esittely
Yhdistäminen tekoäly (AI) ja taiteellisuus paljastavat uusia mahdollisuuksia luovaan digitaaliseen taiteeseen, näkyvästi diffuusiomallien kautta. Nämä mallit erottuvat joukosta luovan AI-sukupolven joukossa ja tarjoavat erilaisen lähestymistavan perinteisistä hermoverkoista. Tämä artikkeli vie sinut tutkivalle matkalle diffuusiomallien syvyyksiin ja selventää niiden ainutlaatuista mekanismia visuaalisesti upeiden ja luovasti rikkaiden taideteosten luomisessa. Ymmärrä diffuusiomallien vivahteet ja hanki käsitys niiden roolista taiteellisen ilmaisun uudelleenmäärittelyssä kehittyneiden tekoälytekniikoiden linssin avulla.

Oppimistavoitteet
- Ymmärrä tekoälyn diffuusiomallien peruskäsitteet.
- Tutustu diffuusiomallien ja perinteisten hermoverkkojen väliseen eroon taiteen luomisessa.
- Analysoi taiteen luomisprosessia diffuusiomallien avulla.
- Arvioi tekoälyn luovia ja esteettisiä vaikutuksia digitaaliseen taiteeseen.
- Keskustele tekoälyn luoman taiteen eettisistä näkökohdista.
Tämä artikkeli julkaistiin osana Data Science Blogathon.
Sisällysluettelo
Diffuusiomallien ymmärtäminen

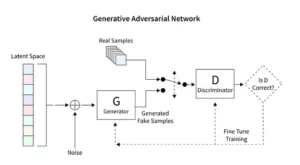
Diffuusiomallit mullistavat generatiivisen tekoälyn ja tarjoavat ainutlaatuisen kuvanluontimenetelmän, joka eroaa perinteisistä tekniikoista, kuten Generative Adversarial Networks (GANs). Satunnaisesta kohinasta alkaen nämä mallit jalostavat sitä asteittain muistuttaen maalausta hienosäätävää taiteilijaa, mikä johtaa monimutkaisiin ja yhtenäisiin kuviin.
Tämä asteittainen jalostusprosessi heijastaa diffuusion metodista luonnetta. Tässä jokainen iteraatio muuttaa kohinaa hienovaraisesti ja lähentää sitä lähemmäksi lopullista taiteellista visiota. Tuotos ei ole vain satunnaisuuden tuote, vaan kehittynyt taideteos, joka erottuu etenemisellään ja viimeistelyllään.
Diffuusiomallien koodaus vaatii syvällistä otetta hermoverkkoihin ja koneoppimiskehikkoihin, kuten TensorFlow tai PyTorch. Tuloksena oleva koodi on monimutkainen, ja se vaatii laajaa koulutusta laajoissa tietojoukoissa saavuttaakseen tekoälyn luomassa taiteessa havaitut vivahteet.
Stabiilin diffuusion soveltaminen Art
AI-taidegeneraattoreiden, kuten vakaiden diffuusiomallien, tulo vaatii kehittynyttä koodausta sellaisilla alustoilla kuin TensorFlow tai PyTorch. Nämä mallit erottuvat kyvystään muuttaa satunnaisuus järjestelmällisesti rakenteeksi, aivan kuten taiteilija, joka hioo alustavan luonnoksen eläväksi mestariteokseksi.
Vakaat diffuusiomallit muokkaavat tekoälyn taidekuvaa muotoilemalla satunnaisuudesta järjestyksessä olevia kuvia välttäen GANille ominaista kilpailudynamiikkaa. He tulkitsevat erinomaisesti käsitteellisiä kehotuksia visuaaliseksi taiteeksi ja edistävät synergististä tanssia tekoälykyvyn ja ihmisen kekseliäisyyden välillä. PyTorchia hyödyntämällä näemme, kuinka nämä mallit jalostavat kaaosta iteratiivisesti selkeydeksi, heijastaen taiteilijan matkaa syntymässä olevasta ideasta hiottuihin luomuksiin.
