مدلهای زبان بزرگ (LLM) در حال افزایش محبوبیت هستند و موارد استفاده جدید دائماً مورد بررسی قرار میگیرند. به طور کلی، میتوانید برنامههایی را با استفاده از LLM با استفاده از مهندسی سریع در کد خود بسازید. با این حال، مواردی وجود دارد که درخواست یک LLM موجود کوتاه است. اینجاست که تنظیم دقیق مدل می تواند کمک کند. مهندسی سریع در مورد هدایت خروجی مدل با ایجاد اعلان های ورودی است، در حالی که تنظیم دقیق در مورد آموزش مدل بر روی مجموعه داده های سفارشی است تا آن را برای وظایف یا دامنه های خاص مناسب تر کند.
قبل از اینکه بتوانید یک مدل را دقیق تنظیم کنید، باید یک مجموعه داده مخصوص کار را پیدا کنید. یکی از مجموعه دادههایی که معمولا استفاده میشود عبارت است از مجموعه داده مشترک Crawl. مجموعه Common Crawl حاوی پتابایت داده است که از سال 2008 به طور منظم جمعآوری شده است و حاوی دادههای خام صفحه وب، عصارههای فراداده و عصاره متن است. علاوه بر تعیین اینکه کدام مجموعه داده باید استفاده شود، پاکسازی و پردازش داده ها مطابق با نیاز خاص تنظیم دقیق مورد نیاز است.
ما اخیراً با مشتری کار کردیم که میخواست زیرمجموعهای از آخرین مجموعه داده Common Crawl را پیش پردازش کند و سپس LLM خود را با دادههای پاکشده تنظیم کند. مشتری به دنبال این بود که چگونه می تواند به مقرون به صرفه ترین راه در AWS به این هدف دست یابد. پس از بحث در مورد الزامات، استفاده از آن را توصیه می کنیم آمازون EMR بدون سرور به عنوان پلت فرم آنها برای پیش پردازش داده ها. EMR Serverless برای پردازش داده در مقیاس بزرگ مناسب است و نیاز به تعمیر و نگهداری زیرساخت را از بین می برد. از نظر هزینه، فقط بر اساس منابع و مدت زمان استفاده شده برای هر کار هزینه می گیرد. مشتری توانست صدها TB داده را در عرض یک هفته با استفاده از EMR Serverless پیش پردازش کند. بعد از اینکه آنها داده ها را از قبل پردازش کردند، استفاده کردند آمازون SageMaker برای تنظیم دقیق LLM.
در این پست، ما شما را در مورد استفاده مشتری و معماری استفاده شده راهنمایی می کنیم.
در بخشهای بعدی، ابتدا مجموعه داده Common Crawl و نحوه کاوش و فیلتر کردن دادههای مورد نیاز را معرفی میکنیم. آمازون آتنا فقط برای اندازه داده ای که اسکن می کند هزینه دریافت می کند و برای کاوش و فیلتر کردن سریع داده ها استفاده می شود، در حالی که مقرون به صرفه است. EMR Serverless گزینه ای مقرون به صرفه و بدون تعمیر و نگهداری برای پردازش داده های Spark ارائه می دهد و برای پردازش داده های فیلتر شده استفاده می شود. بعد، استفاده می کنیم Amazon SageMaker JumpStart برای تنظیم دقیق مدل لاما 2 با مجموعه داده از پیش پردازش شده SageMaker JumpStart مجموعهای از راهحلها را برای رایجترین موارد استفاده ارائه میکند که میتوانند تنها با چند کلیک اجرا شوند. برای تنظیم دقیق یک LLM مانند Llama 2 نیازی به نوشتن هیچ کدی ندارید. در نهایت، مدل تنظیم شده را با استفاده از آمازون SageMaker و تفاوت در خروجی متن برای همان سوال را بین مدل اصلی و دقیق Llama 2 مقایسه کنید.
نمودار زیر معماری این راه حل را نشان می دهد.
قبل از فرو رفتن عمیق در جزئیات راه حل، مراحل پیش نیاز زیر را کامل کنید:
Common Crawl یک مجموعه داده پیکر باز است که با خزیدن بیش از 50 میلیارد صفحه وب به دست می آید. این شامل حجم عظیمی از داده های بدون ساختار در چندین زبان است که از سال 2008 شروع شده و به سطح پتابایت می رسد. به طور مداوم به روز می شود.
همانطور که در نمودار زیر نشان داده شده است، در آموزش GPT-3، مجموعه داده Common Crawl 60٪ از داده های آموزشی آن را تشکیل می دهد (منبع: مدل های زبان یادگیرندگان کمی هستند).
یکی دیگر از مجموعه داده های مهم قابل ذکر است مجموعه داده C4. C4، مخفف Colossal Clean Crawled Corpus، مجموعه داده ای است که از پس پردازش مجموعه داده Common Crawl مشتق شده است. در مقاله LLaMA متا، آنها مجموعه دادههای مورد استفاده را مشخص کردند که Common Crawl 67٪ (با استفاده از 3.3 ترابایت داده) و C4 برای 15٪ (با استفاده از 783 گیگابایت داده) را به خود اختصاص داده است. این مقاله بر اهمیت ترکیب دادههای پیشپردازششده متفاوت برای افزایش عملکرد مدل تأکید میکند. علیرغم اینکه داده های اصلی C4 بخشی از Common Crawl هستند، متا نسخه پردازش مجدد این داده ها را انتخاب کرد.
در این بخش، روشهای متداول تعامل، فیلتر کردن و پردازش مجموعه داده مشترک Crawl را پوشش میدهیم.
