دریاچه های داده مجهز به AWS، که توسط در دسترس بودن بی نظیر پشتیبانی می شوند سرویس ذخیره سازی ساده آمازون (Amazon S3)، میتواند مقیاس، چابکی و انعطافپذیری مورد نیاز برای ترکیب دادههای مختلف و رویکردهای تحلیلی را مدیریت کند. از آنجایی که دریاچههای داده از نظر اندازه بزرگ شدهاند و از نظر استفاده بالغ شدهاند، میتوان تلاش زیادی را صرف حفظ دادهها با رویدادهای تجاری کرد. برای اطمینان از بهروزرسانی فایلها به روشی سازگار تراکنش، تعداد فزایندهای از مشتریان از قالبهای جدول تراکنشهای منبع باز مانند کوه یخ آپاچی, آپاچی هودیو لینوکس بنیاد دلتا لیک که به شما کمک میکند دادهها را با نرخ فشردهسازی بالا ذخیره کنید، به طور بومی با برنامهها و چارچوبهای خود ارتباط برقرار کنید، و پردازش تدریجی دادهها را در دریاچههای داده ساخته شده در Amazon S3 ساده کنید. این قالبها، تراکنشهای ACID (اتمی، سازگاری، انزوا، دوام)، آپلودها و حذفها و ویژگیهای پیشرفتهای مانند سفر در زمان و عکسهای فوری را که قبلاً فقط در انبارهای داده در دسترس بودند، فعال میکنند. هر فرمت ذخیره سازی این قابلیت را به روش های کمی متفاوت اجرا می کند. برای مقایسه رجوع شود انتخاب یک قالب جدول باز برای دریاچه داده تراکنشی خود در AWS.
در 2023، AWS در دسترس بودن عمومی را اعلام کرد برای Apache Iceberg، Apache Hudi و Linux Foundation Delta Lake در آمازون آتنا برای آپاچی اسپارک، که نیاز به نصب کانکتور جداگانه یا وابستگی های مرتبط و مدیریت نسخه ها را از بین می برد و مراحل پیکربندی مورد نیاز برای استفاده از این چارچوب ها را ساده می کند.
در این پست نحوه استفاده از Spark SQL را به شما نشان می دهیم آمازون آتنا نوت بوک و کار با فرمت های جدول Iceberg، Hudi و Delta Lake. ما عملیات رایجی مانند ایجاد پایگاههای اطلاعاتی و جداول، درج دادهها در جداول، جستجوی دادهها و مشاهده عکسهای فوری جداول در Amazon S3 با استفاده از Spark SQL در Athena را نشان میدهیم.
پیش نیازها
پیش نیازهای زیر را کامل کنید:
نمونه نوت بوک ها را از آمازون S3 دانلود و وارد کنید
برای پیگیری، نوت بوک های مورد بحث در این پست را از مکان های زیر دانلود کنید:
پس از دانلود نوتبوکها، آنها را با دنبال کردن موارد زیر وارد محیط Athena Spark خود کنید برای وارد کردن یک نوت بوک بخش در مدیریت فایل های نوت بوک.
به بخش فرمت جدول باز خاص بروید
اگر به فرمت جدول Iceberg علاقه دارید، به آن بروید کار با جداول Apache Iceberg بخش.
اگر به فرمت جدول هودی علاقه مند هستید، به ادامه مطلب بروید کار با جداول آپاچی هودی بخش.
اگر به قالب جدول دلتا لیک علاقه مند هستید، به ادامه مطلب بروید کار با جداول لینوکس پایه دلتا لیک بخش.
کار با جداول Apache Iceberg
هنگام استفاده از نوت بوک های Spark در آتنا، می توانید پرس و جوهای SQL را مستقیماً بدون نیاز به استفاده از PySpark اجرا کنید. ما این کار را با استفاده از جادوهای سلولی انجام می دهیم، که هدرهای خاصی در یک سلول نوت بوک هستند که رفتار سلول را تغییر می دهند. برای SQL، می توانیم اضافه کنیم %%sql magic، که کل محتویات سلول را به عنوان یک دستور SQL برای اجرا در Athena تفسیر می کند.
در این بخش، ما نشان می دهیم که چگونه می توانید از SQL در Apache Spark برای Athena برای ایجاد، تجزیه و تحلیل و مدیریت جداول Apache Iceberg استفاده کنید.
یک جلسه نوت بوک راه اندازی کنید
برای استفاده از Apache Iceberg در Athena، هنگام ایجاد یا ویرایش یک جلسه، گزینه را انتخاب کنید کوه یخ آپاچی گزینه با گسترش خواص آپاچی اسپارک بخش. همانطور که در تصویر زیر نشان داده شده است، ویژگی ها را از قبل پر می کند.