Tekoälyn luoman taiteen kokeilu
Tämä demonstraatio sukeltaa tekoälyn luoman taiteen kiehtovaan maailmaan käyttämällä konvoluutiohermoverkkoa nimeltä ConvDiffusionModel. Tämä malli on koulutettu erilaisiin taidekuviin, jotka sisältävät piirustuksia, maalauksia, veistoksia ja kaiverruksia, jotka on hankittu tämä Kaggle-tietosarja. Tavoitteenamme on tutkia mallin kykyä vangita ja toistaa näiden taideteosten monimutkainen estetiikka.
Malliarkkitehtuuri ja koulutus
Arkkitehtoninen suunnittelu
ConvDiffusionModel on ytimenään hermotekniikan ihme, ja siinä on hienostunut enkooderi-dekooderi-arkkitehtuuri, joka on räätälöity taiteen sukupolven vaatimuksiin. Mallin rakenne on monimutkainen hermoverkko, joka integroi hienostuneita enkooderi-dekooderimekanismeja, jotka on hiottu erityisesti taiteen luomiseen. Taiteellista intuitiota jäljittelevien ylimääräisten mutkaisten kerrosten ja ohitusyhteyksien ansiosta malli voi leikata ja koota taidetta tarkkaan ymmärtäen sommittelua ja tyyliä.
- Encoder: Enkooderi on mallin analyyttinen silmä, joka tutkii jokaisen syötekuvan pienimmätkin yksityiskohdat. Kun kuvat kulkevat kooderin konvoluutiokerrosten läpi, ne tiivistyvät asteittain piileväksi tilaksi – alkuperäisen taideteoksen kompaktiksi, koodatuksi esitykseksi. Enkooderimme ei vain tarkasta syötekuvia, vaan tekee sen nyt laajennetulla havainnointisyvyydellä lisätasojen ja eränormalisointitekniikoiden ansiosta. Tämä laajennettu tarkastelu mahdollistaa rikkaamman, tiivistetyn esityksen piilevässä tilassa, heijastaen taiteilijan syvää pohdiskelua aiheesta.
- dekooderi: Sitä vastoin dekooderi toimii mallin luovana kätenä, joka ottaa abstraktit luonnokset kooderista ja puhaltaa niihin elämää. Se rekonstruoi taideteoksen piilevasta tilasta kerros kerrokselta, yksityiskohta yksityiskohdalta, kunnes syntyy täydellinen kuva. Dekooderimme hyötyy ohitusyhteyksistä ja voi rekonstruoida taideteoksia tarkemmin. Siinä tarkastellaan uudelleen syötteen abstraktia olemusta ja asteittain kaunistaa sitä, jolloin saadaan aikaan lähdemateriaalille uskollisempi esitys. Parannetut kerrokset toimivat yhdessä varmistaakseen, että lopullinen kuva on elävä, monimutkainen pala, joka heijastaa syötteen taiteellisuutta.
Koulutusprosessi
ConvDiffusionModelin koulutus on matka taiteellisen maiseman läpi, joka kattaa 150 aikakautta. Jokainen aikakausi edustaa täydellistä läpikulkua koko tietojoukon läpi mallin pyrkiessä tarkentamaan ymmärrystään ja parantamaan luomiensa kuvien tarkkuutta.
- Hybridihäviötoiminto: Harjoittelun ytimessä on keskimääräisen neliövirheen (MSE) häviöfunktio. Tämä toiminto ilmaisee alkuperäisen mestariteoksen ja mallin virkistyksen välisen eron ja tarjoaa selkeän mittarin minimoimiseksi. Esittelemme esiopetetusta VGG-verkosta johdetun havaintohäviön komponentin, joka täydentää MSE-metriikkaa. Tämä kaksoishäviöstrategia saa mallin kunnioittamaan alkuperäisten taiteellista koskemattomuutta ja viimeistelemään niiden yksityiskohtien teknisen jäljennöksen.