مجموعه داده خام Common Crawl شامل سه نوع فایل داده است: داده خام صفحه وب (WARC)، ابرداده (WAT) و استخراج متن (WET).
دادههای جمعآوریشده پس از سال 2013 در قالب WARC ذخیره میشوند و شامل ابرداده مربوطه (WAT) و دادههای استخراج متن (WET) است. مجموعه داده در آمازون S3 قرار دارد و به صورت ماهانه به روز می شود و می توان مستقیماً از طریق آن به آن دسترسی داشت بازار AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzمجموعه داده Common Crawl همچنین یک جدول شاخص برای فیلتر کردن داده ها ارائه می دهد که cc-index-table نامیده می شود.
جدول cc-index نمایه ای از داده های موجود است که فهرستی مبتنی بر جدول از فایل های WARC ارائه می دهد. این امکان جستجوی آسان اطلاعات را فراهم می کند، مانند اینکه کدام فایل WARC با یک URL خاص مطابقت دارد.
به عنوان مثال، می توانید یک جدول Athena برای ترسیم داده های cc-index با کد زیر ایجاد کنید:
دستورات SQL قبلی نحوه ایجاد جدول Athena، افزودن پارتیشن ها و اجرای پرس و جو را نشان می دهد.
داده ها را از مجموعه داده Common Crawl فیلتر کنید
همانطور که از دستور create table SQL می بینید، چندین فیلد وجود دارد که می تواند به فیلتر کردن داده ها کمک کند. به عنوان مثال، اگر می خواهید تعداد اسناد چینی را در یک دوره خاص دریافت کنید، دستور SQL می تواند به صورت زیر باشد:
اگر می خواهید پردازش بیشتری انجام دهید، می توانید نتایج را در سطل S3 دیگری ذخیره کنید.
تجزیه و تحلیل داده های فیلتر شده
La مخزن مشترک Crawl GitHub چندین مثال PySpark برای پردازش داده های خام ارائه می دهد.
بیایید به یک مثال از دویدن نگاه کنیم server_count.py (نمونه اسکریپت ارائه شده توسط Common Crawl GitHub repo) روی داده های موجود در s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
ابتدا به یک محیط Spark مانند EMR Spark نیاز دارید. به عنوان مثال، می توانید یک آمازون EMR را روی خوشه EC2 راه اندازی کنید us-east-1 (چون مجموعه داده در us-east-1). استفاده از EMR در خوشه EC2 می تواند به شما در انجام آزمایشات قبل از ارسال کار به محیط تولید کمک کند.
پس از راهاندازی EMR در خوشه EC2، باید یک ورود SSH به گره اصلی خوشه انجام دهید. سپس محیط پایتون را بسته بندی کنید و اسکریپت را ارسال کنید (به قسمت مراجعه کنید مستندات کوندا برای نصب Miniconda):
پردازش همه مراجع در warc.path ممکن است زمان ببرد. برای اهداف نمایشی، می توانید زمان پردازش را با استراتژی های زیر بهبود بخشید:
- فایل را دانلود کنید
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzدر دستگاه محلی خود، آن را از حالت فشرده خارج کنید و سپس آن را در HDFS یا Amazon S3 آپلود کنید. این به این دلیل است که فایل .gzip قابل تقسیم نیست. برای پردازش موازی این فایل باید آن را از حالت فشرده خارج کنید. - اصلاح کنید
warc.pathفایل، اکثر خطوط آن را حذف کنید، و فقط دو خط را نگه دارید تا کار بسیار سریعتر اجرا شود.
پس از اتمام کار، می توانید نتیجه را در آن مشاهده کنید s3://xxxx-common-crawl/output/، در قالب پارکت.
پیاده سازی منطق دارای سفارشی
مخزن Common Crawl GitHub یک رویکرد مشترک برای پردازش فایل های WARC ارائه می دهد. به طور کلی، شما می توانید تمدید کنید CCSparkJob برای نادیده گرفتن یک روش واحد (process_record) که برای بسیاری از موارد کافی است.
بیایید به یک مثال نگاه کنیم تا بررسی فیلم های اخیر را در سایت IMDB دریافت کنیم. ابتدا باید فایل های موجود در سایت IMDB را فیلتر کنید:
سپس میتوانید فهرستهای فایل WARC را که حاوی دادههای بررسی IMDB هستند، دریافت کنید و نام فایلهای WARC را بهعنوان فهرست در یک فایل متنی ذخیره کنید.
