Monet pienet ja suuret organisaatiot pyrkivät siirtämään ja modernisoimaan analytiikkatyökuormiaan Amazon Web Servicesissä (AWS). Asiakkailla on monia syitä siirtyä AWS:ään, mutta yksi tärkeimmistä syistä on kyky käyttää täysin hallittuja palveluita sen sijaan, että kuluttaisit aikaa infrastruktuurin ylläpitoon, korjauksiin, valvontaan, varmuuskopiointiin ja muihin. Johto- ja kehitystiimit voivat käyttää enemmän aikaa nykyisten ratkaisujen optimointiin ja jopa uusien käyttötapojen kokeilemiseen nykyisen infrastruktuurin ylläpitämisen sijaan.
Koska pystyt liikkumaan nopeasti AWS:ssä, sinun on myös oltava vastuussa vastaanottamistasi ja käsittelemistäsi tiedoista, kun jatkat skaalausta. Näihin velvollisuuksiin kuuluu tietosuojalakien ja -määräysten noudattaminen ja arkaluonteisten tietojen, kuten henkilökohtaisten tunnistetietojen (PII) tai suojattujen terveystietojen (PHI) säilyttäminen tai paljastaminen alkupään lähteistä.
Tässä viestissä käymme läpi korkean tason arkkitehtuurin ja erityisen käyttötapauksen, joka osoittaa, kuinka voit jatkaa organisaatiosi tietoalustan skaalaamista ilman, että sinun tarvitsee käyttää suuria määriä kehitysaikaa tietosuojaongelmien ratkaisemiseen. Käytämme AWS-liima tunnistaa, peittää ja poistaa henkilökohtaisia tunnistetietoja ennen niiden lataamista Amazon OpenSearch-palvelu.
Ratkaisun yleiskatsaus
Seuraava kaavio havainnollistaa korkean tason ratkaisuarkkitehtuuria. Olemme määrittäneet suunnittelumme kaikki tasot ja komponentit noudattaen Hyvin suunniteltu AWS Framework Data Analytics -linssi.
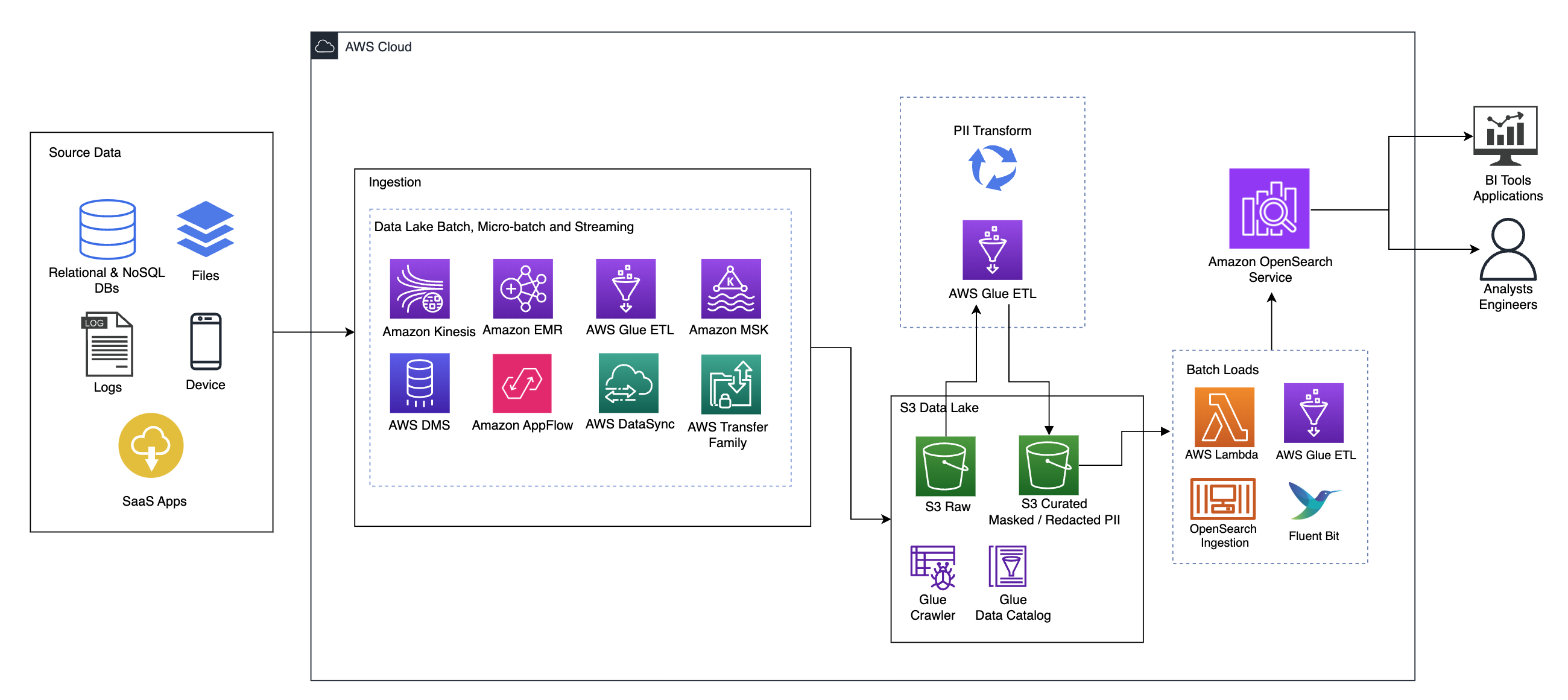
Arkkitehtuuri koostuu useista osista:
Lähdetiedot
Tiedot voivat tulla useista kymmenistä satoihin lähteistä, mukaan lukien tietokannat, tiedostonsiirrot, lokit, ohjelmistot palveluna (SaaS) -sovellukset ja paljon muuta. Organisaatiot eivät välttämättä pysty aina hallitsemaan sitä, mitä dataa tulee näiden kanavien kautta niiden myöhempään tallennustilaan ja sovelluksiin.
Nieleminen: Data Lake -erä, mikroerä ja suoratoisto
Monet organisaatiot siirtävät lähdetietonsa tietojärveensä eri tavoilla, mukaan lukien erä-, mikro-erä- ja suoratoistotyöt. Esimerkiksi, Amazonin EMR, AWS-liimaja AWS -tietokannan siirtopalvelu (AWS DMS) voidaan käyttää erä- ja/tai suoratoistotoimintojen suorittamiseen, jotka uppoavat datajärveen Amazonin yksinkertainen tallennuspalvelu (Amazon S3). Amazon App Flow voidaan käyttää datan siirtämiseen eri SaaS-sovelluksista datajärveen. AWS DataSync ja AWS-siirtoperhe voi auttaa tiedostojen siirtämisessä datajärvelle ja sieltä useiden eri protokollien kautta. Amazon kinesis ja Amazon MSK pystyvät myös suoratoistamaan dataa suoraan Amazon S3:n datajärveen.