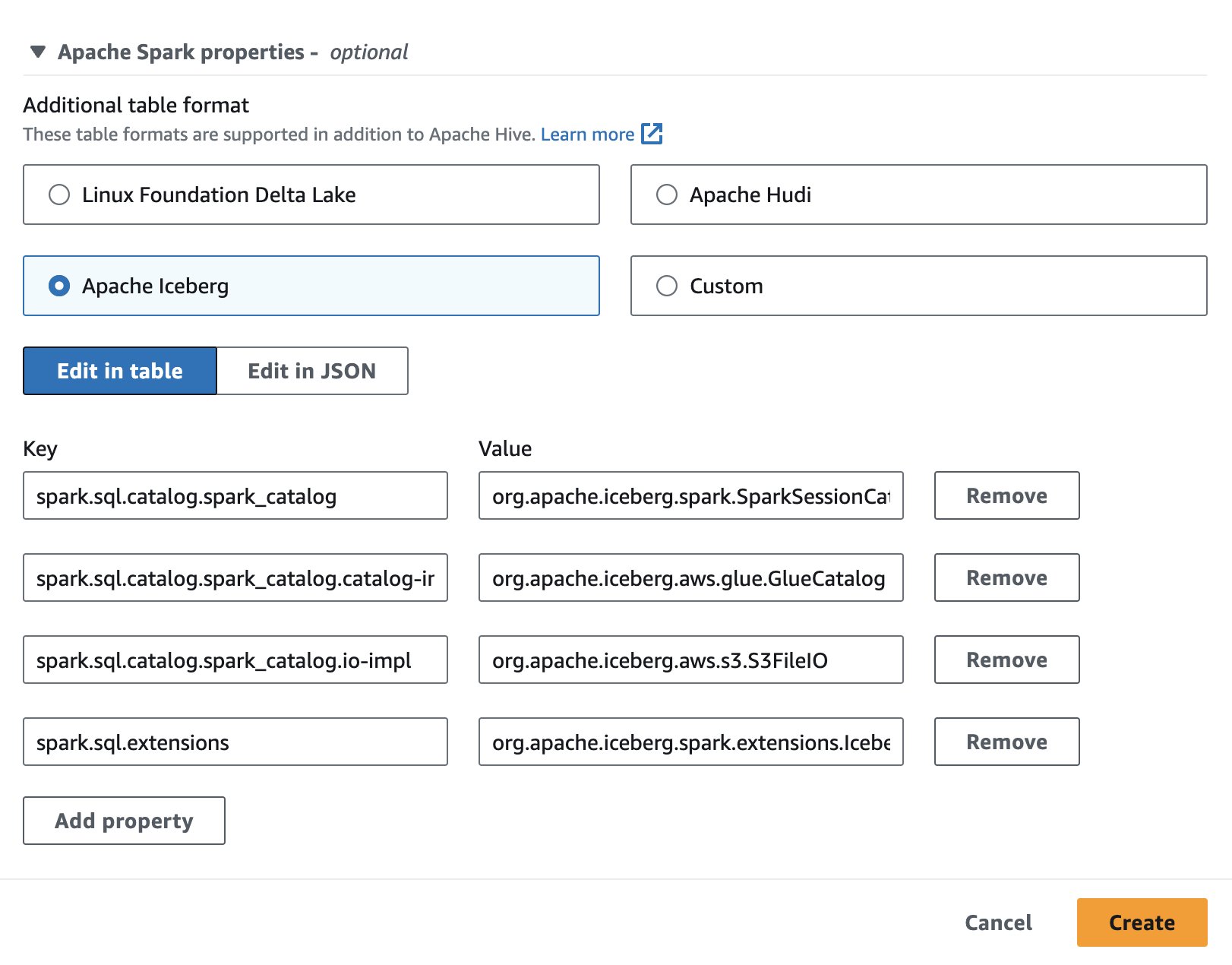
برای مراحل، نگاه کنید ویرایش جزئیات جلسه or ایجاد دفترچه یادداشت خود.
کد استفاده شده در این بخش در قسمت موجود است SparkSQL_iceberg.ipynb فایل جهت پیگیری
یک پایگاه داده و جدول Iceberg ایجاد کنید
ابتدا یک پایگاه داده در کاتالوگ داده چسب AWS ایجاد می کنیم. با SQL زیر می توانیم پایگاه داده ای به نام ایجاد کنیم icebergdb:
بعد، در پایگاه داده icebergdb، یک جدول Iceberg به نام می سازیم noaa_iceberg با اشاره به مکانی در آمازون S3 که در آن داده ها را بارگیری خواهیم کرد. عبارت زیر را اجرا کنید و مکان را جایگزین کنید s3://<your-S3-bucket>/<prefix>/ با سطل و پیشوند S3 شما:
داده ها را در جدول وارد کنید
برای پر کردن noaa_iceberg جدول Iceberg، داده ها را از جدول Parquet وارد می کنیم sparkblogdb.noaa_pq که به عنوان بخشی از پیش نیازها ایجاد شده است. شما می توانید این کار را با استفاده از یک وارد شوید بیانیه در اسپارک:
متناوبا می توانید از آن استفاده کنید ایجاد جدول به عنوان انتخاب با عبارت USING iceberg برای ایجاد جدول Iceberg و درج داده ها از جدول منبع در یک مرحله:
جدول کوه یخ را جستجو کنید
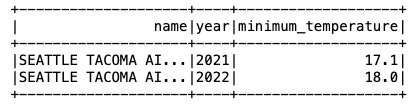
اکنون که داده ها در جدول Iceberg درج شده اند، می توانیم تجزیه و تحلیل آن را آغاز کنیم. بیایید یک Spark SQL را اجرا کنیم تا حداقل دمای ثبت شده را در سال برای آن پیدا کنیم 'SEATTLE TACOMA AIRPORT, WA US' محل:
خروجی زیر را دریافت می کنیم.