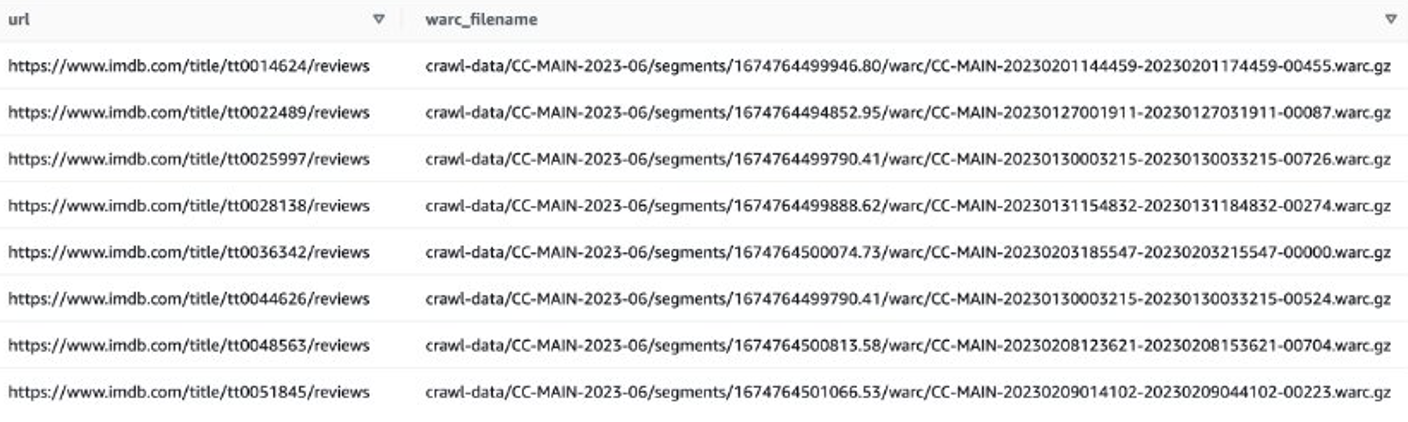
از طرف دیگر، می توانید از EMR Spark برای دریافت لیست فایل های WARC و ذخیره آن در Amazon S3 استفاده کنید. مثلا:
فایل خروجی باید شبیه به s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
مرحله بعدی استخراج نظرات کاربران از این فایل های WARC است. می توانید تمدید کنید CCSparkJob برای نادیده گرفتن process_record() روش:
می توانید اسکریپت قبلی را به عنوان imdb_extractor.py ذخیره کنید که در مراحل زیر از آن استفاده خواهید کرد. بعد از اینکه داده ها و اسکریپت ها را آماده کردید، می توانید از EMR Serverless برای پردازش داده های فیلتر شده استفاده کنید.
EMR بدون سرور
EMR Serverless یک گزینه استقرار بدون سرور برای اجرای برنامه های تجزیه و تحلیل داده های بزرگ با استفاده از چارچوب های منبع باز مانند Apache Spark و Hive بدون پیکربندی، مدیریت و مقیاس بندی خوشه ها یا سرورها است.
با EMR Serverless، میتوانید بارهای کاری تجزیه و تحلیل را در هر مقیاسی با مقیاس خودکار اجرا کنید که اندازه منابع را در چند ثانیه تغییر میدهد تا حجم دادهها و نیازهای پردازش در حال تغییر را برآورده کند. EMR Serverless به طور خودکار منابع را بالا و پایین می کند تا ظرفیت مناسبی را برای برنامه شما فراهم کند و شما فقط برای آنچه استفاده می کنید هزینه می پردازید.
پردازش مجموعه داده Common Crawl عموماً یک کار پردازشی یکباره است و آن را برای بارهای کاری بدون سرور EMR مناسب می کند.
یک برنامه بدون سرور EMR ایجاد کنید
می توانید یک برنامه بدون سرور EMR در کنسول EMR Studio ایجاد کنید. مراحل زیر را کامل کنید:
- در کنسول EMR Studio، را انتخاب کنید اپلیکیشنها زیر بدون سرور در صفحه ناوبری
- را انتخاب کنید ایجاد اپلیکیشن.

- یک نام برای برنامه ارائه دهید و یک نسخه آمازون EMR را انتخاب کنید.

- اگر دسترسی به منابع VPC مورد نیاز است، یک تنظیم شبکه سفارشی شده اضافه کنید.

- را انتخاب کنید ایجاد اپلیکیشن.
سپس محیط بدون سرور Spark شما آماده خواهد شد.
قبل از اینکه بتوانید یک کار را به EMR Spark Serverless ارسال کنید، هنوز باید یک نقش اجرایی ایجاد کنید. رجوع شود به شروع کار با Amazon EMR Serverless برای جزئیات بیشتر.
پردازش دادههای Common Crawl با EMR Serverless
پس از آماده شدن برنامه EMR Spark Serverless، مراحل زیر را برای پردازش داده ها انجام دهید:
- یک محیط Conda آماده کنید و آن را در Amazon S3 آپلود کنید، که به عنوان محیط در EMR Spark Serverless استفاده خواهد شد.
- اسکریپت هایی را که باید اجرا شوند در یک سطل S3 آپلود کنید. در مثال زیر دو اسکریپت وجود دارد:
- imbd_extractor.py - منطق سفارشی برای استخراج محتویات از مجموعه داده. مطالب را می توانید در ابتدای این پست پیدا کنید.
- cc-pyspark/sparkcc.py – مثال چارچوب PySpark از مخزن مشترک Crawl GitHub، که درج آن ضروری است.
- کار PySpark را به Spark بدون سرور EMR ارسال کنید. برای اجرای این مثال در محیط خود پارامترهای زیر را تعریف کنید:
- اپلیکیشن-id – شناسه اپلیکیشن اپلیکیشن بدون سرور EMR شما.
- execution-role-arn - نقش اجرای بدون سرور EMR شما. برای ایجاد آن رجوع شود یک نقش زمان اجرای کار ایجاد کنید.
- محل فایل WARC – مکان فایل های WARC شما.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtحاوی لیست فایل های WARC فیلتر شده است که قبلاً در این پست به دست آورده اید. - spark.sql.warehouse.dir – مکان پیش فرض انبار (از دایرکتوری S3 خود استفاده کنید).
- spark.archives – محل S3 محیط آماده شده کوندا.
- spark.submit.pyFiles – اسکریپت آماده شده PySpark sparkcc.py.
