int, available int, demand int) neljällä rivillä seuraavan esimerkin mukaisesti.
| #tunnus | maksaa | saatavissa | Kysyntä |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Hallitseva työmääräsi koostuu kahdesta kyselystä:
- 70 % kyselyjen malli:
- 20 % kyselyjen malli:
Perinteisillä lajittelutekniikoilla voit lajitella taulukon kustannussarakkeen yli siten, että arviointi cost > 3 hyötyy lajista. Joten kohteiden taulukko lajittelun jälkeen käyttämällä yksittäistä cost sarake näyttää seuraavalta.
| #tunnus | maksaa | saatavissa | Kysyntä |
| Alue #1, hinta <= 3 | |||
| Alue #2, hinta > 3 | |||
| #tunnus | maksaa | saatavissa | Kysyntä |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Käyttämällä tätä perinteistä lajittelua voimme heti sulkea pois kaksi ylintä (sinistä) riviä, joilla on ID 4 ja ID 2, koska ne eivät täytä cost > 3.
Toisaalta moniulotteisella tietoasettelun lajitteluavaimella taulukko lajitellaan kahden käyttäjän työkuormassa yleisesti esiintyvän predikaatin yhdistelmän perusteella, jotka ovat cost > 3 ja available < demand. Tämän seurauksena taulukon rivit lajitellaan neljään alueeseen.
| #tunnus | maksaa | saatavissa | Kysyntä |
| Alue #1, hinta <= 3 ja saatavilla < kysyntä | |||
| Alue #2, hinta <= 3 ja saatavilla >= kysyntä | |||
| Alue #3, hinta > 3 ja saatavilla < kysyntä | |||
| Alue #4, hinta > 3 ja saatavilla >= kysyntä | |||
| #tunnus | maksaa | saatavissa | Kysyntä |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Tämä konsepti on vielä tehokkaampi, kun sitä sovelletaan kokonaisiin lohkoihin yksittäisten rivien sijaan, kun sitä sovelletaan monimutkaisiin predikaatteihin, jotka käyttävät operaattoreita, jotka eivät sovellu perinteisiin lajittelutekniikoihin (esim. like), ja kun sitä käytetään useammalle kuin kahdelle predikaatille.
Järjestelmätaulukot
Seuraavat Amazon Redshift -järjestelmätaulukot näyttävät käyttäjille, käytetäänkö heidän taulukoissaan ja kyselyissään moniulotteisia tietoasetteluja:
- Voit tarkistaa, käyttääkö tietty taulukko moniulotteisen tietojen asettelun lajitteluavainta
sortkey1in svv_table_info on yhtä suuri kuinAUTO(SORTKEY(padb_internal_mddl_key_col)). - Voit määrittää, käyttääkö tietty kysely moniulotteista tietoasettelua taulukkotarkistuksia nopeuttamaan,
step_attributevuonna sys_query_detail näkymä. Arvo on yhtä suuri kuinmulti-dimensionaljos taulukon moniulotteisen tietojen asettelun lajitteluavainta käytettiin tarkistuksen aikana.