S3 datajärvi
Amazon S3:n käyttäminen datajärvelläsi on nykyaikaisen datastrategian mukaista. Se tarjoaa edullista tallennustilaa suorituskyvystä, luotettavuudesta tai saatavuudesta tinkimättä. Tällä lähestymistavalla voit tuoda laskentaa tietoihisi tarpeen mukaan ja maksaa vain kapasiteetista, jota se tarvitsee toimiakseen.
Tässä arkkitehtuurissa raakadata voi olla peräisin useista lähteistä (sisäisistä ja ulkoisista), jotka voivat sisältää arkaluontoisia tietoja.
AWS Glue -indeksointirobottien avulla voimme löytää ja luetteloida tiedot, jotka muodostavat taulukkokaaviot puolestamme. Lopulta AWS Glue ETL:n käyttäminen PII-muunnoksen kanssa on helppoa havaita ja peittää tai poistaa kaikki mahdollisesti saapuneet arkaluontoiset tiedot. datajärvessä.
Liiketoimintakonteksti ja tietojoukot
Osoittaaksemme lähestymistapamme arvon oletetaan, että olet osa rahoituspalveluorganisaation tietotekniikkatiimiä. Vaatimuksenne on havaita ja peittää arkaluontoiset tiedot, kun ne siirretään organisaatiosi pilviympäristöön. Tiedot kulutetaan loppupään analyyttisiin prosesseihin. Jatkossa käyttäjäsi voivat etsiä historiallisia maksutapahtumia turvallisesti sisäisistä pankkijärjestelmistä kerättyjen tietovirtojen perusteella. Käyttötiimien, asiakkaiden ja liitäntäsovellusten hakutulokset on piilotettava arkaluontoisiin kenttiin.
Seuraavassa taulukossa on esitetty ratkaisussa käytetty tietorakenne. Selvyyden vuoksi olemme yhdistäneet raaka-aineet kuratoituihin sarakkeiden nimiin. Huomaat, että useita tämän mallin kenttiä pidetään arkaluontoisina tiedoina, kuten etunimi, sukunimi, sosiaaliturvatunnus (SSN), osoite, luottokortin numero, puhelinnumero, sähköpostiosoite ja IPv4-osoite.
| Raaka sarakkeen nimi | Kuroidun sarakkeen nimi | Tyyppi |
| c0 | etunimi | jono |
| c1 | sukunimi | jono |
| c2 | ssn | jono |
| c3 | osoite | jono |
| c4 | postinumero | jono |
| c5 | maa | jono |
| c6 | ostosivusto | jono |
| c7 | luottokortin numero | jono |
| c8 | credit_card_provider | jono |
| c9 | valuutta | jono |
| c10 | osto_arvo | kokonaisluku |
| c11 | tapahtuman_päivämäärä | data |
| c12 | puhelinnumero | jono |
| c13 | jono | |
| c14 | ipv4 | jono |
Käyttötapaus: PII-erän tunnistus ennen lataamista OpenSearch-palveluun
Asiakkaat, jotka ottavat käyttöön seuraavan arkkitehtuurin, ovat rakentaneet datajärvensä Amazon S3:lle erityyppisten analytiikan suorittamiseksi mittakaavassa. Tämä ratkaisu sopii asiakkaille, jotka eivät vaadi reaaliaikaista pääsyä OpenSearch-palveluun ja aikovat käyttää datan integrointityökaluja, jotka toimivat aikataulussa tai tapahtumien kautta.
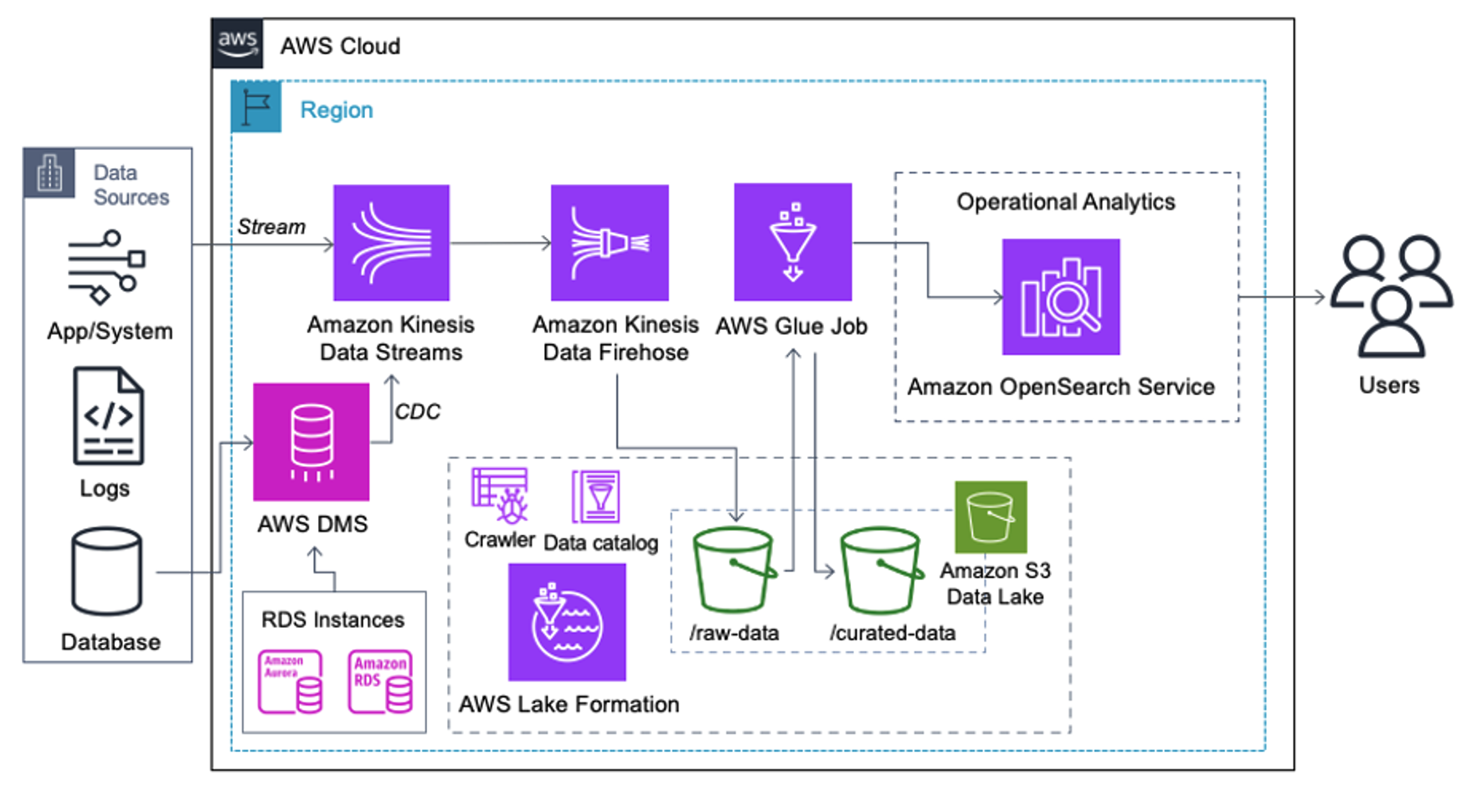
Ennen kuin tietueet laskeutuvat Amazon S3:lle, otamme käyttöön käsittelykerroksen tuodaksemme kaikki tietovirrat luotettavasti ja turvallisesti datajärveen. Kinesis Data Streamsia käytetään sisäänottokerroksena strukturoitujen ja puolistrukturoitujen tietovirtojen nopeutettuun vastaanottamiseen. Esimerkkejä näistä ovat relaatiotietokantamuutokset, sovellukset, järjestelmälokit tai napsautusvirrat. Muutostietojen kaappauksen (CDC) käyttötapauksissa voit käyttää Kinesis Data Streamsiä AWS DMS:n kohteena. Arkaluontoisia tietoja sisältäviä virtoja luovat sovellukset tai järjestelmät lähetetään Kinesis-tietovirtaan jollakin kolmesta tuetuista tavoista: Amazon Kinesis Agent, AWS SDK for Java tai Kinesis Producer Library. Viimeisenä askeleena Amazon Kinesis Data Firehose auttaa meitä lataamaan luotettavasti lähes reaaliaikaisia tietoeriä S3-datajärven kohteeseen.