کد زیر را ببینید:
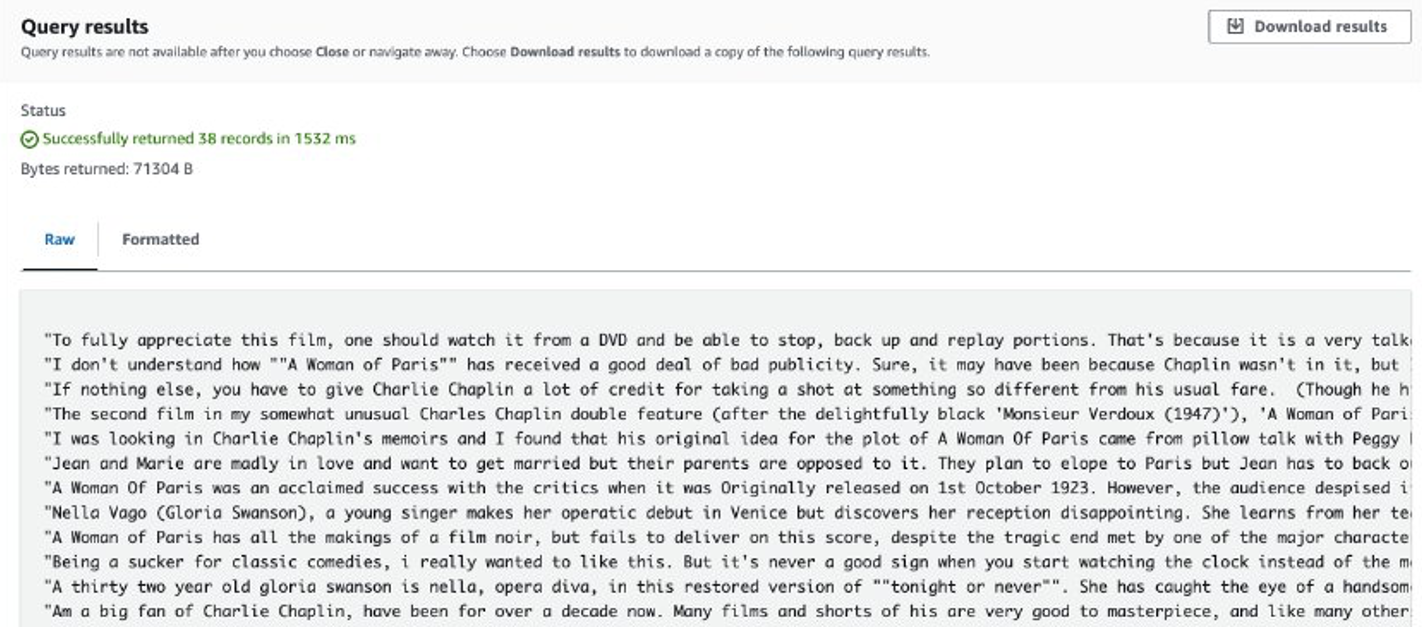
پس از اتمام کار، بررسی های استخراج شده در آمازون S3 ذخیره می شود. برای بررسی محتویات، می توانید از Amazon S3 Select استفاده کنید، همانطور که در تصویر زیر نشان داده شده است.
ملاحظات
موارد زیر نکاتی هستند که باید در هنگام برخورد با حجم عظیمی از داده ها با کد سفارشی در نظر گرفته شوند:
- برخی از کتابخانه های شخص ثالث پایتون ممکن است در Conda در دسترس نباشند. در چنین مواقعی می توانید برای ساخت محیط اجرای PySpark به محیط مجازی پایتون سوئیچ کنید.
- اگر حجم عظیمی از داده برای پردازش وجود دارد، سعی کنید چندین برنامه کاربردی Spark بدون سرور EMR را برای موازی کردن آن ایجاد و استفاده کنید. هر برنامه با زیر مجموعه ای از لیست های فایل سروکار دارد.
- ممکن است هنگام فیلتر کردن یا پردازش داده های Common Crawl با مشکل کندی آمازون S3 مواجه شوید. این به این دلیل است که سطل S3 که داده ها را ذخیره می کند در دسترس عموم است و سایر کاربران ممکن است به طور همزمان به داده ها دسترسی داشته باشند. برای کاهش این مشکل، میتوانید یک مکانیسم امتحان مجدد اضافه کنید یا دادههای خاص را از سطل Common Crawl S3 به سطل خود همگامسازی کنید.
Llama 2 را با SageMaker تنظیم کنید
پس از آماده شدن داده ها، می توانید مدل Llama 2 را با آن تنظیم کنید. شما می توانید این کار را با استفاده از SageMaker JumpStart، بدون نوشتن هیچ کدی انجام دهید. برای اطلاعات بیشتر مراجعه کنید Llama 2 را برای تولید متن در Amazon SageMaker JumpStart تنظیم کنید.
در این سناریو، شما یک تنظیم دقیق تطبیق دامنه را انجام می دهید. با این مجموعه داده، ورودی از یک فایل CSV، JSON یا TXT تشکیل شده است. شما باید تمام داده های بررسی را در یک فایل TXT قرار دهید. برای انجام این کار، می توانید یک کار ساده Spark را به EMR Spark Serverless ارسال کنید. نمونه کد زیر را ببینید:
پس از آماده سازی داده های آموزشی، مکان داده را برای وارد کنید مجموعه داده های آموزشی، پس از آن را انتخاب کنید قطار.