داده ها را در جدول کوه یخ به روز کنید
بیایید به نحوه به روز رسانی داده ها در جدول خود نگاه کنیم. ما می خواهیم نام ایستگاه را به روز کنیم 'SEATTLE TACOMA AIRPORT, WA US' به 'Sea-Tac'. با استفاده از Spark SQL، می توانیم یک را اجرا کنیم بروزرسانی بیانیه ای علیه میز کوه یخ:
سپس میتوانیم کوئری SELECT قبلی را اجرا کنیم تا حداقل دمای ثبتشده را پیدا کنیم 'Sea-Tac' محل:
خروجی زیر را دریافت می کنیم.

فایل های داده فشرده
قالبهای جدول باز مانند Iceberg با ایجاد تغییرات دلتا در ذخیرهسازی فایلها و ردیابی نسخههای ردیفها از طریق فایلهای مانیفست کار میکنند. فایل های داده بیشتر منجر به ذخیره ابرداده های بیشتری در فایل های مانیفست می شود و فایل های داده کوچک اغلب باعث مقدار غیرضروری ابرداده می شوند که در نتیجه پرس و جوهای کارآمدتر و هزینه های دسترسی آمازون S3 بالاتر است. دویدن کوه یخ rewrite_data_files رویه Spark for Athena فایلهای داده را فشرده میکند و بسیاری از فایلهای تغییر دلتا کوچک را در مجموعه کوچکتری از فایلهای پارکت بهینهشده برای خواندن ترکیب میکند. فشرده سازی فایل ها، عملیات خواندن را در هنگام پرس و جو سرعت می بخشد. برای اجرای فشرده سازی در جدول ما، Spark SQL زیر را اجرا کنید:
rewrite_data_files گزینه هایی را ارائه می دهد برای مشخص کردن استراتژی مرتب سازی خود، که می تواند به سازماندهی مجدد و فشرده سازی داده ها کمک کند.
فهرست عکس های فوری جدول
هر عملیات نوشتن، بهروزرسانی، حذف، اضافه کردن و فشردهسازی در جدول Iceberg یک عکس فوری جدید از یک جدول ایجاد میکند و در عین حال دادهها و ابردادههای قدیمی را برای جداسازی عکس فوری و سفر در زمان حفظ میکند. برای فهرست کردن عکسهای فوری جدول Iceberg، عبارت Spark SQL زیر را اجرا کنید:
منقضی شدن عکس های فوری قدیمی
برای حذف فایلهای دادهای که دیگر مورد نیاز نیستند، و برای کوچک نگه داشتن اندازه ابردادههای جدول، اسنپشاتهایی که به طور منظم منقضی میشوند، توصیه میشود. هرگز فایل هایی را که هنوز برای یک عکس فوری منقضی نشده مورد نیاز هستند حذف نمی کند. در Spark for Athena، SQL زیر را اجرا کنید تا عکسهای فوری جدول منقضی شود icebergdb.noaa_iceberg که قدیمی تر از یک مهر زمانی خاص هستند:
توجه داشته باشید که مقدار timestamp به عنوان یک رشته در قالب مشخص شده است yyyy-MM-dd HH:mm:ss.fff. خروجی تعداد داده ها و فایل های ابرداده حذف شده را نشان می دهد.
جدول و پایگاه داده را رها کنید
میتوانید Spark SQL زیر را برای تمیز کردن جداول Iceberg و دادههای مرتبط در Amazon S3 از این تمرین اجرا کنید:
Spark SQL زیر را برای حذف پایگاه داده icebergdb اجرا کنید:
برای کسب اطلاعات بیشتر در مورد تمام عملیاتی که می توانید با استفاده از Spark for Athena روی میزهای Iceberg انجام دهید، به ادامه مطلب مراجعه کنید پرس و جوهای جرقه و رویه های جرقه در مستندات کوه یخ
کار با جداول آپاچی هودی
در مرحله بعد، ما نشان می دهیم که چگونه می توانید از SQL در Spark برای Athena برای ایجاد، تجزیه و تحلیل و مدیریت جداول Apache Hudi استفاده کنید.
یک جلسه نوت بوک راه اندازی کنید
برای استفاده از آپاچی هودی در آتنا، هنگام ایجاد یا ویرایش یک جلسه، گزینه را انتخاب کنید آپاچی هودی گزینه با گسترش خواص آپاچی اسپارک بخش.
