یکی از جنبه های خرد دریافتی در مورد هوش مصنوعی این بوده است که تمام نوآوری ها از موتورهای بزرگ یادگیری/آموزش ماشین در فضای ابری شروع می شود. برخی از این نوآوری ممکن است در نهایت به شکل کاهش یافته/محدود به لبه مهاجرت کنند. تا حدی این نشان دهنده جدید بودن این رشته بود. شاید تا حدی نیاز به راهحلهای از پیش بستهبندیشده یکاندازه و بسیاری برای ویجتهای اینترنت اشیا را نیز منعکس کند. جایی که طراحان در محصولات خود به دنبال هوشمندی بودند اما کاملاً آماده نبودند که متخصص طراحی ML شوند. اما در حال حاضر آن طراحان در حال جبران هستند. آنها همان بیانیه های مطبوعاتی را می خوانند و تحقیق می کنند که همه ما انجام می دهیم و رقبایشان. آنها می خواهند از همین پیشرفت ها بهره ببرند، در حالی که به محدودیت های قدرت و هزینه پایبند هستند.

تشخیص چهره
تمایز هوش مصنوعی در لبه
همه چیز در مورد تمایز در یک بسته هزینه / توان قابل قبول است. بدست آوردن آن از راه حل های از پیش بسته بندی شده سخت است. بالاخره رقبا به راه حل های یکسانی دسترسی دارند. آنچه واقعاً میخواهید مجموعهای از گزینههای الگوریتم است که در پردازنده بهعنوان شتابدهندههای اختصاصی مدلسازی شدهاند که آماده استفاده هستند، با قابلیت لایهبندی بر روی ارزش افزوده مبتنی بر نرمافزار خودتان. ممکن است فکر کنید که در اینجا نمیتوانید کارهای زیادی انجام دهید، خارج از مدیریت و تنظیم. دوره و زمانه عوض شده. CEVA اخیراً پردازنده هوش مصنوعی NeuPro-M خود را معرفی کرده است که امکان بهینهسازی را با استفاده از برخی از آخرین پیشرفتهای ML، عمیق در طراحی الگوریتم فراهم میکند.
خوب، بنابراین کنترل بیشتر الگوریتم، اما به چه منظور؟ شما میخواهید عملکرد را در هر وات بهینه کنید، اما معیار استاندارد - TOPS/W - بسیار درشت است. برنامه های تصویربرداری باید بر اساس فریم در ثانیه (fps) بر وات اندازه گیری شوند. برای کاربردهای امنیتی، ایمنی خودرو یا جلوگیری از برخورد هواپیماهای بدون سرنشین، زمان تشخیص در هر فریم بسیار بیشتر از عملیات خام در ثانیه است. بنابراین پلتفرمی مانند NeuPro-M که می تواند در اصل تا هزاران فریم بر ثانیه را ارائه دهد، نرخ فریم در ثانیه واقعی 30 تا 60 فریم در ثانیه را با قدرت بسیار کم کنترل می کند. این یک پیشرفت واقعی در راه حل های AI از پیش بسته بندی شده سنتی است.
امکان پذیر ساختن آن
الگوریتمهای نهایی با شمارهگیری ویژگیهایی که در مورد آنها خواندهاید، ساخته میشوند و با طیف گستردهای از گزینههای کوانتیزاسیون شروع میشوند. همین امر در مورد تنوع نوع داده در فعال سازی و وزن در طیف وسیعی از اندازه بیت صدق می کند. واحد ضرب عصبی (NMU) به طور بهینه از گزینه های عرض بیت چندگانه برای فعال سازی و وزن هایی مانند 8×2 یا 16×4 پشتیبانی می کند و از انواعی مانند 8×10 نیز پشتیبانی می کند.
این پردازنده از Winograd Transforms یا کانولوشن های کارآمد پشتیبانی می کند که تا 2 برابر افزایش عملکرد و کاهش قدرت با کاهش دقت محدود را ارائه می دهد. بسته به مقدار مقادیر صفر (در داده یا وزن)، موتور اسپاسیت را به مدل اضافه کنید تا شتاب 4 برابری داشته باشد. در اینجا، واحد ضربکننده عصبی طیفی از انواع دادهها را پشتیبانی میکند که از 2×2 تا 16×16، و نقطه شناور (و Bfloat) از 16×16 تا 32×32 ثابت شدهاند.
منطق جریان گزینه هایی را برای مقیاس بندی نقطه ثابت، فعال سازی و ادغام فراهم می کند. پردازنده برداری به شما امکان می دهد لایه های سفارشی خود را به مدل اضافه کنید. ممکن است فکر کنید "پس چه، همه از آن پشتیبانی می کنند"، اما در زیر در مورد توان عملیاتی را مشاهده کنید. همچنین مجموعهای از ویژگیهای نسل بعدی هوش مصنوعی شامل ترانسفورماتورهای بینایی، پیچیدگی سه بعدی، پشتیبانی از RNN و تجزیه ماتریس نیز وجود دارد.
بسیاری از گزینه های الگوریتم، همه توسط بهینه سازی شبکه برای راه حل تعبیه شده شما از طریق چارچوب CDNN برای بهره برداری کامل از قدرت الگوریتم های ML شما پشتیبانی می شوند. CDNN ترکیبی از یک کامپایلر گراف استنتاج شبکه و یک ابزار افزودنی اختصاصی PyTorch است. این ابزار مدل را هرس میکند، بهصورت اختیاری از فشردهسازی مدل از طریق تجزیه ماتریس پشتیبانی میکند، و آموزش مجدد آگاهی از کوانتیزاسیون را اضافه میکند.
