با راه اندازی قابلیت جستجوی عصبی برای سرویس جستجوی باز آمازون در OpenSearch 2.9، اکنون ادغام با مدلهای AI/ML برای تقویت جستجوی معنایی و سایر موارد استفاده آسان است. سرویس OpenSearch از زمان معرفی ویژگی k-nearest همسایه (k-NN) خود در سال 2020، از جستجوی واژگانی و برداری پشتیبانی می کند. با این حال، پیکربندی جستجوی معنایی نیازمند ایجاد چارچوبی برای ادغام مدلهای یادگیری ماشینی (ML) برای جذب و جستجو بود. ویژگی جستجوی عصبی تبدیل متن به برداری را در حین مصرف و جستجو تسهیل می کند. هنگامی که از یک پرس و جو عصبی در حین جستجو استفاده می کنید، پرس و جو به یک جاسازی برداری ترجمه می شود و از k-NN برای برگرداندن نزدیک ترین جاسازی های برداری از بدنه استفاده می شود.
برای استفاده از جستجوی عصبی، باید یک مدل ML راه اندازی کنید. توصیه می کنیم اتصالات AI/ML را برای سرویس های AWS AI و ML پیکربندی کنید (مانند آمازون SageMaker or بستر آمازون) یا جایگزین های شخص ثالث. با شروع نسخه 2.9 در سرویس OpenSearch، کانکتورهای AI/ML با جستجوی عصبی یکپارچه می شوند تا ترجمه مجموعه داده ها و پرس و جوهای شما را به جاسازی های برداری ساده و عملیاتی کنند، در نتیجه بسیاری از پیچیدگی هیدراتاسیون برداری و جستجو را از بین می برند.
در این پست، نحوه پیکربندی کانکتورهای AI/ML برای مدلهای خارجی را از طریق کنسول OpenSearch Service نشان میدهیم.
بررسی اجمالی راه حل
به طور خاص، این پست شما را از طریق اتصال به یک مدل در SageMaker راهنمایی می کند. سپس شما را از طریق استفاده از رابط برای پیکربندی جستجوی معنایی در سرویس OpenSearch به عنوان مثالی از یک مورد استفاده که از طریق اتصال به یک مدل ML پشتیبانی میشود، راهنمایی میکنیم. ادغامهای Amazon Bedrock و SageMaker در حال حاضر در رابط کاربری کنسول OpenSearch Service پشتیبانی میشوند و فهرست ادغامهای شخص اول و شخص ثالث با پشتیبانی از UI همچنان در حال رشد است.
برای هر مدلی که از طریق رابط کاربری پشتیبانی نمیشود، میتوانید با استفاده از APIهای موجود و نقشه های ML. برای اطلاعات بیشتر مراجعه کنید مقدمه ای بر مدل های جستجوی باز. میتوانید طرحهایی را برای هر کانکتور در آن پیدا کنید مخزن ML Commons GitHub.
پیش نیازها
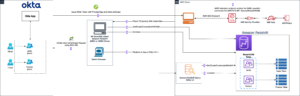
قبل از اتصال مدل از طریق کنسول OpenSearch Service، یک دامنه OpenSearch Service ایجاد کنید. نقشه یک هویت AWS و مدیریت دسترسی (IAM) نقش با نام LambdaInvokeOpenSearchMLCommonsRole به عنوان نقش باطن در ml_full_access نقش با استفاده از افزونه امنیتی در داشبوردهای OpenSearch، همانطور که در ویدیوی زیر نشان داده شده است. گردش کار ادغام سرویس OpenSearch از قبل برای استفاده از آن پر شده است LambdaInvokeOpenSearchMLCommonsRole نقش IAM به طور پیش فرض برای ایجاد رابط بین دامنه OpenSearch Service و مدل مستقر در SageMaker. اگر از یک نقش IAM سفارشی در ادغامهای کنسول سرویس OpenSearch استفاده میکنید، مطمئن شوید که نقش سفارشی به عنوان نقش پشتیبان با ml_full_access مجوزها قبل از استقرار الگو
مدل را با استفاده از AWS CloudFormation مستقر کنید
ویدئوی زیر مراحل استفاده از کنسول سرویس OpenSearch را برای استقرار یک مدل در عرض چند دقیقه در Amazon SageMaker و تولید شناسه مدل از طریق رابطهای هوش مصنوعی نشان میدهد. اولین قدم انتخاب است یکپارچگی در صفحه پیمایش در کنسول AWS سرویس OpenSearch، که به لیستی از ادغام های موجود هدایت می شود. ادغام از طریق یک رابط کاربری تنظیم شده است که ورودی های لازم را از شما می خواهد.
برای راهاندازی یکپارچهسازی، فقط باید نقطه پایانی دامنه سرویس OpenSearch را ارائه کنید و یک نام مدل برای شناسایی منحصربهفرد اتصال مدل ارائه دهید. بهطور پیشفرض، این الگو مدل جمله-تبدیلکنندههای صورت در آغوش گرفته را به کار میگیرد. djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
وقتی انتخاب کردید پشته ایجاد کنید، شما به مسیر هدایت می شوید AWS CloudFormation کنسول. الگوی CloudFormation معماری مشروح در نمودار زیر را به کار می گیرد.

