تقریباً مانند همه مشتریان، شما می خواهید تا حد امکان کمتر هزینه کنید و بهترین عملکرد ممکن را داشته باشید. این بدان معنی است که شما باید به قیمت و عملکرد توجه کنید. با آمازون Redshift، شما می توانید کیک خودرا داشته باشید و آنرا میل کنید! Amazon Redshift تا 4.9 برابر هزینه کمتر برای هر کاربر و تا 7.9 برابر عملکرد قیمت بهتر نسبت به سایر انبارهای داده ابری در بارهای کاری واقعی با استفاده از تکنیکهای پیشرفته مانند مقیاسگذاری همزمان برای پشتیبانی از صدها کاربر همزمان، کدگذاری رشتهای بهبودیافته برای عملکرد جستجوی سریعتر ارائه میکند. ، و آمازون Redshift بدون سرور بهبود عملکرد برای درک اینکه چرا قیمت-عملکرد مهم است و اینکه چگونه Amazon Redshift قیمت-عملکرد معیاری است برای تعیین میزان هزینه برای دستیابی به یک سطح خاص از عملکرد حجم کاری، یعنی عملکرد ROI (بازده سرمایه) بخوانید.
از آنجایی که هم قیمت و هم عملکرد در محاسبه قیمت-عملکرد وارد می شوند، دو راه برای فکر کردن در مورد قیمت-عملکرد وجود دارد. راه اول ثابت نگه داشتن قیمت است: اگر 1 دلار برای خرج کردن دارید، چقدر عملکرد از انبار داده خود دریافت می کنید؟ یک پایگاه داده با قیمت-عملکرد بهتر، به ازای هر 1 دلار خرج شده، عملکرد بهتری ارائه می دهد. بنابراین، هنگام مقایسه دو انبار داده که هزینه یکسانی دارند، قیمت را ثابت نگه میدارید، پایگاه داده با عملکرد قیمت بهتر، درخواستهای شما را سریعتر اجرا میکند.. راه دوم برای بررسی قیمت-عملکرد این است که عملکرد را ثابت نگه دارید: اگر نیاز دارید حجم کاری خود را در 10 دقیقه به پایان برسانید، هزینه آن چقدر خواهد بود؟ یک پایگاه داده با عملکرد بهتر، حجم کاری شما را در 10 دقیقه با هزینه کمتر اجرا می کند. بنابراین، هنگام مقایسه دو انبار داده که برای ارائه عملکرد یکسان عملکرد را ثابت نگه می دارند، پایگاه داده با قیمت-عملکرد بهتر هزینه کمتری خواهد داشت و در هزینه شما صرفه جویی می کند.
در نهایت، یکی دیگر از جنبه های مهم قیمت-عملکرد قابل پیش بینی است. دانستن اینکه انبار داده شما با افزایش تعداد کاربران انبار داده چقدر هزینه دارد، برای برنامه ریزی بسیار مهم است. این نه تنها باید بهترین عملکرد قیمت امروز را ارائه دهد، بلکه باید به طور قابل پیش بینی مقیاس شود و بهترین عملکرد قیمت را ارائه دهد زیرا کاربران و حجم کاری بیشتری اضافه می شود. یک انبار داده ایده آل باید داشته باشد مقیاس خطی- مقیاس بندی انبار داده شما برای ارائه دو برابر توان عملیاتی پرس و جو، در حالت ایده آل باید دو برابر (یا کمتر) هزینه داشته باشد.
در این پست، نتایج عملکرد را به اشتراک می گذاریم تا نشان دهیم که Amazon Redshift چگونه عملکرد قیمتی بهتری را در مقایسه با انبارهای داده ابری جایگزین پیشرو ارائه می دهد. این بدان معناست که اگر همان مقداری را که برای یکی از این انبارهای داده دیگر خرج میکنید، در Amazon Redshift خرج کنید، با Amazon Redshift عملکرد بهتری خواهید داشت. از طرف دیگر، اگر کلاستر Redshift خود را برای ارائه عملکرد یکسان اندازهگیری کنید، در مقایسه با این گزینهها هزینههای کمتری را مشاهده خواهید کرد.
قیمت-عملکرد برای بارهای کاری در دنیای واقعی
شما میتوانید از Amazon Redshift برای ایجاد تنوع بسیار گستردهای از بارهای کاری، از پردازش دستهای گزارشهای مبتنی بر استخراج، تبدیل، و بارگذاری پیچیده (ETL) و تجزیه و تحلیل جریان بیدرنگ گرفته تا داشبوردهای هوش تجاری (BI) با تاخیر کم استفاده کنید. نیاز به سرویس دهی به صدها یا حتی هزاران کاربر همزمان با زمان پاسخ دهی دوم و همه چیز در این بین. یکی از راههایی که ما به طور مستمر عملکرد قیمت را برای مشتریان خود بهبود میبخشیم، مرور مداوم تلهمتری عملکرد نرمافزار و سختافزار ناوگان Redshift، جستجوی فرصتها و موارد استفاده مشتری است که میتوانیم عملکرد Amazon Redshift را بیشتر بهبود بخشیم.
برخی از نمونه های اخیر بهینه سازی عملکرد توسط تله متری ناوگان عبارتند از:
- بهینه سازی پرس و جو رشته ای – با تجزیه و تحلیل اینکه Amazon Redshift چگونه انواع داده های مختلف را در ناوگان Redshift پردازش می کند، متوجه شدیم که بهینه سازی پرس و جوهای رشته ای سنگین مزایای قابل توجهی برای بار کاری مشتریان ما به همراه خواهد داشت. (در ادامه این پست با جزئیات بیشتری در مورد این موضوع صحبت خواهیم کرد.)
