تصویر توسط نویسنده
دوره ها و منابع زیادی در مورد یادگیری ماشین و علم داده وجود دارد، اما در مورد مهندسی داده بسیار اندک. این چند سوال را ایجاد می کند. آیا رشته سختی است؟ آیا دستمزد کم ارائه می دهد؟ آیا به اندازه سایر نقش های فناوری هیجان انگیز در نظر گرفته نمی شود؟ با این حال، واقعیت این است که بسیاری از شرکتها فعالانه به دنبال استعدادهای مهندسی داده هستند و حقوق قابل توجهی را ارائه میدهند که گاهی بیش از 200,000 دلار آمریکا است. مهندسان داده نقش مهمی را به عنوان معماران پلتفرم های داده ایفا می کنند و سیستم های بنیادی را طراحی و ایجاد می کنند که دانشمندان داده و کارشناسان یادگیری ماشین را قادر می سازد تا به طور موثر عمل کنند.
برای رفع این شکاف صنعت، DataTalkClub یک بوت کمپ متحول کننده و رایگان را معرفی کرده است.زومکمپ مهندسی داده". این دوره برای توانمندسازی افراد مبتدی یا حرفه ای که به دنبال تغییر شغل هستند، با مهارت های ضروری و تجربه عملی در مهندسی داده طراحی شده است.
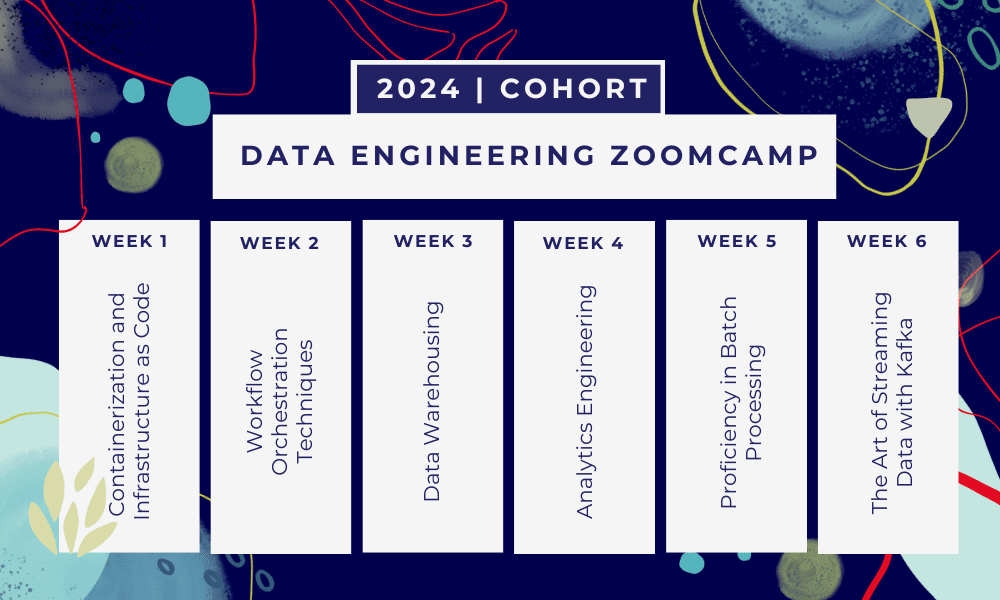
این یک بوت کمپ 6 هفته ای جایی که شما از طریق دوره های متعدد، مطالب خواندنی، کارگاه ها و پروژه ها یاد خواهید گرفت. در پایان هر ماژول، تکالیفی به شما داده می شود تا آنچه را که یاد گرفته اید تمرین کنید.
