Samalla kun OpenAI ChatGPT imee kaiken hapen 24 tunnin uutiskierrosta, Google on hiljaa julkistanut uuden tekoälymallin, joka voi luoda videoita, kun sille annetaan video-, kuva- ja tekstisyötteitä. Uusi Google Dreamix AI -videoeditori tuo nyt luodut videot lähemmäs todellisuutta.
GitHubissa julkaistun tutkimuksen mukaan Dreamix editoi videon videon ja tekstikehotteen perusteella. Tuloksena oleva video säilyttää uskollisuuden värin, asennon, kohteen koon ja kameran asennon suhteen, mikä johtaa ajallisesti yhtenäiseen videoon. Tällä hetkellä Dreamix ei voi luoda videoita pelkästä kehotteesta, mutta se voi ottaa olemassa olevan materiaalin ja muokata videota tekstikehotteilla.
Google käyttää videon diffuusiomalleja Dreamixille, lähestymistapaa, jota on menestyksekkäästi sovellettu useimpiin videokuvan muokkauksiin, joita näemme kuvan tekoälyissä, kuten DALL-E2 tai avoimen lähdekoodin Stable Diffusion.
Lähestymistapaan kuuluu syötevideon voimakas vähentäminen, keinotekoisen kohinan lisääminen ja sen käsittely videon diffuusiomallissa, joka sitten luo tekstikehotteen avulla uuden videon, joka säilyttää jotkin alkuperäisen videon ominaisuudet ja hahmontaa toiset uudelleen. tekstinsyöttöön.
Videon diffuusiomalli tarjoaa lupaavan tulevaisuuden, joka voi aloittaa uuden aikakauden videoiden parissa työskentelemiselle.

Esimerkiksi alla olevassa videossa Dreamix muuttaa syövän apinan (vasemmalla) tanssivaksi karhuksi (oikealla), kun annetaan kehote "Karhu tanssii ja hyppää pirteän musiikin tahtiin, liikuttaa koko kehoaan."
Toisessa alla olevassa esimerkissä Dreamix käyttää yhtä valokuvaa mallina (kuten kuvasta videoon) ja sitten objekti animoidaan siitä videossa kehotteen avulla. Kameran liikkeet ovat mahdollisia myös uudessa kohtauksessa tai myöhemmässä time-lapse-tallennuksessa.
Toisessa esimerkissä Dreamix muuttaa orangutanin vesialtaassa (vasemmalla) orangutaniksi, jolla on oranssit hiukset kylpemässä kauniissa kylpyhuoneessa.
”Kuvan editoinnissa on käytetty onnistuneesti diffuusiomalleja, mutta videoeditointiin niin harvat työt ovat tehneet niin. Esittelemme ensimmäisen diffuusiopohjaisen menetelmän, joka pystyy suorittamaan yleisten videoiden tekstipohjaista liike- ja ulkoasueditointia.
Googlen tutkimuspaperin mukaan Dreamix käyttää videon diffuusiomallia yhdistääkseen päättelyhetkellä alkuperäisen videon matalaresoluutioiset spatiotemporaaliset tiedot uuteen, korkearesoluutioiseen tietoon, jonka se on syntetisoinut linjatakseen ohjaavan tekstikehotteen.
Google sanoi käyttävänsä tätä lähestymistapaa, koska "alkuperäisen videon korkean tarkkuuden saaminen edellyttää osan sen korkearesoluutioisista tiedoista säilyttämistä. Lisäämme alkuperäiseen videoon mallin alustavan hienosäädön, mikä parantaa huomattavasti tarkkuutta."
Alla on videokatsaus Dreamixin toiminnasta.