- نماهای تحقق یافته خودکار - ما متوجه شدیم که مشتریان Redshift آمازون اغلب پرس و جوهای زیادی را اجرا می کنند که دارای الگوهای مشترک فرعی هستند. به عنوان مثال، چندین کوئری مختلف ممکن است با استفاده از شرایط اتصال یکسان به سه جدول مشابه بپیوندند. Amazon Redshift اکنون قادر است به طور خودکار نماهای مادی شده را ایجاد و نگهداری کند و سپس به طور شفاف پرس و جوها را بازنویسی کند تا از نماهای تحقق یافته با استفاده از یادگیری ماشینی استفاده کند. نمای متریال شده خودکار ویژگی autonomics در آمازون Redshift. وقتی فعال باشد، نماهای واقعی خودکار میتوانند به طور شفاف عملکرد پرسوجو را برای پرسوجوهای تکراری بدون هیچ دخالت کاربر افزایش دهند. (توجه داشته باشید که نماهای تحقق یافته خودکار در هیچ یک از نتایج معیار مورد بحث در این پست استفاده نشده است).
- بار کاری با همزمانی بالا - مورد استفاده رو به رشدی که می بینیم استفاده از Amazon Redshift برای ارائه بارهای کاری مشابه داشبورد است. این حجمهای کاری با زمانهای پاسخ پرس و جوی دلخواه از ثانیههای تک رقمی یا کمتر مشخص میشوند، با دهها یا صدها کاربر همزمان که پرسوجوها را بهطور همزمان با یک الگوی استفاده تند و اغلب غیرقابل پیشبینی اجرا میکنند. نمونه اولیه این داشبورد BI مبتنی بر Redshift آمازون است که صبحهای دوشنبه، زمانی که تعداد زیادی از کاربران هفته خود را شروع میکنند، در ترافیک افزایش مییابد.
به ویژه بارهای کاری با همزمانی بالا کاربرد بسیار گسترده ای دارند: اکثر بارهای کاری انبار داده به صورت همزمان عمل می کنند، و غیر معمول نیست که صدها یا حتی هزاران کاربر به طور همزمان درخواست هایی را در Amazon Redshift اجرا کنند. Amazon Redshift به گونه ای طراحی شده است که زمان پاسخ پرس و جو را قابل پیش بینی و سریع نگه دارد. Redshift Serverless با اضافه کردن و حذف محاسبات در صورت نیاز، این کار را به طور خودکار برای شما انجام می دهد تا زمان پاسخگویی به درخواست سریع و قابل پیش بینی باشد. این بدان معناست که داشبورد بدون سرور Redshift که وقتی یک یا دو کاربر به آن دسترسی دارند به سرعت بارگیری می شود، حتی زمانی که بسیاری از کاربران همزمان آن را بارگذاری می کنند، به سرعت بارگیری می شود.
