- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :On
- 10
- 100
- 15%
- 2023
- 7
- a
- pystyy
- poikki
- hyväksymällä
- AI
- samoin
- Kaikki
- Vaikka
- keskuudessa
- an
- ja
- vastauksia
- sovellettu
- OVAT
- AS
- pyytäminen
- näkökohdat
- avustajat
- liittyvä
- At
- hyökkäys
- Hyökkäykset
- saatavissa
- pois
- BE
- ovat
- välillä
- miljardeja
- rakentaa
- yritykset
- mutta
- by
- CAN
- huolellisesti
- toimitusjohtaja
- chatbots
- ChatGPT
- selkeä
- suljettu
- Yhteinen
- Yritykset
- tietokone
- Koskea
- koskevat
- Konferenssi
- voisi
- luoda
- Luominen
- kriittinen
- Tällä hetkellä
- cyber
- Päivämäärä
- osoittaa
- osoittivat
- levityspinnalta
- yksityiskohtainen
- Detection
- kehittää
- eri
- digitaalinen
- löysi
- dr
- yrityksille
- Koko
- Jopa
- näyttö
- olla
- olemassa
- Käyttää hyväkseen
- uuttaminen
- erittäin
- lumoava
- taloudellinen
- rahoituspalvelut
- Etunimi
- keskityttiin
- varten
- alkaen
- edelleen
- saadut
- tietty
- Antaminen
- Maa
- Olla
- kätketty
- raidat
- isännöi
- Miten
- Miten
- Kuitenkin
- HTTPS
- HalaaKasvot
- tärkeä
- in
- kasvoi
- yhä useammin
- teollisuus
- ilmoittaa
- tiedot
- tietoturva
- oivaltava
- Internet
- Investoida
- investoimalla
- IT
- jpg
- avain
- tuntemus
- tunnettu
- Kieli
- suuri
- Suuret yritykset
- käynnistää
- johtava
- OPPIA
- oppiminen
- vähemmän
- vähän
- kone
- koneoppiminen
- merkittävä
- Saattaa..
- mittaus
- miljoonia
- malli
- mallit
- paljon
- Uusi
- of
- on
- avata
- avoimen lähdekoodin
- or
- ulos
- oma
- Paperi
- puolue
- Pietari
- paikat
- suunnittelu
- Platon
- Platonin tietotieto
- PlatonData
- mahdollinen
- mahdollisesti
- voimakas
- valmistelee
- esitetty
- Pääasiallinen
- yksityinen
- toimittaa
- julkisesti
- alue
- hinta
- monistaa
- pyynnöt
- tutkimus
- Tutkijat
- paljastaa
- riskit
- Said
- sanoa
- tutkijat
- turvallisuus
- Palvelut
- setti
- shouldnt
- näyttää
- pienempiä
- fiksu
- So
- jonkin verran
- lähde
- Vaihe
- Käynnistys
- myrsky
- tutkimus
- menestys
- Onnistuneesti
- niin
- otettava
- puhuminen
- kohdennettu
- kohdistaminen
- tehtävät
- joukkue-
- Technologies
- Elektroniikka
- Testaus
- kuin
- että
- -
- tiedot
- UK
- maailma
- heidän
- sitten
- Siellä.
- Nämä
- ne
- ajatella
- kolmas
- tätä
- Tämä vuosi
- kertaa
- että
- työkalut
- siirretty
- transformatiivinen
- Uk
- ymmärtäminen
- sitoutuvat
- yliopisto
- käyttää
- käytetty
- käyttötarkoituksiin
- arvostettu
- hyvin
- haavoittuvuuksia
- oli
- Tapa..
- we
- viikko
- olivat
- joka
- leveä
- Laaja valikoima
- tulee
- with
- sisällä
- ilman
- Referenssit
- treenata
- toimii
- maailman-
- huolestuttava
- vuosi
- zephyrnet
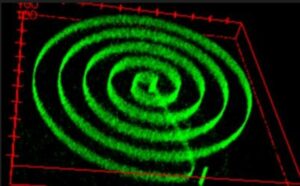
Lisää aiheesta Nanowerk
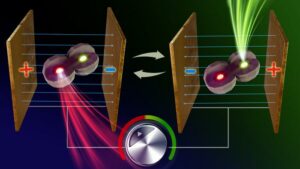
Päästä valloille väriviritettävän nanolaitteiden uusi aikakausi – kaikkien aikojen pienin valonlähde vaihdettavissa olevilla väreillä
Lähdesolmu: 2801585
Aikaleima: Elokuu 3, 2023

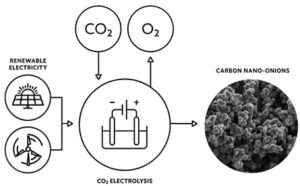
Hiilinanoputkilla voi olla merkittävä rooli ilmakehän hiilidioksidin sitomisessa
Lähdesolmu: 2836729
Aikaleima: Elokuu 21, 2023

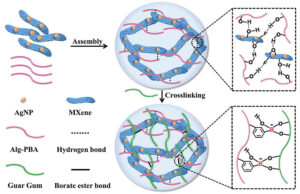
MXene-hydrogeelipohjaiset antibakteeriset epidermiset sensorit
Lähdesolmu: 2661017
Aikaleima: Voi 18, 2023
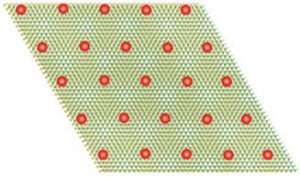
Kun materiaali muuttuu kvantiksi, elektronit hidastuvat ja muodostavat kiteen
Lähdesolmu: 1975767
Aikaleima: Helmikuu 23, 2023

Insinöörit kehittävät tehokkaan prosessin polttoaineen valmistamiseksi hiilidioksidista
Lähdesolmu: 2963812
Aikaleima: Lokakuu 30, 2023