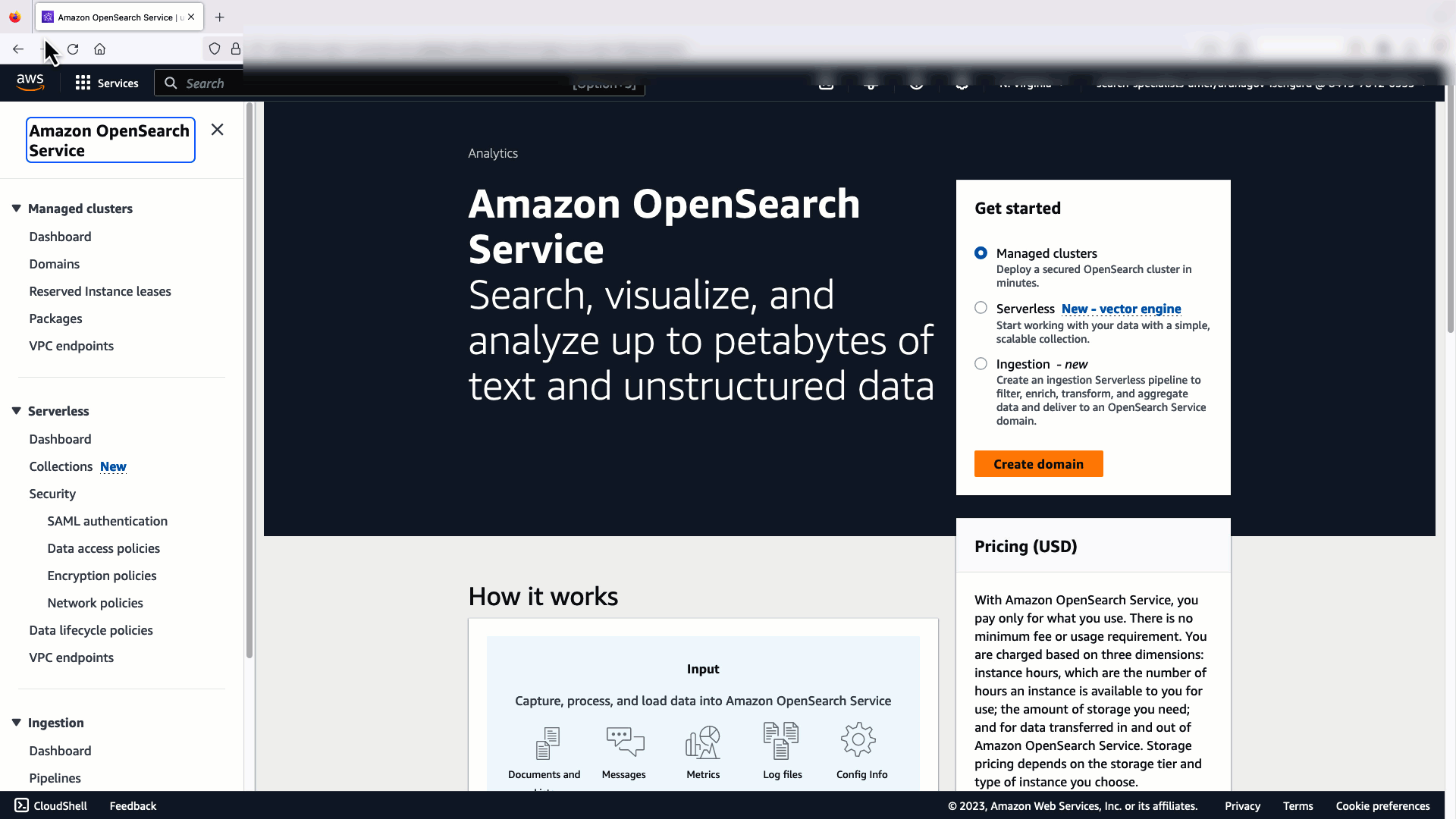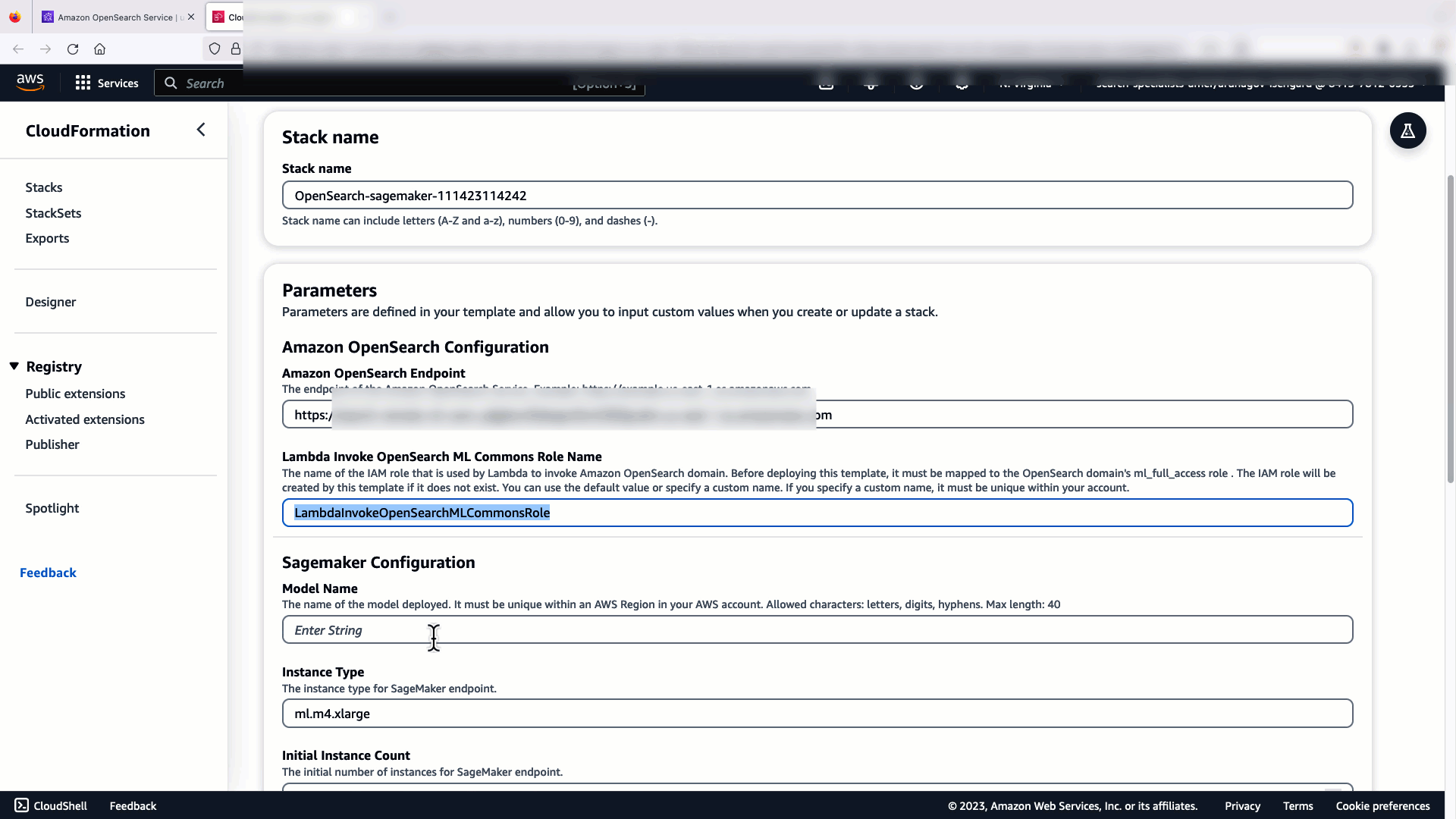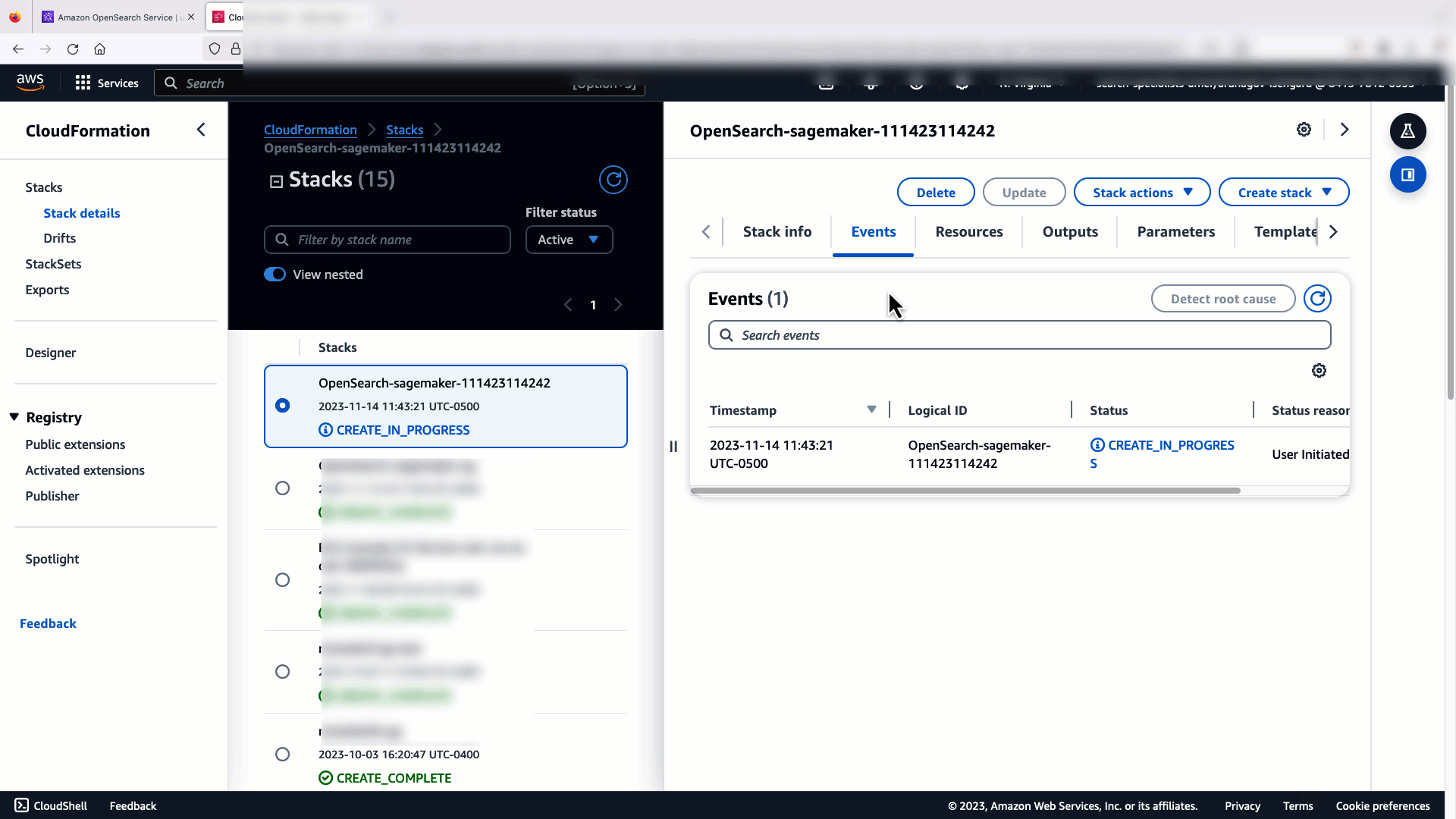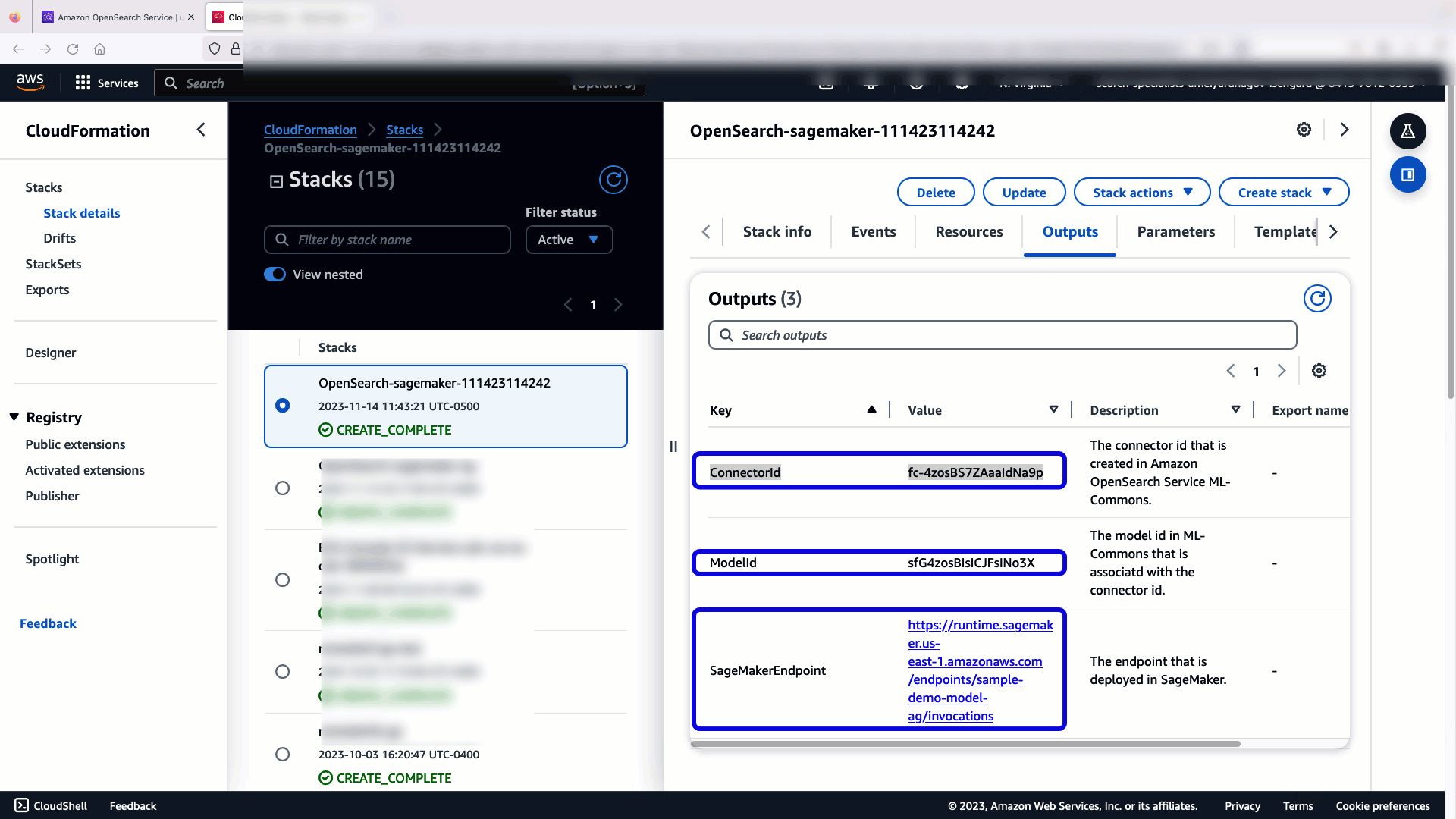
پشته CloudFormation یک را ایجاد می کند AWS لامبدا برنامه ای که مدلی را از سرویس ذخیره سازی ساده آمازون (Amazon S3)، کانکتور را ایجاد می کند و شناسه مدل را در خروجی تولید می کند. سپس می توانید از این شناسه مدل برای ایجاد یک نمایه معنایی استفاده کنید.
اگر مدل پیشفرض all-MiniLM-L6-v2 هدف شما را برآورده نمیکند، میتوانید با ارائه مصنوعات مدل خود به عنوان یک شی S3 قابل دسترسی، هر مدل جاسازی متنی را که انتخاب میکنید در میزبان مدل انتخابی (SageMaker یا Amazon Bedrock) اجرا کنید. یا می توانید یکی از موارد زیر را انتخاب کنید مدل های زبان از پیش آموزش دیده و آن را در SageMaker مستقر کنید. برای دستورالعملهای تنظیم نقطه پایانی و مدلهای خود، به آن مراجعه کنید تصاویر موجود Amazon SageMaker.