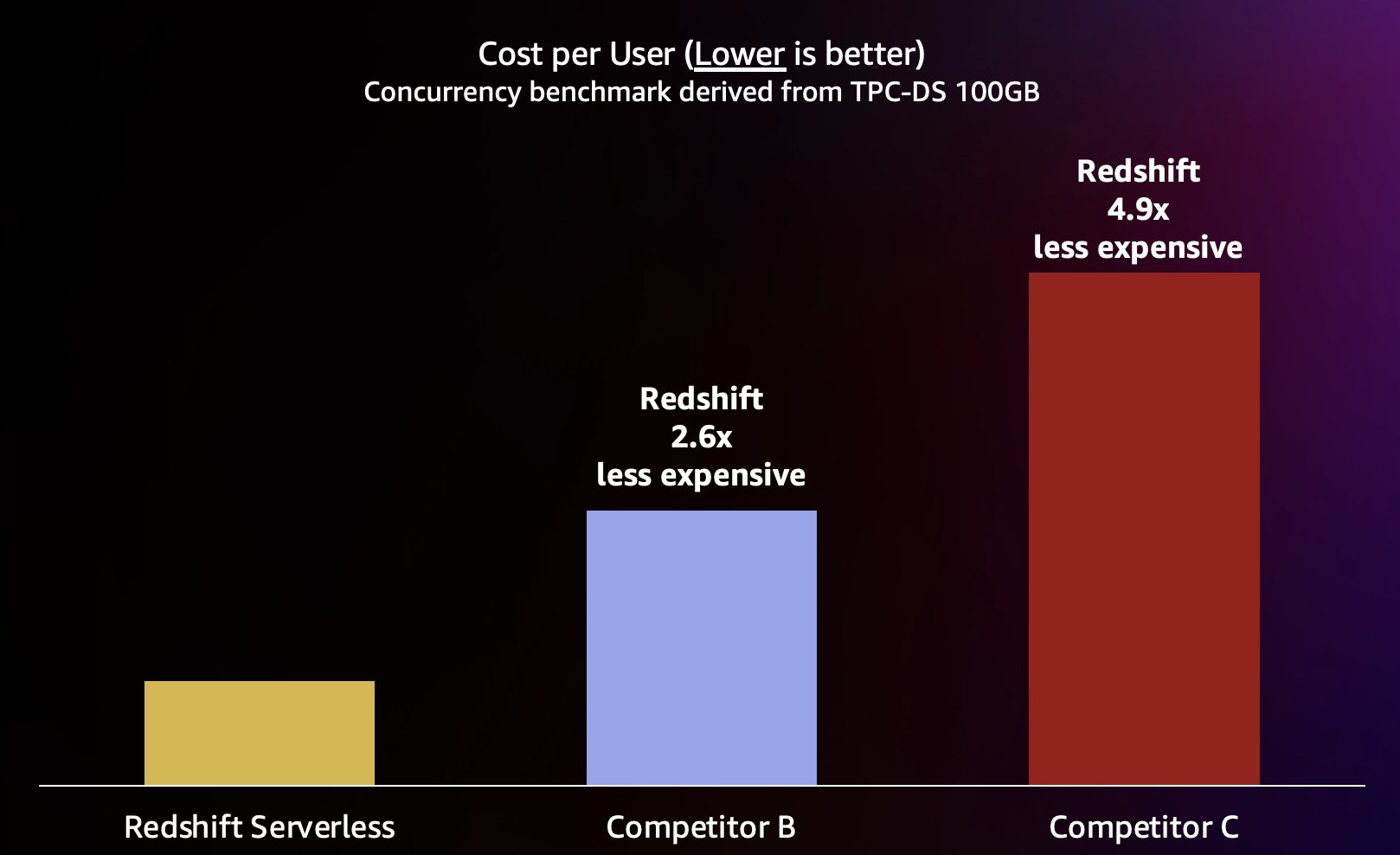
برای شبیهسازی این نوع حجم کاری، از یک معیار مشتق شده از TPC-DS با مجموعه داده 100 گیگابایتی استفاده کردیم. TPC-DS یک معیار استاندارد صنعتی است که شامل انواع پرس و جوهای معمولی انبار داده است. در این مقیاس نسبتاً کوچک 100 گیگابایتی، پرسوجوها در این معیار به طور متوسط در چند ثانیه بر روی Redshift Serverless اجرا میشوند که نشاندهنده انتظار کاربرانی است که داشبورد BI تعاملی را بارگذاری میکنند. ما بین 1 تا 200 آزمایش همزمان از این معیار را انجام دادیم، و بین 1 تا 200 کاربر را شبیهسازی کردیم که سعی داشتند داشبورد را همزمان بارگذاری کنند. ما همچنین آزمایش را در برابر چندین انبار داده ابری جایگزین محبوب تکرار کردیم که از کاهش خودکار نیز پشتیبانی میکنند (اگر با پست آشنا هستید آمازون Redshift به رهبری قیمت و عملکرد خود ادامه می دهد، ما رقیب A را وارد نکردیم زیرا از بزرگ شدن خودکار پشتیبانی نمی کند). ما میانگین زمان پاسخ پرس و جو را اندازهگیری کردیم، به این معنی که کاربر چقدر منتظر است تا درخواستهایش تمام شود (یا داشبوردش بارگیری شود). نتایج در نمودار زیر نشان داده شده است.
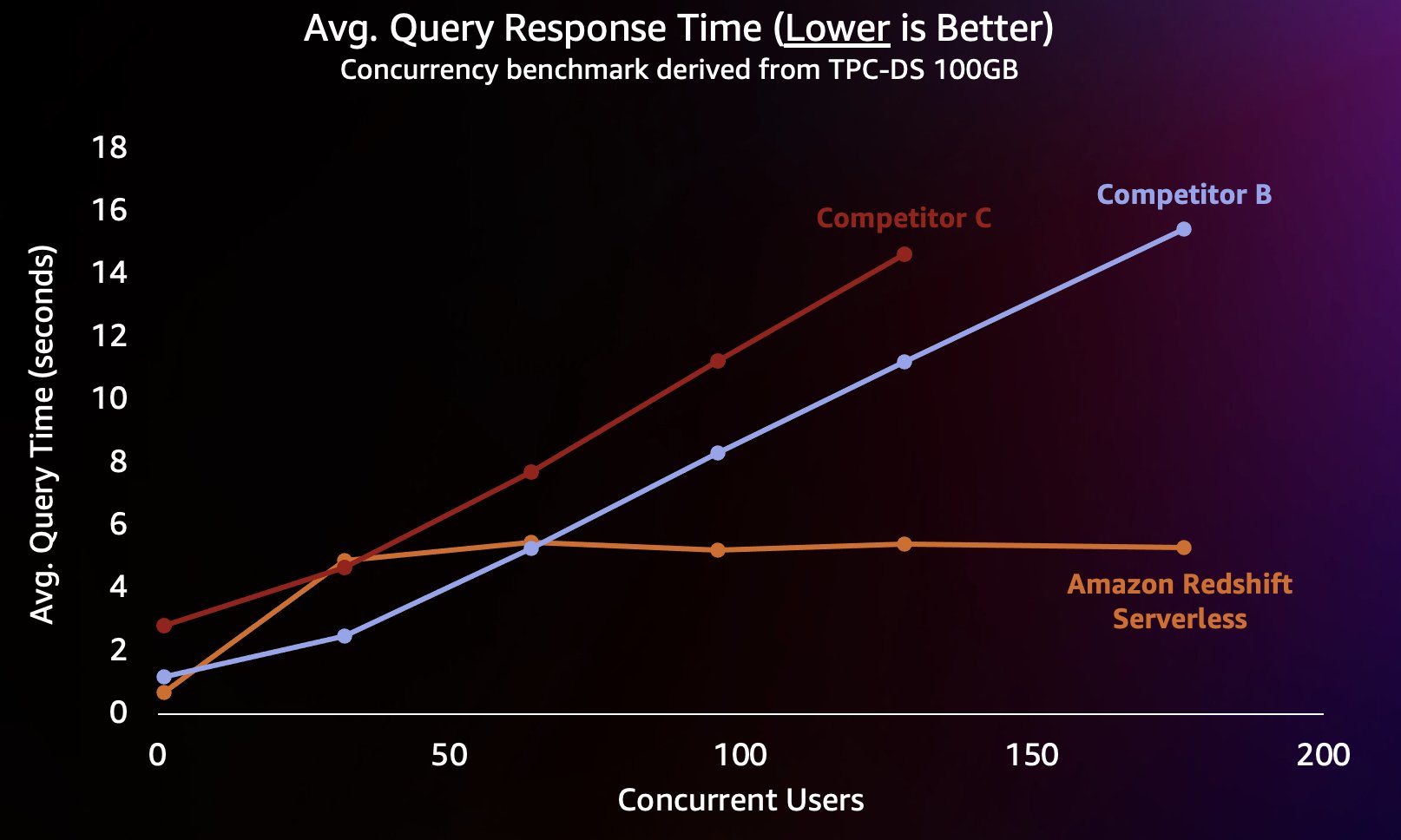
رقیب B تا حدود 64 پرس و جوی همزمان به خوبی مقیاس می شود، در این مرحله قادر به ارائه محاسبات اضافی نیست و پرس و جوها شروع به صف می کنند، که منجر به افزایش زمان پاسخ پرس و جو می شود. اگرچه رقیب C میتواند به صورت خودکار مقیاسبندی کند، اما نسبت به آمازون Redshift و رقیب B به میزان توان پرسوجو کمتر میشود و نمیتواند زمان اجرای پرس و جو را پایین نگه دارد. بهعلاوه، وقتی محاسبات تمام میشود، از پرسوجوهای صف پشتیبانی نمیکند، که مانع از مقیاسپذیری آن از حدود ۱۲۸ کاربر همزمان میشود. ارسال درخواست های اضافی فراتر از این توسط سیستم رد می شود.