- Optimoija: Adam Optimizer ohjaa mallin oppimista dynaamisesti ajastimen säätämän oppimisnopeuden avulla. Tämä mukautuva lähestymistapa varmistaa, että mallin edistyminen taiteen jäljittelemisen ja innovoinnin oppimisessa on sekä vakaata että vankkaa.
- Iterointi ja tarkentaminen: Harjoituksen iteraatiot ovat tanssia taiteellisen olemuksen säilyttämisen ja teknisen replikoinnin välillä. Jokaisella syklillä malli etenee lähemmäksi uskollisuuden ja luovuuden synteesiä.
- Edistyksen visualisointi: Kuvia tallennetaan säännöllisin väliajoin harjoituksen aikana mallin edistymisen visualisoimiseksi. Nämä tilannekuvat tarjoavat ikkunan mallin oppimiskäyrään ja esittelevät, kuinka sen tuotettu taide kehittyy, muuttuen selkeämmiksi, yksityiskohtaisemmiksi ja taiteellisesti johdonmukaisemmiksi kunkin aikakauden myötä.



Yllä oleva osoitetaan seuraavan koodinpalan avulla:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')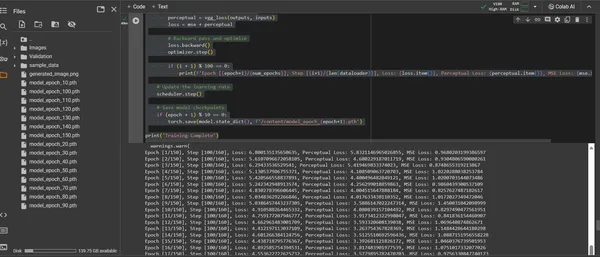
Luodun taideteoksen visualisointi
Ilmenee tekoälyn luomaa taidetta
Kun ConvDiffusionModel on nyt täysin koulutettu, painopiste siirtyy abstraktista konkreettiseen - potentiaalista tekoälyn luoman taiteen toteuttamiseen. Seuraava koodinpätkä toteuttaa mallin opitut taiteelliset ominaisuudet ja muuntaa syötetiedot digitaaliseksi ilmaisukankaaksi.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()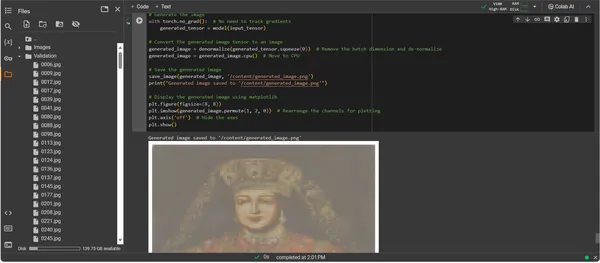

Artwork Generation Code Walkthrough
- Malli ylösnousemus: Ensimmäinen askel taideteosten sukupolvessa on koulutetun ConvDiffusionModel-mallimme elvyttäminen. Mallin opitut painot ladataan ja tuodaan arviointitilaan, mikä asettaa vaiheen luomiselle muuttamatta enempää sen parametreja.
- Kuvan muuntaminen: Johdonmukaisuuden varmistamiseksi harjoitusohjelman kanssa syötekuvat käsitellään saman muunnossarjan kautta. Tämä sisältää koon muuttamisen vastaamaan mallin syöttömittoja, tensorin muuntamisen PyTorch-yhteensopivuutta varten ja normalisoinnin harjoitustietojen tilastoprofiilin perusteella.
- Denormalisointiapuohjelma: Mukautettu toiminto kääntää esikäsittelytehosteet päinvastaiseksi ja skaalaa tensorin uudelleen alkuperäisen kuvan värialueelle. Tämä vaihe on välttämätön luodun tulosteen tekemiseksi visuaalisesti tarkaksi esitykseksi.
- Syötön valmistelu: Kuva ladataan ja sille tehdään edellä mainitut muunnokset. On tärkeää huomata, että tämä kuva toimii muusana, josta tekoäly saa inspiraatiota – hiljainen kuiskaus sytyttää mallin synteettisen mielikuvituksen.