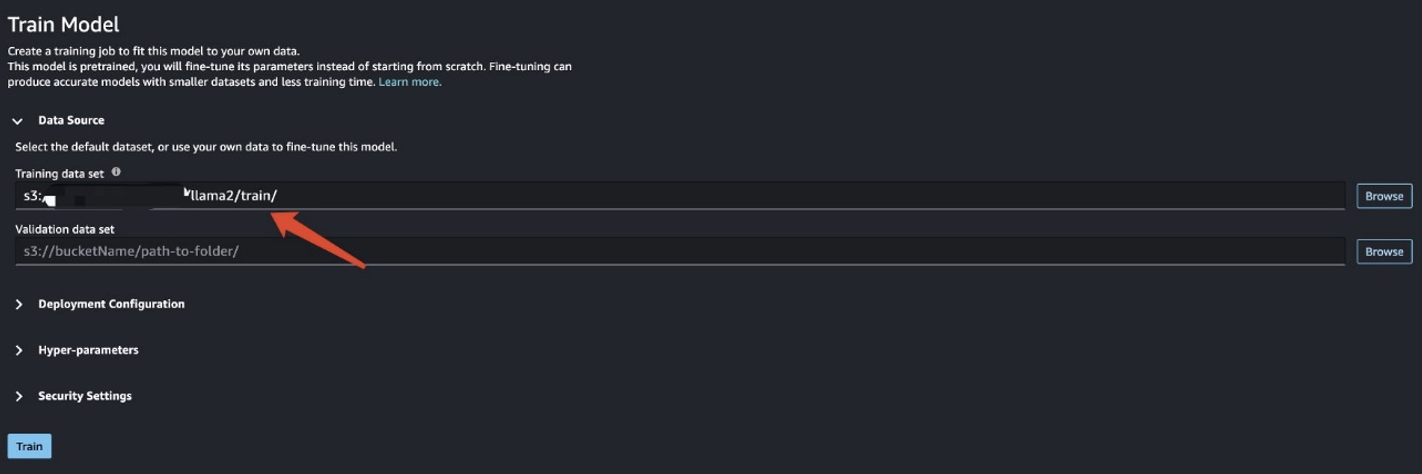
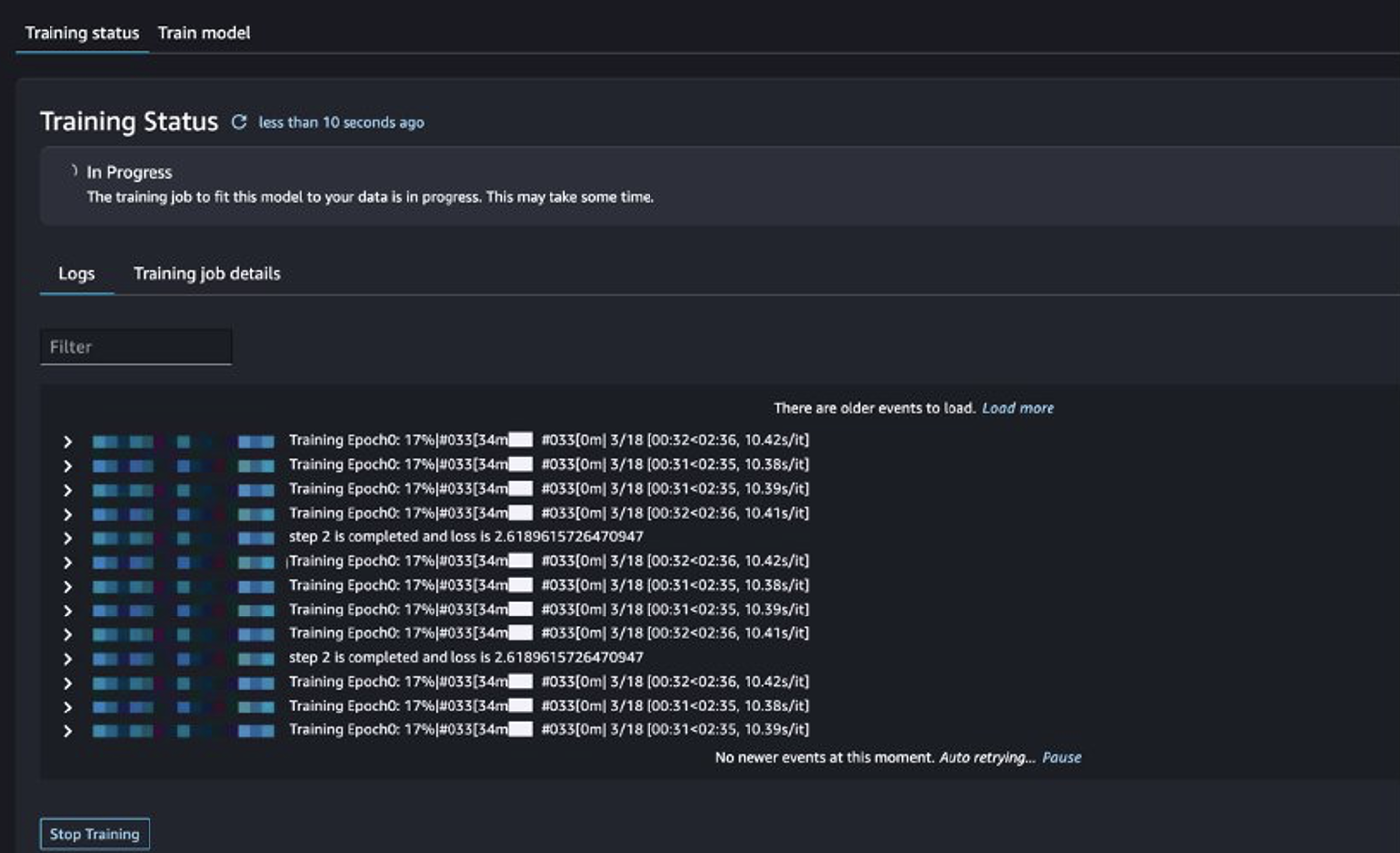
می توانید وضعیت شغلی آموزشی را پیگیری کنید.