در اینجا، Redshift Serverless قادر است زمان پاسخ پرس و جو را تقریباً در حدود 5 ثانیه ثابت نگه دارد، حتی زمانی که صدها کاربر به طور همزمان پرس و جو را اجرا می کنند. میانگین زمان پاسخ پرس و جو برای رقبای B و C به طور پیوسته با افزایش بار در انبارها افزایش می یابد، که در نتیجه کاربران مجبور می شوند زمانی طولانی تر (تا 16 ثانیه) منتظر بمانند تا درخواست های خود در زمانی که انبار داده مشغول است، بازگردند. این به این معنی است که اگر کاربر در تلاش است داشبورد را بهروزرسانی کند (که حتی ممکن است هنگام بارگیری مجدد چندین سؤال همزمان ارسال کند)، آمازون Redshift میتواند زمان بارگذاری داشبورد را بسیار سازگارتر نگه دارد حتی اگر داشبورد توسط دهها یا صدها داشبورد بارگیری شود. کاربران به طور همزمان
از آنجا که آمازون Redshift قادر به ارائه توان پرس و جو بسیار بالا برای پرس و جوهای کوتاه است (همانطور که در مورد آن نوشتیم آمازون Redshift به رهبری قیمت و عملکرد خود ادامه می دهد)، همچنین میتواند این همزمانیهای بالاتر را هنگام کاهش مقیاس به طور کارآمدتر و در نتیجه با هزینه بسیار پایینتری مدیریت کند. برای تعیین کمیت این، ما به قیمت-عملکرد با استفاده از منتشر شده نگاه می کنیم قیمت گذاری بر اساس تقاضا برای هر یک از انبارها در آزمون قبلی، در نمودار زیر نشان داده شده است. شایان ذکر است که با استفاده از موارد رزرو شده (RIs)به خصوص RI های 3 ساله خریداری شده با گزینه پرداخت تمام اولیه، کمترین هزینه را برای اجرای آمازون Redshift در خوشه های Provisioned دارند و در نتیجه بهترین عملکرد نسبی قیمت را در مقایسه با گزینه های درخواستی یا سایر گزینه های RI دارند.

بنابراین نه تنها آمازون Redshift میتواند عملکرد بهتری را در زمانهای همزمان بالاتر ارائه دهد، بلکه میتواند این کار را با هزینهی قابلتوجهی کمتر انجام دهد. هر نقطه داده در نمودار قیمت-عملکرد معادل هزینه اجرای معیار در همزمانی مشخص شده است. از آنجایی که قیمت-عملکرد خطی است، میتوانیم هزینه اجرای معیار در هر زمانی را بر همزمانی (تعداد کاربران همزمان در این نمودار) تقسیم کنیم تا به ما بگوییم افزودن هر کاربر جدید برای این معیار خاص چقدر هزینه دارد.
نتایج قبلی به سادگی قابل تکرار هستند. تمام پرس و جوهای مورد استفاده در معیار در ما موجود است مخزن GitHub و عملکرد با راه اندازی یک انبار داده، فعال کردن مقیاس همزمان در Amazon Redshift (یا ویژگی مقیاس خودکار مربوطه در سایر انبارها)، بارگیری داده ها از جعبه (بدون تنظیم دستی یا تنظیم خاص پایگاه داده) و سپس اجرای یک انبار اندازه گیری می شود. جریان همزمان پرس و جوها به صورت همزمان از 1 تا 200 در مراحل 32 در هر انبار داده. همان ارجاعات مخزن GitHub داده های TPC-DS از پیش تولید شده (و اصلاح نشده) را در سرویس ذخیره سازی ساده آمازون (Amazon S3) در مقیاس های مختلف با استفاده از کیت رسمی تولید داده TPC-DS.
بهینه سازی بارهای کاری سنگین
همانطور که قبلا ذکر شد، تیم آمازون Redshift به طور مداوم به دنبال فرصتهای جدید برای ارائه قیمت و عملکرد بهتر برای مشتریان خود است. یکی از بهبودهایی که اخیراً راه اندازی کردیم که عملکرد به طور قابل توجهی بهبود یافته است، بهینه سازی است که عملکرد پرس و جوها را روی داده های رشته ای تسریع می کند. برای مثال، ممکن است بخواهید کل درآمد حاصل از فروشگاههای خردهفروشی واقع در شهر نیویورک را با درخواستی مانند پیدا کنید. SELECT sum(price) FROM sales WHERE city = ‘New York’. این پرس و جو یک گزاره را روی داده های رشته ای اعمال می کند (city = ‘New York’). همانطور که می توانید تصور کنید، پردازش داده های رشته ای در برنامه های کاربردی انبار داده همه جا وجود دارد.
برای تعیین کمیت تعداد دفعات دسترسی بارهای کاری مشتریان به رشته ها، تجزیه و تحلیل دقیقی از استفاده از نوع داده رشته ای با استفاده از تله متری ناوگان ده ها هزار خوشه مشتری تحت مدیریت Amazon Redshift انجام دادیم. تجزیه و تحلیل ما نشان می دهد که در 90٪ از خوشه ها، ستون های رشته ای حداقل 30٪ از کل ستون ها را تشکیل می دهند، و در 50٪ از خوشه ها، ستون های رشته حداقل 50٪ از تمام ستون ها را تشکیل می دهند. علاوه بر این، اکثر پرس و جوها بر روی پلتفرم انبار داده ابری Amazon Redshift اجرا می شوند به حداقل یک ستون رشته دسترسی دارند. عامل مهم دیگر این است که دادههای رشته اغلب دارای کاردینالیته پایین هستند، به این معنی که ستونها دارای مجموعه نسبتاً کوچکی از مقادیر منحصر به فرد هستند. به عنوان مثال، اگرچه یک orders جدول نشان دهنده داده های فروش ممکن است حاوی میلیاردها ردیف باشد order_status ستون درون آن جدول ممکن است فقط چند مقدار منحصر به فرد را در میان آن میلیاردها ردیف داشته باشد، مانند pending, in processو completed.