- Taideteoksen synteesi: Eteenpäin leviämisen herkässä tanssissa malli tulkitsee syöttötensoria, jolloin sen kerrokset voivat tehdä yhteistyötä uuden taiteellisen vision tuottamiseksi. Suorita tämä prosessi ilman gradientin seurantaa, koska olemme nyt sovellusten, emme koulutuksen, alueella.
- Kuvan muunnos: Mallin tensorilähtö, joka nyt pitää sisällään digitaalisesti syntyneen taideteoksen, on denormalisoitu, mikä muuttaa mallin luomuksen takaisin tutuksi värin ja valon tilaan, jota silmämme voivat arvostaa.
- Taideteoksen ilmestys: Muunnettu tensori asetetaan digitaaliselle kankaalle, mikä huipentuu tallennettuun kuvatiedostoon. Tämä tiedosto on ikkuna tekoälyn luovaan sieluun, staattinen kaiku dynaamisesta prosessista, joka antoi sille elämän.
- Taideteoksen haku: Skripti päättää tallentamalla luodun kuvan määrätylle polulle ja ilmoittamalla sen valmistumisesta. Tallennettu kuva, synteesi opituista taiteellisista periaatteista ja nousevasta luovuudesta, on valmis esille ja mietiskelyyn.
Tulosten analysointi
ConvDiffusionModelin tulos esittää hahmon, jossa on selkeä nyökkäys historialliseen taiteeseen. Taidokkaaseen asuun verhottu tekoälyllä renderöity kuva toistaa klassisten muotokuvien loistoa, mutta samalla selkeällä, modernilla otteella. Kohteen pukeutumisessa on runsaasti tekstuuria, ja siinä yhdistyvät mallin opitut kuviot uuteen tulkintaan. Herkät kasvonpiirteet sekä valon ja varjon hienovarainen vuorovaikutus esittelevät tekoälyn vivahteikkaan ymmärrystä perinteisistä taidetekniikoista. Tämä taideteos on osoitus mallin hienostuneesta koulutuksesta, ja se heijastaa eleganttia historiallisen taiteen synteesiä edistyneen koneoppimisen prisman kautta. Pohjimmiltaan se on digitaalinen kunnianosoitus menneisyydelle, joka on muotoiltu nykyajan algoritmeilla.
Haasteet ja eettiset näkökohdat
Diffuusiomallien käyttöönotto taiteen sukupolvessa tuo mukanaan useita haasteita ja eettisiä näkökohtia, jotka sinun tulee ottaa huomioon:
- Tietojen alkuperä: Koulutustietojoukot on kuratoitava vastuullisesti. On tärkeää varmistaa, että diffuusiomallien kouluttamiseen käytetyt tiedot eivät sisällä tekijänoikeudella suojattuja tai suojattuja teoksia ilman asianmukaista lupaa.
- Harha ja edustus: Tekoälymallit voivat säilyttää harhoja harjoitustiedoissaan. Monipuolisten ja kattavan tietojoukon varmistaminen on tärkeää, jotta vältetään stereotypioiden vahvistaminen tekoälyn tuottamassa taiteessa.
- Ulostulon ohjaus: Koska diffuusiomallit voivat tuottaa monenlaisia tuloksia, on tarpeen asettaa rajat sopimattoman tai loukkaavan sisällön luomisen estämiseksi.
- Oikeudellinen kehys: Vahvan oikeudellisen kehyksen puute tekoälyn vivahteiden käsittelemiseksi luovassa prosessissa on haaste. Lainsäädäntöä on kehitettävä suojelemaan kaikkien osapuolten oikeuksia.
Yhteenveto
Diffuusiomallien nousu tekoälyssä ja taiteessa merkitsee muutosta aikakautta, joka yhdistää laskennallisen tarkkuuden esteettiseen tutkimiseen. Heidän matkansa taidemaailmassa korostaa merkittävää innovaatiopotentiaalia, mutta siihen liittyy monimutkaisuutta. Omaperäisyyden, vaikutuksen, eettisen luomisen ja olemassa olevien teosten kunnioittamisen tasapainottaminen on olennainen osa taiteellista prosessia.