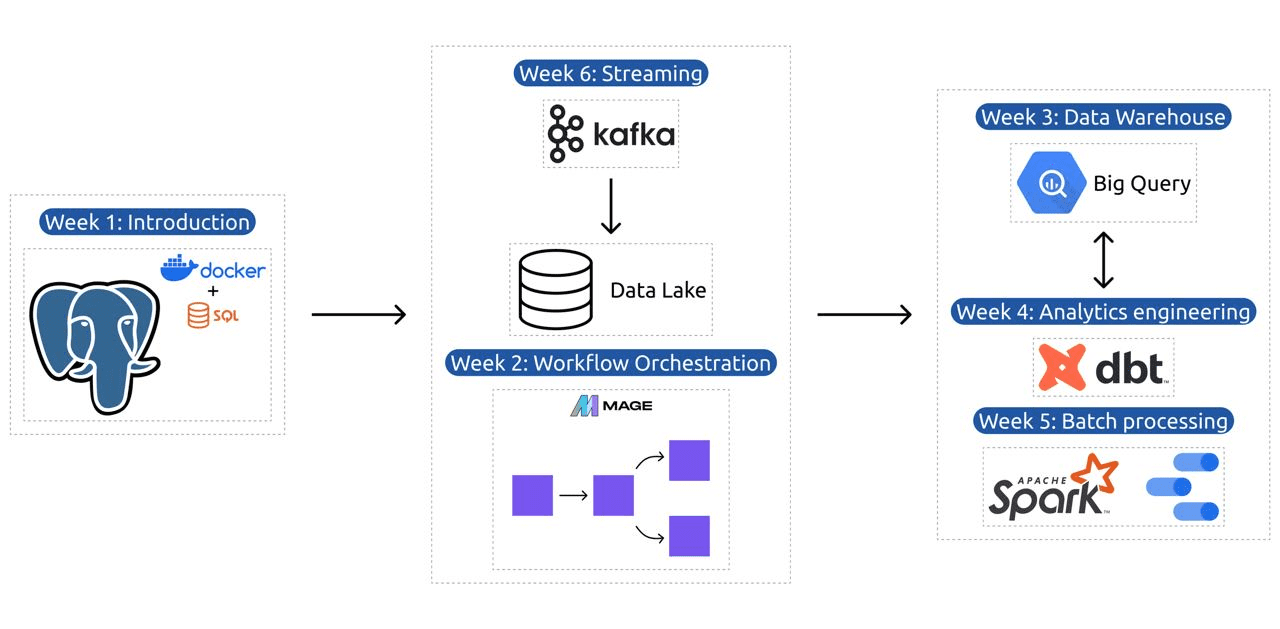
- هفته 1: مقدمه ای بر GCP، Docker، Postgres، Terraform و راه اندازی محیط.
- هفته 2: ارکستراسیون گردش کار با Mage.
- هفته 3: ذخیره سازی داده با BigQuery و یادگیری ماشینی با BigQuery.
- هفته 4: مهندس تحلیل با dbt، Google Data Studio و Metabase.
- هفته 5: پردازش دسته ای با Spark.
- هفته 6: استریم با کافکا.
تصویر از DataTalksClub/data-engineering-zoomcamp
برنامه درسی شامل 6 ماژول، 2 کارگاه و پروژه ای است که همه چیز مورد نیاز برای تبدیل شدن به یک مهندس داده حرفه ای را پوشش می دهد.
ماژول 1: تسلط بر کانتینرسازی و زیرساخت به عنوان کد
در این ماژول، شما با Docker و Postgres آشنا خواهید شد، از اصول اولیه شروع کرده و از طریق آموزش های دقیق در مورد ایجاد خطوط لوله داده، اجرای Postgres با Docker و موارد دیگر پیشرفت خواهید کرد.
این ماژول همچنین ابزارهای ضروری مانند pgAdmin، Docker-compose، و موضوعات بازخوانی SQL را با محتوای اختیاری در شبکه Docker و یک راهنمای ویژه برای کاربران لینوکس زیرسیستم ویندوز پوشش میدهد. در پایان، این دوره شما را با GCP و Terraform آشنا می کند، که درک جامعی از کانتینرسازی و زیرساخت به عنوان یک کد ضروری برای محیط های مبتنی بر ابر مدرن ارائه می دهد.
ماژول 2: تکنیک های ارکستراسیون گردش کار
این ماژول کاوش عمیق Mage را ارائه می دهد، یک چارچوب ترکیبی منبع باز مبتکرانه برای تبدیل و ادغام داده ها. این ماژول با اصول اولیه ارکستراسیون گردش کار شروع می شود، به تمرینات عملی با Mage می رسد، از جمله راه اندازی آن از طریق Docker و ایجاد خطوط لوله ETL از API به Postgres و Google Cloud Storage (GCS) و سپس به BigQuery.
ترکیب این ماژول از ویدئوها، منابع و وظایف عملی، تجربه یادگیری جامع را تضمین میکند و یادگیرندگان را با مهارتهایی برای مدیریت گردشهای کاری دادههای پیچیده با استفاده از Mage تجهیز میکند.