از زمان نوشتن این مقاله، اکثر ستون های رشته ای در آمازون Redshift با فشرده سازی هستند LZO or ZSTD الگوریتم ها اینها الگوریتم های فشرده سازی همه منظوره خوبی هستند، اما برای استفاده از داده های رشته ای کم کاردینالیته طراحی نشده اند. به ویژه، آنها نیاز دارند که داده ها قبل از عمل از حالت فشرده خارج شوند و در استفاده از پهنای باند حافظه سخت افزاری کارایی کمتری دارند. برای داده های با کاردینالیته پایین، نوع دیگری از رمزگذاری وجود دارد که می تواند بهینه تر باشد: BYTEDICT. این رمزگذاری از یک طرح رمزگذاری فرهنگ لغت استفاده می کند که به موتور پایگاه داده اجازه می دهد تا مستقیماً روی داده های فشرده کار کند بدون اینکه نیازی به از حالت فشرده خارج کردن آن ها باشد.
برای بهبود بیشتر کارایی قیمت برای بارهای کاری سنگین، آمازون Redshift اکنون بهبودهای عملکردی دیگری را معرفی میکند که اسکنها و ارزیابیهای محمول را سرعت میبخشد، روی ستونهای رشتهای با کاردینالیته پایین که بهعنوان BYTEDICT کدگذاری میشوند، بین ۵ تا ۶۳ برابر سریعتر (نگاه کنید به نتایج در بخش بعدی) در مقایسه با کدهای فشرده سازی جایگزین مانند LZO یا ZSTD. Amazon Redshift این بهبود عملکرد را با بردار کردن اسکنها روی ستونهای رشتهای سبک وزن، کارآمد با CPU، رمزگذاری شده با BYTEDICT و با کاردینالیته پایین انجام میدهد. این بهینهسازیهای پردازش رشته از پهنای باند حافظه ارائه شده توسط سختافزار مدرن استفاده مؤثری میکنند و امکان تجزیه و تحلیل بلادرنگ روی دادههای رشتهای را فراهم میکنند. این قابلیتهای عملکرد جدید معرفیشده برای ستونهای رشتهای با کاردینالیته پایین (تا چند صد مقدار رشته منحصر به فرد) بهینه هستند.
با فعال کردن می توانید به طور خودکار از این بهبود رشته جدید با کارایی بالا بهره مند شوید بهینه سازی خودکار جدول در انبار داده Amazon Redshift شما. اگر بهینهسازی خودکار جدول را در جداول خود فعال ندارید، میتوانید توصیههایی را از آن دریافت کنید مشاور آمازون Redshift در کنسول Redshift آمازون در مورد مناسب بودن ستون رشته برای رمزگذاری BYTEDICT. همچنین میتوانید جداول جدیدی را تعریف کنید که دارای ستونهای رشتهای با کاردینالیته پایین با رمزگذاری BYTEDICT هستند. بهبودهای رشته در آمازون Redshift اکنون در همه مناطق AWS موجود است Amazon Redshift در دسترس است.
نتایج عملکرد
برای اندازهگیری تأثیر عملکرد بهبود رشتههایمان، یک مجموعه داده 10 ترابایتی (Tera Byte) ایجاد کردیم که شامل دادههای رشتهای با کاردینالیته پایین بود. ما سه نسخه از داده ها را با استفاده از رشته های کوتاه، متوسط و بلند تولید کردیم که مربوط به صدک 25، 50 و 75 طول رشته از تله متری ناوگان Redshift آمازون است. ما این داده ها را دو بار در آمازون Redshift بارگذاری کردیم و در یک مورد با استفاده از فشرده سازی LZO و در مورد دیگر با استفاده از فشرده سازی BYTEDICT آن را رمزگذاری کردیم. در نهایت، ما عملکرد جستوجوهای اسکن سنگین را اندازهگیری کردیم که بسیاری از ردیفها (۹۰٪ جدول)، تعداد ردیفهای متوسط (۵۰٪ جدول) و چند ردیف (۱٪ از جدول) را روی این موارد کم برمیگردانند. مجموعه داده های رشته کاردینالیتی. نتایج عملکرد در نمودار زیر خلاصه شده است.

جستارهایی با گزارههایی که با درصد بالایی از ردیفها مطابقت دارند، با کدگذاری جدید بردار BYTEDICT در مقایسه با LZO، 5 تا 30 برابر بهبود یافتهاند، در حالی که پرسوجوهایی با گزارههایی که با درصد پایینی از ردیفها مطابقت دارند، 10 تا 63 برابر در این معیار داخلی بهبود یافتهاند.
قیمت-عملکرد بدون سرور Redshift
علاوه بر نتایج عملکرد همزمان بالا ارائه شده در این پست، ما همچنین از معیار Cloud Data Warehouse مشتق از TPC-DS برای مقایسه قیمت-عملکرد Redshift Serverless با سایر انبارهای داده با استفاده از مجموعه داده بزرگتر 3 ترابایتی استفاده کردیم. ما انبارهای دادهای را انتخاب کردیم که قیمتهای مشابهی داشتند، در این مورد با استفاده از قیمتگذاری برحسب تقاضا در دسترس عموم، 10٪ از 32 دلار در ساعت. این نتایج نشان میدهد که مانند نمونههای Amazon Redshift RA3، Redshift Serverless در مقایسه با دیگر انبارهای داده ابری پیشرو، عملکرد قیمت بهتری را ارائه میدهد. مثل همیشه، این نتایج را می توان با استفاده از اسکریپت های SQL در ما تکرار کرد مخزن GitHub.