SageMaker یک سرویس کاملاً مدیریت شده است که مجموعه گسترده ای از ابزارها را گرد هم می آورد تا ML با کارایی بالا و کم هزینه را برای هر مورد استفاده ای فعال کند و مزایای کلیدی مانند نظارت بر مدل، میزبانی بدون سرور و اتوماسیون گردش کار را برای آموزش و استقرار مداوم ارائه دهد. SageMaker به شما امکان می دهد چرخه عمر مدل های جاسازی متن را میزبانی و مدیریت کنید، و از آنها برای تقویت عبارت های جستجوی معنایی در سرویس OpenSearch استفاده کنید. در صورت اتصال، SageMaker مدل های شما را میزبانی می کند و از سرویس OpenSearch برای پرس و جو بر اساس نتایج استنتاج SageMaker استفاده می شود.
مدل مستقر شده را از طریق داشبوردهای OpenSearch مشاهده کنید
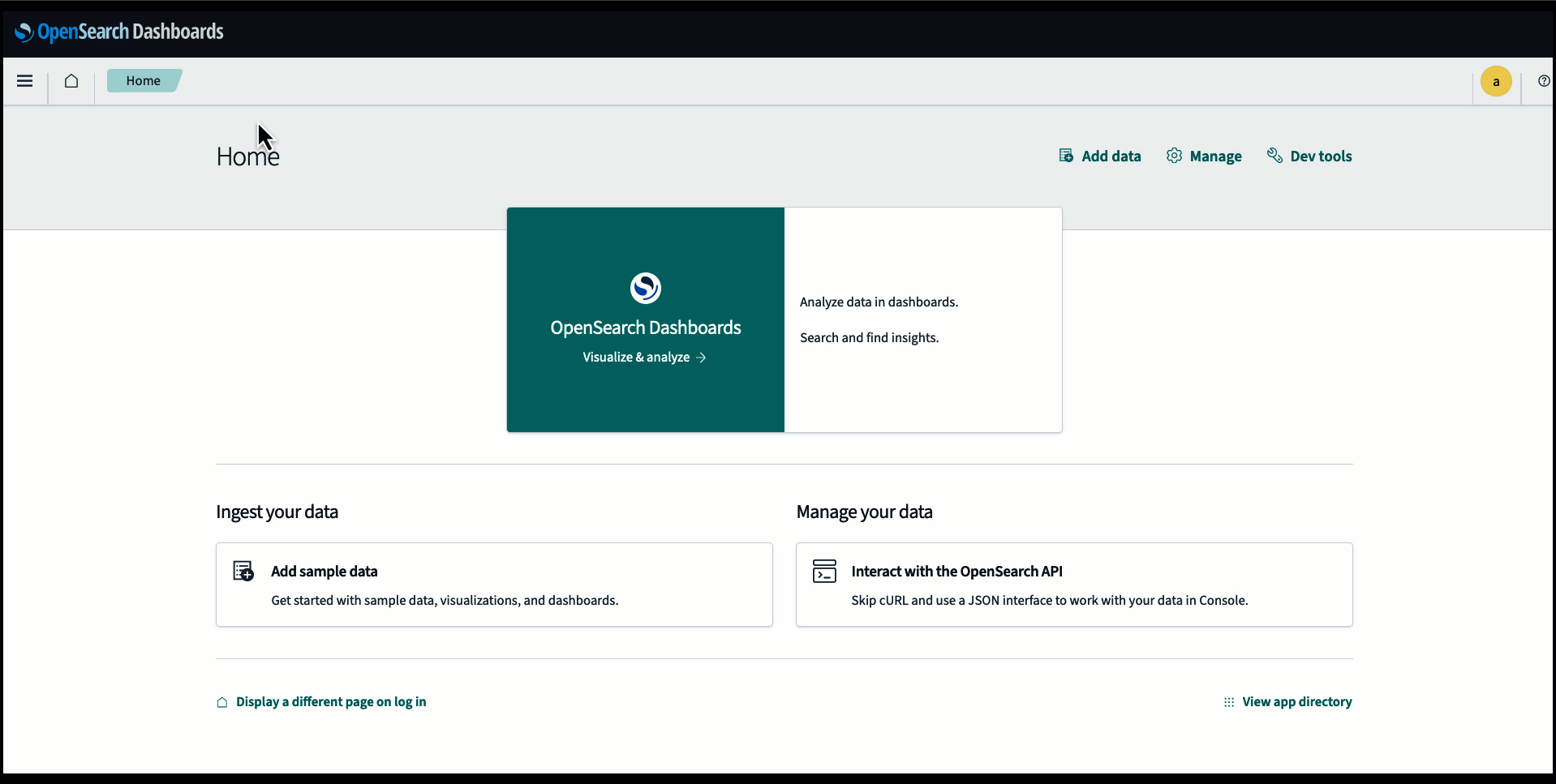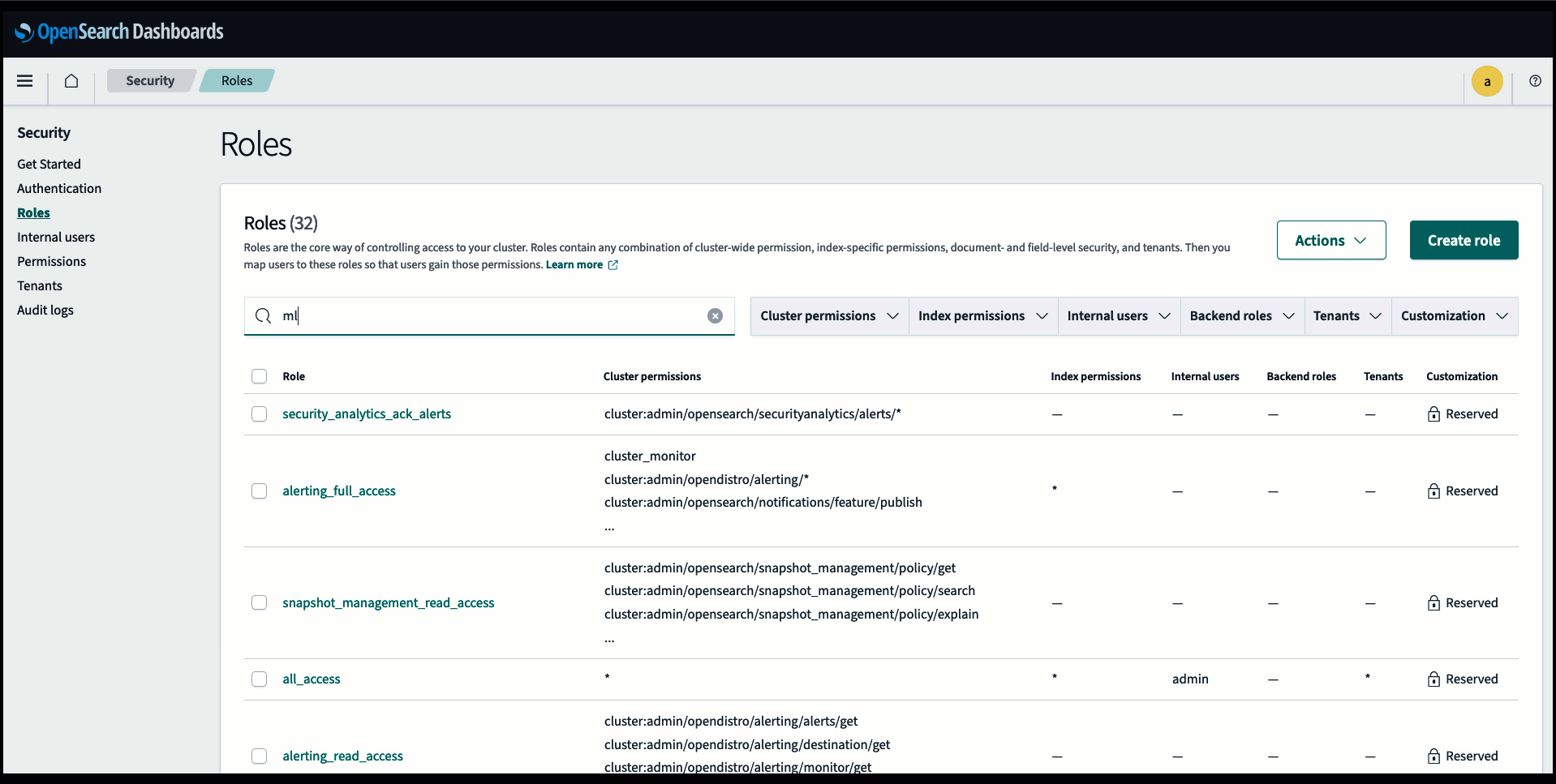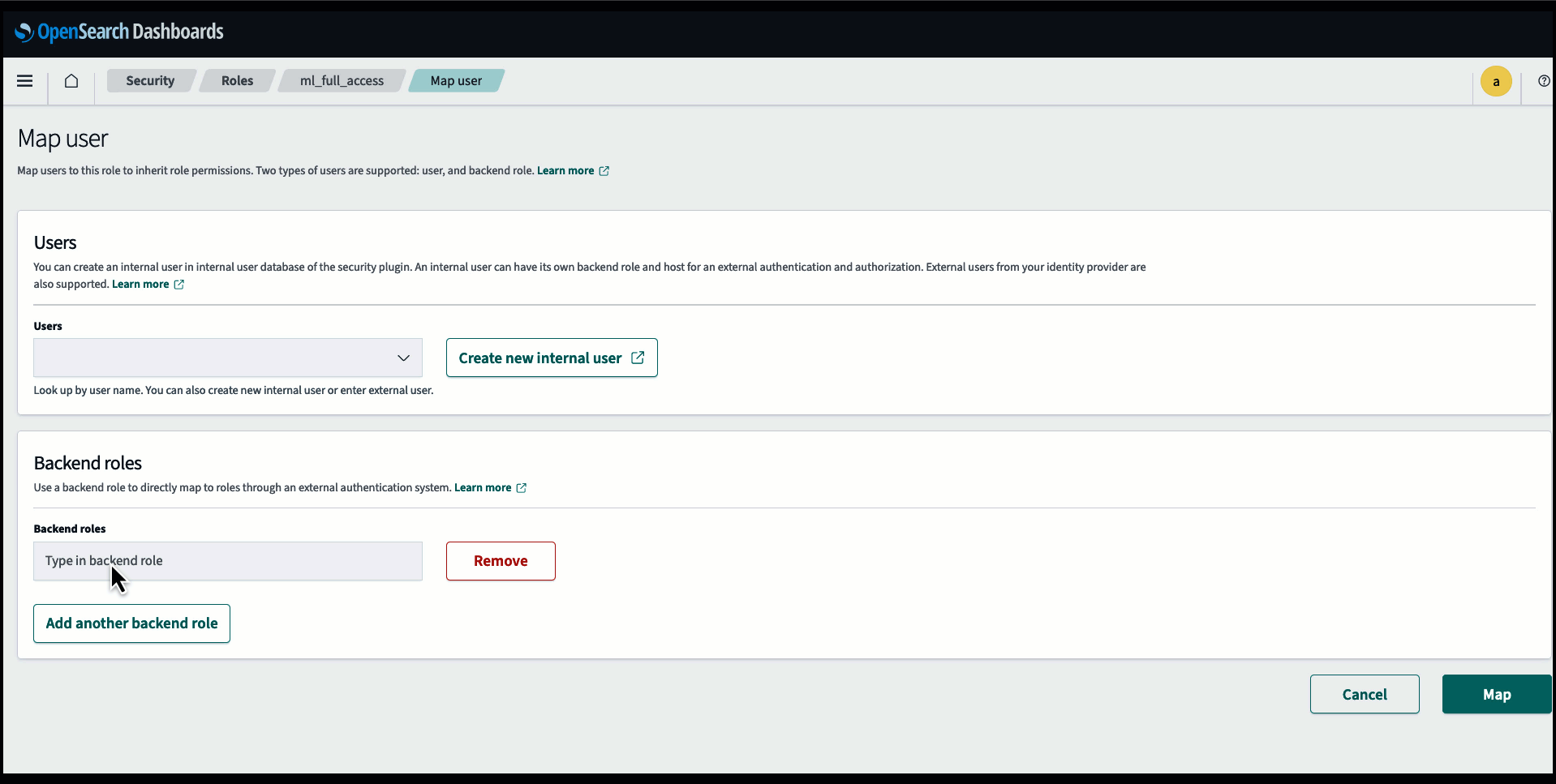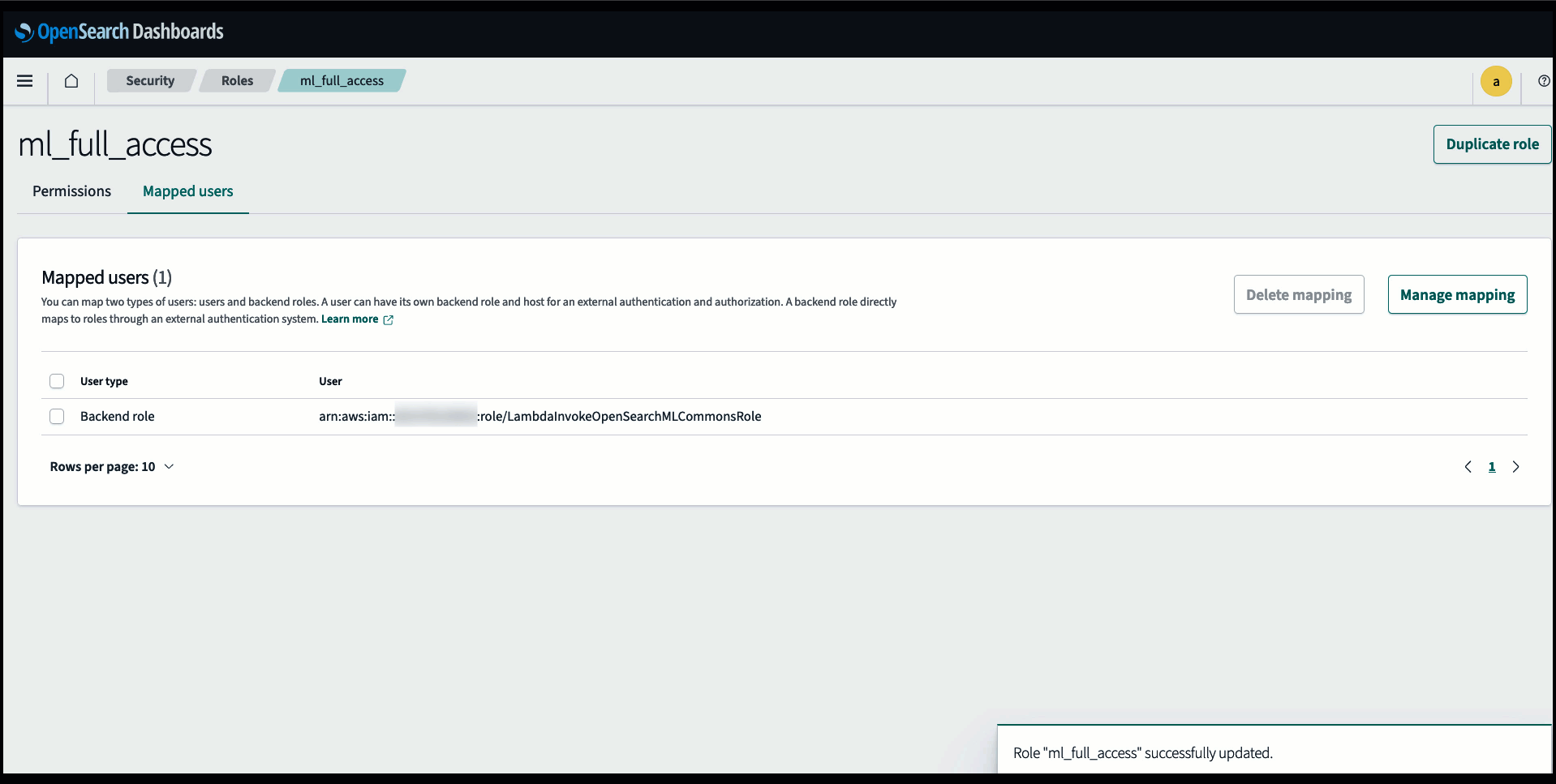