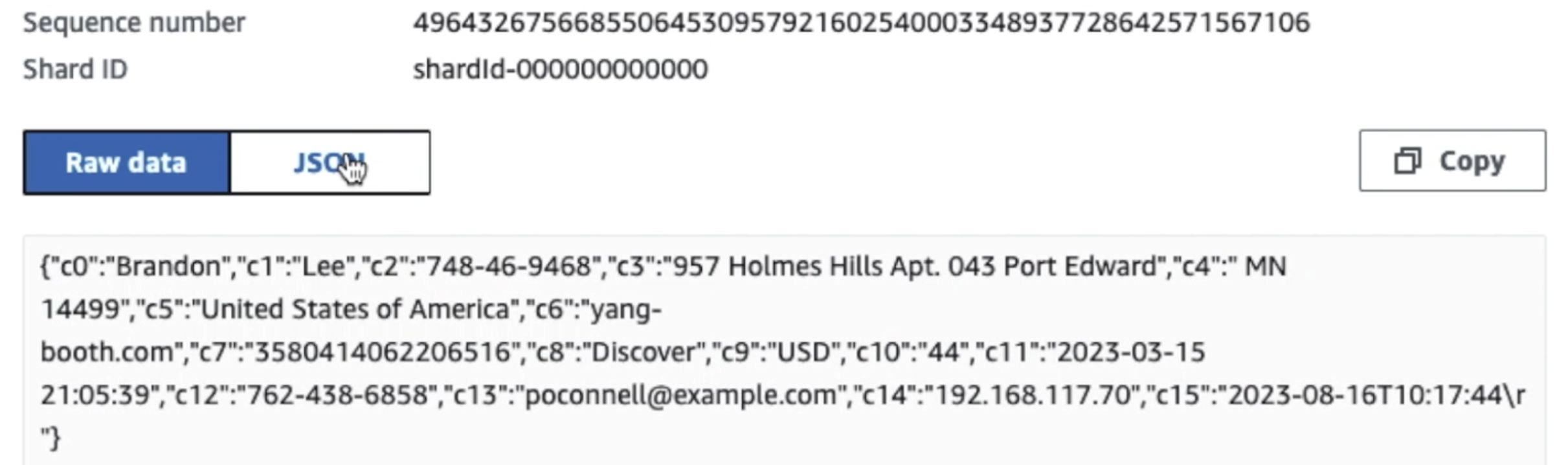
Seuraava kuvakaappaus näyttää, kuinka tiedot kulkevat Kinesis-datavirtojen läpi Data Viewer ja hakee näytetiedot, jotka laskeutuvat raaka S3-etuliitteelle. Tässä arkkitehtuurissa noudatimme S3-etuliitteille annettua tietojen elinkaarta, kuten kohdassa suositellaan Datajärven perustus.
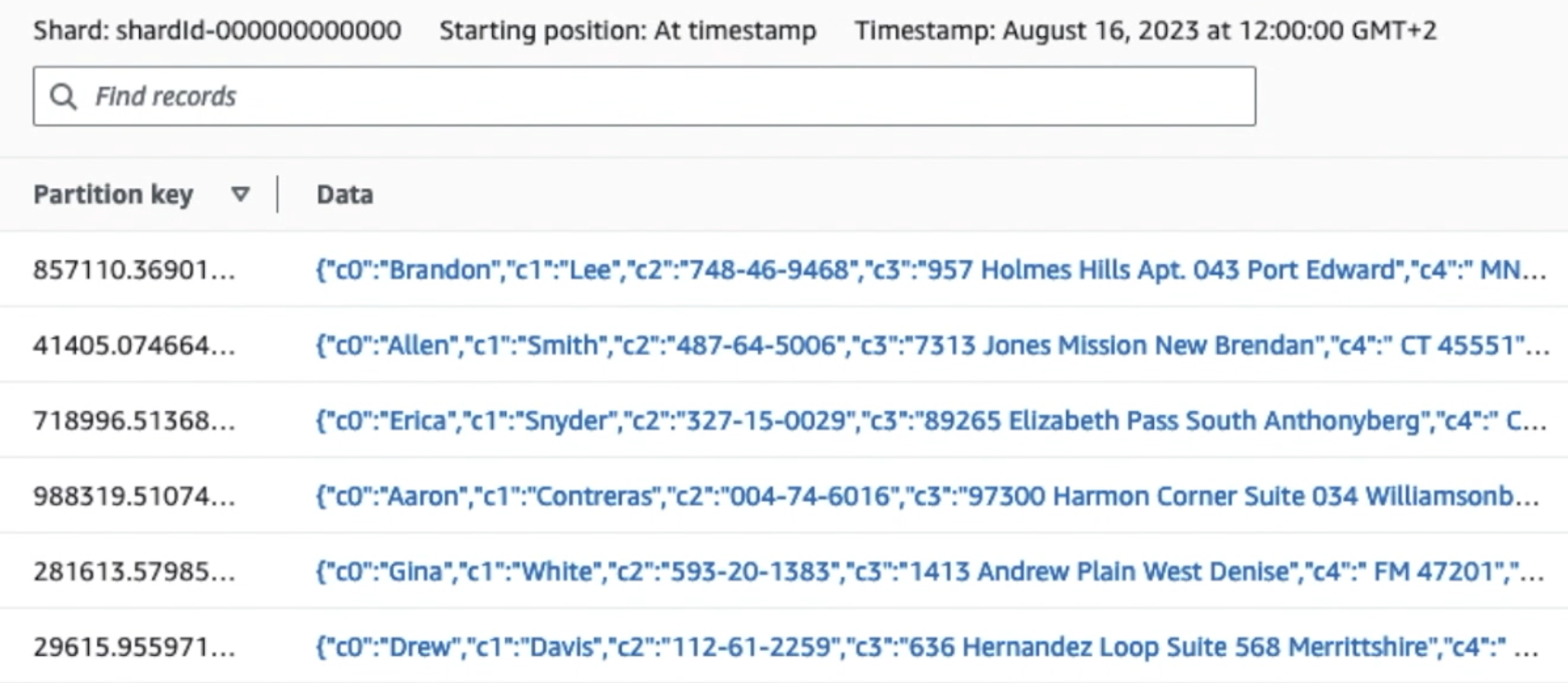
Kuten seuraavan kuvakaappauksen ensimmäisen tietueen tiedoista näkyy, JSON-hyötykuorma noudattaa samaa kaavaa kuin edellisessä osassa. Näet muokkaamattomien tietojen virtaavan Kinesis-tietovirtaan, joka hämärtyy myöhemmin seuraavissa vaiheissa.