ما شما را تشویق می کنیم که Amazon Redshift را با استفاده از نرم افزار خود امتحان کنید اثبات مفهوم حجم کار به عنوان بهترین راه برای مشاهده اینکه Amazon Redshift چگونه می تواند نیازهای تجزیه و تحلیل داده شما را برآورده کند.
بهترین قیمت-عملکرد را برای حجم کاری خود پیدا کنید
معیارهای استفاده شده در این پست از معیار استاندارد صنعتی TPC-DS مشتق شده اند و دارای ویژگی های زیر هستند:
- طرح و داده ها بدون تغییر از TPC-DS استفاده می شوند.
- پرس و جوها با استفاده از کیت رسمی TPC-DS با پارامترهای پرس و جو تولید شده با استفاده از دانه تصادفی پیش فرض کیت TPC-DS تولید می شوند. در صورتی که انبار از گویش SQL پرسوجو پیشفرض TPC-DS پشتیبانی نمیکند، انواع پرسوجو مورد تأیید TPC برای یک انبار استفاده میشود.
- این آزمون شامل 99 عبارت TPC-DS SELECT است. این شامل مراحل نگهداری و توان عملیاتی نمی شود.
- برای تست همزمانی 3 ترابایتی، سه بار مصرف برق اجرا شد و بهترین اجرا برای هر انبار داده گرفته شد.
- قیمت-عملکرد برای پرس و جوهای TPC-DS به صورت هزینه در ساعت (USD) برابر زمان اجرای معیار بر حسب ساعت محاسبه می شود که معادل هزینه اجرای معیار است. آخرین قیمتگذاری بر اساس تقاضا منتشر شده برای همه انبارهای داده استفاده میشود و نه قیمتگذاری نمونه رزرو شده همانطور که قبلا ذکر شد.
ما این را معیار Cloud Data Warehouse می نامیم و شما به راحتی می توانید نتایج معیار قبلی را با استفاده از اسکریپت ها، پرس و جوها و داده های موجود در ما بازتولید کنید. مخزن GitHub. این از معیارهای TPC-DS همانطور که در این پست توضیح داده شد مشتق شده است، و به این ترتیب با نتایج منتشر شده TPC-DS قابل مقایسه نیست، زیرا نتایج آزمایش های ما با مشخصات رسمی مطابقت ندارد.
نتیجه
آمازون Redshift متعهد به ارائه بهترین قیمت و عملکرد صنعت برای طیف وسیعی از حجم کاری است. Redshift Serverless به صورت خطی با بهترین (کمترین) قیمت-عملکرد، پشتیبانی از صدها کاربر همزمان و در عین حال حفظ زمان پاسخ پرس و جو ثابت می کند. بر اساس نتایج آزمایشی که در این پست مورد بحث قرار گرفت، آمازون Redshift تا 2.6 برابر عملکرد قیمت بهتری در همان سطح همزمانی در مقایسه با نزدیکترین رقیب (رقیب B) دارد. همانطور که قبلاً ذکر شد، استفاده از Reserved Instances با گزینه all upfront 3 ساله، کمترین هزینه را برای اجرای Amazon Redshift به شما میدهد و در نتیجه عملکرد نسبی قیمت نسبی بهتری در مقایسه با قیمتگذاری نمونه درخواستی که در این پست استفاده کردیم، به شما میدهد. رویکرد ما برای بهبود عملکرد مستمر شامل ترکیبی منحصر به فرد از وسواس مشتری برای درک موارد استفاده مشتری و تنگناهای مقیاسپذیری مرتبط با آنها همراه با تجزیه و تحلیل مداوم دادههای ناوگان برای شناسایی فرصتها برای بهینهسازی عملکرد قابل توجه است.
هر حجم کاری ویژگی های منحصر به فردی دارد، بنابراین اگر تازه شروع کرده اید، الف اثبات مفهوم بهترین راه برای درک اینکه چگونه آمازون Redshift می تواند هزینه های شما را کاهش دهد در حالی که عملکرد بهتری ارائه می دهد. هنگام اجرای اثبات مفهومی خود، مهم است که روی معیارهای مناسب تمرکز کنید - توان عملیاتی پرس و جو (تعداد پرس و جو در ساعت)، زمان پاسخگویی، و قیمت-عملکرد. شما می توانید با اجرای یک اثبات مفهوم به تنهایی یا مبتنی بر داده تصمیم گیری کنید با کمک از AWS یا a یکپارچه سازی سیستم و شریک مشاوره.
برای بهروز ماندن از آخرین تحولات Amazon Redshift، موارد زیر را دنبال کنید چیزهای جدید در آمازون Redshift تغذیه.
درباره نویسندگان
 استفان گرومول یک مهندس عملکرد ارشد در تیم آمازون Redshift است که مسئولیت اندازه گیری و بهبود عملکرد Redshift را بر عهده دارد. در اوقات فراغت از آشپزی، بازی با سه پسرش و خرد کردن هیزم لذت می برد.
استفان گرومول یک مهندس عملکرد ارشد در تیم آمازون Redshift است که مسئولیت اندازه گیری و بهبود عملکرد Redshift را بر عهده دارد. در اوقات فراغت از آشپزی، بازی با سه پسرش و خرد کردن هیزم لذت می برد.
 راوی انیمی یک رهبر ارشد مدیریت محصول در تیم آمازون Redshift است و چندین حوزه عملکردی سرویس انبار داده ابری Amazon Redshift از جمله عملکرد، تجزیه و تحلیل فضایی، جذب جریانی و استراتژیهای مهاجرت را مدیریت میکند. او دارای تجربه با پایگاههای اطلاعاتی رابطهای، پایگاههای داده چند بعدی، فناوریهای اینترنت اشیا، خدمات زیرساختهای ذخیرهسازی و محاسباتی و اخیراً بهعنوان بنیانگذار استارتآپ با استفاده از هوش مصنوعی/عمیق، بینایی کامپیوتر و روباتیک است.