برای تأیید اینکه الگوی CloudFormation مدل را با موفقیت در دامنه سرویس OpenSearch مستقر کرده و شناسه مدل را دریافت کنید، میتوانید از API ML Commons REST GET از طریق OpenSearch Dashboards Dev Tools استفاده کنید.
GET _plugins REST API اکنون API های اضافی را برای مشاهده وضعیت مدل ارائه می دهد. دستور زیر به شما امکان می دهد وضعیت یک مدل راه دور را مشاهده کنید:
همانطور که در تصویر زیر نشان داده شده است، الف DEPLOYED وضعیت در پاسخ نشان می دهد که مدل با موفقیت در خوشه OpenSearch Service مستقر شده است.

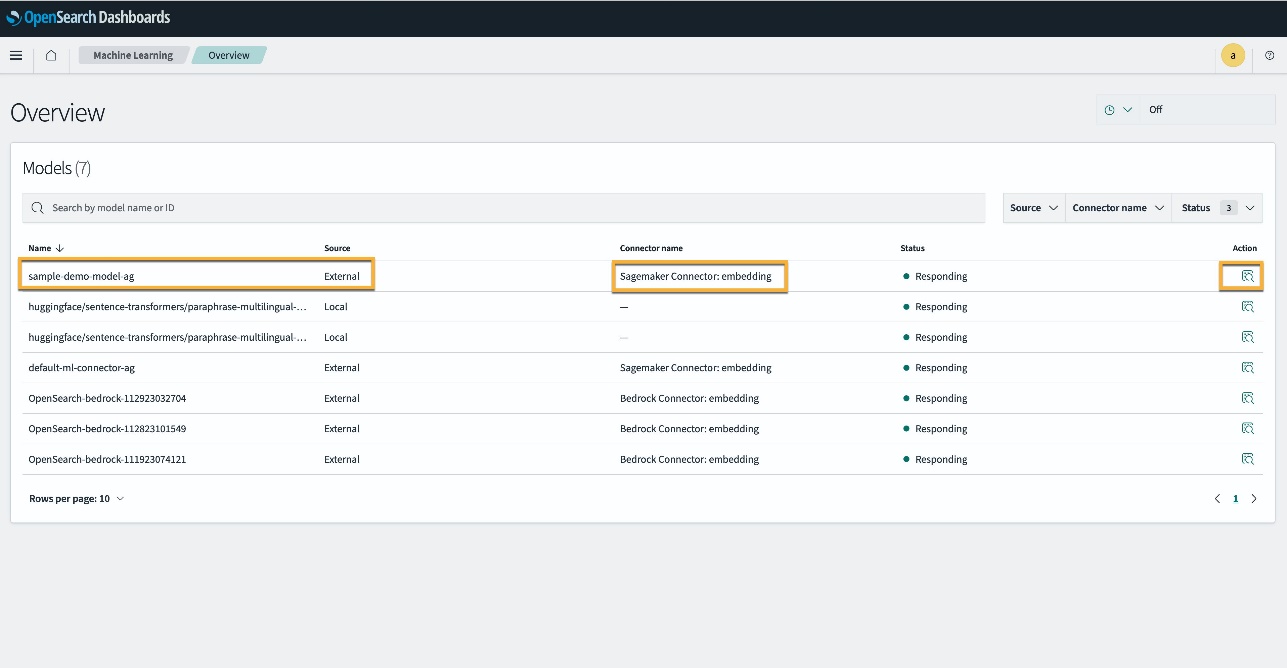
همچنین، می توانید مدل مستقر شده در دامنه سرویس OpenSearch خود را با استفاده از فراگیری ماشین صفحه داشبوردهای OpenSearch.

این صفحه اطلاعات مدل و وضعیت همه مدلهای مستقر شده را فهرست میکند.

خط لوله عصبی را با استفاده از شناسه مدل ایجاد کنید