[Upotetun sisällön]
Kuinka Dreamix-videon diffuusiomallit toimivat
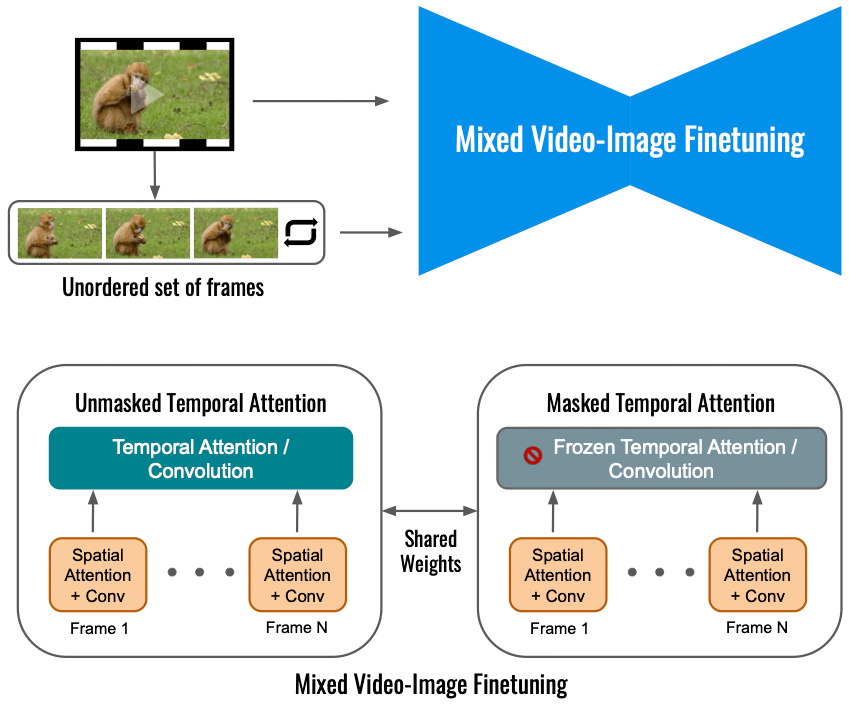
Googlen mukaan Dreamixin videon diffuusiomallin hienosäätö pelkästään tulovideossa rajoittaa liikkeen muutoksen laajuutta. Sen sijaan käytämme sekaobjektiivia, joka hienosäätää alkuperäisen objektiivin (alhaalla vasemmalla) lisäksi myös järjestämättömän kehysjoukon. Tämä tehdään käyttämällä "naamioitua ajallista huomiota", mikä estää ajallisen huomion ja konvoluution hienosäädön (alhaalla oikealla). Tämä mahdollistaa liikkeen lisäämisen staattiseen videoon.
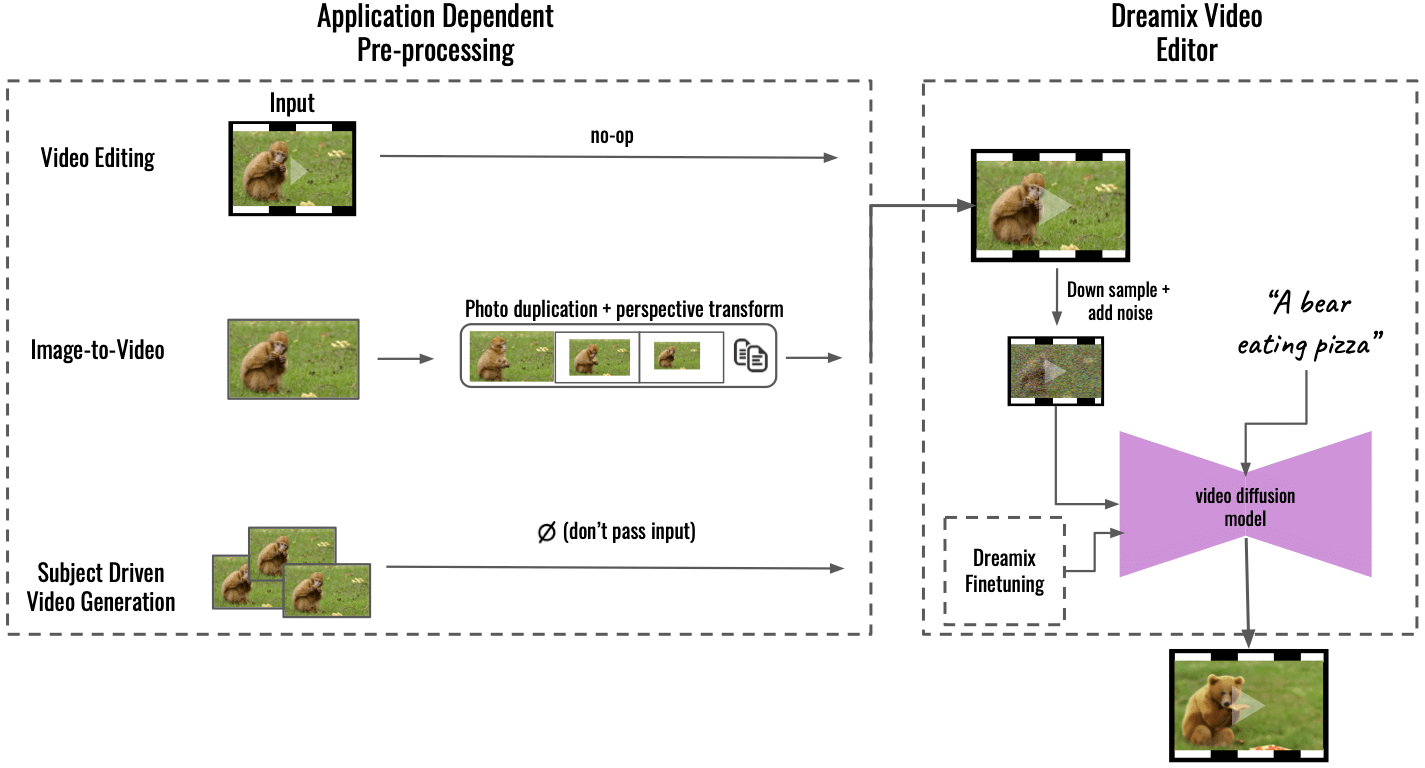
”Menetelmämme tukee useita sovelluksia sovelluskohtaisella esikäsittelyllä (vasemmalla), joka muuntaa syötetyn sisällön yhtenäiseen videomuotoon. Kuvasta videoksi tulokuva monistetaan ja muunnetaan käyttämällä perspektiivimuunnoksia, jolloin syntetisoidaan karkea video jollakin kameran liikkeellä. Aihelähtöisen videon luonnissa syöttö jätetään pois – pelkkä hienosäätö huolehtii tarkkuudesta. Tätä karkeaa videota muokataan sitten yleisellä "Dreamix-videoeditorillamme" (oikealla): ensin korruptoimme videon alasnäytteistyksellä, minkä jälkeen lisäämme kohinaa. Käytämme sitten hienosäädettyä tekstiohjattua videon diffuusiomallia, joka skaalaa videon lopulliseen spatiotemporaaliseen resoluutioon", Dream kirjoitti GitHub.
Voit lukea tutkimuspaperin alta.
Google Dreamix- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- Platoblockchain. Web3 Metaverse Intelligence. Tietoa laajennettu. Pääsy tästä.
- Lähde: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- pystyy
- Mukaan
- AI
- ai video
- AI-käyttöinen