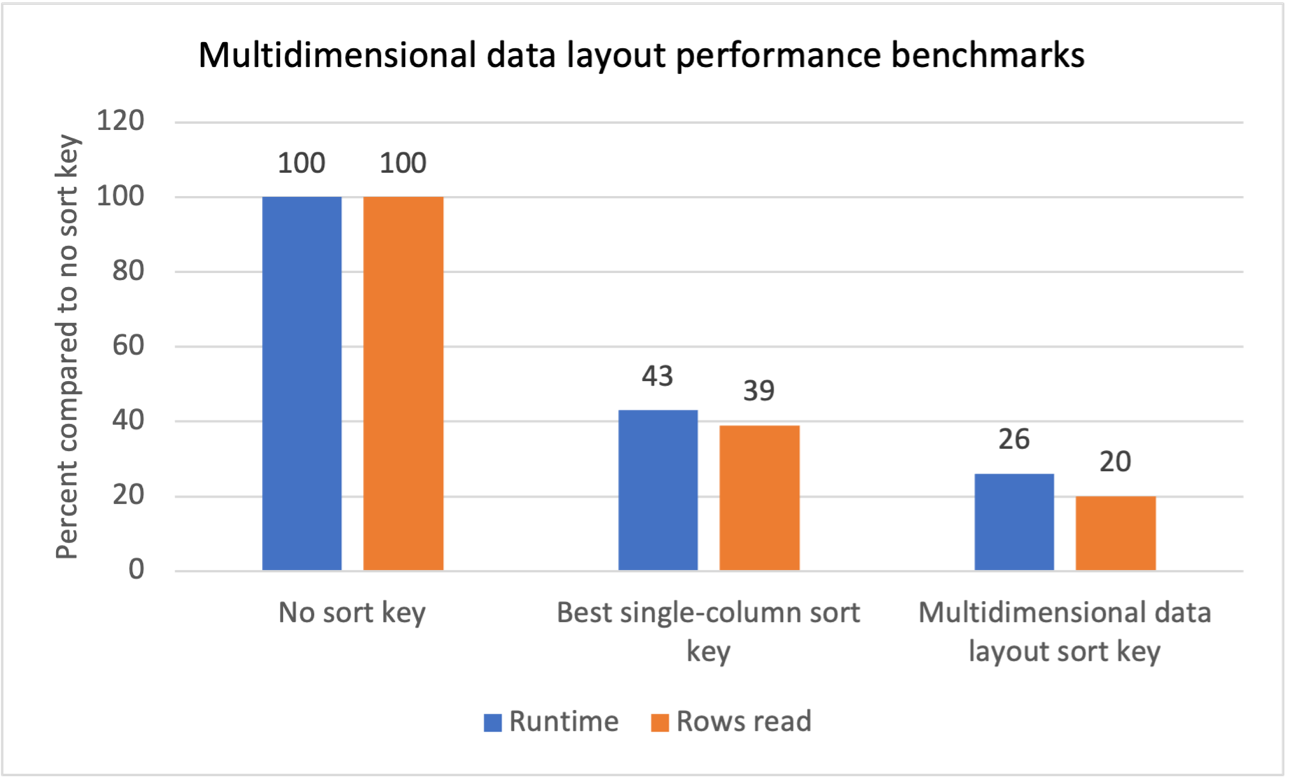
Suorituskyvyn vertailuarvot
Teimme sisäisen vertailutestauksen useille työkuormille toistuvilla skannaussuodattimilla ja havaitsimme, että moniulotteisten tietojen asettelun lajitteluavainten käyttöönotto tuotti seuraavat tulokset:
- Kokonaisajoaika lyhenee 74 % verrattuna lajitteluavaimen puuttumiseen.
- 40 %:n kokonaissuoritusajan vähennys verrattuna kunkin taulukon parhaaseen yhden sarakkeen lajitteluavaimeen.
- Taulukoista luettujen rivien kokonaismäärä on 80 % pienempi verrattuna lajitteluavaimen puuttumiseen.
- Taulukoista luettujen rivien kokonaismäärä on 47 % pienempi verrattuna kunkin taulukon parhaaseen yhden sarakkeen lajitteluavaimeen.
Ominaisuuksien vertailu
Moniulotteisten tietojen asettelun lajitteluavainten käyttöönoton myötä taulukot voidaan nyt lajitella lausekkeiden mukaan, jotka perustuvat työkuormasi yleisesti esiintyviin suodatinpredikaatteihin. Seuraava taulukko tarjoaa Amazon Redshiftin ominaisuuksien vertailun kahteen kilpailijaan.
| Ominaisuus | Amazonin punainen siirto | Kilpailija A | Kilpailija B |
| Tuki sarakkeiden lajittelulle | Kyllä | Kyllä | Kyllä |
| Tuki lajittelulle lausekkeen mukaan | Kyllä | Kyllä | Ei |
| Automaattinen sarakkeen valinta lajittelua varten | Kyllä | Ei | Kyllä |
| Automaattisten lausekkeiden valinta lajittelua varten | Kyllä | Ei | Ei |
| Automaattinen valinta sarakkeiden lajittelun tai lausekkeiden lajittelun välillä | Kyllä | Ei | Ei |
| Lajitteluominaisuuksien automaattinen käyttö lausekkeille skannauksen aikana | Kyllä | Ei | Ei |
Huomioita
Muista seuraavat asiat, kun käytät moniulotteista tietoasettelua:
- Moniulotteinen tietojen asettelu on käytössä, kun asetat taulukoksi SORTKEY AUTO.
- Amazon Redshift Advisor valitsee automaattisesti joko yhden sarakkeen lajitteluavaimen tai moniulotteisen tietoasettelun taulukolle analysoimalla historiallisen työmääräsi.
- Amazon Redshift ATO säätää moniulotteisen dataasettelun lajittelutuloksia sen mukaan, miten käynnissä olevat kyselyt ovat vuorovaikutuksessa työmäärän kanssa.
- Amazon Redshift ATO ylläpitää moniulotteisia tietojen asettelun lajitteluavaimia samalla tavalla kuin nykyisin olemassa oleville lajitteluavaimille. Viitata Työskentely automaattisen taulukon optimoinnin kanssa lisätietoja ATO:sta.
- Moniulotteiset tietojen asettelun lajitteluavaimet toimivat sekä varattujen klustereiden että palvelimettomien työryhmien kanssa.