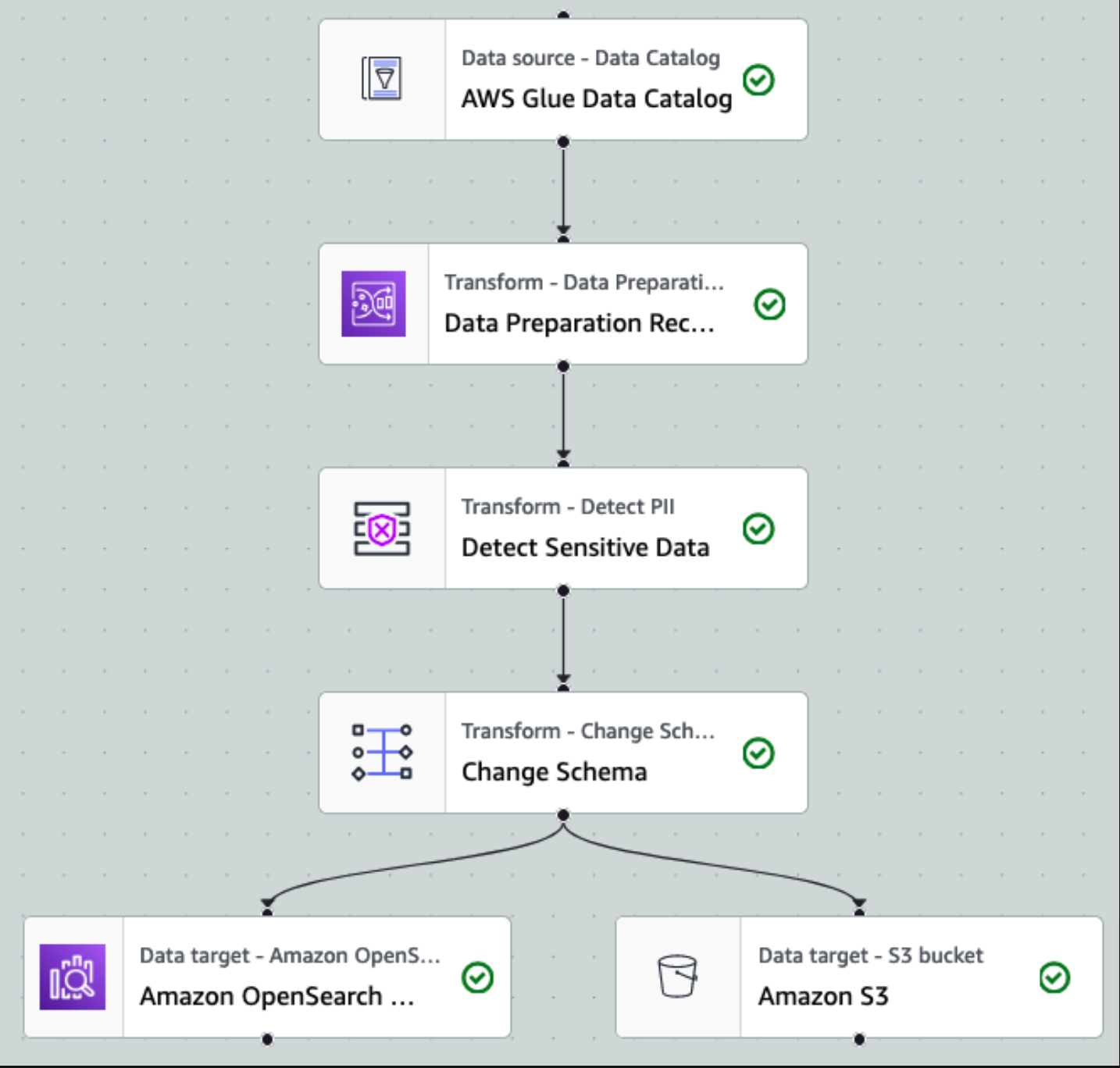
Kun tiedot on kerätty ja syötetty Kinesis Data Streamsiin ja toimitettu S3-ämpäriin Kinesis Data Firehosen avulla, arkkitehtuurin käsittelykerros ottaa vallan. Käytämme AWS Glue PII -muunnosta automatisoidaksemme arkaluonteisten tietojen havaitsemisen ja peittämisen prosessissamme. Kuten seuraavasta työnkulkukaaviosta käy ilmi, otimme koodittoman visuaalisen ETL-lähestymistavan toteuttaaksemme muunnostyömme AWS Glue Studiossa.
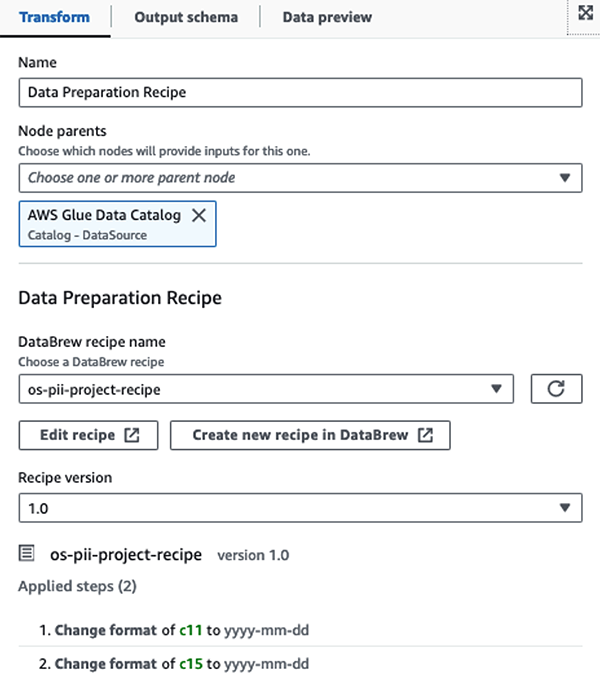
Ensin pääsemme lähdetietokatalogitaulukkoon raakana osoitteesta pii_data_db tietokanta. Taulukossa on edellisessä osiossa esitetty skeemarakenne. Raakakäsiteltyjen tietojen seuraamiseksi käytimme työn kirjanmerkit.