وقتی وضعیت مدل به صورت یکی نشان داده شود DEPLOYED در Dev Tools یا سبز و در حال پاسخگویی در داشبوردهای OpenSearch، می توانید از شناسه مدل برای ایجاد خط لوله جذب عصبی خود استفاده کنید. خط لوله ورودی زیر در ابزارهای توسعه دهنده داشبورد جستجوی باز دامنه شما اجرا می شود. مطمئن شوید که شناسه مدل را با شناسه منحصربهفرد ایجاد شده برای مدل مستقر در دامنه شما جایگزین کردهاید.

فهرست جستجوی معنایی را با استفاده از خط لوله عصبی به عنوان خط لوله پیش فرض ایجاد کنید
اکنون می توانید نگاشت شاخص خود را با خط لوله پیش فرض پیکربندی شده برای استفاده از خط لوله عصبی جدیدی که در مرحله قبل ایجاد کرده اید، تعریف کنید. مطمئن شوید که فیلدهای برداری به صورت اعلام شده اند knn_vector و ابعاد متناسب با مدلی است که در SageMaker مستقر شده است. اگر پیکربندی پیشفرض را برای استقرار مدل all-MiniLM-L6-v2 در SageMaker حفظ کردهاید، تنظیمات زیر را همانطور که هست نگه دارید و دستور را در Dev Tools اجرا کنید.