Keskeiset ostokset
- Diffuusiomallit ovat taiteen luomisen transformatiivisen muutoksen eturintamassa. Ne tarjoavat uusia digitaalisia työkaluja, jotka laajentavat taiteellisen ilmaisun kanvaa perinteisten rajojen yli.
- Tekoälyllä tehostetussa taiteessa koulutustietojen eettisen keräämisen priorisointi ja tekijöiden henkisen omaisuuden kunnioittaminen on välttämätöntä digitaalisen taiteen eheyden säilyttämiseksi.
- Taiteellisen näkemyksen ja teknologisen innovaation lähentyminen avaa ovet taiteilijoiden ja tekoälykehittäjien väliseen symbioottiseen suhteeseen. Edistää yhteistyöympäristöä, joka voi synnyttää uraauurtavaa taidetta.
- On erittäin tärkeää varmistaa, että tekoälyn tuottama taide edustaa laajaa näkökulmaa. Sisällytä monipuolista tietoa, joka heijastaa eri kulttuurien ja näkökulmien rikkautta ja edistää siten osallisuutta.
- Kasvava kiinnostus tekoälyn luomaa taidetta kohtaan edellyttää vankan oikeudellisen kehyksen luomista. Näiden viitekehysten pitäisi selventää tekijänoikeuskysymyksiä, tunnustaa lahjoitukset ja ohjata tekoälyn tuottamien taideteosten kaupallista käyttöä.
Tämän taiteellisen kehityksen kynnyksellä tarjoaa polun, joka on täynnä luovaa potentiaalia, mutta vaatii huolellista huoltajuutta. Meidän velvollisuutemme on viljellä maisemaa, jossa tekoälyn ja taiteen fuusio kukoistaa vastuullisten ja kulttuurisesti herkkien käytäntöjen ohjaamana.
Usein kysytyt kysymykset
A. Diffuusiomallit ovat generatiivisia ML-algoritmeja, jotka luovat kuvia aloittamalla satunnaisen kohinan kuviosta ja muokkaamalla siitä vähitellen koherentiksi kuvaksi. Tämä prosessi muistuttaa taiteilijaa, joka aloittaa tyhjästä kankaasta ja lisää hitaasti yksityiskohtia.
V. GANit, diffuusiomallit eivät vaadi erillistä verkkoa tuotoksen arvioimiseksi. Ne toimivat lisäämällä ja poistamalla kohinaa iteratiivisesti, mikä usein johtaa yksityiskohtaisempiin ja vivahteikampiin kuviin.
V. Kyllä, diffuusiomallit voivat luoda alkuperäisiä taideteoksia oppimalla kuvien tietojoukosta. Omaperäisyyteen vaikuttaa kuitenkin koulutusdatan monimuotoisuus ja laajuus. Parhaillaan käydään keskustelua olemassa olevien taideteosten käytön eettisyydestä näiden mallien kouluttamisessa.
A. Eettiset huolenaiheet sisältävät tekoälyn tuottaman taiteen tekijänoikeusrikkomusten välttämisen. Ihmistaiteilijoiden omaperäisyyden kunnioittaminen, ennakkoluulojen jatkumisen estäminen ja tekoälyn luomisprosessin läpinäkyvyyden varmistaminen.
V. Tekoälyn luoman taiteen tulevaisuus näyttää lupaavalta, sillä diffuusiomallit tarjoavat uusia työkaluja taiteilijoille ja tekijöille. Voimme odottaa näkevämme kehittyneempiä ja monimutkaisempia taideteoksia tekniikan kehittyessä. Luovan yhteisön on kuitenkin ohjattava eettisiä näkökohtia ja pyrittävä kohti selkeitä ohjeita ja parhaita käytäntöjä.