Käytämme AWS Glue DataBrew -reseptit AWS Glue Studion visuaalisessa ETL-työssä muuttaa kaksi päivämääräattribuuttia yhteensopivaksi OpenSearchin kanssa formaatit. Tämä mahdollistaa täydellisen koodittoman kokemuksen.
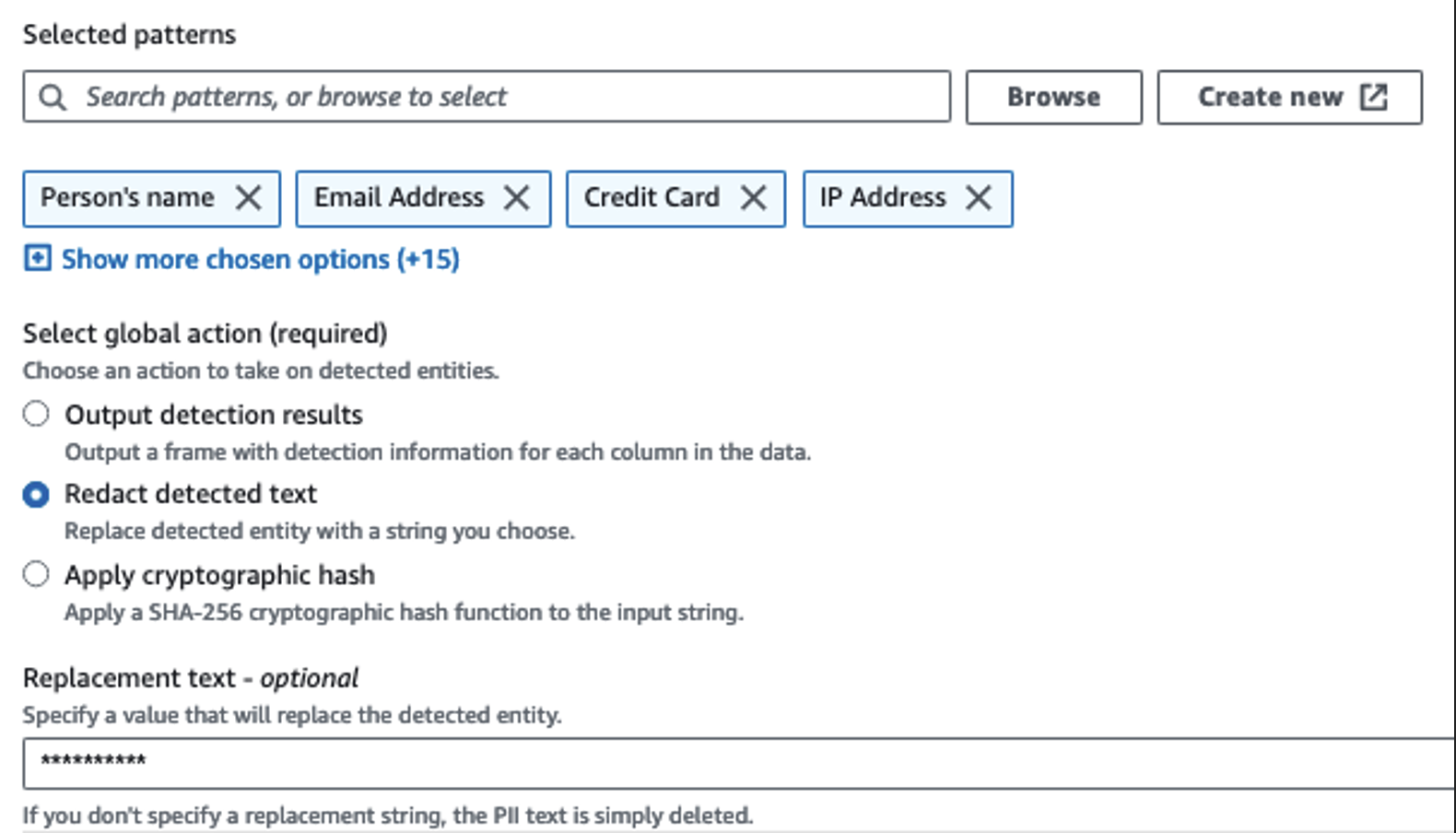
Tunnistamme arkaluontoiset sarakkeet Tunnista PII -toiminnolla. Annetaan AWS Gluen määrittää tämä valittujen mallien, tunnistuskynnyksen ja tietojoukon rivien näyteosuuden perusteella. Esimerkissämme käytimme malleja, jotka koskevat erityisesti Yhdysvaltoja (kuten SSN-numeroita), eivätkä välttämättä havaitse arkaluonteisia tietoja muista maista. Voit etsiä käytettävissä olevia luokkia ja sijainteja käyttötapauksiisi tai käyttää säännöllisiä lausekkeita (regex) AWS Gluessa luodaksesi tunnistuskokonaisuuksia muista maista peräisin oleville arkaluonteisille tiedoille.
On tärkeää valita oikea näytteenottomenetelmä, jonka AWS Glue tarjoaa. Tässä esimerkissä tiedetään, että virrasta tulevassa datassa on arkaluontoisia tietoja jokaisella rivillä, joten tietojoukon riveistä ei tarvitse ottaa 100 %:a. Jos sinulla on vaatimus, jonka mukaan arkaluontoisia tietoja ei sallita myöhempien lähteiden lähteisiin, harkitse 100 %:n näytteenottoa valitsemiesi mallien tiedoista tai skannaa koko tietojoukko ja toimi jokaisessa yksittäisessä solussa varmistaaksesi, että kaikki arkaluontoiset tiedot havaitaan. Näytteenoton hyöty on alemmat kustannukset, koska sinun ei tarvitse skannata niin paljon tietoja.

Tunnista PII -toiminnon avulla voit valita oletusmerkkijonon, kun arkaluontoiset tiedot peitetään. Esimerkissämme käytämme merkkijonoa **********.
Käytämme Apply Mapping -toimintoa tarpeettomien sarakkeiden nimeämiseen ja poistamiseen, kuten ingestion_year, ingestion_monthja ingestion_day. Tämän vaiheen avulla voimme myös muuttaa yhden sarakkeen tietotyyppiä (purchase_value) merkkijonosta kokonaislukuun.