مدل دقیق تنظیم شده را ارزیابی کنید
پس از اتمام آموزش، انتخاب کنید گسترش در SageMaker JumpStart برای استقرار مدل دقیق تنظیم شده شما.

پس از استقرار مدل با موفقیت، انتخاب کنید نوت بوک را باز کنید، که شما را به یک نوت بوک آماده شده Jupyter هدایت می کند که در آن می توانید کد پایتون خود را اجرا کنید.

می توانید از تصویر Data Science 2.0 و هسته Python 3 برای نوت بوک استفاده کنید.
سپس می توانید مدل تنظیم شده و مدل اصلی را در این نوت بوک ارزیابی کنید.
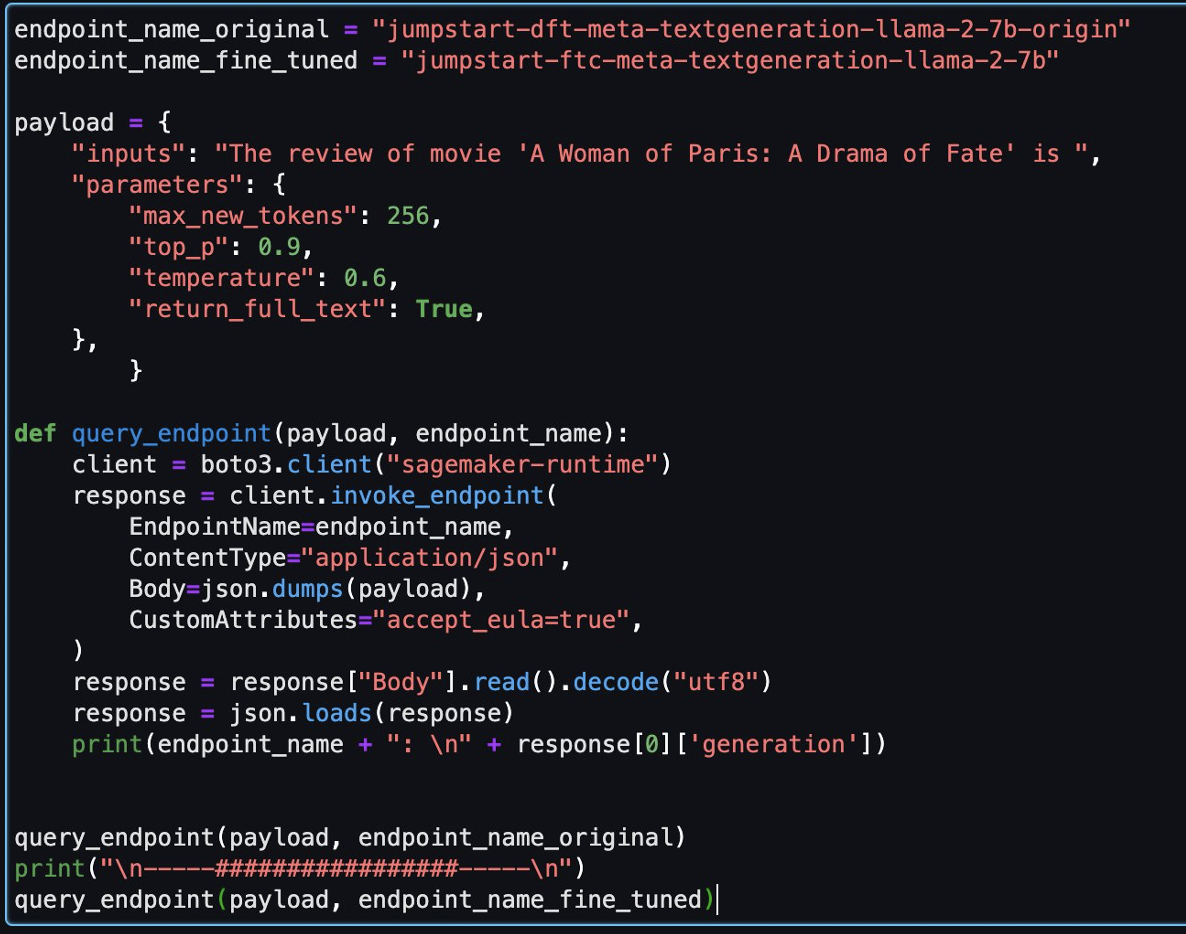
در زیر دو پاسخ ارائه شده توسط مدل اصلی و مدل دقیق تنظیم شده برای یک سوال ارائه شده است.

ما هر دو مدل را با یک جمله ارائه کردیم: «بررسی فیلم «یک زن از پاریس: درام سرنوشت» است و اجازه دهید جمله را کامل کنند.
مدل اصلی جملات بی معنی را خروجی می دهد:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
در مقابل، خروجی های مدل تنظیم شده بیشتر شبیه یک نقد فیلم است:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
بدیهی است که مدل تنظیم شده در این سناریوی خاص بهتر عمل می کند.
پاک کردن
پس از اتمام این تمرین، مراحل زیر را برای پاکسازی منابع خود انجام دهید:
- سطل S3 را حذف کنید که مجموعه داده پاک شده را ذخیره می کند.
- محیط بدون سرور EMR را متوقف کنید.