نمونه اسناد را برای تولید بردارها مصرف کنید
برای این نسخه ی نمایشی، می توانید آن را مصرف کنید نمونه کاتالوگ محصولات دموستور خرده فروشی به جدید semantic_demostore فهرست مطالب. نام کاربری، رمز عبور و نقطه پایانی دامنه را با اطلاعات دامنه خود جایگزین کنید و داده های خام را در سرویس OpenSearch وارد کنید:

شاخص semantic_demostore جدید را اعتبارسنجی کنید
اکنون که مجموعه داده خود را در دامنه سرویس OpenSearch وارد کرده اید، بررسی کنید که آیا بردارهای مورد نیاز با استفاده از یک جستجوی ساده برای واکشی همه فیلدها ایجاد شده اند یا خیر. اگر فیلدها به صورت تعریف شده باشند، اعتبارسنجی کنید knn_vectors بردارهای مورد نیاز را داشته باشد.

با استفاده از ابزار مقایسه نتایج جستجو، جستجوی واژگانی و جستجوی معنایی را با جستجوی عصبی مقایسه کنید
La ابزار مقایسه نتایج جستجو در داشبوردهای OpenSearch برای بارهای کاری تولید در دسترس است. می توانید به مسیر بروید نتایج جستجو را مقایسه کنید صفحه و مقایسه نتایج پرس و جو بین جستجوی واژگانی و جستجوی عصبی پیکربندی شده برای استفاده از مدل شناسه تولید شده قبلی.

پاک کردن
با حذف پشته CloudFormation می توانید منابعی را که طبق دستورالعمل های این پست ایجاد کرده اید حذف کنید. با این کار منابع Lambda و سطل S3 که شامل مدلی است که در SageMaker مستقر شده است را حذف می کند. مراحل زیر را کامل کنید:
- در کنسول AWS CloudFormation، به صفحه جزئیات پشته خود بروید.
- را انتخاب کنید حذف.

- را انتخاب کنید حذف برای تایید.

می توانید پیشرفت حذف پشته را در کنسول AWS CloudFormation نظارت کنید.
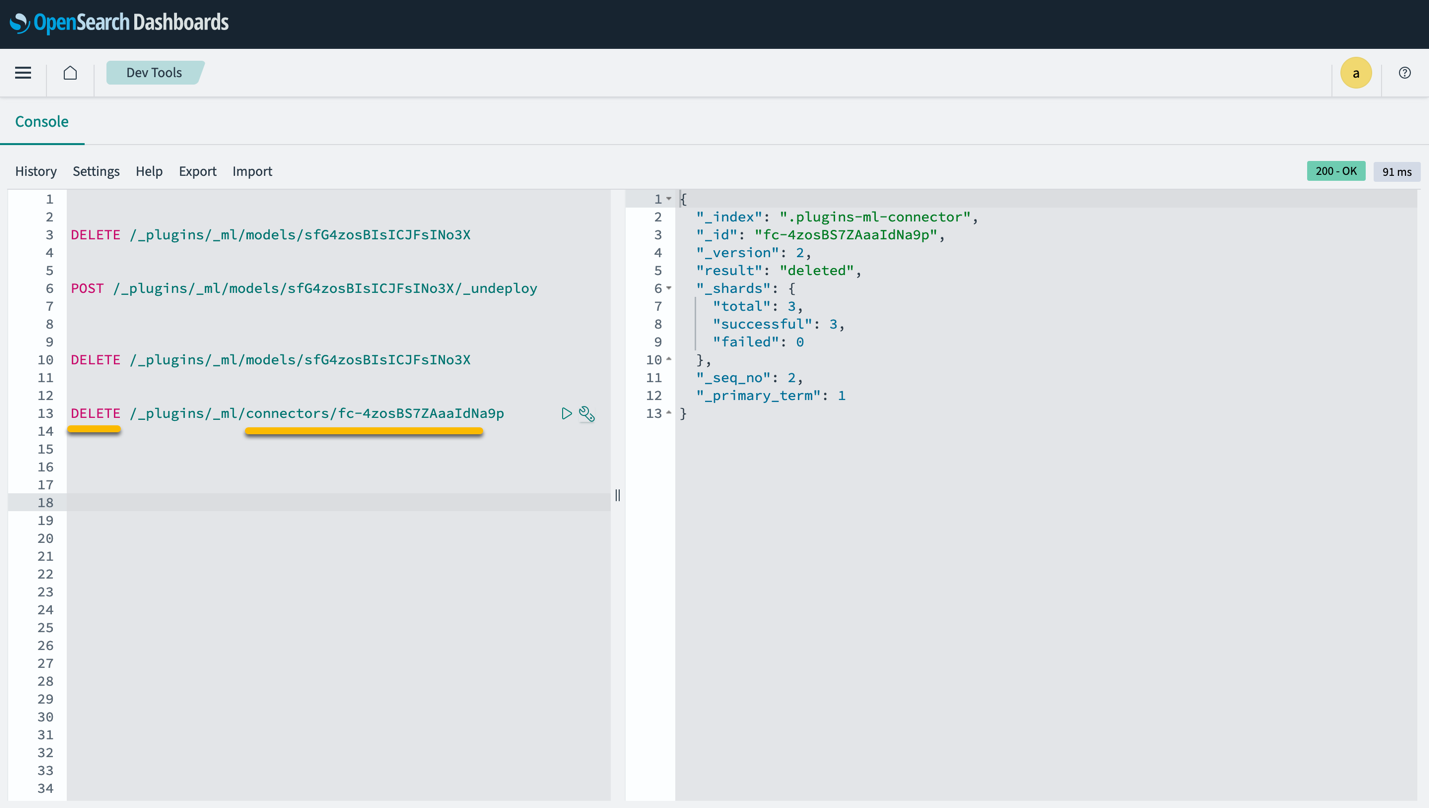
توجه داشته باشید که حذف پشته CloudFormation مدل مستقر در دامنه SageMaker و رابط AI/ML ایجاد شده را حذف نمی کند. این به این دلیل است که این مدل ها و کانکتور را می توان با چندین شاخص در دامنه مرتبط کرد. برای حذف خاص یک مدل و رابط مرتبط با آن، از APIهای مدل همانطور که در تصاویر زیر نشان داده شده است استفاده کنید.
اول، undeploy مدل از حافظه دامنه سرویس OpenSearch:

سپس می توانید مدل را از فهرست مدل حذف کنید:

در نهایت، کانکتور را از فهرست کانکتور حذف کنید:
نتیجه
در این پست، نحوه استقرار یک مدل در SageMaker، ایجاد کانکتور AI/ML با استفاده از کنسول OpenSearch Service و ساخت فهرست جستجوی عصبی را یاد گرفتید. توانایی پیکربندی کانکتورهای AI/ML در سرویس OpenSearch، فرآیند هیدراتاسیون برداری را با بومیسازی ادغامها با مدلهای خارجی ساده میکند. میتوانید با استفاده از خط لوله جذب عصبی و جستجوی عصبی که از شناسه مدل برای تولید بردار تعبیهشده در پرواز در طول جذب و جستجو استفاده میکند، یک فهرست جستجوی عصبی در چند دقیقه ایجاد کنید.
برای کسب اطلاعات بیشتر در مورد این کانکتورهای AI/ML، مراجعه کنید رابطهای هوش مصنوعی سرویس جستجوی باز آمازون برای سرویسهای AWS, ادغام قالب AWS CloudFormation برای جستجوی معناییو ایجاد کانکتور برای پلتفرم های ML شخص ثالث.