راوی انیمی یک رهبر ارشد مدیریت محصول در تیم آمازون Redshift است و چندین حوزه عملکردی سرویس انبار داده ابری Amazon Redshift از جمله عملکرد، تجزیه و تحلیل فضایی، جذب جریانی و استراتژیهای مهاجرت را مدیریت میکند. او دارای تجربه با پایگاههای اطلاعاتی رابطهای، پایگاههای داده چند بعدی، فناوریهای اینترنت اشیا، خدمات زیرساختهای ذخیرهسازی و محاسباتی و اخیراً بهعنوان بنیانگذار استارتآپ با استفاده از هوش مصنوعی/عمیق، بینایی کامپیوتر و روباتیک است.
 عامر شاه یک مهندس ارشد در تیم خدمات آمازون Redshift است.
عامر شاه یک مهندس ارشد در تیم خدمات آمازون Redshift است.
 سانکت هاسه مدیر توسعه نرم افزار در تیم Amazon Redshift Service است.
سانکت هاسه مدیر توسعه نرم افزار در تیم Amazon Redshift Service است.
 اورستیس پلی کرونیو یک مهندس اصلی در تیم خدمات آمازون Redshift است.
اورستیس پلی کرونیو یک مهندس اصلی در تیم خدمات آمازون Redshift است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- : دارد
- :است
- :نه
- :جایی که
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- قادر
- درباره ما
- تسریع می شود
- دسترسی
- قابل دسترسی است
- دستیابی به
- در میان
- اضافه
- اضافه کردن
- اضافه
- اضافی
- پیشرفته
- مزیت - فایده - سود - منفعت
- فراهم شده است
- در برابر
- الگوریتم
- معرفی
- اجازه می دهد تا
- همچنین
- جایگزین
- جایگزین
- هر چند
- همیشه
- آمازون
- آمازون خدمات وب
- مقدار
- an
- تحلیل
- علم تجزیه و تحلیل
- تجزیه و تحلیل
- و
- دیگر
- هر
- برنامه های کاربردی
- با استفاده از
- روش
- هستند
- مناطق
- دور و بر
- AS
- ظاهر
- مرتبط است
- At
- توجه
- خودکار
- خودکار
- اتوماتیک
- بطور خودکار
- در دسترس
- میانگین
- AWS
- b
- پهنای باند
- مستقر
- BE
- زیرا
- قبل از
- شروع
- بودن
- محک
- معیار
- سود
- بهترین
- بهتر
- میان
- خارج از
- میلیاردها
- هر دو
- تنگناها
- جعبه
- به ارمغان بیاورد
- پهن
- کسب و کار
- هوش تجاری
- مشغول
- اما
- by
- کیک
- محاسبه
- محاسبه
- صدا
- CAN
- قابلیت های
- مورد
- موارد
- مشخصات
- مشخص شده است
- چارت سازمانی
- خرد کردن
- را انتخاب
- شهر:
- ابر
- خوشه
- ستون
- ستون ها
- ترکیب
- مرتکب شده
- مشترک
- قابل مقایسه
- مقايسه كردن
- مقایسه
- مقایسه
- رقیب
- رقبای
- پیچیده
- مطابق
- محاسبه
- کامپیوتر
- چشم انداز کامپیوتر
- مفهوم
- رقیب
- شرط
- انجام
- استوار
- کنسول
- ثابت
- به طور مداوم
- را تشکیل می دهند
- مشاوره
- شامل
- به طور مستمر
- ادامه دادن
- ادامه
- مداوم
- به طور مداوم
- پخت و پز
- متناظر
- هزینه
- هزینه
- همراه
- ایجاد
- بسیار سخت
- مشتری
- مشتریان
- داشبورد
- داشبورد
- داده ها
- تحلیل داده ها
- تجزیه و تحلیل داده ها
- پردازش داده ها
- مجموعه داده ها
- انبار داده
- انبارهای داده
- داده محور
- پایگاه داده
- پایگاه های داده
- مجموعه داده ها
- تاریخ
- تصمیم
- به طور پیش فرض
- تعريف كردن
- ارائه
- تحویل
- ارائه
- نشات گرفته
- شرح داده شده
- طراحی
- مطلوب
- جزئیات
- دقیق
- پروژه
- تحولات
- مختلف
- مستقیما
- بحث و تبادل نظر
- بحث کردیم
- تنوع
- تقسیم
- do
- میکند
- نمی کند
- آیا
- رانده
- هر
- پیش از آن
- به آسانی
- خوردن
- موثر
- موثر
- موثر
- فعال
- را قادر می سازد
- تشویق
- موتور
- مهندس
- افزایش
- تقویت
- پیشرفت ها
- وارد
- معادل
- به خصوص
- اتر (ETH)
- ارزیابی
- حتی
- همه چیز
- مثال
- مثال ها
- انتظار
- تجربه
- عصاره
- عامل
- آشنا
- بسیار
- FAST
- سریعتر
- ویژگی
- کمی از
- سرانجام
- پیدا کردن
- پایان
- نام خانوادگی
- ناوگان
- تمرکز
- به دنبال
- پیروی
- برای
- یافت
- موسس
- از جانب
- تابعی
- بیشتر
- همه منظوره
- تولید
- نسل
- دریافت کنید
- گرفتن
- GitHub
- می دهد
- رفتن
- خوب
- در حال رشد
- رشد می کند
- دسته
- سخت افزار
- آیا
- داشتن
- he
- زیاد
- بالاتر
- خود را
- نگه داشتن
- برگزاری
- ساعت
- ساعت ها
- چگونه
- HTML
- HTTP
- HTTPS
- صد
- صدها نفر
- دلخواه
- ایده آل
- شناسایی
- if
- نشان دادن
- تصور کنید
- تأثیر
- مهم
- جنبه مهم
- بهبود
- بهبود یافته
- بهبود
- ارتقاء
- بهبود
- in
- شامل
- شامل
- از جمله
- افزایش
- افزایش
- افزایش
- نشان می دهد
- صنعت
- شالوده
- نمونه
- نمونه ها
- ادغام
- اطلاعات
- تعاملی
- داخلی
- مداخله
- به
- معرفی
- معرفی
- سرمایه گذاری
- شامل
- اینترنت اشیا
- IT
- ITS
- پیوستن
- JPG
- تنها
- نگاه داشتن
- بسته لوازم
- دانا
- بزرگ
- بزرگتر
- بعد
- آخرین
- آخرین تحولات
- راه اندازی
- راه اندازی
- رهبر
- برجسته
- یادگیری
- کمترین
- کمتر
- سطح
- سبک وزن
- پسندیدن
- کوچک
- بار
- بارگیری
- بارهای
- واقع شده
- طولانی
- دیگر
- نگاه کنيد
- به دنبال
- کم
- کاهش
- پایین ترین
- حفظ
- نگهداری
- نگهداری
- اکثریت
- ساخت
- اداره می شود
- مدیریت
- مدیر
- مدیریت می کند
- کتابچه راهنمای
- بسیاری
- مسابقه
- مسائل
- ممکن است..