- نقطه پایانی SageMaker را حذف کنید که میزبان مدل LLM است.
- دامنه SageMaker را حذف کنید که نوت بوک های شما را اجرا می کند.
برنامه ای که ایجاد کرده اید باید به طور پیش فرض پس از 15 دقیقه عدم فعالیت به طور خودکار متوقف شود.
به طور کلی، شما نیازی به تمیز کردن محیط آتنا ندارید زیرا زمانی که از آن استفاده نمی کنید هزینه ای دریافت نمی کنید.
نتیجه
در این پست، مجموعه داده Common Crawl و نحوه استفاده از EMR Serverless را برای پردازش داده ها برای تنظیم دقیق LLM معرفی کردیم. سپس نحوه استفاده از SageMaker JumpStart را برای تنظیم دقیق LLM و استقرار آن بدون هیچ کدی نشان دادیم. برای موارد استفاده بیشتر از EMR Serverless، مراجعه کنید آمازون EMR بدون سرور برای کسب اطلاعات بیشتر در مورد مدل های میزبانی و تنظیم دقیق در Amazon SageMaker JumpStart، به مستندات Sagemaker JumpStart.
درباره نویسنده
 شیجیان تنگ یک معمار راه حل متخصص تجزیه و تحلیل در خدمات وب آمازون است.
شیجیان تنگ یک معمار راه حل متخصص تجزیه و تحلیل در خدمات وب آمازون است.
 متیو لیم یک مدیر ارشد معماری راه حل در خدمات وب آمازون است.
متیو لیم یک مدیر ارشد معماری راه حل در خدمات وب آمازون است.
 دالی خو یک معمار راه حل متخصص تجزیه و تحلیل در خدمات وب آمازون است.
دالی خو یک معمار راه حل متخصص تجزیه و تحلیل در خدمات وب آمازون است.
 یوانجون شیائو یک معمار ارشد راه حل در خدمات وب آمازون است.
یوانجون شیائو یک معمار ارشد راه حل در خدمات وب آمازون است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :است
- :نه
- :جایی که
- $UP
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- ٪۱۰۰
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- قادر
- درباره ما
- دسترسی
- قابل دسترسی است
- در دسترس
- حسابداری (Accounting)
- حساب ها
- رسیدن
- فعال کردن
- اضافه کردن
- اضافه
- افریقا
- پس از
- معرفی
- اجازه می دهد تا
- همچنین
- شگفت انگیز
- آمازون
- آمازون EMR
- آمازون SageMaker
- Amazon SageMaker JumpStart
- آمازون خدمات وب
- مقدار
- مقدار
- an
- علم تجزیه و تحلیل
- و
- دیگر
- هر
- آپاچی
- جرقه آپاچی
- کاربرد
- برنامه های کاربردی
- روش
- معماری
- هستند
- AS
- At
- استرالیا
- اتوماتیک
- بطور خودکار
- در دسترس
- AWS
- زمینه
- مستقر
- اساس
- BE
- خوشگل
- زیرا
- تبدیل شدن به
- قبل از
- شروع
- بودن
- بهتر
- میان
- بزرگ
- بزرگ داده
- بیلیون
- بدن
- هر دو
- ساختن
- by
- نام
- CAN
- می توانید دریافت کنید
- ظرفیت
- حمل
- مورد
- موارد
- متغیر
- شخصیت
- بار
- بررسی
- چینی
- را انتخاب کنید
- کلاس
- تمیز
- مشتری
- خوشه
- رمز
- COM
- مشترک
- عموما
- مقايسه كردن
- کامل
- پیکربندی
- در نظر بگیرید
- تشکیل شده است
- کنسول
- به طور مداوم
- شامل
- شامل
- محتویات
- به طور مداوم
- کنتراست
- متناظر
- مطابقت دارد
- هزینه
- مقرون به صرفه
- میتوانست
- تعداد دفعات مشاهده
- پوشش
- ایجاد
- ایجاد شده
- سفارشی
- مشتری
- سفارشی
- داده ها
- تجزیه و تحلیل داده ها
- پردازش داده ها
- علم اطلاعات
- مجموعه داده ها
- دیویس
- معامله
- معاملات
- عمیق
- به طور پیش فرض
- تعريف كردن
- نسخه ی نمایشی
- نشان دادن
- نشان
- گسترش
- مستقر
- گسترش
- نشات گرفته
- با وجود
- جزئیات
- تعیین
- نمودار
- تفاوت
- متفاوت است
- جهت دار
- مستقیما
- بحث در مورد
- شیرجه رفتن
- do
- اسناد و مدارک
- دامنه
- حوزه
- دونالد
- آیا
- پایین
- درام
- راننده
- مدت
- در طی
- هر
- پیش از آن
- ساده
- حذف می شود
- تأکید می کند
- رویارویی
- مهندسی
- افزایش
- وارد
- محیط
- اتر (ETH)
- ارزیابی
- مثال
- مثال ها
- اعدام
- ورزش
- موجود
- وجود دارد
- اکتشاف
- کشف
- گسترش
- خارجی
- عصاره
- استخراج
- عصاره ها
- آبشار
- غلط
- سریعتر
- سرنوشت
- ویژه
- کمی از
- زمینه
- پرونده
- فایل ها
- فیلتر
- فیلتر
- سرانجام
- پیدا کردن
- پایان
- نام خانوادگی
- پیروی
- به دنبال آن است
- برای
- قالب
- یافت
- چارچوب
- چارچوب
- از جانب
- بیشتر
- سوالات عمومی
- عموما
- مولد
- نسل
- دریافت کنید
- رفتن
- GitHub
- راهنمایی
- آیا
- کمک
- کندو
- میزبانی وب
- میزبان
- چگونه
- چگونه
- اما
- HTML
- HTTPS
- صدها نفر
- i
- IAM
- ID
- if
- نشان می دهد
- تصویر
- واردات
- مهم
- بهبود
- in
- مشمول
- شامل
- گنجاندن
- افزایش
- شاخص
- اطلاعات
- شالوده
- ورودی
- ورودی
- نصب
- تعامل
- به
- معرفی
- معرفی
- موضوع
- IT
- ITS
- جک
- کار
- شغل ها
- json
- نوت بوک ژوپیتر
- تنها
- نگاه داشتن
- کلید
- زبان
- زبان ها
- در مقیاس بزرگ
- آخرین
- راه اندازی
- راه اندازی
- رهبری
- اجازه
- سطح
- کتابخانه ها
- پسندیدن
- محدود
- خطوط
- فهرست
- لیست
- پشم لاما
- llm
- محلی
- واقع شده
- محل
- منطق
- ورود
- نگاه کنيد
- به دنبال
- مراجعه
- دستگاه
- نگهداری
- ساخت
- ساخت
- مدیر
- مدیریت
- بسیاری
- نقشه
- عظیم
- ممکن است..