کارگاه 1: استراتژی های جذب داده
در اولین کارگاه شما بر ساخت خطوط لوله انتقال داده کارآمد مسلط خواهید شد. این کارگاه بر مهارت های ضروری مانند استخراج داده ها از API ها و فایل ها، عادی سازی و بارگذاری داده ها و تکنیک های بارگذاری افزایشی تمرکز دارد. پس از اتمام این کارگاه، شما قادر خواهید بود مانند یک مهندس ارشد داده خطوط انتقال داده کارآمد ایجاد کنید.
ماژول 3: انبار داده ها
این ماژول یک کاوش عمیق در ذخیره سازی و تجزیه و تحلیل داده ها است که بر روی ذخیره سازی داده ها با استفاده از BigQuery تمرکز دارد. این مفاهیم کلیدی مانند پارتیشن بندی و خوشه بندی را پوشش می دهد و به بهترین شیوه های BigQuery می پردازد. این ماژول به موضوعات پیشرفته، به ویژه ادغام یادگیری ماشین (ML) با BigQuery، برجسته کردن استفاده از SQL برای ML، و ارائه منابعی در مورد تنظیم هایپرپارامتر، پیش پردازش ویژگی ها و استقرار مدل، پیشرفت می کند.
ماژول 4: مهندسی تجزیه و تحلیل
ماژول مهندسی تجزیه و تحلیل بر ساخت یک پروژه با استفاده از dbt (ابزار ساخت داده) با یک انبار داده موجود، BigQuery یا PostgreSQL تمرکز دارد.
این ماژول راهاندازی dbt را در محیطهای ابری و محلی، معرفی مفاهیم مهندسی تحلیل، ETL در مقابل ELT و مدلسازی داده را پوشش میدهد. همچنین ویژگی های پیشرفته dbt مانند مدل های افزایشی، برچسب ها، قلاب ها و عکس های فوری را پوشش می دهد.
در پایان، این ماژول تکنیکهایی را برای تجسم دادههای تبدیلشده با استفاده از ابزارهایی مانند Google Data Studio و Metabase معرفی میکند و منابعی را برای عیبیابی و بارگذاری کارآمد دادهها فراهم میکند.
ماژول 5: مهارت در پردازش دسته ای
این ماژول پردازش دستهای با استفاده از Apache Spark را پوشش میدهد، با مقدمهای برای پردازش دستهای و Spark، همراه با دستورالعملهای نصب برای Windows، Linux و MacOS شروع میشود.
این شامل کاوش Spark SQL و DataFrames، آمادهسازی دادهها، انجام عملیات SQL و درک اجزای داخلی Spark است. در نهایت، با اجرای Spark در فضای ابری و ادغام Spark با BigQuery به پایان میرسد.
ماژول 6: هنر پخش جریانی داده ها با کافکا
این ماژول با مقدمه ای بر مفاهیم پردازش جریانی آغاز می شود و به دنبال آن کاوش عمیق کافکا، از جمله اصول آن، ادغام با Confluent Cloud، و کاربردهای عملی شامل تولیدکنندگان و مصرف کنندگان انجام می شود.
این ماژول همچنین پیکربندی و جریانهای کافکا را پوشش میدهد و به موضوعاتی مانند اتصال به جریان، آزمایش، پنجرهسازی و استفاده از Kafka ksqldb & Connect میپردازد. علاوه بر این، تمرکز خود را به محیطهای Python و JVM گسترش میدهد که شامل Faust برای پردازش جریان پایتون، Pyspark – Structured Streaming و Scala برای Kafka Streams میشود.
کارگاه 2: پردازش جریانی با SQL
شما یاد خواهید گرفت که داده های جریانی را با RisingWave پردازش و مدیریت کنید، که راه حلی مقرون به صرفه با تجربه ای به سبک PostgreSQL برای توانمندسازی برنامه های پردازش جریان شما ارائه می دهد.
پروژه: برنامه مهندسی داده در دنیای واقعی
هدف این پروژه پیاده سازی تمام مفاهیمی است که در این دوره آموخته ایم تا یک خط لوله داده سرتاسر بسازیم. شما برای ایجاد یک داشبورد متشکل از دو کاشی با انتخاب یک مجموعه داده، ایجاد خط لوله برای پردازش داده ها و ذخیره آن در دریاچه داده، ساخت یک خط لوله برای انتقال داده های پردازش شده از دریاچه داده به انبار داده، و تبدیل آن ایجاد خواهید کرد. داده های موجود در انبار داده و آماده سازی آن برای داشبورد و در نهایت ساخت داشبورد برای ارائه داده ها به صورت بصری.