- Moniulotteiset tietojen asettelun lajitteluavaimet toimivat olemassa olevien tietojen kanssa niin kauan kuin AUTOMAATTINEN LAJITTELU on käytössä taulukossasi ja toistuvien skannaussuodattimien aiheuttama työkuorma havaitaan. Taulukko järjestetään uudelleen moniulotteisen lajittelufunktion tulosten perusteella.
- Voit poistaa moniulotteiset tietoasettelun lajitteluavaimet käytöstä taulukossa käyttämällä muuta taulukkoa:
ALTER TABLE table_name ALTER SORTKEY NONE. Tämä poistaa käytöstä AUTOMAATTINEN lajitteluavain -ominaisuuden pöydältä. - Moniulotteisen dataasettelun lajitteluavaimet säilytetään, kun hallittu klusteri palautetaan tai siirretään palvelimettomaan klusteriin tai päinvastoin.
Yhteenveto
Tässä viestissä osoitimme, että moniulotteiset tietojen asettelun lajitteluavaimet voivat parantaa merkittävästi kyselyn suoritusaikaa työkuormilla, joissa hallitsevilla kyselyillä on toistuvia tarkistussuodattimia.
Jos haluat luoda esikatseluklusterin Amazon Redshift -konsolista, siirry kohtaan Klusterit ja valitse Luo esikatseluklusteri. Voit luoda klusterin USA:n itä- (Ohio), Yhdysvaltain itä- (N. Virginia), Yhdysvaltain länsi- (Oregon), Aasian ja Tyynenmeren (Tokio), Euroopan (Irlanti) ja Euroopan (Tukholma) alueille ja testata työkuormituksiasi.
Haluaisimme kuulla palautettasi tästä uudesta ominaisuudesta ja odotamme kommenttejasi tähän viestiin.
Tietoja kirjoittajista
 Milind Oke on Data Warehouse Specialist Solutions -arkkitehti New Yorkista. Hän on rakentanut tietovarastoratkaisuja yli 15 vuoden ajan ja on erikoistunut Amazon Redshiftiin.
Milind Oke on Data Warehouse Specialist Solutions -arkkitehti New Yorkista. Hän on rakentanut tietovarastoratkaisuja yli 15 vuoden ajan ja on erikoistunut Amazon Redshiftiin.
 Jialin Ding on Applied Scientist Learned Systems Groupissa, joka on erikoistunut koneoppimis- ja optimointitekniikoiden soveltamiseen tietojärjestelmien, kuten Amazon Redshiftin, suorituskyvyn parantamiseksi.
Jialin Ding on Applied Scientist Learned Systems Groupissa, joka on erikoistunut koneoppimis- ja optimointitekniikoiden soveltamiseen tietojärjestelmien, kuten Amazon Redshiftin, suorituskyvyn parantamiseksi.
 Yanzhu Ji on tuotepäällikkö Amazon Redshift -tiimissä. Hänellä on kokemusta tuotevision ja strategian kehittämisestä alan johtavissa tietotuotteissa ja -alustoissa. Hänellä on erinomainen taito rakentaa merkittäviä ohjelmistotuotteita käyttämällä web-kehitystä, järjestelmäsuunnittelua, tietokantaa ja hajautettuja ohjelmointitekniikoita. Yksityiselämässään Yanzhu pitää maalaamisesta, valokuvaamisesta ja tenniksen pelaamisesta.