Tästä eteenpäin työ jakautuu kahteen tulostuskohteeseen: OpenSearch Service ja Amazon S3.
Tarjottu OpenSearch-palveluklusterimme on yhdistetty kautta OpenSearchin sisäänrakennettu liitin Gluelle. Määritämme OpenSearch-hakemiston, johon haluamme kirjoittaa, ja liitin käsittelee tunnistetiedot, verkkotunnuksen ja portin. Alla olevassa kuvakaappauksessa kirjoitamme määritettyyn hakemistoon index_os_pii.
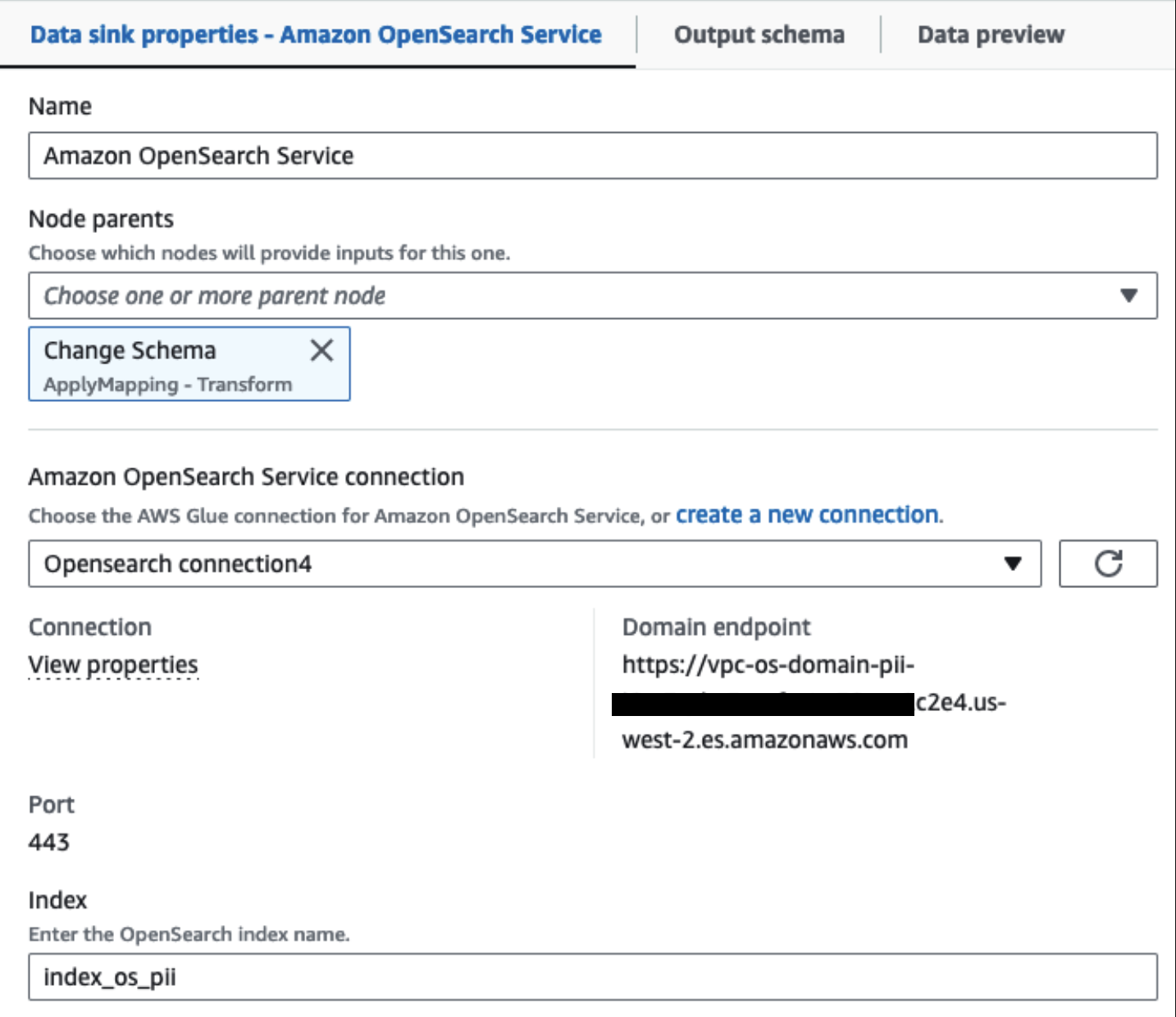
Tallennamme maskatun tietojoukon kuratoituun S3-etuliitteeseen. Siellä meillä on dataa, joka on normalisoitu tiettyyn käyttötapaukseen ja datatutkijoiden turvalliseen kulutukseen tai tapauskohtaisiin raportointitarpeisiin.
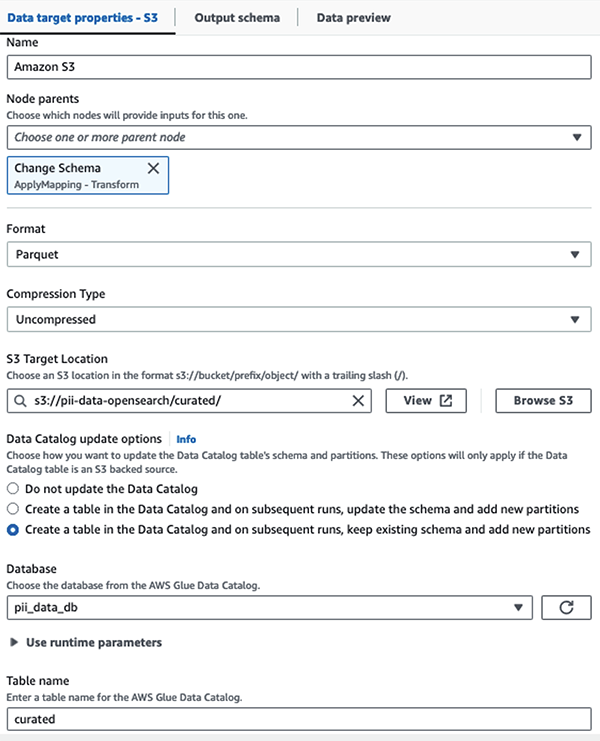
Voit käyttää kaikkien tietojoukkojen ja tietokatalogitaulukoiden yhtenäistä hallintaa, kulunvalvontaa ja kirjausketjuja AWS-järvien muodostuminen. Tämä auttaa sinua rajoittamaan pääsyn AWS Glue Data Catalog -taulukoihin ja niiden taustalla oleviin tietoihin vain niille käyttäjille ja rooleille, joille on myönnetty tarvittavat käyttöoikeudet.