جزئیات گروه 2024
- ثبت نام: اکنون ثبت نام کنید
- تاریخ شروع: 15 ژانویه 2024، ساعت 17:00 CET
- یادگیری خودگام با پشتیبانی هدایت شده
- پوشه کوهورت با تکالیف و ضرب الاجل
- سلامت Slack Community برای یادگیری همتایان
پیش نیازها
- مهارت های اولیه کدنویسی و خط فرمان
- بنیاد در SQL
- پایتون: مفید اما اجباری نیست
مربیان خبره ای که سفر شما را هدایت می کنند
- آنکوش خانا
- ویکتوریا پرز مولا
- الکسی گریگورف
- مت پالمر
- لوئیس اولیویرا
- مایکل شومیکر
به گروه 2024 ما بپیوندید و با یک جامعه مهندسی داده شگفت انگیز شروع به یادگیری کنید. با آموزش تخصصی، تجربه عملی و برنامه درسی متناسب با نیازهای صنعت، این بوت کمپ نه تنها شما را به مهارت های لازم مجهز می کند، بلکه شما را در خط مقدم مسیر شغلی پرسود و پر تقاضا قرار می دهد. امروز ثبت نام کنید و آرزوهای خود را به واقعیت تبدیل کنید!
عابد علی اعوان (@1abidaliawan) یک متخصص دانشمند داده معتبر است که عاشق ساخت مدل های یادگیری ماشینی است. در حال حاضر، او بر تولید محتوا و نوشتن وبلاگ های فنی در زمینه یادگیری ماشین و فناوری های علم داده تمرکز دارد. عابد دارای مدرک کارشناسی ارشد در رشته مدیریت فناوری و مدرک کارشناسی در رشته مهندسی مخابرات است. چشم انداز او ساخت یک محصول هوش مصنوعی با استفاده از یک شبکه عصبی نمودار برای دانش آموزانی است که با بیماری های روانی دست و پنجه نرم می کنند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 000
- 1
- ٪۱۰۰
- 17
- 2024
- a
- قادر
- درباره ما
- فعالانه
- علاوه بر این
- خطاب به
- پیشرفته
- پیشبرد
- پس از
- AI
- معرفی
- در امتداد
- همچنین
- شگفت انگیز
- an
- تحلیل
- تحلیلی
- علم تجزیه و تحلیل
- و
- و زیرساخت
- آپاچی
- جرقه آپاچی
- API
- رابط های برنامه کاربردی
- برنامه های کاربردی
- معماران
- هستند
- هنر
- AS
- At
- در دسترس
- مبانی
- BE
- شدن
- تبدیل شدن به
- مبتدی ها
- مفید
- بهترین
- بهترین شیوه
- بزرگ نمایی
- مخلوط
- وبلاگ ها
- هر دو
- ساختن
- بنا
- اما
- by
- کاریابی
- مشاغل
- مهندسان
- ابر
- فضای ذخیره ابری
- خوشه بندی
- رمز
- برنامه نویسی
- کوهورت
- انجمن
- شرکت
- تکمیل
- جامع
- مفاهیم
- نتیجه گیری می کند
- پیکر بندی
- اتصال
- اتصال
- در نظر گرفته
- شامل
- ساختن
- مصرف کنندگان
- شامل
- محتوا
- تولید محتوا
- دوره
- دوره
- را پوشش می دهد
- ایجاد
- ایجاد
- ایجاد
- بسیار سخت
- در حال حاضر
- برنامه تحصیلی
- داشبورد
- داده ها
- مهندس داده
- دریاچه دریاچه
- علم اطلاعات
- دانشمند داده
- ذخیره سازی داده ها
- انبار داده
- تاریخ
- درجه
- گسترش
- طراحی
- طراحی
- دقیق
- مشکل
- کارگر بارانداز
- هر
- به طور موثر
- موثر
- هر دو
- قدرت دادن
- قادر ساختن
- پایان
- پشت سر هم
- مهندس
- مهندسی
- مورد تأیید
- ثبت نام کردن
- تضمین می کند
- محیط
- محیط
- ضروری است
- اتر (ETH)
- همه چیز
- مثال ها
- مهیج
- موجود
- تجربه
- کارشناسان