Tässä artikkelissa näkyvä media ei ole Analytics Vidhyan omistuksessa, ja sitä käytetään tekijän harkinnan mukaan.
liittyvä
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :On
- :ei
- :missä
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- kyky
- Meistä
- edellä
- TIIVISTELMÄ
- tarkka
- Saavuttaa
- saavuttamisessa
- Aatami
- mukautuva
- lisää
- lisä-
- osoite
- Oikaistu
- kehittynyt
- ennakot
- tulo
- kontradiktorisen
- AI
- ai taide
- kaltainen
- algoritmit
- Kaikki
- Salliminen
- mahdollistaa
- an
- analyyttinen
- Analytics
- Analyysi Vidhya
- ja
- Ilmoittaa
- Hakemus
- arvostaa
- lähestymistapa
- arkkitehtuuri
- OVAT
- Art
- artikkeli
- taiteilija
- taiteellinen
- taiteellisesti
- taiteellisuus
- Taiteilijat
- kuvamateriaali
- taideteokset
- AS
- At
- täydennetty
- lupa
- saatavissa
- väyliä
- välttää
- välttämällä
- AKSELIT
- takaisin
- Huono
- tasapainotus
- perustua
- BE
- tulossa
- Hyödyt
- PARAS
- parhaat käytännöt
- välillä
- Jälkeen
- puolueellisuus
- harhat
- tyhjä
- sekoittaminen
- blogathon
- syntynyt
- sekä
- rajat
- hengittäminen
- täynnä
- Tuo
- laaja
- toi
- orastavaa
- mutta
- by
- laskea
- nimeltään
- CAN
- kangas
- kyvyt
- valmiudet
- kaapata
- haaste
- haasteet
- kanavat
- Kaaos
- ominainen
- tarkastaa
- tarkkailun
- puristin
- selkeys
- luokka
- selkeä
- selkeämpi
- lähempänä
- koodi
- Koodaus
- JOHDONMUKAINEN
- tehdä yhteistyötä
- yhteistyöhön
- väri
- tulee
- kaupallinen
- yhteisö
- kompakti
- yhteensopivuus
- kilpailukykyinen
- täydellinen
- valmistuminen
- monimutkainen
- monimutkaisuus
- komponentti
- koostumus
- laskennallinen
- Laskea
- käsitteet
- käsitteellinen
- huolenaiheet
- konsertti
- päättelee
- Liitännät
- Harkita
- näkökohdat
- sisältää
- pitoisuus
- kontrasti
- maksut
- tavanomainen
- Lähentyminen
- Muuntaminen
- muuntaminen
- konvoluutiohermoverkko
- tekijänoikeus
- tekijänoikeusrikkomus
- Ydin
- lahjoa
- prosessori
- muotoillun
- luoda
- Luominen
- luominen
- Luova
- Luovasti
- luovuus
- luojat
- ratkaiseva
- huipentui
- Viljellä
- kulttuurisesti
- kuratoitu
- käyrä
- asiakassuhde
- sykli
- tanssi
- tiedot
- aineistot
- keskustelu
- syvä
- määrittelemällä
- vaatii
- osoittivat
- syvyys
- syvyydet
- johdettu
- nimetty
- yksityiskohta
- yksityiskohtainen
- yksityiskohdat
- kehittäjille
- laite
- erota
- ero
- eri
- Diffuusio
- digitaalinen
- digitaalinen taide
- digitaalisesti
- Ulottuvuus
- mitat
- harkinnan
- näyttö
- näyttämällä
- selvä
- ero
- useat
- Monimuotoisuus
- do
- ei
- ovet
- piirtää
- Piirustukset
- aikana
- dynaaminen
- dynaamisesti
- dynamiikka
- e
- kukin
- kaiku
- kaikuja
- vaikutukset
- Kehittää
- muu
- syntyy
- koodattu
- käsittää
- kattaa
- Tekniikka
- tehostettu
- varmistaa
- varmistaa