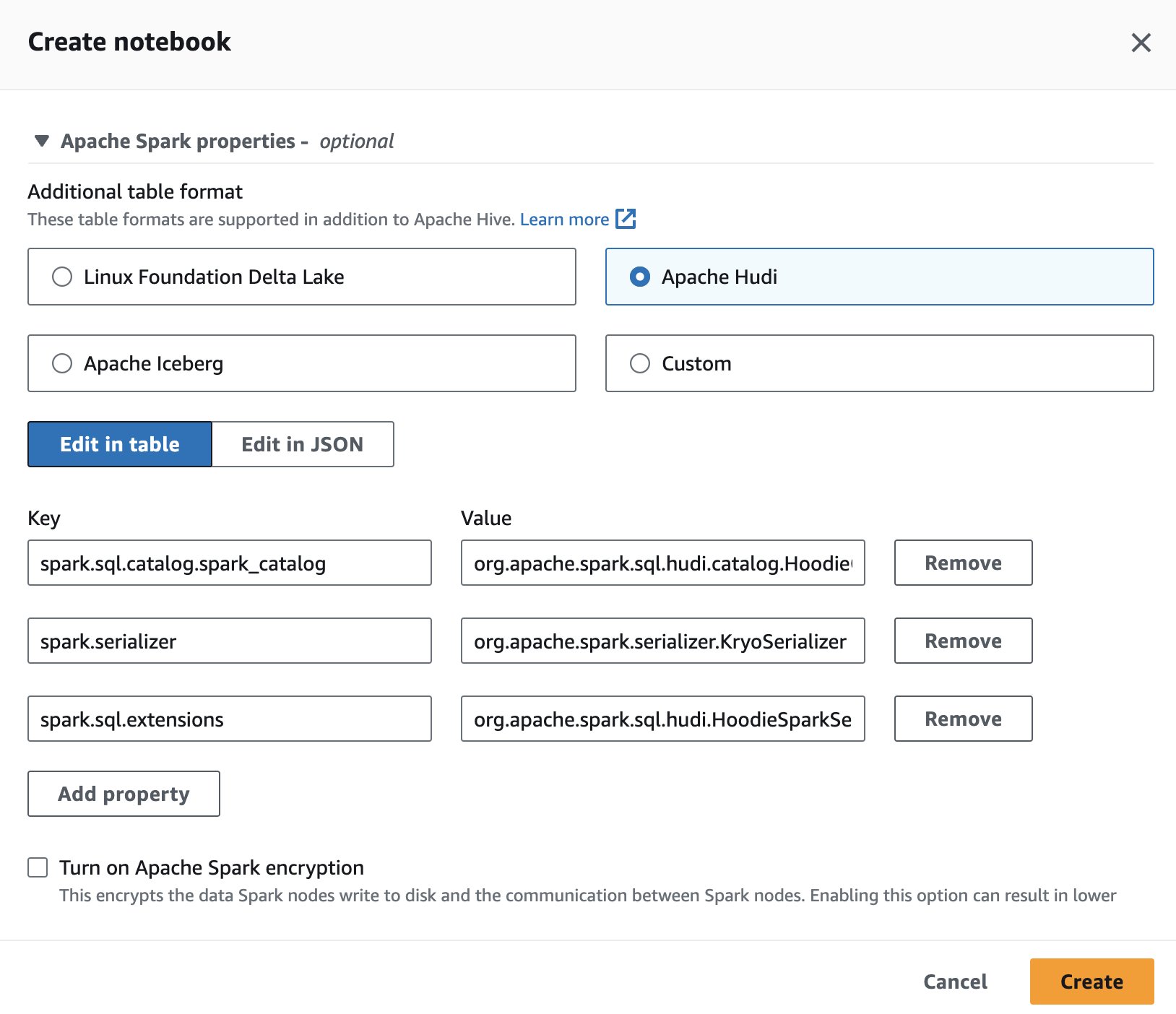
برای مراحل، نگاه کنید ویرایش جزئیات جلسه or ایجاد دفترچه یادداشت خود.
کد استفاده شده در این بخش باید در قسمت موجود باشد SparkSQL_hudi.ipynb فایل جهت پیگیری
یک پایگاه داده و جدول Hudi ایجاد کنید
ابتدا یک پایگاه داده به نام ایجاد می کنیم hudidb که در کاتالوگ داده های چسب AWS ذخیره می شود و سپس جدول Hudi ایجاد می شود:
ما یک جدول Hudi ایجاد می کنیم که به مکانی در آمازون S3 اشاره می کند که در آن داده ها را بارگذاری می کنیم. توجه داشته باشید که جدول از کپی بر روی نوشتن نوع تعریف شده است type= 'cow' در جدول DDL ایستگاه و تاریخ را بهعنوان کلیدهای اصلی متعدد و PreCombinedField را سال تعریف کردهایم. همچنین جدول بر اساس سال تقسیم بندی شده است. عبارت زیر را اجرا کنید و مکان را جایگزین کنید s3://<your-S3-bucket>/<prefix>/ با سطل و پیشوند S3 شما:
داده ها را در جدول وارد کنید
مانند کوه یخ، ما از آن استفاده می کنیم وارد شوید عبارت برای پر کردن جدول با خواندن داده ها از sparkblogdb.noaa_pq جدول ایجاد شده در پست قبل:
جدول هودی را استعلام کنید
اکنون که جدول ایجاد شده است، بیایید یک پرس و جو اجرا کنیم تا حداکثر دمای ثبت شده را پیدا کنیم 'SEATTLE TACOMA AIRPORT, WA US' محل:
داده ها را در جدول Hudi به روز کنید
بیایید نام ایستگاه را تغییر دهیم 'SEATTLE TACOMA AIRPORT, WA US' به 'Sea–Tac'. ما می توانیم یک عبارت UPDATE را در Spark برای Athena اجرا کنیم به روز رسانی سوابق از noaa_hudi جدول:
ما کوئری SELECT قبلی را اجرا می کنیم تا حداکثر دمای ثبت شده را پیدا کنیم 'Sea-Tac' محل:
درخواست های سفر در زمان را اجرا کنید
ما می توانیم از پرس و جوهای سفر در زمان در SQL در Athena برای تجزیه و تحلیل عکس های فوری داده های گذشته استفاده کنیم. مثلا:
این پرس و جو داده های دمای فرودگاه سیاتل را در زمان خاصی در گذشته بررسی می کند. بند مهر زمان به ما امکان می دهد بدون تغییر داده های فعلی به عقب برگردیم. توجه داشته باشید که مقدار timestamp به عنوان یک رشته در قالب مشخص شده است yyyy-MM-dd HH:mm:ss.fff.