- اکتشاف
- بررسی
- گسترش می یابد
- ویژگی
- امکانات
- ویژگی های
- کمی از
- رشته
- فایل ها
- سرانجام
- نام خانوادگی
- تمرکز
- تمرکز
- تمرکز
- به دنبال
- برای
- خط مقدم
- بنیادین
- چارچوب
- رایگان
- از جانب
- تابع
- اصول
- شکاف
- GCP
- داده
- گوگل
- Google Cloud
- گراف
- شبکه عصبی گراف
- هدایت شده
- دست
- آیا
- he
- مشخص کردن
- خود را
- دارای
- جامع
- مشق شب
- قلاب
- اما
- HTTPS
- ترکیبی
- تنظیم فراپارامتر
- بیماری
- انجام
- in
- در عمق
- شامل
- از جمله
- افزایشی
- صنعت
- شالوده
- ابتکاری
- نصب و راه اندازی
- دستورالعمل
- ادغام
- ادغام
- به
- معرفی
- معرفی می کند
- معرفی
- معرفی
- معرفی
- شامل
- IT
- ITS
- ژانویه
- می پیوندد
- کافکا
- kdnuggets
- کلید
- دریاچه
- برجسته
- یاد گرفتن
- آموخته
- زبان آموزان
- یادگیری
- پسندیدن
- لاین
- لینک
- لینوکس
- بارگیری
- محلی
- به دنبال
- دوست دارد
- کم
- نافع
- دستگاه
- فراگیری ماشین
- MacOS در
- مدیریت
- مدیریت
- اجباری
- بسیاری
- استاد
- تسلط
- مصالح
- روانی
- بیماری روانی
- ML
- مدل
- مدل سازی
- مدل
- مدرن
- واحد
- ماژول ها
- بیش
- چندگانه
- لازم
- نیاز
- ضروری
- نیازهای
- شبکه
- شبکه
- عصبی
- شبکه های عصبی
- هدف
- of
- ارائه
- پیشنهادات
- on
- فقط
- منبع باز
- عملیات
- or
- تنظیم و ارکستراسیون
- دیگر
- ما
- زوار امکنه مقدسه که دو برگ خرما را صلیب وار به امکنه مقدسه حمل میکنند
- ویژه
- مسیر
- پرداخت
- همکار
- انجام
- خط لوله
- سیستم عامل
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- موقعیت
- postgresql
- عملی
- برنامه های کاربردی عملی
- تمرین
- شیوه های
- آماده
- در حال حاضر
- روند
- پردازش
- در حال پردازش
- تولید
- محصول
- حرفه ای
- حرفه ای
- در حال پیشرفت
- پروژه
- پروژه ها
- فراهم می کند
- ارائه
- پــایتــون
- سوالات
- افزایش
- مطالعه
- دنیای واقعی
- واقعیت
- منابع
- نقش
- نقش
- در حال اجرا
- s
- حقوق
- اسکالا
- علم
- دانشمند
- دانشمندان
- به دنبال
- انتخاب
- ارشد
- محیط
- برپایی
- مهارت ها
- شل
- راه حل
- برخی از
- گاهی
- مصنوعی
- جرقه
- ویژه
- SQL
- شروع
- راه افتادن
- ذخیره سازی
- جریان
- جریان
- جریان
- ساخت یافته
- تلاش
- دانشجویان
- استودیو
- قابل توجه
- چنین
- پشتیبانی
- گزینه
- سیستم های
- طراحی شده
- استعداد
- وظایف
- فن آوری
- فنی
- تکنیک
- فن آوری
- پیشرفته
- ارتباط از راه دور
- Terraform
- تست
- که
- La
- مبانی
- سپس
- این
- از طریق
- به
- امروز
- ابزار
- ابزار
- تاپیک
- آموزش
- انتقال
- دگرگون کردن
- دگرگونی
- دگرگونی
- مبدل
- تبدیل شدن
- آموزش
- دو
- درک
- دلار آمریکا
- استفاده کنید
- کاربران
- با استفاده از
- Ve
- بسیار
- از طريق
- فیلم های
- دید
- بصری
- vs
- انبار کالا
- انبارداری
- we
- چی
- که
- WHO
- اراده
- پنجره
- با
- گردش کار
- گردش کار
- کارگاه
- کارگاه های آموزشی
- نوشته
- شما
- شما
- زفیرنت