درباره نویسنده
 آرونا گووینداراجو یک معمار راه حل های تخصصی جستجوی باز آمازون است و با بسیاری از موتورهای جستجوی تجاری و منبع باز کار کرده است. او مشتاق جستجو، ارتباط و تجربه کاربری است. تخصص او در ارتباط سیگنال های کاربر نهایی با رفتار موتور جستجو به بسیاری از مشتریان کمک کرده است تا تجربه جستجوی خود را بهبود بخشند.
آرونا گووینداراجو یک معمار راه حل های تخصصی جستجوی باز آمازون است و با بسیاری از موتورهای جستجوی تجاری و منبع باز کار کرده است. او مشتاق جستجو، ارتباط و تجربه کاربری است. تخصص او در ارتباط سیگنال های کاربر نهایی با رفتار موتور جستجو به بسیاری از مشتریان کمک کرده است تا تجربه جستجوی خود را بهبود بخشند.
 داگنی براون یک مدیر محصول اصلی در AWS است که بر OpenSearch متمرکز شده است.
داگنی براون یک مدیر محصول اصلی در AWS است که بر OpenSearch متمرکز شده است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- : دارد
- :است
- :نه
- $UP
- 1
- 100
- 12
- ٪۱۰۰
- 2020
- 25
- 7
- 8
- 9
- a
- توانایی
- درباره ما
- دسترسی
- در دسترس
- اضافی
- AI
- AI / ML
- معرفی
- اجازه می دهد تا
- همچنین
- جایگزین
- آمازون
- آمازون SageMaker
- آمازون خدمات وب
- an
- و
- هر
- API
- رابط های برنامه کاربردی
- کاربرد
- مناسب
- معماری
- هستند
- AS
- مرتبط است
- At
- اتوماسیون
- در دسترس
- AWS
- AWS CloudFormation
- بخش مدیریت
- مستقر
- BE
- زیرا
- رفتار
- مزایای
- میان
- هر دو
- به ارمغان می آورد
- پهن
- ساختن
- بنا
- by
- CAN
- مورد
- موارد
- کاتالوگ
- انتخاب
- را انتخاب کنید
- برگزیده
- خوشه
- تجاری
- مردم عادی
- مقايسه كردن
- کامل
- پیچیدگی
- پیکر بندی
- پیکربندی
- پیکربندی
- تکرار
- متصل
- اتصال
- ارتباط
- کنسول
- شامل
- ادامه دادن
- مداوم
- همبستگی
- ایجاد
- ایجاد شده
- ایجاد
- در حال حاضر
- سفارشی
- مشتریان
- داشبورد
- داده ها
- به طور پیش فرض
- تعريف كردن
- مشخص
- تحویل
- نسخه ی نمایشی
- نشان دادن
- نشان می دهد
- گسترش
- مستقر
- استقرار
- گسترش
- مستقر می کند
- شرح
- دقیق
- جزئیات
- برنامه نویس
- بعد
- ابعاد
- اسناد و مدارک
- نمی کند
- دامنه
- در طی
- هر
- پیش از آن
- بدون دردسر
- هر دو
- تعبیه کردن
- قادر ساختن
- نقطه پایانی
- موتور
- موتورهای حرفه ای
- اطمینان حاصل شود
- اتر (ETH)
- مثال
- تجربه
- تخصص
- خارجی
- چهره
- تسهیل می کند
- ویژگی
- زمینه
- پیدا کردن
- نام خانوادگی
- متمرکز شده است
- پیروی
- برای
- چارچوب
- از جانب
- کاملا
- تولید می کنند
- تولید
- تولید می کند
- دریافت کنید
- GIF
- GitHub
- سبز
- شدن
- راهنمایی
- آیا
- کمک کرد
- او
- عملکرد بالا
- میزبان
- میزبانی وب
- میزبان
- چگونه
- چگونه
- اما
- HTML
- HTTP
- HTTPS
- صورت در آغوش گرفته
- هیدراتاسیون
- IAM
- ID
- شناسایی
- هویت
- if
- بهبود
- in
- شاخص
- فهرستها
- نشان می دهد
- اطلاعات
- ورودی
- در عوض
- دستورالعمل
- ادغام
- ادغام
- یکپارچگی
- به
- معرفی
- IT
- ITS
- JPG
- json
- نگاه داشتن
- کلید
- زبان
- راه اندازی
- یاد گرفتن
- آموخته
- یادگیری
- wifecycwe
- فهرست
- لیست
- کم هزینه
- دستگاه
- فراگیری ماشین
- ساخت
- ساخت
- مدیریت
- اداره می شود
- مدیر
- بسیاری
- نقشه
- نقشه برداری
- حافظه
- روش
- دقیقه
- ML
- مدل
- مدل
- مانیتور
- نظارت بر
- بیش
- بسیار
- چندگانه
- باید
- نام
- بومی
- هدایت
- جهت یابی
- لازم
- نیاز
- عصبی
- جدید
- اکنون
- هدف
- of
- on
- ONE
- فقط
- باز کن
- منبع باز
- or
- دیگر
- تولید
- با ما
- قطعه
- احساساتی
- کلمه عبور
- مجوز
- خط لوله
- افلاطون
- هوش داده افلاطون
- PlatoData
- پلاگین
- پست
- قدرت
- صفحه اصلی
- قبلی
- اصلی
- قبلا
- روند
- پردازنده ها
- محصول
- مدیر تولید
- تولید
- پیشرفت
- املاک
- ارائه
- فراهم می کند
- ارائه
- هدف
- نمایش ها
- خام
- داده های خام
- توصیه
- مراجعه
- دور
- از بین بردن
- جایگزین کردن
- ضروری
- منابع
- پاسخ
- REST
- نتایج
- خرده فروشی
- حفظ شده است
- برگشت
- نقش
- مسیرها
- دویدن
- حکیم ساز
- تصاویر
- جستجو
- موتور جستجو
- موتورهای جستجو
- تیم امنیت لاتاری
- دیدن
- را انتخاب کنید
- خدمت
- بدون سرور
- سرویس
- خدمات
- تنظیم
- تنظیمات
- او
- نشان داده شده
- نشان می دهد
- سیگنال
- ساده
- ساده می کند
- ساده کردن
- پس از
- مزایا
- منبع
- متخصص
- به طور خاص
- پشته
- راه افتادن
- وضعیت
- گام
- مراحل
- ذخیره سازی
- موفقیت
- چنین
- پشتیبانی
- مطمئن
- قالب
- متن
- که
- La
- شان
- آنها
- سپس
- در نتیجه
- اینها
- شخص ثالث
- این
- از طریق
- به
- با هم
- ابزار
- آموزش
- دگرگونی
- ترجمه
- درست
- نوع
- ui
- منحصر به فرد
- منحصر به فرد
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- سابقه کاربر
- با استفاده از
- تصدیق
- بررسی
- نسخه
- از طريق
- تصویری
- چشم انداز
- پیاده روی
- بود
- we
- وب
- خدمات وب
- چه زمانی
- که
- اراده
- با
- در داخل
- مشغول به کار
- گردش کار
- اتوماسیون گردش کار
- شما
- شما
- زفیرنت