Yanzhu Ji on tuotepäällikkö Amazon Redshift -tiimissä. Hänellä on kokemusta tuotevision ja strategian kehittämisestä alan johtavissa tietotuotteissa ja -alustoissa. Hänellä on erinomainen taito rakentaa merkittäviä ohjelmistotuotteita käyttämällä web-kehitystä, järjestelmäsuunnittelua, tietokantaa ja hajautettuja ohjelmointitekniikoita. Yksityiselämässään Yanzhu pitää maalaamisesta, valokuvaamisesta ja tenniksen pelaamisesta.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :on
- :On
- :ei
- :missä
- 1
- 100
- 15 vuotta
- 15%
- 152
- 7
- 8
- 9
- a
- kiihdyttää
- Accessed
- lisä-
- neuvonantaja
- Jälkeen
- vastaan
- algoritmi
- Kaikki
- jo
- Amazon
- Amazon Web Services
- an
- analysoida
- analysointi
- ja
- Toinen
- sovellettu
- Hakeminen
- OVAT
- AS
- Aasia
- Aasia pacific
- auto
- automaattisesti
- automaattisesti
- saatavissa
- AWS
- perustua
- BE
- koska
- ollut
- benchmark
- hyödyttää
- PARAS
- Paremmin
- välillä
- Tukkia
- Blocks
- sininen
- sekä
- Rakentaminen
- mutta
- by
- CAN
- valmiudet
- tarkastaa
- Valita
- pilvi
- Cluster
- Sarake
- Pylväät
- yhdistelmä
- kommentit
- yleisesti
- verrattuna
- vertailu
- kilpailijat
- monimutkainen
- käsite
- Harkita
- muodostuu
- Console
- rakentaa
- sisältää
- Hinta
- kannet
- luoda
- Tällä hetkellä
- tiedot
- tietovarasto
- tietokanta
- päättää
- omistautunut
- määritellä
- Kysyntä
- vaativa
- Malli
- yksityiskohdat
- havaittu
- Määrittää
- Kehitys
- jaettu
- jakelu
- ei
- hallitseva
- Dont
- aikana
- kukin
- Itään
- myöskään
- käytössä
- Koko
- yhtäläinen
- erityisesti
- Eetteri (ETH)
- Eurooppa
- arviointi
- Jopa
- kehittynyt
- esimerkki
- olemassa
- experience
- ilmauksia
- Ominaisuus
- palaute
- suodattaa
- suodattimet
- jälkeen
- seuraa
- varten
- Eteenpäin
- neljä
- alkaen
- toiminto
- Ryhmä
- käsi
- Olla
- ottaa
- he
- kuulla
- hänen
- historiallinen
- historia
- Kuitenkin
- HTML
- HTTPS
- ID
- if
- heti
- parantaa
- parantaa
- in
- sisältää
- henkilökohtainen
- alan johtava
- sen sijaan
- olla vuorovaikutuksessa
- sisäinen
- interventio
- tulee
- esitellä
- käyttöön
- esittely
- Irlanti
- IT
- kohdetta
- avain
- avaimet
- suuri
- Layout
- oppinut
- oppiminen
- elämä
- pitää
- tykkää
- Pitkät
- katso
- näyttää joltakin
- rakkaus
- kone
- koneoppiminen
- ylläpitää
- johtaja
- tapa
- maksimi
- Tavata
- Metadata
- ehkä
- siirtyvät
- mielessä
- minimi
- lisää
- eniten
- moninkertainen
- Navigoida
- Tarve
- Uusi
- uusi ominaisuus
- New York
- Nro
- nyt
- numerot
- esiintyviä
- of
- pois
- tarjotaan
- Ohio
- on
- ONE
- jatkuva
- vain
- operaattorit
- optimointi
- Optimismi
- Vaihtoehto
- or
- tilata
- Oregon
- alkuperäinen
- Muut
- ulos
- erinomainen
- yli
- Tyynenmeren
- maalaus
- osa
- erityinen
- Kuvio
- suorituskyky
- suoritettu
- henkilöstö
- valokuvaus
- fyysinen
- Platforms
- Platon
- Platonin tietotieto
- PlatonData
- pelaa
- Kirje
- voimakas
- säilytetty
- preview
- valmistettu
- Tuotteet
- tuotepäällikkö
- Tuotteemme
- Ohjelmointi
- ominaisuudet
- tarjoaa
- kyselyt
- nopeasti
- Lue
- vähentäminen
- katso
- alue
- alueet
- toistuva
- vaatimukset
- palauttaminen
- johtua
- tulokset
- ajaa
- juoksu
- toimii
- sama
- skannata
- skannaus
- skannaa
- Tiedemies
- Kausi
- nähdä
- valita
- valittu
- valinta
- serverless
- Palvelut
- setti
- hän
- näyttää
- näyteikkuna
- osoittivat
- esitetty
- Näytä
- merkittävästi
- single
- taito
- So
- Tuotteemme
- Ratkaisumme
- asiantuntija
- erikoistunut
- erikoistunut
- varastot
- Strategia
- Myöhemmin
- merkittävä
- niin
- sopiva
- Tukea
- järjestelmä
- järjestelmät
- taulukko
- ottaa
- joukkue-
- tekniikat
- tennis
- testi
- Testaus
- kuin
- että
- -
- heidän
- siksi
- ne
- tätä
- aika
- otsikot
- että
- Tokio
- ylin
- Yhteensä
- perinteinen
- kaksi
- tyyppi
- tyypillisesti
- us
- käyttää
- käytetty
- käyttäjä
- Käyttäjät
- käyttötarkoituksiin
- käyttämällä
- arvo
- arvot
- pahe
- Näytä
- virginia
- visio
- Varasto
- oli
- Tapa..
- we
- verkko
- Web-kehitys
- verkkopalvelut
- Länsi
- kun
- onko
- joka
- laajalti
- tulee
- with
- ilman
- Referenssit
- olisi
- vuotta
- york
- te
- Sinun
- zephyrnet