- varmistamalla
- Koko
- ympäristö
- aikakausi
- aikakausia
- Aikakausi
- virhe
- ydin
- olennainen
- perustaminen
- Eetteri (ETH)
- eettinen
- etiikka
- arviointi
- Joka
- evoluutio
- kehittää
- kehittynyt
- kehittyy
- tutkimus
- kunnostautua
- Paitsi
- olemassa
- Laajentaa
- laaja
- odottaa
- tutkimus
- tutkia
- lauseke
- laajennettu
- laaja
- silmä
- katse
- kasvohoito
- luotettava
- väärä
- tuttu
- lumoava
- Ominaisuudet
- Featuring
- tarkkuus
- Kuva
- filee
- Asiakirjat
- lopullinen
- viimeistely
- Etunimi
- Keskittää
- jälkeen
- varten
- eturintamassa
- Eteenpäin
- Edistää
- edistäminen
- Puitteet
- puitteet
- alkaen
- täysin
- toiminto
- toiminnallinen
- perus-
- edelleen
- fuusio
- tulevaisuutta
- Saada
- GAN
- keräys
- antoi
- tuottaa
- syntyy
- tuottaa
- sukupolvi
- generatiivinen
- generatiiviset vastakkaiset verkot
- Generatiivinen AI
- generaattorit
- Antaa
- tavoite
- GPU
- kaltevuudet
- vähitellen
- suuruusluokka
- ymmärtää
- suurempi
- uraauurtava
- opastettu
- suuntaviivat
- Oppaat
- käsi
- valjastaminen
- sydän
- tätä
- Piilottaa
- raidat
- historiallinen
- pito
- kunnianosoitus
- kunnia
- Miten
- Kuitenkin
- HTTPS
- ihmisen
- i
- ajatus
- if
- syttyy
- kuva
- kuvien
- mielikuvitus
- imperatiivi
- täytäntöönpanosta
- vaikutukset
- tuoda
- tärkeä
- parantaa
- in
- sisältää
- täydellinen
- Osallisuus
- sisällyttää
- kasvoi
- inkrementaalinen
- vakiintuneet
- vaikutus
- vaikuttaneet
- rikkominen
- nerokkuus
- innovoida
- Innovaatio
- panos
- tuloa
- tietoa
- kiinteä
- Integrointi
- eheys
- henkinen
- tekijänoikeuksien
- korko
- tulkinta
- tulee
- monimutkainen
- esitellä
- intuitio
- osallistuva
- kysymykset
- IT
- iteraatio
- toistojen
- SEN
- matka
- jpg
- tuomari
- Lack
- Landschaft
- kerros
- kerrokset
- oppinut
- oppiminen
- juridinen
- oikeudellinen kehys
- lainsäädäntö
- Linssi
- piilee
- elämä
- valo
- pitää
- lastaus
- ulkonäkö
- pois
- tappiot
- kone
- koneoppiminen
- ylläpitää
- ihme
- mestariteos
- ottelu
- materiaali
- matplotlib
- tarkoittaa
- mekanismi
- mekanismit
- Media
- vain
- sulautuvan
- menetelmä
- järjestelmällinen
- metrinen
- minimoida
- minuutti
- peilaus
- ML
- ML-algoritmit
- tila
- malli
- mallit
- Moderni
- moduuli
- lisää
- liikkua
- paljon
- MUSE
- täytyy
- nimet
- orastava
- luonto
- Navigoida
- välttämätön
- tarpeet
- verkko
- verkot
- hermo-
- Hermotekniikka
- neuroverkkomallien
- hermoverkkoihin
- Uusi
- Melu
- huomata
- romaani
- nyt
- vivahteet
- tarkkailla
- Havaittu
- of
- pois
- hyökkäys
- kampanja
- tarjoamalla
- Tarjoukset
- usein
- on
- jatkuva
- vain
- avautuu
- Optimoida
- or
- alkuperäinen
- omaperäisyys
- Originals
- OS
- Muut
- meidän
- ulos
- ulostulo
- lähdöt
- yli
- omistuksessa
- maalaus
- maalauksia