سرعت پرس و جو را با خوشه بندی بهینه کنید
برای بهبود عملکرد پرس و جو، می توانید انجام دهید خوشه بندی در جداول Hudi با استفاده از SQL در Spark for Athena:
میزهای جمع و جور
Compaction یک سرویس جدولی است که توسط Hudi به طور خاص در جداول Merge On Read (MOR) برای ادغام بهروزرسانیها از فایلهای لاگ مبتنی بر ردیف به فایل پایه ستونی مربوطه به صورت دورهای برای تولید نسخه جدیدی از فایل پایه استفاده میشود. فشرده سازی برای جداول Copy On Write (COW) قابل اعمال نیست و فقط برای جداول MOR اعمال می شود. برای انجام فشرده سازی در جداول MOR می توانید پرس و جو زیر را در Spark for Athena اجرا کنید:
جدول و پایگاه داده را رها کنید
Spark SQL زیر را اجرا کنید تا جدول Hudi که ایجاد کرده اید و داده های مرتبط با آن را از محل Amazon S3 حذف کنید:
Spark SQL زیر را برای حذف پایگاه داده اجرا کنید hudidb:
برای اطلاع از تمامی عملیاتی که می توانید با استفاده از Spark for Athena روی جداول Hudi انجام دهید، به ادامه مطلب مراجعه کنید SQL DDL و جراحی ها در اسناد هودی
کار با جداول لینوکس پایه دلتا لیک
در مرحله بعد، ما نشان می دهیم که چگونه می توانید از SQL در Spark برای Athena برای ایجاد، تجزیه و تحلیل و مدیریت جداول Delta Lake استفاده کنید.
یک جلسه نوت بوک راه اندازی کنید
به منظور استفاده از دلتا لیک در اسپارک برای آتنا، هنگام ایجاد یا ویرایش یک جلسه، را انتخاب کنید لینوکس بنیاد دلتا لیک با گسترش خواص آپاچی اسپارک بخش.
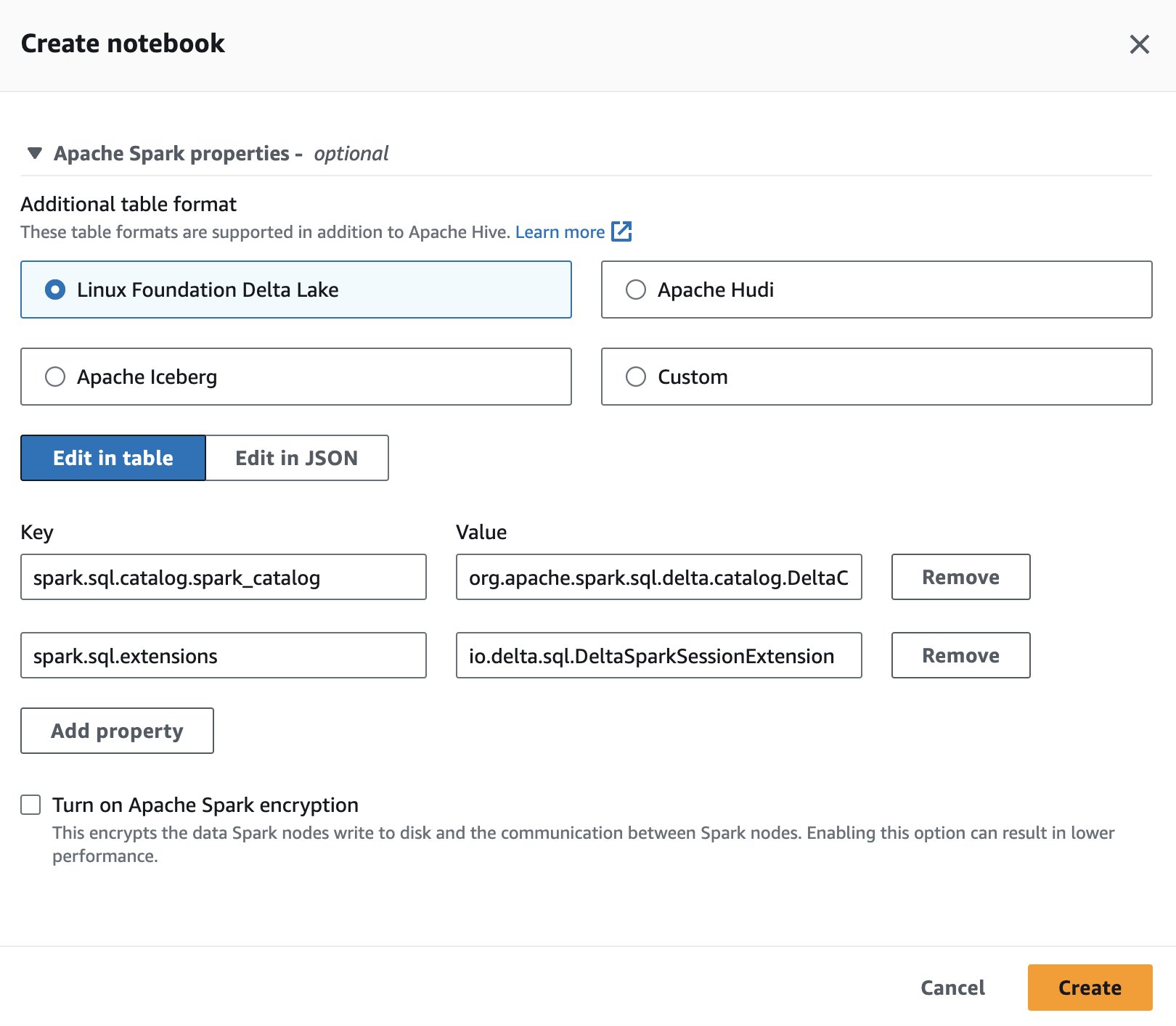
برای مراحل، نگاه کنید ویرایش جزئیات جلسه or ایجاد دفترچه یادداشت خود.
کد استفاده شده در این بخش باید در قسمت موجود باشد SparkSQL_delta.ipynb فایل جهت پیگیری
یک پایگاه داده و جدول دلتا لیک ایجاد کنید
در این بخش یک پایگاه داده در کاتالوگ داده چسب AWS ایجاد می کنیم. با استفاده از SQL زیر می توانیم پایگاه داده ای به نام ایجاد کنیم deltalakedb:
بعد، در پایگاه داده deltalakedb، یک جدول دریاچه دلتا به نام ایجاد می کنیم noaa_delta با اشاره به مکانی در آمازون S3 که در آن داده ها را بارگیری خواهیم کرد. عبارت زیر را اجرا کنید و مکان را جایگزین کنید s3://<your-S3-bucket>/<prefix>/ با سطل و پیشوند S3 شما:
داده ها را در جدول وارد کنید
ما از یک وارد شوید عبارت برای پر کردن جدول با خواندن داده ها از sparkblogdb.noaa_pq جدول ایجاد شده در پست قبل:
همچنین می توانید از CREATE TABLE AS SELECT برای ایجاد جدول Delta Lake و درج داده ها از جدول منبع در یک پرس و جو استفاده کنید.
جدول دریاچه دلتا را جستجو کنید
اکنون که داده ها در جدول دریاچه دلتا درج شده است، می توانیم تجزیه و تحلیل آن را شروع کنیم. بیایید یک Spark SQL را اجرا کنیم تا حداقل دمای ثبت شده را پیدا کنیم 'SEATTLE TACOMA AIRPORT, WA US' محل:
به روز رسانی داده ها در جدول دریاچه دلتا
بیایید نام ایستگاه را تغییر دهیم 'SEATTLE TACOMA AIRPORT, WA US' به 'Sea–Tac'. ما می توانیم اجرا کنیم بروزرسانی بیانیه اسپارک برای آتنا برای به روز رسانی رکوردهای noaa_delta جدول:
میتوانیم کوئری SELECT قبلی را اجرا کنیم تا حداقل دمای ثبتشده را پیدا کنیم 'Sea-Tac' مکان، و نتیجه باید مانند قبل باشد:
فایل های داده فشرده
در Spark for Athena، میتوانید OPTIMIZE را بر روی جدول Delta Lake اجرا کنید، که فایلهای کوچک را به فایلهای بزرگتر فشرده میکند، بنابراین درخواستها توسط سربار فایل کوچک سنگین نمیشوند. برای انجام عملیات فشرده سازی، کوئری زیر را اجرا کنید:
به مراجعه بهینه سازی در اسناد دریاچه دلتا برای گزینه های مختلف موجود هنگام اجرای OPTIMIZE.
فایلهایی را که دیگر توسط جدول دلتا لیک ارجاع داده نمیشوند حذف کنید
با اجرای دستور VACCUM روی جدول با استفاده از Spark for Athena، میتوانید فایلهای ذخیرهشده در آمازون S3 را که دیگر توسط جدول دلتا لیک ارجاع داده نمیشوند و قدیمیتر از آستانه حفظ هستند حذف کنید:
به مراجعه حذف فایل هایی که دیگر توسط جدول دلتا ارجاع داده نمی شوند در اسناد دریاچه دلتا برای گزینه های موجود با VACUUM.