- معنی
- به معنی
- اندازه
- اندازه گیری
- اندازه گیری
- متوسط
- دیدار
- حافظه
- ذکر شده
- قدرت
- مهاجرت
- دقیقه
- مدرن
- دوشنبه
- پول
- بیش
- علاوه بر این
- اکثر
- بسیار
- از جمله
- نیاز
- ضروری
- نیازهای
- جدید
- نیویورک
- شهر نیویورک
- به تازگی
- بعد
- نه
- توجه داشته باشید
- اشاره کرد
- یادداشت برداری
- اکنون
- عدد
- of
- رسمی
- غالبا
- on
- بر روی تقاضا
- ONE
- فقط
- کار
- عمل
- فرصت ها
- بهینه
- بهینه سازی
- بهینه سازی
- گزینه
- گزینه
- or
- دیگر
- ما
- خارج
- روی
- خود
- پارامترهای
- ویژه
- الگو
- الگوهای
- پرداخت
- پرداخت
- برای
- درصد
- کارایی
- برنامه ریزی
- سکو
- افلاطون
- هوش داده افلاطون
- PlatoData
- بازی
- نقطه
- محبوب
- ممکن
- پست
- قدرت
- قابل پیش بینی
- ارائه شده
- جلوگیری از
- قیمت
- قیمت گذاری
- اصلی
- پردازش
- در حال پردازش
- محصول
- مدیریت تولید
- اثبات
- اثبات مفهوم
- ارائه
- عمومی
- منتشر شده
- خریداری شده
- نمایش ها
- به سرعت
- تصادفی
- خواندن
- دنیای واقعی
- زمان واقعی
- گرفتن
- اخیر
- تازه
- توصیه
- منابع
- مناطق
- رد شد..
- نسبی
- نسبتا
- از بین بردن
- مکرر
- تکراری
- تکرار شده
- گزارش ها
- نماینده
- نمایندگی
- نیاز
- محفوظ می باشد
- پاسخ
- مسئوليت
- نتیجه
- نتایج
- خرده فروشی
- برگشت
- درامد
- این فایل نقد می نویسید:
- راست
- رباتیک
- ROI
- دویدن
- در حال اجرا
- اجرا می شود
- حراجی
- همان
- ذخیره
- دید
- مقیاس پذیری
- مقیاس
- مقیاس ها
- مقیاس گذاری
- اسکن
- طرح
- اسکریپت
- دوم
- ثانیه
- بخش
- دیدن
- دانه
- ارشد
- خدمت
- بدون سرور
- سرویس
- خدمات
- تنظیم
- برپایی
- چند
- اشتراک گذاری
- کوتاه
- باید
- نشان
- نشان داده شده
- قابل توجه
- به طور قابل توجهی
- به طور مشابه
- ساده
- به طور همزمان
- تنها
- اندازه
- اندازه
- کوچک
- So
- نرم افزار
- توسعه نرم افزار
- فضایی
- مشخصات
- مشخص شده
- سرعت
- خرج کردن
- صرف
- سنبله
- SQL
- شروع
- آغاز شده
- شروع
- ماندن
- به طور پیوسته
- مراحل
- ذخیره سازی
- پرده
- ساده
- استراتژی ها
- جریان
- جریان
- رشته
- ارسال
- چنین
- مناسب بودن
- پشتیبانی
- حمایت از
- سیستم
- جدول
- گرفتن
- صورت گرفته
- تیم
- تکنیک
- فن آوری
- گفتن
- ده ها
- آزمون
- تست
- نسبت به
- که
- La
- شان
- سپس
- آنجا.
- از این رو
- اینها
- آنها
- فکر می کنم
- این
- کسانی که
- هزاران نفر
- سه
- توان
- زمان
- بار
- به
- امروز
- جمع
- ترافیک
- دگرگون کردن
- شفاف
- امتحان
- تلاش
- دو برابر
- دو
- نوع
- انواع
- نوعی
- همه جا
- ناتوان
- غیر معمول
- فهمیدن
- منحصر به فرد
- غیرقابل پیش بینی
- تا
- us
- استفاده
- دلار آمریکا
- استفاده کنید
- مورد استفاده
- استفاده
- کاربر
- کاربران
- استفاده
- با استفاده از
- ارزشها
- تنوع
- مختلف
- بسیار
- نمایش ها
- عملا
- دید
- صبر کنيد
- می خواهم
- انبار کالا
- بود
- مسیر..
- راه
- we
- وب
- خدمات وب
- هفته
- خوب
- بود
- چی
- چه زمانی
- در حالیکه
- که
- در حین
- چرا
- وسیع
- اراده
- با
- در داخل
- بدون
- با ارزش
- خواهد بود
- نوشته
- نوشت
- نیویورک
- شما
- شما
- زفیرنت