بهینه سازی توان عملیاتی
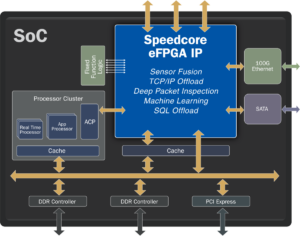
در اکثر سیستمهای هوش مصنوعی، برخی از این عملکردها ممکن است در موتورهای تخصصی انجام شوند، که نیاز به بارگیری دادهها و بارگیری مجدد تبدیل پس از تکمیل دارند. این تأخیر زیادی اضافه شده است (و شاید قدرت را به خطر بیاندازد)، که عملکرد را در مدل دیگر قوی شما کاملاً تضعیف می کند. NeuPro-M با اتصال این مشکل را برطرف می کند تمام این شتاب دهنده ها به طور مستقیم به یک حافظه پنهان L1 مشترک. حفظ پهنای باند بسیار بالاتر از آنچه در شتاب دهنده های معمولی می بینید.
به عنوان یک مثال قابل توجه، واحد پردازش برداری که معمولاً برای تعریف لایه های سفارشی استفاده می شود، در همان سطح با سایر شتاب دهنده ها قرار می گیرد. الگوریتم های پیاده سازی شده شما در VPU از شتابی مشابه بقیه مدل بهره می برند. باز هم، برای تسریع لایه های سفارشی، نیازی به تخلیه و بارگیری مجدد نیست. علاوه بر این، شما می توانید تا 8 عدد از این موتورهای NPM (همه شتاب دهنده ها، به علاوه کش NPM L1) داشته باشید. NeuPro-M همچنین سطح قابل توجهی از بهینه سازی پهنای باند کنترل شده توسط نرم افزار را بین کش L2 و حافظه نهان L1 ارائه می دهد، بهینه سازی کنترل فریم و به حداقل رساندن نیاز به دسترسی های DDR.
طبیعتا NeuPro-M همچنین ترافیک داده و وزن را به حداقل می رساند. برای دادهها، شتابدهندهها همان حافظه پنهان L1 را به اشتراک میگذارند. یک پردازنده میزبان می تواند داده ها را مستقیماً با NeuPro-M L2 ارتباط برقرار کند و دوباره نیاز به انتقال DDR را کاهش دهد. NeuPro-M وزن های روی تراشه را در انتقال با حافظه DDR فشرده و از حالت فشرده خارج می کند. می تواند همین کار را با فعال سازی انجام دهد.
اثبات در شتاب fps/W
CEVA معیارهای استانداردی را با استفاده از ترکیبی از الگوریتمهای مدلسازی شده در شتابدهندهها، از بومی تا وینوگراد، تا وینوگراد+اسپارسیتی، تا وینوگراد+اسپارسیتی+4×4 اجرا کرد. هر دو بنچمارک بهبود عملکرد را تا 3 برابر، با قدرت (fps/W) حدود 5 برابر برای ISP NN نشان دادند. راه حل NeuPro-M در مقایسه با نسل قبلی NeuPro-S، منطقه کوچکتر، عملکرد 4X، 1/3 قدرت را ارائه می دهد.
روندی وجود دارد که من به طور کلی می بینم که با ترکیب الگوریتم های متعدد، عملکرد نهایی را به دست آوریم. چیزی که CEVA اکنون با این پلتفرم امکان پذیر کرده است. می توانید بیشتر بخوانید اینجا.
اشتراک گذاری این پست از طریق: منبع: https://semiwiki.com/artificial-intelligence/306655-ai-at-the-edge-no-longer-means-dumbed-down-ai/
- 3d
- درباره ما
- شتاب دهنده ها
- دسترسی
- در میان
- اضافه کردن در
- اضافه
- مدیر سایت
- مزیت - فایده - سود - منفعت
- AI
- سیستم های هوش مصنوعی
- الگوریتم
- الگوریتم
- معرفی
- برنامه های کاربردی
- محدوده
- دور و بر
- خودرو
- نهانگاه
- CEVA
- ابر
- ترکیب
- رقبای
- داده ها
- طرح
- تنوع
- وزوز
- لبه
- مثال
- کارشناسان
- بهره برداری
- چهره
- تشخیص چهره
- امکانات
- فرم
- چارچوب
- توابع
- اداره
- اینجا کلیک نمایید
- HTTPS
- تصویربرداری
- اجرا
- از جمله
- ابداع
- معرفی
- اینترنت اشیا
- ISP
- IT
- آخرین
- سطح
- محدود شده
- ماتریس
- ML
- الگوریتم های ML
- مدل
- بیش
- ضروری
- شبکه
- عصبی
- پیشنهادات
- عملیات
- گزینه
- دیگر
- در غیر این صورت
- کارایی
- شاید
- سکو
- قدرت
- دقت
- فشار
- اعلامیه مطبوعاتی
- محصولات
- اثبات
- فراهم می کند
- مارماهی
- محدوده
- نرخ
- خام
- واقع بینانه
- منتشر شده
- تحقیق
- REST
- ایمنی
- مقیاس گذاری
- تیم امنیت لاتاری
- تنظیم
- اشتراک گذاری
- به اشتراک گذاشته شده
- So
- مزایا
- تخصصی
- پشتیبانی
- پشتیبانی
- پشتیبانی از
- سیستم های
- از طریق
- ابزار
- سنتی
- ترافیک
- دگرگون کردن
- دید
- چی
- در داخل