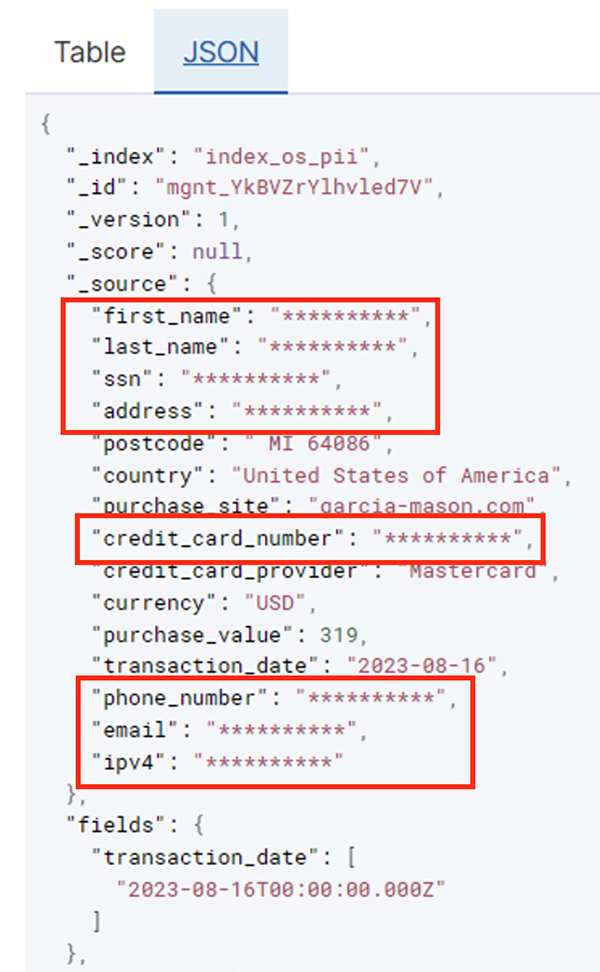
Kun erätyö on suoritettu onnistuneesti, voit käyttää OpenSearch Serviceä hakukyselyjen tai raporttien suorittamiseen. Kuten seuraavassa kuvakaappauksessa näkyy, liukuhihna peitti arkaluontoiset kentät automaattisesti ilman koodin kehitystyötä.

Voit tunnistaa trendit operatiivisista tiedoista, kuten luottokortin tarjoajan suodattamien tapahtumien määrä päivässä, kuten edellisessä kuvakaappauksessa näkyy. Voit myös määrittää sijainnit ja verkkotunnukset, joissa käyttäjät tekevät ostoksia. The transaction_date attribuutti auttaa meitä näkemään nämä trendit ajan mittaan. Seuraava kuvakaappaus näyttää tietueen, jossa kaikki tapahtuman tiedot on muokattu asianmukaisesti.
Katso vaihtoehtoiset menetelmät tietojen lataamiseen Amazon OpenSearchiin Ladataan suoratoistodataa Amazon OpenSearch Serviceen.
Lisäksi arkaluonteisia tietoja voidaan löytää ja peittää myös muilla AWS-ratkaisuilla. Voit esimerkiksi käyttää Amazon Macie tunnistaa arkaluontoiset tiedot S3-ämpäriin ja käyttää sitten Amazonin käsitys poistaaksesi havaitut arkaluontoiset tiedot. Lisätietoja on kohdassa Yleisiä tekniikoita PHI- ja PII-tietojen havaitsemiseen AWS-palveluiden avulla.
Yhteenveto
Tässä viestissä käsiteltiin arkaluontoisten tietojen käsittelyn tärkeyttä ympäristössäsi sekä erilaisia menetelmiä ja arkkitehtuureja, jotta ne pysyisivät vaatimustenmukaisina ja samalla mahdollistetaan organisaatiosi nopea skaalautuminen. Sinulla pitäisi nyt olla hyvä ymmärrys tietojesi havaitsemisesta, peittämisestä tai muokkaamisesta ja lataamisesta Amazon OpenSearch Serviceen.
Tietoja kirjoittajista
 Michael Hamilton on Sr Analytics Solutions -arkkitehti, joka keskittyy auttamaan yritysasiakkaita modernisoimaan ja yksinkertaistamaan analytiikan työtaakkaa AWS:ssä. Hän nauttii maastopyöräilystä ja viettää aikaa vaimonsa ja kolmen lapsensa kanssa, kun hän ei ole töissä.
Michael Hamilton on Sr Analytics Solutions -arkkitehti, joka keskittyy auttamaan yritysasiakkaita modernisoimaan ja yksinkertaistamaan analytiikan työtaakkaa AWS:ssä. Hän nauttii maastopyöräilystä ja viettää aikaa vaimonsa ja kolmen lapsensa kanssa, kun hän ei ole töissä.
 Daniel Rozo on Senior Solutions Architect, jonka AWS tukee asiakkaita Alankomaissa. Hänen intohimonsa on yksinkertaisten data- ja analytiikkaratkaisujen suunnittelu ja asiakkaiden auttaminen siirtymään moderneihin tietoarkkitehtuureihin. Työn ulkopuolella hän pelaa tennistä ja pyöräilee.