- مکانیزم
- دیدار
- ملاقات
- ذکر
- متا
- متاداده
- روش
- دقیقه
- کاهش
- مدل
- مدل
- ماهیانه
- بیش
- اکثر
- سینما
- فیلم ها
- بسیار
- چندگانه
- نام
- نام
- جهت یابی
- لازم
- نیاز
- شبکه
- جدید
- بعد
- نه
- گره
- دفتر یادداشت
- نوت بوک
- به دست آمده
- اکتبر
- of
- on
- ONE
- فقط
- باز کن
- منبع باز
- گزینه
- or
- اصلی
- دیگر
- خارج
- مشخص شده
- تولید
- خروجی
- روی
- باطل کردن
- خود
- بسته
- بسته
- قطعه
- مقاله
- موازی
- پارامترهای
- پاریس
- بخش
- مسیر
- راه ها
- پرداخت
- مردم
- کارایی
- اجرای
- انجام می دهد
- دوره
- پتابایت
- از پا افتادن
- عکاس
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- طرح
- نقطه
- محبوب
- پست
- صفحه اصلی
- پیش
- ماقبل
- آماده
- آماده شده
- اصلی
- روند
- پردازش
- در حال پردازش
- تولید
- پرسیدن
- ارائه
- ارائه
- فراهم می کند
- ارائه
- عمومی
- اهداف
- قرار دادن
- پــایتــون
- پرس و جو
- سوال
- به سرعت
- خام
- داده های خام
- رسیدن به
- خواندن
- اماده
- اخیر
- تازه
- توصیه می شود
- رکورد
- مراجعه
- منابع
- به طور منظم
- ارتباط
- منتشر شد
- تعمیر
- جایگزین کردن
- درخواست
- ضروری
- مورد نیاز
- منابع
- پاسخ
- پاسخ
- نتیجه
- نتایج
- این فایل نقد می نویسید:
- بررسی
- راست
- نقش
- روری
- دویدن
- در حال اجرا
- اجرا می شود
- حکیم ساز
- همان
- ذخیره
- مقیاس
- مقیاس ها
- مقیاس گذاری
- اسکن
- سناریو
- علم
- خط
- اسکریپت
- ثانیه
- بخش
- بخش
- دیدن
- بخش
- را انتخاب کنید
- خود
- ارشد
- جمله
- بدون سرور
- سرورها
- خدمات
- تنظیم
- محیط
- چند
- او
- کوتاه
- باید
- نشان داده شده
- اهمیت
- مشابه
- پس از
- تنها
- سایت
- اندازه
- کاهش سرعت
- قطعه
- So
- راه حل
- مزایا
- سوپ
- منبع
- جرقه
- متخصص
- خاص
- SQL
- SSH
- آغاز شده
- راه افتادن
- بیانیه
- اظهارات
- وضعیت
- گام
- مراحل
- هنوز
- توقف
- opbevare
- ذخیره شده
- پرده
- داستان
- ساده
- استراتژی ها
- رشته
- استودیو
- ارسال
- ارسال
- موفقیت
- چنین
- کافی
- مناسب
- گزینه
- همگام سازی
- جدول
- گرفتن
- هدف
- کار
- وظایف
- جریان تنسور
- قوانین و مقررات
- تست
- متن
- تولید متن
- که
- La
- شان
- آنها
- سپس
- آنجا.
- اینها
- آنها
- شخص ثالث
- این
- سه
- از طریق
- زمان
- برچسب زمان
- به
- مسیر
- آموزش
- سفر
- درست
- امتحان
- دو
- انواع
- زیر
- بدون ساختار
- به روز شده
- URL
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- نقد های کاربران
- کاربران
- با استفاده از
- با استفاده از
- نسخه
- مجازی
- جلد
- راه رفتن
- می خواهم
- خواسته
- انبار کالا
- بود
- مسیر..
- راه
- we
- وب
- خدمات وب
- هفته
- خوب
- چی
- چه زمانی
- در حالیکه
- که
- در حین
- WHO
- حیوانات وحشی
- اراده
- ویلیام
- با
- در داخل
- بدون
- زن
- مشغول به کار
- با ارزش
- نوشتن
- نوشته
- بازده
- شما
- شما
- زفیرنت