جدول و پایگاه داده را رها کنید
Spark SQL زیر را برای حذف جدول Delta Lake که ایجاد کرده اید اجرا کنید:
Spark SQL زیر را برای حذف پایگاه داده اجرا کنید deltalakedb:
اجرای DROP TABLE DDL روی جدول و پایگاه داده دلتا لیک، ابرداده این اشیاء را حذف می کند، اما فایل های داده در آمازون S3 را به طور خودکار حذف نمی کند. می توانید کد پایتون زیر را در سلول نوت بوک اجرا کنید تا داده ها را از محل S3 حذف کنید:
برای کسب اطلاعات بیشتر در مورد دستورات SQL که می توانید با استفاده از Spark for Athena روی جدول Delta Lake اجرا کنید، به شروع سریع در اسناد دریاچه دلتا
نتیجه
این پست نحوه استفاده از Spark SQL را در نوتبوکهای Athena برای ایجاد پایگاههای داده و جداول، درج و جستجوی دادهها و انجام عملیاتهای رایج مانند بهروزرسانی، فشردهسازی و سفر در زمان در جداول Hudi، Delta Lake و Iceberg نشان میدهد. قالبهای جدول باز، تراکنشهای ACID، اضافهها و حذفها را به دریاچههای داده اضافه میکنند و بر محدودیتهای ذخیرهسازی اشیاء خام غلبه میکنند. با حذف نیاز به نصب کانکتورهای جداگانه، Spark در ادغام داخلی Athena مراحل پیکربندی و هزینه های مدیریتی را هنگام استفاده از این چارچوب های محبوب برای ایجاد دریاچه های داده قابل اعتماد در Amazon S3 کاهش می دهد. برای کسب اطلاعات بیشتر در مورد انتخاب قالب جدول باز برای بارهای کاری دریاچه داده خود، به مراجعه کنید انتخاب یک قالب جدول باز برای دریاچه داده تراکنشی خود در AWS.
درباره نویسنده
![]() پاتیک شاه یک معمار آنالیتیکس Sr. در آمازون آتنا است. او در سال 2015 به AWS پیوست و از آن زمان بر روی فضای تجزیه و تحلیل داده های بزرگ تمرکز کرده است و به مشتریان کمک می کند تا راه حل های مقیاس پذیر و قوی با استفاده از خدمات تجزیه و تحلیل AWS بسازند.
پاتیک شاه یک معمار آنالیتیکس Sr. در آمازون آتنا است. او در سال 2015 به AWS پیوست و از آن زمان بر روی فضای تجزیه و تحلیل داده های بزرگ تمرکز کرده است و به مشتریان کمک می کند تا راه حل های مقیاس پذیر و قوی با استفاده از خدمات تجزیه و تحلیل AWS بسازند.
![]() راج دونات مدیر محصول در AWS در آمازون آتنا است. او مشتاق ساخت محصولاتی است که مشتریان دوست دارند و به مشتریان کمک می کند تا از داده های خود ارزش استخراج کنند. پیشینه او در ارائه راه حل ها برای چندین بازار نهایی، مانند امور مالی، خرده فروشی، ساختمان های هوشمند، اتوماسیون خانگی، و سیستم های ارتباط داده است.
راج دونات مدیر محصول در AWS در آمازون آتنا است. او مشتاق ساخت محصولاتی است که مشتریان دوست دارند و به مشتریان کمک می کند تا از داده های خود ارزش استخراج کنند. پیشینه او در ارائه راه حل ها برای چندین بازار نهایی، مانند امور مالی، خرده فروشی، ساختمان های هوشمند، اتوماسیون خانگی، و سیستم های ارتباط داده است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- درباره ما
- دسترسی
- اضافه کردن
- پیشرفته
- در برابر
- فرودگاه
- معرفی
- در امتداد
- همچنین
- آمازون
- آمازون آتنا
- آمازون خدمات وب
- مقدار
- an
- علم تجزیه و تحلیل
- تحلیل
- تجزیه و تحلیل
- و
- اعلام کرد
- آپاچی
- جرقه آپاچی
- مربوط
- برنامه های کاربردی
- اعمال میشود
- رویکردها
- هستند
- دور و بر
- AS
- مرتبط است
- At
- بطور خودکار
- اتوماسیون
- دسترس پذیری
- در دسترس
- AWS
- چسب AWS
- به عقب
- زمینه
- پایه
- BE
- بوده
- رفتار
- بزرگ
- بزرگ داده
- ساختن
- بنا
- ساخته
- ساخته شده در
- کسب و کار
- اما
- by
- صدا
- نام
- CAN
- کاتالوگ
- علت
- سلول
- تغییر دادن
- تبادل
- چک
- تمیز
- رمز
- ترکیب
- ترکیب
- مشترک
- ارتباط
- سیستم های ارتباطی
- جمع و جور
- مقایسه
- پیکر بندی
- استوار