- Kaikki
- mahdollistaa
- yksin
- ja
- Toinen
- sovellukset
- sovellettu
- käyttää
- lähestymistapa
- keinotekoinen
- huomio
- perustua
- Bear
- kaunis
- koska
- ovat
- alle
- elin
- lisäämällä
- pohja
- Tuo
- kamera
- ei voi
- joka
- muuttaa
- ChatGPT
- lähempänä
- väri
- yhdistää
- johdonmukainen
- pitoisuus
- Luominen
- sykli
- tanssi
- Diffuusio
- unelma
- toimittaja
- upotettu
- Aikakausi
- esimerkki
- olemassa
- harvat
- tarkkuus
- lopullinen
- Etunimi
- seurannut
- muoto
- alkaen
- tulevaisuutta
- general
- tuottaa
- syntyy
- sukupolvi
- gif
- GitHub
- tietty
- Hiukset
- raskaasti
- korkea resoluutio
- Miten
- Kuitenkin
- HTTPS
- kuva
- kuvien
- in
- tiedot
- panos
- sen sijaan
- IT
- käynnistää
- rajat
- ylläpitää
- materiaali
- max
- menetelmä
- sekoitettu
- malli
- mallit
- muokata
- hetki
- eniten
- liike
- liikkeet
- liikkuvat
- moninkertainen
- Musiikki
- Uusi
- uutiset
- Melu
- objekti
- tavoite
- Tarjoukset
- avoimen lähdekoodin
- OpenAI
- Oranssi
- alkuperäinen
- Muuta
- yleiskatsaus
- Happi
- Paperi
- suorittaa
- näkökulma
- Platon
- Platonin tietotieto
- PlatonData
- pool
- mahdollinen
- esittää
- estää
- käsittely
- lupaava
- ominaisuudet
- julkaistu
- hiljaa
- Lue
- Todellisuus
- äänitys
- vähentämällä
- Vaatii
- tutkimus
- päätöslauselma
- Saatu ja
- säilyttäen
- Said
- kohtaus
- setti
- merkittävästi
- single
- Koko
- So
- jonkin verran
- vakaa
- Vaihe
- myöhempi
- Onnistuneesti
- niin
- Tukee
- ottaa
- sapluuna
- -
- aika
- että
- muunnokset
- transformoitu
- paljastettiin
- käyttää
- kautta
- Video
- Videoita
- vesi
- joka
- työskentely
- toimii
- youtube
- zephyrnet