Daniel Rozo on Senior Solutions Architect, jonka AWS tukee asiakkaita Alankomaissa. Hänen intohimonsa on yksinkertaisten data- ja analytiikkaratkaisujen suunnittelu ja asiakkaiden auttaminen siirtymään moderneihin tietoarkkitehtuureihin. Työn ulkopuolella hän pelaa tennistä ja pyöräilee.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :on
- :On
- :ei
- :missä
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- kyky
- pystyy
- kiihtyi
- pääsy
- Toimia
- Toiminta
- Ad
- osoite
- Agentti
- Kaikki
- sallittu
- Salliminen
- mahdollistaa
- Myös
- aina
- Amazon
- Amazon kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- määrä
- määrät
- an
- analyyttinen
- Analytics
- ja
- Kaikki
- sovelletaan
- sovellukset
- käyttää
- lähestymistapa
- asianmukaisesti
- arkkitehtuuri
- OVAT
- AS
- At
- attribuutteja
- tilintarkastus
- automatisoida
- automaattisesti
- saatavuus
- saatavissa
- AWS
- AWS-liima
- varmuuskopiot
- Pankkitoiminta
- Pankkijärjestelmät
- perustua
- BE
- koska
- ollut
- ennen
- ovat
- alle
- hyödyttää
- tuoda
- rakentaa
- rakennettu
- sisäänrakennettu
- mutta
- by
- CAN
- kyvyt
- Koko
- kaapata
- kortti
- tapaus
- tapauksissa
- luettelo
- luokat
- CDC
- solu
- muuttaa
- Muutokset
- kanavat
- Lapset
- valitsi
- selkeys
- pilvi
- Cluster
- koodi
- Sarake
- Pylväät
- Tulla
- tulee
- tuleva
- yhteensopiva
- mukautuva
- osat
- Sisältää
- Laskea
- huolenaiheet
- kytketty
- Harkita
- harkittu
- kulutetaan
- kulutus
- sisältää
- tausta
- jatkaa
- ohjaus
- korjata
- kustannukset
- voisi
- maahan
- luoda
- Valtakirja
- pisteitä
- luottokortti
- kuratoitu
- Nykyinen
- Asiakkaat
- tiedot
- Data Analytics
- datan integraatio
- Datajärvi
- Tietoalusta
- Tietosuoja
- tietostrategia
- tietokanta
- tietokannat
- aineistot
- Päivämäärä
- päivä
- oletusarvo
- määritelty
- toimitettu
- osoittaa
- osoittaa
- käyttöön
- Malli
- määränpää
- kohteet
- yksityiskohdat
- havaita
- havaittu
- Detection
- Määrittää
- Kehitys
- kehitysryhmät
- eri
- suoraan
- löytää
- löysi
- keskusteltiin
- do
- verkkotunnuksen
- verkkotunnuksia
- Dont
- kukin
- ponnisteluja
- Tekniikka
- varmistaa
- yritys
- yritysasiakkaat
- Koko
- yksiköt
- ympäristö
- Eetteri (ETH)
- Jopa
- Tapahtumat
- Joka
- esimerkki
- Esimerkit
- odotettu
- experience
- ilmauksia
- ulkoinen
- FAST
- Fields
- filee
- Asiakirjat
- taloudellinen
- rahoituspalvelut
- Etunimi
- Virtaava
- virrat
- tarkennus
- seurannut
- jälkeen
- seuraa
- varten
- Puitteet
- alkaen
- koko
- täysin
- tulevaisuutta
- tuottaa
- saada
- hyvä
- hallinto
- myönnetty
- Vetimet
- Käsittely
- Olla
- he
- terveys
- terveystiedot
- auttaa
- auttaa
- auttaa
- korkean tason
- hänen
- historiallinen
- Miten
- Miten
- HTML
- http
- HTTPS
- Sadat
- tunnistaa
- if
- havainnollistaa
- kuvitella
- toteuttaa
- merkitys
- tärkeä
- in
- sisältää
- Mukaan lukien
- indeksi
- henkilökohtainen
- tiedot
- Infrastruktuuri
- sisällä
- integraatio
- sisäinen
- tulee
- IT
- Jaava
- Job
- Työpaikat
- jpg
- json
- Pitää
- Kinesis Data Firehose
- Kinesis-tietovirrat
- tunnettu
- järvi
- Maa
- maat
- suuri
- Sukunimi
- myöhemmin
- Lait
- Lainsäädäntö
- kerros
- kerrokset
- Johto
- antaa
- Kirjasto
- elinkaari
- pitää
- linja
- kuormitus
- lastaus
- sijainnit
- katso
- edullisia
- tärkein
- ylläpitäminen
- tehdä
- onnistui
- monet
- kartoitus
- naamio
- Saattaa..
- menetelmä
- menetelmät
- vaeltaa
- muutto
- Moderni
- nykyaikaistaa
- seuranta
- lisää
- Vuori
- liikkua
- liikkuvat
- paljon
- moninkertainen
- täytyy
- nimi
- nimet
- välttämätön
- Tarve
- tarvitaan
- tarvitsevat
- tarpeet
- Alankomaat
- Uusi
- Nro
- solmut
- Ilmoitus..
- nyt
- numero
- of
- Tarjoukset
- on
- ONE
- vain
- toiminta
- toiminta-
- Operations
- optimoimalla
- Vaihtoehdot
- or
- organisaatio
- organisaatioiden
- Muut
- meidän
- ulostulo
- ulkopuolella
- yli
- osa
- intohimo
- kauneuspilkku
- kuviot
- Maksaa
- maksu
- varten
- suorittaa
- suorituskyky
- Oikeudet
- Henkilökohtaisesti
- puhelin
- pii
- putki
- suunnitelma
- foorumi
- Platon
- Platonin tietotieto
- PlatonData
- pelaa
- Kohta
- osa
- Kirje
- edeltävä
- esitetty
- edellinen
- yksityisyys
- yksityisyyttä koskevat lait
- jalostettu
- Prosessit
- käsittely
- tuottaja
- suojattu
- protokollat
- toimittaja
- tarjoaa
- ostot
- kyselyt
- nopeasti
- pikemminkin
- raaka
- raakadata
- reaaliaikainen
- syistä
- vastaanottava
- reseptit
- suositeltu
- ennätys
- asiakirjat
- Vähentynyt
- katso
- säännöllinen
- määräykset
- luotettavuus
- jäädä
- poistaa
- Raportointi
- Raportit
- edellyttää
- vaatimus
- vaatimukset
- vastuut
- vastuullinen
- rajoittaa
- tulokset
- roolit
- RIVI
- ajaa
- toimii
- SaaS
- uhraa
- turvallista
- turvallisesti
- sama
- Asteikko
- skannata
- aikataulu
- tutkijat
- Näytön
- sdk
- Haku
- Osa
- turvallisesti
- turvallisuus
- nähdä
- valita
- valittu
- vanhempi
- sensible
- lähetetty
- palvelu
- Palvelut
- laukaus
- shouldnt
- esitetty
- Näytä
- Yksinkertainen
- yksinkertaistaa
- pieni
- So
- sosiaalinen
- Tuotteemme
- ohjelmisto palveluna
- ratkaisu
- Ratkaisumme
- lähde
- Lähteet
- erityinen
- erityisesti
- määritelty
- viettää
- menot
- splits
- vaiheissa
- Valtiot
- Vaihe
- Levytila
- verkkokaupasta
- suora
- Strategia
- virta
- streaming
- puroihin
- jono
- rakenne
- jäsennelty
- studio
- myöhempi
- Onnistuneesti
- niin
- sopiva
- Tuetut
- Tukea
- järjestelmä
- järjestelmät
- taulukko
- vie
- Kohde
- joukkue-
- tiimit
- tekniikat
- tennis
- kymmeniä
- kuin
- että
- -
- Tulevaisuus
- Alankomaat
- Lähde
- heidän
- sitten
- Siellä.
- Nämä
- tätä
- ne
- kolmella
- kynnys
- Kautta
- aika
- että
- otti
- työkalut
- raita
- Liiketoimet
- siirtää
- siirrot
- Muuttaa
- Muutos
- Trendit
- laukeaa
- kaksi
- tyyppi
- tyypit
- Lopulta
- taustalla oleva
- ymmärtäminen
- yhdistynyt
- Yhtenäinen
- Yhdysvallat
- us
- käyttää
- käyttölaukku
- käytetty
- Käyttäjät
- käyttämällä
- arvo
- lajike
- eri
- kautta
- visuaalinen
- kävellä
- oli
- tavalla
- we
- verkko
- verkkopalvelut
- Mitä
- kun
- joka
- vaikka
- KUKA
- vaimo
- tulee
- with
- sisällä
- ilman
- Referenssit
- työnkulku
- työskentely
- kirjoittaa
- te
- Sinun
- zephyrnet