- محتویات
- متناظر
- هزینه
- تعداد دفعات مشاهده
- ایجاد
- ایجاد شده
- ایجاد
- ایجاد
- ایجاد
- جاری
- مشتریان
- داده ها
- تجزیه و تحلیل داده ها
- دریاچه دریاچه
- پردازش داده ها
- انبارهای داده
- پایگاه داده
- پایگاه های داده
- تاریخ
- مشخص
- تحویل
- دلتا
- نشان دادن
- نشان
- وابستگی
- مختلف
- مستقیما
- بحث کردیم
- do
- مستندات
- نمی کند
- دانلود
- قطره
- دوام
- هر
- پیش از آن
- ویرایش
- موثر
- تلاش
- به کار گرفته شده
- قادر ساختن
- پایان
- اطمینان حاصل شود
- تمام
- محیط
- اتر (ETH)
- حوادث
- مثال
- ورزش
- گسترش
- عصاره
- امکانات
- پرونده
- فایل ها
- سرمایه گذاری
- پیدا کردن
- نام خانوادگی
- انعطاف پذیری
- تمرکز
- به دنبال
- به دنبال
- پیروی
- برای
- قالب
- پایه
- چارچوب
- از جانب
- قابلیت
- سوالات عمومی
- دریافت کنید
- دادن
- گروه
- در حال رشد
- رشد کرد
- دسته
- آیا
- داشتن
- he
- هدر
- کمک
- کمک
- hh
- زیاد
- بالاتر
- خود را
- صفحه اصلی
- اتوماسیون خانگی
- چگونه
- چگونه
- HTML
- HTTP
- HTTPS
- تصویر
- پیاده سازی می کند
- واردات
- بهبود
- in
- افزایشی
- نصب
- ادغام
- علاقه مند
- رابط
- به
- انزوا
- IT
- پیوست
- JPG
- نگاه داشتن
- نگهداری
- کلید
- دریاچه
- دریاچه ها
- بزرگتر
- عرض جغرافیایی
- منجر می شود
- یاد گرفتن
- کمتر
- اجازه می دهد تا
- پسندیدن
- محدودیت
- لینوکس
- پایه لینوکس
- فهرست
- بار
- محل
- مکان
- ورود به سیستم
- دیگر
- نگاه کنيد
- به دنبال
- عشق
- شعبده بازي
- مدیریت
- مدیریت
- مدیر
- روش
- بسیاری
- بازارها
- حداکثر
- بیشترین
- ادغام کردن
- متاداده
- دقیقه
- حد اقل
- بیش
- چندگانه
- نام
- بومی
- هدایت
- نیاز
- ضروری
- هرگز
- جدید
- نه
- توجه داشته باشید
- دفتر یادداشت
- نوت بوک
- عدد
- هدف
- ذخیره سازی شی
- اشیاء
- of
- پیشنهادات
- غالبا
- قدیمی
- بزرگتر
- on
- ONE
- فقط
- OP
- باز کن
- منبع باز
- عمل
- عملیات
- بهینه سازی
- گزینه
- گزینه
- or
- سفارش
- ما
- تولید
- فائق آمدن
- خود
- بخش
- احساساتی
- گذشته
- انجام دادن
- کارایی
- افلاطون
- هوش داده افلاطون
- PlatoData
- محبوب
- پست
- پیش نیازها
- قبلی
- قبلا
- اصلی
- روش
- در حال پردازش
- تولید کردن
- محصول
- مدیر تولید
- محصولات
- املاک
- پــایتــون
- نمایش ها
- نرخ
- خام
- خواندن
- مطالعه
- توصیه می شود
- ثبت
- سوابق
- را کاهش می دهد
- مراجعه
- اشاره کرد
- قابل اعتماد
- برداشتن
- حذف می کند
- از بین بردن
- جایگزین کردن
- ضروری
- نتیجه
- نتیجه
- خرده فروشی
- نگهداری
- تنومند
- دویدن
- در حال اجرا
- همان
- مقیاس پذیر
- مقیاس
- سیاتل
- دوم
- بخش
- دیدن
- را انتخاب کنید
- انتخاب
- جداگانه
- سرویس
- خدمات
- جلسه
- تنظیم
- باید
- نشان
- نشان داده شده
- نشان می دهد
- قابل توجه
- ساده
- ساده می کند
- ساده کردن
- پس از
- اندازه
- کمی متفاوت
- PFS
- کوچک
- کوچکتر
- هوشمند
- عکس فوری
- So
- مزایا
- منبع
- فضا
- جرقه
- ویژه
- خاص
- به طور خاص
- مشخص شده
- سرعت
- سرعت
- صرف
- SQL
- شروع
- بیانیه
- اظهارات
- ایستگاه
- گام
- مراحل
- هنوز
- ذخیره سازی
- opbevare
- ذخیره شده
- استراتژی
- رشته
- چنین
- پشتیبانی
- سیستم
- سیستم های
- جدول
- تاکوما
- نسبت به
- که
- La
- شان
- آنها
- سپس
- اینها
- این
- آستانه
- از طریق
- زمان
- سفر در زمان
- برچسب زمان
- به
- پیگردی
- معامله ای
- معاملات
- سفر
- نوع
- بی همتا
- بروزرسانی
- به روز شده
- به روز رسانی
- us
- استفاده
- استفاده کنید
- استفاده
- با استفاده از
- خلاء
- ارزش
- نسخه
- نسخه
- می خواهم
- بود
- راه
- we
- وب
- خدمات وب
- بود
- چه زمانی
- که
- در حین
- اراده
- با
- بدون
- مهاجرت کاری
- نوشتن
- سال
- شما
- شما
- زفیرنت