- parametri
- parametrit
- osa
- osapuolet
- kulkea
- Ohi
- polku
- Kuvio
- kuviot
- havainto
- parantamassa
- suorittaa
- näkökulmia
- kuva
- kappale
- kappaletta
- Platforms
- Platon
- Platonin tietotieto
- PlatonData
- muotokuvia
- mahdollinen
- käytännöt
- Tarkkuus
- alustava
- esittää
- lahjat
- säilöntä
- estää
- estää
- periaatteet
- tulostus
- priorisointi
- prosessi
- jalostettu
- tuottavat
- Tuotteet
- Profiili
- syvällinen
- Edistyminen
- eteneminen
- asteittain
- lupaava
- Edistäminen
- ohjeita
- eteneminen
- asianmukainen
- omaisuus
- suojella
- suojattu
- alkuperä
- tarjoamalla
- julkaistu
- jatkaa
- pytorch
- määrää
- satunnainen
- satunnaisuuden
- alue
- hinta
- valmis
- valtakunta
- tunnistaa
- uudelleenmäärittely
- tarkentaa
- puhdistettu
- heijastava
- heijastaa
- järjestelmä
- säännöllinen
- yhteys
- poistamalla
- mallinnus
- replikointi
- edustus
- edustaa
- lisääntyminen
- edellyttää
- Vaatii
- muistuttavia
- muokkaamaan
- kunnioittaminen
- kunnioittaen
- vastuullinen
- vastuullisesti
- Saatu ja
- palata
- ilmestys
- Elvyttää
- mullistaa
- RGB
- Rikas
- oikeudet
- Nousta
- luja
- Rooli
- sama
- tallennettu
- tallentaa
- kohtaus
- tiede
- laajuus
- käsikirjoitus
- nähdä
- SELF
- sensible
- erillinen
- Järjestys
- palvelee
- setti
- asetus
- setup
- useat
- varjo
- muotoiluun
- siirtää
- Vuorot
- shouldnt
- näyteikkuna
- esittelylle
- esitetty
- merkittävä
- koska
- Hitaasti
- pätkä
- So
- hienostunut
- Sielu
- lähde
- hankitaan
- Tila
- jännitys
- erityisesti
- spektri
- Squared
- vakaa
- Vaihe
- seistä
- Aloita
- tilastollinen
- tasainen
- Vaihe
- Strategia
- pyrkimys
- rakenne
- Upea
- tyyli
- aihe
- myöhempi
- niin
- Symbioottinen
- synergistinen
- synteesi
- synteettinen
- Räätälöity
- vie
- ottaen
- Kohde
- Tekninen
- tekniikat
- teknologinen
- Technologies
- Elektroniikka
- tensorflow
- testamentti
- että
- -
- Tulevaisuus
- Lähde
- heidän
- Niitä
- Siellä.
- Nämä
- ne
- tätä
- viihtyy
- Kautta
- Näin
- että
- työkalut
- taskulamppu
- Torchvision
- kosketa
- kohti
- Seuranta
- perinteinen
- Juna
- koulutettu
- koulutus
- Muuttaa
- Muutos
- muunnokset
- transformatiivinen
- transformoitu
- muuttamassa
- muunnoksia
- Läpinäkyvyys
- totta
- yrittää
- ymmärtää
- ymmärtäminen
- unique
- asti
- Esittelee
- päivittäminen
- päälle
- us
- käyttää
- käytetty
- käyttämällä
- hyödyllisyys
- pätevä
- tarkastaa
- kautta
- katselu
- näkökulmia
- visio
- visuaalinen
- visuaalinen taide
- visualisointi
- havainnollistaa
- visuaalisesti
- elintärkeä
- oli
- we
- WebP
- Mitä
- Mikä on
- joka
- vaikka
- Kuiskaus
- KUKA
- leveä
- Laaja valikoima
- tulee
- ikkuna
- with
- sisällä
- ilman
- Referenssit
- toimii
- maailman-
- X
- Joo
- vielä
- te
- zephyrnet
- nolla-